

Биз "жөнөкөй көрүнгөн" PostgreSQL сурамдарынын натыйжалуулугун жакшыртуунун анча белгилүү эмес жолдорун изилдөөгө арналган макалалардын сериясын улантабыз:
Мага КОШУЛУУ анчалык жакпайт деп ойлобоңуз... :)
Бирок көп учурда ансыз, өтүнүч ага караганда кыйла жемиштүү болуп чыгат. Ошентип, биз бүгүн аракет кылабыз ресурсту көп талап кылган ЖООНдон арылуу - сөздүктү колдонуу.

PostgreSQL 12ден баштап, төмөндө сүрөттөлгөн жагдайлардын айрымдары бир аз башкачараак чыгарылышы мүмкүн . Бул кыймыл-аракетти ачкычты көрсөтүү менен кайтарса болот
MATERIALIZED.
Чектелген лексикадагы көп "фактылар"
Өтө реалдуу колдонмо тапшырмасын алалы - биз тизмени көрсөтүшүбүз керек же жөнөтүүчүлөр менен активдүү тапшырмалар:
25.01 | Иванов И.И. | Подготовить описание нового алгоритма.
22.01 | Иванов И.И. | Написать статью на Хабр: жизнь без JOIN.
20.01 | Петров П.П. | Помочь оптимизировать запрос.
18.01 | Иванов И.И. | Написать статью на Хабр: JOIN с учетом распределения данных.
16.01 | Петров П.П. | Помочь оптимизировать запрос.
Абстрактуу дүйнөдө тапшырманын авторлору биздин уюмдун бардык кызматкерлерине бирдей бөлүштүрүлүшү керек, бирок чындыгында милдеттер, эреже катары, бир кыйла чектелген сандагы адамдардан келет - иерархия боюнча “башкаруудан” же кошуна бөлүмдөрдөн (аналитиктер, дизайнерлер, маркетинг, ...) “субподрядчылардан”.
1000 адамдан турган биздин уюмда 20 гана автор (адатта андан да азыраак) ар бир конкреттүү аткаруучуга тапшырмаларды жана "салттуу" суроону тездетүү.
Скрипт генератору
-- сотрудники
CREATE TABLE person AS
SELECT
id
, repeat(chr(ascii('a') + (id % 26)), (id % 32) + 1) "name"
, '2000-01-01'::date - (random() * 1e4)::integer birth_date
FROM
generate_series(1, 1000) id;
ALTER TABLE person ADD PRIMARY KEY(id);
-- задачи с указанным распределением
CREATE TABLE task AS
WITH aid AS (
SELECT
id
, array_agg((random() * 999)::integer + 1) aids
FROM
generate_series(1, 1000) id
, generate_series(1, 20)
GROUP BY
1
)
SELECT
*
FROM
(
SELECT
id
, '2020-01-01'::date - (random() * 1e3)::integer task_date
, (random() * 999)::integer + 1 owner_id
FROM
generate_series(1, 100000) id
) T
, LATERAL(
SELECT
aids[(random() * (array_length(aids, 1) - 1))::integer + 1] author_id
FROM
aid
WHERE
id = T.owner_id
LIMIT 1
) a;
ALTER TABLE task ADD PRIMARY KEY(id);
CREATE INDEX ON task(owner_id, task_date);
CREATE INDEX ON task(author_id);
Келгиле, конкреттүү аткаруучу үчүн акыркы 100 тапшырманы көрсөтөлү:
SELECT
task.*
, person.name
FROM
task
LEFT JOIN
person
ON person.id = task.author_id
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100; 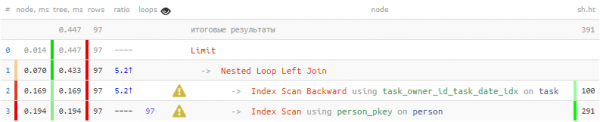
Ал экен 1/3 жалпы убакыт жана 3/4 окуу маалыматтардын барактары авторду 100 жолу издөө үчүн гана жасалган - ар бир чыгуу тапшырмасы үчүн. Бирок бул жүздөгөндөрдүн арасында биз билебиз болгону 20 түрдүү - Бул билимди колдонууга болобу?
