

Šajā rakstā mēs runāsim par funkcionālajām atkarībām datu bāzēs - kas tās ir, kur tās tiek izmantotas un kādi algoritmi pastāv, lai tās atrastu.
Mēs apsvērsim funkcionālās atkarības relāciju datu bāzu kontekstā. Ļoti rupji sakot, šādās datubāzēs informācija tiek glabāta tabulu veidā. Tālāk mēs izmantojam aptuvenus jēdzienus, kas nav savstarpēji aizvietojami stingrā relāciju teorijā: pašu tabulu mēs sauksim par relāciju, kolonnas - atribūtus (to kopa - relāciju shēma) un rindu vērtību kopu atribūtu apakškopā. - korts.
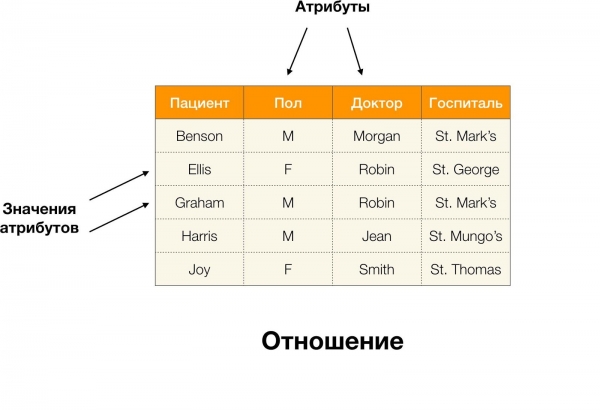
Piemēram, tabulā iepriekš, (Bensons, M, M orgāns) ir atribūtu kopa (Pacients, Pols, ārsts).
Formālāk tas ir rakstīts šādi:  [Pacients, dzimums, ārsts] = (Bensons, M, M ērģeles).
[Pacients, dzimums, ārsts] = (Bensons, M, M ērģeles).
Tagad mēs varam ieviest funkcionālās atkarības (FD) jēdzienu:
1. definīcija. Attiecība R atbilst federālajam likumam X → Y (kur X, Y ⊆ R) tad un tikai tad, ja jebkuram kortežam  ,
,  ∈ R atbilst: ja
∈ R atbilst: ja  [X] =
[X] =  [X], tad
[X], tad  [Y] =
[Y] =  [Y]. Šajā gadījumā mēs sakām, ka X (determinants jeb definējošā atribūtu kopa) funkcionāli nosaka Y (atkarīgo kopu).
[Y]. Šajā gadījumā mēs sakām, ka X (determinants jeb definējošā atribūtu kopa) funkcionāli nosaka Y (atkarīgo kopu).
Citiem vārdiem sakot, federālā likuma klātbūtne X → Y nozīmē, ka, ja mums ir divi korteži R un tie atbilst atribūtiem X, tad tie sakritīs atribūtos Y.
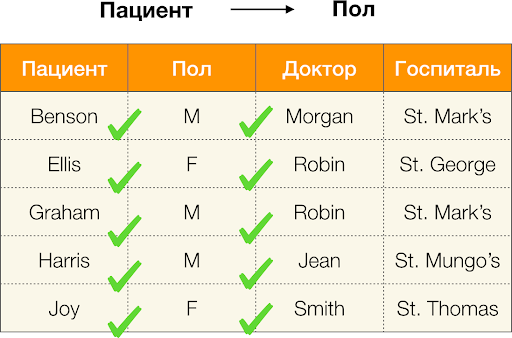
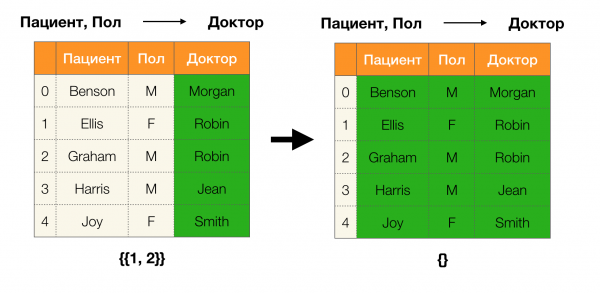
Un tagad kārtībā. Apskatīsim atribūtus Pacients и Paul kuriem mēs vēlamies noskaidrot, vai starp tiem ir atkarības vai nav. Šādai atribūtu kopai var būt šādas atkarības:
- Pacients → Dzimums
- Dzimums → Pacients
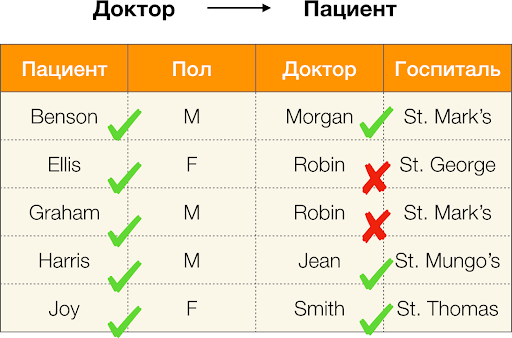
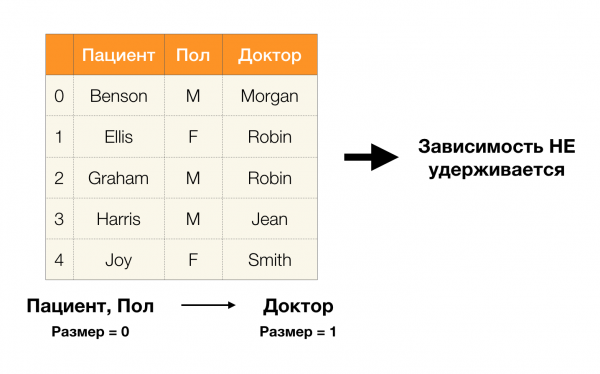
Kā definēts iepriekš, lai saglabātu pirmo atkarību, katra unikālā kolonnas vērtība Pacients jāsakrīt tikai vienai kolonnas vērtībai Paul. Un par piemēru tabulu tas patiešām ir gadījums. Tomēr tas nedarbojas pretējā virzienā, tas ir, otrā atkarība nav apmierināta, un atribūts Paul nav noteicošais faktors Pacients. Līdzīgi, ja mēs pieņemam atkarību Ārsts → Pacients, var redzēt, ka tas ir pārkāpts, jo vērtība penijs šim atribūtam ir vairākas dažādas nozīmes - Eliss un Grehems.
