

Sveiki! Mani sauc Danils Lipovojs, un mūsu Sbertech komanda ir sākusi izmantot HBase kā operatīvu datu noliktavu. To pētot, esam uzkrājuši vērtīgu pieredzi, ko vēlējāmies sistematizēt un aprakstīt (ceram, ka tas daudziem noderēs). Visi tālāk minētie eksperimenti tika veikti ar HBase versijām 1.2.0-cdh5.14.2 un 2.0.0-cdh6.0.0-beta1.
- Vispārējā arhitektūra
- Datu rakstīšana HBASE
- Datu lasīšana no HBASE
- Datu kešatmiņa
- MultiGet/MultiPut pakešdatu apstrāde
- Tabulu sadalīšanas reģionos (sadalīšanas) stratēģija
- Kļūmju tolerance, kompaktums un datu lokalizācija
- Iestatījumi un veiktspēja
- Stresa testēšana
- Atzinumi
1. Vispārīgā arhitektūra
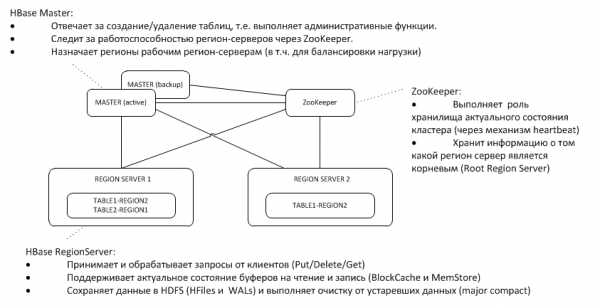
Rezerves galvenais serveris klausās aktīvā ZooKeeper sirdsdarbību mezglā un pārņem galvenā servera funkcijas tā pazušanas gadījumā.
2. Datu rakstīšana HBASE platformā
Vispirms aplūkosim vienkāršāko gadījumu: atslēgas-vērtības objekta ierakstīšanu tabulā, izmantojot put(rowkey). Klientam vispirms ir jānosaka saknes reģiona servera (RRS) atrašanās vieta, kurā tiek glabāta hbase:meta tabula. Šo informāciju tas iegūst no ZooKeeper. Pēc tam tas piekļūst RRS un nolasa hbase:meta tabulu, no kuras tas iegūst informāciju par to, kurš reģiona serveris (RS) ir atbildīgs par datu glabāšanu konkrētajai rindas atslēgai interesējošajā tabulā. Turpmākai lietošanai metatabulu klients saglabā kešatmiņā, tāpēc turpmākās piekļuves ir ātrākas un notiek tieši pie RS.
Saņemot pieprasījumu, RS vispirms to ieraksta WriteAheadLog (WAL), kas ir nepieciešams atkopšanai avārijas gadījumā. Pēc tam dati tiek saglabāti MemStore — atmiņas buferī, kurā ir sakārtots atslēgu kopums noteiktam reģionam. Tabulu var sadalīt reģionos (nodalījumos), katrā no kuriem ir atdalīts atslēgu kopums. Tas ļauj sasniegt lielāku veiktspēju, novietojot reģionus dažādos serveros. Tomēr, neskatoties uz šo acīmredzamo apgalvojumu, mēs vēlāk redzēsim, ka tas nedarbojas visos gadījumos.
Pēc ieraksta ievietošanas MemStore, klients saņem atbildi, kas norāda, ka ieraksts ir veiksmīgi saglabāts. Tomēr ieraksts faktiski tiek saglabāts tikai buferī un tiks ierakstīts diskā tikai pēc noteikta laika perioda vai tad, kad buferis būs piepildīts ar jauniem datiem.
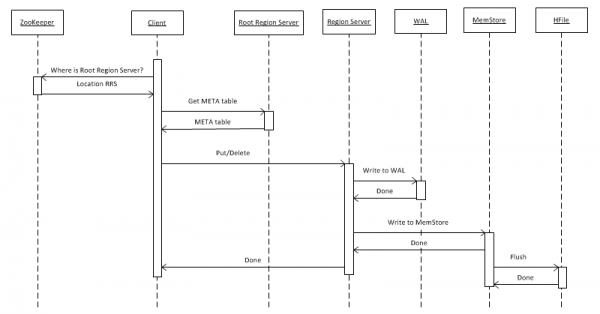
Veicot darbību "Dzēst", dati fiziski netiek dzēsti. Tie vienkārši tiek atzīmēti kā dzēsti, un pati iznīcināšana notiek, kad tiek izsaukta galvenā kompaktā funkcija, kas sīkāk aprakstīta 7. sadaļā.