hstore-сөздүк
Келгиле, пайдаланалы "сөздүк" ачкыч-маанисин түзүү үчүн:
CREATE EXTENSION hstoreБиз жөн гана сөздүккө автордун идентификаторун жана анын атын киргизишибиз керек, ошондо биз бул ачкычты колдонуп чыгара алабыз:
-- формируем целевую выборку
WITH T AS (
SELECT
*
FROM
task
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100
)
-- формируем словарь для уникальных значений
, dict AS (
SELECT
hstore( -- hstore(keys::text[], values::text[])
array_agg(id)::text[]
, array_agg(name)::text[]
)
FROM
person
WHERE
id = ANY(ARRAY(
SELECT DISTINCT
author_id
FROM
T
))
)
-- получаем связанные значения словаря
SELECT
*
, (TABLE dict) -> author_id::text -- hstore -> key
FROM
T; 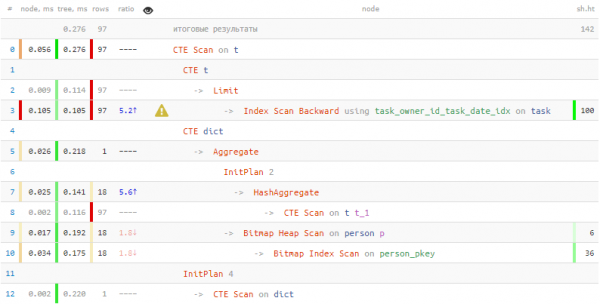
адамдар тууралуу маалымат алууга жумшалган 2 эсе аз убакыт жана 7 эсе аз маалымат окуу! Бул натыйжаларга жетүүбүзгө "сөз байлыгы" менен катар эмне жардам берди жапырт жазуу издөө колдонуу менен бир өтүү менен столдон = ANY(ARRAY(...)).
Таблица жазуулары: Сериялаштыруу жана Сериялаштыруу
Бирок биз бир эле текст талаасын эмес, сөздүктөгү бүт жазууну сактап алышыбыз керек болсочу? Бул учурда, PostgreSQL жөндөмү бизге жардам берет таблица жазуусун жалгыз маани катары караңыз:
...
, dict AS (
SELECT
hstore(
array_agg(id)::text[]
, array_agg(p)::text[] -- магия #1
)
FROM
person p
WHERE
...
)
SELECT
*
, (((TABLE dict) -> author_id::text)::person).* -- магия #2
FROM
T;Келгиле, бул жерде эмне болуп жатканын карап көрөлү:
- Биз алдык p толук адамдын таблицасына лакап ат катары жана алардын массивдерин чогултту.
- бул жаздыруулардын массиви кайра түзүлдү текст саптарынын массивине (person[]::text[]) аны hstore сөздүгүнө маанилердин массиви катары жайгаштырыңыз.
- Тиешелүү жазууну алганыбызда, биз ачкыч менен сөздүктөн алынган текст сап катары.
- Бизге текст керек таблица түрүнүн маанисине айландыруу адам (ар бир таблица үчүн ошол эле аталыштагы тип автоматтык түрдө түзүлөт).
- Терилген жазууну колдонуу менен мамычаларга "кеңейтиңиз"
(...).*.
json сөздүгү
Бирок, биз жогоруда колдонгон мындай амал, эгерде "кастинг" жасоо үчүн тиешелүү үстөлдүн түрү жок болсо, иштебейт. Дал ушундай жагдай жаралат, колдонсок "чыныгы" таблица эмес, CTE катар.
Бул учурда алар бизге жардам беришет :
...
, p AS ( -- это уже CTE
SELECT
*
FROM
person
WHERE
...
)
, dict AS (
SELECT
json_object( -- теперь это уже json
array_agg(id)::text[]
, array_agg(row_to_json(p))::text[] -- и внутри json для каждой строки
)
FROM
p
)
SELECT
*
FROM
T
, LATERAL(
SELECT
*
FROM
json_to_record(
((TABLE dict) ->> author_id::text)::json -- извлекли из словаря как json
) AS j(name text, birth_date date) -- заполнили нужную нам структуру
) j; Белгилей кетчү нерсе, максаттуу структураны сүрөттөп жатканда, биз булак саптын бардык талааларын тизмектеп бере албайбыз, бирок бизге чындап керек болгондор гана. Эгерде бизде "туулган" таблица болсо, анда функцияны колдонгон жакшы json_populate_record.
