

Šajā rakstā es runāšu par to, kā projekts, pie kura es strādāju, no liela monolīta tika pārveidots par mikropakalpojumu komplektu.
Projekts savu vēsturi sāka diezgan sen, 2000. gada sākumā. Pirmās versijas tika rakstītas Visual Basic 6. Laika gaitā kļuva skaidrs, ka attīstība šajā valodā nākotnē būs grūti atbalstāma, jo IDE un pati valoda ir vāji attīstīta. 2000. gadu beigās tika nolemts pāriet uz daudzsološāko C#. Jaunā versija tika rakstīta paralēli vecās versijas pārskatīšanai, pakāpeniski arvien vairāk kodu tika ierakstīts .NET. C# aizmugure sākotnēji bija vērsta uz pakalpojumu arhitektūru, taču izstrādes laikā tika izmantotas kopīgas bibliotēkas ar loģiku un pakalpojumi tika palaisti vienā procesā. Rezultāts bija lietojumprogramma, ko mēs saucām par "pakalpojuma monolītu".
Viena no nedaudzajām šīs kombinācijas priekšrocībām bija pakalpojumu iespēja zvanīt viens otram, izmantojot ārēju API. Bija skaidri priekšnoteikumi pārejai uz pareizāku servisu un nākotnē mikropakalpojumu arhitektūru.
Mēs sākām darbu pie dekompozīcijas ap 2015. gadu. Mēs vēl neesam sasnieguši ideālu stāvokli - joprojām ir liela projekta daļas, kuras diez vai var saukt par monolītiem, taču tās arī neizskatās pēc mikropakalpojumiem. Tomēr progress ir ievērojams.
Par to es runāšu rakstā.
saturs
Esošā risinājuma arhitektūra un problēmas
Sākotnēji arhitektūra izskatījās šādi: UI ir atsevišķa lietojumprogramma, monolītā daļa ir rakstīta Visual Basic 6, .NET lietojumprogramma ir saistītu pakalpojumu kopums, kas strādā ar diezgan lielu datu bāzi.
Iepriekšējā risinājuma trūkumi
Viens neveiksmes punkts
Mums bija viens neveiksmes punkts: .NET lietojumprogramma darbojās vienā procesā. Ja kāds modulis neizdevās, visa lietojumprogramma neizdevās, un tā bija jārestartē. Tā kā mēs automatizējam lielu skaitu procesu dažādiem lietotājiem, kļūmes dēļ vienā no tiem visi kādu laiku nevarēja strādāt. Un programmatūras kļūdas gadījumā pat dublēšana nepalīdzēja.
Uzlabojumu rinda
Šis trūkums ir diezgan organizatorisks. Mūsu lietojumprogrammai ir daudz klientu, un viņi visi vēlas to uzlabot pēc iespējas ātrāk. Iepriekš to nebija iespējams izdarīt paralēli, un visi klienti stāvēja rindā. Šis process uzņēmējiem bija negatīvs, jo viņiem bija jāpierāda, ka viņu uzdevums ir vērtīgs. Un izstrādes komanda pavadīja laiku, organizējot šo rindu. Tas prasīja daudz laika un pūļu, un galu galā produkts nevarēja mainīties tik ātri, kā viņi būtu vēlējušies.
Neoptimāla resursu izmantošana
Mitinot pakalpojumus vienā procesā, mēs vienmēr pilnībā kopējām konfigurāciju no servera uz serveri. Mēs vēlējāmies visvairāk noslogotos pakalpojumus izvietot atsevišķi, lai netērētu resursus un iegūtu elastīgāku kontroli pār mūsu izvietošanas shēmu.
Grūti ieviest mūsdienu tehnoloģijas
Problēma, kas pazīstama visiem izstrādātājiem: ir vēlme projektā ieviest modernās tehnoloģijas, bet nav iespēju. Izmantojot lielu monolītu risinājumu, jebkurš pašreizējās bibliotēkas atjauninājums, nemaz nerunājot par pāreju uz jaunu, pārvēršas par diezgan netriviālu uzdevumu. Ir nepieciešams ilgs laiks, lai pierādītu komandas vadītājam, ka tas dos vairāk bonusu nekā iztērēti nervi.
Grūtības izdot izmaiņas
Šī bija visnopietnākā problēma — mēs izlaidām ik pēc diviem mēnešiem.
Katrs laidiens bankai kļuva par īstu katastrofu, neskatoties uz izstrādātāju testiem un centieniem. Uzņēmums saprata, ka nedēļas sākumā daļa tā funkcionalitātes nedarbosies. Un izstrādātāji saprata, ka viņus gaida nopietnu incidentu nedēļa.
Ikvienam bija vēlme mainīt situāciju.
Cerības no mikropakalpojumiem
Sastāvdaļu problēma, kad tā ir gatava. Sastāvdaļu piegāde, kad tās ir gatavas, sadalot šķīdumu un atdalot dažādus procesus.
Mazas produktu komandas. Tas ir svarīgi, jo lielu komandu, kas strādāja pie vecā monolīta, bija grūti vadīt. Šāda komanda bija spiesta strādāt pēc stingra procesa, taču viņi vēlējās vairāk radošuma un neatkarības. To varēja atļauties tikai mazas komandas.
Pakalpojumu izolēšana atsevišķos procesos. Ideālā gadījumā es vēlētos to izolēt konteineros, taču liels skaits pakalpojumu, kas rakstīti .NET Framework, darbojas tikai zem WindowsTagad parādās pakalpojumi, kuru pamatā ir .NET Core, taču to joprojām ir maz.
Izvietošanas elastība. Mēs vēlētos apvienot pakalpojumus tā, kā mums tas ir nepieciešams, nevis tā, kā kods to uzspiež.
Jauno tehnoloģiju izmantošana. Tas ir interesanti jebkuram programmētājam.