HFile formāta faili tiek uzkrāti HDFS formātā, un laiku pa laikam tiek palaists neliels saspiešanas process, kas vienkārši apvieno mazus failus lielākos, neko neizdzēšot. Laika gaitā tā kļūst par problēmu, kas izpaužas tikai datu lasīšanas laikā (pie tā mēs atgriezīsimies vēlāk).
Papildus iepriekš aprakstītajam ielādes procesam ir daudz efektīvāka procedūra, kas, iespējams, ir šīs datubāzes spēcīgākā iezīme: BulkLoad. Tā ietver manuālu HFile failu izveidi un ielādi diskā, nodrošinot lielisku mērogojamību un sasniedzot diezgan cienījamu ātrumu. Būtībā ierobežojums šeit nav HBase, bet gan aparatūras iespējas. Zemāk ir ielādes rezultāti klasterī, kas sastāv no 16 RegionServers un 16 YARN NodeManager (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 pavedieni), HBase versija 1.2.0-cdh5.14.2.
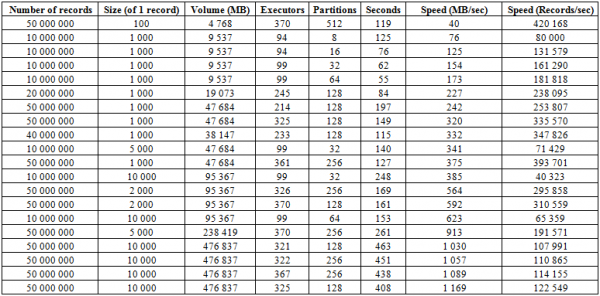
Šeit mēs redzam, ka, palielinot nodalījumu (reģionu) skaitu tabulā, kā arī Spark izpildītāju skaitu, palielinās ielādes ātrums. Ātrums ir atkarīgs arī no rakstīšanas apjoma. Lieli bloki nodrošina pieaugumu MB/sek., savukārt mazi bloki nodrošina ievietoto ierakstu skaita pieaugumu laika vienībā, visiem pārējiem faktoriem esot nemainīgiem.
Varat arī vienlaikus ielādēt divas tabulas, lai dubultotu ātrumu. Zemāk varat redzēt, ka 10 KB bloku ierakstīšana divās tabulās vienlaikus notiek ar aptuveni 600 MB/s katra (kopā 1275 MB/s), kas ir tāds pats kā ierakstīšana vienā tabulā ar ātrumu 623 MB/s (skatiet iepriekš 11. punktu).

Otrais mēģinājums ar 50 KB ierakstiem parāda, ka ielādes ātrums palielinās tikai nedaudz, norādot, ka tuvojas maksimālās vērtības. Ir svarīgi paturēt prātā, ka pati HBASE šeit praktiski netiek noslogota. Viss, kas tai jādara, ir vispirms izgūt datus no hbase:meta, pēc tam, dublējot HFiles, iztīrīt BlockCache datus un saglabāt MemStore buferi diskā, ja tā nav tukša.
3. Datu lasīšana no HBASE
Pieņemot, ka visa informācija no hbase:meta klientam jau ir pieejama (sk. 2. punktu), pieprasījums nonāk tieši pie RS, kur tiek glabāta nepieciešamā atslēga. Meklēšana vispirms tiek veikta MemCache. Neatkarīgi no tā, vai dati tur atrodas, meklēšana tiek veikta arī BlockCache buferī un, ja nepieciešams, HFiles. Ja dati tiek atrasti failā, tie tiek ievietoti BlockCache un tiks atgriezti ātrāk nākamajā pieprasījumā. Meklēšana HFile ir samērā ātra, pateicoties Bloom filtra izmantošanai; pēc neliela datu apjoma nolasīšanas tas nekavējoties nosaka, vai failā ir nepieciešamā atslēga, un, ja nē, tas pāriet uz nākamo failu.
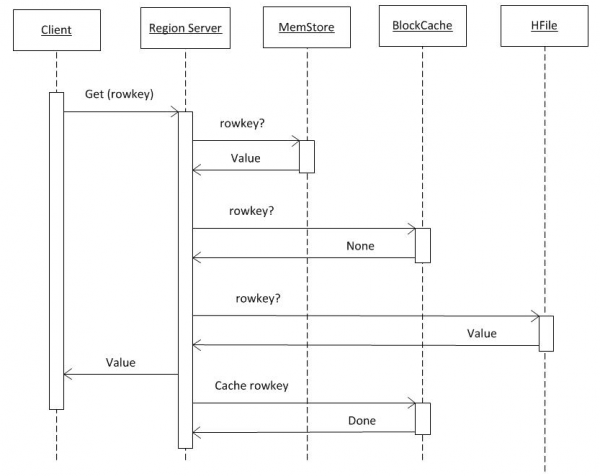
Saņemot datus no šiem trim avotiem, RS ģenerē atbildi. Konkrēti, tas var vienlaikus nosūtīt vairākas atrastās objekta versijas, ja klients ir pieprasījis versiju izveidi.