Tādējādi funkcionālās atkarības ļauj noteikt esošās attiecības starp tabulas atribūtu kopām. Turpmāk mēs apsvērsim interesantākos savienojumus vai drīzāk tādus X → Ykas tie ir:
- netriviāls, tas ir, atkarības labā puse nav kreisās puses apakškopa (Y ̸⊆ X);
- minimāla, tas ir, šādas atkarības nav Z → YKa Z ⊂ X.
Līdz šim izskatītās atkarības bija stingras, tas ir, neparedzēja nekādus pārkāpumus uz galda, bet papildus tiem ir arī tādi, kas pieļauj zināmas neatbilstības starp korešu vērtībām. Šādas atkarības tiek ievietotas atsevišķā klasē, ko sauc par aptuvenu, un tās ir atļauts pārkāpt noteiktam korešu skaitam. Šo summu regulē maksimālās kļūdas indikators emax. Piemēram, kļūdu īpatsvars  = 0.01 var nozīmēt, ka atkarību var pārkāpt 1% no pieejamajiem kortežiem no aplūkotās atribūtu kopas. Tas ir, 1000 ierakstiem ne vairāk kā 10 korteži var pārkāpt federālo likumu. Mēs apsvērsim nedaudz atšķirīgu metriku, pamatojoties uz pa pāriem atšķirīgām salīdzināmo korežu vērtībām. Par atkarību X → Y par attieksmi r tas tiek uzskatīts šādi:
= 0.01 var nozīmēt, ka atkarību var pārkāpt 1% no pieejamajiem kortežiem no aplūkotās atribūtu kopas. Tas ir, 1000 ierakstiem ne vairāk kā 10 korteži var pārkāpt federālo likumu. Mēs apsvērsim nedaudz atšķirīgu metriku, pamatojoties uz pa pāriem atšķirīgām salīdzināmo korežu vērtībām. Par atkarību X → Y par attieksmi r tas tiek uzskatīts šādi:

Aprēķināsim kļūdu priekš Ārsts → Pacients no iepriekš minētā piemēra. Mums ir divi korteži, kuru vērtības atšķiras pēc atribūta Pacients, bet sakrīt Ārsts:  [Ārsts, pacients] = (Robins, Eliss) Un
[Ārsts, pacients] = (Robins, Eliss) Un  [Ārsts, pacients] = (Robins, Grehems). Pēc kļūdas definīcijas mums ir jāņem vērā visi konfliktējošie pāri, kas nozīmē, ka tie būs divi: (
[Ārsts, pacients] = (Robins, Grehems). Pēc kļūdas definīcijas mums ir jāņem vērā visi konfliktējošie pāri, kas nozīmē, ka tie būs divi: ( ,
,  ) un tā apgrieztā (
) un tā apgrieztā ( ,
,  ). Aizstāsim to formulā un iegūsim:
). Aizstāsim to formulā un iegūsim:

Tagad mēģināsim atbildēt uz jautājumu: "Kāpēc tas viss?" Faktiski federālie likumi ir atšķirīgi. Pirmais veids ir tās atkarības, kuras administrators nosaka datu bāzes projektēšanas stadijā. To parasti ir maz, tie ir stingri, un galvenais pielietojums ir datu normalizācija un relāciju shēmas izstrāde.
Otrs veids ir atkarības, kas atspoguļo “slēptos” datus un iepriekš nezināmas attiecības starp atribūtiem. Tas ir, projektēšanas laikā par šādām atkarībām netika domāts un tās tiek atrastas esošajai datu kopai, lai vēlāk, pamatojoties uz daudzajiem identificētajiem federālajiem likumiem, varētu izdarīt jebkādus secinājumus par uzglabāto informāciju. Mēs strādājam tieši ar šīm atkarībām. Ar tiem nodarbojas vesela datu ieguves joma, izmantojot dažādas meklēšanas metodes un uz to pamata veidotus algoritmus. Izdomāsim, kā var noderēt atrastās funkcionālās atkarības (precīzās vai aptuvenās) jebkuros datos.

Mūsdienās viens no galvenajiem atkarību lietojumiem ir datu tīrīšana. Tas ietver procesu izstrādi “netīro datu” identificēšanai un pēc tam to labošanai. Ievērojami “netīro datu” piemēri ir dublikāti, datu kļūdas vai drukas kļūdas, trūkstošās vērtības, novecojuši dati, papildu atstarpes un tamlīdzīgi.
