

Artikel kasebut mbahas sawetara cara kanggo nemtokake persamaan matematika saka garis regresi sing prasaja (dipasangake).
Kabeh cara kanggo ngrampungake persamaan sing dianggep ing kene adhedhasar metode kuadrat paling sithik. Kita bakal nemtokake cara kaya ing ngisor iki:
- Solusi analitik
- Keturunan Gradien
- Penurunan gradien stokastik
Kanggo saben cara kanggo ngrampungake persamaan garis lurus, artikel kasebut nyedhiyakake macem-macem fungsi, sing utamane dipérang dadi sing ditulis tanpa nggunakake perpustakaan. NomPy lan sing digunakake kanggo nindakake petungan NomPy. Punika pitados bilih nggunakake skillful NomPy bakal ngurangi biaya komputasi.
Kabeh kode sing diwenehake ing artikel kasebut ditulis nganggo basa python-2.7 nggunakake Notebook Jupyter KabKode sumber lan file data sampel kasedhiya ing
Artikel iki utamane ditujokake kanggo para pamula lan wong-wong sing wis mulai nguwasani sinau babagan intelijen buatan sing wiyar banget - learning machine.
Kanggo nggambarake materi, kita bakal nggunakake conto sing gampang banget.
Conto kahanan
Kita duwe limang nilai sing nggambarake katergantungan Y saka X (Tabel No. 1):
Tabel No. 1 "Kahanan Tuladha"

Ayo nganggep yen nilai-nilai kasebut  - iki sasi taun, lan
- iki sasi taun, lan  - revenue kanggo sasi iki. Ing tembung liyane, revenue gumantung ing sasi taun, lan
- revenue kanggo sasi iki. Ing tembung liyane, revenue gumantung ing sasi taun, lan  - mung fitur kang revenue gumantung.
- mung fitur kang revenue gumantung.
Conto kasebut rada winates, ing babagan hubungan kondisional antarane revenue lan sasi ing taun, lan babagan jumlah nilai-ana sawetara banget. Nanging, nyederhanakake iki bakal ngidini kita nerangake, ing istilah awam, materi, sing ora tansah gampang dicekel dening pemula. Salajengipun, kesederhanaan angka kasebut bakal ngidini wong-wong sing pengin ngrampungake conto ing kertas tanpa gaweyan sing signifikan.
Ayo kita nganggep manawa katergantungan sing diwenehake ing conto kasebut bisa dikira kanthi cukup kanthi persamaan matematika saka garis regresi prasaja (dipasangake) saka formulir:

ngendi  - iku sasi nalika revenue ditampa,
- iku sasi nalika revenue ditampa,  - revenue sing cocog karo sasi,
- revenue sing cocog karo sasi,  и
и  - koefisien regresi saka garis sing dikira.
- koefisien regresi saka garis sing dikira.
Elinga yen koefisien  asring disebut slope utawa gradient saka garis kira-kira; nggantosi jumlah kang ing
asring disebut slope utawa gradient saka garis kira-kira; nggantosi jumlah kang ing  nalika ngganti
nalika ngganti  .
.
Cetha yen tugas kita ing conto yaiku milih koefisien kasebut ing persamaan  и
и  , ing endi panyimpangan saka nilai revenue sing diwilang miturut wulan saka jawaban sing bener, yaiku nilai sing ditampilake ing conto, bakal minimal.
, ing endi panyimpangan saka nilai revenue sing diwilang miturut wulan saka jawaban sing bener, yaiku nilai sing ditampilake ing conto, bakal minimal.
Metode kuadrat paling sithik
Miturut cara kuadrat paling ora, panyimpangan kudu diitung kanthi kuadrat. Teknik iki nyegah panyimpangan saka mbatalake yen padha duwe pratandha ngelawan. Contone, yen ing siji kasus penyimpangan +5 (plus lima), lan liyane -5 (minus lima), banjur jumlah panyimpangan bakal mbatalake siji liyane lan padha karo 0 (nol). Utawa, tinimbang nggawe kuadrat panyimpangan, kita bisa nggunakake properti nilai absolut, ing kasus iki kabeh panyimpangan bakal positif lan kumulatif. Kita ora bakal njlèntrèhaké kanthi rinci babagan iki, nanging mung cathet menawa kanggo ngétung kanthi gampang, praktik umum kanggo nggawe kuadrat penyimpangan.