4. Datu kešatmiņa
MemStore un BlockCache buferi aizņem līdz pat 80% no piešķirtās RS kaudzes atmiņas (pārējā daļa ir rezervēta RS pakalpojumu uzdevumiem). Ja tipiskais lietošanas režīms ir tāds, ka procesi raksta un nekavējoties nolasa tos pašus datus, ir lietderīgi samazināt BlockCache un palielināt MemStore, jo, rakstot datus, lasīšanas kešatmiņa netiek ietekmēta, un BlockCache tiks izmantota retāk. BlockCache buferis sastāv no divām daļām: LruBlockCache (vienmēr kaudzes atmiņā) un BucketCache (parasti ārpus kaudzes vai SSD diskā). BucketCache jāizmanto, ja ir daudz lasīšanas pieprasījumu un tie neietilpst LruBlockCache, kas noved pie aktīvas atkritumu savācēja aktivitātes. Tomēr nevajadzētu gaidīt ievērojamu veiktspējas pieaugumu no lasīšanas kešatmiņas izmantošanas, bet mēs pie tā atgriezīsimies 8. darbībā.
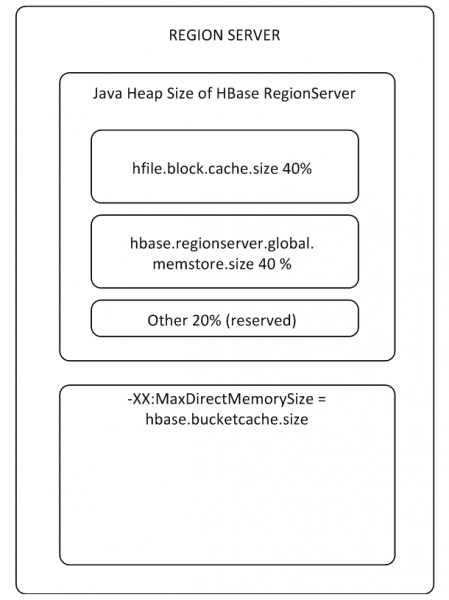
Visai RS ir viena BlockCache, un katrai tabulai ir sava MemStore (viena katrai kolonnu saimei).
Kā Teorētiski kešatmiņā ierakstītie dati netiek ierakstīti, un patiešām, tabulas parametrs CACHE_DATA_ON_WRITE un RS parametrs "Cache DATA on Write" ir iestatīti uz false. Tomēr praksē, ja datus ierakstāt MemStore, pēc tam tos izdzēšat diskā (tādējādi tos notīrot) un pēc tam izdzēšat iegūto failu, datus veiksmīgi izgūsiet, izpildot GET pieprasījumu. Turklāt, pat ja pilnībā atspējojat BlockCache un aizpildāt tabulu ar jauniem datiem, pēc tam izdzēšat MemStore diskā, izdzēšat to un vaicājat no citas sesijas, dati joprojām tiks izgūti no kaut kurienes. Tātad HBase uzglabā ne tikai datus, bet arī noslēpumainus noslēpumus.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Parametrs "Cache DATA on Read" ir iestatīts uz false. Ja jums ir kādas idejas, lūdzu, apspriediet tās komentāros.
5. Pakešu datu apstrāde ar MultiGet/MultiPut
Atsevišķu pieprasījumu (Get/Put/Delete) apstrāde ir diezgan dārga, tāpēc to apvienošana sarakstā vai sarakstā, kad vien iespējams, var ievērojami uzlabot veiktspēju. Tas jo īpaši attiecas uz rakstīšanas operācijām, bet lasīšana rada trūkumus. Zemāk redzamajā grafikā ir parādīts laiks, kas nepieciešams, lai nolasītu 50 000 ierakstu no MemStore. Lasīšana tika veikta vienā pavedienā, un horizontālā ass parāda atslēgu skaitu pieprasījumā. Ir skaidrs, ka, palielinoties atslēgu skaitam vienā pieprasījumā līdz tūkstotim, izpildes laiks samazinās, kas nozīmē, ka veiktspēja palielinās. Tomēr, ja MSLAB režīms ir iespējots pēc noklusējuma, veiktspēja sāk dramatiski samazināties, pārsniedzot šo slieksni, jo, jo lielāks ir datu apjoms ierakstā, jo ilgāks ir izpildes laiks.
