

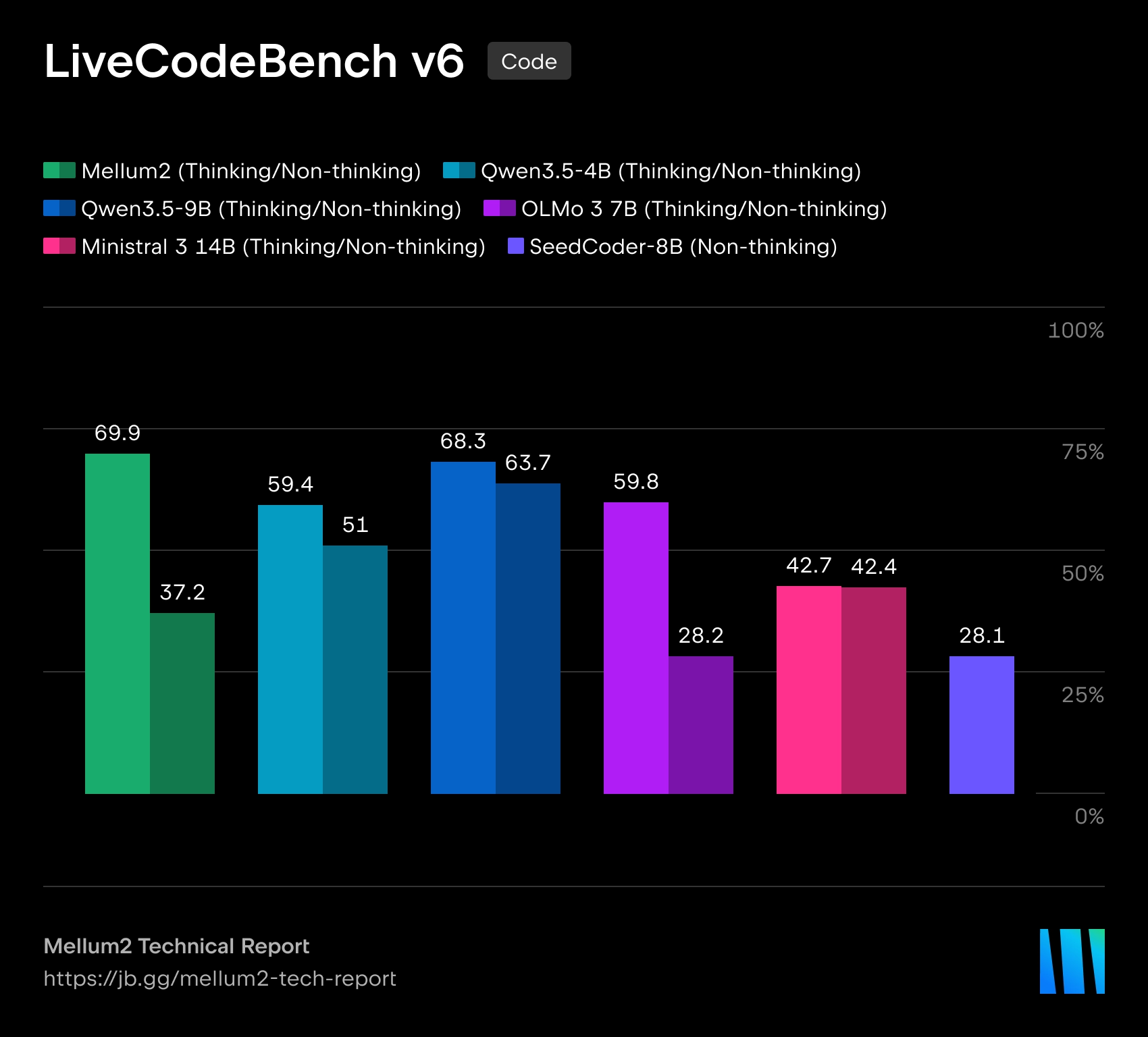
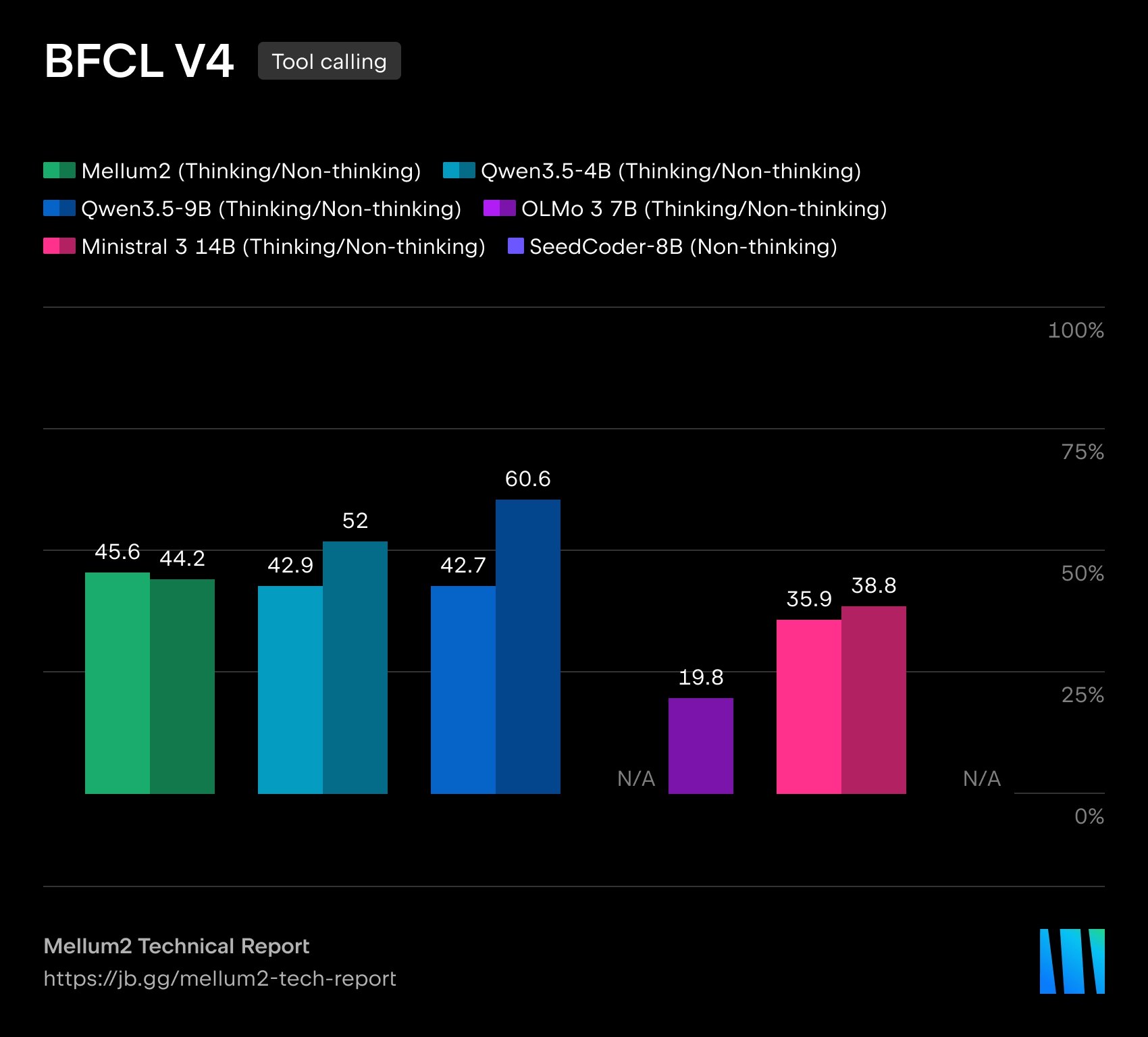
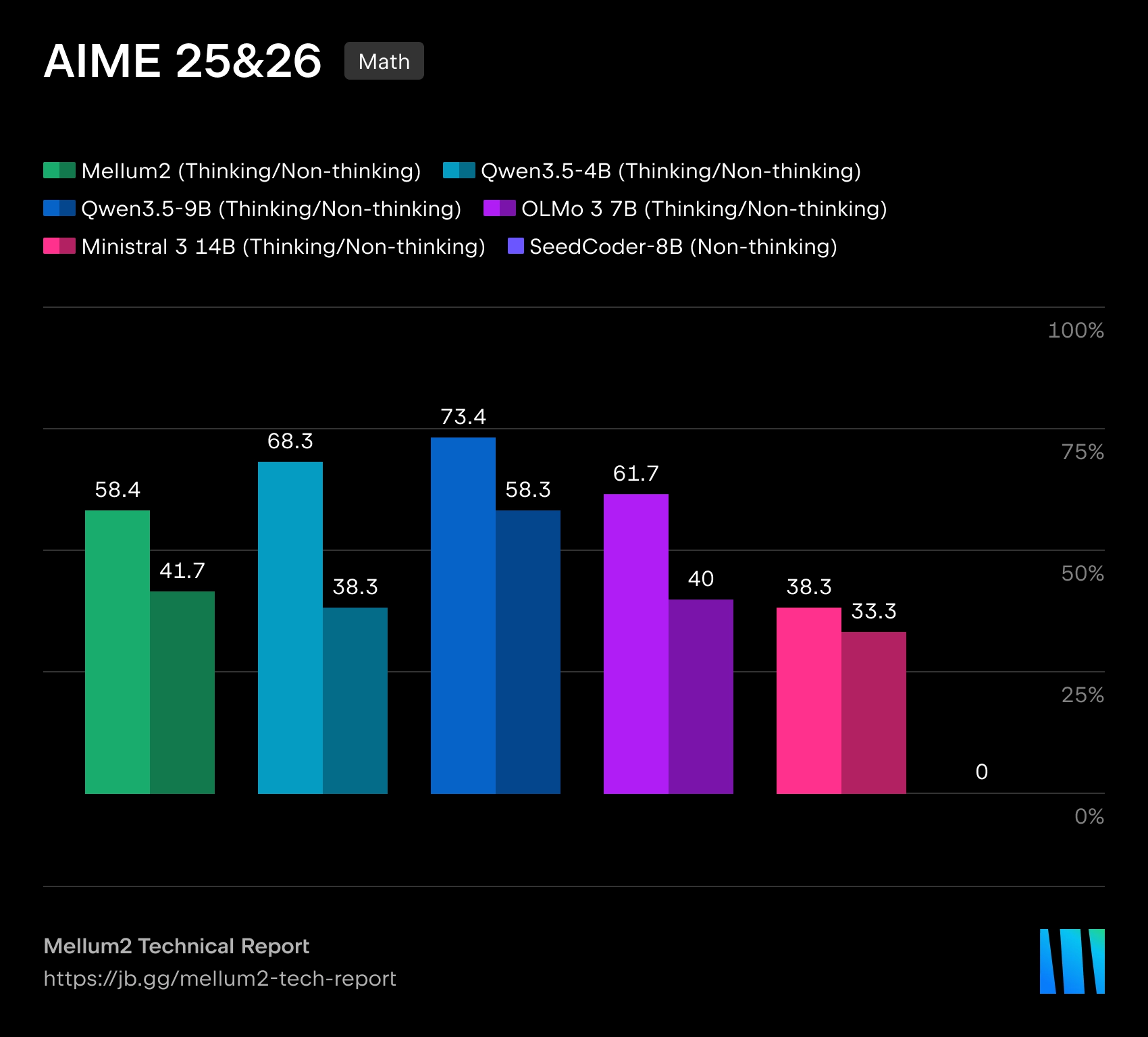
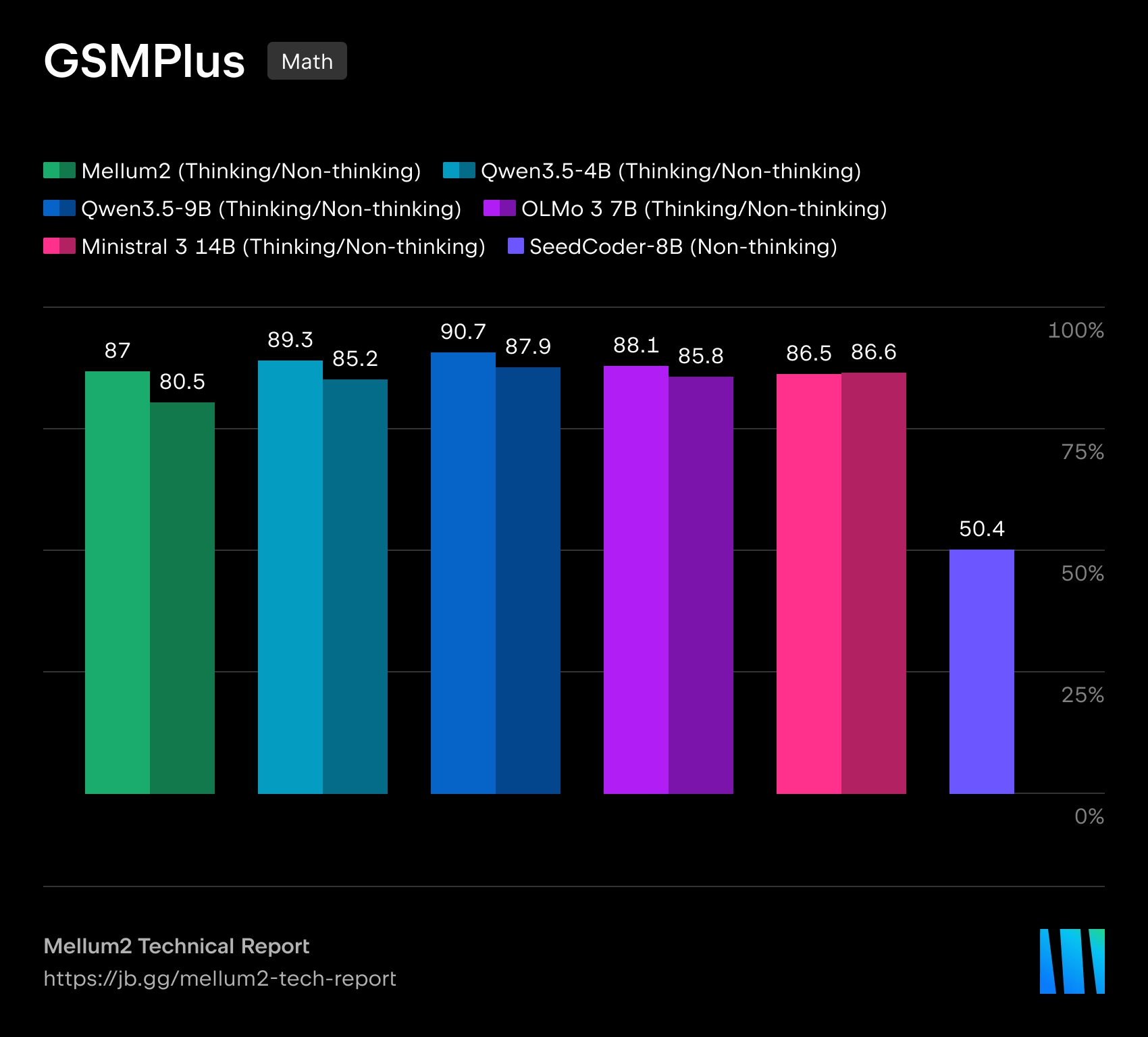
A JetBrains abriu um modelo Mellum2, projetado para uso em ferramentas de IA para desenvolvimento de software. O modelo é publicado sob uma licença Apache 2.0Os pesos estão disponíveis no Hugging Face. A JetBrains enfatiza que o Mellum2 foi treinado do zero e foi projetado não para tarefas multimodais, mas para trabalhar com texto e código: roteamento de requisições, pipelines RAG, sumarização, agentes auxiliares e implantação privada em infraestrutura corporativa.
