

HighLoad++ Moskwa 2018, Sala Kongresowa. 9 listopada, 15:00
Streszczenia i prezentacja:
Yuri Nasretdinov (VKontakte): w raporcie opowiemy o doświadczeniach związanych z wdrażaniem ClickHouse w naszej firmie - dlaczego go potrzebujemy, ile danych przechowujemy, jak je zapisujemy i tak dalej.

Dodatkowe materiały:
Jurij Nasretdinow: - Cześć wszystkim! Nazywam się Yuri Nasretdinov, jak już mnie przedstawiono. Pracuję w VKontakte. Opowiem o tym jak wprowadzamy do ClickHouse dane z naszej floty serwerów (dziesiątki tysięcy).
Co to są dzienniki i po co je zbierać?
Co Ci powiemy: co zrobiliśmy, dlaczego potrzebowaliśmy „ClickHouse”, odpowiednio, dlaczego go wybraliśmy, jaką wydajność można w przybliżeniu uzyskać bez konieczności konfigurowania czegokolwiek specjalnego. Opowiem Ci dalej o tabelach buforów, o problemach, jakie mieliśmy z nimi oraz o naszych rozwiązaniach, które opracowaliśmy z open source - KittenHouse i Lighthouse.
Dlaczego w ogóle musieliśmy cokolwiek robić (na VKontakte wszystko jest zawsze dobre, prawda?). Chcieliśmy zebrać logi debugowania (a było tam setki terabajtów danych), może jakoś wygodniej byłoby policzyć statystyki; i mamy flotę kilkudziesięciu tysięcy serwerów, z których to wszystko trzeba zrobić.
Dlaczego zdecydowaliśmy? Prawdopodobnie mieliśmy rozwiązania do przechowywania kłód. Tutaj – jest taki publiczny „Backend VK”. Gorąco polecam subskrypcję.
Co to są dzienniki? To jest silnik, który zwraca puste tablice. Silniki w VK to coś, co inni nazywają mikrousługami. A oto uśmiechnięta naklejka (całkiem sporo polubień). Jak to? Cóż, słuchaj dalej!

Co można wykorzystać do przechowywania logów? Nie sposób nie wspomnieć o Hadupie. Następnie np. Rsyslog (przechowywanie tych logów w plikach). LSD. Kto wie, co to jest LSD? Nie, nie to LSD. Przechowuj także odpowiednio pliki. Cóż, ClickHouse to dziwna opcja.
Clickhouse i konkurenci: wymagania i możliwości
Czego chcemy? Chcemy mieć pewność, że nie musimy się zbytnio martwić o obsługę, aby działało od razu po wyjęciu z pudełka, najlepiej przy minimalnej konfiguracji. Chcemy pisać dużo i szybko. I chcemy to zachować na całe miesiące, lata, czyli na długo. Możemy chcieć zrozumieć jakiś problem, z którym przyszli do nas i powiedzieli: „Coś tu nie działa”, a to było 3 miesiące temu) i chcemy móc zobaczyć, co wydarzyło się 3 miesiące temu ” Kompresja danych – wiadomo, dlaczego miałaby to być zaleta – bo zmniejsza ilość zajmowanego miejsca.

Mamy takie interesujące wymaganie: czasami zapisujemy dane wyjściowe niektórych poleceń (na przykład logi), z łatwością może to być więcej niż 4 kilobajty. A jeśli to coś działa przez UDP, to nie trzeba wydawać pieniędzy… nie będzie żadnych „narzutów” na połączenie, a dla dużej liczby serwerów będzie to plus.

Zobaczmy, co oferuje nam open source. Po pierwsze, mamy silnik logów - to jest nasz silnik; W zasadzie potrafi wszystko, potrafi nawet pisać długie zdania. No cóż, nie kompresuje danych w sposób przezroczysty - duże kolumny możemy sami kompresować, jeśli chcemy... oczywiście nie chcemy (o ile to możliwe). Jedynym problemem jest to, że może oddać tylko to, co mieści się w jego pamięci; Aby przeczytać resztę, musisz uzyskać binlog tego silnika, a zatem zajmuje to dość dużo czasu.

Jakie są inne opcje? Na przykład „Hadup”. Łatwość obsługi... Kto uważa, że Hadup jest łatwy w konfiguracji? Oczywiście nie ma żadnych problemów z nagraniem. Czytając czasem pojawiają się pytania. W zasadzie powiedziałbym, że raczej nie, szczególnie w przypadku kłód. Długoterminowe przechowywanie - oczywiście tak, kompresja danych - tak, długie ciągi - jasne, że można nagrywać. Ale nagrywanie z dużej liczby serwerów... Nadal musisz coś zrobić sam!
Rsyslog. W rzeczywistości użyliśmy go jako opcji kopii zapasowej, abyśmy mogli go odczytać bez zrzucania dziennika binarnego, ale w zasadzie nie może zapisywać długich linii, nie może zapisać więcej niż 4 kilobajty. Musisz sam dokonać kompresji danych w ten sam sposób. Odczyt będzie pochodził z plików.

Następnie następuje rozwój LSD w formie „baduszki”. Zasadniczo to samo co „Rsyslog”: obsługuje długie ciągi znaków, ale nie może działać przez UDP i tak naprawdę z tego powodu niestety sporo rzeczy trzeba tam przepisać. LSD wymaga przeprojektowania, aby móc nagrywać z dziesiątek tysięcy serwerów.

Ach, tutaj! Zabawną opcją jest ElasticSearch. No cóż, jak mogę to powiedzieć? Z czytaniem radzi sobie dobrze, to znaczy czyta szybko, ale niezbyt dobrze radzi sobie z pisaniem. Po pierwsze, jeśli kompresuje dane, jest bardzo słaby. Najprawdopodobniej pełne wyszukiwanie wymaga większych struktur danych niż pierwotny wolumin. Jest trudny w obsłudze i często pojawiają się z nim problemy. I znowu nagrywanie w Elastic - wszystko musimy zrobić sami.