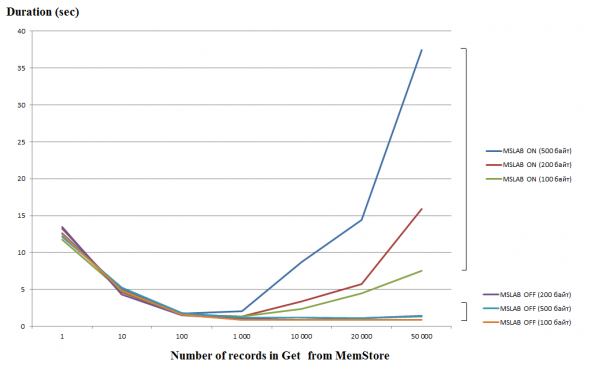
Testi tika veikti virtuālajā mašīnā, 8 kodolos, HBase versijā 2.0.0-cdh6.0.0-beta1.
MSLAB režīms ir izstrādāts, lai samazinātu kaudzes fragmentāciju, ko izraisa jaunu un vecu paaudžu datu sajaukšana. Lai atrisinātu šo problēmu, iespējojot MSLAB, dati tiek ievietoti relatīvi mazos blokos un apstrādāti pa daļām. Tā rezultātā, kad pieprasītā datu paketes lielums pārsniedz piešķirto lielumu, veiktspēja strauji samazinās. Tomēr arī šī režīma atspējošana nav vēlama, jo tas novedīs pie GC apstāšanās intensīvas datu piekļuves periodos. Labs risinājums ir palielināt bloka lielumu aktīvas rakstīšanas gadījumā, izmantojot put, vienlaikus ar lasīšanu. Ir vērts atzīmēt, ka šī problēma nerodas, ja pēc rakstīšanas tiek izpildīta tīrīšanas komanda, kas iztīra MemStore diskā, vai ja ielāde tiek veikta, izmantojot BulkLoad. Zemāk esošajā tabulā redzams, ka pieprasījumi pēc lielākiem (un identiskiem) datiem no MemStore izraisa palēnināšanos. Tomēr bloka lieluma palielināšana atgriež apstrādes laiku normālā stāvoklī.
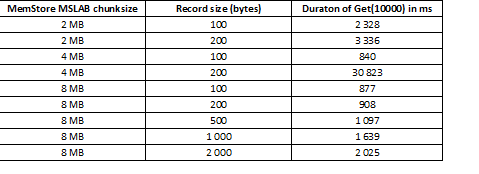
Papildus fragmentu lieluma palielināšanai palīdz arī datu sadalīšana pa reģioniem, t. i., tabulu sadalīšana. Tas nozīmē, ka uz katru reģionu tiek nosūtīts mazāk pieprasījumu, un, ja tie ietilpst šūnā, atbilde joprojām ir laba.
6. Tabulu sadalīšanas reģionos stratēģija (izkliedēšana)
Tā kā HBase ir atslēgu-vērtību krātuve un sadalīšana tiek veikta pēc atslēgas, ir svarīgi datus vienmērīgi sadalīt visos reģionos. Piemēram, šādas tabulas sadalīšana trīs daļās novedīs pie tā, ka dati tiks sadalīti trīs reģionos:
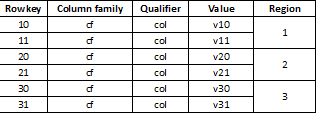
Tas dažreiz var izraisīt strauju palēnināšanos, ja vēlāk ielādētie dati ir, piemēram, garas vērtības, kas lielākoties sākas ar vienu un to pašu skaitli, piemēram:
1000001
1000002
...
1100003
Tā kā atslēgas tiek glabātas kā baitu masīvs, tās visas sāksies vienādi un piederēs vienam un tam pašam 1. reģionam, kurā tiek glabāts šis atslēgu diapazons. Ir vairākas sadalīšanas stratēģijas:
HexStringSplit – Pārveido atslēgu par virkni ar heksadecimālo kodējumu diapazonā "00000000" => "FFFFFFFF" un aizpildītu ar nullēm kreisajā pusē.
UniformSplit – Pārveido atslēgu par baitu masīvu ar heksadecimālu kodējumu diapazonā "00" => "FF" un aizpilda ar nullēm labajā pusē.
Turklāt sadalīšanai var norādīt jebkuru atslēgu diapazonu vai kopu un konfigurēt automātisko sadalīšanu. Tomēr viena no vienkāršākajām un efektīvākajām metodēm ir UniformSplit un jaucējkoda konkatenācijas izmantošana, piemēram, nozīmīgākais baitu pāris no atslēgas palaišanas, izmantojot CRC32(rindas atslēgas) funkciju, un pati rindas atslēga:
hešs + rindas atslēga
Tad visi dati tiks vienmērīgi sadalīti pa reģioniem. Lasot, pirmie divi baiti tiek vienkārši atmesti, atstājot sākotnējo atslēgu. RS arī uzrauga datu un atslēgu apjomu reģionā un automātiski sadala to daļās, ja tiek pārsniegti ierobežojumi.
