


Միայն առաջին անգամն է ցավում!
Բարև բոլորին։ Սիրելի՛ ընկերներ, այս հոդվածում ես ուզում եմ կիսվել իմ փորձով՝ օգտագործելով TensorRT, RetinaNet՝ հիմնված պահոցի վրա։ (սա պաշտոնական պահոցի ճյուղավորումն է , որը թույլ կտա ձեզ սկսել օպտիմիզացված մոդելների օգտագործումը արտադրության մեջ հնարավորինս կարճ ժամանակում): Համայնքային ալիքներում հաղորդագրությունների մեջ թերթում Ես հանդիպում եմ TensorRT-ի օգտագործման վերաբերյալ հարցերի, և հիմնականում հարցերը կրկնվում են, ուստի որոշեցի գրել որքան հնարավոր է ամբողջական TensorRT, RetinaNet, Unet և docker-ի վրա հիմնված արագ եզրակացության օգտագործման ուղեցույց։
Առաջադրանքի նկարագրությունը
Ես առաջարկում եմ առաջադրանքը ձևակերպել հետևյալ կերպ. մենք պետք է պիտակավորենք տվյալների բազմությունը, մարզենք RetinaNet/Unet ցանցը Pytorch 1.3+-ի վրա, ստացված կշիռները փոխարկենք ONNX-ի, այնուհետև փոխարկենք դրանք TensorRT շարժիչի և ամբողջը աշխատացնենք Docker-ում, ցանկալի է՝ Ubuntu 18 և խիստ ցանկալի է ARM (Jetson)* ճարտարապետության վրա, այդպիսով նվազագույնի հասցնելով միջավայրի ձեռքով տեղակայումը: Վերջնական արդյունքը կլինի կոնտեյներ, որը պատրաստ կլինի ոչ միայն RetinaNet/Unet արտահանման և մարզման, այլև դասակարգման և սեգմենտացման համակարգերի լիարժեք մշակման և մարզման համար՝ բոլոր անհրաժեշտ սարքավորումներով:
Քայլ 1. Միջավայրի պատրաստում
Այստեղ կարևոր է նշել, որ վերջերս ես ամբողջությամբ հրաժարվել եմ ցանկացած գրադարաններ օգտագործելուց և տեղակայելուց ինչպես սեղանադիր համակարգչի, այնպես էլ devbox-ի վրա։ Միակ բանը, որ պետք է ստեղծել և տեղադրել, Python վիրտուալ միջավայրն է և deb-ից Cuda 10.2-ը (կարող եք սահմանափակվել մեկ nvidia դրայվերով)։
Ենթադրենք, որ դուք նոր եք տեղադրել Ubuntu 18. Եկեք տեղադրենք cuda 10.2 (deb): Ես չեմ մանրամասնի տեղադրման գործընթացը, պաշտոնական փաստաթղթերը բավականին բավարար են:
Հիմա եկեք տեղադրենք docker-ը, docker-ի տեղադրման ուղեցույցը կարելի է հեշտությամբ գտնել, ահա մի օրինակ , 19+ տարբերակը արդեն հասանելի է — եկեք տեղադրենք այն։ Եվ մի մոռացեք Docker-ը առանց Sudo-ի օգտագործելու հնարավորություն տալ, դա ավելի հարմար կլինի։ Ամեն ինչ կարգավորելուց հետո արեք այսպես.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
Եվ դուք նույնիսկ կարիք չունեք նայելու պաշտոնական պահոցը .
Հիմա մենք git կլոնավորում ենք .
Մնացել է մի փոքր ժամանակ, որպեսզի սկսենք օգտագործել docker-ը nvidia պատկերով, մենք պետք է գրանցվենք NGC Cloud-ում և մուտք գործենք։ Մտեք այստեղ։ , գրանցվեք և NGC Cloud-ում մտնելուց հետո սեղմեք SETUP էկրանի վերին ձախ անկյունում կամ հետևեք այս հղմանը։ Սեղմեք «ստեղծել բանալի»։ Խորհուրդ եմ տալիս պահպանել այն, հակառակ դեպքում հաջորդ անգամ այցելելիս ստիպված կլինեք այն նորից ստեղծել և, համապատասխանաբար, այն նոր մեքենայի վրա տեղադրելիս կրկնել այս գործողությունը։
Եկեք անենք.
