


Neironu tīkli datorredzē aktīvi attīstās, daudzas problēmas joprojām nav atrisinātas. Lai būtu tendencēs savā jomā, vienkārši sekojiet ietekmētājiem pakalpojumā Twitter un lasiet attiecīgos rakstus vietnē arXiv.org. Taču mums bija iespēja doties uz Starptautisko datoru redzes konferenci (ICCV) 2019. Šogad tā notiek Dienvidkorejā. Tagad mēs vēlamies dalīties ar Habr lasītājiem, ko mēs redzējām un uzzinājām.
Mūsu no Yandex tur bija daudz: ieradās pašbraucošo automašīnu izstrādātāji, pētnieki un tie, kas servisos nodarbojas ar CV uzdevumiem. Bet tagad mēs vēlamies iepazīstināt ar nedaudz subjektīvu mūsu komandas - Mašīnu izlūkošanas laboratorijas (Yandex MILAB) viedokli. Pārējie puiši droši vien paskatījās uz konferenci no sava leņķa.
Ko dara laboratorija?Mēs veicam eksperimentālus projektus, kas saistīti ar attēlu un mūzikas ģenerēšanu izklaides nolūkos. Mūs īpaši interesē neironu tīkli, kas ļauj mainīt saturu no lietotāja (fotogrāfijām šo uzdevumu sauc par attēla manipulāciju). mūsu darba rezultāts no YaC 2019 konferences.
Zinātnisko konferenču ir ļoti daudz, bet izceļas topa, tā sauktās A* konferences, kurās parasti tiek publicēti raksti par interesantākajām un svarīgākajām tehnoloģijām. Precīza A* konferenču saraksta nav, šeit ir aptuvens un nepilnīgs saraksts: NeurIPS (agrāk NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Pēdējie trīs specializējas CV tēmā.
ICCV īsumā: plakāti, apmācības, darbnīcas, stendi
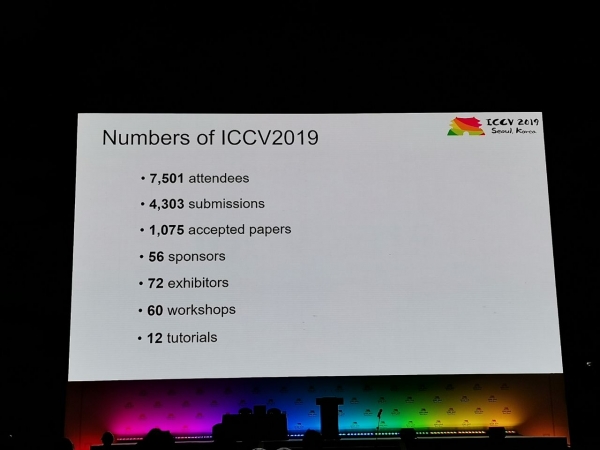
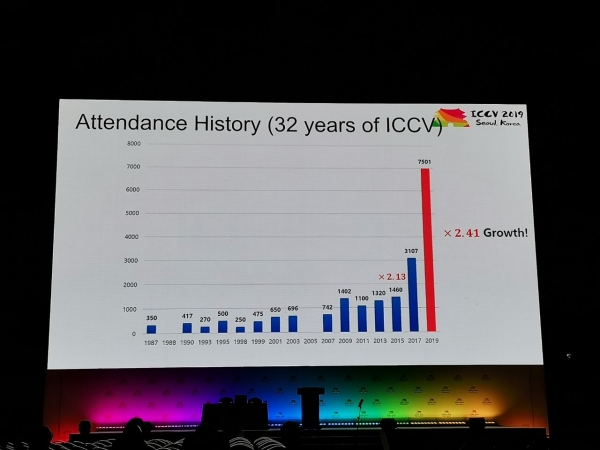
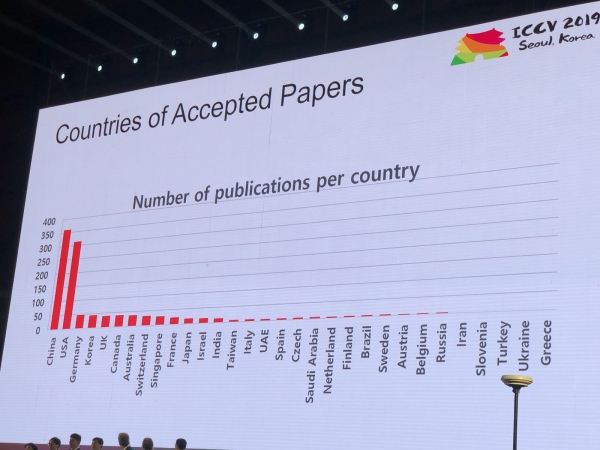
Konferencē tika saņemti 1075 referāti, piedalījās 7500 dalībnieku, no Krievijas bija ieradušies 103 cilvēki, bija raksti no Yandex, Skoltech, Samsung AI centra Maskavas un Samaras universitātes. Šogad ICCV viesojās ne daudzi top pētnieki, bet, piemēram, Aleksejs (Alioša) Efross, kurš vienmēr piesaista daudz cilvēku:

