

Nazywam się Igor Sidorenko i jestem liderem technicznym w zespole administratorów, którzy dbają o to, aby cała infrastruktura Domclick działała prawidłowo.
Chciałbym podzielić się swoim doświadczeniem w zakresie konfiguracji rozproszonego przechowywania danych w Elasticsearch. Przyjrzymy się, które ustawienia na węzłach odpowiadają za dystrybucję fragmentów, jak zbudowany jest ILM i jak działa.
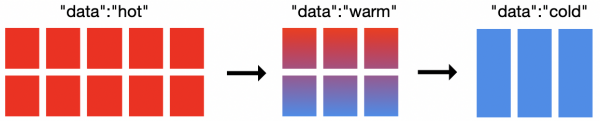
Osoby pracujące z dziennikami, w ten czy inny sposób, stają przed problemem ich długoterminowego przechowywania na potrzeby późniejszej analizy. W przypadku Elasticsearch jest to szczególnie istotne, ponieważ funkcjonalność kuratora była żałosna. Wersja 6.6 wprowadziła funkcjonalność ILM. Składa się z 4 faz:
- Gorąco - indeks jest aktywnie aktualizowany i wyszukiwany.
- Ciepły - indeks nie jest już aktualizowany, ale nadal jest kwerendowany.
- Zimno - indeks nie jest już aktualizowany i rzadko jest sprawdzany. Informacje nadal powinny dać się przeszukiwać, jednak zapytania mogą być wolniejsze.
- Usuń – indeks nie jest już potrzebny i można go bezpiecznie usunąć.
Dany
- Elasticsearch Data Hot: 24 procesory, 128 GB pamięci, dysk SSD 1,8 TB RAID 10 (8 węzłów).
- Ciepłe dane Elasticsearch: 24 procesory, 64 GB pamięci, zasady dotyczące dysków SSD NetApp o pojemności 8 TB (4 węzły).
- Elasticsearch Data Cold: 8 procesorów, pamięć 32 GB, dysk twardy 128 TB RAID 10 (4 węzły).
cel
Ustawienia te są indywidualne, wszystko zależy od miejsca na węzłach, ilości indeksów, logów itd. Dla nas jest to 2-3 TB danych dziennie.
- 5 dni - Faza gorąca (8 głównych / 1 replika).
- 20 dni - Faza ciepła ( 4 główne / 1 replika).
- 90 dni - Faza zimna ( 4 główne / 1 replika).
- 120 dni – faza usuwania.
Konfigurowanie Elasticsearch
Aby rozprowadzić fragmenty pomiędzy węzłami, potrzebny jest tylko jeden parametr:
- HOT-węzły:
~]# cat /etc/elasticsearch/elasticsearch.yml | grep attr # Add custom attributes to the node: node.attr.box_type: hot - Ciepły-węzły:
~]# cat /etc/elasticsearch/elasticsearch.yml | grep attr # Add custom attributes to the node: node.attr.box_type: warm - Zimno-węzły:
~]# cat /etc/elasticsearch/elasticsearch.yml | grep attr # Add custom attributes to the node: node.attr.box_type: cold
Konfigurowanie Logstash
Jak to wszystko działa i w jaki sposób wdrożyliśmy tę funkcję? Zacznijmy od pobrania logów do Elasticsearch. Istnieją dwa sposoby:
- Logstash pobiera logi z Kafki. Możesz oczyścić lub przekształcić po swojej stronie.
- Coś zapisuje dane do samego Elasticsearch, na przykład serwer APM.
Przyjrzyjmy się przykładowi zarządzania indeksami za pośrednictwem Logstash. Tworzy indeks i stosuje go do i odpowiedni .
