

Ја продолжуваме серијата написи посветени на проучување на малку познати начини за подобрување на перформансите на „навидум едноставните“ прашања на PostgreSQL:
Немојте да мислите дека не ми се допаѓа толку многу ПРИКЛУЧУВАЈТЕ... :)
Но, често без него, барањето се покажува значително попродуктивно отколку со него. Затоа денес ќе се обидеме ослободете се од ПРИКЛУЧУВАЊЕТО со интензивни ресурси - користење на речник.

Почнувајќи со PostgreSQL 12, некои од ситуациите опишани подолу може да се репродуцираат малку поинаку поради . Ова однесување може да се врати со наведување на клучот
MATERIALIZED.
Многу „факти“ во ограничен речник
Ајде да преземеме многу реална задача за апликација - треба да прикажеме список или активни задачи со испраќачите:
25.01 | Иванов И.И. | Подготовить описание нового алгоритма.
22.01 | Иванов И.И. | Написать статью на Хабр: жизнь без JOIN.
20.01 | Петров П.П. | Помочь оптимизировать запрос.
18.01 | Иванов И.И. | Написать статью на Хабр: JOIN с учетом распределения данных.
16.01 | Петров П.П. | Помочь оптимизировать запрос.
Во апстрактниот свет, авторите на задачите треба да бидат рамномерно распоредени меѓу сите вработени во нашата организација, но во реалноста задачите доаѓаат, по правило, од прилично ограничен број луѓе - „од менаџмент“ до хиерархијата или „од подизведувачи“ од соседните сектори (аналитичари, дизајнери, маркетинг, ...).
Да прифатиме дека во нашата организација од 1000 луѓе, само 20 автори (обично дури и помалку) поставуваат задачи за секој конкретен изведувач и за да се забрза „традиционалното“ барање.
Генератор на скрипти
-- сотрудники
CREATE TABLE person AS
SELECT
id
, repeat(chr(ascii('a') + (id % 26)), (id % 32) + 1) "name"
, '2000-01-01'::date - (random() * 1e4)::integer birth_date
FROM
generate_series(1, 1000) id;
ALTER TABLE person ADD PRIMARY KEY(id);
-- задачи с указанным распределением
CREATE TABLE task AS
WITH aid AS (
SELECT
id
, array_agg((random() * 999)::integer + 1) aids
FROM
generate_series(1, 1000) id
, generate_series(1, 20)
GROUP BY
1
)
SELECT
*
FROM
(
SELECT
id
, '2020-01-01'::date - (random() * 1e3)::integer task_date
, (random() * 999)::integer + 1 owner_id
FROM
generate_series(1, 100000) id
) T
, LATERAL(
SELECT
aids[(random() * (array_length(aids, 1) - 1))::integer + 1] author_id
FROM
aid
WHERE
id = T.owner_id
LIMIT 1
) a;
ALTER TABLE task ADD PRIMARY KEY(id);
CREATE INDEX ON task(owner_id, task_date);
CREATE INDEX ON task(author_id);
Да ги прикажеме последните 100 задачи за одреден извршител:
SELECT
task.*
, person.name
FROM
task
LEFT JOIN
person
ON person.id = task.author_id
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100; 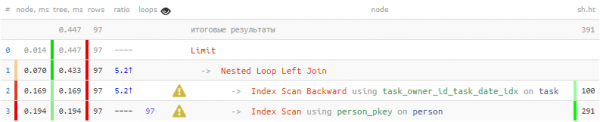
Излегува дека 1/3 вкупно време и 3/4 читања страници со податоци се направени само за да се бара авторот 100 пати - за секоја излезна задача. Но, знаеме дека меѓу овие стотици само 20 различни - Дали е можно да се искористи ова знаење?
hstore-речник
Ајде да ги искористиме за да генерирате „речник“ клуч-вредност:
CREATE EXTENSION hstoreТреба само да го ставиме ликот на идентитетот на авторот и неговото име во речникот за да можеме потоа да го извлечеме користејќи го овој клуч:
-- формируем целевую выборку
WITH T AS (
SELECT
*
FROM
task
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100
)
-- формируем словарь для уникальных значений
, dict AS (
SELECT
hstore( -- hstore(keys::text[], values::text[])
array_agg(id)::text[]
, array_agg(name)::text[]
)
FROM
person
WHERE
id = ANY(ARRAY(
SELECT DISTINCT
author_id
FROM
T
))
)
-- получаем связанные значения словаря
SELECT
*
, (TABLE dict) -> author_id::text -- hstore -> key
FROM
T; 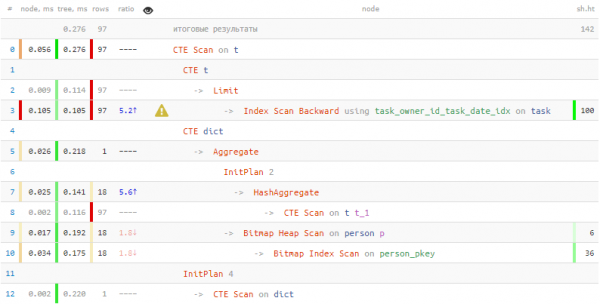
Потрошени за добивање информации за лица 2 пати помалку време и 7 пати помалку читање податоци! Покрај „вокабуларот“, она што ни помогна да ги постигнеме овие резултати беше масовно пребарување на записи од табелата во едно поминување со користење = ANY(ARRAY(...)).
