


Бул 2019-жыл жана бизде Кубернетестеги журналдарды бириктирүү үчүн стандарттуу чечим жок. Бул макалада биз чыныгы практикадан мисалдарды колдонуп, издөөлөрүбүздү, кездешкен көйгөйлөрдү жана аларды чечүү жолдорун бөлүшкүбүз келет.
Бирок, биринчиден, мен журналдарды чогултуу менен ар кандай кардарлар такыр башка нерселерди түшүнө турган ээлеп коём:
- кимдир бирөө коопсуздук жана аудит журналдарын көргүсү келет;
- бирөө - бүткүл инфраструктураны борборлоштурулган каротаждоо;
- жана кээ бирлери үчүн, мисалы, баланстоочуларды кошпогондо, тиркеме журналдарын гана чогултуу жетиштүү.
Төмөндө биз ар кандай "каалоо тизмелерин" кантип ишке ашырганыбыз жана кандай кыйынчылыктарга дуушар болгонубуз жөнүндө төмөндө келтирилген.
Теория: каротаждоо куралдары жөнүндө
Каттоо системасынын компоненттери жөнүндө маалымат
Агрегаттарды кыюу узак жолду басып өттү, анын натыйжасында журналдарды чогултуу жана талдоо методологиялары иштелип чыкты, аны биз бүгүн колдонобуз. 1950-жылдары Фортран стандарттык киргизүү/чыгарма агымдарынын аналогун киргизген, бул программистке өзүнүн программасын оңдоого жардам берген. Булар ошол кездеги программисттердин жашоосун жеңилдеткен биринчи компьютердик журналдар болчу. Бүгүн биз алардан каротаждоо системасынын биринчи компонентин көрүп жатабыз - журналдардын булагы же "өндүрүүчүсү".
Информатика бир орунда турган жок: компьютердик тармактар пайда болду, алгачкы кластерлер... Бир нече компьютерден турган татаал системалар иштей баштады. Эми системалык администраторлор бир нече машиналардан журналдарды чогултууга аргасыз болушкан жана өзгөчө учурларда алар системанын катасын иликтөө керек болгон учурда OS ядросунун билдирүүлөрүн кошо алышкан. 2000-жылдардын башында борборлоштурулган журнал чогултуу системаларын сүрөттөө үчүн, ал басылып чыккан , бул remote_syslog стандартташтырылган. Бул дагы бир маанилүү компоненти пайда болгон: журнал жыйноочу жана аларды сактоо.
Журналдардын көлөмүнүн көбөйүшү жана веб-технологиялардын кеңири жайылуусу менен колдонуучуларга кандай журналдарды ыңгайлуу көрсөтүү керек деген суроо пайда болду. Жөнөкөй консол куралдары (awk/sed/grep) өркүндөтүлгөн куралдар менен алмаштырылды көрүүчүлөр журналы - үчүнчү компонент.
Журналдын көлөмүнүн көбөйүшүнө байланыштуу дагы бир нерсе ачыкка чыкты: журналдар керек, бирок алардын баары эмес. Ал эми ар кандай журналдар ар кандай деңгээлде сакталышын талап кылат: айрымдары бир күндө жоголуп кетсе, башкалары 5 жыл сакталышы керек. Ошентип, маалымат агымын чыпкалоо жана багыттоо үчүн компонент журнал жазуу тутумуна кошулду - келгиле, аны чакыралы чыпкалоо.
Сактагыч дагы чоң секирик жасады: кадимки файлдардан реляциялык маалымат базаларына, андан кийин документке багытталган сактоого (мисалы, Elasticsearch). Ошентип, сактоочу жай коллектордон бөлүнгөн.
Акыр-аягы, журнал түшүнүгү биз тарых үчүн сактап калгыбыз келген окуялардын абстракттуу агымына чейин кеңейди. Тагыраак айтканда, иликтөө жүргүзүү же аналитикалык корутунду түзүү керек болсо...
Натыйжада, салыштырмалуу кыска убакыттын ичинде журналдарды чогултуу чоң маалыматтардагы бөлүмдөрдүн бири деп атоого боло турган маанилүү подсистемага айланды.