7. Kļūmju tolerance un datu lokalizācija
Tā kā par katru atslēgu kopu ir atbildīgs tikai viens reģions, risinājums problēmām, kas saistītas ar RS avārijām vai deaktivizēšanu, ir visu nepieciešamo datu glabāšana HDFS. Kad RS avarē, galvenais serveris to konstatē, jo ZooKeeper mezglā nav sirdsdarbības signāla. Pēc tam tas piešķir apkalpoto reģionu citam RS. Tā kā HFiles tiek glabāti izkliedētā failu sistēmā, jaunais galvenais serveris tos nolasa un turpina apkalpot datus. Tomēr, tā kā daži dati var atrasties MemStore un vēl nav pārsūtīti uz HFiles, WAL, kas arī tiek glabāts HDFS, tiek izmantots, lai atjaunotu darbību vēsturi. Pēc izmaiņu piemērošanas RS spēj atbildēt uz pieprasījumiem, taču pārvietošanas rezultātā daži dati un tos apkalpojošie procesi atrodas dažādos mezglos, samazinot lokalizāciju.
Risinājums ir galvenā saspiešana. Šī procedūra pārvieto failus uz mezgliem, kas par tiem atbild (kur atrodas to reģioni), kā rezultātā šī procesa laikā strauji palielinās tīkla un diska slodze. Tomēr vēlāk piekļuve datiem ir ievērojami ātrāka. Turklāt major_compaction apvieno visus HFiles vienā failā reģiona ietvaros un attīra datus, pamatojoties uz tabulas iestatījumiem. Piemēram, varat norādīt saglabājamo objektu versiju skaitu vai dzīves ilgumu, pēc kura objekts tiek fiziski dzēsts.
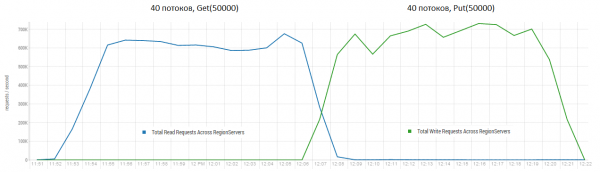
Šai procedūrai var būt ļoti pozitīva ietekme uz HBase veiktspēju. Zemāk redzamajā attēlā ir parādīts, kā veiktspēja pasliktinās lielas datu rakstīšanas rezultātā. Tajā redzami 40 pavedieni, kas raksta vienā tabulā, un 40 pavedieni, kas vienlaikus lasa datus. Rakstīšanas pavedieni ģenerē arvien vairāk HFile failu, kurus pēc tam nolasa citi pavedieni. Tā rezultātā no atmiņas ir jānoņem arvien vairāk datu, un galu galā ieslēdzas GC, praktiski paralizējot visu darbu. Lielas saspiešanas veikšana novērsa radušos uzkrāšanos un atjaunoja veiktspēju.
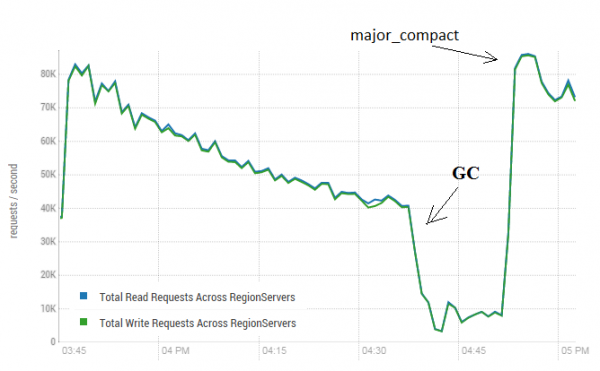
Tests tika veikts ar 3 DataNode un 4 RS (Xeon E5-2680 v4 CPU @ 2.40GHz * 64 pavedieni). HBase versija 1.2.0-cdh5.14.2.
Vērts atzīmēt, ka galvenā saspiešana tika veikta tiešraides tabulā, aktīvi rakstot un lasot datus. Tiešsaistē bija apgalvojumi, ka tas varētu izraisīt nepareizas atbildes, lasot datus. Lai to pārbaudītu, tika palaists process, kas ģenerēja jaunus datus un ierakstīja tos tabulā. Pēc tam tas nekavējoties tos nolasīja un pārbaudīja, vai iegūtā vērtība atbilst ierakstītajai vērtībai. Šī procesa laikā galvenā saspiešana tika veikta aptuveni 200 reizes, un netika reģistrēta neviena kļūme. Iespējams, ka problēma rodas reti un tikai lielas slodzes periodos, tāpēc ir drošāk regulāri apturēt rakstīšanu un lasīšanu un veikt tīrīšanu, lai novērstu šādus GC kritumus.
