


Untuk menguasai Kubernetes sepenuhnya, anda perlu mengetahui cara yang berbeza untuk menskalakan sumber kluster: oleh , ini adalah salah satu tugas utama Kubernetes. Kami telah memberikan gambaran keseluruhan peringkat tinggi mengenai mekanisme penskalaan automatik mendatar dan menegak dan penskalaan semula kluster, serta cadangan tentang cara menggunakannya dengan berkesan.
Artikel diterjemahkan oleh pasukan yang melaksanakan penskalaan automatik dalam .
Mengapa penting untuk memikirkan tentang penskalaan
- alat untuk pengurusan sumber dan orkestrasi. Sudah tentu, adalah bagus untuk bermain-main dengan ciri-ciri hebat untuk menggunakan, memantau dan mengurus pod (pod ialah sekumpulan bekas yang dilancarkan sebagai tindak balas kepada permintaan).
Walau bagaimanapun, anda juga harus memikirkan soalan berikut:
- Bagaimana untuk menskalakan modul dan aplikasi?
- Bagaimana untuk memastikan bekas beroperasi dan cekap?
- Bagaimana untuk bertindak balas terhadap perubahan berterusan dalam kod dan beban kerja daripada pengguna?
Mengkonfigurasi gugusan Kubernetes untuk mengimbangi sumber dan prestasi boleh menjadi mencabar dan memerlukan pengetahuan pakar tentang kerja dalaman Kubernetes. Beban kerja aplikasi atau perkhidmatan anda boleh berubah-ubah sepanjang hari atau bahkan dalam tempoh sejam, jadi pengimbangan sebaiknya dianggap sebagai proses yang berterusan.
Tahap autoscaling Kubernetes
Penskalaan automatik yang berkesan memerlukan penyelarasan antara dua peringkat:
- Tahap pod, termasuk mendatar (Autoscaler Pod Horizontal, HPA) dan autoscaler menegak (Autoscaler Pod Menegak, VPA). Ini menskalakan sumber yang tersedia untuk bekas anda.
- Tahap kluster, yang diuruskan oleh Cluster Autoscaler (CA), yang meningkatkan atau mengurangkan bilangan nod dalam kluster.
Modul Autoscaler (HPA) mendatar
Seperti namanya, HPA menskalakan bilangan replika pod. Kebanyakan devops menggunakan CPU dan beban memori sebagai pencetus untuk menukar bilangan replika. Walau bagaimanapun, adalah mungkin untuk menskalakan sistem berdasarkan mereka atau bahkan .
Gambar rajah pengendalian HPA peringkat tinggi:
- HPA sentiasa menyemak nilai metrik yang ditentukan semasa pemasangan pada selang lalai 30 saat.
- HPA cuba menambah bilangan modul jika ambang yang ditentukan dicapai.
- HPA mengemas kini bilangan replika dalam pengawal penempatan/replikasi.
- Pengawal penempatan/replikasi kemudiannya menggunakan sebarang modul tambahan yang diperlukan.
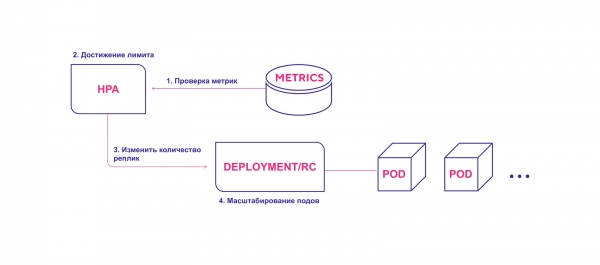
HPA memulakan proses penggunaan modul apabila ambang metrik dicapai
Apabila menggunakan HPA, pertimbangkan perkara berikut:
- Selang semakan HPA lalai ialah 30 saat. Ia ditetapkan oleh bendera mendatar-pod-autoscaler-tempoh-segerak dalam pengurus pengawal.
- Ralat relatif lalai ialah 10%.
- Selepas peningkatan terakhir dalam bilangan modul, HPA menjangkakan metrik akan stabil dalam masa tiga minit. Selang ini ditetapkan oleh bendera horizontal-pod-autoscaler-upscale-delay.
