

Catatan. terjemahArtikel ini, yang ditulis oleh Galo Navarro, Jurutera Perisian Utama di syarikat Eropah Adevinta, adalah "penyiasatan" yang menarik dan memberi pengajaran dalam bidang operasi infrastruktur. Tajuk asalnya telah dipinda sedikit dalam terjemahan atas sebab yang penulis jelaskan pada permulaannya.
Nota dari penulis: Ia kelihatan seperti penerbitan ini Artikel ini telah mendapat perhatian yang jauh lebih daripada yang dijangkakan. Saya masih mendapat komen marah tentang tajuk yang mengelirukan dan beberapa pembaca kecewa. Saya faham sebab-sebabnya, jadi dengan risiko merosakkan keseluruhan cerita, saya ingin menerangkan tentang artikel ini. Apabila pasukan berhijrah ke Kubernetes, saya memerhatikan satu perkara yang ingin tahu: setiap kali masalah timbul (contohnya, peningkatan kependaman selepas penghijrahan), perkara pertama yang mereka salahkan ialah Kubernetes, tetapi ternyata pengaturcara sebenarnya tidak dipersalahkan. Artikel ini adalah mengenai satu kes sedemikian. Tajuknya menggemakan seruan daripada salah seorang pembangun kami (kemudian anda akan melihat bahawa Kubernetes tidak ada kaitan dengannya). Anda tidak akan menemui sebarang pendedahan yang mengejutkan tentang Kubernetes, tetapi anda boleh mengharapkan beberapa pengajaran yang baik tentang sistem yang kompleks.
Beberapa minggu yang lalu, pasukan saya telah memindahkan satu perkhidmatan mikro kepada platform teras yang merangkumi CI/CD, persekitaran pengeluaran berasaskan Kubernetes, metrik dan ciri berguna yang lain. Ini adalah projek perintis: kami merancang untuk membinanya dan memindahkan kira-kira 150 lagi perkhidmatan dalam beberapa bulan akan datang. Semua perkhidmatan ini menguasai beberapa pasaran dalam talian terbesar di Sepanyol (Infojobs, Fotocasa dan lain-lain).
Selepas kami menggunakan aplikasi itu ke Kubernetes dan mengubah hala beberapa lalu lintas kepadanya, kami berhadapan dengan kejutan yang membimbangkan. Latensi (pendaman) Bilangan permintaan dalam Kubernetes adalah 10 kali lebih tinggi daripada EC2. Akhirnya, adalah perlu untuk sama ada mencari penyelesaian kepada masalah ini atau meninggalkan pemindahan perkhidmatan mikro (dan, berpotensi, keseluruhan projek).
Mengapakah kependaman jauh lebih tinggi di Kubernetes berbanding EC2?
Untuk mencari kesesakan, kami mengumpulkan metrik di sepanjang laluan permintaan. Seni bina kami mudah: gerbang API (Zuul) meminta proksi kepada tika perkhidmatan mikro dalam EC2 atau Kubernetes. Dalam Kubernetes, kami menggunakan Pengawal Ingress NGINX, dan bahagian belakang ialah objek biasa jenis dengan aplikasi JVM pada platform Spring.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Isu ini nampaknya berkaitan dengan kependaman pada peringkat awal pemprosesan bahagian belakang (saya menandai kawasan masalah pada graf sebagai "xx"). Dalam EC2, respons aplikasi mengambil masa kira-kira 20 ms. Dalam Kubernetes, kependaman meningkat kepada 100-200 ms.
Kami segera menolak kemungkinan suspek yang berkaitan dengan perubahan masa jalan. Versi JVM kekal sama. Isu kontena juga tidak berkaitan: aplikasi telah berjaya dijalankan dalam bekas dalam EC2. Muatkan? Tetapi kami memerhatikan kependaman yang tinggi walaupun dengan satu permintaan sesaat. Jeda kutipan sampah juga boleh diabaikan.
Salah seorang pentadbir Kubernetes kami bertanya sama ada aplikasi itu mempunyai sebarang kebergantungan luaran, kerana pertanyaan DNS telah menyebabkan isu yang sama pada masa lalu.
Hipotesis 1: Resolusi nama DNS
Untuk setiap permintaan, aplikasi kami membuat satu hingga tiga panggilan ke contoh AWS Elasticsearch dalam domain seperti elastic.spain.adevinta.comDi dalam bekas yang kami ada , jadi kami boleh menyemak sama ada carian domain benar-benar mengambil masa yang lama.
Pertanyaan DNS daripada bekas:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecPermintaan serupa daripada salah satu kejadian EC2 yang menjalankan aplikasi:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecMemandangkan carian mengambil masa kira-kira 30ms, menjadi jelas bahawa resolusi DNS apabila mengakses Elasticsearch sememangnya menyumbang kepada peningkatan kependaman.
Walau bagaimanapun, ini adalah pelik kerana dua sebab:
- Kami sudah mempunyai satu tan aplikasi Kubernetes yang berinteraksi dengan sumber AWS tanpa mengalami kependaman yang ketara. Walau apa pun puncanya, ia khusus untuk kes ini.
