

Skalaen til Amazon Web Services-nettverket er 69 soner rundt om i verden i 22 regioner: USA, Europa, Asia, Afrika og Australia. Hver sone inneholder opptil 8 datasentre - Databehandlingssentre. Hvert datasenter har tusenvis eller hundretusenvis av servere. Nettverket er utformet på en slik måte at alle usannsynlige utfallsscenarier er tatt i betraktning. For eksempel er alle regioner isolert fra hverandre, og tilgjengelighetssoner er adskilt over avstander på flere kilometer. Selv om du kutter kabelen, vil systemet bytte til backup-kanaler, og tapet av informasjon vil utgjøre noen få datapakker. Vasily Pantyukhin vil snakke om hvilke andre prinsipper nettverket er bygget på og hvordan det er strukturert.
Vasily Pantyukhin startet som Unix-administrator i .ru-selskaper, jobbet med stor Sun Microsystem-maskinvare i 6 år, og forkynte en datasentrisk verden i 11 år ved EMC. Det utviklet seg naturlig til private skyer, for så å flytte til offentlige. Nå, som Amazon Web Services-arkitekt, gir han tekniske råd for å hjelpe til med å leve og utvikle seg i AWS-skyen.
I den forrige delen av AWS-trilogien fordypet Vasily utformingen av fysiske servere og databaseskalering. Nitro-kort, tilpasset KVM-basert hypervisor, Amazon Aurora-database - om alt dette i materialet "" Les for kontekst eller se taler.
Denne delen vil fokusere på nettverksskalering, et av de mest komplekse systemene i AWS. Utviklingen fra et flatt nettverk til en Virtual Private Cloud og dens design, interne tjenester til Blackfoot og HyperPlane, problemet med en bråkete nabo, og på slutten - omfanget av nettverket, ryggraden og fysiske kabler. Om alt dette under kuttet.
Ansvarsfraskrivelse: alt nedenfor er Vasilys personlige mening og kan ikke sammenfalle med posisjonen til Amazon Web Services.
Nettverksskalering
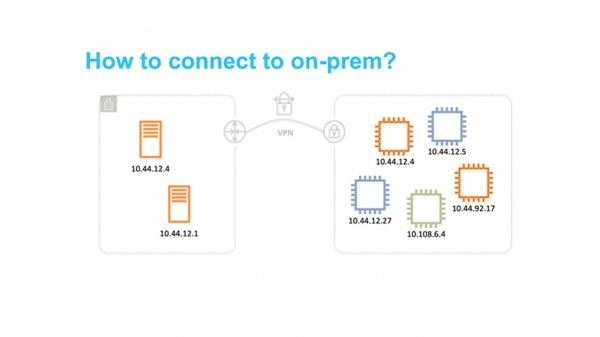
AWS-skyen ble lansert i 2006. Nettverket hans var ganske primitivt – med flat struktur. Utvalget av private adresser var felles for alle skyleietakere. Når du starter en ny virtuell maskin, mottok du ved et uhell en tilgjengelig IP-adresse fra dette området.

Denne tilnærmingen var enkel å implementere, men begrenset grunnleggende bruken av skyen. Spesielt var det ganske vanskelig å utvikle hybridløsninger som kombinerte private nettverk på bakken og i AWS. Det vanligste problemet var overlappende IP-adresseområder.
Virtuell privat sky
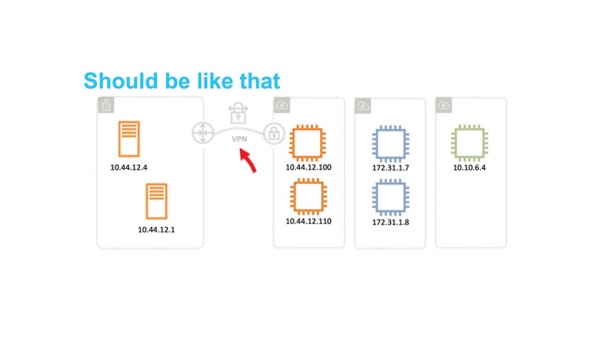
Skyen viste seg å være etterspurt. Tiden er inne for å tenke på skalerbarhet og muligheten for bruk av titalls millioner leietakere. Det flate nettet har blitt et stort hinder. Derfor tenkte vi på hvordan vi kunne isolere brukere fra hverandre på nettverksnivå slik at de selvstendig kunne velge IP-områder.