Statistika 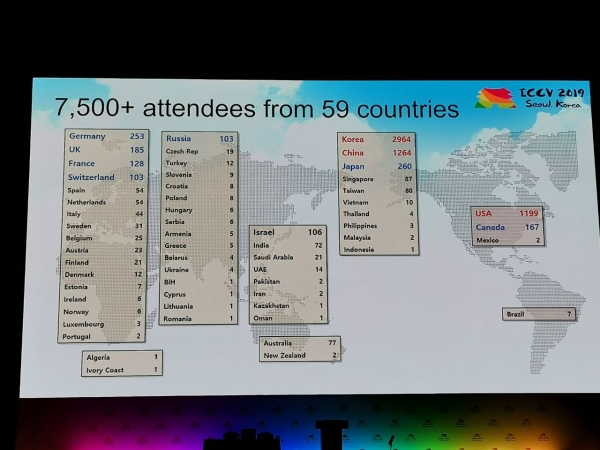

Visās šādās konferencēs raksti tiek prezentēti plakātu veidā ( par formātu), un labākie tiek prezentēti arī īsu ziņojumu veidā.
Šeit ir daži no Krievijas darbiem 


Ar pamācībām jūs varat ienirt noteiktā mācību jomā, tas atgādina lekciju universitātē. To lasa viens cilvēks, parasti nerunājot par konkrētiem darbiem. Foršas apmācības piemērs ():

Gluži pretēji, semināros viņi runā par rakstiem. Parasti tie ir darbi kādā šaurā tēmā, laboratoriju vadītāju stāsti par visiem jaunākajiem studentu darbiem vai raksti, kas netika pieņemti galvenajā konferencē.
Sponsorējošie uzņēmumi uz ICCV ierodas ar stendiem. Šogad ieradās Google, Facebook, Amazon un daudzi citi starptautiski uzņēmumi, kā arī liels skaits startup - korejiešu un ķīniešu. Īpaši daudz bija jaunuzņēmumu, kas specializējās datu marķēšanā. Pie stendiem notiek priekšnesumi, var paņemt līdzi preces un uzdot jautājumus. Medību nolūkos sponsorējošās kompānijas rīko ballītes. Jūs varat tajās iekļūt, ja pārliecināsit darbā iekārtotājus, ka jūs interesē un ka varat iziet intervijas. Ja esi publicējis rakstu (vai turklāt prezentējis), sācis vai beidz doktorantūras studijas, tas ir pluss, bet dažkārt vari sarunāties stendā, uzdodot interesējošus jautājumus uzņēmuma inženieriem.
Tendences
Konference ļauj ieskatīties visā CV jomā. Pēc plakātu skaita par konkrētu tēmu varat novērtēt, cik aktuāla ir tēma. Daži secinājumi liecina, pamatojoties uz atslēgvārdiem:

Zero-shot, one-shot, daži kadri, pašpārraudzīts un daļēji uzraudzīts: jaunas pieejas ilgi pētītiem uzdevumiem
Cilvēki mācās efektīvāk izmantot datus. Piemēram, iekšā iespējams ģenerēt tādu dzīvnieku sejas izteiksmes, kas nebija mācību komplektā (pieteikumā, sniedzot vairākus atsauces attēlus). Deep Image Prior idejas ir izstrādātas, un tagad GAN tīklus var apmācīt uz viena attēla - par to mēs runāsim tālāk . Varat izmantot pašpārraudzību iepriekšējai apmācībai (risinot problēmu, kurai varat sintezēt saskaņotus datus, piemēram, paredzēt attēla pagriešanas leņķi) vai vienlaikus mācīties no iezīmētiem un nemarķētiem datiem. Šajā ziņā rakstu var uzskatīt par radīšanas vainagu . Un šeit ir iepriekšēja apmācība vietnē ImageNet palīdz.

3D un 360°
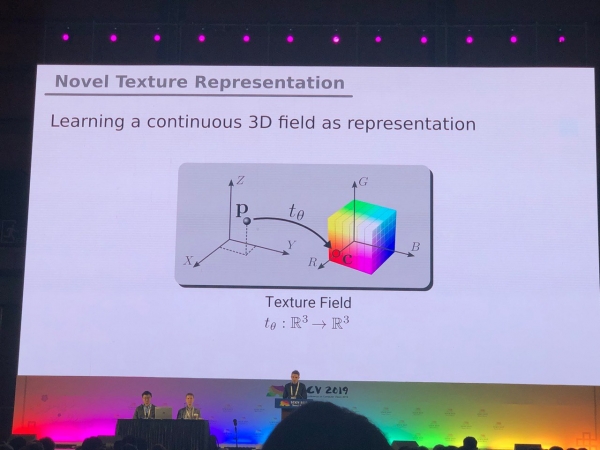
Problēmas, kas galvenokārt tika atrisinātas fotogrāfijām (segmentēšana, noteikšana), prasa papildu izpēti 3D modeļiem un panorāmas video. Mēs esam redzējuši daudzus rakstus par RGB un RGB-D pārveidošanu 3D formātā. Dažas problēmas, piemēram, cilvēka pozas novērtēšanu, var atrisināt dabiskāk, pārejot uz 3D modeļiem. Taču vēl nav vienprātības par to, kā precīzi attēlot XNUMXD modeļus — sieta, punktu mākoņa, vokseļu vai SDF formātā. Šeit ir vēl viena iespēja:
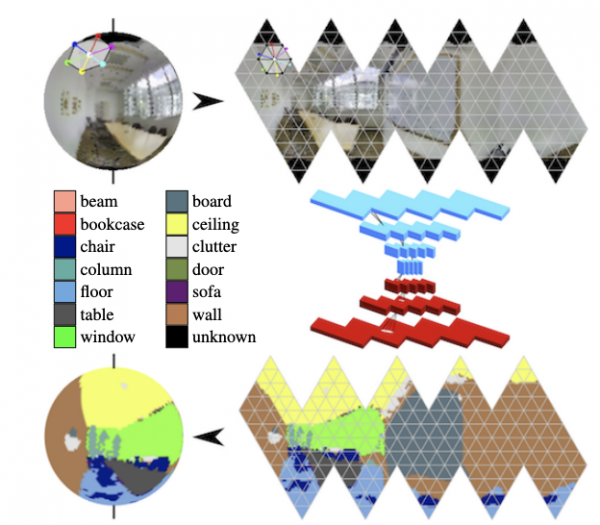
Panorāmās sfēras līkumi aktīvi attīstās (sk. ) un meklējiet galvenos objektus kadrā.
Pozu noteikšana un cilvēka kustību prognozēšana
Pozu noteikšanā 2D jau ir gūti panākumi — tagad uzmanība ir pievērsta darbam ar vairākām kamerām un 3D. Ir iespējams arī, piemēram, atklāt skeletu caur sienu, izsekojot Wi-Fi signāla izmaiņām, kad tas iet cauri cilvēka ķermenim.
Liels darbs ir paveikts rokas atslēgas punktu noteikšanas jomā. Ir parādījušās jaunas datu kopas, tostarp tās, kuru pamatā ir divu cilvēku dialogu video — tagad varat paredzēt roku žestus no sarunas audio vai teksta! Tāds pats progress ir panākts acu izsekošanas uzdevumos (skatiena novērtēšanā).