Биз дагы эле сөздүккө бир жолу киребиз, бирок json-[de]сериялаштыруу чыгымдары кыйла жогору, ошондуктан, бул ыкманы "чынчыл" CTE Scan өзүн жаман көрсөткөн кээ бир учурларда гана колдонуу акылга сыярлык.
Сыноо көрсөткүчү
Ошентип, бизде маалыматтарды сөздүккө сериялаштыруунун эки жолу бар hstore/json_object. Мындан тышкары, ачкычтардын массивдери жана баалуулуктары эки жол менен түзүлүшү мүмкүн, текстке ички же тышкы айландыруу менен: array_agg(i::text) / array_agg(i)::text[].
Келгиле, сериалдаштыруунун ар кандай түрлөрүнүн натыйжалуулугун таза синтетикалык мисал менен текшерип көрөлү - ар кандай сандагы баскычтарды сериялаштыруу:
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, ...) i
)
TABLE dict;Баалоо сценарийи: сериялаштыруу
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
TABLE dict
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 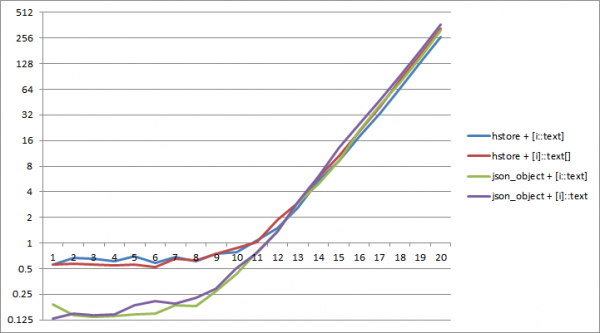
PostgreSQL 11де болжол менен 2^12 баскычтан турган сөздүктүн өлчөмүнө чейин jsonге сериалдаштыруу азыраак убакытты талап кылат. Бул учурда, эң натыйжалуу json_object жана "ички" түрдөгү конверсиянын айкалышы array_agg(i::text).
Эми ар бир ачкычтын маанисин 8 жолу окуганга аракет кылалы - эгер сөздүккө кирбесеңиз, анда ал эмне үчүн керек?
Баалоо сценарийи: сөздүктөн окуу
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
json_object(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
SELECT
(TABLE dict) -> (i % ($$ || (1 << v) || $$) + 1)::text
FROM
generate_series(1, $$ || (1 << (v + 3)) || $$) i
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 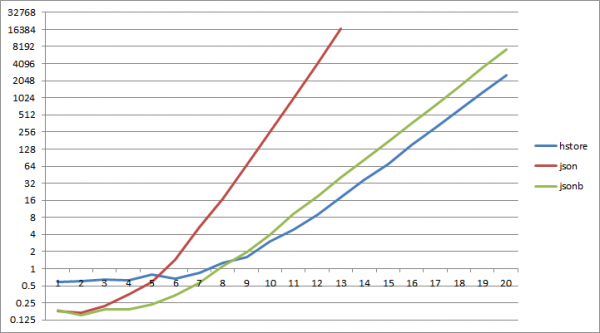
Жана... болжол менен 2^6 баскычтары менен json сөздүгүнөн окуу бир нече жолу жогото баштайт hstoreдон окуу, jsonb үчүн 2^9 да ушундай болот.
Акыркы корутундулар:
- Эгер сиз муну жасашыңыз керек болсо Бир нече кайталануучу жазуулар менен КОШУЛУҢУЗ — таблицанын «сөздүгүн» колдонуу жакшы
- сиздин сөздүгү күтүлгөн болсо кичинекей жана андан көп окуй албайсыз - сиз json[b] колдоно аласыз
- бардык башка учурларда hstore + array_agg(i::text) натыйжалуураак болот
Source: www.habr.com