Hva er det første du tenker på når du tenker på nettverksisolering? Sikkert VLAN и VRF - Virtuell ruting og videresending.
Dessverre fungerte det ikke. VLAN ID er bare 12 bits, noe som gir oss bare 4096 isolerte segmenter. Selv de største bryterne kan bruke maksimalt 1-2 tusen VRF-er. Å bruke VRF og VLAN sammen gir oss bare noen få millioner subnett. Dette er definitivt ikke nok for titalls millioner leietakere, som hver må kunne bruke flere subnett.
Vi har rett og slett ikke råd til å kjøpe det nødvendige antallet store bokser, for eksempel fra Cisco eller Juniper. Det er to grunner: det er vanvittig dyrt, og vi ønsker ikke å være prisgitt deres utviklings- og lappepolitikk.
Det er bare én konklusjon - lag din egen løsning.
I 2009 annonserte vi VPC - Virtuell privat sky. Navnet festet seg og nå bruker mange skyleverandører det også.
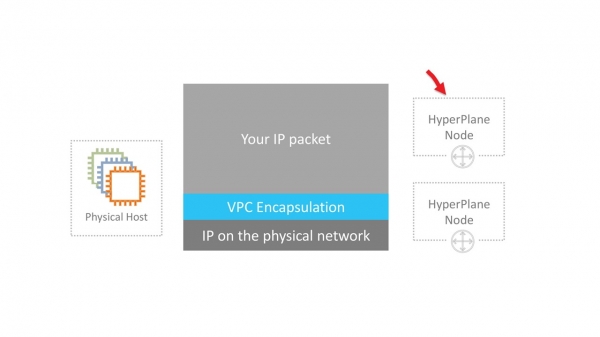
VPC er et virtuelt nettverk SDN (Programvaredefinert nettverk). Vi bestemte oss for ikke å finne opp spesielle protokoller på L2- og L3-nivå. Nettverket kjører på standard Ethernet og IP. For overføring over nettverket er virtuell maskintrafikk innkapslet i vår egen protokollinnpakning. Den indikerer IDen som tilhører leietakers VPC.
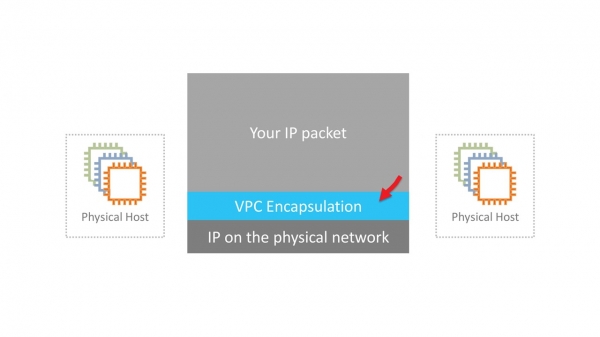
Høres enkelt ut. Det er imidlertid flere alvorlige tekniske utfordringer som må overvinnes. For eksempel hvor og hvordan du lagrer data om kartlegging av virtuelle MAC/IP-adresser, VPC-ID og tilsvarende fysisk MAC/IP. På AWS-skala er dette et stort bord som skal fungere med minimale tilgangsforsinkelser. Ansvarlig for dette karttjeneste, som er spredt i et tynt lag over hele nettverket.
I nye generasjons maskiner utføres innkapsling av Nitro-kort på maskinvarenivå. I eldre tilfeller er innkapsling og dekapsling programvarebasert.