- Selepas pengurangan terakhir dalam bilangan modul, HPA menunggu selama lima minit untuk menstabilkan. Selang ini ditetapkan oleh bendera horizontal-pod-autoscaler-downscale-delay.
- HPA berfungsi paling baik dengan objek penempatan dan bukannya pengawal replikasi. Penskalaan automatik mendatar tidak serasi dengan kemas kini rolling, yang secara langsung memanipulasi pengawal replikasi. Dengan penempatan, bilangan replika bergantung secara langsung pada objek penempatan.
Penskalaan automatik menegak pod
Penskalaan automatik menegak (VPA) memperuntukkan lebih banyak (atau kurang) masa atau memori CPU kepada pod sedia ada. Sesuai untuk pod stateful atau stateless, tetapi bertujuan terutamanya untuk perkhidmatan stateful. Walau bagaimanapun, anda juga boleh menggunakan VPA untuk modul tanpa kewarganegaraan jika anda perlu melaraskan secara automatik jumlah sumber yang diperuntukkan pada mulanya.
VPA juga bertindak balas kepada peristiwa OOM (kehabisan ingatan). Menukar masa dan memori CPU memerlukan memulakan semula pod. Apabila dimulakan semula, VPA menghormati belanjawan peruntukan () untuk menjamin bilangan modul minimum yang diperlukan.
Anda boleh menetapkan sumber minimum dan maksimum untuk setiap modul. Oleh itu, anda boleh mengehadkan jumlah maksimum memori yang diperuntukkan kepada 8 GB. Ini berguna jika nod semasa pasti tidak dapat memperuntukkan lebih daripada 8 GB memori setiap bekas. Spesifikasi terperinci dan mekanisme operasi diterangkan dalam .
Selain itu, VPA mempunyai fungsi pengesyoran yang menarik (VPA Recommender). Ia memantau penggunaan sumber dan peristiwa OOM semua modul untuk mencadangkan memori baharu dan nilai masa CPU berdasarkan algoritma pintar berdasarkan metrik sejarah. Terdapat juga API yang mengambil pemegang pod dan mengembalikan nilai sumber yang dicadangkan.
Perlu diingat bahawa Pengesyor VPA tidak menjejaki "had" sumber. Ini boleh mengakibatkan modul memonopoli sumber dalam nod. Adalah lebih baik untuk menetapkan had pada peringkat ruang nama untuk mengelakkan penggunaan memori atau CPU yang besar.
Skim operasi VPA peringkat tinggi:
- VPA sentiasa menyemak nilai metrik yang ditentukan semasa pemasangan pada selang lalai 10 saat.
- Jika ambang yang ditentukan dicapai, VPA cuba menukar jumlah sumber yang diperuntukkan.
- VPA mengemas kini bilangan sumber dalam pengawal penempatan/replikasi.
- Apabila modul dimulakan semula, semua sumber baharu digunakan pada kejadian yang dibuat.
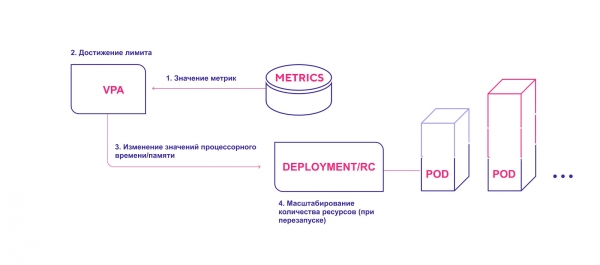
VPA menambah jumlah sumber yang diperlukan
Sila ingat perkara berikut semasa menggunakan VPA:
- Penskalaan memerlukan permulaan semula pod yang wajib. Ini adalah perlu untuk mengelakkan operasi tidak stabil selepas membuat perubahan. Untuk kebolehpercayaan, modul dimulakan semula dan diedarkan merentasi nod berdasarkan sumber yang baru diperuntukkan.
- VPA dan HPA belum lagi serasi antara satu sama lain dan tidak boleh dijalankan pada pod yang sama. Jika anda menggunakan kedua-dua mekanisme penskalaan dalam kelompok yang sama, pastikan tetapan anda menghalangnya daripada diaktifkan pada objek yang sama.