Iki minangka rumus sing bakal mbantu nemtokake jumlah penyimpangan kuadrat sing paling cilik (kesalahan):

ngendi  - iki minangka fungsi kira-kira saka jawaban sing bener (yaiku, revenue sing diwilang),
- iki minangka fungsi kira-kira saka jawaban sing bener (yaiku, revenue sing diwilang),
 - iki minangka jawaban sing bener (asil sing diwenehake ing conto),
- iki minangka jawaban sing bener (asil sing diwenehake ing conto),
 - minangka indeks sampel (nomer sasi ing ngendi panyimpangan ditemtokake)
- minangka indeks sampel (nomer sasi ing ngendi panyimpangan ditemtokake)
Ayo mbedakake fungsi kasebut, nemtokake persamaan diferensial parsial, lan siyap nerusake menyang solusi analitis. Nanging pisanan, ayo dipikirake kanthi ringkes babagan diferensiasi lan ngelingi makna geometris saka turunan kasebut.
Diferensiasi
Diferensiasi yaiku operasi nemokake turunan saka sawijining fungsi.
Apa gunane turunan? Turunan saka sawijining fungsi menehi ciri tingkat owah-owahan fungsi lan nuduhake arah. Yen turunan ing titik tartamtu positif, fungsi tambah; yen ora, fungsi iki mudun. Sing luwih gedhe nilai absolut saka turunan, luwih gedhe tingkat owah-owahan saka nilai fungsi, lan kemiringan grafik fungsi sing luwih curam.
Contone, ing sistem koordinat Cartesian, nilai turunan ing titik M(0,0) padha karo + 25 tegese ing titik tartamtu, nalika Nilai wis pindah  sisih tengen dening unit conventional, Nilai
sisih tengen dening unit conventional, Nilai  mundhak dening 25 Unit conventional. Ing grafik, iki katon kaya kenaikan nilai sing cukup curam.
mundhak dening 25 Unit conventional. Ing grafik, iki katon kaya kenaikan nilai sing cukup curam.  saka titik tartamtu.
saka titik tartamtu.
Conto liyane. Nilai turunan padha karo -0,1 tegese yen dipindhah  saben unit konvensional, nilai
saben unit konvensional, nilai  Ngurangi mung 0,1 unit konvensional. Kajaba iku, ing grafik fungsi, kita bisa mirsani slope mudhun sing meh ora katon. Nggambarake analogi karo gunung, kaya-kaya kita mudhun alon-alon, ora kaya conto sadurunge, ing ngendi kita kudu munggah ing pucuk sing curam banget.
Ngurangi mung 0,1 unit konvensional. Kajaba iku, ing grafik fungsi, kita bisa mirsani slope mudhun sing meh ora katon. Nggambarake analogi karo gunung, kaya-kaya kita mudhun alon-alon, ora kaya conto sadurunge, ing ngendi kita kudu munggah ing pucuk sing curam banget.
Mangkono, wis dibedakake fungsi  dening koefisien
dening koefisien  и
и  , kita nemtokake persamaan diferensial parsial urutan pisanan. Sawise nemtokake persamaan, kita entuk sistem saka rong persamaan, sing bisa milih nilai koefisien.
, kita nemtokake persamaan diferensial parsial urutan pisanan. Sawise nemtokake persamaan, kita entuk sistem saka rong persamaan, sing bisa milih nilai koefisien.  и
и  , sing nilai-nilai turunan sing cocog ing titik-titik kasebut diganti kanthi jumlah sing cilik banget, lan ing kasus solusi analitis, ora owah. Ing tembung liya, fungsi kesalahan kanggo koefisien sing ditemokake bakal tekan minimal, amarga nilai turunan parsial ing titik kasebut bakal padha karo nol.
, sing nilai-nilai turunan sing cocog ing titik-titik kasebut diganti kanthi jumlah sing cilik banget, lan ing kasus solusi analitis, ora owah. Ing tembung liya, fungsi kesalahan kanggo koefisien sing ditemokake bakal tekan minimal, amarga nilai turunan parsial ing titik kasebut bakal padha karo nol.
Dadi, miturut aturan diferensiasi, persamaan turunan parsial orde pertama babagan koefisien.  bakal njupuk formulir:
bakal njupuk formulir:

persamaan derivatif parsial orde kapisan babagan  bakal njupuk formulir:
bakal njupuk formulir:

Akibaté, kita entuk sistem persamaan sing nduweni solusi analitis sing cukup prasaja:
miwiti {persamaan*}
miwiti {kasus}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
pungkasan {kasus}
pungkasan {persamaan*}
Sadurunge ngrampungake persamaan, ayo pra-muat, priksa akurasi loading, lan format data.
Loading lan format data
Perlu dicathet menawa amarga kasunyatan manawa kanggo solusi analitik, lan mengko kanggo gradien lan gradient stokastik, kita bakal nggunakake kode kasebut ing rong variasi: nggunakake perpustakaan NomPy lan tanpa nggunakake, kita kudu format data cocok (ndeleng kode).