k8s-ingress.conf
input {
kafka {
bootstrap_servers => "node01, node02, node03"
topics => ["ingress-k8s"]
decorate_events => false
codec => "json"
}
}
filter {
ruby {
path => "/etc/logstash/conf.d/k8s-normalize.rb"
}
if [log] =~ "[warn]" or [log] =~ "[error]" or [log] =~ "[notice]" or [log] =~ "[alert]" {
grok {
match => { "log" => "%{DATA:[nginx][error][time]} [%{DATA:[nginx][error][level]}] %{NUMBER:[nginx][error][pid]}#%{NUMBER:[nginx][error][tid]}: *%{NUMBER:[nginx][error][connection_id]} %{DATA:[nginx][error][message]}, client: %{IPORHOST:[nginx][error][remote_ip]}, server: %{DATA:[nginx][error][server]}, request: "%{WORD:[nginx][error][method]} %{DATA:[nginx][error][url]} HTTP/%{NUMBER:[nginx][error][http_version]}", (?:upstream: "%{DATA:[nginx][error][upstream][proto]}://%{DATA:[nginx][error][upstream][host]}:%{DATA:[nginx][error][upstream][port]}/%{DATA:[nginx][error][upstream][url]}", )?host: "%{DATA:[nginx][error][host]}"(?:, referrer: "%{DATA:[nginx][error][referrer]}")?" }
remove_field => "log"
}
}
else {
grok {
match => { "log" => "%{IPORHOST:[nginx][access][host]} - [%{IPORHOST:[nginx][access][remote_ip]}] - %{DATA:[nginx][access][remote_user]} [%{HTTPDATE:[nginx][access][time]}] "%{WORD:[nginx][access][method]} %{DATA:[nginx][access][url]} HTTP/%{NUMBER:[nginx][access][http_version]}" %{NUMBER:[nginx][access][response_code]} %{NUMBER:[nginx][access][bytes_sent]} "%{DATA:[nginx][access][referrer]}" "%{DATA:[nginx][access][agent]}" %{NUMBER:[nginx][access][request_lenght]} %{NUMBER:[nginx][access][request_time]} [%{DATA:[nginx][access][upstream][name]}] (?:-|%{IPORHOST:[nginx][access][upstream][addr]}:%{NUMBER:[nginx][access][upstream][port]}) (?:-|%{NUMBER:[nginx][access][upstream][response_lenght]}) %{DATA:[nginx][access][upstream][response_time]} %{DATA:[nginx][access][upstream][status]} %{DATA:[nginx][access][request_id]}" }
remove_field => "log"
}
}
}
output {
elasticsearch {
id => "k8s-ingress"
hosts => ["node01", "node02", "node03", "node04", "node05", "node06", "node07", "node08"]
manage_template => true # включаем управление шаблонами
template_name => "k8s-ingress" # имя применяемого шаблона
ilm_enabled => true # включаем управление ILM
ilm_rollover_alias => "k8s-ingress" # alias для записи в индексы, должен быть уникальным
ilm_pattern => "{now/d}-000001" # шаблон для создания индексов, может быть как "{now/d}-000001" так и "000001"
ilm_policy => "k8s-ingress" # политика прикрепляемая к индексу
index => "k8s-ingress-%{+YYYY.MM.dd}" # название создаваемого индекса, может содержать %{+YYYY.MM.dd}, зависит от ilm_pattern
}
}Konfigurowanie Kibany
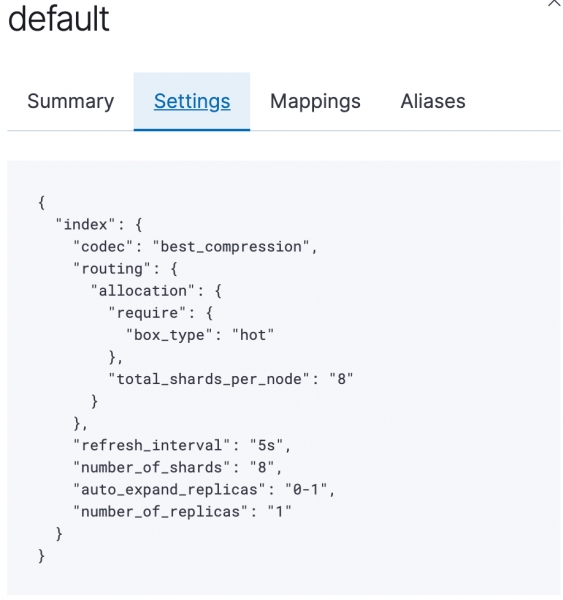
Istnieje podstawowy szablon, który ma zastosowanie do wszystkich nowych indeksów. Definiuje rozkład gorących indeksów, liczbę fragmentów, replik itp. Waga szablonu jest określana przez opcję order. Szablony o wyższych wagach zastępują istniejące parametry szablonu lub dodają nowe.
GET_template/domyślny
{
"default" : {
"order" : -1, # вес шаблона
"version" : 1,
"index_patterns" : [
"*" # применяем ко всем индексам
],
"settings" : {
"index" : {
"codec" : "best_compression", # уровень сжатия
"routing" : {
"allocation" : {
"require" : {
"box_type" : "hot" # распределяем только по горячим нодам
},
"total_shards_per_node" : "8" # максимальное количество шардов на ноду от одного индекса
}
},
"refresh_interval" : "5s", # интервал обновления индекса
"number_of_shards" : "8", # количество шардов
"auto_expand_replicas" : "0-1", # количество реплик на ноду от одного индекса
"number_of_replicas" : "1" # количество реплик
}
},
"mappings" : {
"_meta" : { },
"_source" : { },
"properties" : { }
},
"aliases" : { }
}
}Następnie stosujemy mapowanie do indeksów k8s-ingress-* używając szablonu o większej wadze.