Datu kļūdas piemērs:
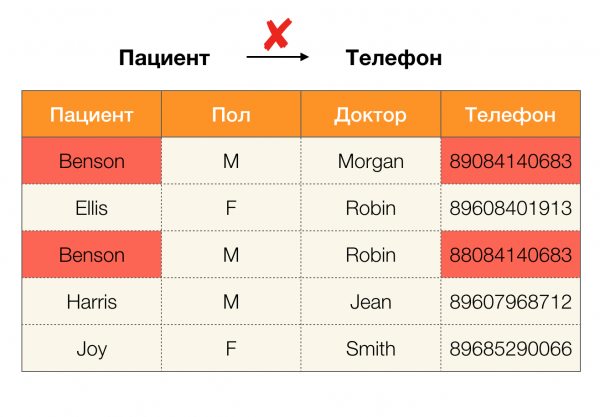
Datu dublikātu piemērs:
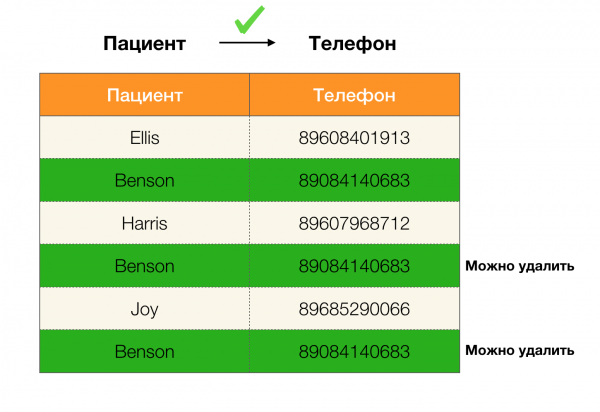
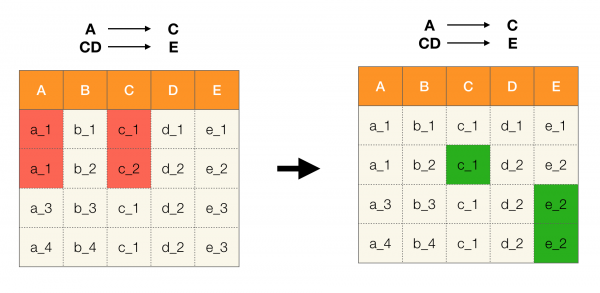
Piemēram, mums ir tabula un federālo likumu kopums, kas ir jāizpilda. Datu tīrīšana šajā gadījumā ietver datu maiņu, lai federālie likumi kļūtu pareizi. Šajā gadījumā modifikāciju skaitam jābūt minimālam (šai procedūrai ir savi algoritmi, uz kuriem mēs šajā rakstā nepievērsīsimies). Tālāk ir sniegts šādas datu pārveidošanas piemērs. Kreisajā pusē ir sākotnējās attiecības, kurās, acīmredzot, nav izpildīti nepieciešamie FL (viena no FL pārkāpuma piemērs ir iezīmēts sarkanā krāsā). Labajā pusē ir atjauninātas attiecības ar zaļajām šūnām, kas parāda mainītās vērtības. Pēc šīs procedūras sāka saglabāt nepieciešamās atkarības.
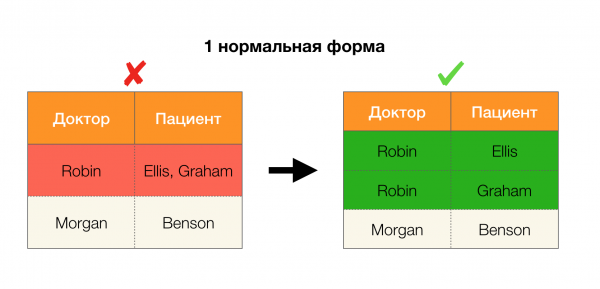
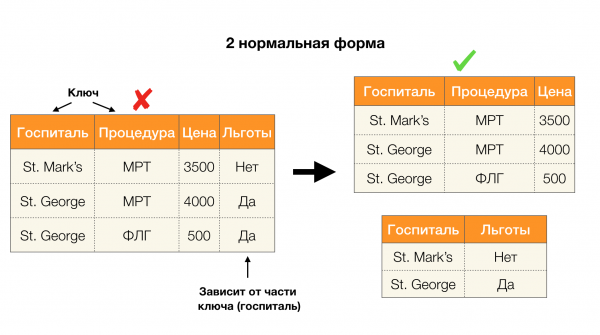
Vēl viena populāra lietojumprogramma ir datu bāzes dizains. Šeit ir vērts atgādināt parastās formas un normalizēšanu. Normalizācija ir process, kurā attiecības tiek saskaņotas ar noteiktu prasību kopumu, no kurām katru savā veidā nosaka normālā forma. Mēs neaprakstīsim dažādu normālo formu prasības (tas tiek darīts jebkurā grāmatā par datu bāzes kursu iesācējiem), bet tikai atzīmēsim, ka katra no tām funkcionālo atkarību jēdzienu izmanto savā veidā. Galu galā FL pēc būtības ir integritātes ierobežojumi, kas tiek ņemti vērā, veidojot datubāzi (šī uzdevuma kontekstā FL dažreiz sauc par superatslēgām).