- VPA menala permintaan kontena untuk sumber hanya berdasarkan penggunaan masa lalu dan semasa. Ia tidak menetapkan had penggunaan sumber. Mungkin terdapat masalah dengan aplikasi tidak berfungsi dengan betul dan mula mengambil alih lebih banyak sumber, ini akan menyebabkan Kubernetes mematikan pod ini.
- VPA masih di peringkat awal pembangunan. Bersedia bahawa sistem mungkin mengalami beberapa perubahan dalam masa terdekat. Anda boleh membaca tentang и . Oleh itu, terdapat rancangan untuk melaksanakan operasi bersama VPA dan HPA, serta penggunaan modul bersama-sama dengan dasar autoscaling menegak untuk mereka (contohnya, label khas 'memerlukan VPA').
Autoscaling gugusan Kubernetes
Cluster Autoscaler (CA) menukar bilangan nod berdasarkan bilangan pod menunggu. Sistem secara berkala menyemak modul yang belum selesai - dan meningkatkan saiz kluster jika lebih banyak sumber diperlukan dan jika kluster tidak melebihi had yang ditetapkan. CA berkomunikasi dengan pembekal perkhidmatan awan, meminta nod tambahan daripadanya atau mengeluarkan nod terbiar. Versi pertama CA yang tersedia secara umum telah diperkenalkan dalam Kubernetes 1.8.
Skim peringkat tinggi operasi SA:
- CA menyemak modul yang belum selesai pada selang lalai 10 saat.
- Jika satu atau lebih pod berada dalam keadaan siap sedia kerana kluster tidak mempunyai sumber tersedia yang mencukupi untuk memperuntukkannya, ia cuba menyediakan satu atau lebih nod tambahan.
- Apabila pembekal perkhidmatan awan memperuntukkan nod yang diperlukan, ia bergabung dengan kluster dan bersedia untuk melayani pod.
- Penjadual Kubernetes mengedarkan pod yang belum selesai ke nod baharu. Jika selepas ini beberapa modul masih kekal dalam keadaan menunggu, proses diulang dan nod baharu ditambahkan pada kluster.
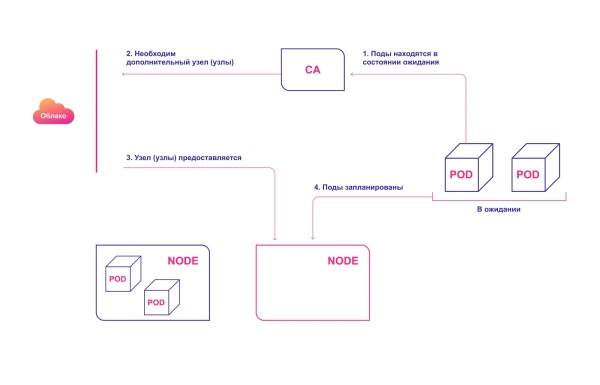
Peruntukan automatik nod kluster dalam awan
Pertimbangkan perkara berikut apabila menggunakan CA:
- CA memastikan bahawa semua pod dalam kluster mempunyai ruang untuk dijalankan, tanpa mengira beban CPU. Ia juga cuba memastikan bahawa tiada nod yang tidak diperlukan dalam kelompok.
- CA mendaftarkan keperluan untuk membuat skala selepas kira-kira 30 saat.
- Sebaik sahaja nod tidak lagi diperlukan, CA lalai menunggu 10 minit sebelum mengecilkan sistem.
- Sistem autoscaling mempunyai konsep pengembang. Ini adalah strategi berbeza untuk memilih kumpulan nod yang mana nod baharu akan ditambahkan.
- Gunakan pilihan dengan penuh tanggungjawab cluster-autoscaler.kubernetes.io/safe-to-evict (true). Jika anda memasang banyak pod, atau jika banyak daripadanya tersebar di semua nod, anda akan kehilangan keupayaan untuk mengecilkan kluster.
- Gunakan untuk mengelakkan pod daripada dipadamkan, yang boleh menyebabkan bahagian aplikasi anda pecah sepenuhnya.
Cara penskala auto Kubernetes berinteraksi antara satu sama lain
Untuk keharmonian yang sempurna, penskalaan automatik hendaklah digunakan pada kedua-dua tahap pod (HPA/VPA) dan tahap kelompok. Mereka berinteraksi antara satu sama lain secara relatifnya:
- HPA atau VPA mengemas kini replika pod atau sumber yang diperuntukkan kepada pod sedia ada.
