

Hello, Habr! Kami telah hidup dalam situasi yang sangat menarik selama beberapa bulan kebelakangan ini dan saya ingin berkongsi kisah penskalaan infrastruktur kami. Pada masa ini, SberMarket telah berkembang dalam pesanan 4 kali ganda dan melancarkan perkhidmatan di 17 bandar baharu. Pertumbuhan pesat dalam permintaan untuk penghantaran barangan runcit memerlukan kami untuk meningkatkan infrastruktur kami. Baca tentang kesimpulan yang paling menarik dan berguna di bawah potongan.

Nama saya Dima Bobylev, saya pengarah teknikal SberMarket. Memandangkan ini adalah catatan pertama di blog kami, saya akan mengatakan beberapa perkataan tentang diri saya dan syarikat. Musim luruh lalu saya mengambil bahagian dalam pertandingan untuk pemimpin muda Runet. Untuk pertandingan I tentang bagaimana kami di SberMarket melihat budaya dalaman dan pendekatan kepada pembangunan perkhidmatan. Dan walaupun saya tidak berjaya memenangi pertandingan itu, saya merumuskan sendiri prinsip asas untuk pembangunan ekosistem IT.
Apabila menguruskan pasukan, adalah penting untuk memahami dan mencari keseimbangan antara keperluan perniagaan dan keperluan setiap pembangun individu. Kini SberMarket berkembang 13 kali tahun ke tahun, dan ini menjejaskan produk, memerlukannya untuk sentiasa meningkatkan volum dan kadar pembangunan. Walaupun begitu, kami memperuntukkan masa yang cukup kepada pembangun untuk analisis awal dan pengekodan kualiti. Pendekatan yang dibentuk membantu bukan sahaja dalam mencipta produk yang berfungsi, tetapi juga dalam penskalaan dan pembangunan selanjutnya. Hasil daripada pertumbuhan ini, SberMarket telah menjadi peneraju dalam perkhidmatan penghantaran barangan runcit: kami menghantar kira-kira 18 ribu pesanan sehari setiap hari, walaupun pada awal Februari terdapat kira-kira 3500.

Pada suatu hari, seorang pelanggan meminta kurier SberMarket untuk menghantar barangan runcit kepadanya tanpa sentuhan - terus ke balkoni
Tetapi mari kita beralih kepada spesifik. Sejak beberapa bulan lalu, kami telah secara aktif meningkatkan infrastruktur syarikat kami. Keperluan ini dijelaskan oleh faktor luaran dan dalaman. Seiring dengan pengembangan pangkalan pelanggan, bilangan kedai yang disambungkan meningkat daripada 90 pada awal tahun kepada lebih daripada 200 menjelang pertengahan Mei. Kami, sudah tentu, telah bersedia, menyimpan infrastruktur utama, dan kami mengira kemungkinan penskalaan menegak dan mendatar semua mesin maya yang dihoskan dalam awan Yandex. Walau bagaimanapun, amalan telah menunjukkan: "Segala sesuatu yang boleh menjadi salah, akan menjadi salah." Dan hari ini saya ingin berkongsi situasi paling menarik yang telah berlaku selama beberapa minggu ini. Saya harap pengalaman kami akan berguna kepada anda.
Hamba dalam kesediaan tempur sepenuhnya
Malah sebelum permulaan wabak, kami berhadapan dengan peningkatan dalam bilangan permintaan kepada pelayan bahagian belakang kami. Trend memesan barangan runcit untuk penghantaran ke rumah mula mendapat momentum, dan dengan pengenalan langkah pengasingan diri pertama akibat COVID-19, beban kerja meningkat secara mendadak sepanjang hari. Terdapat keperluan untuk memunggah pelayan induk pangkalan data utama dengan cepat dan memindahkan beberapa permintaan baca ke pelayan replika (hamba).
Kami bersedia untuk langkah ini lebih awal, dan 2 pelayan hamba telah pun dilancarkan untuk gerakan sedemikian. Ia digunakan terutamanya untuk tugas kelompok menjana suapan maklumat untuk bertukar-tukar data dengan rakan kongsi. Proses-proses ini menimbulkan beban tambahan dan agak betul dikeluarkan daripada persamaan beberapa bulan sebelumnya.