Data loading lan kode pangolahan
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Visualisasi
Saiki kita wis pisanan dimuat data, kapindho diverifikasi sing dimuat bener, lan pungkasanipun format data, ayo mbukak visualisasi pisanan kita. Cara sing asring digunakake kanggo iki yaiku pasangan perpustakaan segaraIng conto kita, amarga nomer winates, ora ana gunane nggunakake perpustakaan. segaraKita bakal nggunakake perpustakaan biasa. matplotlib lan ayo kang katon mung ing scatterplot.
Kode Scatterplot
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()Bagan No. 1 "Ketergantungan Pendapatan ing Wulan Taun"
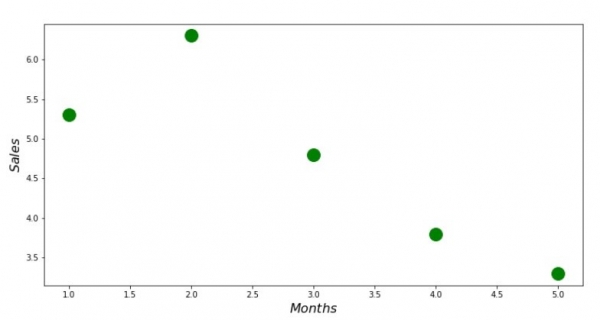
Solusi analitik
Ayo nggunakake alat sing paling umum ing python lan ngrampungake sistem persamaan:
miwiti {persamaan*}
miwiti {kasus}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
pungkasan {kasus}
pungkasan {persamaan*}
Miturut aturan Cramer kita bakal nemokake determinant umum, uga determinants kanggo  lan dening
lan dening  , sawise kang, dibagi determinant dening
, sawise kang, dibagi determinant dening  ing determinan umum - kita bakal nemokake koefisien
ing determinan umum - kita bakal nemokake koefisien  , uga kita nemokake koefisien
, uga kita nemokake koefisien  .
.
Kode solusi analitik
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Iki sing entuk:

Dadi, nilai koefisien wis ditemokake, lan jumlah panyimpangan kuadrat wis ditemtokake. Ayo tarik garis lurus ing histogram scatterplot sing cocog karo koefisien sing ditemokake.
Kode garis regresi
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Bagan 2: Jawaban sing bener lan diwilang
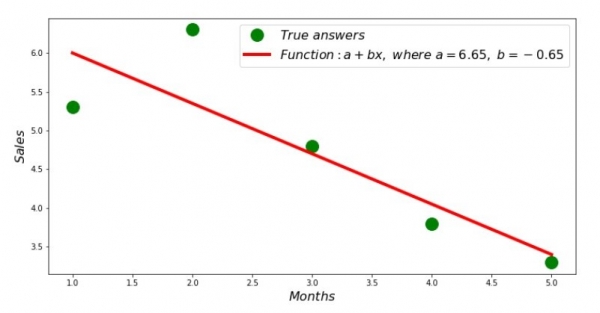
Kita bisa ndeleng grafik deviasi saben wulan. Ing kasus kita, kita ora bakal entuk nilai praktis sing signifikan saka iku, nanging bakal marem rasa penasaran kita babagan carane persamaan regresi linier sing prasaja nggambarake katergantungan revenue ing sasi taun.
Kode jadwal panyimpangan
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Bagan No. 3 "Penyimpangan, %"
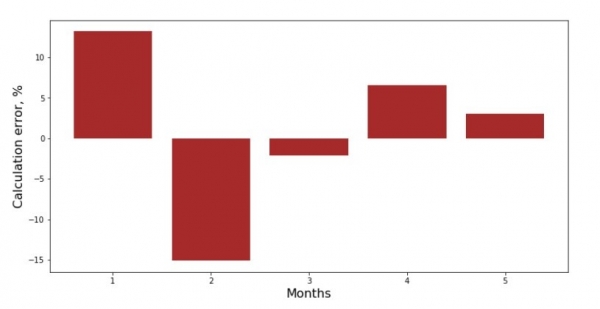
Iku ora sampurna, nanging kita wis rampung goal kita.
Ayo nulis fungsi sing bakal nemtokake koefisien  и
и  nggunakake perpustakaan NomPy, luwih tepat, kita bakal nulis rong fungsi: siji nggunakake matriks pseudoinverse (ora dianjurake ing laku, amarga proses komputasi rumit lan ora stabil), liyane nggunakake persamaan matriks.
nggunakake perpustakaan NomPy, luwih tepat, kita bakal nulis rong fungsi: siji nggunakake matriks pseudoinverse (ora dianjurake ing laku, amarga proses komputasi rumit lan ora stabil), liyane nggunakake persamaan matriks.
Kode solusi analitik (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npAyo mbandhingake wektu sing dibutuhake kanggo nemtokake koefisien  и
и  , sesuai karo 3 cara sing diwenehake.