Записи во табела: серијализација и десериализација
Но, што ако треба да зачуваме не само едно поле за текст, туку цел запис во речникот? Во овој случај, способноста на PostgreSQL ќе ни помогне третирајте го записот во табелата како единствена вредност:
...
, dict AS (
SELECT
hstore(
array_agg(id)::text[]
, array_agg(p)::text[] -- магия #1
)
FROM
person p
WHERE
...
)
SELECT
*
, (((TABLE dict) -> author_id::text)::person).* -- магия #2
FROM
T;Ајде да погледнеме што се случуваше овде:
- Зедовме стр како псевдоним на записот во табелата со целосна личност и состави низа од нив.
- Оваа низата снимки беше преработена до низа текстуални низи (лице[]::текст[]) за да ја сместиме во речникот hstore како низа од вредности.
- Кога ќе добиеме поврзана евиденција, ние извлечено од речникот со клуч како текстуална низа.
- Ни треба текст се претвори во вредност од типот на табелата лице (за секоја табела автоматски се креира тип со исто име).
- „Проширете го“ напишаниот запис во колони користејќи
(...).*.
json речник
Но, таков трик како што применивме погоре нема да работи ако не постои соодветен тип на маса за да се направи „кастинг“. Точно истата ситуација ќе се појави, а ако се обидеме да искористиме ред CTE, а не „вистинска“ табела.
Во овој случај тие ќе ни помогнат :
...
, p AS ( -- это уже CTE
SELECT
*
FROM
person
WHERE
...
)
, dict AS (
SELECT
json_object( -- теперь это уже json
array_agg(id)::text[]
, array_agg(row_to_json(p))::text[] -- и внутри json для каждой строки
)
FROM
p
)
SELECT
*
FROM
T
, LATERAL(
SELECT
*
FROM
json_to_record(
((TABLE dict) ->> author_id::text)::json -- извлекли из словаря как json
) AS j(name text, birth_date date) -- заполнили нужную нам структуру
) j; Треба да се забележи дека при опишување на целната структура, не можеме да ги наведеме сите полиња од изворната низа, туку само оние што навистина ни се потребни. Ако имаме „мајчин“ табела, тогаш подобро е да ја користиме функцијата json_populate_record.
Сè уште еднаш пристапуваме до речникот, но Трошоците за json-[де]сериализација се доста високи, затоа, разумно е да се користи овој метод само во некои случаи кога „чесниот“ CTE Scan се покажува полошо.
Тестирање на перформансите
Значи, добивме два начина за серијализирање на податоците во речник − hstore/json_object. Дополнително, самите низи клучеви и вредности може да се генерираат на два начина, со внатрешна или надворешна конверзија во текст: array_agg (i:: текст) / array_agg (i):: текст[].
Ајде да ја провериме ефективноста на различните видови серијализација користејќи чисто синтетички пример - серијализираат различни броеви на клучеви:
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, ...) i
)
TABLE dict;Сценарио за евалуација: серијализација
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
TABLE dict
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 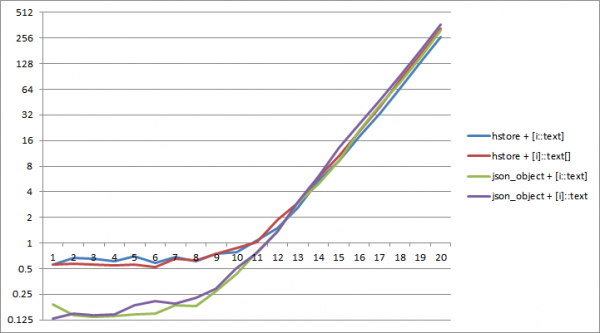
На PostgreSQL 11, до приближно големина на речник од 2^12 копчиња Сериизацијата во json трае помалку време. Во овој случај, најефективната е комбинацијата на json_object и конверзија на „внатрешна“ тип array_agg(i::text).
Сега да се обидеме да ја прочитаме вредноста на секој клуч 8 пати - на крајот на краиштата, ако не пристапувате до речникот, тогаш зошто е потребен?
Скрипта за евалуација: читање од речник
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
json_object(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
SELECT
(TABLE dict) -> (i % ($$ || (1 << v) || $$) + 1)::text
FROM
generate_series(1, $$ || (1 << (v + 3)) || $$) i
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 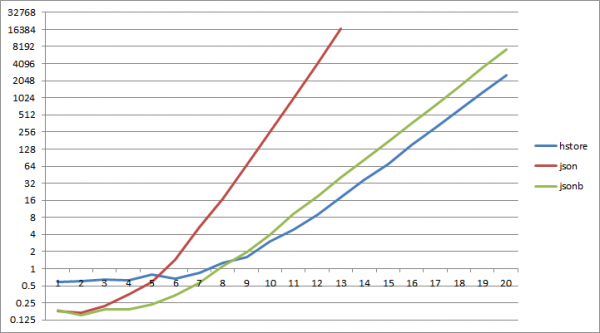
И... веќе приближно со 2^6 копчиња, читањето од речник json почнува да губи повеќекратно читање од hstore, за jsonb истото се случува на 2^9.
Конечни заклучоци:
- ако треба да го направиш тоа ПРИКЛУЧУВАЈ се со повеќекратни записи кои се повторуваат - подобро е да се користи „речник“ на табелата
- ако се очекува вашиот речник мал и нема да прочитате многу од него - можете да користите json[b]
- во сите други случаи hstore + array_agg (i:: текст) ќе биде поефективен
Извор: www.habr.com