Memandangkan replikasi berlaku pada Slave, kami mematuhi konsep bahawa aplikasi hanya boleh berfungsi dengannya dalam mod baca sahaja. Pelan Pemulihan Bencana mengandaikan bahawa sekiranya berlaku bencana, kita hanya boleh memasang Hamba sebagai ganti Tuan dan menukar semua permintaan tulis dan baca kepada Hamba. Walau bagaimanapun, kami juga ingin menggunakan replika untuk keperluan jabatan analitik, jadi pelayan tidak ditukar sepenuhnya kepada status baca sahaja, tetapi setiap hos mempunyai set pengguna sendiri, dan sesetengahnya mempunyai hak menulis untuk menyimpan hasil pengiraan perantaraan.
Sehingga tahap beban tertentu, kami mempunyai induk yang mencukupi untuk menulis dan membaca semasa memproses permintaan http. Pada pertengahan bulan Mac, sebaik sahaja Sbermarket memutuskan untuk beralih sepenuhnya kepada kerja jauh, RPS kami mula berkembang dengan pesat. Semakin ramai pelanggan kami melakukan pengasingan diri atau bekerja dari rumah, yang menjejaskan penunjuk beban kerja kami.
Prestasi "tuan" tidak lagi mencukupi, jadi kami mula memindahkan beberapa permintaan bacaan yang paling berat kepada replika. Untuk mengarahkan permintaan tulis secara telus kepada tuan dan membaca permintaan kepada hamba, kami menggunakan permata delima "" Kami mencipta pengguna khas dengan postfix _readonly tanpa hak tulis. Tetapi disebabkan ralat dalam konfigurasi salah satu hos, beberapa permintaan tulis pergi ke pelayan hamba bagi pihak pengguna yang mempunyai hak yang sesuai.
Masalahnya tidak muncul dengan serta-merta, kerana... beban yang meningkat meningkatkan ketinggalan hamba. Ketidakkonsistenan data ditemui pada waktu pagi apabila, selepas import setiap malam, hamba tidak "mengejar" tuan. Kami mengaitkan ini dengan beban tinggi pada perkhidmatan itu sendiri dan import yang dikaitkan dengan pelancaran kedai baharu. Tetapi menghantar data dengan kelewatan berbilang jam tidak boleh diterima dan kami menukar proses kepada hamba analitik kedua, kerana ia mempunyaiоsumber yang lebih besar dan tidak dimuatkan dengan permintaan baca (iaitu cara kami menjelaskan kepada diri kami kekurangan lag replikasi).
Apabila kita mengetahui sebab-sebab untuk "penyebaran" hamba utama, yang analitikal telah gagal untuk sebab yang sama. Walaupun terdapat dua pelayan tambahan yang kami merancang untuk memindahkan beban sekiranya berlaku kegagalan induk, disebabkan oleh ralat yang malang ternyata tidak ada yang tersedia pada saat kritikal.
Tetapi oleh kerana kami bukan sahaja membuang pangkalan data (pemulihan pada masa itu mengambil masa kira-kira 5 jam), tetapi juga petikan pelayan induk, kami berjaya melancarkan replika dalam masa 2 jam. Benar, selepas ini kami berdepan dengan log replikasi berguling untuk masa yang lama (kerana proses berjalan dalam mod satu benang, tetapi itu cerita yang sama sekali berbeza).
Kesimpulan: Selepas kejadian sedemikian, menjadi jelas bahawa adalah perlu untuk meninggalkan amalan mengehadkan penulisan untuk pengguna dan mengisytiharkan keseluruhan pelayan baca sahaja. Dengan pendekatan ini, tidak ada keraguan bahawa replika akan tersedia pada masa kritikal.
Mengoptimumkan walaupun satu pertanyaan berat boleh menghidupkan semula pangkalan data
Walaupun kami sentiasa mengemas kini katalog di tapak, permintaan yang kami hantar ke pelayan Slave membenarkan sedikit ketinggalan daripada Master. Masa di mana kami menemui dan menghapuskan masalah hamba "tiba-tiba meninggalkan jarak" adalah lebih daripada "penghalang psikologi" (pada masa ini harga mungkin telah dikemas kini, dan pelanggan akan melihat data lapuk), dan kami terpaksa tukar semua permintaan kepada pelayan pangkalan data utama. Akibatnya, laman web itu perlahan... tetapi sekurang-kurangnya ia berfungsi. Dan semasa Slave pulih, kami tidak mempunyai pilihan selain pengoptimuman.
Semasa pelayan Hamba sedang pulih, minit berlalu perlahan-lahan, Master tetap terbeban, dan kami melakukan semua usaha kami untuk mengoptimumkan tugas aktif mengikut "Peraturan Pareto": kami memilih permintaan TOP yang menjana sebahagian besar beban dan mula menala . Ini dilakukan dengan segera.