Turklāt ievērojama saspiešana neietekmē MemStore stāvokli; lai to izvadītu uz disku un saspiestu, jāizmanto flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Iestatījumi un veiktspēja
Kā jau minēts iepriekš, HBase ir visveiksmīgākā, ja tai nekas nav jādara — izpildot BulkLoad. Tomēr tas attiecas uz lielāko daļu sistēmu un cilvēku. Tomēr šis rīks ir vairāk piemērots datu masveida ielādei lielos blokos, savukārt, ja procesam nepieciešami vairāki vienlaicīgi lasīšanas un rakstīšanas pieprasījumi, tiek izmantotas iepriekš aprakstītās Get un Put komandas. Lai noteiktu optimālos parametrus, mēs veicām testus ar dažādām tabulas parametru un iestatījumu kombinācijām:
- 10 pavedieni tika sākti vienlaicīgi 3 reizes pēc kārtas (sauksim to par pavedienu bloku).
- Visu pavedienu darbības laiks blokā tika aprēķināts kā vidējais, un tas bija bloka darbības gala rezultāts.
- Visas tēmas strādāja ar vienu un to pašu tabulu.
- Pirms katras vītņbloka palaišanas tika veikta galvenā blīvēšana.
- Katrs bloks veica tikai vienu no šīm darbībām:
— Put
-Gūt
— Iegūt+Ievietot
- Katrs bloks veica 50 000 savas darbības atkārtojumu.
- Ieraksta lielums blokā ir 100 baiti, 1000 baiti vai 10 000 baiti (nejauši).
- Bloki tika palaisti ar atšķirīgu pieprasīto atslēgu skaitu (vai nu vienu atslēgu, vai 10).
- Bloki tika palaisti ar dažādiem tabulas iestatījumiem. Tika mainīti šādi parametri:
— BlockCache = iespējots vai atspējots
— Bloka izmērs = 65 KB vai 16 KB
— Starpsienas = 1, 5 vai 30
— MSLAB = ieslēgts vai izslēgts
Tātad bloks izskatās šādi:
a. MSLAB režīms tika ieslēgts/izslēgts.
b. Tika izveidota tabula, kurai tika iestatīti šādi parametri: BlockCache = true/none, BlockSize = 65/16 Kb, Partitions = 1/5/30.
c. Tika iestatīta GZ saspiešana.
d. Vienlaikus tika palaisti 10 pavedieni, veicot 1/10 put/get/get+put operācijas šajā tabulā ar ierakstiem 100/1000/10000 baitu apmērā, izpildot 50 000 pieprasījumus pēc kārtas (nejaušas atslēgas).
e. Punkts d tika atkārtots trīs reizes.
f. Tika aprēķināts visu pavedienu darbības laika vidējais rādītājs.
Tika pārbaudītas visas iespējamās kombinācijas. Bija paredzams, ka ieraksta lieluma palielināšana samazinās veiktspēju vai kešatmiņas atspējošana novedīs pie palēninājumiem. Tomēr mērķis bija izprast katra parametra ietekmes pakāpi un nozīmīgumu, tāpēc apkopotie dati tika ievadīti lineārā regresijas funkcijā, kas ļauj veikt uzticamības novērtējumu, izmantojot t-statistiku. Bloku, kas izpilda Put operācijas, rezultāti ir parādīti zemāk. Pilns kombināciju kopums ir 2 * 2 * 3 * 2 * 3 = 144 varianti + 72, jo daži tika izpildīti divreiz. Tāpēc kopā 216 izpildes:
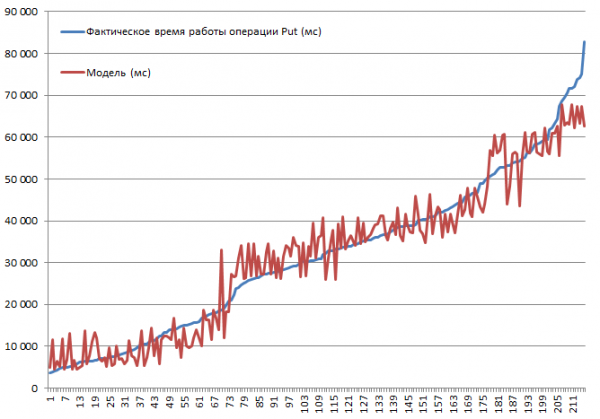
Testēšana tika veikta mini klasterī, kas sastāvēja no trim DataNode un četriem RS (Xeon E5-2680 v4 centrālie procesori ar frekvenci 2.40 GHz * 64 pavedieni). HBase versija 1.2.0-cdh5.14.2.