Tutaj ClickHouse jest oczywiście idealną opcją. Jedyną rzeczą jest to, że nagrywanie z dziesiątek tysięcy serwerów stanowi problem. Ale przynajmniej jest jeden problem, możemy spróbować go jakoś rozwiązać. Pozostała część raportu dotyczy tego problemu. Jakiej wydajności możesz oczekiwać od ClickHouse?
Jak to wprowadzimy? Połącz drzewo
Kto z Was nie słyszał lub nie wie o „ClickHouse”? Muszę ci powiedzieć, prawda? Bardzo szybko. Wstawienie tam wynosi 1-2 gigabity na sekundę, impulsy do 10 gigabitów na sekundę faktycznie wytrzymują tę konfigurację - są dwa 6-rdzeniowe Xeony (czyli nawet nie najpotężniejsze), 256 gigabajtów pamięci RAM, 20 terabajtów w RAID (nikt nie konfigurował, ustawienia domyślne). Alexey Milovidov, programista ClickHouse, prawdopodobnie siedzi i płacze, ponieważ nic nie konfigurowaliśmy (u nas wszystko tak działało). Odpowiednio, jeśli dane są dobrze skompresowane, można uzyskać prędkość skanowania, powiedzmy, około 6 miliardów linii na sekundę. Jeśli lubisz % w ciągu tekstowym - 100 milionów linii na sekundę, to znaczy, że wydaje się to dość szybkie.

Jak to wprowadzimy? Cóż, wiesz, że VK używa PHP. Dla każdego rekordu wstawimy od każdego pracownika PHP poprzez HTTP do „ClickHouse”, do tabeli MergeTree. Kto widzi problem w tym schemacie? Z jakiegoś powodu nie wszyscy podnieśli ręce. Pozwól, że ci powiem.
Po pierwsze, jest dużo serwerów - w związku z tym będzie dużo połączeń (źle). Wtedy lepiej wprowadzać dane do MergeTree nie częściej niż raz na sekundę. A kto wie dlaczego? OK, OK. Opowiem Ci o tym trochę więcej. Kolejną ciekawą kwestią jest to, że nie zajmujemy się analityką, nie potrzebujemy wzbogacać danych, nie potrzebujemy serwerów pośrednich, chcemy wstawiać się bezpośrednio do „ClickHouse” (najlepiej – im bardziej bezpośrednio, tym lepiej).

W związku z tym, w jaki sposób odbywa się wstawianie w MergeTree? Dlaczego lepiej wkładać do niego nie częściej niż raz na sekundę lub rzadziej? Faktem jest, że „ClickHouse” jest bazą kolumnową i sortuje dane w kolejności rosnącej według klucza podstawowego, a przy wstawianiu tworzy się liczba plików co najmniej równa liczbie kolumn, w których posortowane są dane w kolejności rosnącej według klucza podstawowego (tworzony jest osobny katalog, dla każdej wstawki zestaw plików na dysku). Potem następuje kolejne wstawienie, a w tle są one łączone w większe „przegrody”. Ponieważ dane są posortowane, możliwe jest „scalanie” dwóch posortowanych plików bez zużywania dużej ilości pamięci.
Ale, jak można się domyślić, jeśli napiszesz 10 plików dla każdej wstawki, ClickHouse (lub Twój serwer) szybko się zakończy, dlatego zaleca się wstawianie w dużych partiach. W związku z tym nigdy nie wprowadziliśmy do produkcji pierwszego schematu. Od razu uruchomiliśmy taki, który tutaj nr 2 ma:

Tutaj wyobraź sobie, że jest około tysiąca serwerów, na których uruchomiliśmy, jest tylko PHP. A na każdym serwerze znajduje się nasz lokalny agent, którego nazwaliśmy „Kittenhouse”, który utrzymuje jedno połączenie z „ClickHouse” i co kilka sekund wprowadza dane. Wstawia dane nie do MergeTree, ale do tabeli buforów, co właśnie służy temu, aby uniknąć natychmiastowego wstawiania danych bezpośrednio do MergeTree.
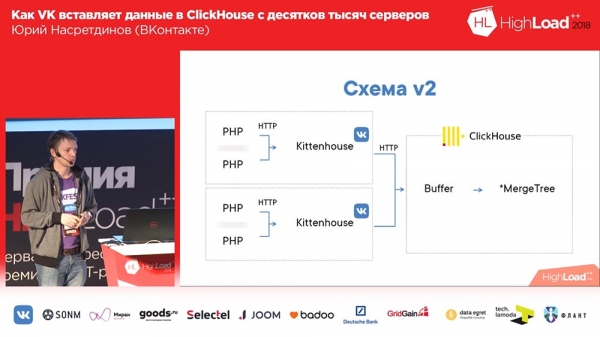
Praca z tabelami buforowymi
Co to jest? Tabele buforów to fragment pamięci, który jest podzielony na fragmenty (to znaczy, że można go często wstawiać). Składają się z kilku sztuk, a każda z nich działa jak niezależny bufor i są one opróżniane niezależnie (jeśli masz wiele sztuk w buforze, to będzie wiele wstawień na sekundę). Z tych tabel można czytać - wtedy czytasz sumę zawartości bufora i tabeli nadrzędnej, ale w tym momencie zapis jest zablokowany, więc lepiej stamtąd nie czytać. A tabele buforów pokazują bardzo dobre QPS, czyli do 3 tysięcy QPS nie będziesz miał żadnych problemów przy wstawianiu. Oczywiste jest, że jeśli serwer straci zasilanie, dane mogą zostać utracone, ponieważ były przechowywane tylko w pamięci.

Jednocześnie schemat z buforem komplikuje ALTER, ponieważ najpierw trzeba usunąć starą tabelę buforów ze starym schematem (dane nigdzie nie znikną, ponieważ zostaną opróżnione przed usunięciem tabeli). Następnie „zmieniasz” potrzebną tabelę i ponownie tworzysz tabelę buforów. W związku z tym, chociaż nie ma tabeli buforów, Twoje dane nie będą nigdzie przepływać, ale możesz je mieć na dysku przynajmniej lokalnie.