Kesan yang menarik ialah MySQL, dimuatkan kepada kapasiti, bertindak balas walaupun sedikit peningkatan dalam proses. Mengoptimumkan beberapa pertanyaan yang menghasilkan hanya 5% daripada jumlah beban telah menunjukkan beban CPU yang ketara. Hasilnya, kami dapat menyediakan bekalan sumber yang boleh diterima untuk Master untuk bekerja dengan pangkalan data dan mendapatkan masa yang diperlukan untuk memulihkan replika.
Kesimpulan: Walaupun pengoptimuman kecil membolehkan anda "bertahan" di bawah beban berlebihan selama beberapa jam. Ini sudah cukup untuk kami memulihkan pelayan dengan replika. Dengan cara ini, kami akan membincangkan bahagian teknikal pengoptimuman pertanyaan dalam salah satu siaran berikut. Jadi sila langgan blog kami jika anda rasa ia berguna.
Mengadakan pemantauan prestasi perkhidmatan rakan kongsi
Kami memproses pesanan daripada pelanggan, dan oleh itu perkhidmatan kami sentiasa berinteraksi dengan API pihak ketiga - ini adalah pintu masuk untuk menghantar SMS, platform pembayaran, sistem penghalaan, geocoder, Perkhidmatan Cukai Persekutuan dan banyak sistem lain. Dan apabila beban mula berkembang dengan pesat, kami mula menghadapi had API perkhidmatan rakan kongsi kami, yang tidak pernah kami fikirkan sebelum ini.
Melebihi kuota perkhidmatan rakan kongsi secara tidak dijangka boleh menyebabkan masa henti anda sendiri. Banyak API menyekat pelanggan yang melebihi had, dan dalam beberapa kes, terlalu banyak permintaan boleh membebankan pengeluaran rakan kongsi.
Sebagai contoh, apabila bilangan penghantaran bertambah, perkhidmatan yang disertakan tidak dapat menampung tugas mengedarkannya dan menentukan laluan. Akibatnya, ternyata pesanan telah dibuat, tetapi perkhidmatan yang mencipta laluan itu tidak berfungsi. Harus dikatakan bahawa ahli logistik kami melakukan yang hampir mustahil di bawah keadaan ini, dan interaksi jelas pasukan membantu mengimbangi kegagalan perkhidmatan sementara. Tetapi adalah tidak realistik untuk memproses jumlah pesanan sedemikian secara manual sepanjang masa, dan selepas beberapa lama kita akan berhadapan dengan jurang yang tidak boleh diterima antara pesanan dan pelaksanaannya.
Beberapa langkah organisasi telah diambil dan kerja pasukan yang diselaraskan dengan baik membantu mendapatkan masa sementara kami bersetuju dengan syarat baharu dan menunggu pemodenan perkhidmatan daripada beberapa rakan kongsi. Terdapat API lain yang mempunyai daya tahan tinggi dan kadar keterlaluan sekiranya trafik tinggi. Sebagai contoh, pada mulanya kami menggunakan satu API pemetaan yang terkenal untuk menentukan alamat tempat penghantaran. Tetapi pada akhir bulan kami menerima bil kemas untuk hampir 2 juta rubel. Selepas itu, mereka memutuskan untuk menggantikannya dengan cepat. Saya tidak akan terlibat dalam pengiklanan, tetapi saya akan mengatakan bahawa perbelanjaan kami telah menurun dengan ketara.
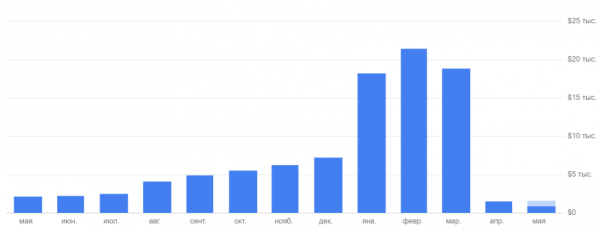
Kesimpulan: Adalah penting untuk memantau keadaan operasi semua perkhidmatan rakan kongsi dan mengingatinya. Walaupun hari ini nampaknya mereka "dengan margin yang besar" untuk anda, ini tidak bermakna esok mereka tidak akan menjadi penghalang kepada pertumbuhan. Dan, sudah tentu, adalah lebih baik untuk bersetuju dengan syarat kewangan peningkatan permintaan untuk perkhidmatan itu terlebih dahulu.
