

Se știe că competența CTO este testată abia a doua oară când îndeplinește acest rol. Pentru că un lucru este să lucrezi într-o companie câțiva ani, să evoluezi odată cu ea și, fiind în același context cultural, să primești treptat mai multă responsabilitate. Și e cu totul altceva să ajungi direct în funcția de director tehnic la o companie cu bagaje vechi și o grămadă de probleme măturate cu grijă sub covor.
În acest sens, experiența lui Leon Fire, pe care a împărtășit-o , nu tocmai unic, dar înmulțit de experiența sa și de numărul de roluri diferite pe care a reușit să le încerce de-a lungul a 20 de ani, este foarte util. Sub tăietură se află o cronologie a evenimentelor de peste 90 de zile și o mulțime de povești despre care e distractiv să râzi când i se întâmplă altcuiva, dar care nu sunt atât de distractive de înfruntat în persoană.
Leon vorbește foarte colorat în rusă, așa că dacă aveți 35-40 de minute, vă recomand să vizionați videoclipul. Versiune text pentru a economisi timp mai jos.

Prima versiune a raportului a fost o descriere bine structurată a lucrului cu oamenii și procesele, care conținea recomandări utile. Dar ea nu a transmis toate surprizele care au fost întâlnite pe parcurs. Prin urmare, am schimbat formatul și am prezentat problemele care mi-au apărut ca un jack-in-the-box în noua companie și metodele de rezolvare a acestora în ordine cronologică.
Cu o lună înainte
Ca multe povești bune, aceasta a început cu alcool. Stăteam cu prietenii într-un bar și, așa cum era de așteptat printre specialiștii IT, toată lumea plângea de problemele lor. Unul dintre ei tocmai își schimbase locul de muncă și vorbea despre problemele lui cu tehnologia, cu oamenii și cu echipa. Cu cât ascultam mai mult, cu atât mi-am dat seama că ar trebui doar să mă angajeze, pentru că acestea sunt tipurile de probleme pe care le rezolv în ultimii 15 ani. I-am spus așa, iar a doua zi ne-am întâlnit într-un mediu de lucru. Compania se numea Teaching Strategies.
Teaching Strategies este lider de piață în curriculum pentru copiii foarte mici de la naștere până la vârsta de trei ani. Compania tradițională „de hârtie” are deja 40 de ani, iar versiunea digitală SaaS a platformei are 10 ani Relativ recent, a început procesul de adaptare a tehnologiei digitale la standardele companiei. Versiunea „nouă” a fost lansată în 2017 și era aproape ca cea veche, doar că a funcționat mai rău.
Cel mai interesant lucru este că traficul acestei companii este foarte previzibil - de la o zi la alta, de la an la an, puteți prezice foarte clar câți oameni vor veni și când. De exemplu, între orele 13 și 15 toți copiii din grădinițe se culcă și profesorii încep să introducă informații. Și asta se întâmplă în fiecare zi, mai puțin în weekend, pentru că aproape nimeni nu lucrează în weekend.
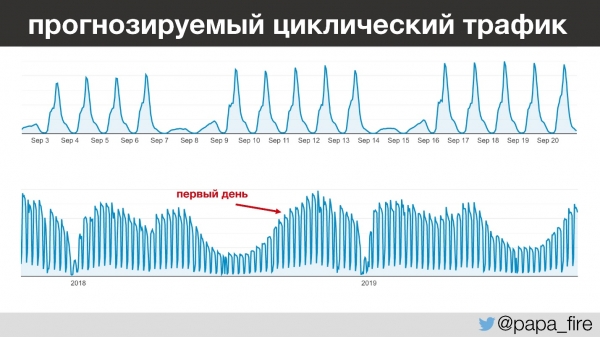
Privind puțin în viitor, voi observa că mi-am început munca în perioada cu cel mai mare trafic anual, ceea ce este interesant din diverse motive.
