

preistorie
Există automate cu design propriu. În interiorul Raspberry Pi și unele cablaje pe o placă separată. Sunt conectate un acceptor de monede, un acceptor de bancnote, un terminal bancar... Totul este controlat de un program auto-scris. Întregul istoric de lucru este scris într-un jurnal de pe o unitate flash (MicroSD), care este apoi transmis prin Internet (folosind un modem USB) către server, unde este stocat într-o bază de date. Informațiile de vânzări sunt încărcate în 1c, există și o interfață web simplă pentru monitorizare etc.
Adică jurnalul este vital - pentru contabilitate (venituri, vânzări etc.), monitorizare (tot felul de nereguli și alte circumstanțe de forță majoră); Aceasta, s-ar putea spune, este toate informațiile pe care le avem despre această mașină.
problemă
Unitățile flash se arată a fi dispozitive foarte nesigure. Ei eșuează cu o regularitate de invidiat. Acest lucru duce atât la oprirea mașinii, cât și (dacă din anumite motive jurnalul nu a putut fi transferat online) la pierderea datelor.
Aceasta nu este prima experiență de utilizare a unităților flash, înainte de aceasta a existat un alt proiect cu peste o sută de dispozitive, unde revista era stocată pe unități flash USB, au apărut și probleme de fiabilitate, uneori numărul celor care au eșuat în o lună era în zeci. Am încercat diferite unități flash, inclusiv cele de marcă cu memorie SLC, iar unele modele sunt mai fiabile decât altele, dar înlocuirea unităților flash nu a rezolvat radical problema.
Atenție! Citiți lung! Dacă nu ești interesat de „de ce”, ci doar de „cum”, poți merge direct articol.
decizie
Primul lucru care îmi vine în minte este: abandonați MicroSD, instalați, de exemplu, un SSD și porniți de pe acesta. Teoretic posibil, probabil, dar relativ scump și nu atât de fiabil (se adaugă un adaptor USB-SATA; statisticile de eșec pentru SSD-urile bugetare nu sunt nici încurajatoare).
De asemenea, HDD-ul USB nu pare o soluție deosebit de atractivă.
Prin urmare, am ajuns la această opțiune: lăsați pornirea de pe MicroSD, dar folosiți-le în modul doar citire și stocați jurnalul de operare (și alte informații unice pentru o anumită piesă de hardware - număr de serie, calibrări ale senzorului etc.) în altă parte. .
Subiectul FS numai pentru citire pentru zmeură a fost deja studiat în interior și în exterior, nu mă voi opri asupra detaliilor de implementare în acest articol (dar dacă există interes, poate voi scrie un mini-articol pe acest subiect). Singurul punct pe care aș dori să-l remarc este că atât din experiența personală, cât și din recenziile celor care l-au implementat deja, există un câștig în fiabilitate. Da, este imposibil să scapi complet de defecțiuni, dar reducerea semnificativă a frecvenței acestora este destul de posibilă. Și cardurile devin unificate, ceea ce face înlocuirea mult mai ușoară pentru personalul de service.
Partea de hardware
Nu a existat nicio îndoială specială cu privire la alegerea tipului de memorie - NOR Flash.
Argumente:
- conexiune simplă (cel mai adesea magistrala SPI, pe care ai deja experiență de utilizare, deci nu sunt prevăzute probleme hardware);
- preț ridicol;
- protocol standard de operare (implementarea este deja în kernel) Linux, dacă doriți, puteți alege unul de la o terță parte, care este și el prezent, sau chiar să vă scrieți propriul, din fericire, totul este simplu);
- fiabilitate și resurse:
dintr-o fișă de date tipică: datele sunt stocate timp de 20 de ani, 100000 de cicluri de ștergere pentru fiecare bloc;
din surse terțe: BER extrem de scăzut, postulează că nu este nevoie de coduri de corectare a erorilor (unele lucrări consideră ECC pentru NOR, dar, de obicei, ele încă înseamnă MLC NOR; acest lucru se întâmplă și).
Să estimăm cerințele pentru volum și resurse.
Aș dori ca datele să fie garantate pentru a fi salvate pentru câteva zile. Acest lucru este necesar pentru ca în cazul oricăror probleme de comunicare, istoricul vânzărilor să nu se piardă. Ne vom concentra pe 5 zile, în această perioadă (chiar ținând cont de weekend și sărbători) problema poate fi rezolvata.
În prezent, colectăm aproximativ 100 kb de loguri pe zi (3-4 mii de intrări), dar treptat această cifră crește - detaliul crește, se adaugă noi evenimente. În plus, uneori există explozii (unele senzori începe să trimită spam cu false pozitive, de exemplu). Vom calcula pentru 10 mii de înregistrări câte 100 de octeți fiecare - megaocteți pe zi.
În total, ies 5 MB de date curate (bine comprimate). Mai mult pentru ei (estimare aproximativă) 1 MB de date de serviciu.
Adică, avem nevoie de un cip de 8MB dacă nu folosim compresie sau de 4MB dacă îl folosim. Cifre destul de realiste pentru acest tip de memorie.
În ceea ce privește resursa: dacă plănuim ca întreaga memorie să fie rescrisă nu mai mult de o dată la 5 zile, atunci peste 10 ani de serviciu vom obține mai puțin de o mie de cicluri de rescriere.
Permiteți-mi să vă reamintesc că producătorul promite o sută de mii.
Câteva despre NOR vs NAND
Astăzi, desigur, memoria NAND este mult mai populară, dar nu aș folosi-o pentru acest proiect: NAND, spre deosebire de NOR, necesită neapărat utilizarea de coduri de corectare a erorilor, un tabel de blocuri defecte etc., precum și picioarele Cipurile NAND de obicei mult mai multe.
Dezavantajele NOR includ:
- volum mic (și, în consecință, preț ridicat pe megaoctet);
- viteză scăzută de comunicare (în mare parte datorită faptului că se folosește o interfață serială, de obicei SPI sau I2C);
- ștergere lentă (în funcție de dimensiunea blocului, durează de la o fracțiune de secundă la câteva secunde).
Se pare că nu este nimic critic pentru noi, așa că continuăm.
Dacă detaliile sunt interesante, microcircuitul a fost selectat (totuși, acest lucru este lipsit de importanță, există o mulțime de analogi pe piață care sunt compatibile în sistemul de pinout și comandă; chiar dacă dorim să instalăm un microcircuit de la un alt producător și/sau o altă dimensiune, totul va funcționa fără a schimba cod).