Var identificēt arī lielu darbu kopu, kas saistīti ar cilvēka kustību prognozēšanu (piemēram, vai ). Uzdevums ir svarīgs un, balstoties uz sarunām ar autoriem, visbiežāk tiek izmantots, lai analizētu gājēju uzvedību autonomajā braukšanā.
Manipulācijas ar cilvēkiem fotogrāfijās un video, virtuālās pielaikošanas kabīnes
Galvenā tendence ir mainīt sejas attēlus atbilstoši interpretējamiem parametriem. Idejas: dziļa viltošana, pamatojoties uz vienu attēlu, maināma izteiksme, pamatojoties uz sejas atveidojumu (), uz priekšu — mainiet parametrus (piemēram, ). Stila pārnesumi no tēmas nosaukuma ir pārcēlušies uz darba pielietojumu. Virtuālās pielaikošanas telpas ir cits stāsts, tās gandrīz vienmēr darbojas slikti, demonstrācijas.


Paaudze no skicēm/grafikiem
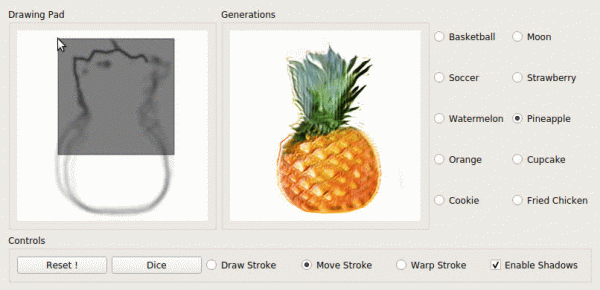
Idejas "Ļaujiet režģim ģenerēt kaut ko, pamatojoties uz iepriekšējo pieredzi" attīstība kļuva par citu: "Parādīsim režģim, kurš variants mūs interesē."
ļauj veikt krāsošanu ar vadību: lietotājs var pabeigt krāsot daļu sejas attēla izdzēstajā zonā un iegūt atjaunotu attēlu atkarībā no pabeigšanas.
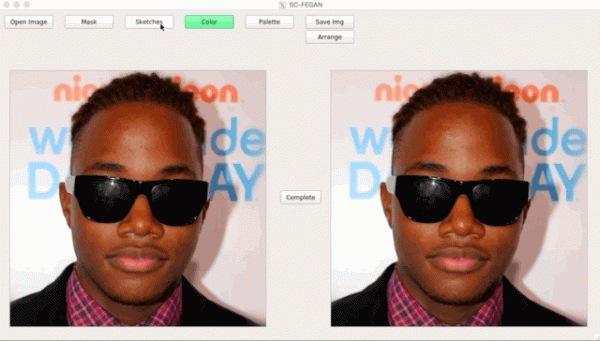
Viens no 25 Adobe rakstiem ICCV apvieno divus GAN: viens pabeidz skici lietotājam, otrs ģenerē fotoreālistisku attēlu no skices ().
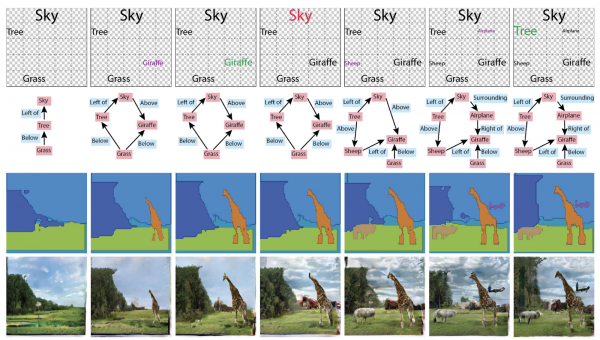
Iepriekš grafi nebija vajadzīgi attēlu ģenerēšanā, bet tagad tie ir izveidoti kā zināšanu konteiners par notikuma vietu. Raksts ieguva arī balvu par goda rakstiem par labāko grāmatu, pamatojoties uz ICCV rezultātiem . Kopumā tos var izmantot dažādos veidos: ģenerēt grafikus no attēliem vai attēlus un tekstus no grafikiem.
Cilvēku un automašīnu atkārtota identifikācija, skaitot pūļa lielumu (!)
Daudzi raksti ir veltīti cilvēku izsekošanai un cilvēku un iekārtu atkārtotai identificēšanai. Bet tas, kas mūs pārsteidza, bija virkne rakstu par pūļa skaitīšanu, visi no Ķīnas.
Plakāti 


