


Csak az első alkalommal fáj!
Sziasztok! Kedves Barátaim! Ebben a cikkben szeretném megosztani tapasztalataimat a TensorRT, RetinaNet használatáról a repository alapján. (ez a hivatalos fehérrépa villája , amely lehetővé teszi, hogy a lehető leghamarabb elkezdje használni az optimalizált modelleket a termelésben). Üzenetek görgetése a közösségi csatornákon , Kérdésekbe ütközöm a TensorRT használatával kapcsolatban, és a kérdések többnyire ismétlődnek, ezért úgy döntöttem, írok a lehető legteljesebb Útmutató a gyors következtetés használatához TensorRT, RetinaNet, Unet és docker alapján.
Feladatleírás
A feladatot a következőképpen javaslom megfogalmazni: fel kell címkéznünk az adathalmazt, Pytorch 1.3+-on kell betanítanunk a RetinaNet/Unet hálózatot, a kapott súlyokat ONNX-re kell konvertálni, majd TensorRT motorra kell konvertálni, és az egészet Dockerben kell futtatni, lehetőleg Ubuntu 18-as verzióban, és rendkívül kívánatos az ARM (Jetson)* architektúrán, ezáltal minimalizálva a környezet manuális telepítését. A végeredmény egy olyan konténer lesz, amely nemcsak a RetinaNet/Unet exportálására és betanítására alkalmas, hanem az osztályozási és szegmentálási rendszerek teljes értékű fejlesztésére és betanítására is, az összes szükséges hardverrel.
1. szakasz. A környezet előkészítése
Itt fontos megjegyezni, hogy az utóbbi időben teljesen elhagytam legalább néhány könyvtár használatát és telepítését asztali gépeken, valamint devboxon. Az egyetlen dolog, amit létre kell hozni és telepíteni, az a python virtuális környezet és a cuda 10.2 (egyetlen nvidia illesztőprogramra korlátozódhat) a deb-ből.
Tegyük fel, hogy van egy frissen telepített Ubuntu 18. Telepítsük a cuda 10.2-es verzióját (deb). Nem fogok részletesen belemenni a telepítési folyamatba, a hivatalos dokumentáció bőven elegendő.
Most telepítsük a dockert, a docker telepítési útmutatója könnyen megtalálható, itt egy példa , a 19+ verzió már elérhető - telepítse. Nos, ne felejtse el lehetővé tenni a docker használatát sudo nélkül, így kényelmesebb lesz. Miután minden megoldódott, a következőket tesszük:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
És még csak a hivatalos adattárat sem kell megnéznie .
Most csináljuk a git klónozást .
Már csak egy kevés van hátra, ahhoz, hogy nvidia képpel kezdhessük használni a dockert, regisztrálnunk kell az NGC Cloudban és be kell jelentkeznünk. Menjünk ide , regisztráljon, és miután beléptünk az NGC Cloudba, kattintson a képernyő bal felső sarkában található BEÁLLÍTÁS elemre, vagy kövesse ezt a linket . Kattintson a „kulcs generálása” gombra. Azt javaslom, hogy mentse el, különben a következő látogatáskor újra elő kell generálnia, és ennek megfelelően telepítenie kell egy új autóra, és meg kell ismételnie ezt a műveletet.
Csináljuk:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
A felhasználónév egyszerűen másolásra került. Nos, vegyük figyelembe a környezetet!
2. szakasz: A dokkoló konténer felépítése
Munkánk második szakaszában dokkolót építünk és megismerkedünk a belső részeivel.
Menjünk a gyökérmappába a retina-examples projekt kapcsán, és hajtsuk végre
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
A dockert úgy építjük, hogy átadjuk az aktuális felhasználót - ez nagyon hasznos, ha az aktuális felhasználó jogaival írsz valamit egy csatlakoztatott VOLUME-ba, különben root és pain lesz.
Amíg a docker épít, vizsgáljuk meg a Dockerfile-t:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Amint a szövegből látható, fogjuk az összes kedvenc könyvtárunkat, lefordítjuk a retinanetet, és hozzáadunk néhány alapvető eszközt a könnyebb használat érdekében. Ubuntu és konfigurálja az OpenSSH szervert. Az első sor örökli az NVIDIA rendszerképet, amelyhez létrehoztuk az NGC Cloud bejelentkezést, és amely tartalmazza a Pytorch1.3-at, a TensorRT6.xxx-et és egy csomó más könyvtárat, amelyek lehetővé teszik számunkra a detektorunk CPP forráskódjának lefordítását.
