


Mijn dagelijkse werk bestaat voornamelijk uit het implementeren van softwaresystemen, wat betekent dat ik veel tijd besteed aan het beantwoorden van vragen als deze:
- De ontwikkelaar heeft de software werkend, maar ik niet. Waarom?
- Gisteren werkte deze software nog voor mij, maar vandaag niet meer. Waarom?
Dit is een vorm van foutopsporing die een beetje verschilt van regulier softwarefoutopsporing. Bij regulier debuggen gaat het om de logica van de code, maar bij debuggen van implementaties gaat het om de interactie tussen de code en de omgeving. Ook al ligt de oorzaak van het probleem in een logische fout, het feit dat alles op de ene machine wel werkt en op de andere niet, betekent dat het probleem op de een of andere manier in de omgeving zit.
Dus in plaats van de gebruikelijke debug-tools zoals gdb Ik heb een andere set hulpmiddelen voor het debuggen van implementaties. En mijn favoriete hulpmiddel om het probleem van "Waarom werkt deze software niet voor mij?" op te lossen het heet spoor.
Wat is strace?
— is een tool voor "traceren van systeemoproepen". Het werd oorspronkelijk gemaakt onder LinuxMaar dezelfde debugtrucs kunnen ook worden toegepast met tools voor andere systemen ( of ).
De basistoepassing is heel eenvoudig. U hoeft alleen maar strace uit te voeren met een opdracht, waarna alle systeemoproepen worden verwijderd (hoewel u het waarschijnlijk eerst zelf moet installeren). spoor):
$ strace echo Hello
...Snip lots of stuff...
write(1, "Hellon", 6) = 6
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++Wat zijn deze systeemaanroepen? Het is zoiets als een API voor de kernel van het besturingssysteem. Lang geleden had software directe toegang tot de hardware waarop het draaide. Als er bijvoorbeeld iets op het scherm moest worden weergegeven, maakte het gebruik van poorten en/of geheugengemapte registers voor videoapparaten. Toen multitaskingcomputersystemen populair werden, ontstond er chaos doordat verschillende applicaties concurreerden om hardware. Bugs in één applicatie kunnen andere applicaties platleggen, of zelfs het hele systeem. Vervolgens verschenen er privilege-modi (of "ringbescherming") in de CPU. De kernel kreeg de meeste privileges: deze kreeg volledige toegang tot de hardware, waardoor er minder privileges ontstonden. Deze moesten toegang aanvragen bij de kernel om met de hardware te kunnen communiceren - via systeemaanroepen.
Op binair niveau is een systeemaanroep iets anders dan een eenvoudige functieaanroep, maar de meeste programma's gebruiken een wrapper uit de standaardbibliotheek. Die. De POSIX C-standaardbibliotheek bevat een functieaanroep schrijven(), die alle architectuur-afhankelijke code voor de systeemoproep bevat schrijven.
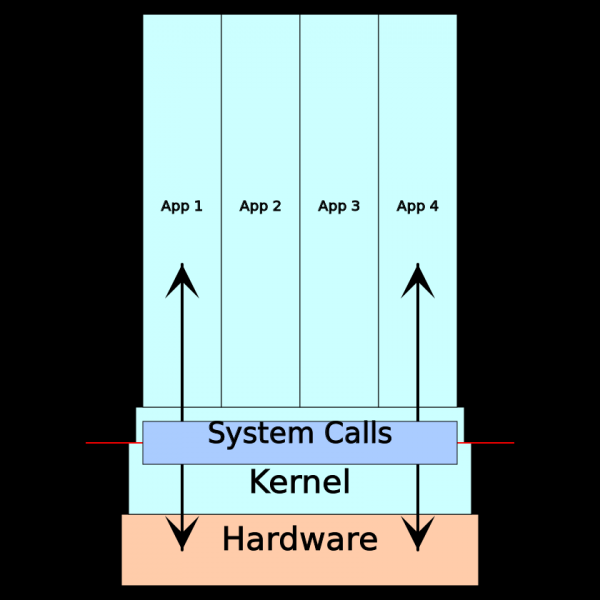
Kort gezegd verloopt elke interactie tussen een applicatie en haar omgeving (computersystemen) via systeemaanroepen. Wanneer software op de ene machine wel werkt en op de andere niet, is het verstandig om naar de resultaten van de tracering van systeemoproepen te kijken. Om specifieker te zijn, volgt hier een lijst met typische momenten die geanalyseerd kunnen worden met behulp van system call tracing:
- Console-I/O
- Netwerk I/O
- Toegang tot bestandssysteem en bestand-I/O
- Het beheren van de levensduur van een proces/thread
- Laag-niveau geheugenbeheer
- Toegang tot drivers voor speciale apparaten
Wanneer gebruik je strace?
