


For et par år siden Kubernetes på den offisielle GitHub-bloggen. Siden den gang har det blitt standardteknologien for distribusjon av tjenester. Kubernetes administrerer nå en betydelig del av interne og offentlige tjenester. Etter hvert som våre klynger vokste og ytelseskravene ble strengere, begynte vi å legge merke til at noen tjenester på Kubernetes sporadisk opplevde ventetid som ikke kunne forklares av belastningen av selve applikasjonen.
I hovedsak opplever applikasjoner tilfeldig nettverksforsinkelse på opptil 100 ms eller mer, noe som resulterer i tidsavbrudd eller gjenforsøk. Tjenester var forventet å kunne svare på forespørsler mye raskere enn 100 ms. Men dette er umulig hvis selve forbindelsen tar så mye tid. Hver for seg observerte vi veldig raske MySQL-spørringer som skulle ta millisekunder, og MySQL ble fullført på millisekunder, men fra den forespørrende applikasjonens perspektiv tok svaret 100ms eller mer.
Det ble umiddelbart klart at problemet bare oppsto ved tilkobling til en Kubernetes-node, selv om anropet kom fra utenfor Kubernetes. Den enkleste måten å reprodusere problemet på er i en test , som kjører fra en hvilken som helst intern vert, tester Kubernetes-tjenesten på en bestemt port, og registrerer sporadisk høy latens. I denne artikkelen skal vi se på hvordan vi klarte å spore opp årsaken til dette problemet.
Eliminerer unødvendig kompleksitet i kjeden som fører til feil
Ved å gjengi det samme eksempelet ønsket vi å begrense fokuset på problemet og fjerne unødvendige lag av kompleksitet. I utgangspunktet var det for mange elementer i flyten mellom Vegeta og Kubernetes-belgene. For å identifisere et dypere nettverksproblem, må du utelukke noen av dem.
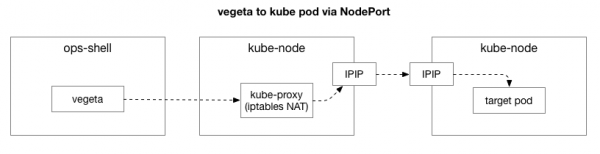
Klienten (Vegeta) oppretter en TCP-forbindelse med en hvilken som helst node i klyngen. Kubernetes fungerer som et overleggsnettverk (på toppen av det eksisterende datasenternettverket) som bruker , det vil si at den kapsler inn IP-pakkene til overleggsnettverket inne i IP-pakkene til datasenteret. Når du kobler til den første noden, utføres nettverksadresseoversettelse (NAT) stateful for å oversette IP-adressen og porten til Kubernetes-noden til IP-adressen og porten i overleggsnettverket (spesifikt poden med applikasjonen). For innkommende pakker utføres omvendt rekkefølge av handlinger. Det er et komplekst system med mye tilstand og mange elementer som hele tiden oppdateres og endres etter hvert som tjenester distribueres og flyttes.
Nytte tcpdump i Vegeta-testen er det en forsinkelse under TCP-håndtrykket (mellom SYN og SYN-ACK). For å fjerne denne unødvendige kompleksiteten, kan du bruke hping3 for enkle "pinger" med SYN-pakker. Vi sjekker om det er en forsinkelse i svarpakken, og tilbakestiller deretter forbindelsen. Vi kan filtrere dataene til kun å inkludere pakker større enn 100 ms og få en enklere måte å reprodusere problemet på enn hele nettverkslag 7-testen i Vegeta. Her er Kubernetes-nodens "pinger" ved hjelp av TCP SYN/SYN-ACK på tjenesten "nodeport" (30927) med 10 ms intervaller, filtrert etter tregeste svar:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flagg=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flagg=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flagg=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flagg=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flagg=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flagg=SA seq=5231 win=29200 rtt=109.2 ms
Kan umiddelbart gjøre den første observasjonen. Etter sekvensnumrene og tidspunktene å dømme, er det klart at dette ikke er engangsoverbelastninger. Forsinkelsen akkumuleres ofte og blir til slutt behandlet.
