


Det gjør bare vondt første gang!
Hei alle sammen! Kjære venner, i denne artikkelen vil jeg dele min erfaring med å bruke TensorRT, RetinaNet basert på depotet (dette er en gaffel av den offisielle kålroten fra , som lar deg begynne å bruke optimaliserte modeller i produksjon så snart som mulig). Bla gjennom meldinger i fellesskapskanaler , Jeg får spørsmål om bruk av TensorRT og spørsmålene gjentar seg stort sett, så jeg bestemte meg for å skrive så komplett som mulig En guide til bruk av rask inferens basert på TensorRT, RetinaNet, Unet og docker.
Oppgavebeskrivelse
Jeg foreslår å formulere oppgaven på denne måten: vi må merke datasettet, trene RetinaNet/Unet-nettverket på Pytorch 1.3+, konvertere de oppnådde vektene til ONNX, deretter konvertere dem til TensorRT-motoren og kjøre det hele i Docker, helst på Ubuntu 18 og svært ønskelig på ARM (Jetson)*-arkitekturen, og dermed minimere manuell distribusjon av miljøet. Sluttresultatet vil være en container som er klar ikke bare for eksport og trening av RetinaNet/Unet, men også for fullverdig utvikling og trening av klassifiserings- og segmenteringssystemer, med all nødvendig maskinvare.
Trinn 1. Forberede miljøet
Det er viktig å merke seg her at jeg nylig har helt forlatt bruken og distribusjonen av i det minste noen biblioteker på en stasjonær maskin, så vel som på devbox. Det eneste du må lage og installere er python virtual environment og cuda 10.2 (du kan begrense deg til én nvidia-driver) fra deb.
La oss anta at du har en nylig installert Ubuntu 18. La oss installere cuda 10.2 (deb). Jeg vil ikke gå i detalj om installasjonsprosessen, den offisielle dokumentasjonen er helt tilstrekkelig.
La oss nå installere docker, installasjonsveiledningen for docker kan enkelt finnes, her er et eksempel , versjon 19+ er allerede tilgjengelig - installer den. Vel, ikke glem å gjøre det mulig å bruke docker uten sudo, det vil være mer praktisk. Etter at alt har ordnet seg, gjør vi dette:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
Og du trenger ikke engang å se på det offisielle depotet .
La oss nå git-klone .
Det er bare litt igjen, for å begynne å bruke docker med et nvidia-bilde, må vi registrere oss hos NGC Cloud og logge inn. La oss gå hit , registrer deg og etter at vi har kommet inn i NGC Cloud, klikk på OPPSETT i øvre venstre hjørne av skjermen eller følg denne lenken . Klikk på "generer nøkkel". Jeg anbefaler å lagre den, ellers må du generere den på nytt neste gang du besøker den, og følgelig installere den på en ny bil og gjenta denne operasjonen.
La oss gjøre:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
Brukernavnet er ganske enkelt kopiert. Vel, tenk på miljøet som er utplassert!
Trinn 2: Bygge docker-containeren
I den andre fasen av arbeidet vårt vil vi bygge docker og gjøre oss kjent med dens indre.
La oss gå til rotmappen i forhold til retina-eksempler-prosjektet og kjøre
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Vi bygger docker ved å sende gjeldende bruker inn i den - dette er veldig nyttig hvis du skriver noe til et montert VOLUME med rettighetene til gjeldende bruker, ellers vil det være root and pain.
Mens docker bygger, la oss undersøke Dockerfilen:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Som du kan se fra teksten, tar vi alle favorittbibliotekene våre, kompilerer retinanet, og legger til noen grunnleggende verktøy for enkelhets skyld. Ubuntu og konfigurer OpenSSH-serveren. Den første linjen arver NVIDIA-imaget som vi opprettet NGC Cloud-påloggingen for, og som inneholder Pytorch1.3, TensorRT6.xxx og en rekke andre biblioteker som lar oss kompilere CPP-kildekoden for detektoren vår.