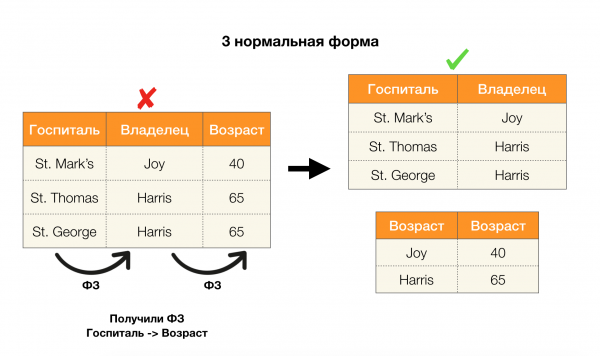
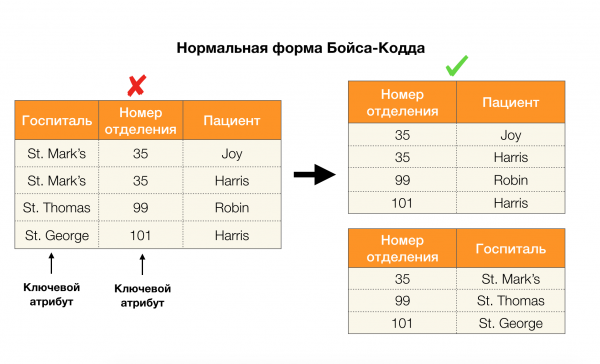
Apskatīsim viņu pieteikumu četrām parastajām veidlapām zemāk esošajā attēlā. Atgādiniet, ka Boyce-Codd parastā forma ir stingrāka nekā trešā forma, bet mazāk stingra nekā ceturtā. Mēs pašlaik neapsveram pēdējo, jo tā formulēšanai ir nepieciešama izpratne par daudzvērtīgām atkarībām, kas šajā rakstā mūs neinteresē.
Vēl viena joma, kurā atkarības ir atradušas savu pielietojumu, ir pazīmju telpas dimensijas samazināšana tādos uzdevumos kā naiva Bayes klasifikatora izveide, nozīmīgu pazīmju identificēšana un regresijas modeļa pārparametrizēšana. Oriģinālrakstos šis uzdevums tiek saukts par liekuma un pazīmju atbilstības noteikšanu [5, 6], un tas tiek risināts, aktīvi izmantojot datu bāzes koncepcijas. Līdz ar šādu darbu parādīšanos var teikt, ka mūsdienās ir pieprasījums pēc risinājumiem, kas ļauj apvienot datubāzi, analīzi un iepriekšminēto optimizācijas problēmu ieviešanu vienā rīkā [7, 8, 9].
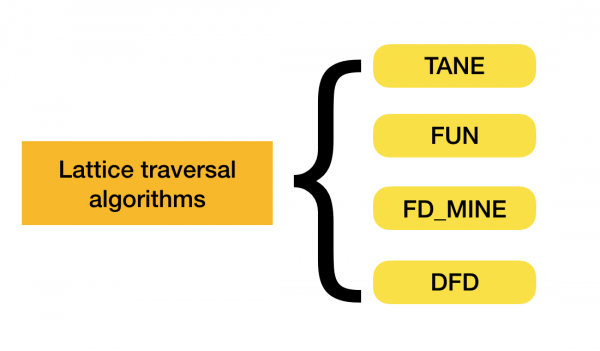
Ir daudz algoritmu (gan modernu, gan ne tik modernu), lai meklētu federālos likumus datu kopā. Šādus algoritmus var iedalīt trīs grupās:
- Algoritmi, kas izmanto algebrisko režģu šķērsošanu (režģa šķērsošanas algoritmi)
- Algoritmi, kuru pamatā ir saskaņoto vērtību meklēšana (atšķirības un vienošanās komplekta algoritmi)
- Algoritmi, kuru pamatā ir pāru salīdzinājumi (atkarības indukcijas algoritmi)
Katra algoritma veida īss apraksts ir parādīts tabulā:
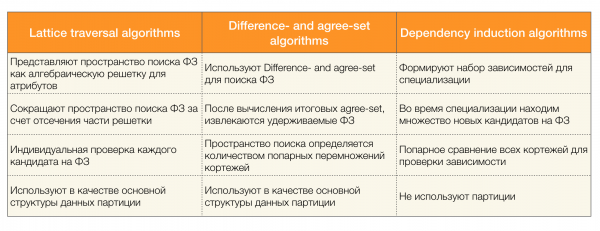
Jūs varat lasīt vairāk par šo klasifikāciju [4]. Tālāk ir sniegti katra veida algoritmu piemēri.
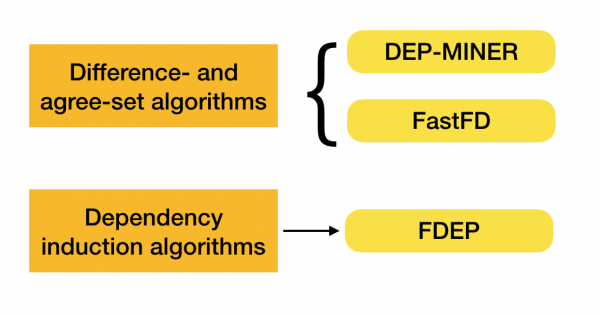
Pašlaik parādās jauni algoritmi, kas apvieno vairākas pieejas funkcionālo atkarību atrašanai. Šādu algoritmu piemēri ir Pyro [2] un HyFD [3]. Viņu darba analīze ir gaidāma turpmākajos šīs sērijas rakstos. Šajā rakstā mēs apskatīsim tikai pamatjēdzienus un lemmu, kas ir nepieciešami, lai izprastu atkarības noteikšanas metodes.
Sāksim ar vienkāršu – atšķirību un piekrišanas kopu, ko izmanto otrā tipa algoritmos. Atšķirību kopa ir kortežu kopa, kurām nav vienādas vērtības, savukārt vienošanās kopa, gluži pretēji, ir korteži, kuriem ir vienādas vērtības. Ir vērts atzīmēt, ka šajā gadījumā mēs apsveram tikai atkarības kreiso pusi.