Eu îl folosesc pe cel încorporat în kernel Linux Driver, pe Raspberry, datorită suportului pentru suprapunerea arborelui de dispozitive, totul este foarte simplu - trebuie să puneți suprapunerea compilată în /boot/overlays și să modificați ușor /boot/config.txt.
Exemplu de fișier dts
Sincer să fiu, nu sunt sigur că este scris fără erori, dar funcționează.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};Și încă o linie în config.txt
dtoverlay=at25:spimaxfrequency=50000000Voi omite descrierea conectării cipul la Raspberry Pi. Pe de o parte, nu sunt un expert în electronică, pe de altă parte, totul aici este banal chiar și pentru mine: microcircuitul are doar 8 picioare, dintre care avem nevoie de masă, putere, SPI (CS, SI, SO, SCK). ); nivelurile sunt aceleași cu cele ale Raspberry Pi, nu este nevoie de cablare suplimentară - doar conectați cei 6 pini indicați.
Declarație de problemă
Ca de obicei, declarația problemei trece prin mai multe iterații și mi se pare că este timpul pentru următoarea. Așa că să ne oprim, să punem cap la cap ceea ce a fost deja scris și să lămurim detaliile care rămân în umbră.
Deci, am decis ca jurnalul să fie stocat în SPI NOR Flash.
Ce este NOR Flash pentru cei care nu știu?
Aceasta este o memorie nevolatilă cu care puteți face trei operații:
- Citind:
Cea mai obișnuită citire: transmitem adresa și citim câți octeți avem nevoie; - înregistrare:
Scrierea în NOR flash arată ca una obișnuită, dar are o particularitate: puteți schimba doar 1 la 0, dar nu și invers. De exemplu, dacă am avut 0x55 într-o celulă de memorie, atunci după ce ați scris 0x0f în ea, 0x05 va fi deja stocat acolo (vezi tabelul de mai jos); - Şterge:
Desigur, trebuie să putem face operația opusă - schimbarea 0 la 1, exact pentru asta este operația de ștergere. Spre deosebire de primele două, funcționează nu cu octeți, ci cu blocuri (blocul minim de ștergere din cipul selectat este de 4kb). Ștergerea distruge întregul bloc și este singura modalitate de a schimba de la 0 la 1. Prin urmare, atunci când lucrați cu memorie flash, adesea trebuie să aliniați structurile de date la limita blocului de ștergere.
Înregistrare în NOR Flash:
Date binare
a fost
01010101
Înregistrate
00001111
A devenit
00000101
Jurnalul în sine reprezintă o secvență de înregistrări de lungime variabilă. Lungimea tipică a unei înregistrări este de aproximativ 30 de octeți (deși uneori apar înregistrări cu o lungime de câțiva kiloocteți). În acest caz, lucrăm cu ele pur și simplu ca un set de octeți, dar, dacă sunteți interesat, CBOR este folosit în interiorul înregistrărilor
Pe lângă jurnal, trebuie să stocăm câteva informații de „setare”, atât actualizate, cât și nu: un anumit ID de dispozitiv, calibrări ale senzorului, un semnalizator „dispozitivul este dezactivat temporar” etc.
Aceste informații sunt un set de înregistrări cheie-valoare, stocate și în CBOR. Nu avem multe din aceste informații (cel mult câțiva kiloocteți) și sunt actualizate rar.
În cele ce urmează îl vom numi context.
Dacă ne amintim de unde a început acest articol, este foarte important să asigurăm stocarea fiabilă a datelor și, dacă este posibil, funcționarea continuă chiar și în cazul unor defecțiuni hardware/corupție a datelor.
Ce surse de probleme pot fi luate în considerare?
- Opriți în timpul operațiunilor de scriere/ștergere. Acesta este din categoria „nu există niciun truc împotriva rangei”.
Informatii de la pe stackexchange: atunci când alimentarea este oprită în timp ce lucrați cu flash, atât ștergerea (setat la 1) cât și scrierea (setat la 0) duc la un comportament nedefinit: datele pot fi scrise, parțial scrise (să zicem, am transferat 10 octeți/80 de biți) , dar nu se pot scrie încă doar 45 de biți), este posibil și ca unii dintre biți să fie într-o stare „intermediară” (citirea poate produce atât 0, cât și 1); - Erori în memoria flash în sine.
BER, deși foarte scăzut, nu poate fi egal cu zero; - Erori de autobuz
Datele transmise prin SPI nu sunt protejate în niciun fel atât erorile de un singur bit, cât și erorile de sincronizare - pierderea sau inserarea de biți (ceea ce duce la o distorsiune masivă a datelor); - Alte erori/difecțiuni
Erori în cod, erori Raspberry, interferență extraterestră...
Am formulat cerințele, a căror îndeplinire, în opinia mea, este necesară pentru a asigura fiabilitatea:
- înregistrările trebuie să intre imediat în memoria flash, scrierile întârziate nu sunt luate în considerare - dacă apare o eroare, aceasta trebuie detectată și procesată cât mai devreme - sistemul trebuie, dacă este posibil, să se recupereze;
(un exemplu din viață „cum nu ar trebui să fie”, pe care cred că l-a întâlnit toată lumea: după o repornire de urgență, sistemul de fișiere este „rupt” și sistemul de operare nu pornește)
Idei, abordări, reflecții
Când am început să mă gândesc la această problemă, mi-au trecut prin cap o mulțime de idei, de exemplu:
- utilizați compresia datelor;
- utilizați structuri inteligente de date, de exemplu, stocând anteturile înregistrărilor separat de înregistrările în sine, astfel încât, dacă există o eroare în orice înregistrare, puteți citi restul fără probleme;
- utilizați câmpuri de biți pentru a controla finalizarea înregistrării atunci când alimentarea este oprită;
- stocați sumele de control pentru orice;
- utilizați un tip de codare rezistentă la zgomot.
Unele dintre aceste idei au fost folosite, în timp ce altele s-au decis să fie abandonate. Să mergem în ordine.
Comprimarea datelor
Evenimentele în sine pe care le înregistrăm în jurnal sunt destul de asemănătoare și repetabile („a aruncat o monedă de 5 ruble”, „a apăsat butonul pentru a da schimb”, ...). Prin urmare, compresia ar trebui să fie destul de eficientă.
