

Néha az emberek a Yandexhez fordulnak, hogy olyan filmet találjanak, amelynek a címe kiesett a fejükből. Leírják a cselekményt, emlékezetes jeleneteket, élénk részleteket: például [hogyan hívják azt a filmet, ahol egy férfi piros vagy kék pirulát választ]. Úgy döntöttünk, hogy áttanulmányozzuk az elfeledett filmek leírásait, és megtudjuk, mire emlékeznek leginkább az emberek a filmekből.
Ma nem csak egy linket osztunk meg a mi oldalunkon , de röviden beszélünk a Yandex szemantikus keresésének fejlődéséről is. Megtudhatja, milyen technológiák segítik a keresést a válasz megtalálásában, még akkor is, ha egyszerűen lehetetlen pontosan megfogalmazni a lekérdezést.
Találós csúszkákat is hozzáadtunk valós emberek lekérdezéseinek példáihoz – érezze magát keresőmotornak, és próbálja kitalálni a választ.
Minden keresőmotor szókereséssel indult. A Yandex már a kezdetekkor figyelembe tudta venni az orosz nyelv morfológiáját, de továbbra is ugyanaz volt, mint a szavak keresése az internetes oldalak lekérdezéséből. Minden szóhoz listát vezettünk az összes ismert oldalról. Ha a kérés kifejezést tartalmazott, akkor elég volt áthúzni a szólistákat - itt a válasz. Remekül működött azokban az időkben, amikor kevés volt a webhely, és a rangsorolás kérdése még nem volt annyira sürgető.
A Runet fejlődött, egyre több oldal volt. A metszéspont szóhoz még két szó került. Egyrészt maguk a felhasználók segítettek nekünk. Elkezdtük figyelembe venni, hogy mely webhelyeket és milyen lekérdezésekre választják. A szavaknak nincs pontos egyezése, de az oldal megoldja az ember problémáját? Ez egy hasznos jelzés. Másrészt az oldalak közötti linkek segítettek, amelyek segítettek felmérni az oldalak jelentőségét.
Három tényező nagyon kevés. Főleg, ha nagyon tehetséges keresőoptimalizálók próbálják becsapni őket. De nehéz volt kézzel többet megemészteni. És itt kezdődött a gépi tanulás korszaka. 2009-ben bevezettük a gradiens növelésen alapuló Matrixnetet (később ez a technológia egy fejlettebb nyílt forráskódú könyvtár alapját képezte ).
Azóta egyre több tényező van, mert már nem kellett manuálisan keresgélnünk közöttük a kapcsolatokat. Ezt a gép csinálta meg helyettünk.
Ahhoz, hogy a Keresés minden későbbi változásáról beszéljünk, nem csak egy bejegyzés, hanem egy könyv sem lesz elég, ezért igyekszünk a legleleplezőbbekre koncentrálni.
A rangsorolás már nem csak a lekérdezési szavak és oldalak összehasonlításáról szól. Két példa.
Még 2014-ben vezettük be a jellemző lekérdezésekkel ellátott dokumentumannotálás technológiáját. Tegyük fel, hogy régebben volt egy lekérdezés [tévésorozat Brazíliából a húskirályról], amire már ismert a jó válasz. Ekkor egy másik felhasználó beír egy lekérdezést [brazil tévésorozat, amelyben volt egy húskirály és egy tejkirály], amelyre a gép még nem tudja a választ. De ezeknek a lekérdezéseknek sok közös szava van. Ez azt jelzi, hogy az első kérelemhez talált oldal releváns lehet a második számára.
Egy másik példa. Vegyük a lekérdezéseket [brazil tévésorozat, amelyben volt egy húskirály és egy tejkirály] és [a Fatal Inheritance című tévésorozat]. Csak egy közös szavuk van - „sorozat”, és ez nem elég a lekérdezések explicit összehasonlításához. Ebben az esetben elkezdtük figyelembe venni a keresési előzményeket. Ha ugyanazokra a webhelyekre van kereslet a keresési eredmények között két különböző lekérdezés esetén, akkor feltételezhetjük, hogy a lekérdezések felcserélhetők. Ez azért hasznos, mert most mindkét lekérdezés szövegében fogunk keresni, hogy további hasznos oldalakat találjunk. De ez csak ismételt lekérdezések esetén működik, amikor már van legalább néhány statisztika. Mi a teendő az új kérésekkel?