- Jika nod tidak mencukupi untuk penskalaan yang dirancang, CA menyedari kehadiran pod dalam keadaan menunggu.
- CA memperuntukkan nod baharu.
- Modul diedarkan kepada nod baharu.
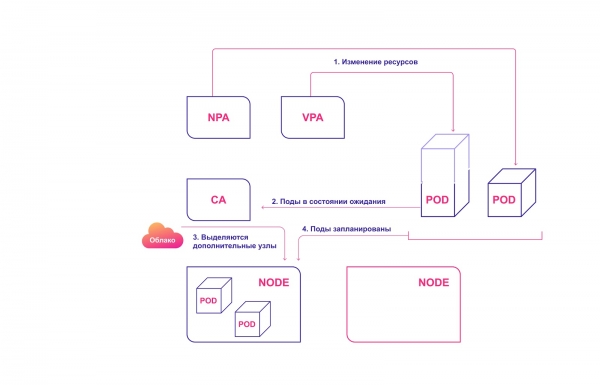
Sistem skala keluar Kubernetes kolaboratif
Kesilapan biasa dalam penskalaan automatik Kubernetes
Terdapat beberapa masalah biasa yang dihadapi apabila cuba melaksanakan autoscaling.
HPA dan VPA bergantung pada metrik dan beberapa data sejarah. Jika sumber tidak mencukupi diperuntukkan, modul akan diminimumkan dan tidak akan dapat menjana metrik. Dalam kes ini, autoscaling tidak akan berlaku.
Operasi penskalaan itu sendiri adalah sensitif masa. Kami mahu modul dan kluster berskala dengan cepat - sebelum pengguna menyedari sebarang masalah atau kegagalan. Oleh itu, purata masa penskalaan untuk pod dan kluster perlu diambil kira.
Senario ideal - 4 minit:
- 30 saat. Kemas kini metrik sasaran: 30−60 saat.
- 30 saat. HPA menyemak nilai metrik: 30 saat.
- Kurang daripada 2 saat. Pod dibuat dan masuk ke keadaan menunggu: 1 saat.
- Kurang daripada 2 saat. CA melihat modul menunggu dan menghantar panggilan ke nod peruntukan: 1 saat.
- 3 minit. Pembekal awan memperuntukkan nod. K8s menunggu sehingga ia bersedia: sehingga 10 minit (bergantung kepada beberapa faktor).
Senario kes terburuk (lebih realistik) - 12 minit:
- 30 saat. Kemas kini metrik sasaran.
- 30 saat. HPA menyemak nilai metrik.
- Kurang daripada 2 saat. Pod dibuat dan memasuki keadaan siap sedia.
- Kurang daripada 2 saat. CA melihat modul menunggu dan membuat panggilan untuk menyediakan nod.
- 10 minit. Pembekal awan memperuntukkan nod. K8s menunggu sehingga mereka bersedia. Masa menunggu bergantung pada beberapa faktor, seperti kelewatan vendor, kelewatan OS dan alat sokongan.
Jangan mengelirukan mekanisme penskalaan penyedia awan dengan CA kami. Yang terakhir berjalan di dalam gugusan Kubernetes, manakala enjin pembekal awan beroperasi pada asas pengedaran nod. Ia tidak tahu apa yang berlaku dengan pod atau aplikasi anda. Sistem ini beroperasi secara selari.
Cara mengurus penskalaan dalam Kubernetes
- Kubernetes ialah alat pengurusan dan orkestrasi sumber. Operasi untuk mengurus pod dan sumber kluster merupakan peristiwa penting dalam menguasai Kubernetes.
- Fahami logik kebolehskalaan pod dengan mengambil kira HPA dan VPA.
- CA hanya boleh digunakan jika anda mempunyai pemahaman yang baik tentang keperluan pod dan bekas anda.
- Untuk mengkonfigurasi kluster secara optimum, anda perlu memahami cara sistem penskalaan yang berbeza berfungsi bersama.
- Apabila menganggarkan masa penskalaan, ingat senario kes terburuk dan kes terbaik.
Sumber: www.habr.com