Co to jest Kittenhouse i jak działa?
Czym jest KittenHouse? To jest pełnomocnik. Zgadnij, jaki język? W swoim raporcie zebrałem najciekawsze tematy – „Clickhouse”, Go, może przypomnę sobie coś innego. Tak, to jest napisane w Go, bo nie bardzo umiem pisać w C, nie chcę.

W związku z tym utrzymuje połączenie z każdym serwerem i może zapisywać w pamięci. Przykładowo, jeśli zapiszemy logi błędów do Clickhouse, to jeśli Clickhouse nie będzie miał czasu na wstawienie danych (w końcu jeśli zapisano ich za dużo), to nie puchniemy pamięci – resztę po prostu wyrzucamy. Bo jeśli napiszemy kilka gigabitów błędów na sekundę, to prawdopodobnie uda nam się część wyrzucić. Kittenhouse może to zrobić. Dodatkowo potrafi niezawodnie dostarczać, czyli zapisywać na dysk na maszynie lokalnej i raz za razem (tam, raz na kilka sekund) próbuje dostarczyć dane z tego pliku. Na początku używaliśmy zwykłego formatu Wartości - a nie jakiegoś formatu binarnego, ale formatu tekstowego (jak w zwykłym SQL).
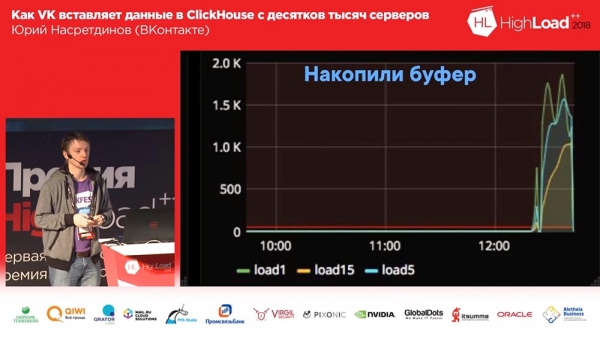
Ale wtedy to się stało. Zastosowaliśmy niezawodne dostarczanie, napisaliśmy logi i wtedy zdecydowaliśmy (był to klaster testów warunkowych)... Na kilka godzin został wygaszony i przywrócony, a z tysiąca serwerów rozpoczęło się wstawianie - okazało się, że Clickhouse nadal miał „ Wątek na „połączeniu modelowym” - odpowiednio na tysiąc połączeń aktywne wstawienie prowadzi do średniego obciążenia serwera na poziomie około półtora tysiąca. Co zaskakujące, serwer akceptował żądania, ale dane nadal były wstawiane po pewnym czasie; ale serwerowi bardzo trudno było to obsłużyć. . .
Dodaj nginxa
Takim rozwiązaniem dla modelu Thread per Connection jest nginx. Zainstalowaliśmy nginx przed Clickhouse, jednocześnie ustawiliśmy balans dla dwóch replik (nasza prędkość wstawiania wzrosła 2-krotnie, chociaż nie jest faktem, że tak powinno być) i ograniczyliśmy liczbę połączeń z Clickhouse, do upstream i odpowiednio więcej, niż w 50 połączeniach, wydaje się, że nie ma sensu wstawiać.
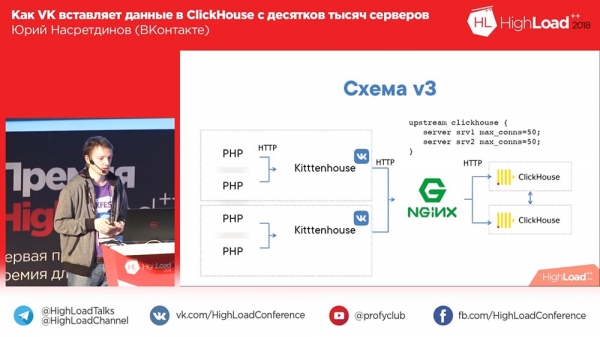
Potem zdaliśmy sobie sprawę, że ogólnie ten schemat ma wady, ponieważ mamy tutaj tylko jeden nginx. W związku z tym, jeśli ten nginx ulegnie awarii, pomimo obecności replik, tracimy dane lub przynajmniej nigdzie nie piszemy. Dlatego stworzyliśmy własne równoważenie obciążenia. Zdaliśmy sobie również sprawę, że „Clickhouse” nadal nadaje się do kłód, a „demon” również zaczął pisać swoje dzienniki w „Clickhouse” - szczerze mówiąc, bardzo wygodne. Nadal używamy go w odniesieniu do innych „demonów”.