A statisztikai adatok hiányát tartalomelemzéssel lehet kompenzálni. A homogén adatok (szöveg, hang, képek) elemzésében pedig a neurális hálózatok teljesítenek a legjobban. 2016-ban meséltünk először a Habr közösségnek arról , amely a neurális hálózatok szélesebb körű használatának kiindulópontja lett a Keresésben.
Elkezdtük a neurális hálózat betanítását a lekérdezési szövegek és az oldalcímek szemantikai közelségének összehasonlítására. Két szöveget vektorként ábrázolunk egy többdimenziós térben, így a közöttük lévő szög koszinusza jól megjósolja annak valószínűségét, hogy valaki egy oldalt választ, és ezáltal a szemantikai közelséget. Ezáltal még azokban a szövegekben is felmérhetjük a jelentésközeliséget, amelyekben nincs szavak metszéspontja.
Példa rétegarchitektúrára a kíváncsiak számára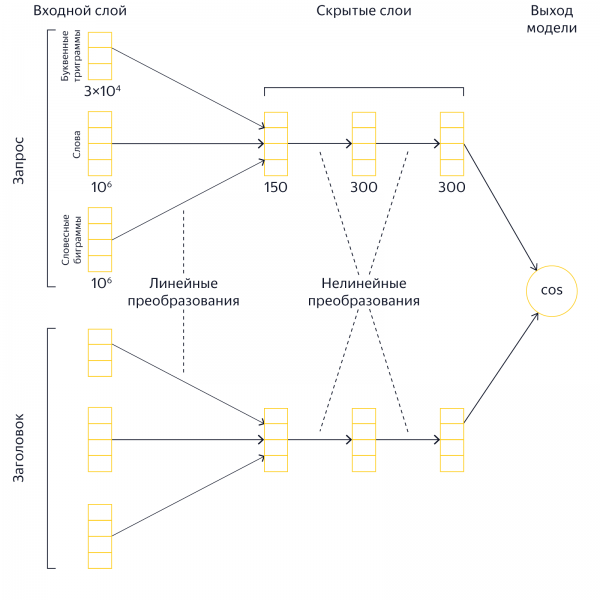
Ugyanígy elkezdtük összehasonlítani a lekérdezési szövegeket, hogy azonosítsuk a köztük lévő kapcsolatokat. Valóságos példa egy keresőmotor motorháztetője alól: az [Amerikai sorozat a metamfetamin főzésének módjáról] lekérdezésnél a neurális hálózat találja a [breaking bad] és [breaking bad] kifejezéseket hasonló jelentésűnek.
A lekérdezések és a fejlécek már jók, de nem adtuk fel a reményt, hogy neurális hálózatokat alkalmazzunk az oldalak teljes szövegére. Ezen túlmenően, amikor felhasználói kérést kapunk, fokozatosan elkezdjük kiválasztani a legjobb oldalakat a több millió indexoldal közül, de a Palekh-ben csak a rangsor legfrissebb szakaszában (L3) használtunk neurális hálózati modelleket - körülbelül a 150 legjobb dokumentumot. Ez a jó válaszok elvesztéséhez vezethet.
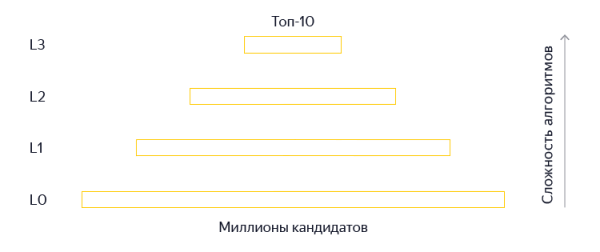
Az ok kiszámítható - korlátozott erőforrások és magas követelmények a válaszadási sebességgel szemben. A számítástechnika kemény korlátai egy egyszerű tényből fakadnak: a felhasználót nem lehet várakozni. De aztán kitaláltunk valamit.