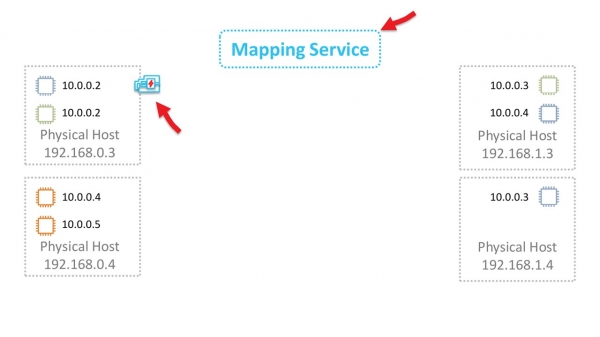
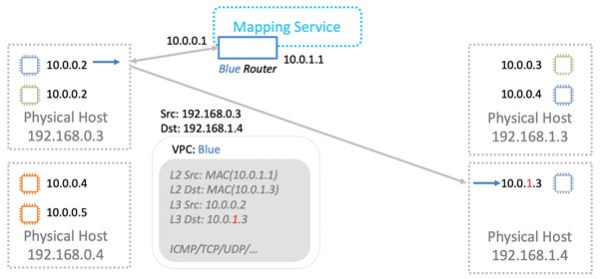
La oss finne ut hvordan det fungerer i generelle termer. La oss starte med L2-nivået. La oss anta at vi har en virtuell maskin med IP 10.0.0.2 på en fysisk server 192.168.0.3. Den sender data til virtuell maskin 10.0.0.3, som lever på 192.168.1.4. En ARP-forespørsel genereres og sendes til nettverkets Nitro-kort. For enkelhets skyld antar vi at begge virtuelle maskinene lever i samme "blå" VPC.

Kartet erstatter kildeadressen med sin egen og videresender ARP-rammen til karttjenesten.
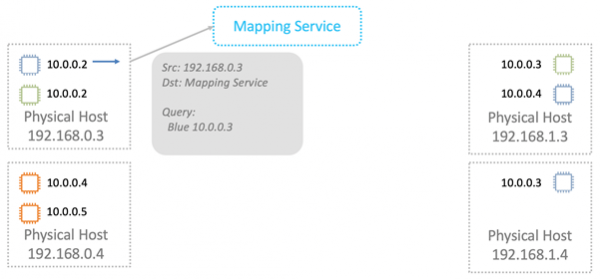
Karttjenesten returnerer informasjon som er nødvendig for overføring over det fysiske L2-nettverket.
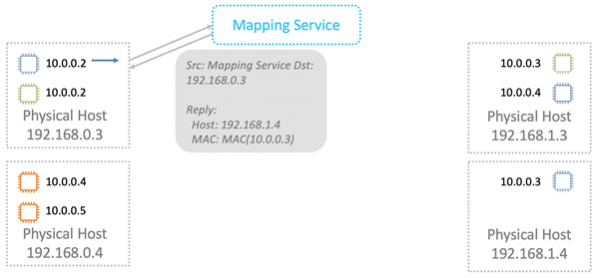
Nitro-kortet i ARP-svaret erstatter MAC på det fysiske nettverket med en adresse i VPC.
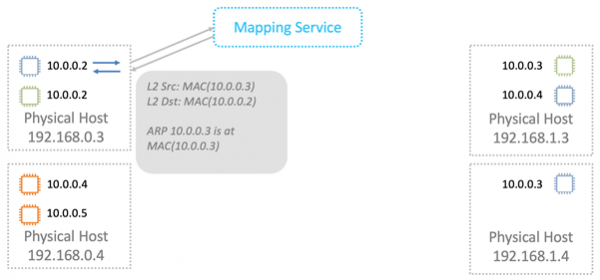
Ved overføring av data pakker vi logisk MAC og IP inn i en VPC-innpakning. Vi overfører alt dette over det fysiske nettverket ved å bruke riktige kilde- og destinasjons-IP Nitro-kort.
