

Olá a todos. Neste artigo contarei por que nós da Avito escolhemos Kafka há nove meses e o que é. Compartilharei um dos casos de uso: um corretor de mensagens. E, finalmente, vamos falar sobre as vantagens que obtivemos ao usar a abordagem Kafka as a Service.
problema

Primeiro, um pouco de contexto. Há algum tempo começamos a nos afastar da arquitetura monolítica e agora o Avito já conta com várias centenas de serviços diferentes. Eles têm seus próprios repositórios, sua própria pilha de tecnologia e são responsáveis por sua parte na lógica de negócios.
Um dos problemas com um grande número de serviços é a comunicação. O Serviço A geralmente deseja saber informações que o Serviço B possui. Nesse caso, o Serviço A acessa o Serviço B por meio de uma API síncrona. O serviço B quer saber o que está acontecendo com os serviços D e D, e eles, por sua vez, estão interessados nos serviços A e B. Quando há muitos desses serviços “curiosos”, as conexões entre eles se transformam em um emaranhado.
Ao mesmo tempo, o serviço A pode ficar indisponível a qualquer momento. E o que o serviço B e todos os outros serviços a ele ligados devem fazer neste caso? E se uma cadeia de chamadas síncronas sequenciais for necessária para concluir uma operação comercial, a probabilidade de falha de toda a operação torna-se ainda maior (e quanto mais longa a cadeia, maior ela é).
Seleção de tecnologia

Ok, os problemas são claros. Eles podem ser eliminados com a criação de um sistema de mensagens centralizado entre os serviços. Agora, cada um dos serviços só precisa saber sobre esse sistema de mensagens. Além disso, o próprio sistema deve ser tolerante a falhas e escalável horizontalmente, e também, em caso de acidentes, acumular um buffer de acesso para processamento posterior.
Vamos agora selecionar a tecnologia na qual a entrega de mensagens será implementada. Para fazer isso, vamos primeiro entender o que esperamos dele:
- as mensagens entre serviços não devem ser perdidas;
- as mensagens podem ser duplicadas;
- as mensagens podem ser armazenadas e lidas por vários dias (buffer persistente);
- os serviços podem assinar os dados que lhes interessam;
- vários serviços podem ler os mesmos dados;
- as mensagens podem conter carga útil volumosa e detalhada (transferência de estado transportada por evento);
- Às vezes você precisa garantir a ordem das mensagens.
Também foi extremamente importante para nós escolher o sistema mais escalável e confiável com alto rendimento (pelo menos 100 mil mensagens de vários kilobytes por segundo).
Neste ponto, dissemos adeus ao RabbitMQ (difícil de manter estável em altas rps), ao PGQ do SkyTools (não é rápido o suficiente e não escala bem) e ao NSQ (não persistente). Utilizamos todas essas tecnologias em nossa empresa, mas elas não eram adequadas para o problema que estava sendo resolvido.
Em seguida, começamos a examinar tecnologias que eram novas para nós – Apache Kafka, Apache Pulsar e NATS Streaming.
Pulsar foi o primeiro a ser descartado. Decidimos que Kafka e Pulsar são soluções bastante semelhantes. E apesar de o Pulsar ter sido testado por grandes empresas, ser mais novo e oferecer menor latência (em teoria), decidimos deixar o Kafka desses dois como o padrão de fato para tais tarefas. Provavelmente retornaremos ao Apache Pulsar no futuro.
E agora restam dois candidatos: NATS Streaming e Apache Kafka. Estudamos ambas as soluções com algum detalhe e ambas eram adequadas para a tarefa. Mas no final, estávamos com medo da relativa juventude do NATS Streaming (e do fato de um dos principais desenvolvedores, Tyler Treat, ter decidido deixar o projeto e começar o seu próprio - Liftbridge). Ao mesmo tempo, o modo Clustering do NATS Streaming não oferecia a possibilidade de um forte escalonamento horizontal (provavelmente isso não é mais um problema após a adição do modo de particionamento em 2017).