Deretter ønsker vi å finne ut hvilke komponenter som kan være involvert i forekomsten av overbelastning. Kanskje dette er noen av de hundrevis av iptables-reglene i NAT? Eller er det noen problemer med IPIP-tunnelering på nettverket? En måte å teste dette på er å teste hvert trinn i systemet ved å eliminere det. Hva skjer hvis du fjerner NAT og brannmurlogikk, og bare etterlater IPIP-delen:
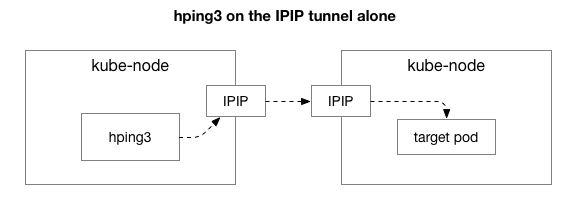
Heldigvis, Linux lar deg enkelt få direkte tilgang til IP-overleggslaget hvis maskinen er på samme nettverk:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flagg=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flagg=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flagg=RA seq=7348 win=0 rtt=107.2 ms
Etter resultatene å dømme gjenstår problemet fortsatt! Dette ekskluderer iptables og NAT. Så problemet er TCP? La oss se hvordan en vanlig ICMP-ping går:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
lengde=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
lengde=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
lengde=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
lengde=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
lengde=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
lengde=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
lengde=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
lengde=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
lengde=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
lengde=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms
Resultatene viser at problemet ikke har forsvunnet. Kanskje dette er en IPIP-tunnel? La oss forenkle testen ytterligere:
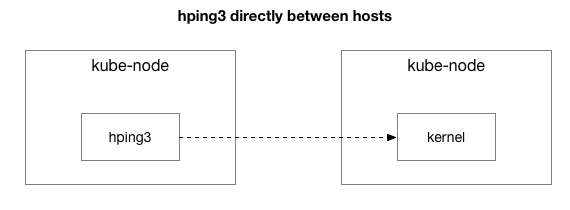
Sendes alle pakker mellom disse to vertene?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
lengde=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
lengde=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
lengde=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
lengde=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
lengde=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
lengde=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
lengde=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
lengde=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
lengde=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 ms
Vi har forenklet situasjonen til to Kubernetes-noder som sender hverandre en hvilken som helst pakke, til og med en ICMP-ping. De ser fortsatt ventetid hvis målverten er "dårlig" (noen verre enn andre).
Nå er det siste spørsmålet: hvorfor skjer forsinkelsen bare på kube-node-servere? Og skjer det når kube-node er avsender eller mottaker? Heldigvis er dette også ganske enkelt å finne ut ved å sende en pakke fra en vert utenfor Kubernetes, men med samme "kjente dårlige" mottaker. Som du kan se, har ikke problemet forsvunnet:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flagg=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flagg=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flagg=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flagg=RA seq=7929 win=0 rtt=131.2 ms
Vi kjører deretter de samme forespørslene fra den forrige kildekubenoden til den eksterne verten (som ekskluderer kildeverten siden pingen inkluderer både en RX- og TX-komponent):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
Ved å undersøke latenspakkefangst fikk vi litt tilleggsinformasjon. Nærmere bestemt at avsenderen (nederst) ser denne tidsavbruddet, men mottakeren (øverst) ikke - se Delta-kolonnen (i sekunder):
I tillegg, hvis du ser på forskjellen i rekkefølgen på TCP- og ICMP-pakker (etter sekvensnummer) på mottakersiden, kommer ICMP-pakker alltid i samme rekkefølge som de ble sendt i, men med forskjellig timing. Samtidig interlever TCP-pakker noen ganger, og noen av dem blir sittende fast. Spesielt hvis du undersøker portene til SYN-pakker, er de i orden på avsenderens side, men ikke på mottakerens side.
Det er en subtil forskjell i hvordan moderne servere (som de i datasenteret vårt) behandler pakker som inneholder TCP eller ICMP. Når en pakke kommer, "hasher" nettverksadapteren den per tilkobling, det vil si at den prøver å bryte tilkoblingene i køer og sende hver kø til en egen prosessorkjerne. For TCP inkluderer denne hashen både kilde- og destinasjons-IP-adressen og porten. Med andre ord, hver tilkobling hashes (potensielt) forskjellig. For ICMP er det bare IP-adresser som hashes, siden det ikke er noen porter.
En annen ny observasjon: i løpet av denne perioden ser vi ICMP-forsinkelser på all kommunikasjon mellom to verter, men TCP gjør det ikke. Dette forteller oss at årsaken sannsynligvis er relatert til RX-køhashing: overbelastningen er nesten helt sikkert i behandlingen av RX-pakker, ikke i sendingen av svar.