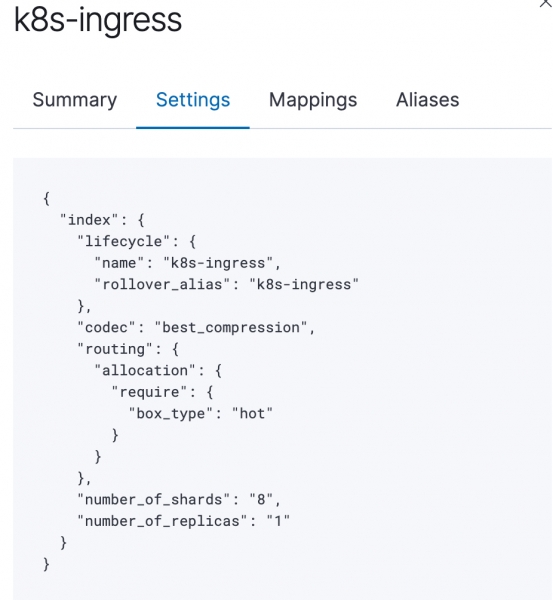
POBIERZ _template/k8s-ingress
{
"k8s-ingress" : {
"order" : 100,
"index_patterns" : [
"k8s-ingress-*"
],
"settings" : {
"index" : {
"lifecycle" : {
"name" : "k8s-ingress",
"rollover_alias" : "k8s-ingress"
},
"codec" : "best_compression",
"routing" : {
"allocation" : {
"require" : {
"box_type" : "hot"
}
}
},
"number_of_shards" : "8",
"number_of_replicas" : "1"
}
},
"mappings" : {
"numeric_detection" : false,
"_meta" : { },
"_source" : { },
"dynamic_templates" : [
{
"all_fields" : {
"mapping" : {
"index" : false,
"type" : "text"
},
"match" : "*"
}
}
],
"date_detection" : false,
"properties" : {
"kubernetes" : {
"type" : "object",
"properties" : {
"container_name" : {
"type" : "keyword"
},
"container_hash" : {
"index" : false,
"type" : "keyword"
},
"host" : {
"type" : "keyword"
},
"annotations" : {
"type" : "object",
"properties" : {
"value" : {
"index" : false,
"type" : "text"
},
"key" : {
"index" : false,
"type" : "keyword"
}
}
},
"docker_id" : {
"index" : false,
"type" : "keyword"
},
"pod_id" : {
"type" : "keyword"
},
"labels" : {
"type" : "object",
"properties" : {
"value" : {
"type" : "keyword"
},
"key" : {
"type" : "keyword"
}
}
},
"namespace_name" : {
"type" : "keyword"
},
"pod_name" : {
"type" : "keyword"
}
}
},
"@timestamp" : {
"type" : "date"
},
"nginx" : {
"type" : "object",
"properties" : {
"access" : {
"type" : "object",
"properties" : {
"agent" : {
"type" : "text"
},
"response_code" : {
"type" : "integer"
},
"upstream" : {
"type" : "object",
"properties" : {
"port" : {
"type" : "keyword"
},
"name" : {
"type" : "keyword"
},
"response_lenght" : {
"type" : "integer"
},
"response_time" : {
"index" : false,
"type" : "text"
},
"addr" : {
"type" : "keyword"
},
"status" : {
"index" : false,
"type" : "text"
}
}
},
"method" : {
"type" : "keyword"
},
"http_version" : {
"type" : "keyword"
},
"bytes_sent" : {
"type" : "integer"
},
"request_lenght" : {
"type" : "integer"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
},
"remote_user" : {
"type" : "text"
},
"referrer" : {
"type" : "text"
},
"remote_ip" : {
"type" : "ip"
},
"request_time" : {
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis||dd/MMM/YYYY:H:m:s Z",
"type" : "date"
},
"host" : {
"type" : "keyword"
},
"time" : {
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis||dd/MMM/YYYY:H:m:s Z",
"type" : "date"
}
}
},
"error" : {
"type" : "object",
"properties" : {
"server" : {
"type" : "keyword"
},
"upstream" : {
"type" : "object",
"properties" : {
"port" : {
"type" : "keyword"
},
"proto" : {
"type" : "keyword"
},
"host" : {
"type" : "keyword"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
}
}
},
"method" : {
"type" : "keyword"
},
"level" : {
"type" : "keyword"
},
"http_version" : {
"type" : "keyword"
},
"pid" : {
"index" : false,
"type" : "integer"
},
"message" : {
"type" : "text"
},
"tid" : {
"index" : false,
"type" : "keyword"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
},
"referrer" : {
"type" : "text"
},
"remote_ip" : {
"type" : "ip"
},
"connection_id" : {
"index" : false,
"type" : "keyword"
},
"host" : {
"type" : "keyword"
},
"time" : {
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis||dd/MMM/YYYY:H:m:s Z",
"type" : "date"
}
}
}
}
},
"log" : {
"type" : "text"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"eventtime" : {
"type" : "float"
}
}
},
"aliases" : { }
}
}Po zastosowaniu wszystkich szablonów stosujemy politykę ILM i rozpoczynamy monitorowanie cyklu życia indeksów.