Overheadul de compresie este nesemnificativ (procesorul nostru este destul de puternic, chiar și primul Pi avea un singur nucleu cu o frecvență de 700 MHz, modelele actuale au mai multe nuclee cu o frecvență de peste un gigahertz), cursul de schimb cu stocarea este scăzut (mai multe megaocteți pe secundă), dimensiunea înregistrărilor este mică. În general, dacă compresia are un impact asupra performanței, aceasta va fi doar pozitivă. (absolut necritic, doar afirmând)În plus, nu avem unul încorporat real, ci unul obișnuit. Linux — deci implementarea nu ar trebui să necesite mult efort (este suficient să legați biblioteca și să folosiți câteva funcții din ea).
O bucată din jurnal a fost preluată de pe un dispozitiv de lucru (1.7 MB, 70 de mii de intrări) și a verificat mai întâi compresibilitatea folosind gzip, lz4, lzop, bzip2, xz, zstd disponibile pe computer.
- gzip, xz, zstd au prezentat rezultate similare (40Kb).
Am fost surprins că xz-ul la modă s-a arătat aici la nivel de gzip sau zstd; - lzip cu setările implicite a dat rezultate puțin mai proaste;
- lz4 și lzop au dat rezultate nu foarte bune (150Kb);
- bzip2 a arătat un rezultat surprinzător de bun (18Kb).
Deci, datele sunt comprimate foarte bine.
Deci (dacă nu găsim defecte fatale) va exista compresie! Pur și simplu pentru că mai multe date pot încăpea pe aceeași unitate flash.
Să ne gândim la dezavantaje.
Prima problemă: am convenit deja că fiecare înregistrare trebuie să treacă imediat la flash. De obicei, arhivatorul colectează date din fluxul de intrare până când decide că este timpul să scrie în weekend. Trebuie să primim imediat un bloc de date comprimat și să îl stocăm în memoria nevolatilă.
Văd trei moduri:
- Comprimați fiecare înregistrare folosind compresia dicționarului în loc de algoritmii discutați mai sus.
Este o opțiune complet funcțională, dar nu-mi place. Pentru a asigura un nivel de compresie mai mult sau mai puțin decent, dicționarul trebuie să fie „adaptat” la anumite date; orice modificare va duce la o scădere catastrofală a nivelului de compresie. Da, problema poate fi rezolvată prin crearea unei noi versiuni a dicționarului, dar aceasta este o durere de cap - va trebui să stocăm toate versiunile dicționarului; în fiecare intrare va trebui să indicăm cu ce versiune a dicționarului a fost comprimat... - Comprimați fiecare înregistrare folosind algoritmi „clasici”, dar independent de celelalte.
Algoritmii de compresie luați în considerare nu sunt proiectați să funcționeze cu înregistrări de această dimensiune (zeci de octeți), raportul de compresie va fi în mod clar mai mic de 1 (adică, creșterea volumului de date în loc de comprimare); - Efectuați FLUSH după fiecare înregistrare.
Multe biblioteci de compresie au suport pentru FLUSH. Aceasta este o comandă (sau un parametru al procedurii de compresie), la primirea căreia arhivatorul formează un flux comprimat, astfel încât să poată fi folosit pentru a restaura toate date necomprimate care au fost deja primite. Un astfel de analogsyncîn sisteme de fișiere saucommitîn sql.
Important este că operațiunile de compresie ulterioare vor putea folosi dicționarul acumulat și raportul de compresie nu va avea de suferit la fel de mult ca în versiunea anterioară.
Cred că este evident că am ales a treia opțiune, să o privim mai detaliat.
Găsite despre FLUSH în zlib.
Am făcut un test de genunchi pe baza articolului, am luat 70 de mii de intrări de jurnal de pe un dispozitiv real, cu o dimensiune a paginii de 60 Kb (Vom reveni la dimensiunea paginii mai târziu) primit:
Datele brute
Compresie gzip -9 (fără FLUSH)
zlib cu Z_PARTIAL_FLUSH
zlib cu Z_SYNC_FLUSH
Volumul, KB
1692
40
352
604
La prima vedere, prețul adus de FLUSH este excesiv de mare, dar în realitate nu avem de ales – fie să nu comprimăm deloc, fie să comprimăm (și foarte eficient) cu FLUSH. Nu trebuie să uităm că avem 70 de mii de înregistrări, redundanța introdusă de Z_PARTIAL_FLUSH este de doar 4-5 octeți pe înregistrare. Și raportul de compresie s-a dovedit a fi aproape 5:1, ceea ce este mai mult decât un rezultat excelent.
Poate fi o surpriză, dar Z_SYNC_FLUSH este de fapt o modalitate mai eficientă de a face FLUSH
Când utilizați Z_SYNC_FLUSH, ultimii 4 octeți ai fiecărei intrări vor fi întotdeauna 0x00, 0x00, 0xff, 0xff. Și dacă le cunoaștem, atunci nu trebuie să le stocăm, așa că dimensiunea finală este de doar 324Kb.
Articolul la care am legat are o explicație:
Se atașează un nou bloc de tip 0 cu conținut gol.
Un bloc de tip 0 cu conținut gol este format din:
- antetul blocului de trei biți;
- 0 până la 7 biți egali cu zero, pentru a obține alinierea octeților;
- secvența de patru octeți 00 00 FF FF.
După cum puteți vedea cu ușurință, în ultimul bloc înainte de acești 4 octeți există de la 3 la 10 biți zero. Cu toate acestea, practica a arătat că există de fapt cel puțin 10 biți zero.
Se dovedește că astfel de blocuri scurte de date sunt de obicei (întotdeauna?) codificate folosind un bloc de tip 1 (bloc fix), care se termină neapărat cu 7 biți zero, dând un total de 10-17 biți zero garantați (și restul vor fie zero cu o probabilitate de aproximativ 50%).
Deci, pe datele de testare, în 100% din cazuri există un octet zero înainte de 0x00, 0x00, 0xff, 0xff și în mai mult de o treime din cazuri există doi octeți zero (poate că faptul este că folosesc CBOR binar, iar când folosesc text JSON, blocurile de tip 2 - bloc dinamic ar fi mai frecvente, respectiv blocuri fără zero octeți suplimentari înainte de a fi întâlnite 0x00, 0x00, 0xff, 0xff).
În total, folosind datele de testare disponibile, este posibil să se încadreze în mai puțin de 250 Kb de date comprimate.
Puteți economisi puțin mai mult jongland cu biți: deocamdată ignorăm prezența câtorva biți zero la sfârșitul blocului, câțiva biți la începutul blocului nici nu se modifică...