Następnie odkryliśmy ten interesujący problem: jeśli użyjesz niestandardowej metody wstawiania w trybie SQL, wymusza to pełnoprawny parser SQL oparty na AST, który jest dość powolny. W związku z tym dodaliśmy ustawienia, aby mieć pewność, że taka sytuacja nigdy się nie zdarzy. Zrównoważyliśmy obciążenie i sprawdziliśmy stan zdrowia, więc jeśli ktoś umrze, nadal zostawiamy dane. Mamy teraz sporo tabel, w których potrzebujemy różnych klastrów Clickhouse. Zaczęliśmy też myśleć o innych zastosowaniach – na przykład chcieliśmy pisać logi z modułów nginx, ale nie wiedziały one, jak komunikować się za pomocą naszego RPC. Cóż, chciałbym ich nauczyć przynajmniej w jakiś sposób wysyłać - na przykład odbierać zdarzenia na localhost przez UDP, a następnie przesyłać je do Clickhouse.
Jeden krok od rozwiązania
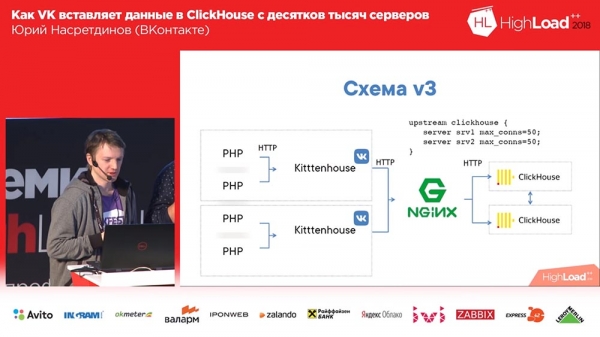
Ostateczny schemat zaczął wyglądać tak (czwarta wersja tego schematu): na każdym serwerze przed Clickhouse znajduje się nginx (na tym samym serwerze) i po prostu przekazuje żądania do localhost z limitem liczby połączeń wynoszącym 50 sztuki. I ten schemat już działał, wszystko było z nim całkiem dobre.
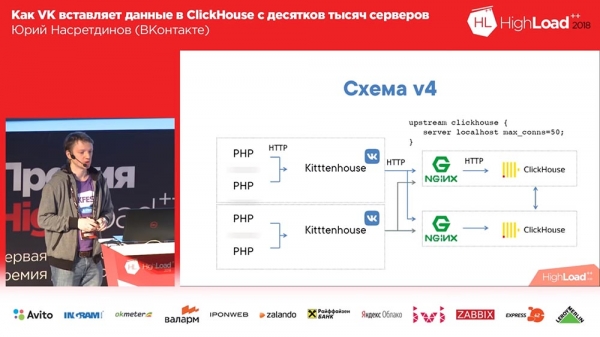
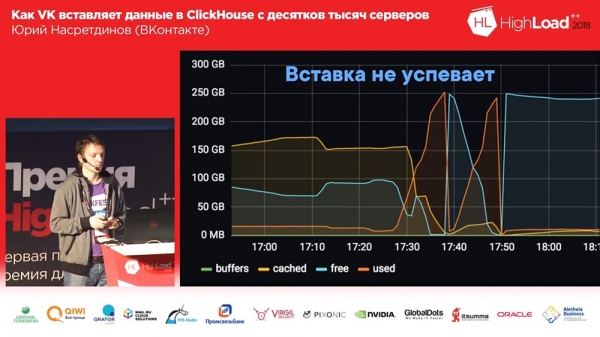
Żyliśmy tak około miesiąca. Wszyscy byli zadowoleni, dodawali tabele, dodawali, dodawali... Ogólnie rzecz biorąc, okazało się, że sposób, w jaki dodaliśmy tabele buforów, nie był zbyt optymalny (nazwijmy to). Zrobiliśmy 16 sztuk na każdym stole i kilkusekundową przerwę flash; mieliśmy 20 stołów i każdy stół otrzymywał 8 wstawek na sekundę - i w tym momencie zaczął się „Clickhouse”… zapisy zaczęły zwalniać. Nawet nie przeszli… Nginx domyślnie miał tak interesującą rzecz, że jeśli połączenia kończyły się na upstream, po prostu zwracał „502” do wszystkich nowych żądań.

I tutaj mamy (właśnie przejrzałem logi w samym Clickhouse) około pół procent żądań zakończyło się niepowodzeniem. W związku z tym wykorzystanie dysku było wysokie, nastąpiło wiele połączeń. Cóż, co zrobiłem? Oczywiście nie zadałem sobie trudu, aby dokładnie dowiedzieć się, dlaczego połączenie i upstream się zakończyły.
Zastąpienie nginx odwrotnym proxy
Zdecydowałem, że musimy sami sobie z tym poradzić, nie musimy zostawiać tego nginxowi - nginx nie wie, jakie tabele znajdują się w Clickhouse, więc zastąpiłem nginx odwrotnym proxy, które również sam napisałem.
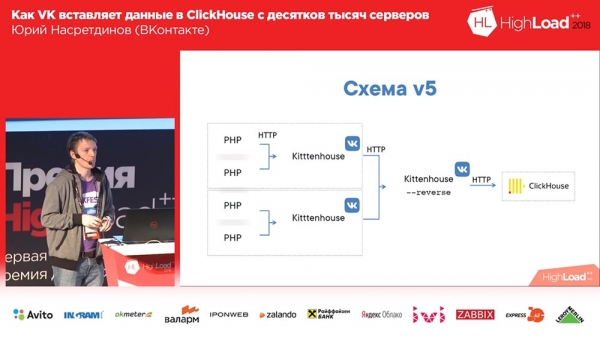
Co on robi? Działa w oparciu o bibliotekę fasthttp „goshnoy”, czyli szybko, prawie tak szybko, jak nginx. Przepraszam, Igor, jeśli jesteś tutaj obecny (uwaga: Igor Sysoev to rosyjski programista, który stworzył serwer WWW Nginx). Potrafi zrozumieć, jakiego rodzaju są to zapytania – INSERT lub SELECT – odpowiednio przechowuje różne pule połączeń dla różnych typów zapytań.