Platforma, care părea să aibă doar 2 ani, avea o stivă deosebită: ColdFusion & SQL Server din 2008. ColdFusion, dacă nu știi, și cel mai probabil nu știi, este o întreprindere PHP care a apărut la mijlocul anilor 90 și de atunci nici nu am mai auzit de el. Au mai fost: Ruby, MySQL, PostgreSQL, Java, Go, Python. Dar monolitul principal a funcționat pe ColdFusion și SQL Server.
Probleme
Cu cât vorbeam mai mult cu angajații companiei despre muncă și despre ce probleme au fost întâmpinate, cu atât mi-am dat seama că problemele nu erau doar de natură tehnică. Bine, tehnologia este veche - și nu au lucrat la ea, dar au existat probleme cu echipa și cu procesele, iar compania a început să înțeleagă acest lucru.
În mod tradițional, tehnicienii lor stăteau în colț și făceau un fel de muncă. Dar tot mai multe afaceri au început să treacă prin versiunea digitală. Prin urmare, în ultimul an înainte de a începe să lucrez, în companie au apărut altele noi: consiliu de administrație, director CTO, CPO și QA. Adică, compania a început să investească în sectorul tehnologiei.
Urmele unei moșteniri grele nu erau doar în sisteme. Compania a avut procese moștenite, oameni moșteniți, cultură moștenită. Toate acestea trebuiau schimbate. M-am gândit că cu siguranță nu va fi plictisitor și am decis să încerc.
Cu două zile înainte
Cu două zile înainte de a începe un nou loc de muncă, am ajuns la birou, am completat ultimele documente, am întâlnit echipa și am descoperit că echipa se confrunta cu o problemă în acel moment. A fost că timpul mediu de încărcare a paginii a sărit la 4 secunde, adică de 2 ori.
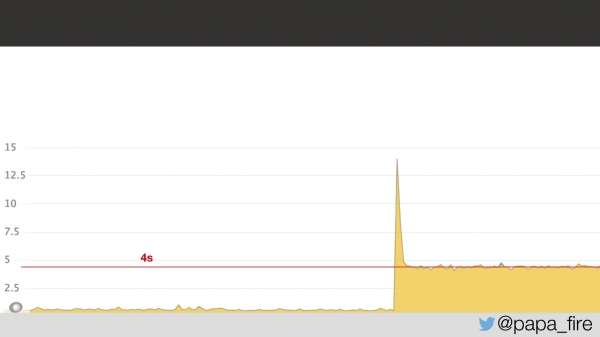
Judecând după grafic, ceva s-a întâmplat în mod clar și nu este clar ce. S-a dovedit că problema era latența rețelei în centrul de date: latența de 5 ms în centrul de date s-a transformat în 2 s pentru utilizatori. Nu știam de ce s-a întâmplat acest lucru, dar în orice caz s-a știut că problema era în centrul de date.
O zi
Au trecut două zile și în prima mea zi de muncă am descoperit că problema nu a dispărut.
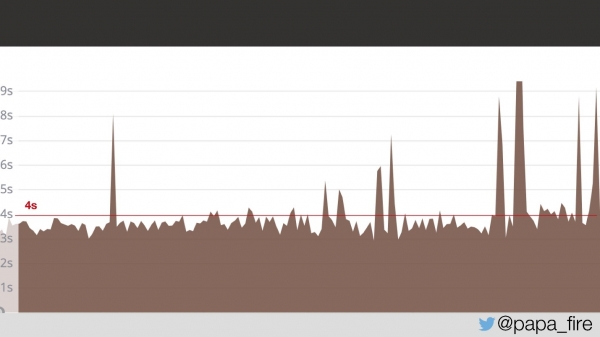
Timp de două zile, paginile utilizatorilor s-au încărcat în medie în 4 secunde. Întreb dacă au găsit care este problema.
- Da, am deschis un bilet.
- și?
- Ei bine, încă nu ne-au răspuns.
Apoi mi-am dat seama că tot ceea ce mi s-a spus înainte era doar un mic vârf al aisbergului cu care trebuia să mă lupt.
Există un citat bun care se potrivește foarte bine cu asta:
„Uneori, pentru a schimba tehnologia, trebuie să schimbați organizația.”
