

Dette innlegget vil være av interesse for de som bruker databehandlingsbiblioteket data.table i R-tabellen, og som kanskje vil sette pris på å se fleksibiliteten i bruken i ulike eksempler.
Inspirert av et godt eksempel , og i håp om at du allerede har lest artikkelen hans, foreslår jeg at du går dypere inn i kodeoptimalisering og ytelse basert på data bord.
Introduksjon: Hvor kommer data.table fra?
Det er best å begynne å bli kjent med biblioteket litt lenger unna, nemlig med datastrukturene som data.table-objektet (heretter kalt DT) kan hentes fra.
matrise
Kode
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
En slik struktur er en matrise (?base::array). Som i andre språk er arrayer her flerdimensjonale. Det som er interessant er imidlertid at for eksempel en todimensjonal array begynner å arve egenskaper fra matriseklassen. (?base::matrise), og en endimensjonal matrise, som også er viktig, arver ikke fra en vektor (?base::vektor).
Det er viktig å forstå at datatypen i et objekt bør kontrolleres av funksjonen base::typeof, som returnerer den interne beskrivelsen av typen i henhold til R-innvendige deler — en felles språkprotokoll knyttet til originalen C.
En annen kommando for å bestemme klassen til et objekt, base::class, i tilfelle vektorer, returnerer vektortypen (den har et annet navn enn det interne, men lar deg også forstå datatypen).
Liste
Fra en todimensjonal matrise, også kjent som en matrise, kan du gå til en liste (?base::list).
Kode
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Flere ting skjer samtidig:
- Den andre dimensjonen av matrisen kollapser, det vil si at vi får både en liste og en vektor samtidig.
- En liste arver dermed fra disse klassene. Husk at hvert listeelement vil korrespondere med en enkelt (skalar) verdi fra en celle i matrise-arrayet.
Siden en liste også er en vektor, kan noen vektorfunksjoner brukes på den.
Dataramme
Fra en liste, matrise eller vektor kan du gå til en dataramme (?base::data.frame).
Kode
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Det interessante med det er at datarammen arver fra en liste! Datarammens kolonner er listens celler. Dette vil være viktig senere når vi bruker funksjoner som gjelder for lister.
data bord
Hent DT (?data.tabell::data.tabell) kan være fra dataramme, liste, vektor eller matrise. For eksempel, slik som dette (på plass).
Kode
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Det som er nyttig er at en DT, i likhet med en dataframe, arver egenskapene til en liste.
DT og minne
I motsetning til alle andre objekter i R-basen sendes DT-er via referanse. Hvis du trenger å kopiere dem til en ny minneplassering, trenger du en funksjon data.tabell::kopi eller du må gjøre et valg fra det gamle objektet.
Kode
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Dette avslutter introduksjonen. DT er en fortsettelse av utviklingen av datastrukturer i R, primært gjennom utvidelse og akselerasjon av operasjoner utført på dataframe-objekter. Samtidig som arv fra andre primitiver opprettholdes.
Noen eksempler på bruk av data.table-egenskaper
Som en liste…
Å iterere over radene i en dataframe eller DT er ikke den beste ideen, siden løkkekoden er i språket. R mye tregere C, men det er fullt mulig å gå gjennom kolonner i løkker, som vanligvis er mye færre. Når du går gjennom kolonner i løkker, husk at hver kolonne er et listeelement, som vanligvis inneholder en vektor. Og operasjoner på vektorer er godt vektorisert i de grunnleggende språkfunksjonene. Du kan også bruke utvalgsoperatorene som er iboende i lister og vektorer: `[[`, `$`.
Kode
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vektorisering
Hvis du trenger å iterere gjennom en stor DT, er den beste løsningen å skrive en vektorisert funksjon. Men hvis det ikke fungerer, husk at løkken innenfor DT er fortsatt raskere enn syklusen i R, siden den utføres på C.