Pārejas problēmas
Protams, ja monolītu būtu viegli sadalīt mikropakalpojumos, par to nebūtu jārunā konferencēs un jāraksta raksti. Šajā procesā ir daudz nepilnību, es aprakstīšu galvenās, kas mums traucēja.
Pirmā problēma raksturīgs lielākajai daļai monolītu: biznesa loģikas saskaņotība. Kad mēs rakstām monolītu, mēs vēlamies atkārtoti izmantot savas klases, lai nerakstītu nevajadzīgu kodu. Un, pārejot uz mikropakalpojumiem, tā kļūst par problēmu: viss kods ir diezgan cieši savienots, un pakalpojumus ir grūti nodalīt.
Darba uzsākšanas brīdī repozitorijā bija vairāk nekā 500 projektu un vairāk nekā 700 tūkstoši koda rindu. Tas ir diezgan liels lēmums un otrā problēma. Nevarēja vienkārši paņemt un sadalīt mikropakalpojumos.
Trešā problēma — nepieciešamās infrastruktūras trūkums. Faktiski mēs manuāli kopējām avota kodu uz serveriem.
Kā pāriet no monolīta uz mikropakalpojumiem
Mikropakalpojumu nodrošināšana
Pirmkārt, mēs uzreiz paši noteicām, ka mikropakalpojumu atdalīšana ir iteratīvs process. Mums vienmēr tika prasīts paralēli attīstīt biznesa problēmas. Kā mēs to tehniski īstenosim, tā jau ir mūsu problēma. Tāpēc mēs sagatavojāmies iteratīvam procesam. Tas nedarbosies citādi, ja jums ir liela lietojumprogramma un tā sākotnēji nav gatava pārrakstīšanai.
Kādas metodes mēs izmantojam, lai izolētu mikropakalpojumus?
Pirmā metode — pārvietot esošos moduļus kā pakalpojumus. Šajā ziņā mums paveicās: jau bija reģistrēti pakalpojumi, kas darbojās, izmantojot WCF protokolu. Tie tika sadalīti atsevišķās asamblejās. Mēs tos pārnēsājām atsevišķi, katrai būvei pievienojot nelielu palaišanas programmu. Tas tika uzrakstīts, izmantojot brīnišķīgo Topshelf bibliotēku, kas ļauj palaist lietojumprogrammu gan kā pakalpojumu, gan kā konsoli. Tas ir ērti atkļūdošanai, jo risinājumā nav nepieciešami papildu projekti.
Pakalpojumi tika savienoti saskaņā ar biznesa loģiku, jo tie izmantoja kopējus mezglus un strādāja ar kopīgu datu bāzi. Diez vai tos varētu saukt par mikropakalpojumiem tīrā veidā. Taču šos pakalpojumus mēs varētu sniegt atsevišķi, dažādos procesos. Tas vien ļāva samazināt to ietekmi vienam uz otru, samazinot problēmu ar paralēlu attīstību un vienu neveiksmes punktu.
Montāža ar resursdatoru ir tikai viena koda rindiņa Programmas klasē. Mēs slēpām darbu ar Topshelf palīgklasē.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Otrs veids, kā piešķirt mikropakalpojumus, ir: izveidot tos jaunu problēmu risināšanai. Ja tajā pašā laikā monolīts neaug, tas jau ir lieliski, kas nozīmē, ka mēs virzāmies pareizajā virzienā. Lai atrisinātu jaunas problēmas, mēģinājām izveidot atsevišķus pakalpojumus. Ja bija tāda iespēja, tad izveidojām “kanoniskākus” servisus, kas pilnībā pārvalda savu datu modeli, atsevišķu datu bāzi.
Mēs, tāpat kā daudzi, sākām ar autentifikācijas un autorizācijas pakalpojumiem. Tie ir ideāli piemēroti šim nolūkam. Tie ir neatkarīgi, kā likums, tiem ir atsevišķs datu modelis. Viņi paši nesadarbojas ar monolītu, tikai tas vēršas pie viņiem, lai atrisinātu dažas problēmas. Izmantojot šos pakalpojumus, varat sākt pāreju uz jaunu arhitektūru, atkļūdot tajos esošo infrastruktūru, izmēģināt dažas ar tīkla bibliotēkām saistītas pieejas utt. Mūsu organizācijā nav nevienas komandas, kas nevarētu izveidot autentifikācijas pakalpojumu.
Trešais veids, kā piešķirt mikropakalpojumusTas, ko mēs izmantojam, mums ir nedaudz specifisks. Tā ir biznesa loģikas noņemšana no lietotāja interfeisa slāņa. Mūsu galvenā lietotāja saskarnes lietojumprogramma ir darbvirsma; tā, tāpat kā aizmugure, ir rakstīta C#. Izstrādātāji periodiski pieļāva kļūdas un pārsūtīja uz lietotāja saskarni loģikas daļas, kurām vajadzēja pastāvēt aizmugursistēmā un izmantot atkārtoti.
Ja paskatās uz reālu piemēru no UI daļas koda, jūs varat redzēt, ka lielākā daļa šī risinājuma satur reālu biznesa loģiku, kas ir noderīga citos procesos, ne tikai UI veidlapas veidošanā.
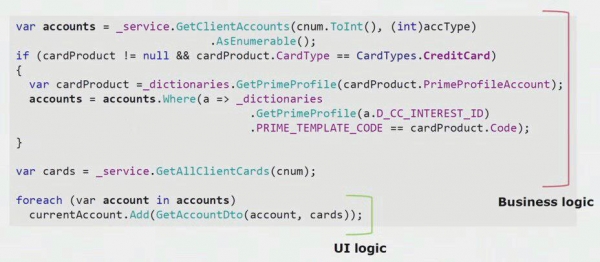
Īstā lietotāja interfeisa loģika ir tikai pēdējās pāris rindiņās. Mēs to pārsūtījām uz serveri, lai to varētu izmantot atkārtoti, tādējādi samazinot lietotāja interfeisu un panākot pareizo arhitektūru.