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
Մենք պարզապես պատճենում ենք օգտատիրոջ անունը։ Դե, պատկերացրեք տեղակայված միջավայրը։
Քայլ 2. Docker կոնտեյների կառուցում
Մեր աշխատանքի երկրորդ փուլում մենք կկառուցենք docker-ը և կծանոթանանք դրա ներքին կառուցվածքին։
Եկեք գնանք retina-examples նախագծին վերաբերող root թղթապանակ և գործարկենք
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Մենք docker-ը կառուցում ենք՝ ընթացիկ օգտատիրոջը փոխանցելով դրան։ Սա շատ օգտակար է, եթե դուք պատրաստվում եք ինչ-որ բան գրել միացված VOLUME-ում ընթացիկ օգտատիրոջ իրավունքներով, հակառակ դեպքում դա կլինի root և pain։
Մինչ docker-ը կառուցվում է, եկեք ուսումնասիրենք Dockerfile-ը։
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Ինչպես կարող եք տեսնել տեքստից, մենք վերցնում ենք մեր բոլոր սիրելի գրադարանները, կազմում ենք retinanet-ը, ավելացնում ենք մի քանի հիմնական գործիքներ՝ դրանց հետ աշխատանքը հեշտացնելու համար։ Ubuntu և կարգավորել OpenSSH սերվերը։ Առաջին տողը ժառանգում է NVIDIA պատկերը, որի համար մենք ստեղծել ենք NGC Cloud մուտքանունը և որը պարունակում է Pytorch1.3, TensorRT6.xxx և մի շարք այլ գրադարաններ, որոնք թույլ են տալիս մեզ կազմել մեր դետեկտորի CPP կոդը։
Քայլ 3. Docker կոնտեյների գործարկում և վրիպազերծում
Եկեք անցնենք կոնտեյների և մշակման միջավայրի հիմնական օգտագործման դեպքին, նախ կգործարկենք nvidia docker-ը։ Եկեք գործարկենք՝
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestԿոնտեյները այժմ հասանելի է ssh-ի միջոցով @localhost: Հաջող մեկնարկից հետո բացեք նախագիծը PyCharm-ում: Հաջորդը, բացեք
Settings->Project Interpreter->Add->Ssh Interpreter Քայլ 1
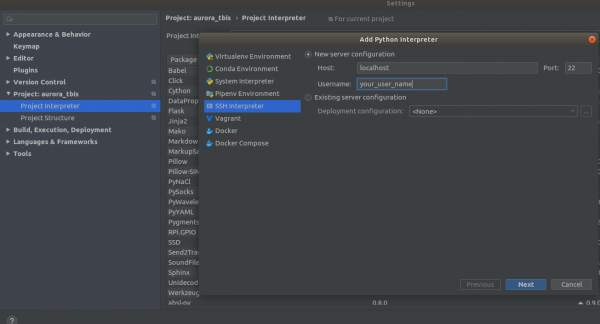
Քայլ 2
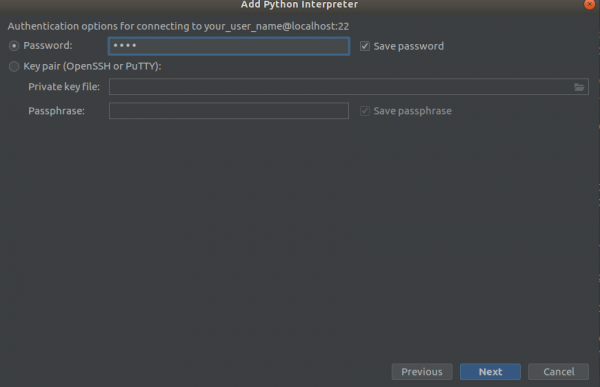
Քայլ 3
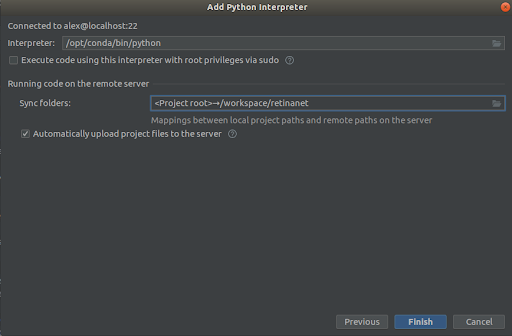
Մենք ամեն ինչ ընտրում ենք, ինչպես էկրանի նկարներում,
Interpreter -> /opt/conda/bin/python- այն կլինի Python3.6-ի վրա և
Sync folder -> /workspace/retinanetՍեղմեք «Ավարտել» կոճակը, սպասեք ինդեքսավորմանը, և վերջ, միջավայրը պատրաստ է օգտագործման համար։
ԿԱՐԵՎՈՐ !!! Ինդեքսավորումից անմիջապես հետո Docker-ից արդյունահանեք Retinanet-ի համար կազմված ֆայլերը: Նախագծի արմատային մասում գտնվող համատեքստային ցանկում ընտրեք հետևյալ կետը.