In theorie, spoor Wordt gebruikt met elk programma in de gebruikersruimte, omdat elk programma in de gebruikersruimte systeemaanroepen moet doen. Het werkt efficiënter met gecompileerde programma's op een laag niveau, maar het werkt ook met hogere programmeertalen zoals Python, als je de extra ruis van de runtime en de interpreter kunt negeren.
In al zijn glorie spoor manifesteert zich tijdens het debuggen van software die op de ene machine prima werkt, maar plotseling stopt met werken op een andere machine, waarbij vage meldingen worden gegeven over bestanden, machtigingen of mislukte pogingen om bepaalde opdrachten uit te voeren, enz. Helaas gaat het niet zo goed samen met problemen op een hoger niveau, zoals fouten bij het verifiëren van certificaten. Meestal is hier een combinatie vereist spoor, Soms en hulpmiddelen op een hoger niveau (zoals de opdrachtregeltool openssl (om het certificaat te debuggen).
We gebruiken een geïsoleerde server als voorbeeld, maar het traceren van systeemaanroepen kan vaak ook op complexere implementatieplatformen worden uitgevoerd. Het enige dat u hoeft te doen, is het juiste gereedschap kiezen.
Eenvoudig debugvoorbeeld
Stel dat je een geweldige serverapplicatie foo wilt draaien, en je krijgt dit:
$ foo
Error opening configuration file: No such file or directoryBlijkbaar kon het programma het configuratiebestand dat u schreef niet vinden. Dit gebeurt omdat pakketbeheerders soms de verwachte bestandslocaties overschrijven wanneer ze een toepassing compileren. En als u de installatiehandleiding voor de ene distributie volgt, vindt u in een andere distributie bestanden op een heel andere plaats dan u verwachtte. Het probleem zou binnen een paar seconden opgelost kunnen zijn als in de foutmelding stond waar het configuratiebestand te vinden was, maar dat is niet het geval. Waar moet je dan zoeken?
Als je toegang hebt tot de broncode, kun je deze lezen en alles te weten komen. Een goed back-upplan, maar niet de snelste oplossing. U kunt een stapsgewijze debugger gebruiken zoals gdb en kijk wat het programma doet, maar het is veel effectiever om een hulpmiddel te gebruiken dat specifiek is ontworpen om de interactie met de omgeving te laten zien: spoor.
Uitgang spoor Dat lijkt misschien veel, maar het goede nieuws is dat u het grootste deel ervan gerust kunt negeren. Het is vaak handig om de operator -o te gebruiken om de traceerresultaten in een apart bestand op te slaan:
$ strace -o /tmp/trace foo
Error opening configuration file: No such file or directory
$ cat /tmp/trace
execve("foo", ["foo"], 0x7ffce98dc010 /* 16 vars */) = 0
brk(NULL) = 0x56363b3fb000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=25186, ...}) = 0
mmap(NULL, 25186, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f2f12cf1000
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "177ELF2113 3 > 1 260A2 "..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=1824496, ...}) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2f12cef000
mmap(NULL, 1837056, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f2f12b2e000
mprotect(0x7f2f12b50000, 1658880, PROT_NONE) = 0
mmap(0x7f2f12b50000, 1343488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x22000) = 0x7f2f12b50000
mmap(0x7f2f12c98000, 311296, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x16a000) = 0x7f2f12c98000
mmap(0x7f2f12ce5000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1b6000) = 0x7f2f12ce5000
mmap(0x7f2f12ceb000, 14336, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f2f12ceb000
close(3) = 0
arch_prctl(ARCH_SET_FS, 0x7f2f12cf0500) = 0
mprotect(0x7f2f12ce5000, 16384, PROT_READ) = 0
mprotect(0x56363b08b000, 4096, PROT_READ) = 0
mprotect(0x7f2f12d1f000, 4096, PROT_READ) = 0
munmap(0x7f2f12cf1000, 25186) = 0
openat(AT_FDCWD, "/etc/foo/config.json", O_RDONLY) = -1 ENOENT (No such file or directory)
dup(2) = 3
fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
brk(NULL) = 0x56363b3fb000
brk(0x56363b41c000) = 0x56363b41c000
fstat(3, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x8), ...}) = 0
write(3, "Error opening configuration file"..., 60) = 60
close(3) = 0
exit_group(1) = ?