3. szakasz: A Docker-tároló indítása és hibakeresése
Térjünk át a konténer és a fejlesztői környezet használatának fő esetére; először indítsuk el az nvidia dockert. Csináljuk:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestA tároló mostantól elérhető az ssh-n keresztül @helyi kiszolgáló. A sikeres indítás után nyissa meg a projektet a PyCharmban. Legközelebb nyitunk
Settings->Project Interpreter->Add->Ssh Interpreter Lépés 1
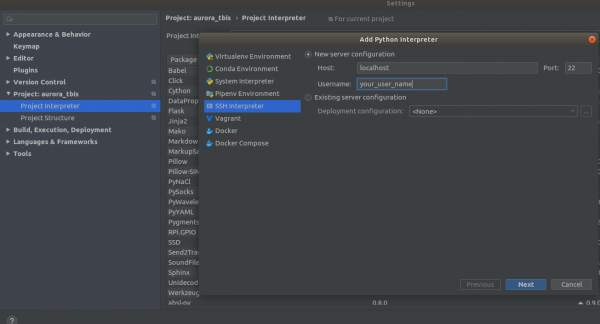
Lépés 2
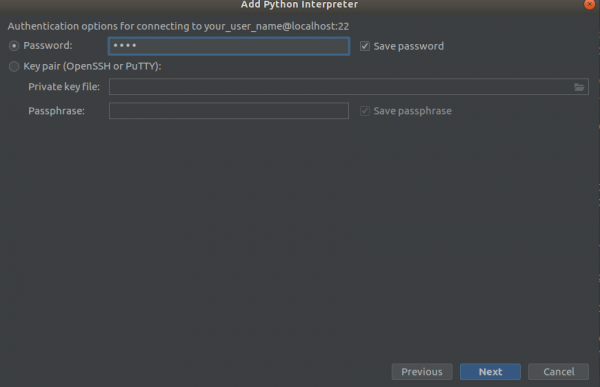
Lépés 3
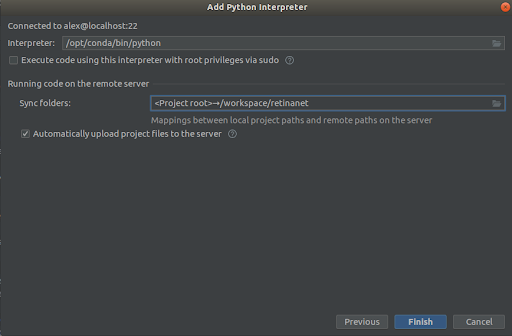
Mindent úgy választunk ki, mint a képernyőképeken,
Interpreter -> /opt/conda/bin/python- ez lesz a Python3.6-ban és
Sync folder -> /workspace/retinanetMegnyomjuk a befejezést, megvárjuk az indexelést, és kész, a környezet használatra kész!
FONTOS !!! Az indexelés után azonnal húzza ki a Retinanethez összeállított fájlokat a dockerből. A projektgyökér helyi menüjében válassza ki az elemet
Deployment->DownloadMegjelenik egy fájl és két mappa: build, retinanet.egg-info és _С.so
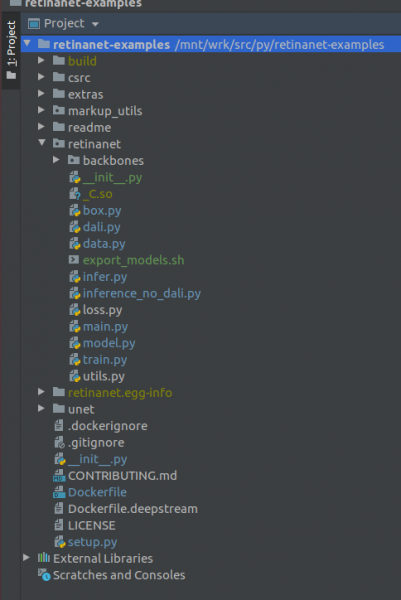
Ha a projektje így néz ki, akkor a környezet látja az összes szükséges fájlt, és készen állunk a RetinaNet betanítására.
4. szakasz: Címkézze fel az adatokat és tanítsa be a detektort
Jelölésre főleg használom — kellemes és kényelmes eszköz, a közelmúltban egy csomó hibát kijavítottak, és lényegesen jobban viselkedett.