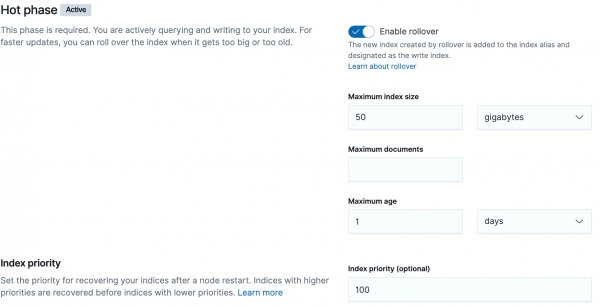
POBIERZ _ilm/policy/k8s-ingress
{
"k8s-ingress" : {
"version" : 14,
"modified_date" : "2020-06-11T10:27:01.448Z",
"policy" : {
"phases" : {
"warm" : { # теплая фаза
"min_age" : "5d", # срок жизни индекса после ротации до наступления теплой фазы
"actions" : {
"allocate" : {
"include" : { },
"exclude" : { },
"require" : {
"box_type" : "warm" # куда перемещаем индекс
}
},
"shrink" : {
"number_of_shards" : 4 # обрезание индексов, т.к. у нас 4 ноды
}
}
},
"cold" : { # холодная фаза
"min_age" : "25d", # срок жизни индекса после ротации до наступления холодной фазы
"actions" : {
"allocate" : {
"include" : { },
"exclude" : { },
"require" : {
"box_type" : "cold" # куда перемещаем индекс
}
},
"freeze" : { } # замораживаем для оптимизации
}
},
"hot" : { # горячая фаза
"min_age" : "0ms",
"actions" : {
"rollover" : {
"max_size" : "50gb", # максимальный размер индекса до ротации (будет х2, т.к. есть 1 реплика)
"max_age" : "1d" # максимальный срок жизни индекса до ротации
},
"set_priority" : {
"priority" : 100
}
}
},
"delete" : { # фаза удаления
"min_age" : "120d", # максимальный срок жизни после ротации перед удалением
"actions" : {
"delete" : { }
}
}
}
}
}
}Problemy
Wystąpiły problemy na etapie konfiguracji i debugowania.
Faza gorąca
Aby obrót indeksu był prawidłowy, obecność na końcu jest kluczowa index_name-date-000026 format liczb 000001. W kodzie znajdują się linijki, które sprawdzają indeksy, stosując na końcu wyrażenie regularne dla liczb. W przeciwnym wypadku wystąpi błąd, zasady nie zostaną zastosowane do indeksu i indeks zawsze będzie w fazie gorącej.
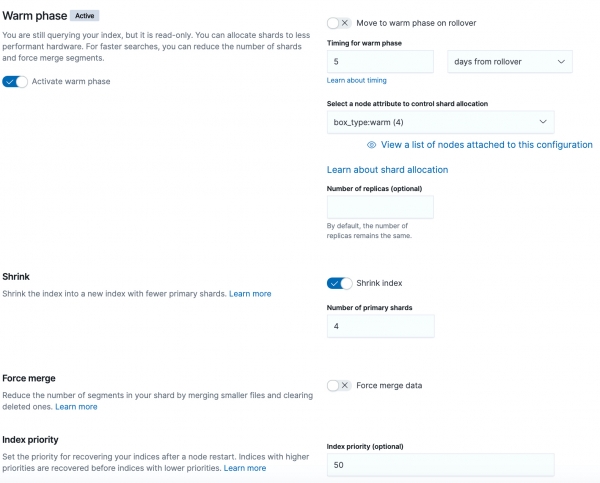
Faza ciepła
kurczyć (cięcie) - zmniejszanie ilości odłamków, ponieważ w fazie ciepłej i zimnej mamy 4 węzły. Dokumentacja zawiera następujące wiersze:
- Indeks musi być tylko do odczytu.