- Kami tahu bahawa JVM melaksanakan cache DNS dalam memori. Dalam imej kami, nilai TTL dikodkan dengan keras
$JAVA_HOME/jre/lib/security/java.securitydan tetapkan kepada 10 saat:networkaddress.cache.ttl = 10Dalam erti kata lain, JVM harus menyimpan semua pertanyaan DNS selama 10 saat.
Untuk mengesahkan hipotesis pertama, kami memutuskan untuk melumpuhkan carian DNS buat sementara waktu dan melihat sama ada masalah itu akan diselesaikan. Pertama, kami mempertimbangkan untuk mengkonfigurasi semula aplikasi untuk berkomunikasi dengan Elasticsearch secara langsung melalui alamat IPnya dan bukannya nama domainnya. Ini memerlukan perubahan kod dan penggunaan baharu, jadi kami hanya memetakan domain ke alamat IPnya /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comBekas itu kini menerima alamat IPnya hampir serta-merta. Ini menghasilkan sedikit peningkatan, tetapi kami hanya menghampiri sedikit tahap kependaman yang dijangkakan. Walaupun penyelesaian DNS mengambil masa yang lama, punca sebenar masih mengelak kami.
Diagnostik rangkaian
Kami memutuskan untuk menganalisis trafik dari bekas menggunakan tcpdumpuntuk menjejaki apa sebenarnya yang berlaku pada rangkaian:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Kemudian kami menghantar beberapa permintaan dan memuat turun tangkapan mereka (kubectl cp my-service:/capture.pcap capture.pcap) untuk analisis lanjut dalam .
Tiada apa-apa yang mencurigakan tentang pertanyaan DNS (kecuali satu butiran kecil yang akan saya bincangkan kemudian). Walau bagaimanapun, terdapat beberapa keanehan dalam cara perkhidmatan kami memproses setiap permintaan. Di bawah ialah tangkapan skrin daripada tangkapan yang menunjukkan permintaan diterima sebelum respons bermula:
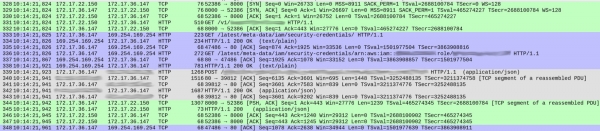
Nombor paket ditunjukkan dalam lajur pertama. Untuk kejelasan, saya telah menyerlahkan aliran TCP yang berbeza dalam warna.
Strim hijau bermula dengan paket 328 menunjukkan bagaimana pelanggan (172.17.22.150) mewujudkan sambungan TCP ke bekas (172.17.36.147). Selepas jabat tangan awal (328-330), paket 331 dibawa HTTP GET /v1/.. — permintaan masuk untuk perkhidmatan kami. Keseluruhan proses mengambil masa 1 ms.
Strim kelabu (bermula dengan paket 339) menunjukkan bahawa perkhidmatan kami menghantar permintaan HTTP kepada contoh Elasticsearch (tiada jabat tangan TCP kerana ia menggunakan sambungan sedia ada). Ini mengambil masa 18 ms.
Setakat ini semuanya baik-baik saja, dan masa adalah kira-kira sejajar dengan kelewatan yang dijangkakan (20-30 ms apabila diukur daripada pelanggan).
Walau bagaimanapun, bahagian biru mengambil masa 86 ms. Apa yang berlaku di sana? Dengan paket 333, perkhidmatan kami menghantar permintaan HTTP GET kepada /latest/meta-data/iam/security-credentials, dan sejurus selepas itu, melalui sambungan TCP yang sama, satu lagi permintaan GET untuk /latest/meta-data/iam/security-credentials/arn:...
Kami mendapati bahawa ini konsisten dengan setiap permintaan sepanjang jejak. Resolusi DNS sememangnya perlahan sedikit dalam bekas kami (penjelasan untuk fenomena ini agak menarik, tetapi saya akan menyimpannya untuk artikel berasingan). Ternyata latensi besar disebabkan oleh panggilan ke perkhidmatan Metadata Instance AWS untuk setiap permintaan.
Hipotesis 2: Panggilan yang berlebihan kepada AWS
Kedua-dua titik akhir adalah milik Perkhidmatan mikro kami menggunakan perkhidmatan ini apabila bekerja dengan Elasticsearch. Kedua-dua panggilan adalah sebahagian daripada proses kebenaran asas. Titik akhir yang diakses semasa permintaan awal mengeluarkan peranan IAM yang dikaitkan dengan contoh.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_rolePermintaan kedua menghubungi titik akhir kedua untuk kebenaran sementara untuk contoh ini:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Pelanggan boleh menggunakannya untuk tempoh masa yang singkat dan mesti menerima sijil baharu secara berkala (sehingga ia tamat tempoh). Expiration). Modelnya mudah: AWS kerap memutarkan kunci sementara atas sebab keselamatan, tetapi pelanggan boleh menyimpannya selama beberapa minit untuk mengimbangi penalti prestasi yang dikaitkan dengan mendapatkan sijil baharu.