Tételezzük fel, hogy megjelölte az adatkészletet és letöltötte, de nem tudja azonnal elhelyezni a RetinaNet-ünkben, mivel az saját formátumban van, és ehhez át kell konvertálnunk COCO-ba. A konvertáló eszköz a következő helyen található:
markup_utils/supervisly_to_coco.pyKérjük, vegye figyelembe, hogy a szkriptben szereplő kategória egy példa, és be kell illesztenie a sajátját (nem kell hozzáadnia a háttérkategóriát)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Valamiért az eredeti adattár szerzői úgy döntöttek, hogy a COCO/VOC-on kívül semmi mást nem tanítasz a detektálásra, ezért kicsit szerkeszteniük kellett a forrásfájlt.
retinanet/dataset.pyHa hozzáadja kedvenc kiegészítéseit ide és vágja ki a vezetékes kategóriákat a COCO-ból. Lehetőség van nagy érzékelési területek kivágására is, ha kis objektumokat keresel nagy képeken, akkor van egy kis adatkészleted =), és semmi sem működik, de erről majd máskor.
Általában a vonathurok is gyenge, kezdetben nem mentett ellenőrzőpontokat, valami szörnyű menetrendet használt stb. De most már csak a gerincet kell kiválasztania és végrehajtania
/opt/conda/bin/python retinanet/main.pyparaméterekkel:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
A konzolon látni fogja:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148A paraméterek teljes készletének felfedezéséhez nézze meg
retinanet/main.pyÁltalában szabványosak az észleléshez, és leírásuk is van. Kezdje el az edzést, és várja meg az eredményeket. A következtetésre egy példa látható:
retinanet/infer_example.pyvagy futtasd a parancsot:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
Az adattárba már beépített Focal Loss és több gerinchálózat is van, és könnyen beágyazható a saját
retinanet/backbones/*.pyA táblázatban a szerzők megadnak néhány jellemzőt:
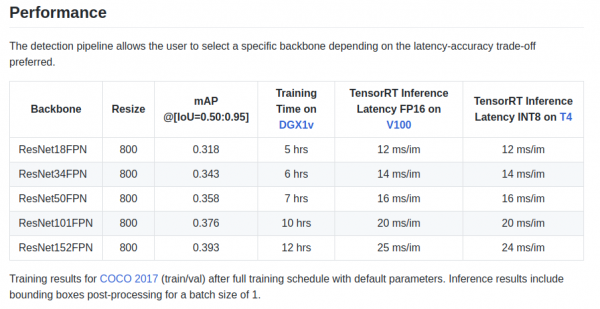
Van még egy gerinc ResNeXt50_32x4dFPN és ResNeXt101_32x8dFPN, amelyek a torchvision-ból származnak.
Remélem kicsit rájöttél az észlelésre, de ehhez mindenképpen el kell olvasnod a hivatalos dokumentációt megértsék az exportálási és naplózási módokat.
5. szakasz. Unet modellek exportálása és következtetése Resnet kódolóval
Amint valószínűleg észrevette, a szegmentálásra szolgáló könyvtárak telepítve voltak a Dockerfile-ban, és különösen a csodálatos lib. . A unitet csomagban példákat találhat a pytorch ellenőrzőpontok következtetésére és exportálására a TensorRT motorba.
A fő probléma az Unet-szerű modellek ONNX-ből TensoRT-be való exportálásakor az, hogy fix Upsample-méretet kell beállítani vagy ConvTranspose2D-t kell használni:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
Ezzel a transzformációval ezt automatikusan megteheti az ONNX-be való exportáláskor, de már a TensorRT 7-es verziójában ez a probléma megoldódott, és még sokat kell várnunk.
Következtetés
Amikor elkezdtem használni a dockert, kétségeim támadtak a feladataim során nyújtott teljesítményével kapcsolatban. Az egyik egységem jelenleg meglehetősen nagy hálózati forgalmat generál több kamera.
Az interneten végzett különféle tesztek viszonylag nagy ráfordítást jeleztek a hálózati interakcióhoz és a VOLUME-on történő rögzítéshez, plusz az ismeretlen és szörnyű GIL-hez, és mivel a keret rögzítése, a meghajtó működtetése és a keret hálózaton keresztüli továbbítása módban atomi művelet. kemény valós idejű, a hálózati késések nagyon kritikusak számomra.
De minden rendben volt =)
PS. Nem marad más hátra, mint hozzáadni kedvenc vonathurkát a szegmentáláshoz és a gyártáshoz!
Kösz
Köszönet a közösségnek , nélküle nem lehet fejlődni! Nagyon köszönöm , aki DL-re biztatott, felbecsülhetetlen értékű tanácsaiért és rendkívüli professzionalizmusáért!
Használjon optimalizált modelleket a gyártásban!
 Aurorai, llc
Aurorai, llc
Forrás: will.com