W związku z tym, nawet jeśli nie będziemy mieli czasu na realizację próśb o wstawienie, „wybory” przejdą i odwrotnie. I grupuje dane w tabele buforów – z małym buforem: jeśli były jakieś błędy, błędy składniowe itd. – tak, aby nie miały one większego wpływu na resztę danych, ponieważ kiedy po prostu wstawimy do tabel buforów, miał małe „bachi” i wszystkie błędy składniowe dotyczyły tylko tego małego fragmentu; i tutaj będą już miały wpływ na duży bufor. Mały to 1 megabajt, czyli nie taki mały.
Wstawienie synchronizacji zasadniczo zastępuje nginx, robi zasadniczo to samo, co wcześniej nginx - nie musisz w tym celu zmieniać lokalnego „Kittenhouse”. A ponieważ korzysta z fasthttp, jest bardzo szybki - możesz wykonać ponad 100 tysięcy żądań na sekundę dla pojedynczych wstawek za pośrednictwem odwrotnego proxy. Teoretycznie możesz wstawić jedną linię na raz do odwrotnego proxy w domku dla kotów, ale oczywiście tego nie robimy.
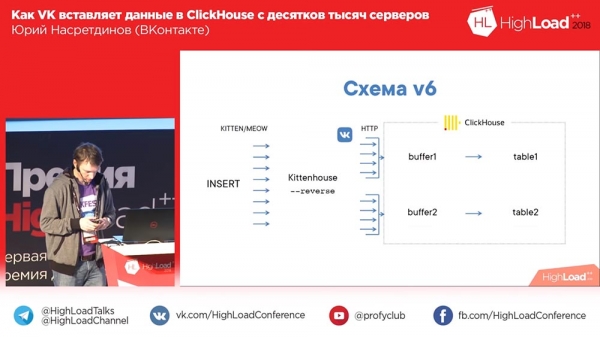
Schemat zaczął wyglądać tak: „Kittenhouse”, odwrotne proxy grupuje wiele żądań w tabele, a tabele buforów z kolei wstawiają je do głównych.
Killer to rozwiązanie tymczasowe, Kitten to rozwiązanie trwałe
To ciekawy problem... Czy ktoś z Was korzystał z fasthttp? Kto korzystał z fasthttp z żądaniami POST? Prawdopodobnie nie powinno się tego robić, ponieważ domyślnie buforuje treść żądania, a rozmiar bufora ustawiono na 16 megabajtów. Wstawianie przestało w pewnym momencie być realizowane i ze wszystkich dziesiątek tysięcy serwerów zaczęły napływać 16-megabajtowe fragmenty, które przed wysłaniem do Clickhouse były buforowane w pamięci. W związku z tym skończyła się pamięć, pojawił się Zabójca Out-Of-Memory i zabił odwrotne proxy (lub „Clickhouse”, który teoretycznie mógłby „zjeść” więcej niż odwrotne proxy). Cykl się powtórzył. Niezbyt przyjemny problem. Chociaż natknęliśmy się na to dopiero po kilku miesiącach działania.
Co zrobiłem? Powtórzę jeszcze raz: nie chcę rozumieć, co dokładnie się wydarzyło. Myślę, że to całkiem oczywiste, że nie należy buforować w pamięci. Nie mogłem załatać fasthttp, chociaż próbowałem. Ale znalazłem sposób, żeby nie było potrzeby niczego łatać i wymyśliłem własną metodę w HTTP - nazwałem ją KITTEN. Cóż, to logiczne - „VK”, „Kotek”… Co jeszcze?..

Jeśli żądanie przyjdzie do serwera metodą Kitten, to serwer powinien odpowiedzieć „miau” – logicznie. Jeśli na to odpowie, to uważa się, że rozumie ten protokół, a następnie przechwytuję połączenie (fasthttp ma taką metodę), a połączenie przechodzi w tryb „surowy”. Dlaczego tego potrzebuję? Chcę kontrolować sposób, w jaki odbywa się odczyt z połączeń TCP. TCP ma cudowną właściwość: jeśli nikt nie czyta z drugiej strony, zapis zaczyna czekać, a pamięć nie jest na to specjalnie wydawana.
I tak czytam od około 50 klientów na raz (od pięćdziesięciu, bo pięćdziesiąt na pewno powinno wystarczyć, nawet jeśli stawka pochodzi z innego DC)... Konsumpcja przy tym podejściu spadła co najmniej 20 razy, ale ja, szczerze mówiąc , nie udało mi się dokładnie zmierzyć o której godzinie, bo to już nie ma sensu (doszło już do poziomu błędu). Protokół jest binarny, to znaczy zawiera nazwę tabeli i dane; nie ma nagłówków http, więc nie korzystałem z gniazda sieciowego (nie muszę komunikować się z przeglądarkami - stworzyłem protokół, który odpowiada naszym potrzebom). I wszystko z nim było w porządku.
Tabela buforów jest smutna
Niedawno natknęliśmy się na kolejną interesującą funkcję tabel buforów. A ten problem jest już znacznie bardziej bolesny niż inne. Wyobraźmy sobie taką sytuację: już aktywnie korzystasz z Clickhouse, masz dziesiątki serwerów Clickhouse i masz niektóre żądania, których odczytanie zajmuje bardzo dużo czasu (powiedzmy ponad 60 sekund); i w tym momencie przychodzisz i robisz Alter... W międzyczasie „wybory”, które rozpoczęły się przed „Alter” nie zostaną uwzględnione w tej tabeli, „Alter” nie zostanie uruchomiony - prawdopodobnie niektóre funkcje działania „Clickhouse” w to miejsce. Może da się to naprawić? Czy jest to niemożliwe?

Generalnie widać, że w rzeczywistości nie jest to aż tak duży problem, jednak w przypadku tabel buforowych staje się to bardziej bolesne. Ponieważ, jeśli, powiedzmy, przekroczenie limitu czasu „Alter” (a może przekroczyć limit czasu na innym hoście - na przykład nie na twoim, ale na replice), to... Usunąłeś tabelę buforów, twoje „Alter” ( lub inny host) upłynął limit czasu, wystąpił błąd „Alter”) - musisz jeszcze zadbać o to, aby dane były nadal zapisywane: ponownie tworzysz tabele buforów (według tego samego schematu, co tabela nadrzędna), następnie „Alter” przechodzi, kończy się jednak, a bufor tabeli zaczyna różnić się schematem od rodzica. W zależności od tego, czym był „Alter”, wstawka może nie trafiać już do tej tabeli buforów - jest to bardzo smutne.

Jest też taki znak (może ktoś go zauważył) - w nowych wersjach Clickhouse nazywa się query_thread_log. Domyślnie w niektórych wersjach był taki. Tutaj zgromadziliśmy 840 milionów rekordów w ciągu kilku miesięcy (100 gigabajtów). Wynika to z faktu, że wpisano tam „wkładki” (może, swoją drogą, teraz ich nie zapisano). Jak już mówiłem, nasze „wstawki” są małe – mieliśmy wiele „wstawek” w tabelach buforów. Oczywiste jest, że jest to wyłączone - mówię tylko, co widziałem na naszym serwerze. Dlaczego? To kolejny argument przeciwko używaniu tabel buforowych! Spoty jest bardzo smutny.

