

Բարև, Հաբր: Dodo Pizza Engineering-ում մենք սիրում ենք տվյալներ (ո՞վ չի սիրում այս օրերին): Այժմ կլինի պատմություն այն մասին, թե ինչպես կարելի է կուտակել բոլոր տվյալները Dodo Pizza-ի աշխարհում և ընկերության ցանկացած աշխատակցի հարմար մուտք տալ տվյալների այս զանգվածին: Աստղանիշի տակ առաջադրանքը՝ փրկել Data Engineering թիմի նյարդերը:
Ինչպես իսկական Պլյուշկինները, մենք հավաքում ենք բոլոր տեսակի տեղեկություններ մեր պիցցերիաների աշխատանքի մասին.
- մենք հիշում ենք բոլոր օգտագործողների պատվերները.
- մենք գիտենք, թե որքան ժամանակ է պահանջվել Սիկտիվկարում առաջին պիցցան պատրաստելու համար.
- մենք տեսնում ենք, թե որքան ժամանակ է պահանջվում, որպեսզի պիցցան սառչի Վորոնեժի ջեռուցման դարակում հենց հիմա.
- մենք պահպանում ենք ապրանքների դուրսգրման տվյալները.
- և շատ շատ ուրիշներ:
Ներկայումս Dodo Pizza-ում տվյալների հետ աշխատելու համար պատասխանատու են մի քանի թիմեր, որոնցից մեկը Data Engineering թիմն է: Այժմ նրանց (այսինքն՝ մեզ) խնդիր է դրված ընկերության ցանկացած աշխատակցի տվյալների այս զանգվածին հարմար հասանելիություն տրամադրել։
Երբ մենք սկսեցինք մտածել, թե ինչպես դա անել և սկսեցինք քննարկել խնդիրը, մենք գտանք տվյալների կառավարման շատ հետաքրքիր մոտեցում. (հետևեք հղմանը, դուք կգտնեք հսկայական, հիանալի հոդված): Նրա գաղափարները շատ լավ համապատասխանում են մեր պատկերացումներին, թե ինչպես ենք մենք ցանկանում կառուցել մեր համակարգը: Հոդվածի մնացած մասը կկենտրոնանա մոտեցման մեր վերաիմաստավորման վրա և այն մասին, թե ինչպես ենք այն իրականացվում Dodo Pizza Engineering-ում:
Ի՞նչ ենք հասկանում «տվյալներ» ասելով
Նախ, եկեք սահմանենք, թե ինչ նկատի ունենք Dodo Pizza Engineering-ում տվյալներ ասելով.
- Ծառայությունների կողմից ուղարկված իրադարձություններ (մենք ունենք ընդհանուր ավտոբուս, որը կառուցվել է RabbitMQ-ի միջոցով);
- Գրառումներ տվյալների բազայի ներսում (մեզ համար սա MySQL և CosmosDB է);
- Clickstream բջջային հավելվածից և կայքից:
Որպեսզի Dodo Pizza-ն կարողանա օգտագործել և հենվել այս տվյալների վրա, կարևոր է, որ պահպանվեն հետևյալ պայմանները.