Vēl viens svarīgs jēdziens, kas tika sastapts iepriekš, ir algebriskais režģis. Tā kā daudzi mūsdienu algoritmi darbojas saskaņā ar šo koncepciju, mums ir nepieciešams priekšstats par to, kas tas ir.
Lai ieviestu režģa jēdzienu, ir nepieciešams definēt daļēji sakārtotu kopu (vai daļēji sakārtotu kopu, saīsināti kā poset).
2. definīcija. Tiek uzskatīts, ka kopa S ir daļēji sakārtota pēc binārās attiecības ⩽, ja visiem a, b, c ∈ S ir izpildītas šādas īpašības:
- Refleksivitāte, tas ir, a ⩽ a
- Antisimetrija, tas ir, ja a ⩽ b un b ⩽ a, tad a = b
- Transitivitāte, tas ir, a ⩽ b un b ⩽ c, no tā izriet, ka a ⩽ c
Šādu relāciju sauc par (vaļīgu) daļējas secības relāciju, un pašu kopu sauc par daļēji sakārtotu kopu. Formālais apzīmējums: ⟨S, ⩽⟩.
Kā vienkāršāko daļēji sakārtotas kopas piemēru varam ņemt visu naturālo skaitļu kopu N ar parasto secības sakarību ⩽. Ir viegli pārbaudīt, vai visas nepieciešamās aksiomas ir izpildītas.
Nozīmīgāks piemērs. Apsveriet visu apakškopu kopu {1, 2, 3}, kas sakārtotas pēc iekļaušanas attiecības ⊆. Patiešām, šī sakarība atbilst visiem daļējas secības nosacījumiem, tāpēc ⟨P ({1, 2, 3}), ⊆⟩ ir daļēji sakārtota kopa. Zemāk redzamajā attēlā ir parādīta šīs kopas struktūra: ja vienu elementu var sasniegt ar bultiņām uz citu elementu, tad tie atrodas secības attiecībās.
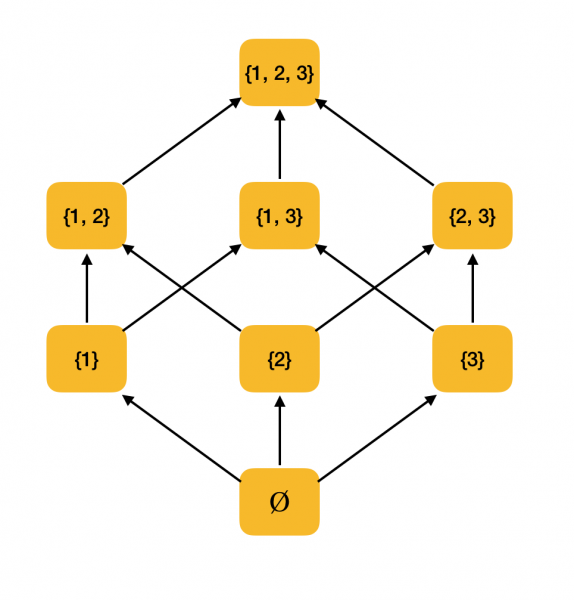
Mums būs vajadzīgas vēl divas vienkāršas definīcijas no matemātikas jomas - supremum un infimum.
3. definīcija. Pieņemsim, ka ⟨S, ⩽⟩ ir daļēji sakārtota kopa, A ⊆ S. A augšējā robeža ir elements u ∈ S tā, ka ∀x ∈ S: x ⩽ u. Lai U ir visu S augšējo robežu kopa. Ja U ir mazākais elements, tad to sauc par supremumu un apzīmē ar sup A.
Precīzas apakšējās robežas jēdziens tiek ieviests līdzīgi.
4. definīcija. Pieņemsim, ka ⟨S, ⩽⟩ ir daļēji sakārtota kopa, A ⊆ S. A infimums ir tāds elements l ∈ S, ka ∀x ∈ S: l ⩽ x. Lai L ir visu S apakšējo robežu kopa. Ja L ir lielākais elements, tad to sauc par infimum un apzīmē kā inf A.
Apsveriet kā piemēru iepriekš daļēji sakārtoto kopu ⟨P ({1, 2, 3}), ⊆⟩ un atrodiet tajā supremum un infimum:
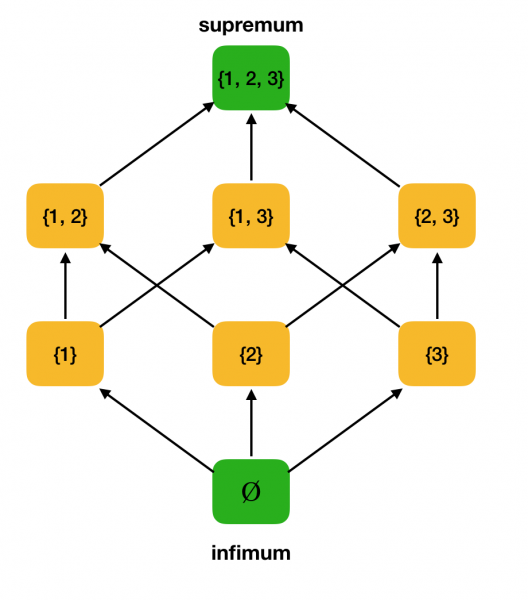
Tagad mēs varam formulēt algebriskā režģa definīciju.