Dar, din moment ce am început să lucrez în cea mai aglomerată perioadă a anului, a trebuit să mă uit la ambele opțiuni de rezolvare a problemei: atât rapid, cât și pe termen lung. Și începe cu ceea ce este critic acum.
Ziua a treia
Deci, încărcarea durează 4 secunde, iar de la 13 la 15 cele mai mari vârfuri.
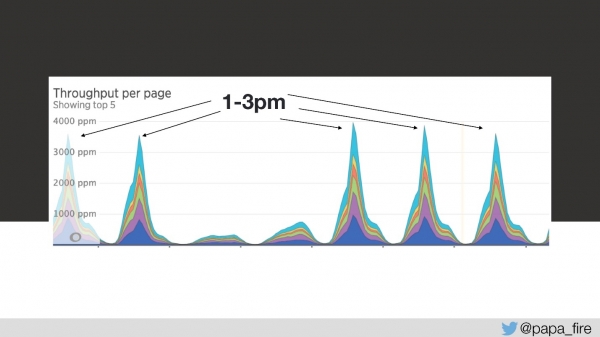
În a treia zi din această perioadă de timp, viteza de descărcare a arătat astfel:
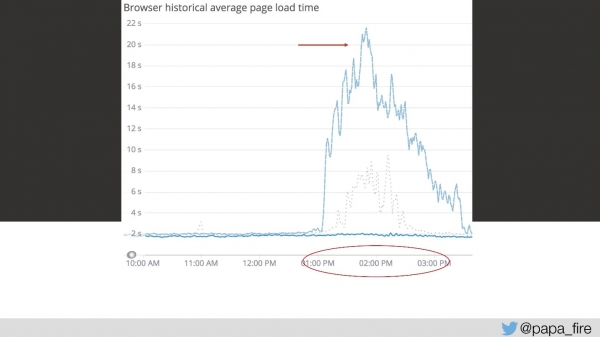
Din punctul meu de vedere, nimic nu a funcționat. Din punctul de vedere al tuturor, mergea puțin mai încet decât de obicei. Dar pur și simplu nu se întâmplă așa - este o problemă serioasă.
Am încercat să conving echipa, la care au răspuns că pur și simplu au nevoie de mai multe servere. Aceasta, desigur, este o soluție la problemă, dar nu este întotdeauna singura și cea mai eficientă. Am întrebat de ce nu sunt suficiente servere, care a fost volumul de trafic. Am extrapolat datele și am constatat că avem aproximativ 150 de solicitări pe secundă, ceea ce, în principiu, se încadrează în limite rezonabile.
Dar nu trebuie să uităm că înainte de a obține răspunsul corect, trebuie să pui întrebarea potrivită. Următoarea mea întrebare a fost: câte servere frontend avem? Răspunsul „m-a derutat puțin” - aveam 17 servere frontend!
— Îmi este rușine să întreb, dar 150 împărțit la 17 dă aproximativ 8? Vrei să spui că fiecare server permite 8 cereri pe secundă, iar dacă mâine sunt 160 de solicitări pe secundă, vom avea nevoie de încă 2 servere?
Desigur, nu am avut nevoie de servere suplimentare. Soluția a fost în codul în sine și la suprafață:
var currentClass = classes.getCurrentClass();
return currentClass; A existat o funcție getCurrentClass(), pentru că totul de pe site funcționează în contextul unei clase - așa este. Și pentru această funcție pe fiecare pagină au existat Peste 200 de cereri.
Soluția în acest fel a fost foarte simplă, nici nu trebuia să rescrieți nimic: doar nu mai cere aceleași informații.
if ( !isDefined("REQUEST.currentClass") ) {
var classes = new api.private.classes.base();
REQUEST.currentClass = classes.getCurrentClass();
}
return REQUEST.currentClass;Am fost foarte fericit pentru că am decis că abia a treia zi am găsit principala problemă. Oricât de naiv am fost, aceasta a fost doar una dintre multele probleme.