Trinn 3: Lansering og feilsøking av Docker Container
La oss gå videre til hovedsaken med bruk av container- og utviklingsmiljøet; La oss først starte nvidia docker. La oss gjøre:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestContaineren er nå tilgjengelig via ssh @lokal vert. Etter vellykket lansering åpner du prosjektet i PyCharm. Neste åpner vi
Settings->Project Interpreter->Add->Ssh Interpreter Trinn 1
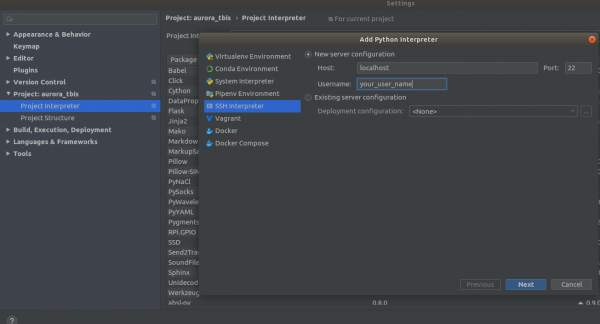
Trinn 2
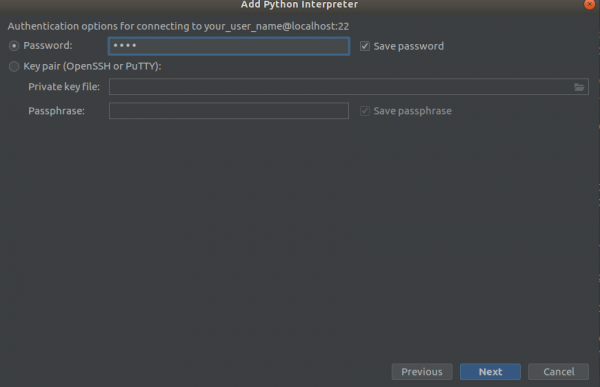
Trinn 3
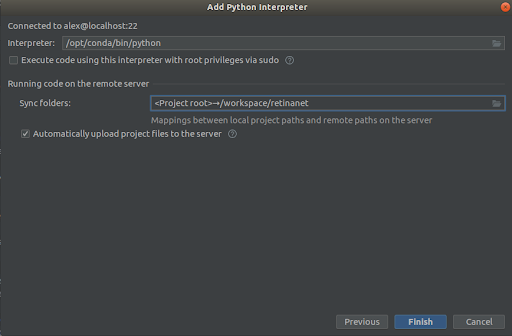
Vi velger alt som i skjermbildene,
Interpreter -> /opt/conda/bin/python- dette vil være inne i Python3.6 og
Sync folder -> /workspace/retinanetVi trykker på fullfør, venter på indeksering, og det er det, miljøet er klart til bruk!
VIKTIG !!! Umiddelbart etter indeksering, trekk de kompilerte filene for Retinanet fra docker. Velg elementet i kontekstmenyen i prosjektroten
Deployment->DownloadEn fil og to mapper vises: build, retinanet.egg-info og _С.so
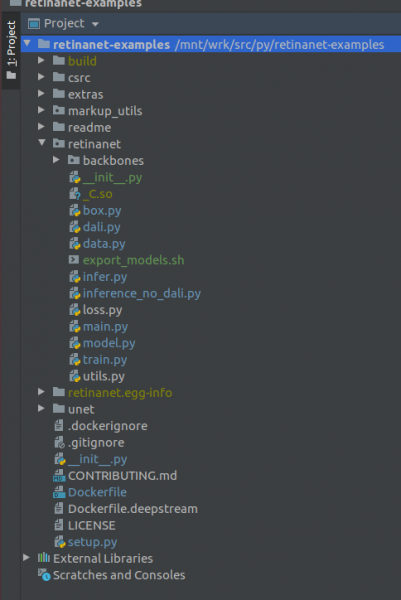
Hvis prosjektet ditt ser slik ut, så ser miljøet alle nødvendige filer og vi er klare til å trene RetinaNet.
Trinn 4. Merk dataene og tren opp detektoren
For markering bruker jeg hovedsakelig — et hyggelig og praktisk verktøy, nylig har en haug med feil blitt fikset og det har blitt betydelig bedre oppført.