Ceturtais un vissvarīgākais veids, kā izolēt mikropakalpojumus, kas ļauj samazināt monolītu, ir esošo pakalpojumu noņemšana ar apstrādi. Ja mēs izņemam esošos moduļus tādus, kādi tie ir, rezultāts ne vienmēr atbilst izstrādātājiem, un biznesa process var būt novecojis kopš funkcionalitātes izveides. Izmantojot pārstrukturēšanu, mēs varam atbalstīt jaunu biznesa procesu, jo biznesa prasības pastāvīgi mainās. Mēs varam uzlabot avota kodu, novērst zināmos defektus un izveidot labāku datu modeli. Uzkrāsies daudz priekšrocību.
Pakalpojumu nodalīšana no apstrādes ir nesaraujami saistīta ar ierobežota konteksta jēdzienu. Šī ir domēna vadīta dizaina koncepcija. Tas nozīmē domēna modeļa sadaļu, kurā visi vienas valodas termini ir unikāli definēti. Apskatīsim apdrošināšanas un rēķinu konteksta piemēru. Mums ir monolīta lietojumprogramma, un mums ir jāstrādā ar kontu apdrošināšanā. Mēs sagaidām, ka izstrādātājs atradīs esošu konta klasi citā komplektā, atsaucēs uz to no apdrošināšanas klases, un mums būs darba kods. Tiks ievērots DRY princips, uzdevums tiks paveikts ātrāk, izmantojot esošo kodu.
Rezultātā izrādās, ka kontu un apdrošināšanas konteksti ir saistīti. Parādoties jaunām prasībām, šī sakabe traucēs attīstībai, palielinot jau tā sarežģītās biznesa loģikas sarežģītību. Lai atrisinātu šo problēmu, kodā jāatrod robežas starp kontekstiem un jānovērš to pārkāpumi. Piemēram, apdrošināšanas kontekstā pilnīgi iespējams, ka pietiks ar 20 ciparu Centrālās bankas konta numuru un konta atvēršanas datumu.
Lai atdalītu šos ierobežotos kontekstus vienu no otra un sāktu mikropakalpojumu atdalīšanas procesu no monolīta risinājuma, mēs izmantojām tādu pieeju kā ārējo API izveidošana lietojumprogrammā. Ja mēs zinājām, ka kādam modulim ir jākļūst par mikropakalpojumu, kaut kā modificētam procesa gaitā, tad ar ārējiem izsaukumiem nekavējoties izsaucām loģiku, kas pieder citam ierobežotam kontekstam. Piemēram, izmantojot REST vai WCF.
Mēs stingri nolēmām, ka neizvairīsimies no koda, kas prasīs izplatītus darījumus. Mūsu gadījumā izrādījās, ka ir diezgan viegli ievērot šo noteikumu. Mēs vēl neesam saskārušies ar situācijām, kad patiešām būtu nepieciešamas stingri sadalītas transakcijas - galīgā konsekvence starp moduļiem ir diezgan pietiekama.
Apskatīsim konkrētu piemēru. Mums ir orķestra jēdziens — konveijera, kas apstrādā “lietojumprogrammas” entītiju. Viņš pēc kārtas izveido klientu, kontu un bankas karti. Ja klients un konts ir izveidots veiksmīgi, bet kartes izveide neizdodas, lietojumprogramma nepāriet uz “veiksmīga” statusu un paliek “karte nav izveidota” statusā. Turpmāk fona darbības to uztvers un pabeigs. Sistēma jau kādu laiku ir bijusi nekonsekvences stāvoklī, taču kopumā esam apmierināti ar to.
Ja radīsies situācija, kad ir nepieciešams konsekventi saglabāt daļu datu, visticamāk, dosimies uz pakalpojuma konsolidāciju, lai to apstrādātu vienā procesā.
Apskatīsim mikropakalpojuma piešķiršanas piemēru. Kā to var salīdzinoši droši nogādāt ražošanā? Šajā piemērā mums ir atsevišķa sistēmas daļa - algas apkalpošanas modulis, kura vienu no koda sadaļām vēlamies izveidot mikroservisu.
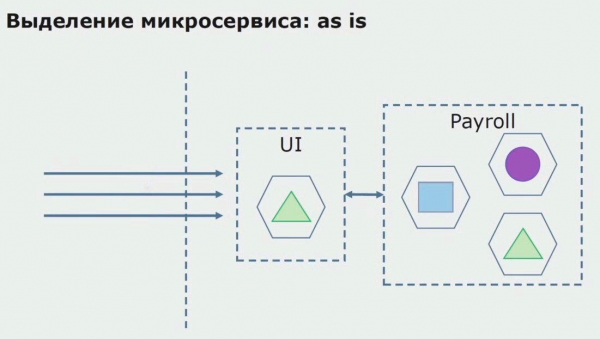
Pirmkārt, mēs izveidojam mikropakalpojumu, pārrakstot kodu. Mēs uzlabojam dažus aspektus, ar kuriem mēs nebijām apmierināti. Mēs ieviešam jaunas biznesa prasības no klienta puses. Mēs pievienojam API vārteju savienojumam starp UI un aizmugursistēmu, kas nodrošinās zvanu pāradresāciju.