, sesuai karo 3 cara sing diwenehake.
Kode kanggo ngitung wektu pitungan
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Ing jumlah data sing cilik, fungsi sing ditulis dhewe metu ing ngarep, sing nemokake koefisien nggunakake metode Cramer.
Saiki kita bisa pindhah menyang cara liya kanggo nemokake koefisien  и
и  .
.
Keturunan Gradien
Pisanan, ayo nemtokake gradien. Cukup, gradien minangka bagean sing nuduhake arah pertumbuhan maksimal sawijining fungsi. Padha karo munggah gunung, arah titik gradien minangka pendakian paling curam menyang ndhuwur. Ngembangake conto gunung, elinga yen apa sing kita butuhake yaiku turunan sing paling curam kanggo tekan lembah, utawa minimal, kanthi cepet-titik ing ngendi fungsi kasebut ora mundhak utawa nyuda. Ing titik iki, turunan bakal nol. Mulane, kita ora butuh gradien, nanging antigradient. Kanggo nemokake antigradient, mung multiply gradien dening -1 (minus siji).
Elinga yen fungsi bisa duwe pirang-pirang minima, lan kanthi mudhun menyang salah sijine nggunakake algoritma sing diusulake ing ngisor iki, kita ora bakal bisa nemokake minimal liyane, sing bisa uga luwih murah tinimbang sing ditemokake. Tenang, iki ora bakal kelakon! Ing kasus kita, kita lagi dealing karo minimal siji, wiwit kita fungsi  Ing grafik, katon kaya parabola biasa. Lan kita kabeh kudu ngerti saka kelas matematika sekolah, parabola mung duwe minimal siji.
Ing grafik, katon kaya parabola biasa. Lan kita kabeh kudu ngerti saka kelas matematika sekolah, parabola mung duwe minimal siji.
Sawise kita ngerti sebabe kita butuh kecerunan, lan uga kecerunan minangka bagean, yaiku, vektor kanthi koordinat sing diwenehake, sing persis koefisien kasebut.  и
и  Kita bisa ngleksanakake keturunan gradien.
Kita bisa ngleksanakake keturunan gradien.
Sadurunge diluncurake, aku saranake sampeyan maca sawetara ukara babagan algoritma keturunan:
- Kita nemtokake koordinat saka koefisien kanthi cara pseudo-acak
 и Ing conto kita, kita bakal nemtokake koefisien cedhak nol. Iki minangka praktik umum, nanging saben kasus mbutuhake pendekatan khusus dhewe.
и Ing conto kita, kita bakal nemtokake koefisien cedhak nol. Iki minangka praktik umum, nanging saben kasus mbutuhake pendekatan khusus dhewe. - Saka koordinat kita nyuda nilai turunan parsial urutan pisanan ing titik kasebut Dadi, yen turunan positif, fungsi kasebut mundhak. Mulane, kanthi nyuda turunan, kita bakal pindhah menyang arah ngelawan saka kenaikan, yaiku, ing arah keturunan. Yen turunan kasebut negatif, mula fungsi kasebut mudhun ing titik iki, lan kanthi nyuda turunan kasebut, kita pindhah menyang arah keturunan.
- Kita nindakake operasi sing padha karo koordinat : nyuda nilai turunan parsial ing titik kasebut .
- Kanggo ngindhari overshooting minimal lan mabur menyang papan sing jero, sampeyan kudu nyetel ukuran langkah mudhun. Nyatane, artikel kabeh bisa ditulis babagan carane nyetel ukuran langkah kanthi bener lan carane ngganti nalika mudhun kanggo nyuda biaya komputasi. Nanging saiki kita ngadhepi tugas sing rada beda, lan kita bakal nggunakake metode uji coba ilmiah, utawa, kaya sing dikandhakake, kanthi empiris, kanggo nemtokake ukuran langkah.
- Sawise kita wis ninggalake koordinat diwenehi и nyuda nilai turunan, kita entuk koordinat anyar и Kita njupuk langkah sabanjure (subtraction), wektu iki saka koordinat sing diwilang. Dadi siklus diwiwiti maneh lan maneh nganti konvergensi sing dikarepake bisa ditindakake.
 и
и  Ing conto kita, kita bakal nemtokake koefisien cedhak nol. Iki minangka praktik umum, nanging saben kasus mbutuhake pendekatan khusus dhewe.
Ing conto kita, kita bakal nemtokake koefisien cedhak nol. Iki minangka praktik umum, nanging saben kasus mbutuhake pendekatan khusus dhewe. kita nyuda nilai turunan parsial urutan pisanan ing titik kasebut
kita nyuda nilai turunan parsial urutan pisanan ing titik kasebut  Dadi, yen turunan positif, fungsi kasebut mundhak. Mulane, kanthi nyuda turunan, kita bakal pindhah menyang arah ngelawan saka kenaikan, yaiku, ing arah keturunan. Yen turunan kasebut negatif, mula fungsi kasebut mudhun ing titik iki, lan kanthi nyuda turunan kasebut, kita pindhah menyang arah keturunan.