AWS Java SDK harus mengambil alih tanggungjawab untuk mengatur proses ini, tetapi atas sebab tertentu ini tidak berlaku.
Selepas mencari melalui isu di GitHub, kami menemui masalah Dia membantu kami menentukan arah untuk menggali lebih jauh.
AWS SDK memperbaharui sijil apabila salah satu daripada keadaan berikut berlaku:
- tarikh luputnya (
Expiration) masuk ke dalamEXPIRATION_THRESHOLD, berkod keras hingga 15 minit. - Sudah lebih banyak masa sejak percubaan terakhir untuk memperbaharui sijil daripada
REFRESH_THRESHOLD, dikod keras selama 60 minit.
Untuk melihat tarikh tamat tempoh sebenar sijil yang kami terima, kami menjalankan perintah cURL di atas daripada bekas dan contoh EC2. Sijil yang diterima daripada bekas mempunyai tarikh tamat tempoh yang lebih pendek: tepat 15 minit.
Kini semuanya menjadi jelas: untuk permintaan pertama, perkhidmatan kami menerima sijil sementara. Memandangkan tarikh tamat tempohnya terhad kepada 15 minit, AWS SDK akan memperbaharuinya atas permintaan berikutnya. Dan ini berlaku dengan setiap permintaan.
Mengapakah tempoh sah sijil menjadi lebih pendek?
Perkhidmatan Metadata Instance AWS direka untuk berfungsi dengan tika EC2, bukan Kubernetes. Sebaliknya, kami tidak mahu menukar antara muka aplikasi. Untuk mencapai ini, kami menggunakan — alat yang, menggunakan ejen pada setiap nod Kubernetes, membenarkan pengguna (jurutera yang mengerahkan aplikasi ke kluster) untuk menetapkan peranan IAM kepada bekas dalam pod seolah-olah ia adalah kejadian EC2. KIAM memintas panggilan ke perkhidmatan Metadata Instance AWS dan memprosesnya daripada cachenya, setelah menerimanya daripada AWS sebelum ini. Dari perspektif aplikasi, tiada apa yang berubah.
KIAM menyediakan sijil jangka pendek kepada pod. Ini masuk akal memandangkan purata jangka hayat pod adalah lebih pendek daripada contoh EC2. Secara lalai, sijil tamat tempoh. .
Akhirnya, menggabungkan kedua-dua lalai ini menimbulkan masalah. Setiap sijil yang diberikan kepada permohonan tamat tempoh selepas 15 minit. AWS Java SDK memaksa pembaharuan mana-mana sijil yang tinggal kurang daripada 15 minit sehingga tamat tempoh.
Akibatnya, sijil sementara terpaksa diperbaharui dengan setiap permintaan, yang memerlukan beberapa panggilan ke API AWS dan meningkatkan kependaman dengan ketara. Kami menemui ini dalam AWS Java SDK. , yang menyebut masalah yang sama.
Penyelesaiannya ternyata mudah. Kami hanya mengkonfigurasi semula KIAM untuk meminta sijil dengan tempoh sah yang lebih lama. Sebaik sahaja ini berlaku, permintaan mula diteruskan tanpa perkhidmatan Metadata AWS, dan kependaman menurun ke tahap yang lebih rendah daripada EC2.
Penemuan
Berdasarkan pengalaman kami dengan migrasi, salah satu sumber masalah yang paling biasa ialah bukan pepijat dalam Kubernetes atau elemen platform lain. Ia juga tidak berkaitan dengan sebarang kelemahan asas dalam perkhidmatan mikro yang kami pindahkan. Masalah sering timbul hanya kerana kita meletakkan elemen yang berbeza bersama-sama.
Kami menggabungkan sistem kompleks yang tidak pernah berinteraksi antara satu sama lain sebelum ini, mengharapkan mereka membentuk satu sistem yang lebih besar. Malangnya, lebih banyak unsur, lebih besar potensi ralat dan lebih tinggi entropi.
Dalam kes kami, kependaman yang tinggi bukanlah hasil daripada pepijat atau keputusan yang lemah dalam Kubernetes, KIAM, AWS Java SDK atau perkhidmatan mikro kami. Ia adalah hasil daripada dua tetapan lalai bebas: satu dalam KIAM dan satu dalam AWS Java SDK. Secara individu, kedua-dua tetapan masuk akal: dasar pembaharuan sijil aktif dalam AWS Java SDK dan masa tamat tempoh sijil yang singkat dalam KAIM. Tetapi apabila digabungkan, hasilnya menjadi tidak dapat diramalkan. Dua penyelesaian bebas dan logik tidak semestinya masuk akal apabila digabungkan.
PS daripada penterjemah
Anda boleh mengetahui lebih lanjut tentang seni bina utiliti KIAM untuk menyepadukan AWS IAM dengan Kubernetes dalam daripada penciptanya.
Dan dalam blog kami, anda juga boleh membaca:
- «»;
- «»;
- «»;
- «'.
Sumber: www.habr.com