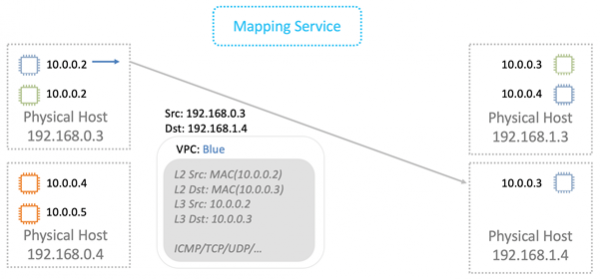
Den fysiske maskinen som pakken er bestemt til utfører kontrollen. Dette er nødvendig for å forhindre muligheten for adresseforfalskning. Maskinen sender en spesiell forespørsel til karttjenesten og spør: «Fra fysisk maskin 192.168.0.3 mottok jeg en pakke som er beregnet på 10.0.0.3 i den blå VPC. Er han legitim?
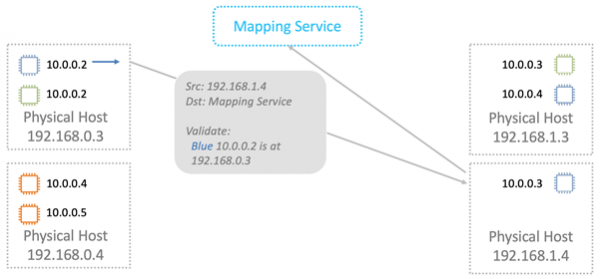
Karttjenesten sjekker sin ressursallokeringstabell og tillater eller nekter pakken å passere gjennom. I alle nye tilfeller er ytterligere validering innebygd i Nitro-kort. Det er umulig å omgå det selv teoretisk. Derfor vil ikke spoofing til ressurser i en annen VPC fungere.
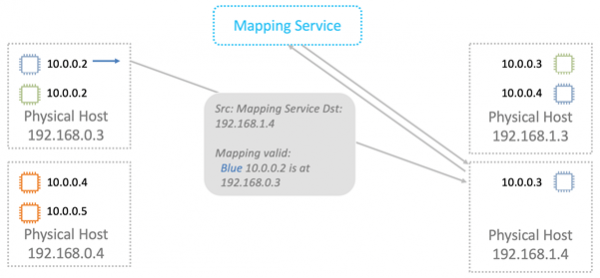
Deretter sendes dataene til den virtuelle maskinen de er beregnet på.
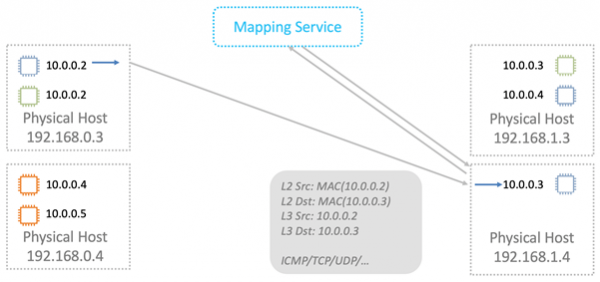
Karttjenesten fungerer også som en logisk ruter for overføring av data mellom virtuelle maskiner i ulike undernett. Alt er konseptuelt enkelt, jeg vil ikke gå i detalj.
Det viser seg at når hver pakke overføres, henvender serverne seg til karttjenesten. Hvordan håndtere uunngåelige forsinkelser? Buffer, selvfølgelig.
Det fine er at du ikke trenger å cache hele det enorme bordet. En fysisk server er vert for virtuelle maskiner fra et relativt lite antall VPC-er. Du trenger bare å cache informasjon om disse VPC-ene. Det er fortsatt ikke legitimt å overføre data til andre VPC-er i "standard"-konfigurasjonen. Hvis funksjonalitet som VPC-peering brukes, blir informasjon om de tilsvarende VPC-ene i tillegg lastet inn i cachen.