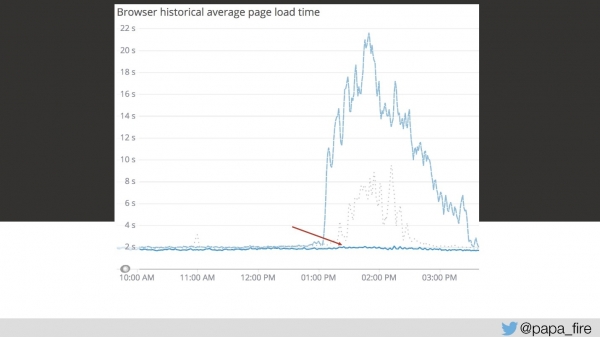
Dar rezolvarea acestei prime probleme a scăzut graficul mult mai jos.
În același timp, făceam și alte optimizări. Erau multe lucruri la vedere care puteau fi reparate. De exemplu, în aceeași a treia zi am descoperit că până la urmă există un cache în sistem (la început am crezut că toate cererile vin direct din baza de date). Când mă gândesc la un cache, mă gândesc la standard Redis sau Memcached. Dar eu am fost singurul care a crezut așa, pentru că acel sistem folosea MongoDB și SQL Server pentru cache - același din care tocmai au fost citite datele.
Ziua zece
Prima săptămână m-am ocupat de probleme care trebuiau rezolvate chiar acum. Undeva în a doua săptămână, am venit pentru prima dată la stand-up pentru a comunica cu echipa, pentru a vedea ce se întâmplă și cum decurge întregul proces.
S-a descoperit din nou ceva interesant. Echipa a fost formată din: 18 dezvoltatori; 8 testere; 3 manageri; 2 arhitecti. Și toți au participat la ritualuri comune, adică peste 30 de oameni veneau la stand-up în fiecare dimineață și spuneau ce au făcut. Este clar că întâlnirea nu a durat 5 sau 15 minute. Nimeni nu a ascultat de nimeni pentru că toată lumea lucrează pe sisteme diferite. În această formă, 2-3 bilete pe oră pentru o ședință de îngrijire a fost deja un rezultat bun.
Primul lucru pe care l-am făcut a fost împărțirea echipei în mai multe linii de produse. Pentru diferite secțiuni și sisteme, am alocat echipe separate, care au inclus dezvoltatori, testeri, manageri de produs și analiști de afaceri.
Ca rezultat am obtinut:
- Reducerea stand-up-urilor și mitingurilor.
- Cunoașterea subiectului despre produs.
- Un sentiment de proprietate. Când oamenii obișnuiau să joace cu sistemele tot timpul, știau că cel mai probabil altcineva va trebui să lucreze cu erorile lor, dar nu ei înșiși.
- Colaborarea între grupuri. Inutil să spun că QA nu a comunicat prea mult cu programatorii înainte, produsul și-a făcut propriul lucru etc. Acum au un punct comun de responsabilitate.
Ne-am concentrat în principal pe eficiență, productivitate și calitate - acestea sunt problemele pe care am încercat să le rezolvăm odată cu transformarea echipei.
Ziua unsprezece
În procesul de schimbare a structurii echipei, am descoperit cum să număr PovestePuncte. 1 SP era egal cu o zi și fiecare bilet conținea SP atât pentru dezvoltare, cât și pentru QA, adică cel puțin 2 SP.
Cum am descoperit asta?
Am găsit o eroare: într-unul dintre rapoarte, unde este trecută data de început și de sfârșit a perioadei pentru care este necesar raportul, nu se ia în calcul ultima zi. Adică undeva în cerere nu era <=, ci pur și simplu <. Mi s-a spus că acestea sunt trei Story Points, adică 3 zile.
După aceasta noi:
- Sistemul de rating Story Points a fost revizuit. Acum, remediile pentru erori minore care pot fi trecute rapid prin sistem ajung mai repede la utilizator.
- Am început să îmbinăm biletele aferente pentru dezvoltare și testare. Anterior, fiecare bilet, fiecare bug era un ecosistem închis, nelegat de nimic altceva. Schimbarea a trei butoane pe o pagină ar fi putut fi trei bilete diferite cu trei procese diferite de QA în loc de un test automat pe pagină.
- Am început să lucrăm cu dezvoltatorii la o abordare a estimării costurilor cu forța de muncă. Trei zile pentru a schimba un buton nu este amuzant.