Dette eliminerer sending av pakker fra listen over mulige årsaker. Vi vet nå at pakkebehandlingsproblemet er på mottakssiden på noen kube-node-servere.
Forstå pakkebehandling i kjernen Linux
For å forstå hvorfor problemet oppstår på mottakeren på noen kube-node-servere, la oss se på hvordan kjernen Linux behandler pakker.
For å gå tilbake til den enkleste tradisjonelle implementeringen, mottar nettverkskortet pakken og sender kjerne Linuxat det er en pakke som må behandles. Kjernen stopper annet arbeid, bytter kontekst til avbruddshåndtereren, behandler pakken og går deretter tilbake til gjeldende oppgave.
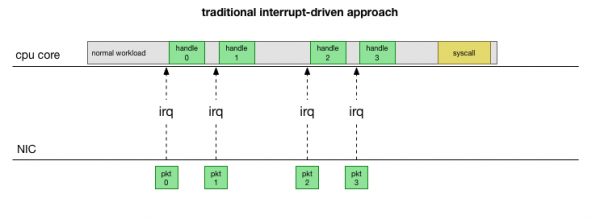
Denne kontekstvekslingen er treg: ventetid var kanskje ikke merkbar på 10 Mbps nettverkskort på 90-tallet, men på moderne 10G-kort med en maksimal gjennomstrømning på 15 millioner pakker per sekund, kan hver kjerne i en liten åttekjernes server bli avbrutt for millioner av mennesker ganger per sekund.
For å unngå å måtte håndtere avbrudd hele tiden, for mange år siden i Linux la til : Network API som alle moderne drivere bruker for å forbedre ytelsen ved høye hastigheter. Ved lave hastigheter mottar kjernen fortsatt avbrudd fra nettverkskortet på den gamle måten. Når nok pakker ankommer som overskrider terskelen, deaktiverer kjernen avbrudd og begynner i stedet å polle nettverksadapteren og plukke opp pakker i biter. Behandlingen utføres i softirq, det vil si i etter systemanrop og maskinvareavbrudd, når kjernen (i motsetning til brukerplass) allerede kjører.
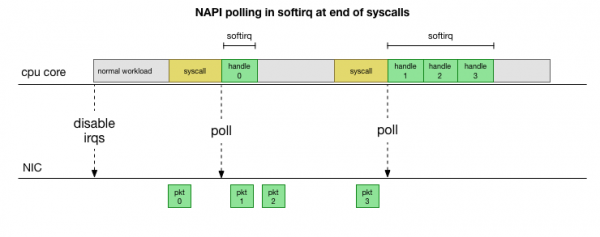
Dette er mye raskere, men forårsaker et annet problem. Hvis det er for mange pakker, går all tiden med til å behandle pakker fra nettverkskortet, og brukerplassprosesser har ikke tid til å faktisk tømme disse køene (lesing fra TCP-tilkoblinger osv.). Etter hvert fylles køene opp og vi begynner å slippe pakker. I et forsøk på å finne en balanse, setter kjernen et budsjett for maksimalt antall pakker som behandles i softirq-konteksten. Når dette budsjettet er overskredet, vekkes en egen tråd ksoftirqd (du vil se en av dem i ps per kjerne) som håndterer disse softirqene utenfor den normale syscall/avbruddsbanen. Denne tråden er planlagt ved hjelp av standard prosessplanlegger, som prøver å fordele ressurser rettferdig.
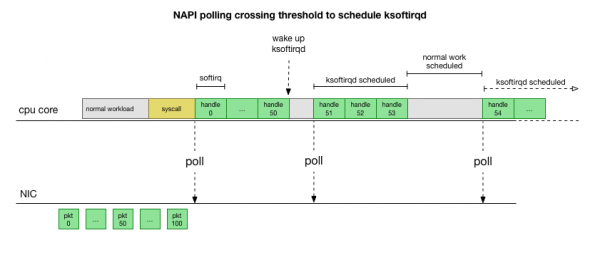
Etter å ha studert hvordan kjernen behandler pakker, kan du se at det er en viss sannsynlighet for overbelastning. Hvis softirq-anrop mottas sjeldnere, vil pakker måtte vente en stund på å bli behandlet i RX-køen på nettverkskortet. Dette kan skyldes at en oppgave blokkerer prosessorkjernen, eller noe annet hindrer kjernen i å kjøre softirq.