Kto wiedział, że ten facet miał na imię Spotty? Pracownicy VK podnieśli ręce. OK.
O planach „KitttenHouse”
Planami zwykle się nie dzieli, prawda? Nagle przestaniesz je spełniać i nie będziesz dobrze wyglądać w oczach innych ludzi. Ale podejmę ryzyko! Chcemy wykonać następujące czynności: wydaje mi się, że tabele buforowe nadal stanowią oparcie i musimy sami buforować wstawianie. Ale nadal nie chcemy buforować go na dysku, więc buforujemy wstawienie do pamięci.

W związku z tym, gdy zostanie wykonane „wstawienie”, nie będzie ono już synchroniczne - będzie już działać jako tabela buforów, wstawi do tabeli nadrzędnej (no cóż, pewnego dnia później) i zgłosi osobnym kanałem, które wstawienia przeszły, a które nie.

Dlaczego nie mogę opuścić wstawki synchronicznej? To o wiele wygodniejsze. Faktem jest, że jeśli wstawisz z 10 tysięcy hostów, wszystko będzie w porządku - od każdego hosta dostaniesz trochę, wstawisz tam raz na sekundę, wszystko jest w porządku. Ale chciałbym, żeby ten schemat działał na przykład z dwóch maszyn, aby można było pobierać z dużą prędkością - może nie wydobądź maksimum z Clickhouse, ale zapisz co najmniej 100 megabajtów na sekundę z jednej maszyny przez odwrotne proxy - to schemat musi być skalowany zarówno do dużych, jak i małych ilości, więc nie możemy czekać sekundy na każde wstawienie, więc musi to być asynchroniczne. W ten sam sposób potwierdzenia asynchroniczne powinny pojawiać się po zakończeniu wstawiania. Będziemy wiedzieć, czy przeszło, czy nie.
Najważniejsze jest to, że w tym schemacie wiemy na pewno, czy wstawienie nastąpiło, czy nie. Wyobraź sobie taką sytuację: masz tabelę buforów, napisałeś coś do niej, a następnie, powiedzmy, tabela przeszła w tryb tylko do odczytu i próbowała opróżnić bufor. Gdzie trafią dane? Pozostaną w buforze. Ale tego nie możemy być pewni - co się stanie, jeśli wystąpi jakiś inny błąd, przez który dane nie pozostaną w buforze... (Adresy Aleksieja Milovidova, Yandex, programisty ClickHouse) A może pozostaną? Zawsze? Aleksiej przekonuje nas, że wszystko będzie dobrze. Nie mamy powodu, żeby mu nie wierzyć. Ale mimo wszystko: jeśli nie skorzystamy z tabel buforowych, to na pewno nie będzie z nimi problemów. Tworzenie dwukrotnie większej liczby tabel jest również niewygodne, choć w zasadzie nie ma z tym większych problemów. Taki jest plan.
Porozmawiajmy o czytaniu
Porozmawiajmy teraz o czytaniu. Tutaj również napisaliśmy własne narzędzie. Wydawałoby się, po co pisać tutaj własny instrument?.. A kto używał Tabixa? Jakoś niewiele osób podniosło rękę... A kto jest zadowolony z występu Tabixa? Cóż, nie jesteśmy z tego zadowoleni i nie jest to zbyt wygodne do przeglądania danych. Jest w porządku do analiz, ale tylko do oglądania wyraźnie nie jest zoptymalizowany. Napisałem więc własny, własny interfejs.

Jest to bardzo proste - może jedynie odczytywać dane. Nie umie pokazać grafiki, nie umie nic zrobić. Ale może pokazać, czego potrzebujemy: na przykład, ile wierszy jest w tabeli, ile miejsca zajmuje (bez podziału na kolumny), czyli potrzebujemy bardzo podstawowego interfejsu.
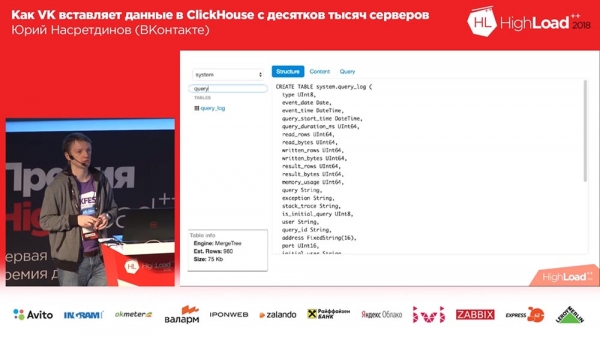
I wygląda bardzo podobnie do Sequel Pro, ale tylko stworzonego na Twitterze Bootstrap i drugiej wersji. Pytasz: „Yuri, dlaczego w drugiej wersji?” Który rok? 2018? Ogólnie rzecz biorąc, zrobiłem to dość dawno temu dla „Muscle” (MySQL) i po prostu zmieniłem tam kilka linii w zapytaniach i zaczęło działać dla „Clickhouse”, za co specjalne podziękowania! Ponieważ parser jest bardzo podobny do „muscle”, a zapytania są bardzo podobne - bardzo wygodne, szczególnie na początku.
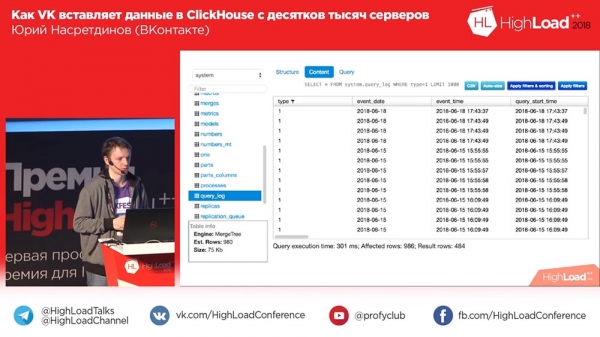
Cóż, może filtrować tabele, może pokazywać strukturę i zawartość tabeli, pozwala sortować, filtrować według kolumn, pokazuje zapytanie, które dało wynik, wiersze, których to dotyczy (ile w rezultacie), czyli podstawowe rzeczy do przeglądania danych. Całkiem szybko.
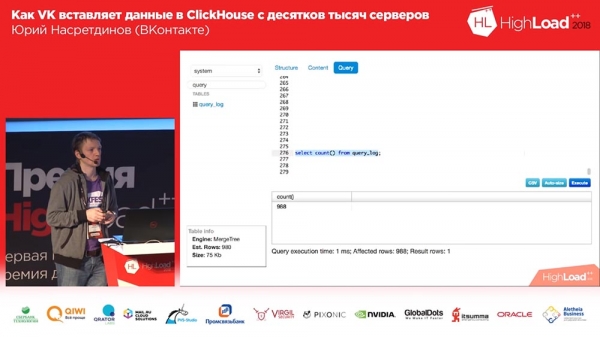
Jest też redaktor. Szczerze próbowałem ukraść cały edytor Tabixowi, ale nie mogłem. Ale jakoś to działa. W zasadzie to wszystko.
„Clickhouse” nadaje się do nor
Chcę Wam powiedzieć, że Clickhouse, pomimo wszystkich opisanych problemów, bardzo dobrze radzi sobie z balami. Co najważniejsze, rozwiązuje nasz problem - jest bardzo szybki i pozwala filtrować logi po kolumnach. W zasadzie tabele buforów nie spisują się dobrze, ale zazwyczaj nikt nie wie dlaczego... Może teraz wiesz lepiej, gdzie będziesz mieć problemy.