Ziua a douăzecea
Undeva la mijlocul primei luni, situația s-a stabilizat puțin, mi-am dat seama ce se întâmplă practic și am început deja să privesc în viitor și să mă gândesc la soluții pe termen lung.
Obiective pe termen lung:
- Platformă gestionată. Sute de solicitări pe fiecare pagină nu sunt serioase.
- Tendințe previzibile. Au existat vârfuri periodice de trafic care, la prima vedere, nu s-au corelat cu alte valori - trebuia să înțelegem de ce s-a întâmplat acest lucru și să învățăm să prezicem.
- Extinderea platformei. Afacerea este în continuă creștere, vin din ce în ce mai mulți utilizatori, iar traficul crește.
În trecut se spunea adesea: „Să rescriem totul în [limbă/cadru], totul va funcționa mai bine!”
În cele mai multe cazuri, acest lucru nu funcționează, este bine dacă rescrierea funcționează deloc. Prin urmare, trebuia să creăm o foaie de parcurs - o strategie specifică care să ilustreze pas cu pas cum vor fi atinse obiectivele de afaceri (ce vom face și de ce), care:
- reflectă misiunea și obiectivele proiectului;
- prioritizează obiectivele principale;
- conţine un program de realizare a acestora.
Înainte de aceasta, nimeni nu a vorbit cu echipa despre scopul oricăror modificări. Acest lucru necesită valorile corecte de succes. Pentru prima dată în istoria companiei, am stabilit KPI-uri pentru grupul tehnic, iar acești indicatori au fost legați de cei organizaționali.
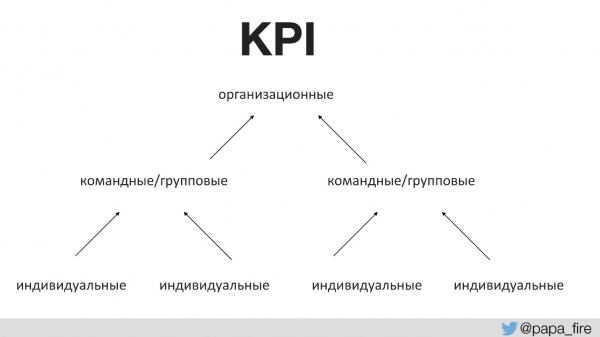
Adică, KPI-urile organizaționale sunt susținute de echipe, iar KPI-urile de echipă sunt susținute de KPI-urile individuale. În caz contrar, dacă KPI-urile tehnologice nu coincid cu cele organizaționale, atunci toată lumea își trage pătura.
De exemplu, unul dintre KPI-urile organizaționale crește cota de piață prin produse noi.
Cum puteți susține obiectivul de a avea mai multe produse noi?
- În primul rând, dorim să petrecem mai mult timp dezvoltării de produse noi în loc să remediem defectele. Aceasta este o soluție logică care este ușor de măsurat.
- În al doilea rând, dorim să susținem o creștere a volumului tranzacțiilor, deoarece cu cât este mai mare cota de piață, cu atât mai mulți utilizatori și, în consecință, cu atât mai mult trafic.
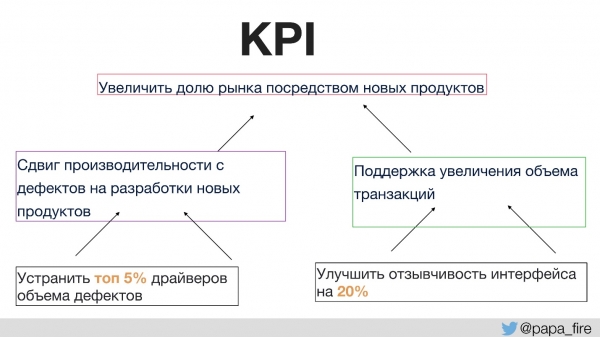
Apoi KPI-urile individuale care pot fi executate în cadrul grupului vor fi, de exemplu, în locul de unde provin principalele defecte. Dacă vă concentrați în mod special pe această secțiune, vă puteți asigura că există mult mai puține defecte, iar apoi timpul pentru dezvoltarea de noi produse și din nou pentru susținerea KPI-urilor organizaționale va crește.