Vislielākais ievietošanas ātrums — 3.7 sekundes — tika iegūts, atspējojot MSLAB režīmu, tabulā ar vienu nodalījumu, iespējotu BlockCache, BlockSize = 16 un 100 baitu ierakstiem 10 ierakstu partijā.
Zemākais ievietošanas ātrums — 82.8 s — tika iegūts ar iespējotu MSLAB režīmu, tabulā ar vienu nodalījumu, iespējotu BlockCache, BlockSize = 16 un 10 000 baitu ierakstiem, pa 1 katrā.
Tagad aplūkosim modeli. Mēs redzam labu modeļa kvalitāti attiecībā uz R2, taču ir skaidrs, ka ekstrapolācija šeit ir kontrindicēta. Faktiskās sistēmas uzvedība nebūs lineāra, mainoties parametriem; šis modelis ir nepieciešams nevis prognozēm, bet gan lai izprastu, kas noticis doto parametru ietvaros. Piemēram, šeit no Stjudenta t-testa mēs redzam, ka BlockSize un BlockCache parametri nav būtiski Put operācijai (kas parasti ir diezgan paredzama):

Tas, ka nodalījumu skaita palielināšana noved pie veiktspējas samazināšanās, ir nedaudz negaidīts (mēs jau esam redzējuši pozitīvo ietekmi, ko sniedz nodalījumu skaita palielināšana ar BulkLoad), lai gan tas ir saprotams. Pirmkārt, apstrādei ir nepieciešams ģenerēt vaicājumus 30 reģioniem, nevis vienam, un datu apjoms nav pietiekami liels, lai nodrošinātu veiktspējas pieaugumu. Otrkārt, kopējo izpildes laiku nosaka lēnākais RS, un, tā kā DataNode skaits ir mazāks nekā RS skaits, dažiem reģioniem ir nulle lokalizācijas. Apskatīsim piecus galvenos:

Tagad novērtēsim Get bloku izpildes rezultātus:

Nodalījumu skaits ir kļuvis mazāk nozīmīgs, iespējams, tāpēc, ka dati ir labi kešatmiņā un lasīšanas kešatmiņa ir (statistiski) nozīmīgākais parametrs. Protams, ziņojumu skaita palielināšana vienā vaicājumā ir ļoti labvēlīga arī veiktspējai. Labākie rezultāti:

Visbeidzot, aplūkosim bloka modeli, kas vispirms veica get un pēc tam put:

Visi parametri šeit ir nozīmīgi. Un līderu rezultāti:

9. Slodzes pārbaude
Visbeidzot, palaidīsim vairāk vai mazāk pienācīgu darba slodzi, taču vienmēr ir interesantāk, ja ir ar ko salīdzināt. Cassandra galvenā izstrādātāja DataStax tīmekļa vietnē ir NT vairākām NoSQL krātuves sistēmām, tostarp HBase versijai 0.98.6-1. Ielāde tika veikta, izmantojot 40 pavedienus ar datu lielumu 100 baiti, izmantojot SSD diskus. Lasīšanas-modificēšanas-rakstīšanas testa rezultāti parādīja sekojošo.
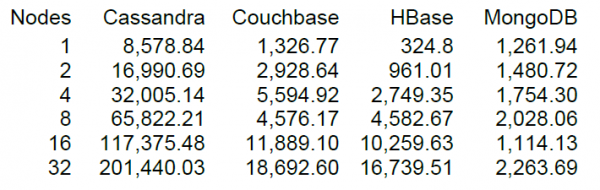
Cik es saprotu, lasīšana tika veikta 100 ierakstu blokos, un 16 HBase mezgliem DataStax tests uzrādīja 10 tūkstošu operāciju sekundē veiktspēju.
Par laimi, mūsu klasterī arī ir 16 mezgli, bet ne tik ļoti, ka katram ir 64 kodoli (pavedi), savukārt DataStax testā ir tikai 4. No otras puses, viņiem ir SSD diski, savukārt mums ir HDD diski un jaunāka HBase versija, tāpēc centrālā procesora noslodze slodzes laikā gandrīz nepalielinājās (redzami par 5–10 procentiem). Neskatoties uz to, mēs mēģināsim palaist šo konfigurāciju. Tabulas iestatījumi ir noklusējuma iestatījumi: nolasīšana tiek veikta nejauši atslēgām no 0 līdz 50 miljoniem (t. i., būtībā katru reizi jauns ieraksts). Tabulā ir 50 miljoni ierakstu, kas sadalīti 64 nodalījumos. Atslēgas tiek hešētas, izmantojot crc32. Tabulas iestatījumi ir noklusējuma iestatījumi, un ir iespējots MSLAB. Mēs palaižam 40 pavedienus, katrs pavediens nolasa 100 nejaušu atslēgu kopu un nekavējoties ieraksta atpakaļ 100 ģenerētus baitus šīm atslēgām.
