

古き良きかくれんぼのゲームは、人工知能 (AI) ボットがどのように意思決定を行い、相互に、また周囲のさまざまなオブジェクトと対話するかを実証するための優れたテストとなる可能性があります。
彼には 、有名になった非営利の人工知能研究組織である OpenAI の研究者によって発表されました。 コンピュータ ゲーム Dota 2 では、人工知能によって制御されるエージェントが、仮想環境内でお互いを探索したり隠れたりする際に、より高度に訓練される方法について科学者らが説明しています。 研究の結果、XNUMX 台のボットからなるチームは、味方のいない単一のエージェントよりも効果的かつ迅速に学習することが実証されました。

科学者たちは長い間名声を博してきた方法を使用してきました この人工知能では、人工知能は未知の環境に置かれますが、人工知能と対話する特定の方法があり、その行動の結果に対して報酬や罰金が課せられるシステムもあります。 AI は人間の想像の何百万倍もの速さで仮想環境内でさまざまなアクションを実行できるため、この方法は非常に効果的です。 これにより、特定の問題を解決するための最も効果的な戦略を試行錯誤することができます。 ただし、このアプローチにはいくつかの制限もあります。たとえば、環境を作成して多数のトレーニング サイクルを実行するには膨大なコンピューティング リソースが必要であり、プロセス自体にも AI アクションの結果と目標を比較するための正確なシステムが必要です。 さらに、この方法でエージェントが獲得するスキルは、記述されたタスクに限定されており、AI がそれに対処する方法を学習するとすぐに、それ以上の改善は行われなくなります。
AI にかくれんぼをさせるよう訓練するために、科学者たちは「無向探索」と呼ばれるアプローチを使用しました。このアプローチでは、エージェントは完全に自由にゲーム世界の理解を深め、勝利戦略を立てることができます。 これは、DeepMind の研究者が複数の人工知能システムを使用するときに使用したマルチエージェント学習アプローチに似ています。 。 この場合と同様、AI エージェントは事前にゲームのルールについて訓練されていませんでしたが、時間が経つにつれて基本的な戦略を学習し、自明ではない解決策で研究者を驚かせることさえできました。
かくれんぼのゲームでは、隠れるのが仕事である数人のエージェントが、捜索エージェントのチームが動けなくなっている間、わずかに有利なスタートを切った後、相手の視線を避ける必要がありました。 さらに、この文脈における「視線」は、個々のボットの前にある 135 度の円錐です。 エージェントはプレイエリアの外側にあまり冒険することはできず、遮蔽物の作成と内部への侵入の両方に使用できる、周囲に点在するいくつかの外部オブジェクト (ボックス、可動壁、特別なスロープ) を使用する機能を使用して、ランダムに生成された部屋を移動することを余儀なくされました。 。
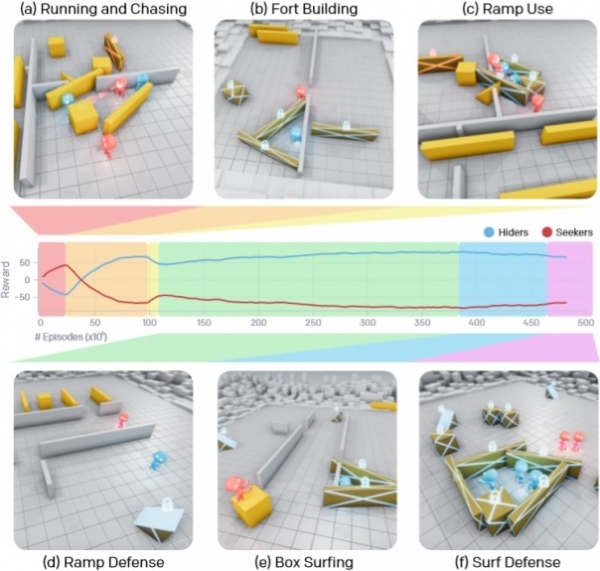
長い学習プロセスを通じて、AI エージェントは 25 つの独自の戦略を学習し、それぞれがゲームの次のステージに進むのに役立ちました。 当初、シーカー チームとハイダー チームは単に逃げたり追いかけたりしていましたが、約 75 万回の試合の後、ハイダー チームは箱で通路を塞ぎ、その中にシェルターを建てることを学びました。 さらに 10 万回の試合を行った後、チームはスロープを使用してこれらの隠れ家に侵入する方法を発見しました。 さらに XNUMX 万発を発射した後、ハイダーはスロープを競技エリアの端まで引きずり込み、対戦相手が使用できないように所定の位置に固定することを学びました。