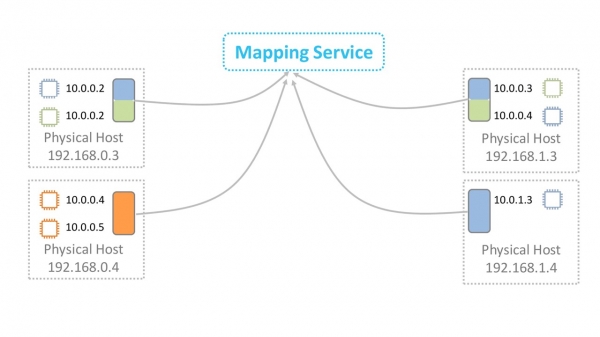
Vi ordnet overføringen av data til VPC.
Blackfoot
Hva skal man gjøre i tilfeller der trafikk må overføres utenfor, for eksempel til Internett eller via VPN til bakken? Hjelper oss her Blackfoot — AWS interntjeneste. Den er utviklet av vårt sørafrikanske team. Derfor er tjenesten oppkalt etter en pingvin som bor i Sør-Afrika.
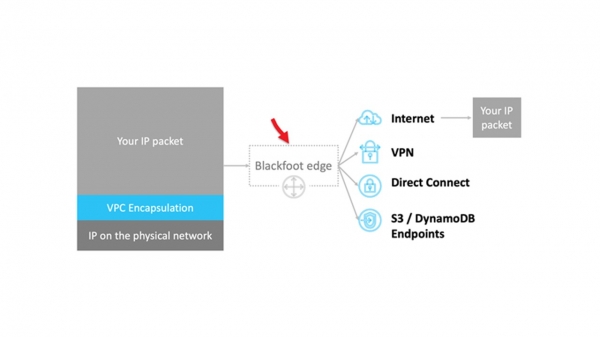
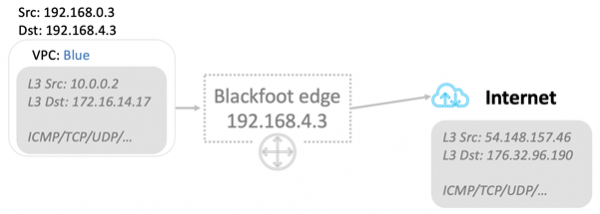
Blackfoot dekapsler trafikken og gjør det som trengs med den. Data sendes til Internett som de er.
Dataene dekapsles og pakkes inn på nytt i IPsec når du bruker en VPN.
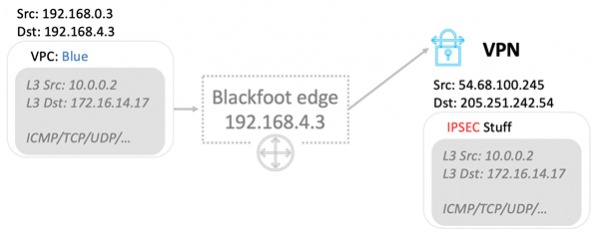
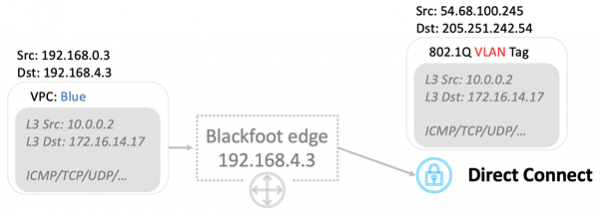
Når du bruker Direct Connect, merkes trafikken og sendes til riktig VLAN.
HyperPlane
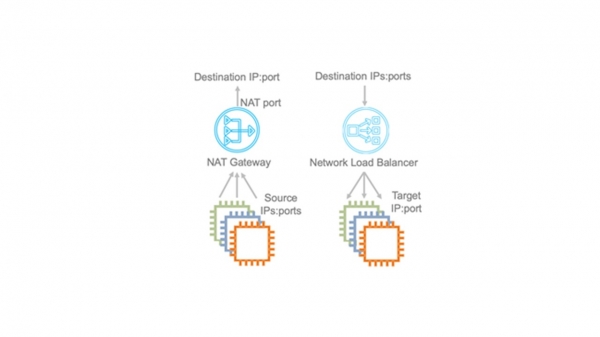
Dette er en intern flytkontrolltjeneste. Mange nettverkstjenester krever overvåking dataflyttilstander. For eksempel, når du bruker NAT, må flytkontroll sikre at hvert IP:destinasjonsportpar har en unik utgående port. I tilfelle av en balanserer NLB - Network Load Balancer, bør dataflyten alltid rettes til den samme virtuelle målmaskinen. Security Groups er en stateful brannmur. Den overvåker innkommende trafikk og åpner implisitt porter for utgående pakkeflyt.