Dadi, yen turunan positif, fungsi kasebut mundhak. Mulane, kanthi nyuda turunan, kita bakal pindhah menyang arah ngelawan saka kenaikan, yaiku, ing arah keturunan. Yen turunan kasebut negatif, mula fungsi kasebut mudhun ing titik iki, lan kanthi nyuda turunan kasebut, kita pindhah menyang arah keturunan.  : nyuda nilai turunan parsial ing titik kasebut
: nyuda nilai turunan parsial ing titik kasebut  .
. и
и  nyuda nilai turunan, kita entuk koordinat anyar
nyuda nilai turunan, kita entuk koordinat anyar  и
и  Kita njupuk langkah sabanjure (subtraction), wektu iki saka koordinat sing diwilang. Dadi siklus diwiwiti maneh lan maneh nganti konvergensi sing dikarepake bisa ditindakake.
Kita njupuk langkah sabanjure (subtraction), wektu iki saka koordinat sing diwilang. Dadi siklus diwiwiti maneh lan maneh nganti konvergensi sing dikarepake bisa ditindakake.Mekaten! Saiki kita wis siyap budhal golek jurang paling jero ing Palung Mariana. Ayo dadi miwiti.
Kode keturunan gradien
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Kita nyilem menyang paling ngisor Mariana Trench lan nemokake nilai koefisien sing padha ing kana.  и
и  , sing sejatine sing dikarepake.
, sing sejatine sing dikarepake.
Ayo nggawe nyilem maneh, mung wektu iki, ngisi peralatan laut jero bakal dadi teknologi sing beda, yaiku perpustakaan. NomPy.
Kode Keturunan Gradien (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Nilai saka koefisien  и
и  ora owah.
ora owah.
Ayo goleki carane kesalahan diganti nalika keturunan gradien, yaiku, carane jumlah penyimpangan kuadrat diganti karo saben langkah.
Kode kanggo jumlah kuadrat deviasi grafik
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Grafik #4: "Jumlah penyimpangan kuadrat ing keturunan gradien"
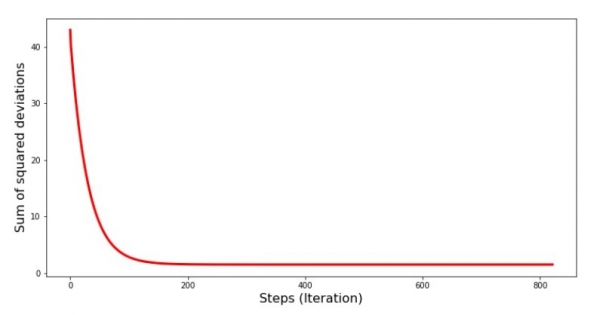
Ing grafik, kita weruh yen saben langkah kesalahane suda, lan sawise sawetara iterasi kita mirsani garis sing meh horisontal.
Pungkasan, ayo ngevaluasi bedane wektu eksekusi kode:
Kode kanggo nemtokake wektu komputasi turunan gradien
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Mbok kita nindakake soko salah, nanging maneh iku prasaja "omah-digawe" fungsi sing ora nggunakake perpustakaan NomPy ngluwihi fungsi sing nggunakake perpustakaan ing syarat-syarat wektu pitungan NomPy.
Nanging kita ora mandheg; kita pindhah menyang njelajah cara liyane sing menarik kanggo ngatasi persamaan regresi linier sing prasaja. Ketemu!
Penurunan gradien stokastik
Kanggo mangerteni kanthi cepet cara kerja turunan gradient stokastik, luwih becik nemtokake bedane saka turunan gradien biasa. Ing kasus keturunan gradien, kita nggunakake persamaan turunan  и
и  nggunakake jumlah nilai kabeh fitur lan jawaban sing bener sing kasedhiya ing sampel (yaiku, jumlah kabeh
nggunakake jumlah nilai kabeh fitur lan jawaban sing bener sing kasedhiya ing sampel (yaiku, jumlah kabeh  и
и  ). Ing keturunan kecerunan stokastik, kita ora bakal nggunakake kabeh nilai sing kasedhiya ing sampel, nanging, kita bakal pseudo-acak milih indeks sampel sing diarani lan nggunakake nilai kasebut.
). Ing keturunan kecerunan stokastik, kita ora bakal nggunakake kabeh nilai sing kasedhiya ing sampel, nanging, kita bakal pseudo-acak milih indeks sampel sing diarani lan nggunakake nilai kasebut.