La oss anta at du har merket opp datasettet og lastet det ned, men du vil ikke umiddelbart kunne legge det inn i vårt RetinaNet, siden det er i sitt eget format og for dette må vi konvertere det til COCO. Konverteringsverktøyet er plassert i:
markup_utils/supervisly_to_coco.pyVær oppmerksom på at kategori i skriptet er et eksempel, og du må sette inn din egen (det er ikke nødvendig å legge til bakgrunnskategorien)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Av en eller annen grunn bestemte forfatterne av det originale depotet at du ikke ville trene noe annet enn COCO/VOC for deteksjon, så de måtte redigere kildefilen litt
retinanet/dataset.pyVed å legge til favorittutvidelsene dine her og kuttet ut fastkoblede kategorier fra COCO. Det er også mulig å beskjære store deteksjonsområder, leter du etter små objekter i store bilder har du et lite datasett =), og ingenting fungerer, men mer om det en annen gang.
Generelt er togsløyfen også svak, i utgangspunktet lagret den ikke sjekkpunkter, den brukte en slags forferdelig planlegger, etc. Men nå er det bare å velge ryggraden og utføre
/opt/conda/bin/python retinanet/main.pymed parametere:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
I konsollen vil du se:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148For å utforske hele settet med parametere, se
retinanet/main.pyGenerelt er de standard for deteksjon, og de har en beskrivelse. Start treningen og vent på resultatene. Et eksempel på slutning kan sees i:
retinanet/infer_example.pyeller kjør kommandoen:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
Lagret har allerede Focal Loss og flere ryggrader innebygd, og det er også enkelt å bygge inn din egen
retinanet/backbones/*.pyI tabellen gir forfatterne noen karakteristikker:
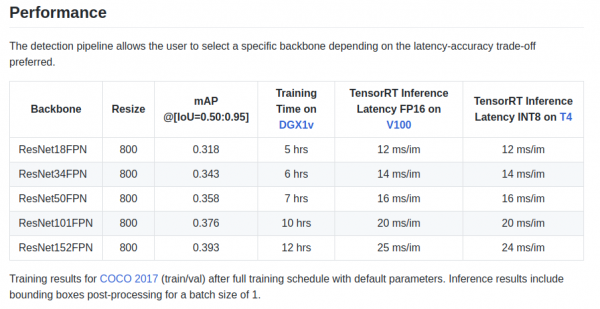
Det er også en ryggrad ResNeXt50_32x4dFPN og ResNeXt101_32x8dFPN, hentet fra torchvision.
Jeg håper du har funnet ut av deteksjonen litt, men du bør definitivt lese den offisielle dokumentasjonen slik at forstå eksport- og loggingsmoduser.
Trinn 5. Eksport og slutning av Unet-modeller med Resnet-koder
Som du sikkert har lagt merke til, ble biblioteker for segmentering installert i Dockerfile, og spesielt den fantastiske lib . I unitet-pakken kan du finne eksempler på inferens og eksport av pytorch-sjekkpunkter til TensorRT-motoren.
Hovedproblemet ved eksport av Unet-lignende modeller fra ONNX til TensoRT er behovet for å angi en fast Upsample-størrelse eller bruke ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
Ved å bruke denne transformasjonen kan du gjøre dette automatisk når du eksporterer til ONNX, men allerede i versjon 7 av TensorRT ble dette problemet løst, og vi må vente en del.
Konklusjon
Da jeg begynte å bruke docker, var jeg i tvil om ytelsen til oppgavene mine. En av enhetene mine har for tiden ganske mye nettverkstrafikk generert av flere kameraer.
Ulike tester på Internett snakket om en relativt stor overhead for nettverksinteraksjon og opptak på VOLUME, pluss den ukjente og forferdelige GIL, og siden fange en ramme, er betjening av driveren og overføring av rammen over nettverket en atomoperasjon i modusen vanskelig sanntid, nettverksforsinkelser er svært kritiske for meg.
Men alt gikk bra =)
PS Alt som gjenstår er å legge til favoritttogsløyfen for segmentering og produksjon!
Takk
Takk til fellesskapet , uten det er det umulig å utvikle! Takk så mye , som oppmuntret meg til å gjøre DL, for hans uvurderlige råd og ekstreme profesjonalitet!
Bruk optimaliserte modeller i produksjonen!
 Aurorai, LLC
Aurorai, LLC
Kilde: www.habr.com