2017-ben bemutattuk a Korolev keresőfrissítést, amely nemcsak a neurális hálózatok kiterjesztett használatát foglalta magában, hanem az architektúrán is komoly munkát végzett az erőforrások megtakarítása érdekében. A Habré egy másik posztjában már részletesebben, rétegdiagramokkal és egyéb részletekkel írtunk, de most emlékeztessünk a lényegre.
Ahelyett, hogy figyelembe venné a dokumentum címét és kiszámítaná a szemantikai vektorát a lekérdezés végrehajtása során, előre kiszámíthatja ezt a vektort, és tárolhatja a keresési adatbázisban. Más szóval, a munka nagy részét előre el tudjuk végezni. Természetesen ugyanakkor több hely kellett a vektorok tárolására, de így processzoridőt takarítottunk meg. De ez még nem minden.
Még egy diagram a kíváncsiskodóknak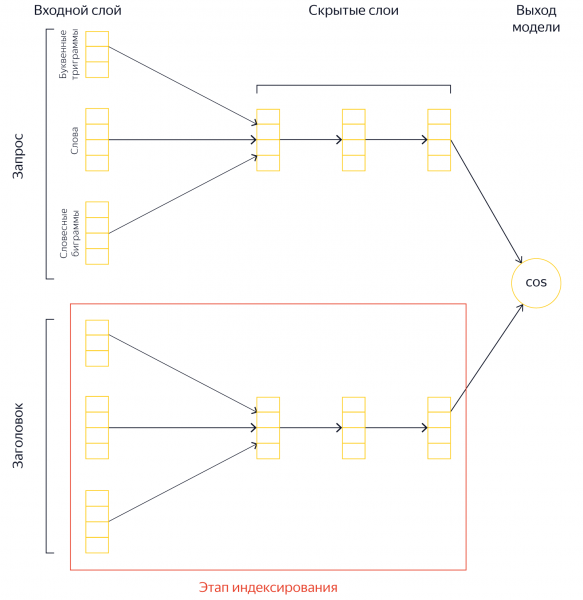
Készítettünk egy további indexet. Hipotézisen alapul: ha több szóból álló lekérdezéshez minden szóhoz vagy kifejezéshez kellően nagy listát vesz a legrelevánsabb dokumentumokról, akkor közöttük lesznek olyan dokumentumok, amelyek minden szóra vonatkoznak egyszerre. A gyakorlatban ez ezt jelenti. Minden szóhoz és népszerű szópárhoz egy további index jön létre, amely tartalmazza az oldalak listáját és azok előzetes relevanciáját a lekérdezés szempontjából. Vagyis a munka egy részét átvisszük az L0 szakaszból az indexelési szakaszba, és újra elmentjük.
Ennek eredményeként az architektúra megváltoztatása és a terhelések újraelosztása lehetővé tette számunkra, hogy neurális hálózatokat használjunk nem csak az L3 szakaszban, hanem az L2 és L1 szakaszban is. Sőt, a vektor előzetes és kevésbé szigorú teljesítménykövetelményekkel történő generálása lehetővé tette, hogy ne csak az oldal címét, hanem a szövegét is használjuk.
Tovább tovább. Idővel a neurális hálózatokat a rangsorolás nagyon korai szakaszában kezdtük el használni. Megtanítjuk a neurális hálózatokat az implicit minták azonosítására a szavak sorrendjében és relatív helyzetükben. És még azonosítani kell a különböző nyelvű szövegek szemantikai hasonlóságát. Mindegyik terület külön cikket érdemel, és a közeljövőben igyekszünk visszatérni velük.
Ma ismét emlékeztettünk arra, hogy a keresőmotorok hogyan tanulnak meg választ találni, ha a lekérdezés homályos és információhiányos. A filmek leírása alapján történő keresése nem csak speciális esete az ilyen jellegű lekérdezéseknek, hanem kiváló témája is . Ebből megtudhatja: mire emlékeznek a legerősebben az emberek a moziban, milyen műfajokhoz és országok mozikhoz kötődnek, milyen cselekménymozgások keltenek különleges benyomást.
Forrás: will.com