Innsnevring av behandlingen til kjernen eller metoden
Softirq-forsinkelser er bare en gjetning foreløpig. Men det er fornuftig, og vi vet at vi ser noe veldig likt. Så neste trinn er å bekrefte denne teorien. Og hvis det er bekreftet, så finn årsaken til forsinkelsene.
La oss gå tilbake til våre langsomme pakker:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
lengde=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
lengde=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
lengde=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
lengde=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
lengde=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
lengde=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
lengde=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms
Som diskutert tidligere, blir disse ICMP-pakkene hashet inn i en enkelt NIC RX-kø og behandlet av en enkelt CPU-kjerne. Hvis vi ønsker å forstå operasjonen Linux, er det nyttig å vite hvor (på hvilken CPU-kjerne) og hvordan (softirq, ksoftirqd) disse pakkene behandles for å spore prosessen.
Nå er det på tide å bruke verktøy som lar deg overvåke kjernens ytelse i sanntid. LinuxHer brukte vi . Dette settet med verktøy lar deg skrive små C-programmer som kobler vilkårlige funksjoner i kjernen og buffer hendelsene inn i et Python-program på brukerområdet som kan behandle dem og returnere resultatet til deg. Å koble til vilkårlige funksjoner i kjernen er en vanskelig forretning, men verktøyet er designet for maksimal sikkerhet og er designet for å spore opp nøyaktig den type produksjonsproblemer som ikke lett kan reproduseres i et test- eller utviklingsmiljø.
Planen her er enkel: vi vet at kjernen behandler disse ICMP-pingene, så vi setter en krok på kjernefunksjonen , som aksepterer en innkommende ICMP-ekkoforespørselspakke og starter sending av et ICMP-ekkosvar. Vi kan identifisere en pakke ved å øke icmp_seq-nummeret, som viser hping3 ovenfor.
Kode ser komplisert ut, men det er ikke så skummelt som det virker. Funksjon icmp_echo formidler struct sk_buff *skb: Dette er en "ekkoforespørsel"-pakke. Vi kan spore det, trekke ut sekvensen echo.sequence (som sammenlignes med icmp_seq av hping3 выше), og send den til brukerområdet. Det er også praktisk å fange opp gjeldende prosessnavn/id. Nedenfor er resultatene som vi ser direkte mens kjernen behandler pakker:
TGID PID PROSESSNAVN ICMP_SEQ 0 0 bytte/11 770 0 bytte/0 11 771 bytte/0 0 11 bytte/772 0 0 bytte/11 773 0 prometheus 0 11 774 bytte/20041 20086 775 bytte/0 0 11 bytte/776 0 0 eiker-rapport-s 11
Det skal her bemerkes at i sammenhengen softirq prosesser som foretok systemanrop vil vises som "prosesser" når det faktisk er kjernen som trygt behandler pakker i konteksten til kjernen.
Med dette verktøyet kan vi knytte spesifikke prosesser til spesifikke pakker som viser en forsinkelse på hping3. La oss gjøre det enkelt grep på denne fangsten for visse verdier icmp_seq. Pakker som samsvarer med icmp_seq-verdiene ovenfor ble flagget sammen med deres RTT vi observerte ovenfor (i parentes er de forventede RTT-verdiene for pakker vi filtrerte ut på grunn av RTT-verdier mindre enn 50ms):
TGID PID PROSESSNAVN ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99ms 76 76 ksoftirqd/11 1954 ** 89ms 76 76 ksoftirqd/11 1955 ** 79ms 76 76 ksoftirqd/11 1956 ** 69ms 76 76 ksoftirqd/11 1957 ** 59ms 76 76 ksoftirqd/11 1958 ** (49 ms) 76 76 ksoftirqd/11 1959 ** (39 ms) 76 76 ksoftirqd/11 1960 ** (29 ms) 76 76 ksoftirqd/11 1961 ** (19 ms) 76 76 ksoftirqd/11 1962 ** (9 ms) -- 10137 10436 cadvisor 2068 10137 10436 cadvisor 2069 76 76 ksoftirqd/11 2070 ** 75ms 76 76 ksoftirqd/11 2071 ** 65ms 76 76 ksoftirqd/11 2072 ** 55ms 76 76 ksoftirqd/11 2073 ** (45 ms) 76 76 ksoftirqd/11 2074 ** (35 ms) 76 76 ksoftirqd/11 2075 ** (25 ms) 76 76 ksoftirqd/11 2076 ** (15 ms) 76 76 ksoftirqd/11 2077 ** (5ms)
Resultatene forteller oss flere ting. For det første behandles alle disse pakkene av konteksten ksoftirqd/11. Dette betyr at for dette spesielle paret av maskiner ble ICMP-pakker hashe til kjerne 11 på mottakersiden. Vi ser også at når det er en jam, er det pakker som behandles i sammenheng med systemkallingen cadvisor. deretter ksoftirqd tar over oppgaven og behandler den akkumulerte køen: nøyaktig antall pakker som har akkumulert etter cadvisor.