Stends: 16 DataNode un 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 pavedieni). HBase versija 1.2.0-cdh5.14.2.
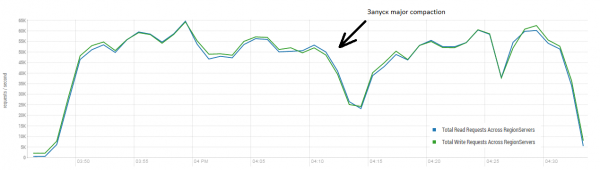
Vidējais rezultāts ir tuvāk 40 000 operācijām sekundē, kas ir ievērojami labāk nekā DataStax testā. Tomēr eksperimentāliem nolūkiem nosacījumus var nedaudz mainīt. Ir diezgan maz ticams, ka viss darbs tiks veikts tikai ar vienu tabulu un tikai ar unikālām atslēgām. Pieņemsim, ka pastāv "karstais" atslēgu kopums, kas ģenerē lielāko daļu slodzes. Tāpēc mēs mēģināsim ģenerēt slodzi ar lielākiem ierakstiem (10 KB), arī 100 ierakstu partijās, četrās dažādās tabulās, ierobežojot pieprasīto atslēgu diapazonu līdz 50 000. Zemāk redzamajā grafikā parādīti 40 darbojošies pavedieni, katrs pavediens nolasa 100 atslēgu kopu un nekavējoties ieraksta nejaušus 10 KB atpakaļ šajās atslēgās.
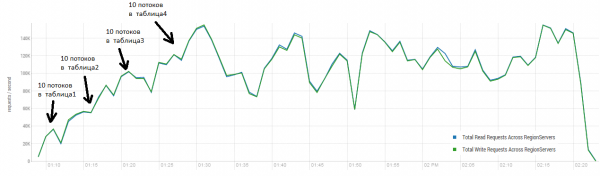
Stends: 16 DataNode un 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 pavedieni). HBase versija 1.2.0-cdh5.14.2.
Ielādes laikā vairākas reizes tika veikta ievērojama saspiešana. Kā parādīts iepriekš, bez šīs procedūras veiktspēja pakāpeniski pasliktinātos. Tomēr izpildes laikā radās arī papildu slodze. Kritumus izraisīja dažādi faktori. Dažreiz pavedieni tika pārtraukti, izraisot pauzi to restartēšanas laikā, un dažreiz trešo pušu lietojumprogrammas radīja slodzi klasterī.
Lasīšanas un rakstīšanas operācijas ir viena no prasīgākajām HBase darba slodzēm. Izmantojot tikai mazus put vaicājumus, piemēram, 100 baitus katru, kas sadalīti 10 000–50 000 daļās, var sasniegt simtiem tūkstošu darbību sekundē. Tas pats attiecas uz tikai lasīšanas vaicājumiem. Jāatzīmē, ka rezultāti ir ievērojami labāki nekā tie, kas iegūti ar DataStax, jo īpaši 50 000 baitu vaicājuma lieluma dēļ.
Stends: 16 DataNode un 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 pavedieni). HBase versija 1.2.0-cdh5.14.2.
10. Secinājumi
Šī sistēma ir diezgan elastīga konfigurācijā, taču daudzu parametru ietekme joprojām nav zināma. Daži no tiem tika pārbaudīti, bet netika iekļauti galīgajā testu komplektā. Piemēram, sākotnējie eksperimenti uzrādīja mazu nozīmi parametram DATA_BLOCK_ENCODING, kas kodē informāciju, izmantojot vērtības no blakus esošajām šūnām, kas ir saprotams nejauši ģenerētiem datiem. Izmantojot lielu skaitu atkārtotu objektu, ieguvumi var būt ievērojami. Kopumā HBase šķiet diezgan stabila un labi izstrādāta datubāze, kas var būt diezgan produktīva, apstrādājot lielus datu blokus, īpaši, ja lasīšanu un rakstīšanu var veikt ar intervāliem.
Ja uzskatāt, ka kaut ko neesmu pietiekami aplūkojis, labprāt paskaidrošu. Aicinām dalīties pieredzē vai apspriest jebkādas domstarpības.
Avots: www.habr.com