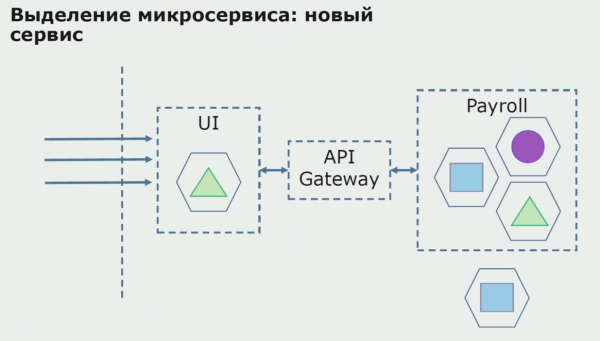
Pēc tam mēs laižam šo konfigurāciju ekspluatācijā, bet izmēģinājuma stāvoklī. Lielākā daļa mūsu lietotāju joprojām strādā ar veciem biznesa procesiem. Jaunajiem lietotājiem mēs izstrādājam jaunu monolītās lietojumprogrammas versiju, kurā vairs nav šī procesa. Būtībā mums ir monolīta un mikropakalpojuma kombinācija, kas darbojas kā pilots.
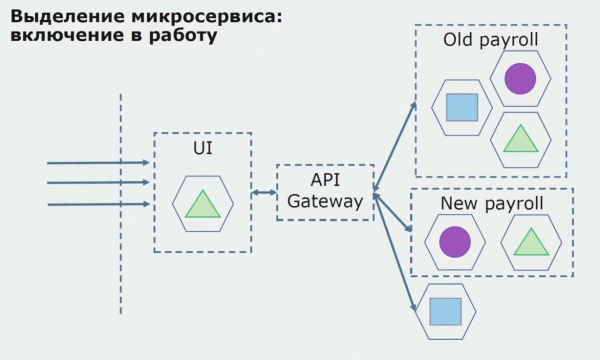
Ar veiksmīgu izmēģinājuma versiju mēs saprotam, ka jaunā konfigurācija patiešām ir funkcionāla, mēs varam noņemt veco monolītu no vienādojuma un atstāt jauno konfigurāciju vecā risinājuma vietā.
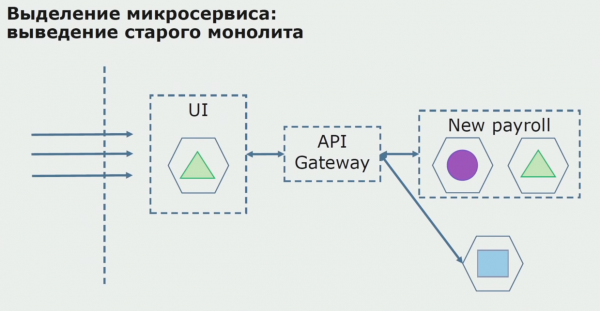
Kopumā mēs izmantojam gandrīz visas esošās metodes monolīta avota koda sadalīšanai. Visi no tiem ļauj mums samazināt lietojumprogrammas daļu lielumu un pārtulkot tās jaunās bibliotēkās, padarot labāku pirmkodu.
Darbs ar datu bāzi
Datu bāzi var sadalīt sliktāk nekā avota kodu, jo tajā ir ne tikai pašreizējā shēma, bet arī uzkrātie vēsturiskie dati.
Mūsu datubāzei, tāpat kā daudzām citām, bija vēl viens būtisks trūkums - tās milzīgais izmērs. Šī datu bāze tika veidota saskaņā ar sarežģīto monolīta biznesa loģiku un attiecībām, kas uzkrātas starp dažādu ierobežotu kontekstu tabulām.
Mūsu gadījumā, lai papildinātu visas nepatikšanas (liela datu bāze, daudzi savienojumi, dažreiz neskaidras robežas starp tabulām), radās problēma, kas rodas daudzos lielos projektos: koplietotās datu bāzes veidnes izmantošana. Dati tika ņemti no tabulām caur skatu, izmantojot replikāciju un nosūtīti uz citām sistēmām, kur šī replikācija bija nepieciešama. Tā rezultātā mēs nevarējām pārvietot tabulas atsevišķā shēmā, jo tās tika aktīvi izmantotas.
Tas pats iedalījums ierobežotos kontekstos kodā palīdz mums atdalīties. Tas parasti sniedz mums diezgan labu priekšstatu par to, kā mēs sadalām datus datu bāzes līmenī. Mēs saprotam, kuras tabulas pieder vienam ierobežotam kontekstam un kuras citam.
Mēs izmantojām divas globālas datu bāzes sadalīšanas metodes: esošo tabulu sadalīšanu un sadalīšanu ar apstrādi.
Esošo tabulu sadalīšana ir laba metode, ko izmantot, ja datu struktūra ir laba, atbilst biznesa prasībām un visi ir ar to apmierināti. Šajā gadījumā esošās tabulas varam atdalīt atsevišķā shēmā.
Nodaļa ar apstrādi ir vajadzīga, kad biznesa modelis ir ļoti mainījies, un tabulas mūs vairs neapmierina.
Esošo tabulu sadalīšana. Mums ir jānosaka, ko mēs atdalīsim. Bez šīm zināšanām nekas nedarbosies, un šeit mums palīdzēs ierobežoto kontekstu atdalīšana kodā. Parasti, ja jūs varat saprast kontekstu robežas avota kodā, kļūst skaidrs, kuras tabulas jāiekļauj nodaļas sarakstā.
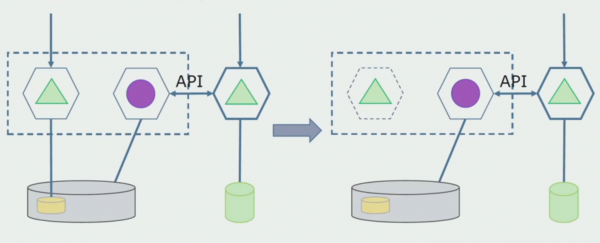
Iedomāsimies, ka mums ir risinājums, kurā divi monolīti moduļi mijiedarbojas ar vienu datu bāzi. Mums ir jāpārliecinās, ka tikai viens modulis mijiedarbojas ar atdalīto tabulu sadaļu, bet otrs sāk mijiedarboties ar to, izmantojot API. Sākumā pietiek ar to, ka caur API tiek veikta tikai ierakstīšana. Tas ir nepieciešams nosacījums, lai mēs varētu runāt par mikropakalpojumu neatkarību. Lasīšanas savienojumi var saglabāties tik ilgi, kamēr nav lielu problēmu.