+++ exited with 1 +++Bijna de gehele eerste pagina van de output spoor - dit is meestal een voorbereiding op de lancering op laag niveau. (Veel uitdagingen mmap, mbeschermen, brk voor zaken als detectie van geheugen op laag niveau en dynamische toewijzing van bibliotheken.) Bij het debuggen is de uitvoer spoor Het is beter om helemaal vanaf het einde te lezen. Er zal hieronder een oproep zijn schrijven, wat een foutmelding weergeeft. We kijken hierboven en zien de eerste foutieve systeemoproep - de oproep openat, waardoor een foutmelding ontstaat GENOENT ("bestand of map niet gevonden") probeert te openen /etc/foo/config.json. Hier zou het configuratiebestand moeten staan.
Dit was slechts een voorbeeld, maar ik zou zeggen dat ik 90% van de tijd gebruik spoor, er is niets moeilijker dan dit. Hieronder vindt u een complete stapsgewijze handleiding voor foutopsporing:
- Gefrustreerd door vage systeemfoutmelding van programma
- Start het programma opnieuw met spoor
- Zoek de foutmelding in de trace-resultaten
- Ga hoger totdat je de eerste mislukte systeemoproep tegenkomt
De kans is groot dat u in de systeemoproep in stap 4 kunt zien wat er mis is gegaan.
tips
Voordat ik u een complexer debugvoorbeeld laat zien, zal ik u een paar trucjes laten zien om dit effectief te gebruiken. spoor:
man is je vriend
Op veel *nix-systemen kan een complete lijst met systeemoproepen naar de kernel worden verkregen door het uitvoeren van man syscalls. Je zult dingen zien zoals brk(2), wat betekent dat er meer informatie kan worden verkregen door het uitvoeren man 2 brk.
Kleine valkuilen: man 2 vork laat mij de pagina voor de shell zien vork() в GNU libc, wat, zo blijkt, wordt geïmplementeerd door het aanroepen van kloon(). Semantiek van oproepen vork blijft hetzelfde als je een programma schrijft dat gebruik maakt van vork(), en voer een trace uit - ik vind geen oproepen vorkin plaats daarvan zullen er zijn kloon(). Dit soort hark veroorzaakt alleen verwarring als je de bron gaat vergelijken met de uitvoer spoor.
Gebruik -o om de uitvoer in een bestand op te slaan.
spoor kan een uitgebreide uitvoer genereren, daarom is het vaak nuttig om de traceerresultaten in aparte bestanden op te slaan (zoals in het bovenstaande voorbeeld). En het helpt ook om de programma-uitvoer niet te verwarren met de uitvoer spoor in de console.
Gebruik -s om meer argumentgegevens te bekijken.
U hebt wellicht opgemerkt dat de tweede helft van het foutbericht niet wordt weergegeven in het bovenstaande tracebackvoorbeeld. Dit komt omdat spoor Standaard worden alleen de eerste 32 bytes van het tekenreeksargument weergegeven. Als je meer wilt zien, voeg dan iets toe zoals -s 128 aan de uitdaging spoor.
- maakt het makkelijker om bestanden, sockets, etc. te volgen
"Alles is bestand" betekent dat *nix-systemen alle I/O uitvoeren met behulp van bestandsdescriptoren, ongeacht of dat naar een bestand, een netwerk of interprocess-pipes is. Dit is handig voor het programmeren, maar het maakt het moeilijk om te volgen wat er werkelijk gebeurt als je veelvoorkomende problemen ziet. dit artikel lezen и schrijven in de resultaten van de systeemoproeptracering.
Door de operator toe te voegen -j, je zult dwingen spoor Geef bij elke bestandsdescriptor in de uitvoer aan waarnaar deze verwijst.
Koppel aan een reeds lopend proces met -p**
Zoals u in het onderstaande voorbeeld kunt zien, moet u soms een programma traceren dat al wordt uitgevoerd. Als bekend is dat het proces 1337 draait (bijvoorbeeld vanuit de uitvoer ps), dan kun je het als volgt traceren:
$ strace -p 1337
...system call trace output...Mogelijk hebt u root-toegang nodig.