Dar apoi am luat o decizie puternică să mă opresc, altfel în acest ritm aș putea ajunge să-mi dezvolt propriul arhivator.
În total, din datele mele de testare am primit 3-4 octeți per scriere, raportul de compresie s-a dovedit a fi mai mare de 6:1. Voi fi sincer: nu mă așteptam la un astfel de rezultat, în opinia mea, ceva mai bun decât 2:1 este deja un rezultat care justifică utilizarea compresiei.
Totul este în regulă, dar zlib (dezumflare) este încă un algoritm de compresie arhaic, binemeritat și ușor demodat. Simplul fapt că ultimii 32 Kb din fluxul de date necomprimat sunt folosiți ca dicționar astăzi arată ciudat (adică, dacă un bloc de date este foarte asemănător cu ceea ce era în fluxul de intrare cu 40 Kb în urmă, atunci va începe să fie arhivat din nou, și nu se va referi la o apariție anterioară). În arhivatorii moderni la modă, dimensiunea dicționarului este adesea măsurată în megaocteți, mai degrabă decât în kiloocteți.
Așa că ne continuăm mini-studiul despre arhivatori.
Apoi am testat bzip2 (rețineți că fără FLUSH a arătat un raport de compresie fantastic de aproape 100:1). Din păcate, a funcționat foarte slab cu FLUSH, dimensiunea datelor comprimate s-a dovedit a fi mai mare decât a datelor necomprimate.
Ipotezele mele despre motivele eșecului
Libbz2 oferă o singură opțiune de ștergere, care pare să șterge dicționarul (analog cu Z_FULL_FLUSH în zlib nu se vorbește despre nicio compresie eficientă după aceasta);
Iar ultimul care a fost testat a fost zstd. În funcție de parametri, se comprimă fie la nivelul gzip, dar mult mai rapid, fie mai bine decât gzip.
Din păcate, cu FLUSH nu a funcționat prea bine: dimensiunea datelor comprimate era de aproximativ 700Kb.
Я pe pagina github a proiectului, am primit un răspuns că ar trebui să contați pe până la 10 octeți de date de serviciu pentru fiecare bloc de date comprimate, ceea ce este aproape de rezultatele obținute, nu există nicio modalitate de a ajunge din urmă cu deflate.
Am decis să mă opresc în acest moment în experimentele mele cu arhive (dați-mi să vă reamintesc că xz, lzip, lzo, lz4 nu s-au arătat nici măcar în faza de testare fără FLUSH și nu am luat în considerare algoritmi de compresie mai exotici).
Să revenim la problemele de arhivare.
A doua problemă (cum se spune în ordine, nu în valoare) este că datele comprimate sunt un singur flux, în care există în mod constant referințe la secțiunile anterioare. Astfel, dacă o secțiune de date comprimate este deteriorată, pierdem nu numai blocul asociat de date necomprimate, ci și toate cele ulterioare.
Există o abordare pentru a rezolva această problemă:
- Preveniți apariția problemei - adăugați redundanță la datele comprimate, ceea ce vă va permite să identificați și să corectați erorile; despre asta vom vorbi mai târziu;
- Minimizați consecințele dacă apare o problemă
Am spus deja mai devreme că puteți comprima fiecare bloc de date în mod independent, iar problema va dispărea de la sine (deteriorarea datelor unui bloc va duce la pierderea datelor numai pentru acest bloc). Cu toate acestea, acesta este un caz extrem în care compresia datelor va fi ineficientă. Extrema opusă: folosiți toți cei 4MB ai cipului nostru ca o singură arhivă, ceea ce ne va oferi o compresie excelentă, dar consecințe catastrofale în cazul coruperii datelor.
Da, este nevoie de un compromis în ceea ce privește fiabilitatea. Dar trebuie să ne amintim că dezvoltăm un format de stocare a datelor pentru memorie nevolatilă cu BER extrem de scăzut și o perioadă declarată de stocare a datelor de 20 de ani.
În timpul experimentelor, am descoperit că pierderile mai mult sau mai puțin vizibile ale nivelului de compresie încep pe blocuri de date comprimate cu dimensiunea mai mică de 10 KB.
S-a menționat anterior că memoria utilizată este paginată. Nu văd niciun motiv pentru care corespondența „o pagină - un bloc de date comprimate” să nu fie folosită.
Adică, dimensiunea minimă rezonabilă a paginii este de 16 Kb (cu o rezervă pentru informații de service). Cu toate acestea, o dimensiune atât de mică a paginii impune restricții semnificative asupra dimensiunii maxime a înregistrării.
Deși încă nu mă aștept la înregistrări mai mari de câțiva kiloocteți în formă comprimată, am decis să folosesc pagini de 32 Kb (pentru un total de 128 de pagini per cip).
Rezumat:
- Stocăm datele comprimate folosind zlib (deflate);
- Pentru fiecare intrare setăm Z_SYNC_FLUSH;
- Pentru fiecare înregistrare comprimată, tăiem octeții de sfârșit (de ex. 0x00, 0x00, 0xff, 0xff); în antet indicăm câți octeți tăiem;
- Stocăm datele în pagini de 32Kb; există un singur flux de date comprimate în interiorul paginii; Pe fiecare pagină începem din nou compresia.
Și, înainte de a termina cu compresia, aș dori să vă atrag atenția asupra faptului că avem doar câțiva octeți de date comprimate pe înregistrare, așa că este extrem de important să nu umflați informațiile de serviciu, aici fiecare octet contează.
Stocarea antetelor de date
Deoarece avem înregistrări de lungime variabilă, trebuie să determinăm cumva plasarea/limitele înregistrărilor.
Cunosc trei abordări:
- Toate înregistrările sunt stocate într-un flux continuu, mai întâi există un antet de înregistrare care conține lungimea, iar apoi înregistrarea în sine.
în acest exemplu de realizare, atât anteturile cât şi datele pot fi de lungime variabilă.
În esență, obținem o listă cu legături unice care este folosită tot timpul; - Anteturile și înregistrările în sine sunt stocate în fluxuri separate.
Prin utilizarea antetelor de lungime constantă, ne asigurăm că deteriorarea unui antet nu le afectează pe celelalte.
O abordare similară este utilizată, de exemplu, în multe sisteme de fișiere; - Înregistrările sunt stocate într-un flux continuu, limita înregistrării este determinată de un anumit marker (un caracter/secvență de caractere care este interzisă în blocurile de date). Dacă există un marcator în interiorul înregistrării, atunci îl înlocuim cu o secvență (scap it).