Deployment->DownloadԿհայտնվեն մեկ ֆայլ և երկու թղթապանակ՝ build, retinanet.egg-info և _С.so
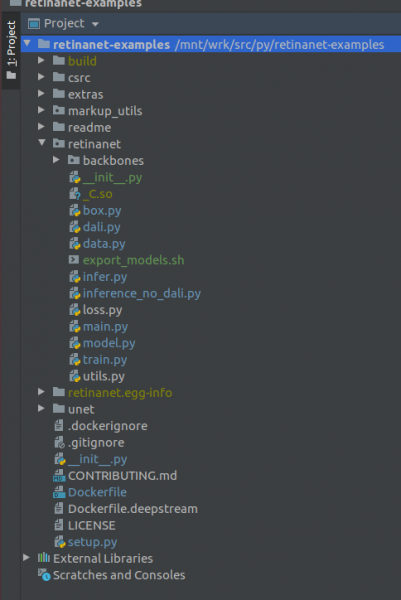
Եթե ձեր նախագիծը այսպիսի տեսք ունի, ապա միջավայրը տեսնում է բոլոր անհրաժեշտ ֆայլերը, և մենք պատրաստ ենք մարզել RetinaNet-ը։
Քայլ 4. Նշեք տվյալները և մարզեք դետեկտորը
Նշման համար ես հիմնականում օգտագործում եմ — հաճելի և հարմար գործիք, վերջերս մի շարք սխալներ են շտկվել, և այն սկսել է շատ ավելի լավ աշխատել։
Ենթադրենք, որ դուք նշել եք տվյալների բազմությունը և ներբեռնել այն, բայց չեք կարողանա այն անմիջապես տեղադրել մեր RetinaNet-ում, քանի որ այն ունի իր սեփական ձևաչափը, և դրա համար մենք պետք է այն փոխարկենք COCO-ի: Փոխարկման գործիքը գտնվում է հետևյալ հասցեով՝
markup_utils/supervisly_to_coco.pyԽնդրում ենք նկատի ունենալ, որ սկրիպտում «Կատեգորիա» բառը օրինակ է, և դուք պետք է մուտքագրեք ձեր սեփականը (ֆոնային կատեգորիան անհրաժեշտ չէ ավելացնել):
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Ինչ-ինչ պատճառներով սկզբնական պահոցի հեղինակները որոշեցին, որ դուք COCO/VOC-ից բացի ուրիշ ոչինչ չեք մարզելու հայտնաբերման համար, ուստի ես ստիպված էի մի փոքր խմբագրել սկզբնաղբյուր ֆայլը։
retinanet/dataset.pyԱվելացրեք այստեղ ձեր նախընտրած լրացումները և COCO-ից կտրել կոշտ կոդավորված կատեգորիաները: Հնարավոր է նաև կտրել հայտնաբերման մեծ տարածքներ, եթե մեծ պատկերներում փնտրում եք փոքր օբյեկտներ, ունեք փոքր տվյալների բազմություն =), և ոչինչ չի աշխատում, բայց դրա մասին կխոսենք մեկ այլ անգամ:
Ընդհանուր առմամբ, գնացքի ցիկլը նույնպես թույլ է, սկզբում այն չէր պահպանում անցակետերը, օգտագործում էր որոշ սարսափելի ժամանակացույց և այլն: Բայց հիմա դուք միայն պետք է ընտրեք մայրուղին և կատարեք
/opt/conda/bin/python retinanet/main.pyպարամետրերով:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
Կոնսոլում դուք կտեսնեք.