Bet Facebook, gluži pretēji, anonimizē fotoattēlu. Un tas tiek darīts interesantā veidā: tas apmāca neironu tīklu ģenerēt seju bez unikālām detaļām - līdzīgu, bet ne tik līdzīgu, lai to varētu pareizi identificēt ar sejas atpazīšanas sistēmām.

Aizsardzība pret pretinieku uzbrukumiem
Attīstoties datorredzes lietojumprogrammām reālajā pasaulē (pašbraucošās automašīnās, sejas atpazīšanā), arvien biežāk rodas jautājums par šādu sistēmu uzticamību. Lai pilnībā izmantotu CV, jums ir jābūt pārliecinātam, ka sistēma ir izturīga pret pretuzbrukumiem – tāpēc par aizsardzību pret tiem bija ne mazāk rakstu kā par pašiem uzbrukumiem. Ir bijis daudz darba, lai izskaidrotu tīkla prognozes (izcilības karte) un izmērītu pārliecību par rezultātu.
Kombinētie uzdevumi
Lielākajā daļā uzdevumu ar vienu mērķi kvalitātes uzlabošanas iespējas ir praktiski izsmeltas, viens no jaunajiem virzieniem tālākai kvalitātes paaugstināšanai ir mācīt neironu tīklus risināt vairākas līdzīgas problēmas vienlaikus. Piemēri:
— darbības prognozēšana + optiskās plūsmas prognozēšana,
— video prezentācija + valodas prezentācija (),
Sākot no .
Ir arī raksti par segmentāciju, pozas noteikšanu un dzīvnieku atkārtotu identifikāciju!

Izceļ
Gandrīz visi raksti bija zināmi iepriekš, teksts bija pieejams arXiv.org. Tāpēc diezgan dīvaina šķiet tādu darbu kā Everybody Dance Now, FUNIT, Image2StyleGAN prezentācija - tie ir ļoti noderīgi darbi, bet ne jauni. Šķiet, ka klasiskais zinātnisko publikāciju process te brūk – zinātne virzās pārāk ātri.
Ir ļoti grūti noteikt labākos darbus – to ir daudz, priekšmeti ir dažādi. Saņemti vairāki raksti .
Mēs vēlamies izcelt darbus, kas ir interesanti no attēlu manipulācijas viedokļa, jo šī ir mūsu tēma. Tie mums izrādījās diezgan svaigi un interesanti (nepretendējam uz objektīviem).
SinGAN (labākā papīra balva) un InGAN
SinGAN: , , .
InGAN: , , .
Dziļā attēla izstrāde Iepriekšēja ideja no Dmitrija Uļjanova, Andrea Vedaldi un Viktora Lempitska. Tā vietā, lai apmācītu GAN datu kopā, tīkli mācās no viena un tā paša attēla fragmentiem, lai atcerētos tajā esošo statistiku. Apmācītais tīkls ļauj rediģēt un animēt fotogrāfijas (SinGAN) vai ģenerēt jaunus jebkura izmēra attēlus no sākotnējā attēla faktūrām, saglabājot lokālo struktūru (InGAN).
SinGAN:

InGAN:

Redzot, ko GAN nevar radīt
.
Neironu tīkli, kas ģenerē attēlus, bieži izmanto nejauša trokšņa vektoru kā ievadi. Apmācītā tīklā daudzi ievades vektori veido atstarpi, nelielas kustības pa kuru rada nelielas izmaiņas attēlā. Izmantojot optimizāciju, jūs varat atrisināt apgriezto problēmu: atrast piemērotu ievades vektoru attēlam no reālās pasaules. Autore parāda, ka gandrīz nekad nav iespējams atrast pilnīgi atbilstošu attēlu neironu tīklā. Daži attēlā redzamie objekti netiek ģenerēti (acīmredzot šo objektu lielās mainīguma dēļ).
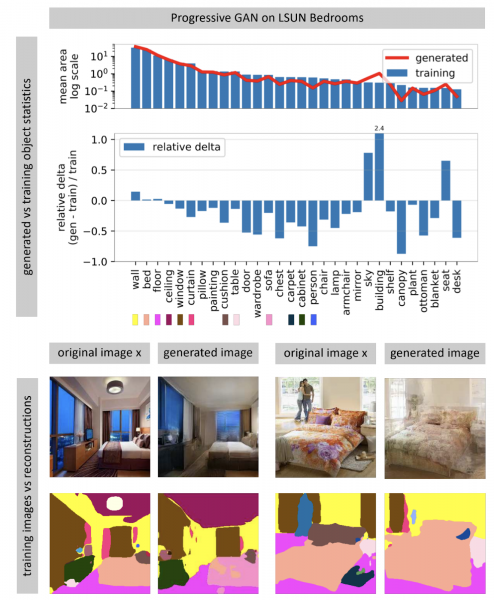
Autors izvirza hipotēzi, ka GAN neaptver visu attēlu telpu, bet gan tikai kādu apakškopu, kas pildīta ar caurumiem, piemēram, sieru. Mēģinot tajā atrast fotogrāfijas no reālās pasaules, mums vienmēr neizdosies, jo GAN joprojām ģenerē ne gluži īstas fotogrāfijas. Atšķirības starp reāliem un ģenerētiem attēliem var pārvarēt, tikai mainot tīkla svarus, tas ir, pārkvalificējot to konkrētam fotoattēlam.

Kad tīkls ir papildus apmācīts konkrētam fotoattēlam, varat izmēģināt dažādas manipulācijas ar šo attēlu. Tālāk esošajā piemērā fotoattēlam tika pievienots logs, un tīkls papildus radīja atspulgus uz virtuves iekārtu. Tas nozīmē, ka tīkls pat pēc papildu apmācības fotografēšanai nezaudēja spēju saskatīt saikni starp objektiem ainā.

GANalyze: ceļā uz kognitīvā attēla īpašību vizuālajām definīcijām
, .
Izmantojot šī darba pieeju, jūs varat vizualizēt un analizēt to, ko neironu tīkls ir iemācījies. Autori ierosina apmācīt GAN izveidot attēlus, kuriem tīkls ģenerēs noteiktas prognozes. Rakstā kā piemēri tika izmantoti vairāki tīkli, tostarp MemNet, kas paredz fotoattēlu iegaumējamību. Izrādījās, ka labākai iegaumēšanai fotoattēlā redzamajam objektam vajadzētu:
- būt tuvāk centram
- ir apaļāka vai kvadrātveida forma un vienkārša struktūra,
- būt uz vienota fona,
- satur izteiksmīgas acis (vismaz suņu fotogrāfijām),
- būt gaišākai, piesātinātākai, dažos gadījumos sarkanākai.

Šķidruma deformācijas GAN: vienots ietvars cilvēka kustības imitācijai, izskata pārnešanai un jauna skatījuma sintēzei
, , .
Cauruļvads cilvēku fotoattēlu ģenerēšanai pa vienam fotoattēlam. Autori rāda veiksmīgus piemērus, kā viena cilvēka kustību pārnest uz otru, pārnēsāt apģērbu starp cilvēkiem un ģenerēt jaunus cilvēka rakursus – tas viss no vienas fotogrāfijas. Atšķirībā no iepriekšējiem darbiem, šeit mēs izmantojam nevis galvenos punktus 2D (poza), bet gan ķermeņa 3D sietu (poza + forma), lai radītu apstākļus. Autori arī izdomāja, kā pārsūtīt informāciju no sākotnējā attēla uz ģenerēto (Liquid Warping Block). Rezultāti izskatās pieklājīgi, taču iegūtā attēla izšķirtspēja ir tikai 256x256. Salīdzinājumam, vid2vid, kas parādījās pirms gada, spēj ģenerēt 2048x1024 izšķirtspējā, taču tam kā datu kopai ir nepieciešamas pat 10 minūtes video ierakstīšanas.

