

Бул жазуу R - data.table үчүн таблицалуу маалыматтарды иштетүү китепканасын колдонгондор үчүн кызыктуу болот жана ар кандай мисалдарда аны колдонуунун ийкемдүүлүгүн көрүп ыраазы болушу мүмкүн.
жакшы үлгү менен шыктанган , жана сиз анын макаласын окуп чыктыңыз деп үмүттөнүп, мен кодду оптималдаштыруу жана аткарууну тереңдетүүнү сунуштайм. маалымат.стол.
Киришүү: data.table кайдан келет?
Китепкана менен бир аз алыстан, тактап айтканда, data.table объектисин (мындан ары - ДТ) алууга боло турган маалымат структуралары менен таанышууну баштоо эң жакшы.
Array
коду
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Мындай структуралардын бири массив (?base::array). Башка тилдердегидей эле, бул жерде массивдер көп өлчөмдүү. Бирок, кызыктуу нерсе, мисалы, эки өлчөмдүү массив матрицалык класстын касиеттерин мурастай баштайт. (?база::матрица) жана бир өлчөмдүү массив, бул дагы маанилүү, вектордон ((?база::вектор).
Кандайдыр бир объектте камтылган маалыматтардын түрү функцияны колдонуу менен текшерилиши керек экенин түшүнүү керек base::typeof, ылайык ички түр сыпаттамасын кайтарат R Ички - түп нуска менен байланышкан тилдин жалпы протоколу C.
Объекттин классын аныктоо үчүн дагы бир буйрук база::класс, векторлордо, вектор түрүн кайтарат (ал ички түрүнөн аты менен айырмаланат, бирок ошондой эле маалымат түрүн түшүнүүгө мүмкүндүк берет).
тизме
Матрица деп да белгилүү болгон эки өлчөмдүү массивден тизмеге (?base::list).
коду
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Бир эле учурда бир нече нерсе болот:
- Матрицанын экинчи өлчөмү кыйрайт, башкача айтканда, биз бир эле учурда тизмени да, векторду да алабыз.
- Ошентип, тизме бул класстардан мураска калат. Тизме элементи массив матрицасынын уячасынан бир (скаляр) мааниге туура келерин эстен чыгарбоо керек.
Тизме дагы вектор болгондуктан, ага кээ бир вектордук функцияларды колдонсо болот.
Dataframe
Сиз тизмеден, матрицадан же вектордон датафрамга өтсөңүз болот (?base::data.frame).
коду
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Анын эмнеси кызык: dataframe тизмеден мураска алат! Dataframe мамычалары тизме клеткалары. Бул кийинчерээк тизмелерге колдонулган функцияларды колдонгондо маанилүү болот.
маалымат.стол
DT алуу (?data.table::data.table)дан болушу мүмкүн dataframe, тизме, вектор же матрица. Мисалы, ушу сыяктуу (жеринде).
коду
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Датафрайм сыяктуу эле, DT тизменин касиеттерин мурастап алганы пайдалуу.
DT жана эс
R базасындагы бардык башка объекттерден айырмаланып, DT шилтемелер аркылуу өткөрүлөт. Жаңы эстутум аймагына көчүрмөнү жасоо керек болсо, сизге функция керек data.table::copy же эски объекттен тандоо керек.
коду
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Муну менен кириш сөз аяктайт. DT – R-де маалымат структураларынын өнүгүүсүнүн уландысы, ал негизинен dataframe классынын объектилери менен аткарылуучу операциялардын кеңейиши жана тездешинин эсебинен пайда болот. Ошол эле учурда башка примитивдерден тукум куучулук сакталат.
data.table касиеттерин колдонуунун кээ бир мисалдары
Тизме сыяктуу...
Dataframe же DT катарларынын үстүнөн итерациялоо жакшы идея эмес, анткени тилде цикл коду R алда канча жайыраак C, бирок, адатта, бир топ кичине болгон мамычалар аркылуу өтүү толук мүмкүн. Мамычаларды карап жатып, ар бир тилке көбүнчө векторду камтыган тизменин элементи экенин унутпаңыз. Ал эми векторлор боюнча операциялар тилдин негизги функцияларында жакшы векторлоштурулган. Тизмелер жана векторлор үчүн жалпы тандоо операторлорун да колдонсоңуз болот: `[[`, `$`.
коду
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Векторизация
Эгерде чоң ДТ сызыктарынан өтүү зарылчылыгы болсо, эң жакшы чечим векторизация менен функцияны жазуу болмок. Бирок бул иштебесе, анда цикл экенин эстен чыгарбоо керек ичинде DT дагы эле циклден тезирээк R, ал аткарылгандыктан C.
Келгиле, аны 100 миң катар менен чоңураак мисалда сынап көрөлү. Вектордук тилкеге кирген сөздөрдөн биринчи тамганы чыгарабыз w.