Gebruik -f om onderliggende processen te bewaken
spoor Standaard wordt er slechts één proces getraceerd. Als dit proces onderliggende processen genereert, kunt u de systeemoproep om het onderliggende proces te genereren zien, maar de systeemoproepen van het onderliggende proces worden niet weergegeven.
Als u denkt dat de fout zich in een onderliggend proces bevindt, gebruikt u de operator -f, dit zal tracering mogelijk maken. Het nadeel hiervan is dat de conclusie alleen maar voor meer verwarring zorgt. Wanneer spoor traceert een enkel proces of thread, het toont een enkele stroom van aanroepgebeurtenissen. Wanneer het meerdere processen tegelijk traceert, ziet u mogelijk dat het begin van een gesprek wordt onderbroken door een bericht , dan een heleboel oproepen naar andere takken van uitvoering, en pas dan het einde van de eerste <… foocall hervat>. Of splits alle trace-resultaten in verschillende bestanden met behulp van de operator -ff (details in op spoor).
Filter het spoor met -e
Zoals u kunt zien, is het trace-resultaat een echte verzameling van alle mogelijke systeemaanroepen. Vlag -e U kunt het spoor filteren (zie op spoor). Het belangrijkste voordeel is dat het uitvoeren van een gefilterde trace sneller is dan het uitvoeren van een volledige trace en vervolgens grep`bij. Eerlijk gezegd maakt het me bijna nooit uit.
Niet alle fouten zijn slecht
Een eenvoudig en algemeen voorbeeld is een programma dat op meerdere plaatsen tegelijk naar een bestand zoekt, vergelijkbaar met een shell die zoekt naar een map met daarin een uitvoerbaar bestand:
$ strace sh -c uname
...
stat("/home/user/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory)
stat("/usr/local/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory)
stat("/usr/bin/uname", {st_mode=S_IFREG|0755, st_size=39584, ...}) = 0
...Heuristiek zoals "laatste mislukte aanvraag vóór foutmelding" is goed om relevante fouten te vinden. Hoe het ook zij, het is verstandig om helemaal onderaan te beginnen.
C-programmeerhandleidingen zijn een goede plek om te beginnen met het begrijpen van systeemaanroepen.
De standaardaanroepen naar de C-bibliotheken zijn geen systeemaanroepen, maar slechts een dunne oppervlaktelaag. Als u dus enigszins weet hoe en wat u in C moet doen, zult u de resultaten van een systeemoproep-trace gemakkelijker kunnen begrijpen. Als u bijvoorbeeld problemen ondervindt bij het debuggen van oproepen naar netwerksystemen, kijk dan naar dezelfde klassieke .
Een complexer voorbeeld van foutopsporing
Ik heb al gezegd dat het eenvoudige debugvoorbeeld een voorbeeld is van waar ik het meest mee te maken krijg als ik met spoor. Soms is echter echt onderzoek nodig. Daarom volgt hier een echt voorbeeld van foutopsporing dat iets complexer is.
— taakplanner, een andere implementatie van de *nix-daemon cron. Het is op de server geïnstalleerd, maar wanneer iemand het schema probeert te bewerken, gebeurt het volgende:
# crontab -e -u logs
bcrontab: Fatal: Could not create temporary fileOké dan, bcron probeerde een bepaald bestand te schrijven, maar het lukte niet en hij wil niet toegeven waarom. Laten we uitpakken spoor:
# strace -o /tmp/trace crontab -e -u logs
bcrontab: Fatal: Could not create temporary file
# cat /tmp/trace
...
openat(AT_FDCWD, "bcrontab.14779.1573691864.847933", O_RDONLY) = 3
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000
read(3, "#Ansible: logsaggn20 14 * * * lo"..., 8192) = 150
read(3, "", 8192) = 0
munmap(0x7f82049b4000, 8192) = 0
close(3) = 0
socket(AF_UNIX, SOCK_STREAM, 0) = 3
connect(3, {sa_family=AF_UNIX, sun_path="/var/run/bcron-spool"}, 110) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000
write(3, "156:Slogs #Ansible: logsaggn20 1"..., 161) = 161
read(3, "32:ZCould not create temporary f"..., 8192) = 36
munmap(0x7f82049b4000, 8192) = 0
close(3) = 0
write(2, "bcrontab: Fatal: Could not creat"..., 49) = 49
unlink("bcrontab.14779.1573691864.847933") = 0
exit_group(111) = ?