TCP? Ogólnie rzecz biorąc, w VK zwyczajowo używa się UDP. A kiedy użyłem protokołu TCP... Oczywiście nikt mi nie powiedział: „Yuri, o czym ty mówisz! Nie możesz, potrzebujesz UDP.” Okazało się, że TCP nie jest taki straszny. Jedyną rzeczą jest to, że jeśli masz napisane dziesiątki tysięcy związków aktywnych, musisz przygotować je trochę ostrożniej; ale jest to możliwe i całkiem łatwe.
Obiecałem wrzucić „Kittenhouse” i „Lighthouse” na HighLoad Siberia, jeśli wszyscy subskrybują nasz publiczny „backend VK”… I wiesz, nie wszyscy subskrybują… Oczywiście nie będę wymagał, abyś subskrybował nasz publiczny. Jest Was jeszcze za dużo, może ktoś się nawet obrazi, ale mimo wszystko proszę o subskrypcję (a tu muszę zrobić oczy jak kot). Zaczynamy . Dziękuję bardzo! Github jest nasz . Dzięki Clickhouse Twoje włosy będą miękkie i jedwabiste.

Moderator: - Przyjaciele, teraz pytania. Zaraz po wręczeniu dyplomu uznania i Waszego reportażu na VHS.
Jurij Nasretdinow (zwany dalej YN): – Jak udało ci się nagrać mój reportaż na VHS, skoro właśnie się skończył?

Moderator: – Nie możesz też w pełni określić, jak „Clickhouse” będzie działać, czy nie! Kochani, 5 minut na pytania!
pytania
Pytanie od publiczności (zwane dalej „Q”): - Dzień dobry. Dziękuję bardzo za raport. Mam dwa pytania. Zacznę od czegoś błahego: czy ilość liter t w nazwie „Kittenhouse” na schematach (3, 4, 7...) wpływa na zadowolenie kotów?
YN: - Ilość czego?
Z: – Litera t. Są trzy t, gdzieś około trzech t.
YN: - Czy tego nie naprawiłem? Oczywiście, że tak! To różne produkty – cały czas tylko Was oszukiwałem. OK, żartuję – to nie ma znaczenia. Ach, właśnie tutaj! Nie, to to samo, zrobiłem literówkę.
Z: - Dziękuję. Drugie pytanie jest poważne. O ile rozumiem, w Clickhouse tabele buforów żyją wyłącznie w pamięci, nie są buforowane na dysku i dlatego nie są trwałe.
YN: - TAk.
Z: – Jednocześnie Twój klient buforuje na dysku, co oznacza pewną gwarancję dostarczenia tych samych dzienników. Clickhouse nie gwarantuje tego jednak w żaden sposób. Wyjaśnij, w jaki sposób realizowana jest gwarancja, z powodu czego?.. Oto ten mechanizm bardziej szczegółowo
YN: – Tak, teoretycznie nie ma tu sprzeczności, bo kiedy Clickhouse upadnie, tak naprawdę można to wykryć na milion różnych sposobów. Jeśli Clickhouse ulegnie awarii (jeśli zakończy się niepoprawnie), możesz, z grubsza mówiąc, przewinąć trochę swojego dziennika, który zapisałeś i zacząć od momentu, gdy wszystko było w porządku. Załóżmy, że przewijasz minutę do tyłu, to znaczy uważa się, że przeczyściłeś wszystko w ciągu minuty.
Z: – Czyli „Kittenhouse” dłużej trzyma okno, a w razie upadku potrafi je rozpoznać i przewinąć?
YN: – Ale to teoretycznie. W praktyce tego nie robimy, a dostawa jest niezawodna od zera do nieskończoności. Ale średnio jeden. Jesteśmy usatysfakcjonowani, że jeśli Clickhouse z jakiegoś powodu ulegnie awarii lub serwery „zresetują się”, to trochę stracimy. We wszystkich innych przypadkach nic się nie stanie.
Z: - Cześć. Od samego początku wydawało mi się, że rzeczywiście od samego początku raportu będziesz korzystał z protokołu UDP. Masz http i to wszystko... A większość problemów, które opisałeś, jak rozumiem, była spowodowana tym konkretnym rozwiązaniem...
YN: – Do czego używamy protokołu TCP?
Z: - Zasadniczo tak.
YN: - Nie.
Z: – To z fasthttp były problemy, z połączeniem były problemy. Gdybyś właśnie użył protokołu UDP, zaoszczędziłbyś sobie trochę czasu. No cóż, byłyby problemy z długimi wiadomościami lub czymś innym...
YN: - Z czym?