5. definīcija. Pieņemsim, ka ⟨P,⩽⟩ ir daļēji sakārtota kopa tā, ka katrai divu elementu apakškopai ir augšējā un apakšējā robeža. Tad P sauc par algebrisko režģi. Šajā gadījumā sup{x, y} raksta kā x ∨ y, un inf {x, y} kā x ∧ y.
Pārbaudīsim, vai mūsu darba piemērs ⟨P ({1, 2, 3}), ⊆⟩ ir režģis. Patiešām, jebkuram a, b ∈ P ({1, 2, 3}), a∨b = a∪b un a∧b = a∩b. Piemēram, apsveriet kopas {1, 2} un {1, 3} un atrodiet to infimum un supremum. Ja mēs tos krustosim, mēs iegūsim kopu {1}, kas būs infimum. Supremumu iegūstam, tos apvienojot - {1, 2, 3}.
Fizisko problēmu identificēšanas algoritmos meklēšanas telpa bieži tiek attēlota režģa formā, kur viena elementa kopas (lasiet meklēšanas režģa pirmo līmeni, kur atkarību kreisā puse sastāv no viena atribūta) attēlo katru atribūtu. sākotnējās attiecības.
Pirmkārt, mēs aplūkojam formas ∅ → atkarības Viens atribūts. Šī darbība ļauj noteikt, kuri atribūti ir primārās atslēgas (šādiem atribūtiem nav determinantu, un tāpēc kreisā puse ir tukša). Turklāt šādi algoritmi virzās uz augšu pa režģi. Ir vērts atzīmēt, ka nevar šķērsot visu režģi, tas ir, ja ieejai tiek nodots vēlamais maksimālais kreisās puses izmērs, tad algoritms netiks tālāk par līmeni ar šo izmēru.
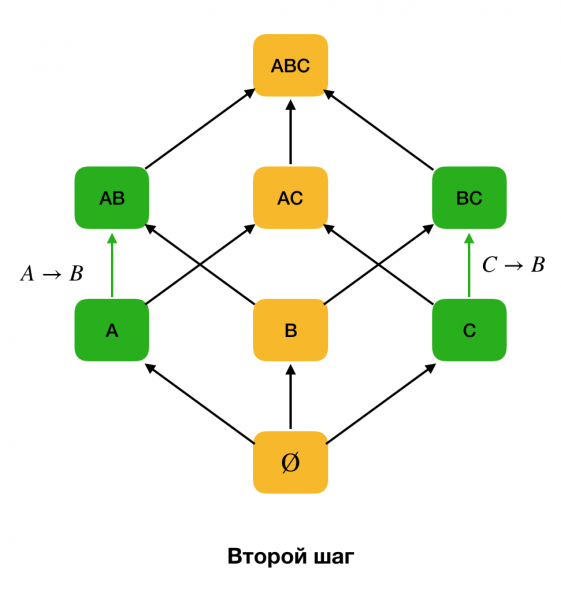
Zemāk redzamajā attēlā parādīts, kā algebrisko režģi var izmantot FZ atrašanas uzdevumā. Šeit katra mala (X, XY) apzīmē atkarību X → Y. Piemēram, mēs esam izgājuši pirmo līmeni un zinām, ka atkarība tiek saglabāta A → B (mēs to parādīsim kā zaļu savienojumu starp virsotnēm A и B). Tas nozīmē, ka tālāk, virzoties uz augšu pa režģi, mēs varam nepārbaudīt atkarību A, C → B, jo tas vairs nebūs minimāls. Tāpat mēs to nepārbaudītu, ja atkarība būtu bijusi C → B.
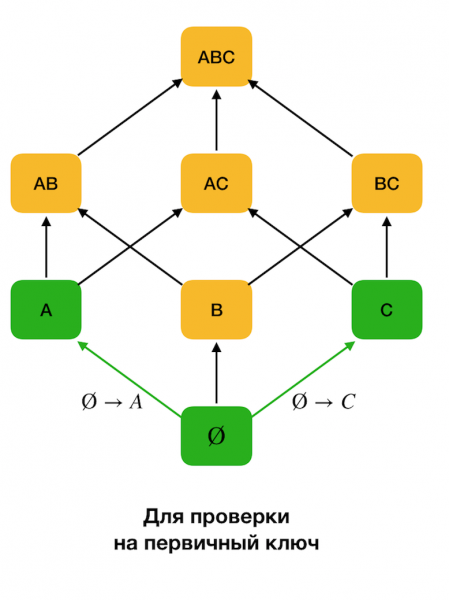
Turklāt, kā likums, visi mūsdienu algoritmi federālo likumu meklēšanai izmanto datu struktūru, piemēram, nodalījumu (sākotnējā avotā - attīrīts nodalījums [1]). Sadalījuma formālā definīcija ir šāda:
6. definīcija. Lai X ⊆ R ir atribūtu kopa relācijai r. Klasteris ir indeksu kopa ar korežiem r, kuriem ir vienāda vērtība X, tas ir, c(t) = {i|ti[X] = t[X]}. Sadalījums ir klasteru kopa, izņemot kopas ar vienības garumu:

Vienkāršiem vārdiem sakot, nodalījums atribūtam X ir sarakstu kopa, kurā katrā sarakstā ir rindu numuri ar vienādām vērtībām X. Mūsdienu literatūrā struktūru, kas attēlo nodalījumus, sauc par pozīciju saraksta indeksu (PLI). Vienības garuma kopas tiek izslēgtas PLI saspiešanas nolūkos, jo tās ir kopas, kurās ir tikai ieraksta numurs ar unikālu vērtību, kuru vienmēr būs viegli identificēt.