388 億 458 万試合を経て、シーカーはブロックされたスロープを使って持ち込まれた木箱に登り、そこに直接移動して移動可能な壁で作られた敵の隠れ家に侵入する方法を学びました。 そして最後に、XNUMX 億 XNUMX 万回の対戦を経て、隠れチームはすべてのオブジェクトをブロックしてからシェルターを構築する必要があるという結論に達し、それが最終的な勝利につながったようです。
特に印象的なのは、22 万回のマッチングを経て、エージェントが自分たちの行動を調整することを学び、コラボレーションの効率が今後ますます向上することです。たとえば、各自が自分の箱や壁を持ち込んでシェルターを作り、自分の分担するオブジェクトを選択するようになりました。ブロックすると、対戦相手にとってゲームの難易度が複雑になります。

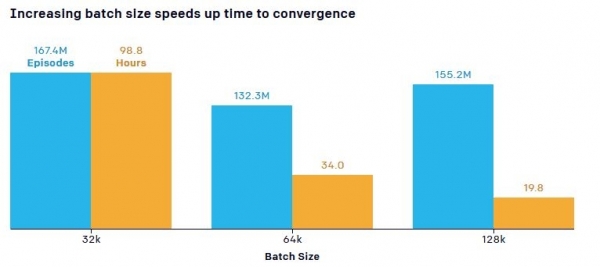
科学者らはまた、トレーニング オブジェクトの数 (ニューラル ネットワークを通過するデータの量、つまり「バッチ サイズ」) が学習速度に及ぼす影響に関する重要な点にも注目しました。 デフォルトのモデルでは、隠れチームがランプをブロックする方法を学習するまでに 132,3 時間のトレーニングで 34 億 0,5 万のマッチが必要でしたが、データが増えるとトレーニング時間が大幅に短縮されました。 たとえば、パラメータの数 (トレーニング プロセス全体で取得されるデータの一部) を 5,8 万から 2,2 万に増やすと、サンプリング効率が 64 倍に向上し、入力データのサイズが 128 KB から XNUMX KB に増えると、トレーニング時間が短縮されます。時間はほぼXNUMX倍です。
研究者らは研究の終わりに、エージェントがゲーム外で同様のタスクに対処するのにどれだけゲーム内トレーニングが役立つかをテストすることにした。 テストは全部で 4 つあります。オブジェクトの数の認識 (オブジェクトが見えなくなったり使用されなくなっても存在し続けることを理解する)。 「ロックして戻る」 - 元の位置を記憶し、追加のタスクを完了した後に元の位置に戻る能力。 「順次ブロック」 - ドアのない XNUMX つの部屋に XNUMX つのボックスがランダムに配置されていましたが、中に入るためのスロープがあり、エージェントはそれらをすべて見つけてブロックする必要がありました。 所定の場所にボックスを配置する。 円筒形のオブジェクトの周囲にシェルターを作成します。
その結果、XNUMX つのタスクのうち XNUMX つにおいて、ゲーム内で事前トレーニングを受けたボットは、問題を解決するためにゼロからトレーニングされた AI よりも学習が速く、より良い結果を示しました。 彼らは、タスクを完了して開始位置に戻り、密室でボックスを順番にブロックし、所定のエリアにボックスを配置する点ではわずかに優れた成績を収めましたが、オブジェクトの数を認識し、別のオブジェクトの周囲に遮蔽物を作成する点ではわずかにパフォーマンスが劣りました。
研究者らは、さまざまな結果が AI が特定のスキルを学習し記憶する方法に起因していると考えています。 「ゲーム内の事前トレーニングが最も効果を発揮したタスクには、以前に学習したスキルを使い慣れた方法で再利用することが含まれていたが、残りのタスクをゼロからトレーニングした AI よりもうまく実行するには、それらを別の方法で使用する必要があると考えています。より困難です」とこの論文の共著者は書いている。 「この結果は、トレーニングを通じて獲得したスキルをある環境から別の環境に移す際に効果的に再利用する方法を開発する必要性を浮き彫りにしています。」
この教育方法の使用の可能性はあらゆるゲームの限界をはるかに超えているため、行われた研究は本当に印象的です。 研究者らは、自分たちの研究は、病気を診断し、複雑なタンパク質分子の構造を予測し、CTスキャンを分析できる「物理学に基づいた」「人間のような」動作を備えたAIの開発に向けた重要な一歩であると述べている。
以下のビデオでは、学習プロセス全体がどのように行われたか、AI がどのようにチームワークを学習し、その戦略がますます狡猾で複雑になったかがはっきりとわかります。

出所: 3dnews.ru