Z: – Przy długich wiadomościach, bo może się nie zmieścić w MTU, coś innego... No cóż, mogą pojawić się problemy same w sobie. Pytanie brzmi: dlaczego nie UDP?
YN: – Wierzę, że autorzy, którzy opracowali TCP/IP, są o wiele mądrzejsi ode mnie i potrafią lepiej serializować pakiety (żeby mogły przejść), jednocześnie dostosowując okno nadawcze, nie przeciążając sieci, informując o tym, co nie jest odczytywane, nie licząc danych z drugiej strony... Wszystkie te problemy, moim zdaniem, istniałyby również w UDP, tylko musiałbym napisać jeszcze więcej kodu, niż mam, żeby to zaimplementować, i to najprawdopodobniej słabo. Nie przepadam nawet za pisaniem w C, a co dopiero w tym...
Z: - Po prostu wygodne! Wysłano ok i nie czekaj na nic – jest to całkowicie asynchroniczne. Przyszło powiadomienie, że wszystko w porządku - czyli dotarło; Jeśli nie przychodzi, to znaczy, że jest źle.
YN: – potrzebuję obu – muszę móc wysłać zarówno z gwarancją dostawy, jak i bez gwarancji dostawy. To dwa różne scenariusze. Nie muszę zgubić niektórych kłód lub nie stracić ich w rozsądnym zakresie.
Z: – Nie będę marnować czasu. Należy to omówić więcej. Dziękuję.
Moderator: – Kto ma pytania – ręce do góry!

Z: - Cześć, jestem Sasza. Gdzieś w połowie raportu pojawiło się przeczucie, że oprócz TCP można zastosować gotowe rozwiązanie – swego rodzaju Kafkę.
YN: – No cóż… mówiłem, że nie chcę korzystać z serwerów pośrednich, bo… w Kafce okazuje się, że mamy dziesięć tysięcy hostów; w rzeczywistości mamy więcej - dziesiątki tysięcy hostów. Praca z Kafką bez żadnych serwerów proxy może być również bolesna. Ponadto, co najważniejsze, nadal daje „opóźnienie”, daje dodatkowe hosty, które musisz mieć. Ale ja nie chcę ich mieć – chcę…
Z: „Ale ostatecznie i tak tak wyszło”.
YN: – Nie, nie ma gospodarzy! Wszystko to działa na hostach Clickhouse.
Z: - No i „Kittenhouse”, czyli odwrotnie – gdzie on mieszka?

YN: – Na hoście Clickhouse nie zapisuje niczego na dysk.
Z: - No cóż, powiedzmy.
Moderator: – Czy jesteś zadowolony? Czy możemy dać ci pensję?
Z: - Tak, tak. Tak naprawdę jest wiele kul, aby uzyskać to samo, a teraz - poprzednia odpowiedź na temat TCP zaprzecza, moim zdaniem, tej sytuacji. Po prostu czuję, że wszystko można było zrobić na kolanach w znacznie krótszym czasie.
YN: – A także dlaczego nie chciałem korzystać z Kafki, bo na czacie Clickhouse Telegram było dość dużo skarg, że np. wiadomości od Kafki ginęły. Nie od samego Kafki, ale poprzez integrację Kafki i Clickhausa; albo coś tam nie łączyło. Z grubsza trzeba by wtedy napisać klienta dla Kafki. Nie sądzę, że może być prostsze i bardziej niezawodne rozwiązanie.
Z: – Powiedz mi, dlaczego nie próbowałeś w kolejkach lub jakimś wspólnym autobusie? Ponieważ mówisz, że przy asynchronii możesz wysyłać same dzienniki przez kolejkę i asynchronicznie odbierać odpowiedź przez kolejkę?

YN: – Proszę o sugestie, jakie kolejki można zastosować?
Z: – Wszelkie, nawet bez gwarancji, że są w porządku. Jakiś rodzaj Redis, RMQ...
YN: – Mam wrażenie, że Redis najprawdopodobniej nie będzie w stanie wyciągnąć takiej liczby wstawek nawet na jednym hoście (w sensie kilku serwerów), co wyciąga Clickhouse. Nie mogę tego poprzeć żadnymi dowodami (nie przeprowadzałem testów porównawczych), ale wydaje mi się, że Redis nie jest tutaj najlepszym rozwiązaniem. W zasadzie system ten można uznać za zaimprowizowaną kolejkę wiadomości, ale dostosowaną tylko do „Clickhouse”
Moderator: – Jurij, dziękuję bardzo. Proponuję na tym zakończyć pytania i odpowiedzi i powiedzieć, któremu z zadających pytanie przekażemy książkę.
YN: – Chciałbym podarować książkę pierwszej osobie, która zada pytanie.
Moderator: - Wspaniały! Świetnie! Wspaniały! Wielkie dzięki!

Kilka reklam 🙂
Dziękujemy za pobyt z nami. Podobają Ci się nasze artykuły? Chcesz zobaczyć więcej ciekawych treści? Wesprzyj nas składając zamówienie lub polecając znajomym, , unikalny odpowiednik serwerów klasy podstawowej, który został przez nas wymyślony dla Ciebie: (dostępne z RAID1 i RAID10, do 24 rdzeni i do 40 GB DDR4).
Dell R730xd 2 razy taniej w centrum danych Equinix Tier IV w Amsterdamie? Tylko tutaj w Holandii! Dell R420 — 2x E5-2430 2.2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gb/s 100 TB — od 99 USD! Czytać o
Źródło: www.habr.com