- Նրանք պետք է լինեն անբաժանելի: Մենք պետք է ապահովենք, որ մենք չփոխենք տվյալները դրանց մշակման, պահպանման և ցուցադրման ընթացքում: Եթե ձեռնարկությունները չեն կարող վստահել մեր տվյալներին, դա ոչ մի օգուտ չի ունենա:
- Դրանք պետք է լինեն ժամանակի կնիքով և չվերագրվեն: Սա նշանակում է, որ ցանկացած պահի մենք ցանկանում ենք, որ կարողանանք հետ գլորել և նայել տվյալ ժամանակահատվածի տվյալները: Օրինակ՝ պարզեք, թե քանի պիցցա է վաճառվել 8 թվականի հուլիսի 2018-ին։
- Նրանք պետք է հուսալի լինեն: Տվյալների հավաքագրման և պահպանման գործընթացում մենք չպետք է կորցնենք ոչ միայն ամբողջականությունը, այլև հուսալիությունը: Մենք չենք կարող կորցնել տվյալներ, ժամանակի հատվածներ, քանի որ դրանց հետ մեկտեղ կորցնում ենք մեր հաճախորդների վստահությունը (ինչպես արտաքին, այնպես էլ ներքին):
- Նրանք պետք է ունենան կայուն սխեմա. մենք հարցումներ ենք գրում այս տվյալների համար: Մենք իսկապես չէինք ցանկանա, որ հավելվածի կոդը փոխվի և վերամշակվի այնքան, որ մեր հարցումները դադարեն աշխատել: Հարցումները գրող անձը երբեք չի իմանա, որ դուք վերամշակել եք, քանի դեռ ամեն ինչ չի կոտրվել: Ես չէի ցանկանա լսել այս մասին հաճախորդներից:
Այս բոլոր պահանջները հաշվի առնելով՝ մենք եկանք այն եզրակացության, որ Dodo-ում տվյալները արտադրանք են։ Նույնը, ինչ ծառայության հանրային API-ն: Համապատասխանաբար, տվյալները պետք է պատկանեն նույն թիմին, որին պատկանում է ծառայությունը: Բացի այդ, տվյալների սխեմայի փոփոխությունները միշտ պետք է լինեն հետհամատեղելի:
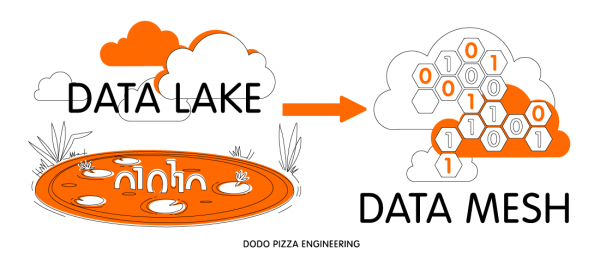
Ավանդական մոտեցում – Data Lake
Մեծ տվյալների հուսալի պահպանման և մշակման խնդիրները լուծելու համար կա ավանդական մոտեցում, որը որդեգրված է շատ ընկերությունների կողմից, որոնք աշխատում են տեղեկատվության նման լողավազանի հետ՝ Data Lake: Այս մոտեցմամբ տվյալների ինժեներները տեղեկատվություն են հավաքում համակարգի բոլոր բաղադրիչներից և դնում այն մեկ մեծ պահեստում (օրինակ՝ Hadoop, Azure Kusto, Apache Cassandra կամ նույնիսկ MySQL կրկնօրինակը, եթե տվյալները տեղավորվում են դրա մեջ):
Հետո նույն ինժեներները հարցումներ են գրում նման պահեստավորման համար: Այս մոտեցման իրականացումը Dodo Pizza Engineering-ում նշանակում է, որ Data Engineering թիմը կունենա տվյալների սխեման վերլուծական պահեստում:
Այս սցենարում թիմը դառնում է շատ տխուր կատուներ, և ահա թե ինչու.
- Նա պետք է վերահսկի փոփոխությունները ԲՈԼՈՐ ծառայություններ ընկերության ներսում: Եվ դրանք շատ են և շատ փոփոխություններ (միջինում մենք միավորում ենք շաբաթական ~ 100 pull հարցումներ, մինչդեռ շատ ծառայություններ ընդհանրապես pull հարցումներ չեն անում):
- Երբ տվյալների սխեման փոխվում է, արտադրանքի սեփականատերը և տվյալների սխեման փոխող թիմը պետք է սպասեն, որ Data Engineering-ը գրի փոփոխություններն աջակցելու համար անհրաժեշտ կոդը: Միևնույն ժամանակ, մենք արդեն վաղուց խաղարկային թիմեր ենք, և շատ հազվադեպ է այն իրավիճակը, երբ մի թիմը սպասում է մյուսին։ Եվ մենք չենք ուզում, որ սա դառնա զարգացման գործընթացի «նորմալ» մաս:
- Այն պետք է ընկղմվի մեջ ԲՈԼՈՐ ընկերության բիզնես. Պիցցայի ցանցը կարծես պարզ բիզնես է, բայց միայն այդպես է թվում: Շատ դժվար է մեկ թիմում հավաքել բավարար իրավասություններ՝ ամբողջ ընկերության համար համարժեք տվյալների մոդել ստեղծելու համար:
- Դա ձախողման մեկ կետ է: Ամեն անգամ, երբ ծառայության կողմից վերադարձված տվյալները փոխելու կամ հարցում գրելու անհրաժեշտություն է առաջանում, այս բոլոր առաջադրանքները ընկնում են Data Engineering թիմի վրա: Արդյունքում թիմը ծանրաբեռնված հետք ունի։
Ստացվում է, որ թիմը գտնվում է հսկայական թվով կարիքների խաչմերուկում և դժվար թե կարողանա դրանք բավարարել։ Միաժամանակ նա կլինի մշտական ժամանակային ճնշման ու սթրեսի մեջ։ Մենք դա իսկապես չենք ուզում: Այսպիսով, մենք պետք է մտածենք, թե ինչպես լուծել այս խնդիրները և դեռ կարողանալ վերլուծել տվյալները:
Հոսում է Data Lake-ից դեպի Data Mesh
Բարեբախտաբար, մենք միակը չէինք, որ ինքներս մեզ տվեցինք այս հարցը: Փաստորեն, այս խնդիրն արդեն լուծված է արդյունաբերության մեջ (ալելուիա): Պարզապես մեկ այլ ոլորտում՝ հավելվածի տեղակայում: Այո, ես խոսում եմ DevOps մոտեցման մասին, որտեղ թիմը որոշում է, թե ինչպես տեղակայել իր ստեղծած արտադրանքը:
Data Lake-ի խնդիրների լուծման համանման մոտեցում է առաջարկել ThoughtWorks-ի խորհրդատու Ժամակ Դեհղանին: Netflix-ը և Spotify-ը նման մարտահրավերներին դիմակայելուց հետո նա փայլուն հոդված է գրել (դրա հղումը հոդվածի սկզբում էր): Հիմնական գաղափարները, որոնք մենք հանեցինք դրանից.
- Տվյալների մեծ լիճը բաժանեք տվյալների տիրույթների, որոնք շատ նման են տիրույթի վրա հիմնված դիզայնի տիրույթներին: Յուրաքանչյուր տիրույթ փոքր սահմանափակ համատեքստ է:
- Հատկանշական թիմերը, որոնք պատասխանատու են DDD տիրույթների համար, պատասխանատու են նաև տվյալների համապատասխան տիրույթների համար: Նրանք պահում են սխեման, փոփոխություններ են կատարում դրանում և բեռնում տվյալները դրա մեջ: Միևնույն ժամանակ, նրանք ամեն ինչ գիտեն՝ ինչպես փոխել տվյալների բեռնումը և ոչինչ չխախտել, երբ հավելվածը փոխվում է։ Գիտելիքը երբեք չի անհետանում: Տվյալները բացելու համար նրանք ոչ մի տեղ պետք չէ գնալ: Թիմն ինքն է իրականացնում զարգացման ամբողջական ցիկլը՝ գործառնական տվյալների փոփոխությունից մինչև երրորդ կողմերին վերլուծական տվյալներ տրամադրելը: Մեկ թիմին է պատկանում տիրույթի հետ կապված ամեն ինչ (ինչպես բիզնես տիրույթը, այնպես էլ տվյալների տիրույթը):
- Տվյալների ինժեները դեր է Feature Team-ում: Պարտադիր չէ, որ դա լինի միայնակ, բայց պետք է լինի թիմ, որն ունի այս իրավասությունը:
Միևնույն ժամանակ, Data Engineering թիմը…
Եթե պատկերացնենք, որ այս ամենը հնարավոր է իրականացնել մատի սեղմումով, ապա մնում է երկու հարցի պատասխան.