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148Պարամետրերի ամբողջական հավաքածուն ուսումնասիրելու համար տե՛ս
retinanet/main.pyԸնդհանուր առմամբ, դրանք հայտնաբերման ստանդարտ են և ունեն նկարագրություն: Գործարկեք ուսուցումը և սպասեք արդյունքներին: Եզրակացության օրինակ կարելի է գտնել հետևյալում.
retinanet/infer_example.pyկամ գործարկեք հրամանը՝
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
Պահոցն արդեն ունի ներկառուցված Focal Loss և մի քանի մայրուղիներ, և հեշտ է նաև ավելացնել ձեր սեփականը։
retinanet/backbones/*.pyԱղյուսակում հեղինակները ներկայացնում են որոշ բնութագրեր.
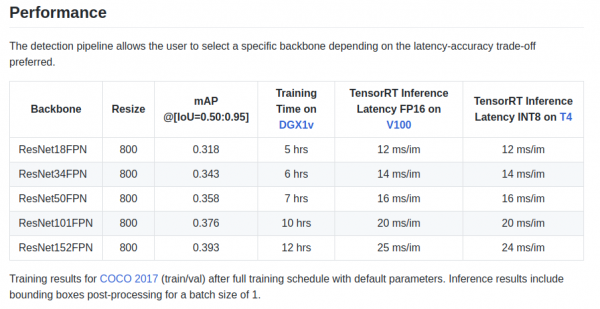
Կա նաև Torchvision-ից վերցված ResNeXt50_32x4dFPN մայրուղի և ResNeXt101_32x8dFPN։
Հուսով եմ՝ մենք մի փոքր լուծեցինք հայտնաբերման խնդիրը, բայց անպայման արժե կարդալ պաշտոնական փաստաթղթերը։ հասկանալ արտահանման և գրանցման ռեժիմները.
Քայլ 5. Unet մոդելների արտահանում և եզրակացություն Resnet կոդավորիչով
Ինչպես գուցե նկատել եք, Dockerfile-ը տեղադրել է սեգմենտացիայի համար նախատեսված գրադարաններ, մասնավորապես՝ հրաշալի գրադարանը։ Unet փաթեթում կարող եք գտնել pytorch ստուգիչ կետերի եզրակացության և TensorRT շարժիչ արտահանման օրինակներ։
Unet-անման մոդելները ONNX-ից TensoRT արտահանելիս հիմնական խնդիրը Upsample-ի ֆիքսված չափ սահմանելու կամ ConvTranspose2D օգտագործելու անհրաժեշտությունն է։
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
Այս փոխակերպման միջոցով դուք կարող եք դա անել ավտոմատ կերպով ONNX արտահանելիս, բայց TensorRT-ի 7-րդ տարբերակում այս խնդիրը լուծվեց, և մեզ մնացել է միայն մի փոքր ժամանակ սպասելու։
Ամփոփում
Երբ սկսեցի օգտագործել docker-ը, կասկածներ ունեի դրա արդյունավետության վերաբերյալ իմ առաջադրանքների համար։ Իմ սարքերից մեկը ներկայումս բավականին շատ ցանցային երթևեկություն ունի, որը ստեղծվում է մի քանի տեսախցիկների կողմից։
Ինտերնետում տարբեր փորձարկումներ ցույց են տվել ցանցային փոխազդեցության և VOLUME-ով ձայնագրման համեմատաբար մեծ ծախսեր, գումարած անհայտ և վախեցնող GIL-ը, և քանի որ կադր նկարահանելը, դրայվերի գործողությունը և կադրի փոխանցումը ցանցով ռեժիմում ատոմային գործողություն են։ դժվար իրական ժամանակ, ցանցի ուշացումները շատ կարևոր են ինձ համար։
Բայց ամեն ինչ լավ ստացվեց =)
Հ.Գ. Մնում է միայն ավելացնել ձեր սիրելի գնացքի օղակը՝ սեգմենտացիայի և արտադրության համար։
Շնորհակալություններ
Շնորհակալություն համայնքին , առանց դրա անհնար է զարգանալ։ Շատ շնորհակալ եմ։ , ով ինձ ոգեշնչեց զբաղվել դիպլոմային ուսմամբ, իր անգնահատելի խորհուրդների և արտակարգ պրոֆեսիոնալիզմի համար։
Օգտագործեք օպտիմիզացված մոդելներ արտադրության մեջ։
 Ավրորա, ՍՊԸ
Ավրորա, ՍՊԸ
Source: www.habr.com