O abordare similară este utilizată, de exemplu, în protocolul PPP.
voi ilustra.
1 opțiune:

Totul este foarte simplu aici: cunoscând lungimea înregistrării, putem calcula adresa următorului antet. Așa că ne deplasăm prin titluri până când întâlnim o zonă plină cu 0xff (zonă liberă) sau sfârșitul paginii.
2 opțiune:

Din cauza lungimii variabile a înregistrărilor, nu putem spune în avans de câte înregistrări (și, prin urmare, antete) vom avea nevoie pe pagină. Puteți distribui anteturile și datele în sine pe pagini diferite, dar prefer o abordare diferită: plasăm atât anteturile, cât și datele pe o singură pagină, dar anteturile (de dimensiune constantă) vin de la începutul paginii, iar datele (de lungime variabilă) provin de la sfârșit. De îndată ce se „întâlnesc” (nu există suficient spațiu liber pentru o nouă intrare), considerăm această pagină completă.
3 opțiune:

Nu este nevoie să stocați lungimea sau alte informații despre locația datelor în antet sunt suficiente markeri care indică limitele înregistrărilor. Cu toate acestea, datele trebuie prelucrate la scriere/citire.
Aș folosi 0xff ca marker (care umple pagina după ștergere), așa că zona liberă nu va fi tratată cu siguranță ca date.
Tabel comparativ:
Opțiunea 1
Opțiunea 2
Opțiunea 3
Toleranță la eroare
-
+
+
densitate
+
-
+
Complexitatea implementării
*
**
**
Opțiunea 1 are un defect fatal: dacă oricare dintre anteturi este deteriorat, întregul lanț ulterior este distrus. Opțiunile rămase vă permit să recuperați unele date chiar și în cazul unei daune masive.
Dar aici este oportun să ne amintim că am decis să stocăm datele într-o formă comprimată și astfel pierdem toate datele de pe pagină după o înregistrare „ruptă”, așa că, deși există un minus în tabel, nu ia in calcul.
Compactitate:
- în prima opțiune, trebuie să stocăm doar lungimea în antet dacă folosim numere întregi de lungime variabilă, atunci în majoritatea cazurilor ne putem descurca cu un octet;
- în a doua opțiune trebuie să stocăm adresa de pornire și lungimea; înregistrarea trebuie să aibă o dimensiune constantă, eu estimez 4 octeți per înregistrare (doi octeți pentru offset și doi octeți pentru lungime);
- a treia opțiune are nevoie doar de un caracter pentru a indica începutul înregistrării, plus înregistrarea în sine va crește cu 1-2% datorită ecranării. În general, aproximativ paritate cu prima opțiune.
Inițial, am considerat a doua opțiune drept principală (și chiar am scris implementarea). L-am abandonat abia când am decis în sfârșit să folosesc compresia.
Poate că într-o zi voi folosi în continuare o opțiune similară. De exemplu, dacă trebuie să mă ocup de stocarea datelor pentru o navă care călătorește între Pământ și Marte, vor exista cerințe complet diferite pentru fiabilitate, radiații cosmice, ...
În ceea ce privește a treia opțiune: i-am acordat două stele pentru dificultatea implementării pur și simplu pentru că nu-mi place să mă încurc cu ecranarea, să schimb lungimea în proces etc. Da, poate sunt părtinitoare, dar va trebui să scriu codul - de ce să te forțezi să faci ceva ce nu-ți place.
Rezumat: Alegem opțiunea de stocare sub formă de lanțuri „antet cu lungime - date de lungime variabilă” datorită eficienței și ușurinței implementării.
Utilizarea câmpurilor de biți pentru a monitoriza succesul operațiunilor de scriere
Nu-mi amintesc acum de unde mi-a venit ideea, dar arată cam așa:
Pentru fiecare intrare, alocam mai mulți biți pentru a stoca steaguri.
După cum am spus mai devreme, după ștergere, toți biții sunt umpluți cu 1 și putem schimba de la 1 la 0, dar nu invers. Deci pentru „steagul nu este setat” folosim 1, pentru „steagul este setat” folosim 0.
Iată cum ar putea arăta introducerea unei înregistrări cu lungime variabilă în flash:
- Setați steagul „înregistrarea lungimii a început”;
- Înregistrați lungimea;
- Setați indicatorul „înregistrarea datelor a început”;
- Înregistrăm datele;
- Setați indicatorul „înregistrare încheiată”.
În plus, vom avea un flag „eroare a avut loc”, pentru un total de steaguri de 4 biți.
În acest caz, avem două stări stabile „1111” - înregistrarea nu a început și „1000” - înregistrarea a avut succes; în cazul unei întreruperi neașteptate a procesului de înregistrare, vom primi stări intermediare, pe care apoi le putem detecta și procesa.
Abordarea este interesantă, dar protejează doar împotriva întreruperilor bruște de curent și a defecțiunilor similare, ceea ce, desigur, este important, dar acesta este departe de singurul (sau chiar principalul) motiv al posibilelor defecțiuni.
Rezumat: Să mergem mai departe în căutarea unei soluții bune.
Sume de control
Sumele de control permit, de asemenea, să ne asigurăm (cu o probabilitate rezonabilă) că citim exact ceea ce ar fi trebuit scris. Și, spre deosebire de câmpurile de biți discutate mai sus, ele funcționează întotdeauna.
Dacă luăm în considerare lista de surse potențiale de probleme despre care am discutat mai sus, atunci suma de control este capabilă să recunoască o eroare indiferent de originea acesteia (cu excepția, poate, a extratereștrilor rău-intenționați - pot falsifica și suma de control).
Deci, dacă scopul nostru este să verificăm dacă datele sunt intacte, sumele de verificare sunt o idee grozavă.
Alegerea algoritmului pentru calcularea sumei de control nu a ridicat nicio întrebare - CRC. Pe de o parte, proprietățile matematice fac posibilă prinderea anumitor tipuri de erori 100%, pe de altă parte, pe date aleatoare, acest algoritm arată de obicei probabilitatea de coliziuni nu mult mai mare decât limita teoretică;  . Poate că nu este cel mai rapid algoritm și nici nu este întotdeauna minim în ceea ce privește numărul de ciocniri, dar are o calitate foarte importantă: în testele pe care le-am întâlnit, nu au existat modele în care să eșueze clar. Stabilitatea este principala calitate în acest caz.