Mellum2 é construído sobre a arquitetura Mistura de especialistasCom um tamanho total de 12 bilhões de parâmetros Apenas cerca de 1000 são ativados por token. 2.5 bilhões de parâmetrosO que deve reduzir os custos computacionais e a latência durante a inferência. De acordo com a JetBrains, o desempenho do modelo em benchmarks é comparável ao de modelos de código aberto de tamanho similar, mas oferece mais que o dobro da aceleração na inferência.
A JetBrains descreve o Mellum2 como uma evolução do modelo Mellum original, criado inicialmente para autocompletar código. A nova versão expande-se para uma classe mais ampla de tarefas que exigem o trabalho tanto com código de programa quanto com linguagem natural. A empresa posiciona o Mellum2 como um modelo "focado" — não um substituto para grandes modelos de linguagem natural (LLMs) de uso geral, mas um componente rápido e especializado para operações intermediárias frequentes em sistemas complexos de IA.
Entre os casos de uso propostos estão: são chamados Classificação e encaminhamento de solicitações entre modelos e ferramentas, compressão e processamento de contexto em sistemas RAG, preparação de dados para agentes, agendamento, validação de resultados intermediários e execução local em ambientes onde não é possível enviar código-fonte ou dados internos para APIs externas.
Na cara de abraço publicado uma coleção Mellum 2, que inclui diversas variantes de modelos: Thinking, Instruct, Thinking-SFT, Instruct-SFT, Base e Base-Pretrain. Os modelos são distribuídos no formato Safetensors sob a licença Apache 2.0.
São fornecidos exemplos de utilização através de Transformers, vLLM, SGLang e Docker Model Runner para execução.
O que é tecnicamente mais interessante não é o surgimento de mais um modelo de código aberto, mas sim o nicho escolhido pela JetBrains. A empresa não está focada em competir com os maiores modelos de propósito geral, mas sim em componentes rápidos e de baixo custo que podem ser integrados diretamente em IDEs, assistentes internos, sistemas RAG corporativos e pipelines de agentes. Para desenvolvedores e empresas, isso significa a capacidade de executar alguma lógica de IA localmente ou em seus próprios servidores, mantendo o controle sobre o código, os dados e os custos de inferência.
Fonte: linux.org.ru