Contone, yen indeks ditemtokake dadi nomer 3 (telu), banjur njupuk nilai  и
и  , banjur kita ngganti nilai kasebut menyang persamaan turunan lan nemtokake koordinat anyar. Banjur, sawise nemtokake koordinat, kita pseudorandomly nemtokake indeks sampel, ngganti nilai sing cocog karo indeks menyang persamaan turunan parsial, lan nemtokake maneh koordinat.
, banjur kita ngganti nilai kasebut menyang persamaan turunan lan nemtokake koordinat anyar. Banjur, sawise nemtokake koordinat, kita pseudorandomly nemtokake indeks sampel, ngganti nilai sing cocog karo indeks menyang persamaan turunan parsial, lan nemtokake maneh koordinat.  и
и  Lan sateruse nganti konvergensi dadi ijo. Sepisanan, bisa uga angel kanggo ndeleng kepiye cara iki bisa ditindakake, nanging bisa uga. Wigati dicathet, yen kesalahan ora suda saben langkah, nanging mesthi ana tren.
Lan sateruse nganti konvergensi dadi ijo. Sepisanan, bisa uga angel kanggo ndeleng kepiye cara iki bisa ditindakake, nanging bisa uga. Wigati dicathet, yen kesalahan ora suda saben langkah, nanging mesthi ana tren.
Apa kaluwihan saka turunan gradient stokastik tinimbang keturunan standar? Yen ukuran sampel kita gedhe banget, diukur ing puluhan ewu nilai, iku Ngartekno luwih gampang kanggo proses, ngomong, sampel acak saka sewu mau saka kabeh sampel. Iki ngendi keturunan gradient stokastik teka menyang muter. Ing kasus kita, kita mesthi ora bakal weruh akeh prabédan.
Ayo katon ing kode.
Kode kanggo turunan gradient stokastik
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Kita katon rapet ing koefisien lan nemokake dhéwé takon, "Kepiye iki bisa?" Kita wis entuk nilai koefisien sing beda.  и
и  Mbok menawa keturunan kecerunan stokastik nemokake paramèter persamaan sing luwih optimal? Sayange, ora. Cukup deleng jumlah panyimpangan kuadrat lan deleng yen kanthi nilai koefisien anyar, kesalahane luwih gedhe. Ayo ora kentekan niat. Ayo plot grafik saka owah-owahan kesalahan.
Mbok menawa keturunan kecerunan stokastik nemokake paramèter persamaan sing luwih optimal? Sayange, ora. Cukup deleng jumlah panyimpangan kuadrat lan deleng yen kanthi nilai koefisien anyar, kesalahane luwih gedhe. Ayo ora kentekan niat. Ayo plot grafik saka owah-owahan kesalahan.
Kode kanggo jumlah plot penyimpangan kuadrat ing turunan gradient stokastik
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Grafik #5: "Jumlah penyimpangan kuadrat ing turunan gradient stokastik"
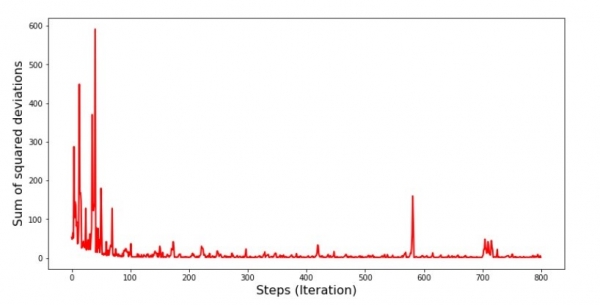
Deleng ing grafik, kabeh wis ana lan saiki kita bakal ndandani kabeh.
Dadi, apa sing kedadeyan? Ing ngisor iki kedadeyan. Nalika kita milih sasi kanthi acak, algoritma kita ngupaya nyuda kesalahan ing pitungan revenue kanggo sasi kasebut. Banjur kita pilih sasi liyane lan baleni pitungan, nanging kita nyuda kesalahan kanggo sasi kapindho sing dipilih. Saiki elinga yen rong sasi kapisan kita nyimpang sacara signifikan saka persamaan regresi linier sing prasaja. Iki tegese nalika kita milih salah siji saka rong sasi iki, kanthi ngurangi kesalahan kanggo saben, algoritma kita Ngartekno nambah kesalahan kanggo kabeh sampel. Dadi apa sing kudu kita lakoni? Jawaban iki prasaja: kita kudu ngurangi langkah keturunan. Sawise kabeh, kanthi nyuda langkah mudhun, kesalahan uga bakal mandheg mlumpat munggah lan mudhun. Utawa, kesalahan ora bakal mandheg mlumpat, nanging bakal ditindakake kanthi cepet. Ayo priksa.