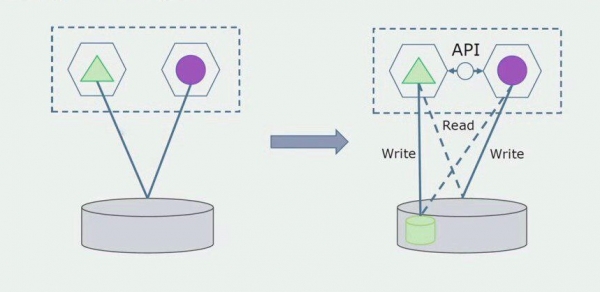
Nākamais solis ir tas, ka mēs varam atdalīt koda sadaļu, kas darbojas ar atdalītām tabulām, ar vai bez apstrādes, atsevišķā mikropakalpojumā un palaist to atsevišķā procesā, konteinerā. Tas būs atsevišķs pakalpojums ar savienojumu ar monolītu datu bāzi un tām tabulām, kas ar to tieši neattiecas. Monolīts joprojām mijiedarbojas lasīšanai ar noņemamo daļu.
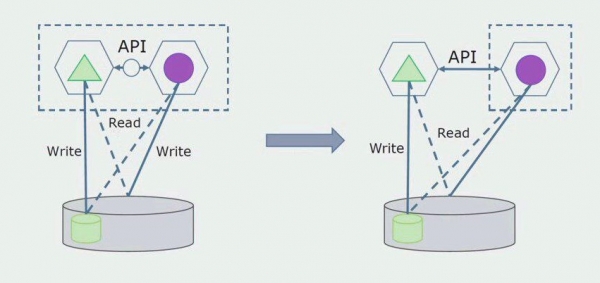
Vēlāk mēs noņemsim šo savienojumu, tas ir, datu nolasīšana no monolītās lietojumprogrammas no atdalītām tabulām tiks pārsūtīta arī uz API.
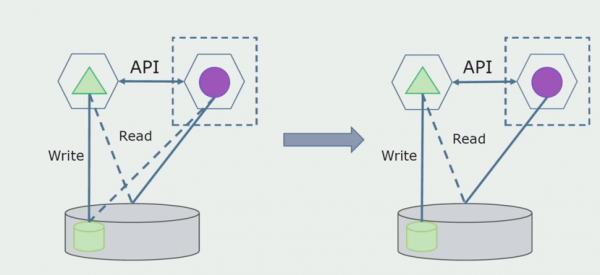
Tālāk no vispārējās datu bāzes atlasīsim tabulas, ar kurām strādā tikai jaunais mikropakalpojums. Mēs varam pārvietot tabulas uz atsevišķu shēmu vai pat uz atsevišķu fizisku datu bāzi. Joprojām ir lasīšanas savienojums starp mikroservisu un monolītu datu bāzi, taču nav par ko uztraukties, šādā konfigurācijā tā var dzīvot diezgan ilgu laiku.
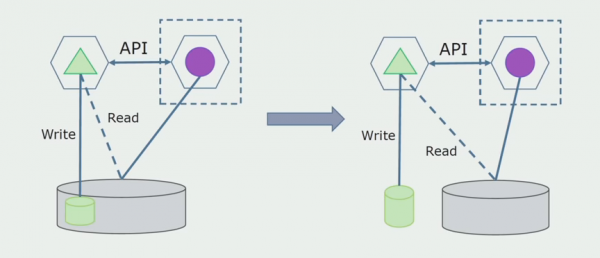
Pēdējais solis ir pilnībā noņemt visus savienojumus. Šādā gadījumā mums var būt nepieciešams migrēt datus no galvenās datu bāzes. Dažreiz mēs vēlamies atkārtoti izmantot dažus datus vai direktorijus, kas replicēti no ārējām sistēmām vairākās datu bāzēs. Pie mums tas notiek periodiski.
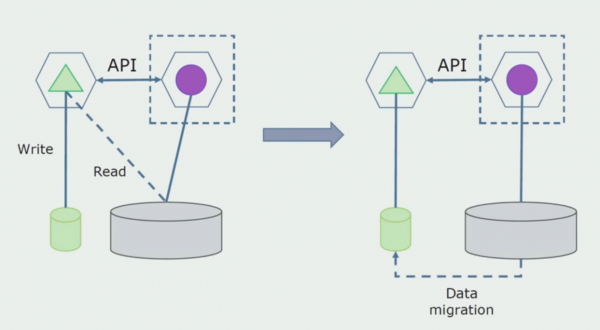
Apstrādes nodaļa. Šī metode ir ļoti līdzīga pirmajai, tikai apgrieztā secībā. Mēs nekavējoties piešķiram jaunu datu bāzi un jaunu mikropakalpojumu, kas mijiedarbojas ar monolītu, izmantojot API. Bet tajā pašā laikā paliek datu bāzes tabulu kopa, kuru mēs vēlamies dzēst nākotnē. Mums tas vairs nav vajadzīgs; mēs to nomainījām jaunajā modelī.
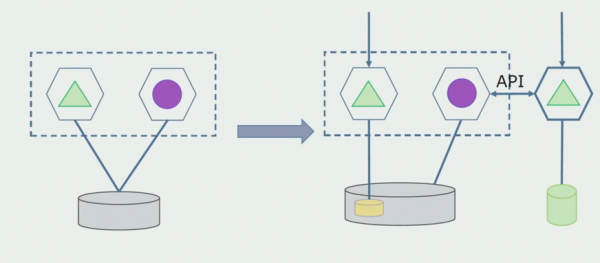
Lai šī shēma darbotos, mums, visticamāk, būs nepieciešams pārejas periods.