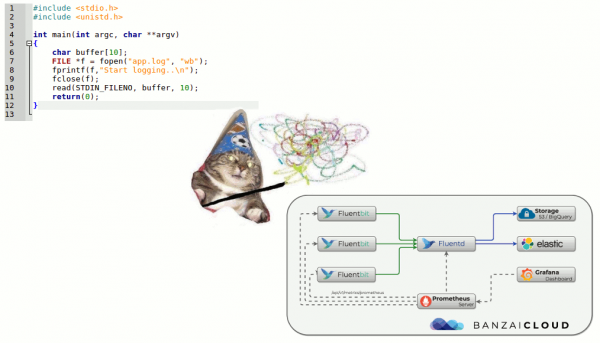
Эгерде качандыр бир кезде кадимки басып чыгаруулар “каротаждоо системасы” үчүн жетиштүү болсо, азыр абал бир топ өзгөрдү.
Kubernetes жана журналдар
Кубернетес инфраструктурага келгенде, журналдарды чогултуу көйгөйү да аны айланып өткөн жок. Кандайдыр бир деңгээлде бул ого бетер оорлоду: инфраструктуралык платформаны башкаруу жөнөкөйлөштүрүлбөстөн, ошол эле учурда татаалдашкан. Көптөгөн эски кызматтар микросервистерге өтө баштады. Журналдардын контекстинде бул лог булактарынын көбөйүшүнөн, алардын өзгөчө жашоо циклинен жана журналдар аркылуу системанын бардык компоненттеринин өз ара мамилелерине көз салуу зарылчылыгынан көрүнүп турат...
Алдыга карап, мен айта алам, тилекке каршы, Kubernetes үчүн стандартташтырылган каттоо варианты жок, ал башкаларга салыштырмалуу жакшы. Коомчулукта эң популярдуу схемалар төмөнкүлөр:
- кимдир бирөө стекти чечет EFK (Elasticsearch, Fluentd, Kibana);
- кимдир бирөө жакында бошотулган аракет кылып жатат же колдонот ;
- нас (жана балким биз эле эмес?..) Мен өзүмдүн өнүгүүсүмө канааттанам - ...
Эреже катары, биз K8s кластерлеринде төмөнкү таңгактарды колдонобуз (өз алдынча жайгаштырылган чечимдер үчүн):
- ;
- .
Бирок, мен аларды орнотуу жана конфигурациялоо боюнча көрсөтмөлөргө токтолбойм. Тескерисинче, мен алардын кемчиликтерине жана жалпы логдорго байланыштуу кырдаал жөнүндө көбүрөөк глобалдуу корутундуларга токтолом.
K8s журналдары менен машыгыңыз

“Күнүмдүк журналдар”, канчасың?..
Жетиштүү чоң инфраструктурадан журналдарды борборлоштурулган чогултуу журналдарды чогултууга, сактоого жана кайра иштетүүгө сарпталуучу олуттуу ресурстарды талап кылат. Ар кандай долбоорлорду ишке ашырууда биз ар кандай талаптарга жана алардан келип чыккан операциялык көйгөйлөргө туш болдук.
Келгиле ClickHouse аракет кылалы
Келгиле, долбоордогу борборлоштурулган сактагычты карап көрөлү. Келгиле, анын журналдары менен иштей баштайлы, аларды ClickHouseга кошуп.
Максималдуу реалдуу убакыт талап кылынар замат, ClickHouse менен 4 ядролук сервер дисктин подсистемасына ашыкча жүктөлөт:
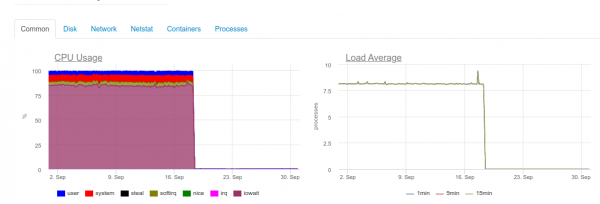
Жүктөөнүн бул түрү биз ClickHouseда мүмкүн болушунча тезирээк жазууга аракет кылып жатканыбызга байланыштуу. Ал эми маалымат базасы буга катуу диск жүктөө менен жооп берет, бул төмөнкү каталарды алып келиши мүмкүн:
DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts
Учур болуп саналат ClickHouse ичинде (алар журнал маалыматтарын камтыйт) жазуу операцияларында өз кыйынчылыктарына ээ. Аларга киргизилген маалыматтар убактылуу бөлүмдү жаратат, ал андан кийин негизги таблица менен бириктирилет. Натыйжада, жазуу дискте абдан талап кылынат, ошондой эле биз жогоруда эскертүү алган чектөөгө дуушар болот: 1 секунданын ичинде 300дөн ашык бөлүмчөлөрдү бириктирүүгө болбойт (чындыгында бул 300 кыстаруу. секундасына).