Apskatīsim piemēru. Atgriezīsimies pie viena galda ar pacientiem un izveidosim starpsienas kolonnām Pacients и Paul (kreisajā pusē ir parādījusies jauna kolonna, kurā atzīmēti tabulas rindu numuri):
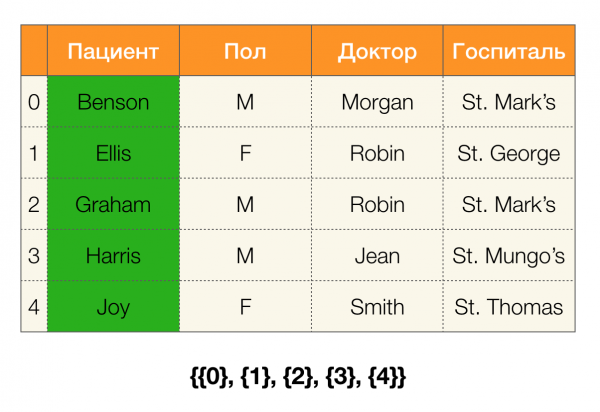
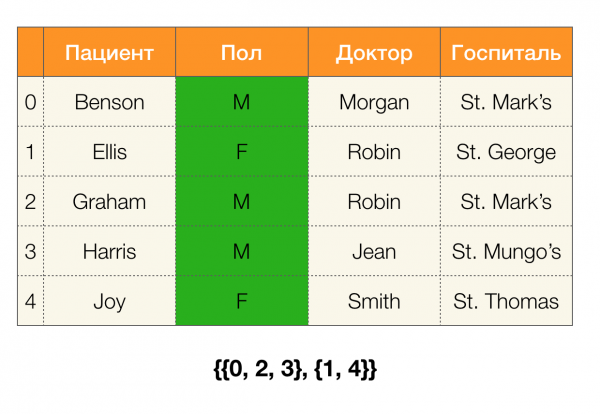
Turklāt saskaņā ar definīciju kolonnas nodalījums Pacients faktiski būs tukšs, jo atsevišķas kopas tiek izslēgtas no nodalījuma.
Starpsienas var iegūt pēc vairākiem atribūtiem. Un ir divi veidi, kā to izdarīt: izejot cauri tabulai, izveidojiet nodalījumu, izmantojot visus nepieciešamos atribūtus vienlaikus, vai izveidojiet to, izmantojot nodalījumu krustošanās darbību, izmantojot atribūtu apakškopu. Federālo likumu meklēšanas algoritmi izmanto otro iespēju.
Vienkāršiem vārdiem sakot, lai, piemēram, iegūtu nodalījumu pa kolonnām Ābece, jūs varat ņemt nodalījumus AC и B (vai jebkuru citu nesaistītu apakškopu kopu) un krusto tās savā starpā. Divu nodalījumu krustošanās operācija izvēlas lielākā garuma kopas, kas ir kopīgas abām starpsienām.
Apskatīsim piemēru:
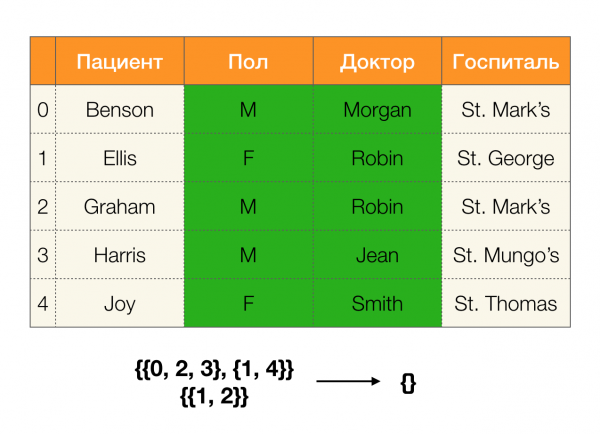

Pirmajā gadījumā mēs saņēmām tukšu nodalījumu. Ja paskatās uzmanīgi uz tabulu, tad patiešām abiem atribūtiem nav identisku vērtību. Ja mēs nedaudz pārveidosim tabulu (labajā pusē), mēs jau iegūsim netukšu krustojumu. Turklāt 1. un 2. rindā faktiski ir vienādas atribūtu vērtības Paul и Ārsts.