No entanto, NATS Streaming é uma tecnologia interessante escrita em Go e apoiada pela Cloud Native Computing Foundation. Ao contrário do Apache Kafka, ele não precisa do Zookeeper para funcionar (talvez ), uma vez que implementa RAFT internamente. Ao mesmo tempo, o NATS Streaming é mais fácil de administrar. Não descartamos que voltaremos a esta tecnologia no futuro.
E ainda assim, hoje nosso vencedor é Apache Kafka. Em nossos testes, mostrou-se bastante rápido (mais de um milhão de mensagens por segundo para leitura e escrita com volume de mensagens de 1 kilobyte), bastante confiável, altamente escalável e comprovado pela experiência na produção de grandes empresas. Além disso, Kafka suporta pelo menos várias grandes empresas comerciais (nós, por exemplo, usamos a versão Confluent), e Kafka também possui um ecossistema desenvolvido.
Visão geral de Kafka
Antes de começarmos, gostaria de recomendar imediatamente um excelente livro - "Kafka: o guia definitivo" (há também uma tradução para o russo, mas os termos são um pouco confusos). Ele contém as informações que você precisa para obter uma compreensão básica do Kafka e até um pouco mais. A documentação do Apache e o blog do Confluent também são bem escritos e fáceis de ler.
Então, vamos dar uma olhada geral em como o Kafka funciona. A topologia básica do Kafka consiste em produtor, consumidor, corretor e tratador.
corretor
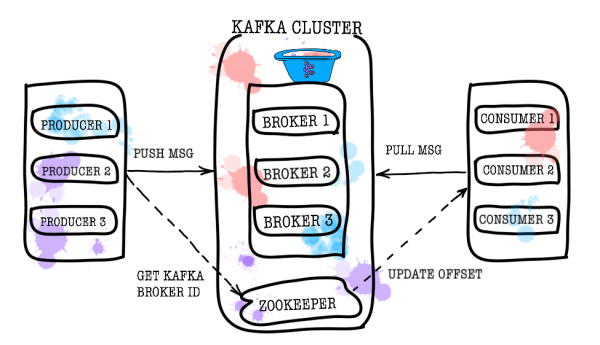
A corretora é responsável por armazenar seus dados. Todos os dados são armazenados em formato binário e a corretora sabe pouco sobre o que são e qual é sua estrutura.
Cada tipo de evento lógico geralmente está localizado em seu próprio tópico separado. Por exemplo, o evento de criação de um anúncio pode cair no tópico item.criado, e o evento de alteração pode cair no tópico item.alterado. Os tópicos podem ser considerados classificadores de eventos. No nível do tópico, você pode definir parâmetros de configuração como:
- a quantidade de dados armazenados e/ou sua idade (retention.bytes, retention.ms);
- fator de redundância de dados (fator de replicação);
- tamanho máximo de uma mensagem (max.message.bytes);
- o número mínimo de réplicas consistentes nas quais os dados podem ser gravados em um tópico (min.insync.replicas);
- a capacidade de realizar um failover em uma réplica atrasada não síncrona com potencial perda de dados (unclean.leader.election.enable);
- e muitos mais ().
Por sua vez, cada tópico é dividido em uma ou mais partições. É nos partidos que os acontecimentos acabam por cair. Se houver mais de um corretor no cluster, as partições serão distribuídas uniformemente entre todos os corretores (na medida do possível), o que permitirá que a carga de gravação e leitura em um tópico seja dimensionada para vários corretores ao mesmo tempo.
No disco, os dados de cada partição são armazenados na forma de arquivos de segmento, por padrão iguais a um gigabyte (controlados por log.segment.bytes). Um recurso importante é que os dados são excluídos das partições (quando a retenção é acionada) em segmentos (você não pode excluir um evento de uma partição, só pode excluir um segmento inteiro e apenas um inativo).
Zookeeper
Zookeeper atua como armazenamento e coordenador de metadados. É ele quem consegue dizer se os corretores estão vivos (você pode ver isso através dos olhos do zookeeper usando zookeeper-shell com o comando ls /brokers/ids), qual corretor é o controlador (get /controller), se as partições estão sincronizadas com suas réplicas (get /brokers/topics/topic_name/partitions/partition_number/state). Além disso, é ao zookeeper que o produtor e o consumidor irão primeiro descobrir em qual corretor quais tópicos e partições estão armazenados. Nos casos em que um fator de replicação maior que 1 for especificado para um tópico, o zookeeper indicará quais partições são as líderes (elas serão gravadas e lidas). Em caso de falha do broker, as informações sobre as novas partições líderes serão registradas no zookeeper (a partir da versão 1.1.0 de forma assíncrona, ).