UPDATED
коду
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Биринчи саптар боюнча итерациялоону иштетиңиз:
Бирдиги: миллисекунд
expr min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", белгиленген = T))[1]), by = 1:nrow(dt)] } 439.6217
lq орточо uq макс невал
451.9998 460.1593 456.2505 460.9147 621.4042 100
Экинчи ишке киргизүү, мында тизмени матрицага айландыруу жана 1 индекси бар кесимдеги элементтерди алуу аркылуу векторизация ишке ашат (акыркысы векторизациянын өзү). Түзөтүү: функция деңгээлинде векторлоо strsplit, ал векторду киргизүү катары кабыл алат. Көрсө, тизмени матрицага айландыруу процедурасы векторизациянын өзүнө караганда алда канча татаал, бирок бул учурда векторлоштурулбаган версияга караганда бир топ ылдамыраак.
Бирдиги: миллисекунд
expr min lq орточо uq макс невал
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Медиана боюнча ылдамдатуу 3 жолу.
Үчүнчү чуркоо, анда матрицага трансформация схемасы өзгөртүлгөн.
Бирдиги: миллисекунд
expr min lq орточо uq макс невал
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Медиана боюнча ылдамдатуу 13 жолу.
Бул маселе менен эксперимент керек, канчалык көп болсо, ошончолук жакшы болот.
Векторизациянын дагы бир мисалы, мында да текст бар, бирок ал реалдуу шарттарга жакын: сөздөрдүн ар кандай узундугу, ар кандай сөздөрдүн саны. Сиз биринчи 3 сөздү алышыңыз керек. Бул сыяктуу:
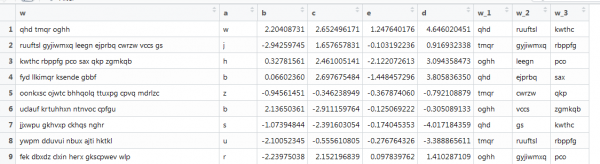
Бул жерде мурунку функция иштебейт, анткени векторлор ар кандай узундукта болгондуктан, биз матрицанын өлчөмүн койдук. Келгиле, муну интернеттен казып кайра жасайлы.
коду
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Бирдиги: миллисекунд
expr min lq орточо медиана
{ dt[, `:=`((paste0("w_", 1:3)), strsplit(w, split = " ", белгиленген = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Сценарий орточо 1 секунд ылдамдыкта иштеди. Жаман эмес.
Бир чынжыр менен байланышкан...
Сиз чынжырчаны колдонуу менен DT объекттери менен иштей аласыз. Бул каша синтаксисин оңго, негизинен кантты тиркөө сыяктуу көрүнөт.
коду
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Түтүктөр аркылуу агып...
Ошол эле операцияларды түтүк аркылуу жасоого болот, ал окшош көрүнөт, бирок функционалдык жактан бай, анткени сиз жөн гана DT эмес, каалаган ыкмаларды колдоно аласыз. Келгиле, DT боюнча бир катар фильтрлер менен синтетикалык маалыматтарыбыз үчүн логистикалык регрессия коэффициенттерин чыгаралы.
коду
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
DT ичиндеги статистика, машина үйрөнүү жана башкалар
Сиз lambda функцияларын колдоно аласыз, бирок кээде аларды өзүнчө түзүп, маалыматтарды талдоо тутумун жазып, андан ары улантыңыз - алар DT ичинде иштешет. Мисал жогоруда көрсөтүлгөн бардык функциялар менен байытылган, ошондой эле DT арсеналынын бир нече пайдалуу нерселери (мисалы, DTдин өзүнө шилтеме аркылуу DTдин ичине кирүү, кээде ырааттуу эмес, бирок ушундай болушу үчүн).
коду
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
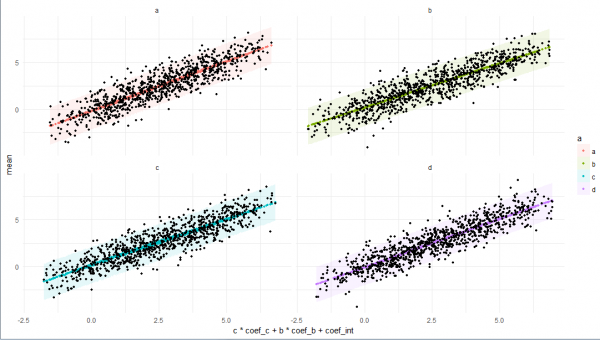
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
жыйынтыктоо
Мен R класстарынан мурастоо менен байланышкан касиеттеринен баштап, тыкан элементтерден өзүнүн өзгөчөлүктөрүнө жана чөйрөсүнө чейин, data.table сыяктуу объекттин толук, бирок, албетте, толук эмес сүрөтүн түзө алдым деп үмүттөнөм. . Бул китепкананы жакшыраак үйрөнүүгө жана жумушта колдонууга жардам берет деп ишенем оюн-зоок.
рахмат!
Толук код
коду
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Source: www.habr.com