I AWS-skyen er kravene til overføringsforsinkelse ekstremt høye. Derfor HyperPlane avgjørende for ytelsen til hele nettverket.
Hyperplane er bygget på virtuelle EC2-maskiner. Det er ingen magi her, bare list. Trikset er at dette er virtuelle maskiner med stor RAM. Operasjoner er transaksjonelle og utføres utelukkende i minnet. Dette lar deg oppnå forsinkelser på bare titalls mikrosekunder. Å jobbe med disken ville drepe all produktivitet.
Hyperplane er et distribuert system av et stort antall slike EC2-maskiner. Hver virtuell maskin har en båndbredde på 5 GB/s. På tvers av hele det regionale nettverket gir dette utrolige terabiter med båndbredde og tillater prosessering millioner av tilkoblinger per sekund.
HyperPlane fungerer bare med strømmer. VPC-pakkeinnkapsling er helt gjennomsiktig for det. En potensiell sårbarhet i denne interne tjenesten vil fortsatt forhindre at VPC-isolasjonen brytes. Nivåene nedenfor er ansvarlige for sikkerheten.
Støyende nabo
Det er fortsatt et problem bråkete nabo - bråkete nabo. La oss anta at vi har 8 noder. Disse nodene behandler strømmene til alle skybrukere. Alt ser ut til å være i orden og belastningen skal være jevnt fordelt over alle noder. Noder er veldig kraftige og det er vanskelig å overbelaste dem.
Men vi bygger arkitekturen vår basert på til og med usannsynlige scenarier.
Lav sannsynlighet betyr ikke umulig.
Vi kan forestille oss en situasjon der en eller flere brukere vil generere for mye belastning. Alle HyperPlane-noder er involvert i å behandle denne belastningen, og andre brukere kan potensielt oppleve en slags ytelsestreff. Dette bryter konseptet med skyen, der leietakere ikke har noen mulighet til å påvirke hverandre.

Hvordan løse problemet med en bråkete nabo? Det første du tenker på er skjæring. Våre 8 noder er logisk delt inn i 4 skår med 2 noder hver. Nå vil en bråkete nabo bare forstyrre en fjerdedel av alle brukere, men det vil forstyrre dem sterkt.
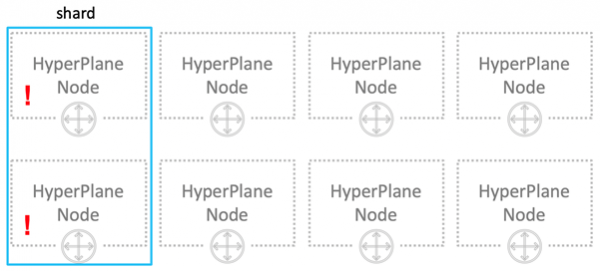
La oss gjøre ting annerledes. Vi vil tildele kun 3 noder til hver bruker.
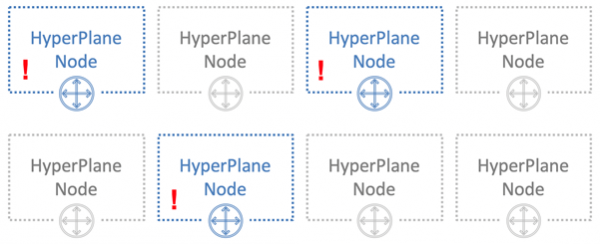
Trikset er å tilfeldig tildele noder til forskjellige brukere. På bildet nedenfor krysser den blå brukeren noder med en av de to andre brukerne - grønn og oransje.