Tad ir divas iespējamās pieejas.
Pirmais: mēs dublējam visus datus jaunajā un vecajā datubāzē. Šajā gadījumā mums ir datu dublēšana un var rasties sinhronizācijas problēmas. Bet mēs varam uzņemt divus dažādus klientus. Viens darbosies ar jauno versiju, otrs ar veco.
Otrais: mēs sadalām datus pēc dažiem biznesa kritērijiem. Piemēram, mums sistēmā bija 5 produkti, kas tika saglabāti vecajā datu bāzē. Sesto ievietojam jaunā biznesa uzdevuma ietvaros jaunā datu bāzē. Bet mums būs nepieciešama API vārteja, kas sinhronizēs šos datus un parādīs klientam, no kurienes un ko iegūt.
Abas pieejas darbojas, izvēlieties atkarībā no situācijas.
Kad esam pārliecināti, ka viss darbojas, monolīta daļu, kas darbojas ar vecām datu bāzes struktūrām, var atspējot.
Pēdējais solis ir noņemt vecās datu struktūras.
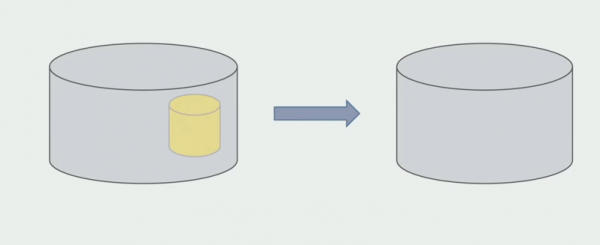
Rezumējot, varam teikt, ka mums ir problēmas ar datu bāzi: ar to ir grūti strādāt, salīdzinot ar avota kodu, grūtāk koplietot, bet to var un vajag darīt. Mēs esam atraduši dažus veidus, kas ļauj to izdarīt diezgan droši, taču joprojām ir vieglāk kļūdīties ar datiem, nevis ar pirmkodu.
Darbs ar pirmkodu
Šādi izskatījās pirmkoda diagramma, kad sākām analizēt monolītu projektu.
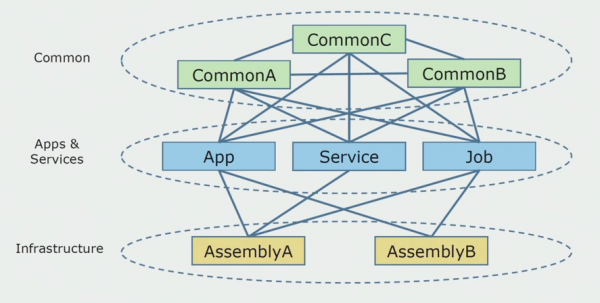
To var aptuveni sadalīt trīs slāņos. Šis ir palaistu moduļu, spraudņu, pakalpojumu un atsevišķu darbību slānis. Faktiski tie bija ieejas punkti monolītā risinājumā. Visi tie bija cieši noslēgti ar kopējo slāni. Tam bija biznesa loģika, ko pakalpojumi koplietoja, un daudz savienojumu. Katrs pakalpojums un spraudnis izmantoja līdz pat 10 vai vairāk izplatītu komplektu atkarībā no to lieluma un izstrādātāju sirdsapziņas.
Mums paveicās ar infrastruktūras bibliotēkām, kuras varēja izmantot atsevišķi.
Dažkārt radās situācija, kad daži kopīgi objekti faktiski nepiederēja šim slānim, bet bija infrastruktūras bibliotēkas. Tas tika atrisināts, pārdēvējot.
Vislielākās bažas radīja ierobežotie konteksti. Gadījās, ka 3-4 konteksti tika sajaukti vienā kopējā komplektācijā un viens otru izmantoja vienās un tajās pašās biznesa funkcijās. Bija jāsaprot, kur to var sadalīt un pa kādām robežām, un ko darīt tālāk, kartējot šo sadalījumu avota koda komplektos.
Mēs esam formulējuši vairākus noteikumus koda sadalīšanas procesam.
Pirmais: mēs vairs nevēlējāmies koplietot biznesa loģiku starp pakalpojumiem, darbībām un spraudņiem. Mēs vēlējāmies padarīt biznesa loģiku neatkarīgu mikropakalpojumos. No otras puses, mikropakalpojumi ideālā gadījumā tiek uzskatīti par pakalpojumiem, kas pastāv pilnīgi neatkarīgi. Uzskatu, ka šāda pieeja ir zināmā mērā izšķērdīga un grūti panākama, jo, piemēram, servisi C# valodā jebkurā gadījumā tiks savienoti ar standarta bibliotēku. Mūsu sistēma ir rakstīta C#, citas tehnoloģijas mēs vēl neesam izmantojuši. Tāpēc nolēmām, ka varam atļauties izmantot kopīgus tehniskos mezglus. Galvenais, lai tie nesatur nekādus biznesa loģikas fragmentus. Ja jūsu izmantotajam ORM ir ērts iesaiņojums, tā kopēšana no pakalpojuma uz pakalpojumu ir ļoti dārga.
Mūsu komanda ir domēna virzīta dizaina cienītāja, tāpēc sīpolu arhitektūra mums bija lieliski piemērota. Mūsu pakalpojumu pamatā ir nevis datu piekļuves slānis, bet gan komplekss ar domēna loģiku, kas satur tikai biznesa loģiku un nav saistīts ar infrastruktūru. Tajā pašā laikā mēs varam neatkarīgi modificēt domēna komplektu, lai atrisinātu ar ietvariem saistītas problēmas.