Kode kanggo mbukak SGD kanthi langkah sing luwih cilik
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Grafik #6: "Jumlah penyimpangan kuadrat ing turunan gradient stokastik (80 langkah)"
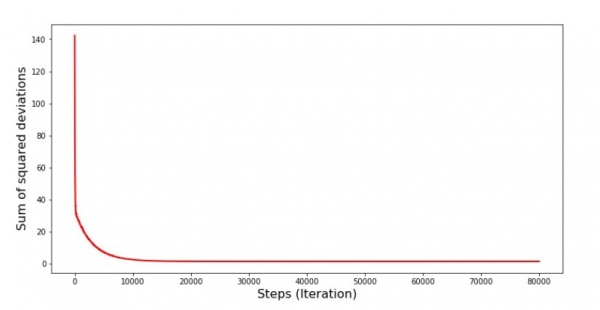
Nilai koefisien wis apik, nanging isih durung sampurna. Kanthi hipotesis, iki bisa didandani kanthi cara ing ngisor iki. Contone, kita bakal milih nilai koefisien kanggo 1000 iterasi pungkasan sing ngasilake kesalahan minimal. Nanging, kanggo nindakake iki, kita kudu ngrekam nilai koefisien dhewe. Kita ora bakal nindakake; tinimbang, ayo kang katon ing graph. Katon lancar, lan kesalahan katon mudhun kanthi rata. Ing kasunyatan, iki ora. Ayo ndeleng 1000 iterasi pisanan lan mbandhingake karo sing pungkasan.
Kode kanggo grafik SGD (1000 langkah pisanan)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Grafik #7 "Jumlah sisihan kuadrat SGD (1000 langkah pisanan)"
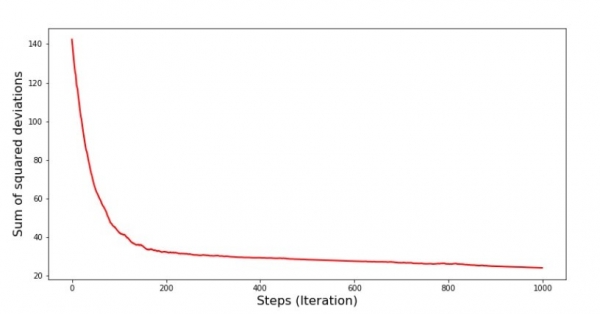
Bagan #8 "Jumlah SGD saka Penyimpangan Kuadrat (1000 Langkah Terakhir)"
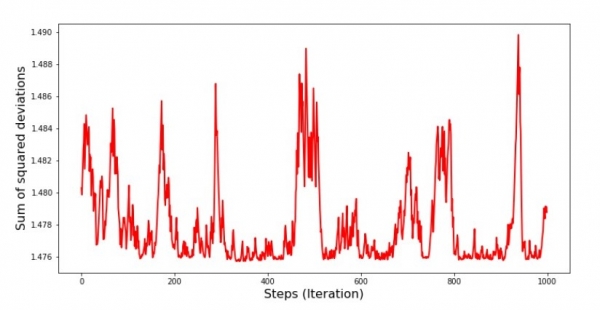
Ing awal banget mudhun, kita mirsani nyuda cukup mantep lan tajem ing kesalahan. Ing pengulangan final, kita waca sing kesalahan fluctuates watara 1,475 lan ing sawetara titik malah padha karo Nilai optimal iki, nanging banjur isih munggah ... Maneh, kita bisa ngrekam nilai koefisien.  и
и  , banjur pilih sing duwe kesalahan paling sithik. Nanging, kita nemoni masalah sing luwih serius: kita kudu nindakake 80 langkah (deleng kode) kanggo entuk nilai sing paling optimal. Iki mbantah ide kanggo ngirit wektu komputasi kanthi turunan gradient stokastik dibandhingake karo turunan gradien. Apa sing bisa didandani lan didandani? Iku gampang kanggo ndeleng sing ing iterasi pisanan, kita ajeg obah mudhun, lan mulane, kita kudu tetep ukuran langkah gedhe kanggo iterasi pisanan lan ngurangi nalika kita maju. Kita ora bakal nindakake ing artikel iki - wis cukup suwe. Sing pengin bisa ngerteni dhewe; ora angel.
, banjur pilih sing duwe kesalahan paling sithik. Nanging, kita nemoni masalah sing luwih serius: kita kudu nindakake 80 langkah (deleng kode) kanggo entuk nilai sing paling optimal. Iki mbantah ide kanggo ngirit wektu komputasi kanthi turunan gradient stokastik dibandhingake karo turunan gradien. Apa sing bisa didandani lan didandani? Iku gampang kanggo ndeleng sing ing iterasi pisanan, kita ajeg obah mudhun, lan mulane, kita kudu tetep ukuran langkah gedhe kanggo iterasi pisanan lan ngurangi nalika kita maju. Kita ora bakal nindakake ing artikel iki - wis cukup suwe. Sing pengin bisa ngerteni dhewe; ora angel.