Kadang-kadang ternyata ""(c) tidak membantu
Kami terbiasa dengan "gags" dalam pangkalan data utama atau pada pelayan aplikasi, tetapi apabila menskalakan, masalah boleh muncul di tempat yang tidak dijangka. Untuk carian teks penuh di tapak, kami menggunakan enjin Apache Solr. Apabila beban meningkat, kami mencatatkan penurunan dalam masa tindak balas, dan beban pemproses pelayan sudah mencapai 100%. Apa yang lebih mudah - mari berikan bekas dengan Solr lebih banyak sumber.
Daripada peningkatan prestasi yang dijangkakan, pelayan hanya "mati". Ia serta-merta dimuatkan pada 100% dan bertindak balas dengan lebih perlahan. Pada mulanya kami mempunyai 2 teras dan 2 GB RAM. Kami memutuskan untuk melakukan perkara yang biasanya membantu - kami memberikan pelayan 8 teras dan 32 GB. Segala-galanya menjadi lebih teruk (kami akan memberitahu anda dengan tepat bagaimana dan mengapa dalam siaran berasingan).
Sepanjang beberapa hari, kami mengetahui selok-belok isu ini dan mencapai prestasi optimum dengan 8 teras dan 32 GB. Konfigurasi ini membolehkan kami terus meningkatkan beban hari ini, yang sangat penting, kerana pertumbuhan bukan sahaja pada pelanggan, tetapi juga dalam bilangan kedai yang disambungkan - dalam 2 bulan bilangan mereka telah meningkat dua kali ganda.
Kesimpulan: Kaedah standard seperti "tambah lebih banyak besi" tidak selalu berfungsi. Jadi apabila menskalakan mana-mana perkhidmatan, anda perlu mempunyai pemahaman yang baik tentang cara ia menggunakan sumber dan menguji operasinya dalam keadaan baharu terlebih dahulu.
Stateless adalah kunci kepada penskalaan mendatar yang mudah
Secara umum, pasukan kami mengikut pendekatan yang terkenal: perkhidmatan tidak sepatutnya mempunyai keadaan dalaman (tanpa kewarganegaraan) dan harus bebas daripada persekitaran pelaksanaan. Ini membolehkan kami mengatasi pertumbuhan beban dengan hanya penskalaan mendatar. Tetapi kami mempunyai satu perkhidmatan pengecualian - pengendali untuk tugas latar belakang yang panjang. Beliau terlibat dalam menghantar e-mel dan sms, memproses acara, menjana suapan, mengimport harga dan stok, dan memproses imej. Kebetulan ia bergantung pada storan fail tempatan dan berada dalam satu salinan.
Apabila bilangan tugas dalam baris gilir pemproses meningkat (dan ini secara semula jadi berlaku dengan peningkatan bilangan pesanan), prestasi hos di mana pemproses dan storan fail terletak menjadi faktor pengehad. Akibatnya, mengemas kini pelbagai dan harga, menghantar pemberitahuan kepada pengguna dan banyak lagi fungsi kritikal yang tersekat dalam baris gilir berhenti. Pasukan Ops dengan cepat memindahkan storan fail ke storan rangkaian seperti S3, dan ini membolehkan kami menaikkan beberapa mesin berkuasa untuk menskala pemproses tugas latar belakang.
Kesimpulan: Peraturan Tanpa Kewarganegaraan mesti dipatuhi untuk semua komponen tanpa pengecualian, walaupun nampaknya "kita pasti tidak akan dapat menentang di sini." Adalah lebih baik untuk meluangkan sedikit masa untuk mengatur operasi semua sistem dengan betul daripada menulis semula kod dengan tergesa-gesa dan membetulkan perkhidmatan yang terlebih beban.
7 prinsip untuk pertumbuhan intensif
Walaupun terdapat kapasiti tambahan, kami telah melangkah ke atas beberapa kesilapan dalam proses pertumbuhan. Pada masa ini, bilangan pesanan meningkat lebih daripada 4 kali ganda. Kini kami sudah menghantar lebih daripada 17 pesanan setiap hari di 000 bandar dan merancang untuk mengembangkan geografi dengan lebih jauh lagi - pada separuh pertama 62 perkhidmatan itu dijangka akan dilancarkan di seluruh Rusia. Untuk mengatasi beban kerja yang semakin meningkat, dengan mengambil kira kon kami yang sudah penuh, kami telah membangunkan 2020 prinsip asas untuk bekerja dalam keadaan pertumbuhan berterusan:
- Pengurusan kemalangan. Kami mencipta papan di Jira, di mana setiap kejadian ditunjukkan dalam bentuk tiket. Ini akan membantu dalam mengutamakan dan melaksanakan tugas yang berkaitan dengan insiden. Lagipun, pada dasarnya, ia tidak menakutkan untuk membuat kesilapan, tetapi ia menakutkan untuk membuat kesilapan dua kali pada masa yang sama. Bagi kes-kes di mana kejadian berulang sebelum punca boleh diperbetulkan, arahan untuk tindakan harus sedia, kerana semasa beban berat adalah penting untuk bertindak balas dengan kelajuan kilat.
