

Å bringe en ny prosjektutgivelse i produksjon krever en nøye balanse mellom distribusjonshastighet og løsningspålitelighet. Slack verdier raske iterasjoner, korte tilbakemeldingssykluser og rask respons på brukerforespørsler. I tillegg har selskapet hundrevis av programmerere som streber etter å være så produktive som mulig.
Forfatterne av materialet, oversettelsen av som vi publiserer i dag, sier at et selskap som streber etter å overholde slike verdier og samtidig vokser, må hele tiden forbedre prosjektdistribusjonssystemet. Selskapet må investere i åpenhet og pålitelighet av arbeidsprosesser, og gjøre dette for å sikre at disse prosessene samsvarer med prosjektets omfang. Her skal vi snakke om arbeidsflytene som har utviklet seg i Slack, og om noen av beslutningene som førte til at selskapet tok i bruk prosjektdistribusjonssystemet som eksisterer i dag.
Hvordan prosjektdistribusjonsprosesser fungerer i dag
Hver PR (pull request) i Slack må være gjenstand for kodegjennomgang og må bestå alle tester. Først etter at disse betingelsene er oppfylt, kan programmereren slå sammen koden sin til hovedgrenen til prosjektet. Denne koden distribueres imidlertid bare i arbeidstiden, nordamerikansk tid. Som et resultat, på grunn av det faktum at våre ansatte er på arbeidsplassen, er vi fullt forberedt på å løse eventuelle uventede problemer.
Hver dag gjennomfører vi ca 12 planlagte utplasseringer. Under hver distribusjon er programmereren som er utpekt som distribusjonsleder ansvarlig for å sette den nye bygningen i produksjon. Dette er en flertrinnsprosess som sikrer at monteringen bringes i produksjon jevnt. Takket være denne tilnærmingen kan vi oppdage feil før de påvirker alle brukerne våre. Hvis det er for mange feil, kan utplasseringen av sammenstillingen rulles tilbake. Hvis et spesifikt problem oppdages etter utgivelsen, kan det enkelt frigis en reparasjon for det.
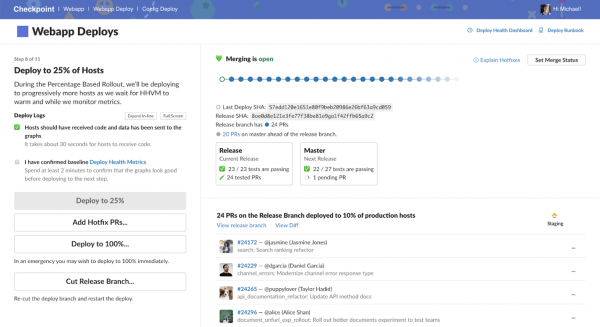
Grensesnitt til Checkpoint-systemet, som brukes i Slack for å distribuere prosjekter
Prosessen med å distribuere en ny utgivelse til produksjon kan tenkes å bestå av fire trinn.
▍1. Opprette en utgivelsesgren
Hver utgivelse starter med en ny utgivelsesgren, et punkt i Git-historien vår. Dette lar deg tilordne tagger til utgivelsen og gir et sted hvor du kan gjøre live-fikser for feil funnet i prosessen med å forberede utgivelsen for utgivelse til produksjon.
▍2. Utrulling i et oppsamlingsmiljø
Neste trinn er å distribuere sammenstillingen på staging-servere og kjøre en automatisk test for den totale ytelsen til prosjektet (røyketest). Staging-miljøet er et produksjonsmiljø som ikke mottar ekstern trafikk. I dette miljøet utfører vi ytterligere manuell testing. Dette gir oss ytterligere tillit til at det modifiserte prosjektet fungerer riktig. Automatiserte tester alene er ikke nok til å gi dette nivået av tillit.
▍3. Utplassering i dogfood- og kanarimiljøer
Utrulling til produksjon starter med et internkontrollmiljø, representert av et sett med verter som betjener våre interne Slack-arbeidsområder. Siden vi er veldig aktive Slack-brukere, hjalp denne tilnærmingen oss med å fange mange feil tidlig i distribusjonen. Etter at vi har forsikret oss om at den grunnleggende funksjonaliteten til systemet ikke er ødelagt, utplasseres sammenstillingen i kanarimiljøet. Det representerer systemer som står for omtrent 2 % av produksjonstrafikken.
▍4. Gradvis utgivelse til produksjon
Hvis overvåkingsindikatorene for den nye utgivelsen viser seg å være stabile, og hvis vi etter å ha distribuert prosjektet i kanarimiljøet ikke har mottatt noen klager, fortsetter vi gradvis å overføre produksjonsserverne til den nye utgivelsen. Implementeringsprosessen er delt inn i følgende stadier: 10 %, 25 %, 50 %, 75 % og 100 %. Som et resultat kan vi sakte overføre produksjonstrafikk til den nye versjonen av systemet. Samtidig har vi tid til å undersøke situasjonen dersom det oppdages avvik.
▍Hva hvis noe går galt under distribusjonen?
Å gjøre endringer i koden er alltid en risiko. Men vi takler dette takket være tilstedeværelsen av godt trente "distribusjonsledere" som styrer prosessen med å bringe en ny utgivelse i produksjon, overvåker overvåkingsindikatorer og koordinerer arbeidet til programmerere som slipper kode.
I tilfelle noe virkelig går galt, prøver vi å oppdage problemet så tidlig som mulig. Vi undersøker problemet, finner PR-en som forårsaker feilene, ruller den tilbake, analyserer den grundig og lager et nytt bygg. Det er sant at noen ganger går problemet ubemerket frem til prosjektet går i produksjon. I en slik situasjon er det viktigste å gjenopprette tjenesten. Derfor, før vi begynner å undersøke problemet, går vi umiddelbart tilbake til forrige arbeidsbygg.