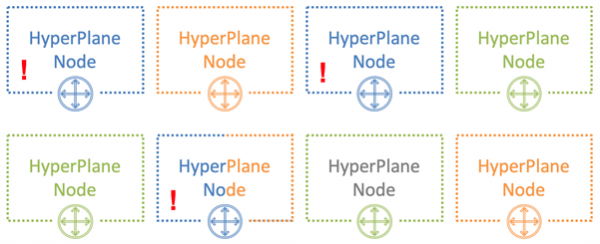
Med 8 noder og 3 brukere er sannsynligheten for at en støyende nabo krysser en av brukerne 54 %. Det er med denne sannsynligheten at en blå bruker vil påvirke andre leietakere. Samtidig bare en del av lasten. I vårt eksempel vil denne påvirkningen på en eller annen måte være merkbar ikke for alle, men for bare en tredjedel av alle brukere. Dette er allerede et godt resultat.
Antall brukere som vil krysse hverandre
Sannsynlighet i prosent
0
18%
1
54%
2
26%
3
2%
La oss bringe situasjonen nærmere virkeligheten – la oss ta 100 noder og 5 brukere på 5 noder. I dette tilfellet vil ingen av nodene krysse hverandre med en sannsynlighet på 77 %.
Antall brukere som vil krysse hverandre
Sannsynlighet i prosent
0
77%
1
21%
2
1,8%
3
0,06%
4
0,0006%
5
0,00000013%
I en reell situasjon, med et stort antall HyperPlane-noder og brukere, er den potensielle innvirkningen av en støyende nabo på andre brukere minimal. Denne metoden kalles blande skjæring - shuffle sharding. Det minimerer den negative effekten av nodesvikt.
Mange tjenester er bygget på basis av HyperPlane: Network Load Balancer, NAT Gateway, Amazon EFS, AWS PrivateLink, AWS Transit Gateway.
Nettverksskala
La oss nå snakke om omfanget av selve nettverket. For oktober 2019 tilbyr AWS sine tjenester i 22 regioner, og 9 til er planlagt.
- Hver region inneholder flere tilgjengelighetssoner. Det er 69 av dem rundt om i verden.
- Hver AZ består av databehandlingssentre. Det er ikke mer enn 8 av dem totalt.
- Datasenteret huser et stort antall servere, noen med opptil 300 000.
La oss nå gjennomsnittet alt dette, multiplisere og få et imponerende tall som gjenspeiler Amazon skyskala.
Det er mange optiske koblinger mellom Availability Zones og datasenteret. I en av våre største regioner er det lagt 388 kanaler kun for AZ-kommunikasjon mellom hverandre og kommunikasjonssentre med andre regioner (Transit Centers). Totalt gir dette sprøtt 5000 Tbit.
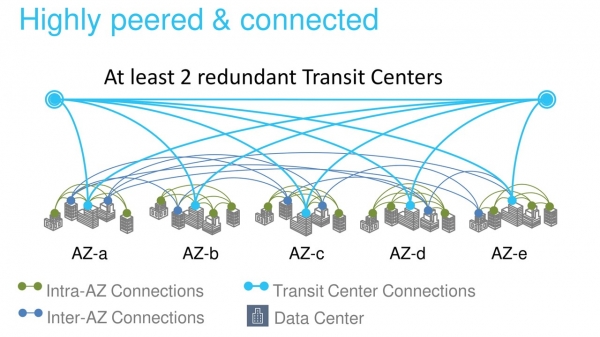
Backbone AWS er bygget spesielt for og optimalisert for skyen. Vi bygger det på kanalene 100 GB / s. Vi kontrollerer dem fullstendig, med unntak av regioner i Kina. Trafikken deles ikke med lasten til andre selskaper.