. Poate că nu este cel mai rapid algoritm și nici nu este întotdeauna minim în ceea ce privește numărul de ciocniri, dar are o calitate foarte importantă: în testele pe care le-am întâlnit, nu au existat modele în care să eșueze clar. Stabilitatea este principala calitate în acest caz.
Exemplu de studiu volumetric: , (link-uri către narod.ru, îmi pare rău).
Cu toate acestea, sarcina de a selecta o sumă de control nu este completă; Trebuie să decideți lungimea și apoi să alegeți un polinom.
Alegerea lungimii sumei de control nu este o întrebare atât de simplă pe cât pare la prima vedere.
Să ilustrez:
Să avem probabilitatea unei erori în fiecare octet  și o sumă de control ideală, să calculăm numărul mediu de erori per milion de înregistrări:
și o sumă de control ideală, să calculăm numărul mediu de erori per milion de înregistrări:
Date, octet
Sumă de control, octet
Erori nedetectate
Detectarea erorilor false
Total fals pozitive
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
S-ar părea că totul este simplu - în funcție de lungimea datelor care sunt protejate, alegeți lungimea sumei de control cu un minim de pozitive incorecte - iar trucul este în geantă.
Cu toate acestea, apare o problemă cu sumele de verificare scurte: deși sunt bune la detectarea erorilor pe un singur bit, pot accepta, cu o probabilitate destul de mare, date complet aleatorii ca fiind corecte. Exista deja un articol despre Habré care descrie .
Prin urmare, pentru a face o potrivire aleatoare a sumei de control aproape imposibilă, trebuie să utilizați sume de control care au o lungime de 32 de biți sau mai mult. (pentru lungimi mai mari de 64 de biți, sunt utilizate de obicei funcții hash criptografice).
În ciuda faptului că am scris mai devreme că trebuie să economisim spațiu prin toate mijloacele, vom folosi în continuare o sumă de control de 32 de biți (16 biți nu sunt de ajuns, probabilitatea unei coliziuni este mai mare de 0.01%; și 24 de biți, deoarece acestea spune, nu sunt nici aici, nici acolo).
O obiecție poate apărea aici: am salvat fiecare octet atunci când am ales compresia pentru a oferi acum 4 octeți deodată? Nu ar fi mai bine să nu comprimați sau să adăugați o sumă de control? Bineînțeles că nu, fără compresie nu înseamnă, că nu avem nevoie de verificarea integrității.
Atunci când alegem un polinom, nu vom reinventa roata, ci vom lua acum popularul CRC-32C.
Acest cod detectează erori de 6 biți pe pachete de până la 22 de octeți (poate cel mai frecvent caz pentru noi), erori de 4 biți pe pachete de până la 655 de octeți (de asemenea, un caz obișnuit pentru noi), 2 sau orice număr impar de erori de biți pe pachete de orice lungime rezonabilă.
Daca este cineva interesat de detalii
despre CRC.
pe — poate cel mai important specialist CRC de pe planetă.
В există , care oferă parametri ceva mai buni pentru lungimile de pachete care sunt relevante pentru noi, dar nu am considerat diferența semnificativă și am fost suficient de competent să aleg codul personalizat în locul celui standard și bine cercetat.
De asemenea, deoarece datele noastre sunt comprimate, se pune întrebarea: ar trebui să calculăm suma de control a datelor comprimate sau necomprimate?
Argumente în favoarea calculării sumei de control a datelor necomprimate:
- În cele din urmă trebuie să verificăm siguranța stocării datelor – așa că o verificăm direct (în același timp, vor fi verificate eventuale erori în implementarea compresiei/decompresiei, daune cauzate de memoria spartă etc.);
- Algoritmul de deflare din zlib are o implementare destul de matură și nu ar trebui În plus, este adesea capabil să detecteze în mod independent erorile în fluxul de intrare, reducând probabilitatea generală de nedetectare a unei erori (a efectuat un test cu inversarea unui singur bit într-o înregistrare scurtă, zlib a detectat o eroare; în aproximativ o treime din cazuri).
Argumente împotriva calculării sumei de control a datelor necomprimate:
- CRC este „adaptat” special pentru puținele erori de biți care sunt caracteristice memoriei flash (o eroare de biți într-un flux comprimat poate provoca o schimbare masivă a fluxului de ieșire, pe care, pur teoretic, putem „prinde” o coliziune);
- Nu prea îmi place ideea de a transmite date potențial rupte la decompresor, cum va reactiona.
În acest proiect, am decis să mă abat de la practica general acceptată de stocare a unei sume de control a datelor necomprimate.
Rezumat: Folosim CRC-32C, calculăm suma de control din datele în forma în care sunt scrise pentru a flash (după compresie).
Redundanţă
Utilizarea codării redundante nu elimină, desigur, pierderea de date, cu toate acestea, poate reduce semnificativ (de multe ori cu multe ordine de mărime) probabilitatea pierderii irecuperabile a datelor.
Putem folosi diferite tipuri de redundanță pentru a corecta erorile.
Codurile Hamming pot corecta erorile pe un singur bit, codurile de caractere Reed-Solomon, copiile multiple ale datelor combinate cu sume de control sau codificări precum RAID-6 pot ajuta la recuperarea datelor chiar și în cazul unei corupții masive.
Inițial, m-am angajat în utilizarea pe scară largă a codării rezistente la erori, dar apoi mi-am dat seama că trebuie mai întâi să avem o idee despre erorile de care vrem să ne protejăm și apoi să alegem codarea.
Am spus mai devreme că erorile trebuie depistate cât mai repede posibil. În ce puncte putem întâlni erori?
- Înregistrare neterminată (din anumite motive în momentul înregistrării, alimentarea a fost oprită, Raspberry a înghețat, ...)
Din păcate, în cazul unei astfel de erori, tot ce rămâne este să ignorați înregistrările nevalide și să considerați datele pierdute; - Erori de scriere (din anumite motive, ceea ce a fost scris în memoria flash nu a fost ceea ce a fost scris)
Putem detecta imediat astfel de erori dacă facem un test citit imediat după înregistrare; - Distorsiunea datelor din memorie în timpul stocării;
- Erori de citire
Pentru a o corecta, dacă suma de control nu se potrivește, este suficient să repeți citirea de mai multe ori.
Adică, numai erorile de al treilea tip (coruperea spontană a datelor în timpul stocării) nu pot fi corectate fără codificare rezistentă la erori. Se pare că astfel de erori sunt încă extrem de puțin probabile.