Det faktum at umiddelbart før det alltid fungerer cadvisor, antyder hans engasjement i problemet. Ironisk nok hensikten - "analysere ressursbruk og ytelsesegenskaper til kjørende containere" i stedet for å forårsake dette ytelsesproblemet.
Som med andre aspekter av containere, er disse alle svært avanserte verktøy og kan forventes å oppleve ytelsesproblemer under noen uforutsette omstendigheter.
Hva gjør cadvisor som bremser pakkekøen?
Nå har vi en ganske god forståelse av hvordan krasjet oppstår, hvilken prosess som forårsaker det, og på hvilken CPU. Vi ser at på grunn av den harde låsingen, kjernen Linux har ikke tid til å planlegge i tide ksoftirqd. Og vi ser at pakker behandles i kontekst cadvisor. Det er logisk å anta det cadvisor starter en langsom syscall, hvoretter alle pakker akkumulert på det tidspunktet blir behandlet:
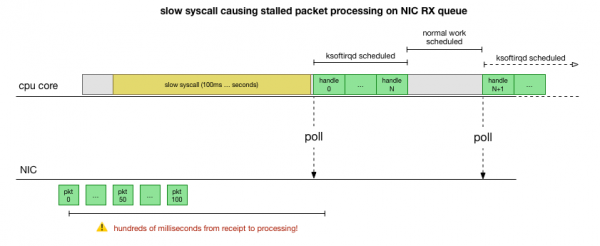
Dette er en teori, men hvordan tester man den? Det vi kan gjøre er å spore CPU-kjernen gjennom denne prosessen, finne punktet hvor antall pakker går over budsjettet og ksoftirqd kalles, og så se litt lenger tilbake for å se nøyaktig hva som kjørte på CPU-kjernen rett før det punktet . Det er som å røntgenbilde CPUen med noen få millisekunder. Det vil se omtrent slik ut:
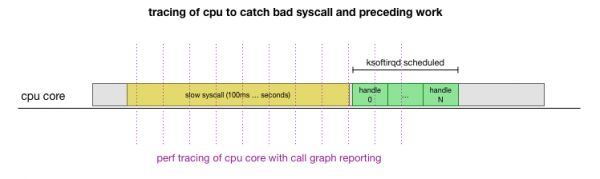
Beleilig kan alt dette gjøres med eksisterende verktøy. For eksempel, sjekker en gitt CPU-kjerne med en spesifisert frekvens og kan generere en kallegraf over det kjørende systemet, inkludert både brukerplass og kjernen LinuxDu kan ta denne posten og behandle den ved hjelp av en liten fork i programmet. fra Brendan Gregg, som bevarer rekkefølgen på stabelsporet. Vi kan lagre enkeltlinjes stabelspor hver 1 ms, og deretter markere og lagre en prøve 100 millisekunder før sporet treffer ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
Her er resultatene:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
Det er mange ting her, men hovedsaken er at vi finner "cadvisor before ksoftirqd"-mønsteret som vi så tidligere i ICMP-sporeren. Hva betyr det?
Hver linje er et CPU-spor på et bestemt tidspunkt. Hvert anrop nedover stabelen på en linje er atskilt med et semikolon. I midten av linjene ser vi syskallet som kalles: read(): .... ;do_syscall_64;sys_read; .... Så cadvisor bruker mye tid på systemsamtalen read()relatert til funksjoner mem_cgroup_* (øverst på anropsstabel/slutt av linjen).