Ի՞նչ է անելու Տվյալների ինժեներական թիմը հիմա: Dodo Pizza Engineering-ն արդեն ունի հարթակ/SRE թիմ: Դրա նպատակն է ծրագրավորողներին տալ գործիքներ՝ ծառայությունները հեշտությամբ տեղակայելու համար: Տվյալների ինժեներական թիմը կկատարի նույն դերը, բայց տվյալների համար:
Գործառնական տվյալները պատկերացումների վերածելը բարդ գործընթաց է: Անալիտիկ տվյալները ամբողջ ընկերությանը հասանելի դարձնելն էլ ավելի դժվար է: Հենց այս խնդիրների լուծման վրա է աշխատելու Data Engineering թիմը:
Մենք պատրաստվում ենք Feature Team-ին տրամադրել գործիքների և պրակտիկաների մի շարք, որոնք նրանք կարող են օգտագործել իրենց ծառայության տվյալները ընկերության մնացած հատվածում հրապարակելու համար: Մենք պատասխանատու կլինենք նաև տվյալների խողովակաշարի ընդհանուր ենթակառուցվածքային մասերի համար (հերթեր, հուսալի պահեստավորում, տվյալների վրա փոխակերպումներ կատարելու կլաստերներ):
Ինչպե՞ս կհայտնվեն Տվյալների ինժեների հմտությունները Feature Team-ում: Խաղարկային թիմի հետ ամեն ինչ ավելի բարդ է: Իհարկե, մենք կարող ենք փորձել վարձել տվյալների մեկ ինժեներ մեր թիմերից յուրաքանչյուրի համար: Բայց դա շատ դժվար է։ Տվյալների մշակման լավ փորձ ունեցող մեկին գտնելը և նրանց համոզել աշխատել արտադրանքի թիմում, դժվար է:
Dodo-ի մեծ պլյուսն այն է, որ մենք սիրում ենք ներքին մարզումները: Այսպիսով, այժմ մեր պլանը հետևյալն է. Data Engineering թիմը սկսում է հրապարակել որոշ ծառայություններից տվյալներ, լաց է լինում, խայթում է իրեն, բայց շարունակում է կակտուս ուտել: Երբ մենք զգում ենք, որ ունենք հրապարակման գործընթաց, մենք սկսում ենք այն կիսվել Feature Team-ի հետ:
Դա անելու մի քանի եղանակ ունենք.
- , որտեղ մենք ձեզ կպատմենք, թե ինչպիսին է մեր ստեղծած գործընթացը, ինչ գործիքներ կան և ինչպես դրանք օգտագործել առավել արդյունավետ։
- DevForum-ում ելույթ ունենալը կօգնի մեզ հետադարձ կապ հավաքել արտադրանքի մշակողների կողմից: Դրանից հետո մենք կկարողանանք միանալ արտադրանքի թիմերին և օգնել նրանց լուծել տվյալների հրապարակման հետ կապված խնդիրները, կազմակերպել թրեյնինգներ թիմերի համար:
Տվյալների սպառում
Հիմա ես շատ եմ խոսել տվյալների հրապարակման մասին: Բայց կա նաև սպառում. Ինչ վերաբերում է այս հարցին:
Մենք ունենք հիանալի BI թիմ, որը շատ բարդ հաշվետվություններ է գրում կառավարող ընկերության համար: Dodo IS-ում կան բազմաթիվ զեկույցներ մեր գործընկերների համար, որոնք կօգնեն նրանց կառավարել իրենց պիցցերիաները: Մեր նոր մոդելում մենք նրանց համարում ենք տվյալների սպառողներ, ովքեր ունեն իրենց սեփական տվյալների տիրույթները: Եվ հենց սպառողներն են պատասխանատու իրենց սեփական տիրույթների համար։ Երբեմն սպառողական տիրույթը կարող է նկարագրվել մեկ հարցմամբ դեպի վերլուծական պահեստ, և դա լավ է: Բայց մենք հասկանում ենք, որ դա միշտ չէ, որ կաշխատի։ Ահա թե ինչու մենք ցանկանում ենք, որ պլատֆորմը, որը մենք ստեղծում ենք արտադրանքի թիմերի համար, օգտագործելի լինի նաև տվյալների սպառողների կողմից (Dodo IS-ի շրջանակներում հաշվետվությունների դեպքում դրանք կլինեն նույն թիմերը):
Ահա թե ինչպես ենք մենք տեսնում տվյալների հետ աշխատելը Dodo Pizza Engineering-ում: Ուրախ կլինենք կարդալ ձեր կարծիքը այս հարցի վերաբերյալ մեկնաբանություններում:
Source: www.habr.com