Rezumat: s-a decis să se abandoneze codificarea redundantă, dar dacă operațiunea arată eroarea acestei decizii, atunci reveniți la examinarea problemei (cu statistici deja acumulate privind eșecurile, ceea ce va permite alegerea tipului optim de codare).
Alții
Desigur, formatul articolului nu ne permite să justificăm fiecare bit din format (și puterea mea s-a terminat deja), așa că voi trece pe scurt peste câteva puncte care nu au fost atinse mai devreme.
- S-a decis ca toate paginile să fie „egale”
Adică nu vor exista pagini speciale cu metadate, fire separate etc., ci în schimb un singur thread care rescrie toate paginile pe rând.
Acest lucru asigură o uzură uniformă a paginilor, niciun punct de eșec unic și pur și simplu îmi place; - Este imperativ să furnizați versiunea formatului.
Un format fără un număr de versiune în antet este rău!
Este suficient să adăugați un câmp cu un anumit număr magic (semnătură) la antetul paginii, care va indica versiunea formatului utilizat (Nu cred că în practică vor fi nici măcar o duzină); - Utilizați un antet cu lungime variabilă pentru înregistrări (dintre care există o mulțime), încercând să îl faceți de 1 octet în majoritatea cazurilor;
- Pentru a codifica lungimea antetului și lungimea părții tăiate a înregistrării comprimate, utilizați coduri binare cu lungime variabilă.
A ajutat mult Codurile Huffman. În doar câteva minute am putut selecta codurile de lungime variabilă necesare.
Descrierea formatului de stocare a datelor
Ordinea octetilor
Câmpurile mai mari de un octet sunt stocate în format big-endian (ordinea octeților de rețea), adică 0x1234 este scris ca 0x12, 0x34.
Paginare
Toată memoria flash este împărțită în pagini de dimensiuni egale.
Dimensiunea implicită a paginii este de 32Kb, dar nu mai mult de 1/4 din dimensiunea totală a cipului de memorie (pentru un cip de 4MB se obțin 128 de pagini).
Fiecare pagină stochează date independent de celelalte (adică datele de pe o pagină nu fac referire la datele de pe altă pagină).
Toate paginile sunt numerotate în ordine naturală (în ordinea crescătoare a adreselor), începând cu numărul 0 (pagina zero începe de la adresa 0, prima pagină începe de la 32Kb, a doua pagină începe de la 64Kb etc.)
Cipul de memorie este folosit ca buffer ciclic (ring buffer), adică mai întâi scrierea merge la pagina numărul 0, apoi numărul 1, ..., când umplem ultima pagină, începe un nou ciclu și înregistrarea continuă de la pagina zero .
În interiorul paginii

La începutul paginii, este stocat un antet de pagină de 4 octeți, apoi o sumă de control antet (CRC-32C), apoi înregistrările sunt stocate în formatul „antet, date, sumă de control”.
Titlul paginii (verde murdar în diagramă) este format din:
- câmp Magic Number de doi octeți (de asemenea, un semn al versiunii de format)
pentru versiunea curentă a formatului se calculează ca0xed00 ⊕ номер страницы; - contor de doi octeți „Versiune pagină” (numărul ciclului de rescriere a memoriei).
Intrările de pe pagină sunt stocate în formă comprimată (se folosește algoritmul de deflare). Toate înregistrările de pe o pagină sunt comprimate într-un singur fir (se folosește un dicționar comun), iar pe fiecare pagină nouă compresia începe din nou. Adică, pentru a decomprima orice înregistrare, sunt necesare toate înregistrările anterioare de pe această pagină (și numai aceasta).
Fiecare înregistrare va fi comprimată cu flag-ul Z_SYNC_FLUSH, iar la sfârșitul fluxului comprimat vor fi 4 octeți 0x00, 0x00, 0xff, 0xff, eventual precedați de încă unul sau doi octeți zero.
Renunțăm la această secvență (cu lungimea de 4, 5 sau 6 octeți) când scriem în memoria flash.
Antetul înregistrării are 1, 2 sau 3 octeți și stochează:
- un bit (T) indicând tipul de înregistrare: 0 - context, 1 - log;
- un câmp de lungime variabilă (S) de la 1 la 7 biți, care definește lungimea antetului și a „cozii” care trebuie adăugate în înregistrare pentru decompresie;
- lungimea înregistrării (L).
Tabel de valori S:
S
Lungimea antetului, octeți
Eliminat la scriere, octet
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Am încercat să ilustrez, nu știu cât de clar a ieșit:
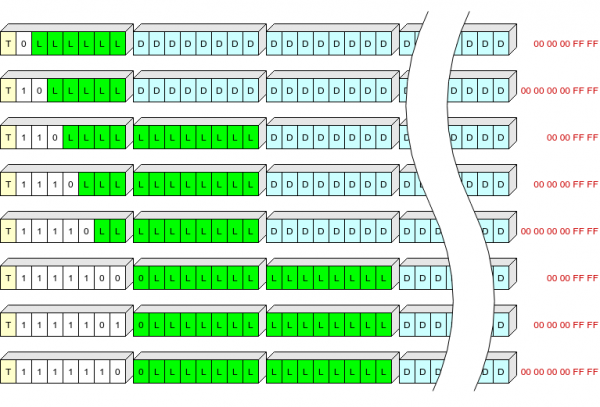
Galbenul indică aici câmpul T, alb câmpul S, verde L (lungimea datelor comprimate în octeți), albastru datele comprimate, roșu octeții finali ai datelor comprimate care nu sunt scrise în memoria flash.
Astfel, putem scrie anteturi de înregistrare de cea mai comună lungime (până la 63+5 octeți în formă comprimată) într-un octet.
După fiecare înregistrare, este stocată o sumă de control CRC-32C, în care valoarea inversată a sumei de control anterioare este utilizată ca valoare inițială (init).
CRC are proprietatea „durată”, următoarea formulă funcționează (plus sau minus inversarea biților în proces):  .
.
Adică, de fapt, calculăm CRC-ul tuturor octeților anteriori de anteturi și date de pe această pagină.
Direct după suma de control este antetul următoarei înregistrări.
Antetul este proiectat în așa fel încât primul său octet să fie întotdeauna diferit de 0x00 și 0xff (dacă în loc de primul octet al antetului întâlnim 0xff, atunci aceasta înseamnă că aceasta este o zonă nefolosită; 0x00 semnalează o eroare).