Šajā posmā mēs saskārāmies ar savu pirmo nopietno problēmu. Pakalpojumam bija jāatsaucas uz vienu domēna komplektu, mēs vēlējāmies padarīt loģiku neatkarīgu, un DRY princips mums šeit ļoti traucēja. Izstrādātāji vēlējās atkārtoti izmantot klases no blakus esošajiem kompleksiem, lai izvairītos no dublēšanās, un rezultātā domēni atkal sāka saistīt kopā. Mēs analizējām rezultātus un nolēmām, ka, iespējams, problēma ir arī avota koda atmiņas ierīces jomā. Mums bija liels repozitorijs, kurā bija viss avota kods. Visa projekta risinājumu bija ļoti grūti salikt vietējā mašīnā. Tāpēc projekta daļām tika izveidoti atsevišķi mazi risinājumi, un neviens neaizliedza tiem pievienot kādu kopīgu vai domēna komplektāciju un izmantot atkārtoti. Vienīgais rīks, kas mums neļāva to izdarīt, bija koda pārskatīšana. Bet dažreiz tas arī neizdevās.
Pēc tam mēs sākām pāriet uz modeli ar atsevišķām krātuvēm. Biznesa loģika vairs neplūst no pakalpojuma uz pakalpojumu, domēni ir patiesi kļuvuši neatkarīgi. Ierobežoti konteksti tiek atbalstīti skaidrāk. Kā mēs atkārtoti izmantojam infrastruktūras bibliotēkas? Mēs tos sadalījām atsevišķā repozitorijā, pēc tam ievietojām Nuget pakotnēs, kuras ievietojām artifactory. Veicot jebkādas izmaiņas, montāža un publicēšana notiek automātiski.
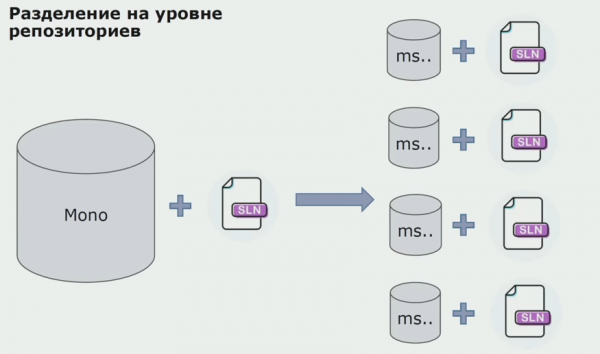
Mūsu pakalpojumi sāka atsaukties uz iekšējām infrastruktūras pakotnēm tāpat kā uz ārējām. Mēs lejupielādējam ārējās bibliotēkas no Nuget. Lai strādātu ar Artifactory, kur ievietojām šīs pakotnes, mēs izmantojām divus pakotņu pārvaldniekus. Mazajās krātuvēs mēs izmantojām arī Nuget. Repozitorijās ar vairākiem pakalpojumiem mēs izmantojām Paket, kas nodrošina lielāku versiju konsekvenci starp moduļiem.
Tādējādi, strādājot pie pirmkoda, nedaudz mainot arhitektūru un atdalot repozitorijus, mēs padarām savus pakalpojumus neatkarīgākus.
Infrastruktūras problēmas
Lielākā daļa negatīvo aspektu, kas saistīti ar pāreju uz mikropakalpojumiem, ir saistīti ar infrastruktūru. Jums būs nepieciešama automatizēta izvietošana, jums būs nepieciešamas jaunas bibliotēkas, lai palaistu infrastruktūru.
Manuāla uzstādīšana vidēs
Sākotnēji risinājumu vidēm uzstādījām manuāli. Lai automatizētu šo procesu, mēs izveidojām CI/CD konveijeru. Mēs izvēlējāmies nepārtrauktas piegādes procesu, jo nepārtraukta izvietošana mums vēl nav pieņemama no biznesa procesu viedokļa. Tāpēc nosūtīšana darbībai tiek veikta, izmantojot pogu, un pārbaudei - automātiski.
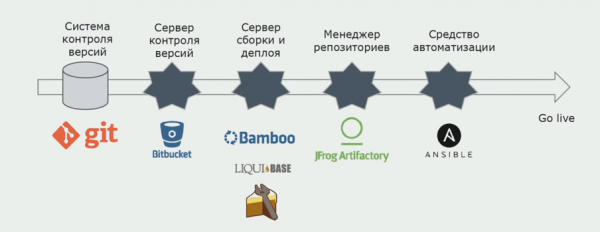
Mēs izmantojam Atlassian, Bitbucket pirmkoda glabāšanai un Bamboo būvēšanai. Mums patīk rakstīt veidošanas skriptus programmā Cake, jo tas ir tas pats, kas C#. Gatavās pakotnes nonāk Artifactory, un Ansible automātiski nokļūst testa serveros, pēc tam tās var nekavējoties pārbaudīt.
Atsevišķa mežizstrāde
Savulaik viena no monolīta idejām bija nodrošināt kopīgu mežizstrādi. Mums arī bija jāsaprot, ko darīt ar atsevišķiem diskos esošajiem žurnāliem. Mūsu žurnāli tiek ierakstīti teksta failos. Mēs nolēmām izmantot standarta ELK kaudzi. Mēs nerakstījām ELK tieši caur pakalpojumu sniedzējiem, bet nolēmām, ka modificēsim teksta žurnālus un ierakstīsim tajos izsekošanas ID kā identifikatoru, pievienojot pakalpojuma nosaukumu, lai vēlāk šos žurnālus varētu parsēt.
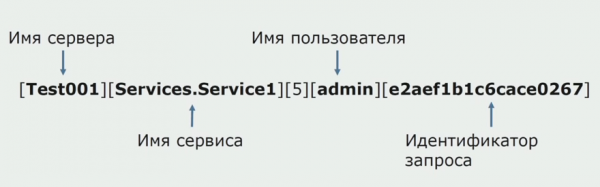
Ar Filebeat mēs varam apkopot žurnālus no serveriem, pēc tam pārveidojiet tos, izmantojiet Kibana, lai lietotāja saskarnē veidotu vaicājumus, un skatiet, kā zvans tika novirzīts starp pakalpojumiem. Šim nolūkam ļoti noderīgi ir izsekošanas ID.