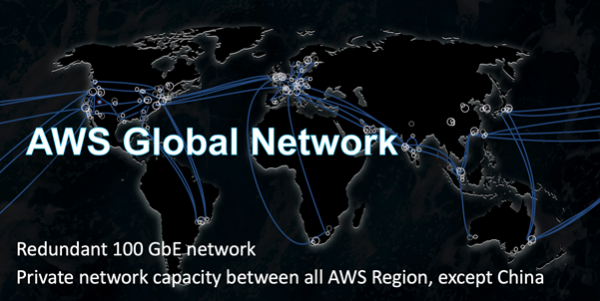
Selvfølgelig er vi ikke den eneste skyleverandøren med et privat ryggradsnettverk. Stadig flere store bedrifter følger denne veien. Dette bekreftes av uavhengige forskere, for eksempel fra .
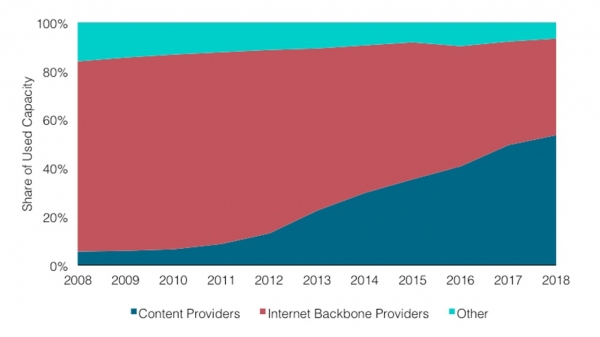
Grafen viser at andelen innholdsleverandører og skyleverandører vokser. På grunn av dette synker andelen Internett-trafikk til ryggradsleverandører stadig.
Jeg skal forklare hvorfor dette skjer. Tidligere var de fleste nettjenester tilgjengelige og konsumert direkte fra Internett. Nå for tiden er flere og flere servere plassert i skyen og er tilgjengelige via CDN - Innholdsdistribusjonsnettverk. For å få tilgang til en ressurs, går brukeren bare gjennom Internett til nærmeste CDN PoP - Tilstedeværelse. Oftest er det et sted i nærheten. Så forlater den det offentlige Internett og flyr gjennom en privat ryggrad over Atlanterhavet, for eksempel, og kommer direkte til ressursen.
Jeg lurer på hvordan Internett vil endre seg om 10 år hvis denne trenden fortsetter?
Fysiske kanaler
Forskere har ennå ikke funnet ut hvordan de kan øke lyshastigheten i universet, men de har gjort store fremskritt i metoder for å overføre det gjennom optisk fiber. Vi bruker for tiden 6912 fiberkabler. Dette bidrar til å optimalisere kostnadene for installasjonen deres betydelig.
I noen regioner må vi bruke spesielle kabler. For eksempel bruker vi i Sydney-regionen kabler med et spesielt belegg mot termitter.

Ingen er immun mot problemer og noen ganger blir kanalene våre skadet. Bildet til høyre viser optiske kabler i en av de amerikanske regionene som ble revet av bygningsarbeidere. Krasjet førte til at bare 13 datapakker gikk tapt, noe som er overraskende. Nok en gang - bare 13! Systemet byttet bokstavelig talt øyeblikkelig til backup-kanaler - vekten fungerer.
Vi galopperte gjennom noen av Amazons skytjenester og teknologier. Jeg håper at du i det minste har en ide om omfanget av oppgavene våre ingeniører må løse. Personlig synes jeg dette er veldig spennende.
Dette er den siste delen av trilogien fra Vasily Pantyukhin om AWS-enheten. I deler beskriver serveroptimalisering og databaseskalering, og i — serverløse funksjoner og Firecracker.
På i november vil Vasily Pantyukhin dele nye detaljer om Amazon-enheten. Han om årsakene til feil og utformingen av distribuerte systemer hos Amazon. 24. oktober er fortsatt mulig billett til en god pris, og betal senere. Vi venter på deg på HighLoad++, kom og la oss prate!
Kilde: www.habr.com