Nas versões mais antigas do Kafka, o zookeeper também era responsável por armazenar as compensações, mas agora elas são armazenadas em um tópico especial __consumer_offsets no corretor (embora você ainda possa usar o zookeeper para esses fins).
A maneira mais fácil de transformar seus dados em uma abóbora é perder informações do tratador. Nesse cenário, será muito difícil entender o que ler e de onde.
Produtor
O produtor geralmente é um serviço que grava dados diretamente no Apache Kafka. O Produtor seleciona um tópico no qual armazenar suas mensagens de tópico e começa a escrever informações nele. Por exemplo, o produtor poderia ser um serviço de publicidade. Neste caso, enviará eventos como “anúncio criado”, “anúncio atualizado”, “anúncio excluído”, etc. Cada evento é um par de valores-chave.
Por padrão, todos os eventos são distribuídos entre partições de tópico usando round-robin se a chave não for especificada (perdendo a ordem) e através de MurmurHash (chave) se a chave estiver presente (ordenando dentro de uma partição).
É importante notar desde já que Kafka garante a ordem dos eventos apenas dentro de um lote. Mas, na realidade, isso muitas vezes não é um problema. Por exemplo, você pode ter certeza de adicionar todas as alterações na mesma declaração em uma partição (preservando assim a ordem dessas alterações dentro da declaração). Você também pode enviar um número de sequência em um dos campos do evento.
Consumidores
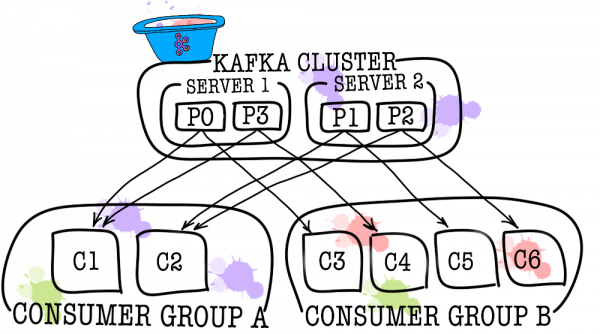
O consumidor é responsável por buscar dados do Apache Kafka. Se voltarmos ao exemplo acima, o consumidor poderia ser um serviço de moderação. Este serviço será inscrito no tópico de serviço de anúncios e, quando um novo anúncio aparecer, irá recebê-lo e analisá-lo quanto ao cumprimento de algumas políticas especificadas.
Apache Kafka lembra quais eventos recentes o consumidor recebeu (um tópico de serviço é usado para isso __consumer__offsets), garantindo assim que, se a leitura for bem-sucedida, o consumidor não receberá a mesma mensagem duas vezes. Porém, se você usar a opção enable.auto.commit = true e delegar completamente ao Kafka o trabalho de rastrear a posição do consumidor no tópico, você pode . No código de produção, na maioria das vezes a posição do consumidor é controlada manualmente (o desenvolvedor controla o momento em que o commit do evento de leitura deve ocorrer).
Nos casos em que um consumidor não é suficiente (por exemplo, o fluxo de novos eventos é muito grande), é possível adicionar vários outros consumidores vinculando-os em um grupo de consumidores. Um grupo de consumidores é logicamente igual a um consumidor, mas com dados distribuídos entre os membros do grupo. Isso permite que cada participante receba sua parcela de mensagens, aumentando assim a velocidade de leitura.
Resultados do teste

Não vou escrever muito texto explicativo aqui, apenas compartilharei os resultados obtidos. Os testes foram realizados em 3 máquinas físicas (12 CPU, 384 GB de RAM, 15k SAS DISK, 10GBit/s Net), corretores e zookeeper foram implantados em lxc.
Teste de performance
Durante o teste, os seguintes resultados foram obtidos.
- A velocidade de gravação simultânea de mensagens de 1 KB por 9 produtores é de 1300000 eventos por segundo.