Мындай жүрүм-турумду болтурбоо үчүн, мүмкүн болушунча чоң бөлүктөрдө жана ар 1 секундада 2 жолудан ашык эмес. Бирок, чоң жарылуулар менен жазуу ClickHouse'та азыраак жазышыбызды сунуштайт. Бул өз кезегинде буфердин толуп кетишине жана журналдардын жоголушуна алып келиши мүмкүн. Чечим Fluentd буферин көбөйтүү болуп саналат, бирок андан кийин эстутум керектөө да көбөйөт.
пикир: ClickHouse менен чечимибиздин дагы бир көйгөйлүү аспектиси биздин ишибизде бөлүү (loghouse) туташтырылган тышкы таблицалар аркылуу ишке ашырылганына байланыштуу болгон. . Бул чоң убакыт аралыгын тандап алууда ашыкча RAM талап кылынышына алып келет, анткени метатаблица бардык бөлүмдөр аркылуу кайталанат - ал тургай, албетте, зарыл болгон маалыматтарды камтыбайт. Бирок, азыр бул ыкма ClickHouse учурдагы версиялары үчүн эскирген деп жарыяланышы мүмкүн (c ).
Натыйжада, ар бир долбоор ClickHouse реалдуу убакытта журналдарды чогултуу үчүн жетиштүү ресурстарга ээ эмес экени айкын болуп калат (тагыраак айтканда, аларды бөлүштүрүү ылайыктуу болбойт). Мындан тышкары, сиз колдонуу керек болот батарея, ага биз кийинчерээк кайтабыз. Жогоруда айтылган окуя реалдуу. Ал эми ошол учурда биз кардарга ылайыктуу жана минималдуу кечигүү менен журналдарды чогултууга мүмкүндүк берген ишенимдүү жана туруктуу чечимди сунуштай алган жокпуз...
Elasticsearch жөнүндө эмне айтууга болот?
Elasticsearch оор жүктөрдү көтөрөрү белгилүү. Келгиле, ошол эле долбоордо аракет кылалы. Эми жүк төмөнкүдөй көрүнөт:
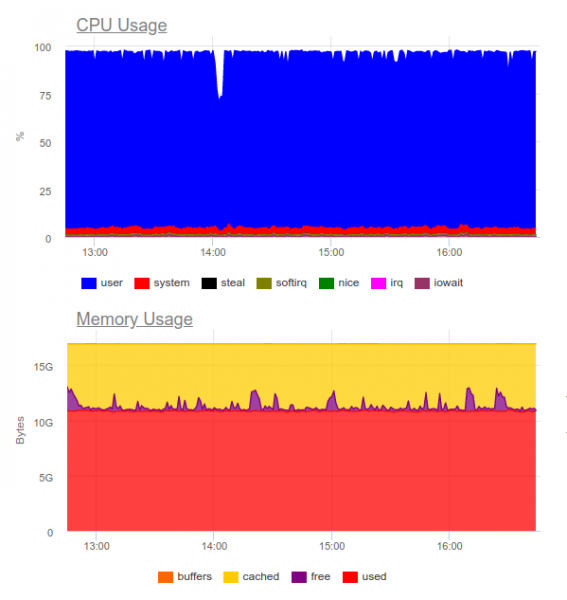
Elasticsearch маалымат агымын сиңире алган, бирок ага мындай көлөмдөрдү жазуу процессорду көп колдонот. Бул кластер уюштуруу менен чечилет. Техникалык жактан алганда, бул көйгөй эмес, бирок лог чогултуу тутумун иштетүү үчүн биз 8 өзөктү колдонобуз жана системада кошумча жүктөлгөн компонент бар экен...
Жыйынтык: бул вариантты актоого болот, бирок долбоор чоң болсо жана анын жетекчилиги борборлоштурулган каротаж системасына олуттуу ресурстарды сарптоого даяр болсо гана.
Анан табигый суроо туулат:
Кандай журналдар чынында эле керек?
 Келгиле, мамиленин өзүн өзгөртүүгө аракет кылалы: журналдар бир эле учурда маалыматтык болушу керек жана камтылбайт ар бири системадагы окуя.
Келгиле, мамиленин өзүн өзгөртүүгө аракет кылалы: журналдар бир эле учурда маалыматтык болушу керек жана камтылбайт ар бири системадагы окуя.