- Pemantauan diperlukan untuk semua elemen infrastruktur tanpa pengecualian. Terima kasih kepadanya bahawa kami dapat meramalkan pertumbuhan beban dan dengan betul memilih "kehampaan" untuk mengutamakan penyingkiran. Kemungkinan besar, di bawah beban yang tinggi, semua yang anda tidak pernah fikirkan akan pecah atau mula perlahan. Oleh itu, adalah lebih baik untuk membuat makluman baharu sejurus selepas insiden pertama berlaku untuk memantau dan menjangkanya.
- Makluman yang betul hanya perlu apabila beban meningkat secara mendadak. Pertama, mereka mesti melaporkan apa sebenarnya yang rosak. Kedua, tidak sepatutnya terdapat banyak makluman, kerana banyak amaran tidak kritikal menyebabkan mengabaikan semua makluman sama sekali.
- Permohonan mestilah tanpa kewarganegaraan. Kami yakin bahawa tidak ada pengecualian untuk peraturan ini. Kami memerlukan kebebasan sepenuhnya daripada persekitaran runtime. Untuk melakukan ini, anda boleh menyimpan data kongsi dalam pangkalan data atau, sebagai contoh, terus dalam S3. Lebih baik, ikut peraturan.. Semasa peningkatan masa yang mendadak, tiada cara untuk mengoptimumkan kod, dan anda perlu mengatasi beban dengan meningkatkan sumber pengkomputeran dan penskalaan mendatar secara langsung.
- Kuota dan prestasi perkhidmatan luar. Dengan pertumbuhan pesat, masalah mungkin timbul bukan sahaja dalam infrastruktur anda, tetapi juga dalam perkhidmatan luaran. Perkara yang paling menjengkelkan adalah apabila ini berlaku bukan kerana kegagalan, tetapi kerana mencapai kuota atau had. Jadi perkhidmatan luaran harus berskala sama seperti yang anda lakukan.
- Asingkan proses dan baris gilir. Ini banyak membantu apabila terdapat sekatan di salah satu pintu masuk. Kami tidak akan mengalami kelewatan dalam pemindahan data jika baris gilir penghantaran SMS penuh tidak mengganggu pertukaran pemberitahuan antara sistem maklumat. Dan lebih mudah untuk menambah bilangan pekerja jika mereka bekerja secara berasingan.
- Realiti kewangan. Apabila terdapat pertumbuhan pesat dalam aliran data, tidak ada masa untuk memikirkan tentang tarif dan langganan. Tetapi anda perlu mengingati mereka, terutamanya jika anda sebuah syarikat kecil. Pemilik mana-mana API, serta penyedia pengehosan anda, boleh menanggung bil yang besar. Jadi anda perlu membaca kontrak dengan teliti.
Kesimpulan
Bukan tanpa kerugian, tetapi kami berjaya bertahan di peringkat ini, dan hari ini kami cuba mematuhi semua prinsip yang ditemui, dan setiap mesin mempunyai keupayaan untuk meningkatkan prestasi x4 dengan mudah untuk menghadapi beberapa kejadian yang tidak dijangka.
Dalam siaran berikut, kami akan berkongsi pengalaman kami dalam menyiasat kemerosotan prestasi dalam Apache Solr, dan juga bercakap tentang pengoptimuman pertanyaan dan cara interaksi dengan Perkhidmatan Cukai Persekutuan membantu syarikat menjimatkan wang. Langgan blog kami supaya anda tidak terlepas apa-apa, dan beritahu kami dalam ulasan jika anda mengalami masalah yang sama semasa pertumbuhan trafik.

Hanya pengguna berdaftar boleh mengambil bahagian dalam tinjauan. , Sama-sama.
Pernahkah anda mengalami kelembapan/penurunan dalam perkhidmatan disebabkan peningkatan mendadak dalam beban disebabkan oleh:
-
55,6% Ketidakupayaan untuk menambah sumber pengkomputeran dengan cepat10
-
16,7% Had infrastruktur penyedia hosting3
-
33,3% Had API pihak ketiga6
-
27,8% Pelanggaran prinsip tanpa kerakyatan bagi penggunaannya5
-
88,9% Kod perkhidmatan sendiri yang tidak optimum16
18 pengguna mengundi. 6 pengguna berpantang.
Sumber: www.habr.com