+++ exited with 111 +++Er is een foutmelding bijna aan het einde schrijven, maar deze keer is er iets anders. Ten eerste is er geen relevante systeemoproepfout die normaal gesproken hiervoor optreedt. Ten tweede is het duidelijk dat ergens iemand de foutmelding al heeft gelezen. Het lijkt erop dat het echte probleem ergens anders ligt, en bcrontab speelt simpelweg het bericht af.
Als je kijkt naar man 2 lees, kunt u zien dat het eerste argument (3) een bestandsdescriptor is, die *nix gebruikt voor alle I/O-verwerking. Hoe weet ik wat bestandsdescriptor 3 voorstelt? In dit specifieke geval kunt u rennen spoor met behulp van -j (zie hierboven) en het zal u automatisch vertellen dat u dit soort dingen wilt uitzoeken, is het echter handig om te weten hoe u de trace-resultaten moet lezen en analyseren.
De bron van de bestandsdescriptor kan een van de vele systeemaanroepen zijn (het hangt er helemaal vanaf waarvoor de descriptor is: een console, een netwerksocket, het bestand zelf of iets anders). Wat het geval ook is, we zoeken naar aanroepen die 3 retourneren (dat wil zeggen, we zoeken naar "= 3" in de trace-resultaten). In dit resultaat zijn er 2: openat helemaal bovenaan en stopcontact Middenin. openat opent het bestand maar dichtbij(3) Daarna zal het laten zien dat het weer sluit. (Rake: Bestandsbeschrijvingen kunnen opnieuw worden gebruikt wanneer ze worden geopend en gesloten.) Aanroep stopcontact () Het past omdat het de laatste is voor lezen(), en het blijkt dat bcrontab via een socket met iets werkt. De volgende regel laat zien dat de bestandsdescriptor is gekoppeld aan unix domein socket onderweg /var/run/bcron-spool.
We moeten dus een proces vinden dat verbonden is met unix-socket aan de andere kant. Hiervoor bestaan een aantal handige trucjes, die beide handig zijn bij het debuggen van serverimplementaties. De eerste is om te gebruiken netstat of nieuwer ss (socketstatus). Beide opdrachten tonen de actieve netwerkverbindingen van het systeem en nemen de operator mee -l om luistercontactdozen te beschrijven, evenals de operator -p om programma's die op de socket zijn aangesloten als een client weer te geven. (Er zijn nog veel meer nuttige opties, maar deze twee zijn voldoende voor deze taak.)
# ss -pl | grep /var/run/bcron-spool
u_str LISTEN 0 128 /var/run/bcron-spool 1466637 * 0 users:(("unixserver",pid=20629,fd=3))Dit suggereert dat de luisteraar het team is. inixserver, uitgevoerd met proces-ID 20629. (En toevallig gebruikt het bestandsdescriptor 3 als socket.)
De tweede echt nuttige tool om dezelfde informatie te vinden heet lsof. Geeft een overzicht van alle geopende bestanden (of bestandsbeschrijvingen) op het systeem. Of u kunt informatie over een specifiek bestand krijgen:
# lsof /var/run/bcron-spool
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
unixserve 20629 cron 3u unix 0x000000005ac4bd83 0t0 1466637 /var/run/bcron-spool type=STREAMProces 20629 is een server met een lange levensduur, dus u kunt er verbinding mee maken spoor met behulp van iets als strace -o /tmp/trace -p 20629. Als u de cron-job in een andere terminal bewerkt, krijgt u de uitvoer van de trace-resultaten met de fout die optreedt. En dit is het resultaat:
accept(3, NULL, NULL) = 4
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21181
close(4) = 0
accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21181, si_uid=998, si_status=0, si_utime=0, si_stime=0} ---
wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], WNOHANG|WSTOPPED, NULL) = 21181
wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes)
rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0
rt_sigreturn({mask=[]}) = 43
accept(3, NULL, NULL) = 4
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21200
close(4) = 0
accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21200, si_uid=998, si_status=111, si_utime=0, si_stime=0} ---
wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 111}], WNOHANG|WSTOPPED, NULL) = 21200
wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes)
rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0
rt_sigreturn({mask=[]}) = 43
accept(3, NULL, NULL(Laatst aanvaarden() Helaas bevat dit resultaat niet de fout die we zoeken. We zien geen berichten die bcrontag naar de socket verzendt of ontvangt. In plaats daarvan is er sprake van continu procesmanagement (klonen, wacht 4, SIGCHLD enz.) Dit proces genereert een onderliggend proces dat, zoals u wellicht al vermoedt, het echte werk doet. En als je haar spoor wilt volgen, voeg dan toe aan de oproep strace -f. Dit is wat we zullen vinden als we zoeken naar de foutmelding in het nieuwe resultaat met strace -f -o /tmp/trace -p 20629:
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied)
21470 write(1, "32:ZCould not create temporary f"..., 36) = 36
21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84
21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory)
21470 exit_group(111) = ?