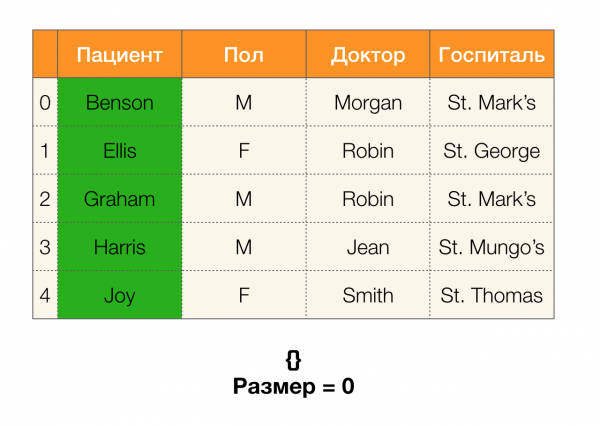
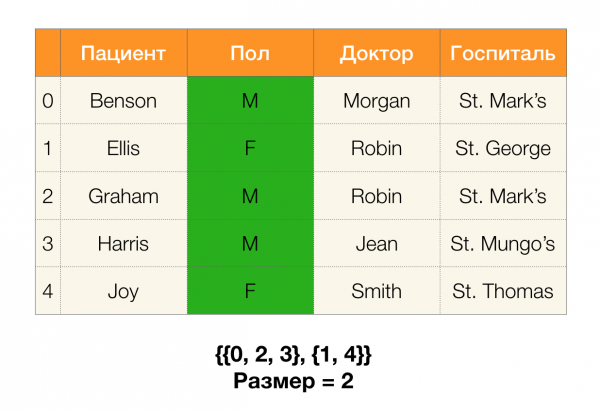
Tālāk mums būs nepieciešams tāds jēdziens kā nodalījuma lielums. Formāli:

Vienkārši sakot, nodalījuma lielums ir nodalījumā iekļauto klasteru skaits (atcerieties, ka atsevišķi klasteri nodalījumā nav iekļauti!):
Tagad mēs varam definēt vienu no galvenajām lemmām, kas dotajiem nodalījumiem ļauj noteikt, vai atkarība tiek saglabāta vai nē:
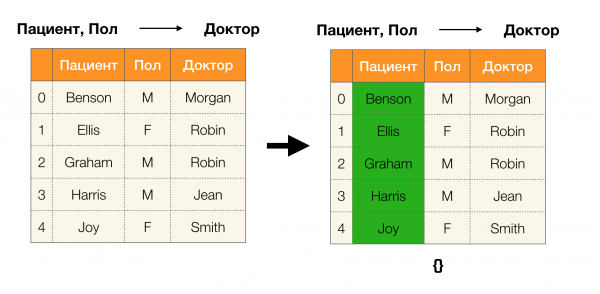
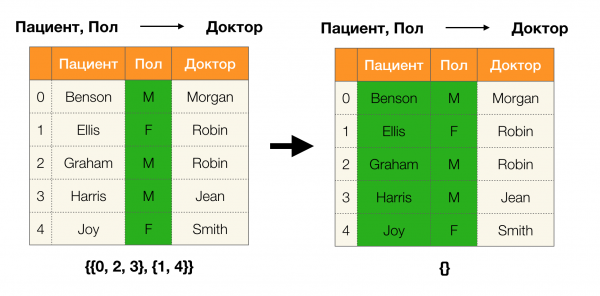
Lemma 1. Atkarība A, B → C pastāv tad un tikai tad

Saskaņā ar lemmu, lai noteiktu, vai pastāv atkarība, ir jāveic četras darbības:
- Aprēķiniet nodalījumu atkarības kreisajai pusei
- Aprēķiniet atkarības labās puses nodalījumu
- Aprēķiniet pirmās un otrās darbības reizinājumu
- Salīdziniet pirmajā un trešajā darbībā iegūto starpsienu izmērus
Tālāk ir sniegts piemērs, kā pārbaudīt, vai atkarība ir spēkā saskaņā ar šo lemmu:
Šajā rakstā mēs apskatījām tādus jēdzienus kā funkcionālā atkarība, aptuvenā funkcionālā atkarība, apskatījām, kur tie tiek izmantoti, kā arī kādi ir fizisko funkciju meklēšanas algoritmi. Mēs arī detalizēti izskatījām pamata, bet svarīgos jēdzienus, kas tiek aktīvi izmantoti mūsdienu algoritmos federālo likumu meklēšanai.
Atsauces:
- Huhtala Y. et al. TANE: efektīvs algoritms funkcionālo un aptuveno atkarību noteikšanai //Datora žurnāls. – 1999. – T. 42. – Nr. 2. – 100.-111.lpp.
- Kruse S., Naumann F. Aptuveno atkarību efektīva atklāšana // Proceedings of the VLDB Endowment. – 2018. – T. 11. – Nr. 7. – 759.-772.lpp.
- Papenbrock T., Naumann F. Hibrīda pieeja funkcionālās atkarības atklāšanā // 2016. gada Starptautiskās datu pārvaldības konferences materiāli. – ACM, 2016. – 821.-833.lpp.
- Papenbroks T. et al. Funkcionālās atkarības atklāšana: septiņu algoritmu eksperimentāls novērtējums //Proceedings of the VLDB Endowment. – 2015. – T. 8. – Nr. 10. – 1082.-1093.lpp.
- Kumar A. et al. Pievienoties vai nepievienoties?: Divreiz domājot par pievienošanos pirms funkciju atlases //2016. gada starptautiskās datu pārvaldības konferences materiāli. – ACM, 2016. – 19.-34.lpp.
- Abo Khamis M. et al. Mācīšanās datu bāzē ar retajiem tensoriem // 37. ACM SIGMOD-SIGACT-SIGAI simpozija par datubāzu sistēmu principiem materiāli. – ACM, 2018. – 325.-340.lpp.
- Hellerstein J. M. et al. MADlib analītikas bibliotēka: vai MAD prasmes, SQL //Proceedings of the VLDB Endowment. – 2012. – T. 5. – Nr. 12. – 1700.-1711.lpp.
- Qin C., Rusu F. Spekulatīvās aproksimācijas terascale sadalītās gradienta nolaišanās optimizācijai // Proceedings of the Fourth Workshop on Data analytics in the Cloud. – ACM, 2015. – 1. lpp.
- Meng X. et al. Mllib: Mašīnmācīšanās apache dzirksteles //Mašīnmācīšanās pētījumu žurnāls. – 2016. – T. 17. – Nr. 1. – 1235.-1241.lpp.
Raksta autori: , pētnieks plkst , и , pētnieks plkst
Avots: www.habr.com