Exemple de algoritmi
Citirea din memoria flash
Orice citire vine cu o verificare a sumei de control.
Dacă suma de control nu se potrivește, citirea se repetă de mai multe ori în speranța de a citi datele corecte.
(asta are sens, Linux Nu stochează în cache citirile din memoria flash NOR (verificat)
Scrieți în memoria flash
Înregistrăm datele.
Să le citim.
Dacă datele citite nu se potrivesc cu datele scrise, umplem zona cu zerouri și semnalăm o eroare.
Pregătirea unui nou microcircuit pentru funcționare
Pentru inițializare, un antet cu versiunea 1 este scris pe prima pagină (sau mai degrabă zero).
După aceea, contextul inițial este scris pe această pagină (conține UUID-ul mașinii și setările implicite).
Gata, memoria flash este gata de utilizare.
Încărcarea mașinii
La încărcare, sunt citiți primii 8 octeți ai fiecărei pagini (antet + CRC), paginile cu un număr magic necunoscut sau un CRC incorect sunt ignorate.
Din paginile „corecte” sunt selectate pagini cu versiunea maximă, iar din acestea se ia pagina cu cel mai mare număr.
Se citește prima înregistrare, se verifică corectitudinea CRC și prezența steagului „context”. Dacă totul este în regulă, această pagină este considerată actuală. Dacă nu, revenim la cea anterioară până găsim o pagină „live”.
iar pe pagina găsită citim toate înregistrările, cele pe care le folosim cu steag „context”.
Salvați dicționarul zlib (va fi necesar pentru adăugarea la această pagină).
Gata, descărcarea este completă, contextul este restaurat, poți lucra.
Adăugarea unei intrări de jurnal
Comprimăm înregistrarea cu dicționarul corect, specificând Z_SYNC_FLUSH. Vedem dacă înregistrarea comprimată se încadrează în pagina curentă.
Dacă nu se potrivește (sau au existat erori CRC pe pagină), începeți o pagină nouă (vezi mai jos).
Notăm dosarul și CRC. Dacă apare o eroare, porniți o pagină nouă.
Pagina noua
Selectăm o pagină liberă cu numărul minim (considerăm că o pagină liberă este o pagină cu o sumă de control incorectă în antet sau cu o versiune mai mică decât cea actuală). Dacă nu există astfel de pagini, selectați pagina cu numărul minim dintre cele care au o versiune egală cu cea actuală.
Ștergem pagina selectată. Verificăm conținutul cu 0xff. Dacă ceva nu este în regulă, accesați următoarea pagină gratuită etc.
Scriem un antet pe pagina ștearsă, prima intrare este starea curentă a contextului, următoarea este intrarea de jurnal nescrisă (dacă există).
Aplicabilitatea formatului
După părerea mea, s-a dovedit a fi un format bun pentru stocarea oricăror fluxuri de informații mai mult sau mai puțin compresibile (text simplu, JSON, MessagePack, CBOR, eventual protobuf) în NOR Flash.
Desigur, formatul este „personalizat” pentru SLC NOR Flash.
Nu ar trebui utilizat cu medii BER ridicate, cum ar fi NAND sau MLC NOR (este o astfel de memorie chiar disponibila pentru vanzare? Am vazut-o mentionata doar in lucrarile privind codurile de corectare).
Mai mult, nu trebuie folosit cu dispozitive care au propriul FTL: USB flash, SD, MicroSD etc (pentru o astfel de memorie am creat un format cu o dimensiune a paginii de 512 octeți, o semnătură la începutul fiecărei pagini și numere de înregistrare unice - uneori a fost posibil să recuperez toate datele de pe o unitate flash „defecționată” printr-o simplă citire secvențială).
În funcție de sarcini, formatul poate fi utilizat fără modificări pe unitățile flash de la 128Kbit (16Kb) la 1Gbit (128MB). Dacă doriți, îl puteți utiliza pe jetoane mai mari, dar probabil că trebuie să ajustați dimensiunea paginii (Dar aici se pune deja problema fezabilității economice; prețul pentru un volum mare NOR Flash nu este încurajator).
Dacă cineva consideră că formatul este interesant și dorește să-l folosească într-un proiect deschis, scrieți, voi încerca să găsesc timpul, să șlefuiesc codul și să-l postez pe github.
Concluzie
După cum puteți vedea, până la urmă formatul s-a dovedit a fi simplu și chiar plictisitor.
Este dificil să reflectez evoluția punctului meu de vedere într-un articol, dar crede-mă: inițial am vrut să creez ceva sofisticat, indestructibil, capabil să supraviețuiască chiar și unei explozii nucleare în imediata apropiere. Cu toate acestea, rațiunea (sper) a câștigat încă și treptat prioritățile s-au mutat spre simplitate și compactitate.
Poate că am greșit? Da sigur. S-ar putea dovedi, de exemplu, că am achiziționat un lot de microcircuite de calitate scăzută. Sau dintr-un alt motiv, echipamentul nu va îndeplini așteptările de fiabilitate.
Am un plan pentru asta? Cred că după ce ai citit articolul nu ai nicio îndoială că există un plan. Și nici măcar singur.
Într-o notă ceva mai serioasă, formatul a fost dezvoltat atât ca opțiune de lucru, cât și ca „balon de probă”.
În acest moment, totul de pe masă funcționează bine, literalmente zilele trecute soluția va fi implementată (aproximativ) pe sute de dispozitive, să vedem ce se întâmplă în operațiunea „de luptă” (din fericire, sper că formatul vă permite să detectați în mod fiabil eșecurile; astfel încât să puteți colecta statistici complete). În câteva luni se vor putea trage concluzii (și dacă ai ghinion, chiar mai devreme).
Dacă, pe baza rezultatelor utilizării, se descoperă probleme serioase și sunt necesare îmbunătățiri, atunci cu siguranță voi scrie despre asta.
Literatură
Nu am vrut să fac o listă plictisitoare de lucrări folosite, la urma urmei, toată lumea are Google.
Aici am decis să las o listă de constatări care mi s-au părut deosebit de interesante, dar treptat au migrat direct în textul articolului și un articol a rămas pe listă:
- Utilitate de la autorul zlib. Poate afișa clar conținutul arhivelor deflate/zlib/gzip. Dacă aveți de-a face cu structura internă a formatului deflate (sau gzip), vă recomand cu căldură.
Sursa: www.habr.com