Бизде ийгиликтүү онлайн дүкөн бар дейли. Кандай журналдар маанилүү? Мүмкүн болушунча көбүрөөк маалымат чогултуу, мисалы, төлөм шлюзунан, бул сонун идея. Бирок продукт каталогундагы сүрөттөрдү кесүү кызматынын бардык журналдары биз үчүн маанилүү эмес: каталар жана өркүндөтүлгөн мониторинг гана жетиштүү (мисалы, бул компонент жараткан 500 катанын пайызы).
Ошентип, биз ушундай жыйынтыкка келдик борборлоштурулган жыгач даярдоо дайыма эле актай бербейт. Көбүнчө, кардар бардык журналдарды бир жерде чогултууну каалайт, бирок чындыгында бүт журналдан бизнес үчүн маанилүү болгон билдирүүлөрдүн 5% шарттуу гана талап кылынат:
- Кээде конфигурациялоо үчүн жетиштүү болот, айталы, бир гана контейнер журналынын өлчөмүн жана ката чогултуучу (мисалы, Sentry).
- Ката жөнүндө билдирүү жана чоң жергиликтүү журналдын өзү инциденттерди иликтөө үчүн көп учурда жетиштүү болушу мүмкүн.
- Бизде функционалдык тесттер жана каталарды чогултуу системалары менен иштеген долбоорлорубуз бар болчу. Иштеп чыгуучуга журналдардын кереги жок болчу - алар ката издеринен баштап баарын көрүштү.
Жашоодон алынган иллюстрация
Дагы бир окуя жакшы мисал боло алат. Кубернетести киргизүүгө чейин эле иштелип чыккан коммерциялык чечимди колдонуп жүргөн кардарларыбыздын биринин коопсуздук командасынан сурам алдык.
Корпоративдик көйгөйлөрдү аныктоо сенсору - QRadar менен журналдарды чогултуунун борборлоштурулган тутумун "достошуу" керек болчу. Бул система syslog протоколу аркылуу журналдарды кабыл алып, аларды FTPден чыгара алат. Бирок, аны fluentd үчүн remote_syslog плагини менен интеграциялоо дароо мүмкүн болгон жок (көрүлгөндөй, ). QRadarды орнотуудагы көйгөйлөр кардардын коопсуздук командасы тарапта болуп чыкты.
Натыйжада, бизнес үчүн маанилүү журналдардын бир бөлүгү FTP QRadarга жүктөлдү, ал эми экинчи бөлүгү алыскы система аркылуу түз түйүндөрдөн багытталды. Бул үчүн биз да жазганбыз - балким, бул кимдир бирөөгө ушундай эле көйгөйдү чечүүгө жардам берет... Алынган схеманын аркасында кардар өзү критикалык журналдарды кабыл алып, талдап чыкты (өзүнүн сүйүктүү инструменттерин колдонуу менен), биз каротаждоо системасынын баасын төмөндөтүп, өткөн айда.
Дагы бир мисал эмне кылбоо керек экенин көрсөтүп турат. иштетүү үчүн биздин кардарлардын бири ар биринин колдонуучудан келген окуялар, көп сапты түздү структураланбаган өндүрүш маалымат журналында. Сиз ойлогондой, мындай журналдар окууга да, сактоого да өтө ыңгайсыз болгон.
Журналдар үчүн критерийлер
Мындай мисалдар журнал чогултуу системасын тандоодон тышкары, керек деген жыйынтыкка алып келет ошондой эле журналдарды өздөрү долбоорлоо! Бул жерде кандай талаптар бар?
- Журналдар машина окуй турган форматта болушу керек (мисалы, JSON).
- Журналдар компакттуу жана мүмкүн болгон көйгөйлөрдү оңдоо үчүн журналдын деңгээлин өзгөртүү мүмкүнчүлүгүнө ээ болушу керек. Ошол эле учурда, өндүрүш чөйрөлөрүндө сиз сыяктуу журналдар деңгээли менен системаларды иштетүү керек эскертүү же ката.
- Журналдар нормалдаштырылган болушу керек, башкача айтканда, журнал объектисинде бардык саптар бирдей талаа тибине ээ болушу керек.
Структураланбаган журналдар журналдарды сактоого жүктөө жана аларды иштетүүнү толугу менен токтотууда көйгөйлөргө алып келиши мүмкүн. Иллюстрация катары, бул жерде 400 катасы бар мисал келтирилген, аны көптөгөн адамдар ачык журналдарда жолуктурушкан:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"
Ката сиз түрү туруксуз талааны даяр карта менен индекске жөнөтүп жатканыңызды билдирет. Эң жөнөкөй мисал nginx журналындагы өзгөрмөлүү талаа $upstream_status. Ал санды же сапты камтышы мүмкүн. Мисалы:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}
Журналдар сервер 10.100.0.10 404 катасы менен жооп берип, сурам башка мазмун сактагычка жөнөтүлгөнүн көрсөтүп турат. Натыйжада, журналдардагы маани мындай болуп калды:
"upstream_response_time": "0.001, 0.007"
Бул жагдай абдан таралган, ал тургай, өзүнчө татыктуу .