- Kopia każdego fragmentu w indeksie musi znajdować się na tym samym węźle.
- Status kondycji klastra musi być zielony.
Aby przyciąć indeks, Elasticsearch przenosi wszystkie podstawowe fragmenty do jednego węzła, duplikuje przycięty indeks z wymaganymi parametrami, a następnie usuwa stary. Parametr total_shards_per_node musi być równa lub większa od liczby fragmentów podstawowych, aby można je było umieścić na jednym węźle. W przeciwnym wypadku pojawią się powiadomienia, a fragmenty nie zostaną przeniesione do wymaganych węzłów.
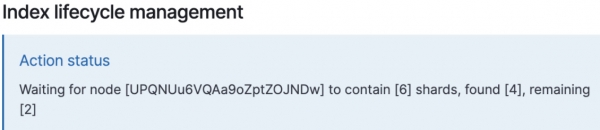
POBIERZ /shrink-k8s-ingress-2020.06.06-000025/_settings
{
"shrink-k8s-ingress-2020.06.06-000025" : {
"settings" : {
"index" : {
"refresh_interval" : "5s",
"auto_expand_replicas" : "0-1",
"blocks" : {
"write" : "true"
},
"provided_name" : "shrink-k8s-ingress-2020.06.06-000025",
"creation_date" : "1592225525569",
"priority" : "100",
"number_of_replicas" : "1",
"uuid" : "psF4MiFGQRmi8EstYUQS4w",
"version" : {
"created" : "7060299",
"upgraded" : "7060299"
},
"lifecycle" : {
"name" : "k8s-ingress",
"rollover_alias" : "k8s-ingress",
"indexing_complete" : "true"
},
"codec" : "best_compression",
"routing" : {
"allocation" : {
"initial_recovery" : {
"_id" : "_Le0Ww96RZ-o76bEPAWWag"
},
"require" : {
"_id" : null,
"box_type" : "cold"
},
"total_shards_per_node" : "8"
}
},
"number_of_shards" : "4",
"routing_partition_size" : "1",
"resize" : {
"source" : {
"name" : "k8s-ingress-2020.06.06-000025",
"uuid" : "gNhYixO6Skqi54lBjg5bpQ"
}
}
}
}
}
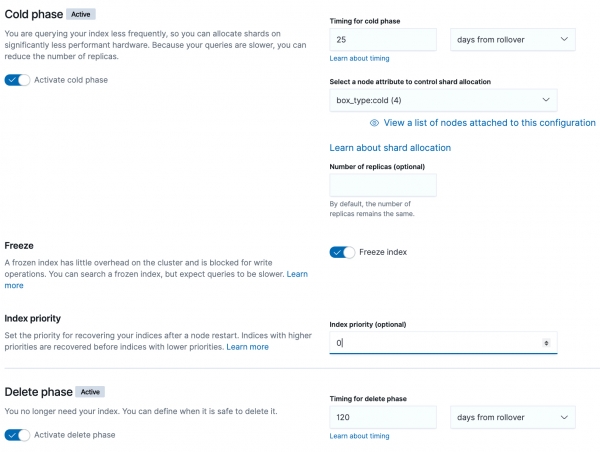
}Faza zimna
Zamrażać (zamrożenie) - zamrażamy indeks w celu optymalizacji zapytań na podstawie danych historycznych.
Wyszukiwania wykonywane na zamrożonych indeksach korzystają z małego, dedykowanego wątku search_throttled, który kontroluje liczbę równoczesnych wyszukiwań trafiających na zamrożone fragmenty na każdym węźle. Ogranicza to ilość dodatkowej pamięci wymaganej dla przejściowych struktur danych odpowiadających zamrożonym fragmentom, co w konsekwencji chroni węzły przed nadmiernym zużyciem pamięci.
Zamrożone indeksy są przeznaczone tylko do odczytu: nie można do nich indeksować.
Oczekuje się, że wyszukiwania zamrożonych indeksów będą przebiegać powoli. Zamrożone indeksy nie są przeznaczone do dużego obciążenia wyszukiwaniem. Możliwe jest, że przeszukiwanie zablokowanego indeksu może zająć sekundy lub minuty, nawet jeśli te same wyszukiwania zakończyły się w ciągu milisekund, gdy indeksy nie były zablokowane.
Wyniki
Dowiedzieliśmy się, jak przygotować węzły do pracy z ILM, skonfigurować szablon do dystrybucji fragmentów pomiędzy aktywnymi węzłami i skonfigurować ILM dla indeksu ze wszystkimi fazami życia.
Przydatne linki
Źródło: www.habr.com