FSGAN: priekšmeta agnostiķu seju maiņa un reanaktēšana
, .
Sākumā šķiet, ka nav nekā neparasta: deepfake ar vairāk vai mazāk normālu kvalitāti. Bet galvenais darba sasniegums ir seju aizstāšana no viena attēla. Atšķirībā no iepriekšējiem darbiem, apmācība bija nepieciešama daudzās konkrētas personas fotogrāfijās. Cauruļvads izrādījās apgrūtinošs (reinacting un segmentation, view interpolation, inpainting, blending) un ar daudziem tehniskiem uzlauzumiem, taču rezultāts ir tā vērts.

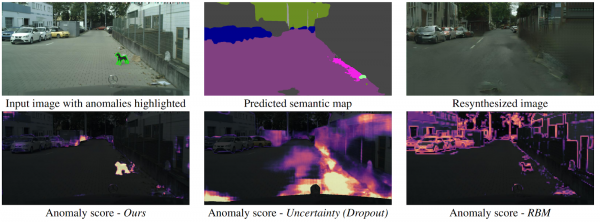
Negaidītā noteikšana, izmantojot attēla atkārtotu sintēzi
.
Kā drons saprast, ka tā priekšā pēkšņi ir parādījies objekts, kas neietilpst nevienā semantiskās segmentācijas klasē? Ir vairākas metodes, taču autori piedāvā jaunu, intuitīvu algoritmu, kas darbojas labāk nekā tā priekšgājēji. Semantiskā segmentācija tiek prognozēta no ievadceļa attēla. Tas tiek ievadīts kā ievade GAN (pix2pixHD), kas mēģina atjaunot sākotnējo attēlu tikai no semantiskās kartes. Anomālijas, kas neietilpst nevienā no segmentiem, ievērojami atšķirsies izvadē un ģenerētajā attēlā. Trīs attēli (sākotnējie, segmentētie un rekonstruētie) tiek ievadīti citā tīklā, kas paredz anomālijas. Datu kopa šim nolūkam tika ģenerēta no labi zināmās Cityscapes datu kopas, nejauši mainot klases semantiskajā segmentācijā. Interesanti, ka šajā iestatījumā suns, kas stāv ceļa vidū, bet pareizi segmentēts (tas nozīmē, ka tam ir sava klase), nav anomālija, jo sistēma to spēja atpazīt.
Secinājums
Pirms konferences ir svarīgi zināt, kādas ir jūsu zinātniskās intereses, kādas prezentācijas vēlaties apmeklēt un ar ko runāt. Tad viss būs daudz produktīvāk.
ICCV, pirmkārt un galvenokārt, ir tīklu veidošana. Jūs saprotat, ka ir augstākie institūti un augstākās zinātniskās nodaļas, jūs sākat to saprast, iepazīstat cilvēkus. Un jūs varat lasīt rakstus par arXiv — un, starp citu, tas ir ļoti forši, ka jums nekur nav jādodas, lai iegūtu zināšanas.
Turklāt konferencē var padziļināti ienirt tēmās, kas tev nav tuvas un saskatīt tendences. Nu, izveidojiet lasāmo rakstu sarakstu. Ja esi students, šī ir iespēja Tev satikt potenciālo skolotāju, ja esi no nozares, tad pie jauna darba devēja, un ja uzņēmums, tad parādīt sevi.
Abonēt ! Šis ir personisks projekts: mēs to vadām kopā ar . Visus darbus, kas mums patika konferences laikā, ievietojām šeit: .
Avots: www.habr.com