21470 +++ exited with 111 +++Dat is tenminste wat. Proces 21470 krijgt de foutmelding 'toegang geweigerd' bij het proberen een bestand op het pad aan te maken tmp/spool.21470.1573692319.854640 (relatief ten opzichte van de huidige werkdirectory). Als we alleen de huidige werkdirectory zouden kennen, dan zouden we het volledige pad kennen en kunnen we achterhalen waarom het proces geen tijdelijk bestand in deze directory kan aanmaken. Helaas is het proces al beëindigd, dus je kunt het niet zomaar gebruiken lsof-p 21470 om de huidige directory te vinden, maar u kunt ook andersom werken: zoek naar systeemoproepen van PID 21470 die de directory wijzigen. (Als er geen zijn, moet PID 21470 ze van de ouder hebben geërfd, en dit is al na lsof -p Ik kan er niet achter komen.) Deze systeemoproep is chdir (wat gemakkelijk te vinden is via moderne online zoekmachines). En hier is het resultaat van omgekeerde zoekopdrachten op basis van de traceerresultaten, helemaal tot aan de PID 20629-server:
20629 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21470
...
21470 execve("/usr/sbin/bcron-spool", ["bcron-spool"], 0x55d2460807e0 /* 27 vars */) = 0
...
21470 chdir("/var/spool/cron") = 0
...
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied)
21470 write(1, "32:ZCould not create temporary f"..., 36) = 36
21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84
21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory)
21470 exit_group(111) = ?
21470 +++ exited with 111 +++(Als je verdwaald bent, wil je misschien mijn vorige bericht lezen .) Server PID 20629 had dus geen toestemming om een bestand op het pad aan te maken /var/spool/cron/tmp/spool.21470.1573692319.854640. Waarschijnlijk ligt dit aan de klassieke machtigingsinstellingen van het bestandssysteem. Laten we het eens controleren:
# ls -ld /var/spool/cron/tmp/
drwxr-xr-x 2 root root 4096 Nov 6 05:33 /var/spool/cron/tmp/
# ps u -p 20629
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
cron 20629 0.0 0.0 2276 752 ? Ss Nov14 0:00 unixserver -U /var/run/bcron-spool -- bcron-spoolDaar ligt de hond begraven! De server draait als een gebruiker-cron, maar alleen root heeft toestemming om naar de directory te schrijven /var/spool/cron/tmp/. Eenvoudig commando chown cron /var/spool/cron/tmp/ zal dwingen bcron werkt naar behoren. (Mocht dit niet het probleem zijn, dan is de SE-kernelbeveiligingsmodule de meest waarschijnlijke oorzaak.)Linux of AppArmor, dus ik zou het kernelberichtenlogboek controleren met dmesg.)
In totaal
Voor een beginner kan de uitvoer van systeemoproeptraceringen overweldigend zijn, maar ik hoop dat ik heb laten zien dat je hiermee snel een hele klasse aan veelvoorkomende implementatieproblemen kunt debuggen. Stel je voor dat je een multi-process-bestand probeert te debuggen bcron, met behulp van de stapsgewijze debugger.
Het parseren van de trace-resultaten langs de systeemoproepketen vereist vaardigheid, maar zoals ik al zei, is het bijna altijd mogelijk om spoorIk krijg alleen het trace-resultaat en zoek naar fouten vanaf het einde. Hoe dan ook, spoor bespaart mij veel tijd bij het debuggen. Ik hoop dat je het ook nuttig vindt.
Bron: www.habr.com