Saiki ayo nindakake turunan gradient stokastik nggunakake perpustakaan NomPy (lan aja nganti kesandhung ing watu sing wis dingerteni sadurunge)
Kode kanggo turunan gradient stokastik (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
Nilai-nilai kasebut meh padha karo nalika mudhun tanpa nggunakake NomPy. Nanging, iki logis.
Ayo goleki sepira suwene turune kecerunan stokastik.
Kode kanggo nemtokake wektu komputasi SGD (80 ewu langkah)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Luwih menyang alas, awan sing luwih peteng: sepisan maneh, rumus "digawe omah" nuduhake asil sing paling apik. Kabeh iki nuduhake yen kudu ana cara sing luwih halus kanggo nggunakake perpustakaan. NomPy, sing tenan nyepetake operasi komputasi. Kita ora bakal sinau babagan iki ing artikel iki. Iku bakal menehi sampeyan mikir babagan ing wektu luang. :)
Ringkesan
Sadurunge nyimpulake, aku pengin mangsuli pitakon sing ditakoni para pamaca. Kok repot-repot karo turunan? Yagene kita kudu mlaku munggah lan mudhun gunung (biasane mudhun) kanggo nemokake titik kurang coveted, nalika kita duwe piranti kuat lan prasaja ing tangan kita, solusi analitis, sing langsung teleports kita menyang lokasi sing dikarepake?
Jawaban kanggo pitakonan iki ketok. Kita mung ndeleng conto sing gampang banget sing jawabane bener  gumantung ing siji tandha
gumantung ing siji tandha  Iki dudu perkara sing asring sampeyan temoni ing urip nyata, mula bayangake manawa kita duwe 2, 30, 50, utawa luwih akeh fitur. Tambah ewu, malah puluhan ewu, nilai kanggo saben fitur. Ing kasus iki, solusi analitis bisa gagal lan gagal. Katurunan gradien lan variasi, ing tangan liyane, bakal alon-alon nanging mesthi nggawa kita nyedhaki goal kita-minimal fungsi. Lan aja kuwatir babagan kacepetan - kita mesthi bakal njelajah cara sing ngidini kita nyetel lan nyetel dawa langkah (yaiku, kacepetan).
Iki dudu perkara sing asring sampeyan temoni ing urip nyata, mula bayangake manawa kita duwe 2, 30, 50, utawa luwih akeh fitur. Tambah ewu, malah puluhan ewu, nilai kanggo saben fitur. Ing kasus iki, solusi analitis bisa gagal lan gagal. Katurunan gradien lan variasi, ing tangan liyane, bakal alon-alon nanging mesthi nggawa kita nyedhaki goal kita-minimal fungsi. Lan aja kuwatir babagan kacepetan - kita mesthi bakal njelajah cara sing ngidini kita nyetel lan nyetel dawa langkah (yaiku, kacepetan).
Lan saiki ringkesan ringkes.
Kaping pisanan, muga-muga materi sing disedhiyakake ing artikel kasebut bakal mbantu para ilmuwan data wiwit ngerti carane ngatasi persamaan regresi linier sing prasaja (lan ora mung).
Kapindho, kita wis ndeleng sawetara cara kanggo ngatasi persamaan kasebut. Saiki, gumantung saka kahanan, kita bisa milih sing paling cocog karo tugas sing ditindakake.
Katelu, kita wis ndeleng kekuwatan setelan tambahan, yaiku dawa langkah keturunan gradien. Parameter iki ora kudu diabaikan. Kaya sing kasebut ing ndhuwur, kanggo nyuda biaya komputasi, dawa langkah kudu disetel nalika mudhun.
Papat, ing kasus kita, fungsi "ditulis ing omah" nuduhake wektu komputasi sing luwih apik. Iki bisa uga amarga panggunaan perpustakaan sing kurang profesional. NomPyNanging apa wae, kesimpulan ing ngisor iki jelas. Ing tangan siji, kadhangkala worth takon panemu sing wis mapan, nanging ing sisih liyane, iku ora tansah worth overcomplicating iku - ing nalisir, kadhangkala solusi prasaja kanggo masalah dadi luwih efektif. Lan amarga tujuane kanggo nliti telung pendekatan kanggo ngrampungake persamaan regresi linier sing sederhana, nggunakake fungsi "gawean omah" cukup cukup.
Sastra (utawa sapanunggalane)
1. Regresi linier
2. Metode kuadrat paling sithik
3. Turunan
4. Gradien
5. Keturunan gradien
6. Pustaka NumPy
Source: www.habr.com