Det er upraktisk å se i en samtalesporing nøyaktig hva som blir lest, så la oss løpe strace og la oss se hva cadvisor gjør og finne systemanrop som er lengre enn 100 ms:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
Som du kanskje forventer, ser vi trege anrop her read(). Fra innholdet i leseoperasjoner og kontekst mem_cgroup det er klart at disse utfordringene read() referer til filen memory.stat, som viser minnebruk og cgroup-grenser (Dockers ressursisolasjonsteknologi). Cadvisor-verktøyet spør etter denne filen for å få informasjon om ressursbruk for containere. La oss sjekke om det er kjernen eller cadvisor som gjør noe uventet:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
ekte 0m0.153s
bruker 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $
Nå kan vi reprodusere feilen og forstå at kjernen Linux møter patologi.
Hvorfor er leseoperasjonen så treg?
På dette stadiet er det mye lettere å finne meldinger fra andre brukere om lignende problemer. Som det viste seg, ble denne feilen rapportert som i cadvisor-trackeren , det er bare det at ingen la merke til at latensen også reflekteres tilfeldig i nettverksstakken. Det ble faktisk lagt merke til at cadvisor brukte mer CPU-tid enn forventet, men dette ble ikke gitt stor betydning, siden våre servere har mange CPU-ressurser, så problemet ble ikke nøye studert.
Problemet er at cgroups tar hensyn til minnebruk i navneområdet (beholderen). Når alle prosessene i denne cgroup avsluttes, slipper Docker minne cgroup. Men "minne" er ikke bare prosessminne. Selv om selve prosessminnet ikke lenger brukes, ser det ut til at kjernen fortsatt tildeler bufret innhold, slik som dentries og inoder (katalog- og filmetadata), som er bufret i minnet-cgroup. Fra problembeskrivelsen:
zombie cgroups: cgroups som ikke har noen prosesser og har blitt slettet, men som fortsatt har minne tildelt (i mitt tilfelle fra dentry-cachen, men det kan også tildeles fra sidecachen eller tmpfs).
Kjernens sjekk av alle sidene i hurtigbufferen ved frigjøring av en cgroup kan være veldig treg, så den late prosessen er valgt: vent til disse sidene blir bedt om igjen, og tøm til slutt cgroup når minnet faktisk er nødvendig. Inntil dette er cgroup fortsatt tatt i betraktning ved innsamling av statistikk.
Fra et ytelsessynspunkt ofret de minne for ytelse: fremskynde den første oppryddingen ved å legge igjen noe bufret minne. Dette er greit. Når kjernen bruker det siste av det hurtigbufrede minnet, blir cgroup til slutt tømt, så den kan ikke kalles en "lekkasje". Dessverre, den spesifikke implementeringen av søkemekanismen memory.stat i denne kjerneversjonen (4.9), kombinert med den enorme mengden minne på serverne våre, betyr det at det tar mye lengre tid å gjenopprette de siste hurtigbufrede dataene og tømme cgroup-zombier.
Det viser seg at noen av nodene våre hadde så mange cgroup-zombier at lesingen og latensen oversteg et sekund.
Løsningen for cadvisor-problemet er å umiddelbart frigjøre dentries/inodes-cacher i hele systemet, noe som umiddelbart eliminerer leselatens så vel som nettverkslatens på verten, siden tømming av cachen slår på de bufrede cgroup zombiesidene og de frigjøres også. Dette er ikke en løsning, men det bekrefter årsaken til problemet.
Det viste seg at i nyere kjerneversjoner (4.19+) ble anropsytelsen forbedret memory.stat, så å bytte til denne kjernen løste problemet. Samtidig hadde vi verktøy for å oppdage problematiske noder i Kubernetes-klynger, tømme dem elegant og starte dem på nytt. Vi finkjemmet alle klyngene, fant noder med høy nok ventetid og startet dem på nytt. Dette ga oss tid til å oppdatere OS på de gjenværende serverne.
Oppsummering
Fordi denne feilen stoppet RX NIC-købehandlingen i hundrevis av millisekunder, forårsaket den samtidig både høy latens på korte tilkoblinger og mid-connection latency, for eksempel mellom MySQL-forespørsler og svarpakker.
Å forstå og vedlikeholde ytelsen til de mest grunnleggende systemene, som Kubernetes, er avgjørende for påliteligheten og hastigheten til alle tjenester basert på dem. Hvert system du kjører drar nytte av Kubernetes ytelsesforbedringer.
Kilde: www.habr.com