- A velocidade de leitura simultânea de mensagens de 1 KB por 9 consumidores é de 1500000 eventos por segundo.
Teste de tolerância a falhas
Durante os testes, foram obtidos os seguintes resultados (3 corretores, 3 tratadores do zoológico).
- O encerramento anormal de um dos intermediários não faz com que o cluster pare ou fique indisponível. O trabalho continua normalmente, mas os demais corretores têm uma carga de trabalho pesada.
- O encerramento anormal de dois corretores no caso de um cluster de três corretores e min.isr = 2 faz com que o cluster fique indisponível para gravação, mas acessível para leitura. Se min.isr = 1, o cluster continua disponível para leitura e gravação. No entanto, este modo contradiz o requisito de elevada segurança de dados.
- Um desligamento anormal de um dos servidores Zookeeper não faz com que o cluster pare ou fique indisponível. O trabalho continua normalmente.
- Um desligamento anormal de dois servidores Zookeeper faz com que o cluster fique indisponível até que pelo menos um dos servidores Zookeeper seja restaurado. Esta afirmação é verdadeira para um cluster Zookeeper de 3 servidores. Como resultado, após pesquisa, foi decidido aumentar o cluster Zookeeper para 5 servidores para aumentar a tolerância a falhas.
Kafka como serviço

Estamos convencidos de que Kafka é uma excelente tecnologia que nos permite resolver a tarefa que nos foi atribuída (implementar um corretor de mensagens). No entanto, decidimos proibir os serviços de acessar diretamente o Kafka e fechamos o serviço com um serviço de barramento de dados. Por que fizemos isso? Na verdade, existem alguns motivos.
O Data-bus assumiu todas as tarefas relacionadas à integração com Kafka (implementação e configuração de consumidores e produtores, monitoramento, alertas, registro, escalonamento, etc.). Assim, a integração com o message broker é o mais simples possível.
O barramento de dados nos permitiu abstrair de uma linguagem ou biblioteca específica para trabalhar com Kafka.
O barramento de dados permitiu que outros serviços abstraíssem a camada de armazenamento. Talvez em algum momento mudemos Kafka para Pulsar e ninguém notará nada (todos os serviços só conhecem a API do barramento de dados).
O barramento de dados assumiu a validação dos esquemas de eventos.
A autenticação é implementada usando barramento de dados.
Sob a cobertura do barramento de dados, podemos atualizar silenciosamente as versões do Kafka sem tempo de inatividade, gerenciar centralmente as configurações de produtores, consumidores, corretores, etc.
O barramento de dados nos permitiu adicionar os recursos necessários que não estão no Kafka (como auditar tópicos, monitorar anomalias no cluster, criar DLQ, etc.).
O barramento de dados permite implementar o failover centralmente para todos os serviços.
No momento, para começar a enviar eventos para o message broker, basta conectar uma pequena biblioteca ao seu código de serviço. Isso é tudo. Você tem a capacidade de escrever, ler e dimensionar com uma linha de código. Toda a implementação fica oculta para você, com apenas algumas alças de tamanho de lote destacadas. Nos bastidores, o serviço de barramento de dados aumenta o número necessário de instâncias de produtores e consumidores no Kubernetes e fornece a eles a configuração necessária, mas tudo isso é transparente para o seu serviço.
É claro que não existe solução mágica e esta abordagem tem as suas limitações.
- O barramento de dados precisa ser suportado internamente, em oposição a bibliotecas de terceiros.
- O barramento de dados aumenta o número de interações entre os serviços e o corretor de mensagens, o que resulta em desempenho inferior em comparação com o Kafka simples.
- Nem tudo pode ser ocultado dos serviços tão facilmente; não queremos duplicar a funcionalidade do KSQL ou Kafka Streams no barramento de dados, então às vezes temos que permitir que os serviços sejam executados diretamente.
No nosso caso, os prós superaram os contras e a decisão de cobrir o corretor de mensagens com um serviço separado foi justificada. Durante o ano de operação não tivemos acidentes ou problemas graves.
PS Obrigado à minha namorada, Ekaterina Obalyaeva, pelas fotos legais deste artigo. Se você gostou deles, há mais ilustrações por vir.
Fonte: habr.com