Byggesteiner for et distribusjonssystem
La oss se på teknologiene som ligger til grunn for vårt prosjektdistribusjonssystem.
▍Raske distribusjoner
Arbeidsflyten beskrevet ovenfor kan i ettertid virke noe opplagt. Men distribusjonssystemet vårt ble ikke slik med en gang.
Da selskapet var mye mindre, kunne hele applikasjonen vår kjøre på 10 Amazon EC2-instanser. Å distribuere prosjektet i denne situasjonen innebar å bruke rsync for å raskt synkronisere alle servere. Tidligere var ny kode bare ett skritt unna produksjon, representert ved et iscenesettelsesmiljø. Samlinger ble laget og testet i et slikt miljø, og gikk deretter rett i produksjon. Det var veldig enkelt å forstå et slikt system; det tillot enhver programmerer å distribuere koden han hadde skrevet når som helst.
Men etter hvert som antallet kunder vokste, økte også omfanget av infrastrukturen som kreves for å støtte prosjektet. Snart, gitt den konstante veksten av systemet, gjorde ikke vår distribusjonsmodell, basert på å skyve ny kode til serverne, jobben sin lenger. Det å legge til hver ny server betydde nemlig å øke tiden som kreves for å fullføre distribusjonen. Selv strategier basert på parallell bruk av rsync har visse begrensninger.
Vi endte opp med å løse dette problemet ved å gå over til et helt parallelt distribusjonssystem, som var utformet annerledes enn det gamle systemet. Nå sendte vi nemlig ikke kode til serverne ved hjelp av et synkroniseringsskript. Nå lastet hver server uavhengig ned den nye sammenstillingen, vel vitende om at den måtte gjøre det ved å overvåke Consul-nøkkelendringen. Serverne lastet koden parallelt. Dette tillot oss å opprettholde en høy utrullingshastighet selv i et miljø med konstant systemvekst.

1. Produksjonsservere overvåker Consul-nøkkelen. 2. Nøkkelen endres, dette forteller serverne at de må begynne å laste ned ny kode. 3. Servere laster ned tarball-filer med applikasjonskode
▍Atomplasseringer
En annen løsning som hjalp oss med å nå et flerlags distribusjonssystem var atomdistribusjon.
Før du bruker atomdistribusjoner, kan hver distribusjon resultere i et stort antall feilmeldinger. Faktum er at prosessen med å kopiere nye filer til produksjonsservere ikke var atomær. Dette resulterte i et kort tidsvindu der koden som kalte nye funksjoner var tilgjengelig før selve funksjonene var tilgjengelige. Når en slik kode ble kalt, resulterte det i at interne feil ble returnert. Dette manifesterte seg i mislykkede API-forespørsler og ødelagte nettsider.
Teamet som jobbet med dette problemet løste det ved å introdusere konseptet "varme" og "kalde" kataloger. Koden i hot directory er ansvarlig for behandling av produksjonstrafikk. Og i "kalde" kataloger blir koden, mens systemet kjører, bare klargjort for bruk. Under distribusjon kopieres ny kode til en ubrukt kald katalog. Deretter, når det ikke er noen aktive prosesser på serveren, utføres en øyeblikkelig katalogbytte.
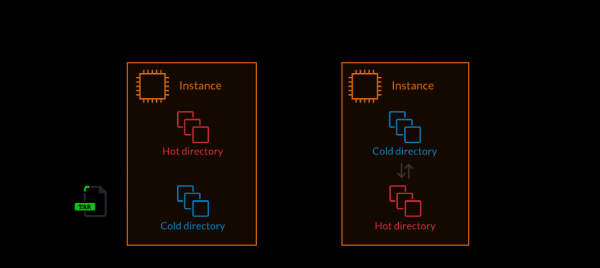
1. Pakke ut applikasjonskoden i en "kald" katalog. 2. Bytte systemet til en "kald" katalog, som blir "varm" (atomisk drift)
Resultater: skifte i vekt til pålitelighet
I 2018 vokste prosjektet til et slikt omfang at svært rask distribusjon begynte å skade stabiliteten til produktet. Vi hadde et veldig avansert distribusjonssystem som vi investerte mye tid og krefter i. Alt vi trengte å gjøre var å gjenoppbygge og forbedre distribusjonsprosessene våre. Vi har vokst til et ganske stort selskap, hvis utvikling har blitt brukt over hele verden til å organisere uavbrutt kommunikasjon og løse viktige problemer. Derfor ble pålitelighet i fokus for vår oppmerksomhet.
Vi trengte å gjøre prosessen med å distribuere nye Slack-utgivelser sikrere. Dette behovet førte til at vi forbedret distribusjonssystemet vårt. Faktisk diskuterte vi dette forbedrede systemet ovenfor. I dypet av systemet fortsetter vi å bruke raske og atomære distribusjonsteknologier. Måten distribusjonen gjøres på har endret seg. Vårt nye system er designet for gradvis å distribuere ny kode på forskjellige nivåer, i forskjellige miljøer. Vi bruker nå mer avanserte støtteverktøy og systemovervåkingsverktøy enn tidligere. Dette gir oss muligheten til å fange opp og fikse feil lenge før de har en sjanse til å nå sluttbrukeren.
Men vi skal ikke stoppe der. Vi forbedrer hele tiden dette systemet ved å bruke mer avanserte hjelpeverktøy og arbeidsautomatiseringsverktøy.
Kjære lesere! Hvordan fungerer prosessen med å distribuere nye prosjektutgivelser der du jobber?
Kilde: www.habr.com