Ar testēšanu un atkļūdošanu saistīti pakalpojumi
Sākotnēji mēs pilnībā nesapratām, kā atkļūdot pakalpojumus, kas tiek izstrādāti. Ar monolītu viss bija vienkārši; mēs to izmantojām vietējā mašīnā. Sākumā viņi mēģināja darīt to pašu ar mikropakalpojumiem, taču dažreiz, lai pilnībā palaistu vienu mikropakalpojumu, ir jāpalaiž vairāki citi, un tas ir neērti. Mēs sapratām, ka mums ir jāpāriet uz modeli, kurā vietējā mašīnā atstājam tikai pakalpojumu vai pakalpojumus, kurus vēlamies atkļūdot. Pārējie pakalpojumi tiek izmantoti no serveriem, kas atbilst konfigurācijai ar prod. Pēc atkļūdošanas, testēšanas laikā katram uzdevumam testa serverim tiek izsniegti tikai mainītie pakalpojumi. Tādējādi risinājums tiek testēts tādā formā, kādā tas nākotnē parādīsies ražošanā.
Ir serveri, kuros darbojas tikai pakalpojumu ražošanas versijas. Šie serveri ir nepieciešami incidentu gadījumā, lai pārbaudītu piegādi pirms izvietošanas un lai veiktu iekšējo apmācību.
Mēs esam pievienojuši automatizētu testēšanas procesu, izmantojot populāro Specflow bibliotēku. Testi tiek veikti automātiski, izmantojot NUnit tūlīt pēc izvietošanas no Ansible. Ja uzdevumu pārklājums ir pilnībā automātisks, manuāla pārbaude nav nepieciešama. Lai gan dažreiz joprojām ir nepieciešama papildu manuāla pārbaude. Mēs izmantojam Jira tagus, lai noteiktu, kuri testi jāveic konkrētai problēmai.
Turklāt ir pieaugusi nepieciešamība pēc slodzes testēšanas, iepriekš tā tika veikta tikai retos gadījumos. Mēs izmantojam JMeter, lai palaistu testus, InfluxDB, lai tos saglabātu, un Grafana, lai izveidotu procesa grafikus.
Ko esam sasnieguši?
Pirmkārt, mēs atbrīvojāmies no jēdziena “atbrīvošana”. Ir pagājuši divu mēnešu milzīgie izlaidumi, kad šis koloss tika izvietots ražošanas vidē, īslaicīgi traucējot biznesa procesus. Tagad mēs izvietojam pakalpojumus vidēji ik pēc 1,5 dienām, grupējot tos, jo tie tiek nodoti ekspluatācijā pēc apstiprināšanas.
Mūsu sistēmā nav fatālu kļūmju. Ja mēs izlaidīsim mikropakalpojumu ar kļūdu, ar to saistītā funkcionalitāte tiks bojāta, un visas pārējās funkcionalitātes netiks ietekmētas. Tas ievērojami uzlabo lietotāja pieredzi.
Mēs varam kontrolēt izvietošanas modeli. Ja nepieciešams, varat atlasīt pakalpojumu grupas atsevišķi no pārējā risinājuma.
Turklāt mēs esam ievērojami samazinājuši problēmu ar lielu uzlabojumu rindu. Tagad mums ir atsevišķas produktu komandas, kas ar dažiem pakalpojumiem strādā neatkarīgi. Scrum process jau šeit ir piemērots. Konkrētai komandai var būt atsevišķs produkta īpašnieks, kas tai piešķir uzdevumus.
Kopsavilkums
- Mikropakalpojumi ir labi piemēroti sarežģītu sistēmu sadalīšanai. Šajā procesā mēs sākam saprast, kas ir mūsu sistēmā, kādi ir ierobežoti konteksti, kur ir to robežas. Tas ļauj pareizi sadalīt uzlabojumus starp moduļiem un novērst koda sajaukšanu.
- Mikropakalpojumi sniedz organizatoriskas priekšrocības. Par tiem bieži runā tikai kā par arhitektūru, taču jebkura arhitektūra ir nepieciešama biznesa vajadzību risināšanai, nevis pati par sevi. Līdz ar to varam teikt, ka mikropakalpojumi ir labi piemēroti problēmu risināšanai mazās komandās, ņemot vērā, ka šobrīd Scrum ir ļoti populārs.
- Atdalīšana ir iteratīvs process. Jūs nevarat paņemt pieteikumu un vienkārši sadalīt to mikropakalpojumos. Iegūtais produkts, visticamāk, nebūs funkcionāls. Piešķirot mikropakalpojumus, ir izdevīgi pārrakstīt esošo mantojumu, tas ir, pārvērst to par kodu, kas mums patīk un labāk atbilst biznesa vajadzībām funkcionalitātes un ātruma ziņā.
Neliels brīdinājums: Izmaksas, pārejot uz mikropakalpojumiem, ir diezgan ievērojamas. Lai vienatnē atrisinātu infrastruktūras problēmu, bija nepieciešams ilgs laiks. Tātad, ja jums ir neliela lietojumprogramma, kurai nav nepieciešama īpaša mērogošana, ja vien jums nav liels klientu skaits, kas sacenšas par jūsu komandas uzmanību un laiku, mikropakalpojumi var nebūt tie, kas jums šodien ir nepieciešami. Tas ir diezgan dārgi. Ja procesu sāksi ar mikropakalpojumiem, tad izmaksas sākotnēji būs lielākas nekā tad, ja tādu pašu projektu uzsāksi ar monolīta izstrādi.
PS Emocionālāks stāsts (un it kā jums personīgi) - saskaņā ar .
Šeit ir pilna ziņojuma versija.
Avots: www.habr.com