Ишенимдүүлүк жөнүндө эмне айтууга болот?
Бардык журналдар өзгөчө маанилүү болгон учурлар бар. Ушуну менен, жогоруда сунушталган/талкууланган K8s үчүн типтүү журналдарды чогултуу схемаларында көйгөйлөр бар.
Мисалы, fluentd кыска мөөнөттүү контейнерлерден журналдарды чогулта албайт. Биздин долбоорлордун биринде, маалымат базасынын миграциялык контейнери 4 секундага жетпеген убакыт жашап, андан кийин өчүрүлгөн - тиешелүү аннотацияга ылайык:
"helm.sh/hook-delete-policy": hook-succeeded
Ушундан улам, миграцияны аткаруу журналы сактагычка киргизилген эмес. Бул учурда саясат жардам бере алат. before-hook-creation.
Дагы бир мисал - Docker журналынын айлануусу. Журналдарга активдүү жазган тиркеме бар дейли. Кадимки шарттарда биз бардык журналдарды иштеп чыгууга жетишебиз, бирок көйгөй пайда болору менен - мисалы, туура эмес формат менен жогоруда сүрөттөлгөндөй - иштетүү токтойт жана Докер файлды айлантат. Натыйжада, бизнес үчүн маанилүү журналдар жоголуп кетиши мүмкүн.
Мына ушул себептен лог агымдарын бөлүү маанилүү, алардын коопсуздугун камсыз кылуу үчүн эң баалууларын түздөн-түз колдонмого жөнөтүү. Мындан тышкары, кээ бир түзүү ашыкча болмок эмес журналдардын "аккумулятору", бул маанилүү билдирүүлөрдү сактоо менен бирге кыска сактагычтын жетишсиздигине туруштук бере алат.
Акыр-аягы, биз муну унутпашыбыз керек Кандайдыр бир подсистеманы туура көзөмөлдөө маанилүү. Болбосо, эркин сүйлөй турган абалга туш болуу оңой CrashLoopBackOff жана эч нерсе жөнөтпөйт жана бул маанилүү маалыматтын жоголушун убада кылат.
табылгалары
Бул макалада биз Datadog сыяктуу SaaS чечимдерин карап жаткан жокпуз. Бул жерде сүрөттөлгөн көйгөйлөрдүн көбү журналдарды чогултууга адистешкен коммерциялык компаниялар тарабынан тигил же бул жол менен чечилген, бирок баары эле ар кандай себептерден улам SaaS колдоно албайт. (негизгилери наркы жана 152-ФЗ ылайык).
Борборлоштурулган журналдарды чогултуу алгач жөнөкөй иш сыяктуу көрүнөт, бирок такыр андай эмес. Бул эстен чыгарбоо маанилүү:
- Мониторингди жана каталарды чогултууну башка системалар үчүн конфигурациялоого болот, ал эми маанилүү компоненттерди гана деталдуу түрдө киргизүү керек.
- Керексиз жүктү кошпоо үчүн өндүрүштөгү журналдар минималдуу болушу керек.
- Журналдар машинада окула турган, нормалдаштырылган жана катуу форматка ээ болушу керек.
- Чынында эле критикалык журналдар өзүнчө агымда жөнөтүлүшү керек, алар негизгилерден бөлүнүшү керек.
- Сизди чоң жүктүн жарылуусунан куткара турган жана сактоочу жайдагы жүктү бир калыпта кыла турган журнал аккумуляторун карап чыгуу зарыл.

Бул жөнөкөй эрежелер, эгерде бардык жерде колдонулса, жогоруда сүрөттөлгөн схемалардын иштөөсүнө мүмкүндүк берет - аларда маанилүү компоненттер (батарея) жок болсо дагы. Эгерде сиз мындай принциптерди карманбасаңыз, тапшырма сизди жана инфраструктураны системанын башка жогорку жүктөлгөн (жана ошол эле учурда натыйжасыз) компонентине оңой алып барат.
PS
Биздин блогдон дагы окуңуз:
- «";
- «";
- ««.
Source: www.habr.com