La oss prøve det på et større eksempel med 100 000 rader. Vi trekker ut den første bokstaven fra ord som er inkludert i kolonnevektoren. w.
oppdatert
Kode
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Første kjøring med iterasjon over rader:
Enhet: millisekunder
uttrykk min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", fixed = T))[1]), by = 1:nrow(dt)] } 439.6217
lq gjennomsnittlig median uq maks neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
Den andre kjøringen, hvor vektorisering skjer ved å konvertere listen til en matrise og ta elementene i seksjonen med indeks 1 (sistnevnte er den faktiske vektoriseringen). Korreksjon: vektorisering på funksjonsnivå. strsplitt, som kan akseptere en vektor som input. Det viser seg at prosedyren for å konvertere en liste til en matrise er mye mer kompleks enn selve vektoriseringen, men selv i dette tilfellet er den mye raskere enn den ikke-vektoriserte versjonen.
Enhet: millisekunder
expr min lq gjennomsnitt median uq max neval
{ dt[, `:=`(første_l, .(første_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Akselerasjon med median i 3 ganger.
Den tredje kjøringen, der matrisekonverteringsskjemaet ble endret.
Enhet: millisekunder
expr min lq gjennomsnitt median uq max neval
{ dt[, `:=`(første_l, .(første_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Akselerasjon med median i 13 ganger.
Du må eksperimentere med dette, jo mer jo bedre.
Her er et annet vektoriseringseksempel, også med tekst, men nærmere virkelige forhold: forskjellige ordlengder og forskjellige ordtall. Målet er å trekke ut de tre første ordene. Slik:
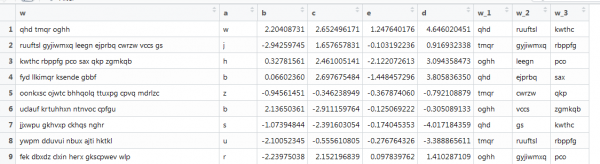
Den forrige funksjonen fungerer ikke her fordi vektorene har ulik lengde, og vi spesifiserte matrisestørrelsen. La oss omarbeide dette ved å grave litt rundt på nettet.
Kode
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Enhet: millisekunder
uttrykk min lq gjennomsnitt median
{ dt[, `:=`((paste0(“w_”, 1:3)), strsplit(w, split = " ", fixed = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Skriptet kjørte med en gjennomsnittshastighet på 1 sekund. Ikke verst.
Sammenknyttet av én kjede…
Du kan jobbe med DT-objekter ved hjelp av kjedekobling. Dette ser ut som å kjede sammen parentessyntaksen til høyre, i hovedsak et sukkerlag.
Kode
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Det lekker gjennom rørene...
De samme operasjonene kan utføres ved hjelp av piping; det ser likt ut, men er mer funksjonelt rikt, ettersom alle metoder kan brukes, ikke bare DT. La oss utlede de logistiske regresjonskoeffisientene for våre syntetiske data med en rekke DT-filtre.
Kode
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Statistikk, maskinlæring og mer innen DT
Lambda-funksjoner kan brukes, men noen ganger er det bedre å opprette dem separat, skrive hele dataanalysepipelinen, og så er du i gang – de fungerer i DT-en. Eksemplet er beriket med alle funksjonene nevnt ovenfor, pluss flere nyttige ting fra DT-arsenalet (som å få tilgang til selve DT-en i DT-en via en lenke, noen ganger satt inn i feil rekkefølge, men bare for å være sikker).
Kode
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
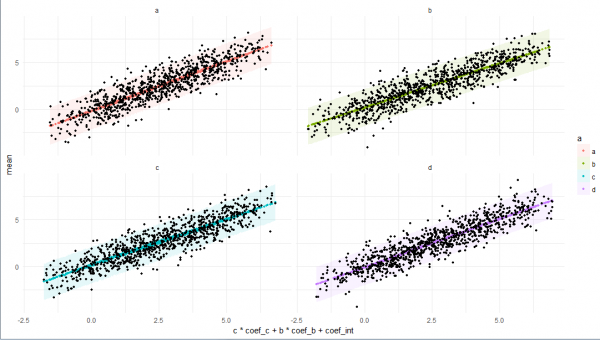
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Konklusjon
Jeg håper jeg har klart å skape et omfattende, men absolutt ikke fullstendig, bilde av data.table-objektet, fra dets egenskaper knyttet til arv fra R-klasser til dets egne funksjoner og miljø av tidyverse-elementer. Jeg håper dette vil hjelpe deg å bedre forstå og anvende dette biblioteket i arbeidet ditt. underholdning.
Takk!
Full kode
Kode
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Kilde: www.habr.com