Astfel, fiecare decizie, inclusiv rescrierea codului, trebuie să susțină obiectivele specifice pe care compania ni le-a stabilit (creștere organizațională, funcții noi, recrutare).
În timpul acestui proces a ieșit la iveală un lucru interesant, care a devenit o știre nu doar pentru tehnicieni, ci în general în companie: toate biletele trebuie să fie concentrate pe cel puțin un KPI. Adică, dacă un produs spune că dorește să creeze o funcție nouă, ar trebui pusă prima întrebare: „Ce KPI acceptă această caracteristică?” Dacă nu, atunci îmi pare rău - pare o caracteristică inutilă.
Ziua treizeci
La sfârșitul lunii, am descoperit o altă nuanță: nimeni din echipa mea de operațiuni nu a văzut vreodată contractele pe care le încheiem cu clienții. Puteți întreba de ce trebuie să vedeți contacte.
- În primul rând, pentru că SLA-urile sunt specificate în contracte.
- În al doilea rând, SLA-urile sunt toate diferite. Fiecare client a venit cu propriile cerințe, iar departamentul de vânzări a semnat fără să se uite.
O altă nuanță interesantă este că contractul cu unul dintre cei mai mari clienți prevede că toate versiunile de software suportate de platformă trebuie să fie n-1, adică nu cea mai recentă versiune, ci penultima.
Este clar cât de departe eram de n-1 dacă platforma se baza pe ColdFusion și SQL Server 2008, care nu mai era deloc suportat în iulie.
Ziua patruzeci și cinci
Pe la mijlocul celei de-a doua luni am avut suficient timp să mă așez și să fac valoarecurentcartografiere complet pentru întregul proces. Aceștia sunt pașii necesari care trebuie făcuți, de la crearea unui produs până la livrarea acestuia către consumator și trebuie descriși cât mai detaliat posibil.
Împărțiți procesul în bucăți mici și vedeți ce necesită prea mult timp, ce poate fi optimizat, îmbunătățit etc. De exemplu, cât durează pentru ca o solicitare de produs să treacă prin îngrijire, când ajunge la un bilet pe care îl poate lua un dezvoltator, QA etc. Deci, vă uitați la fiecare pas individual în detaliu și vă gândiți la ceea ce poate fi optimizat.
Când am făcut asta, două lucruri mi-au atras atenția:
- procent mare de bilete returnate de la QA înapoi dezvoltatorilor;
- Evaluările cererilor de tragere au durat prea mult.
Problema a fost că acestea au fost concluzii de genul: pare să ia mult timp, dar nu suntem siguri cât timp.
„Nu poți îmbunătăți ceea ce nu poți măsura”.
Cum să justifice cât de gravă este problema? Pierde zile sau ore?
Pentru a măsura acest lucru, am adăugat câțiva pași la procesul Jira: „gata pentru dezvoltare” și „gata pentru QA” pentru a măsura cât timp așteaptă fiecare bilet și de câte ori revine la un anumit pas.
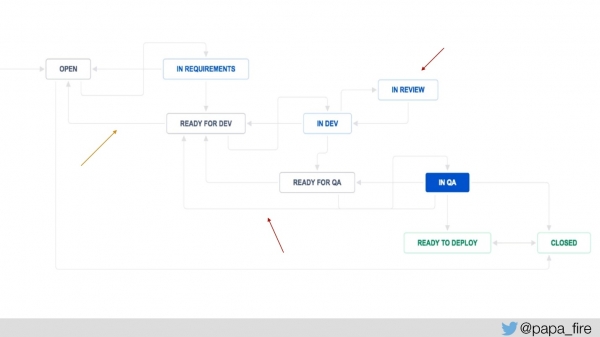
Am adăugat, de asemenea, „în revizuire” pentru a ști câte bilete sunt în medie pentru revizuire, iar din aceasta puteți începe să dansați. Aveam valori de sistem, acum am adăugat noi valori și am început să măsurăm:
- Eficiența procesului: performanță și planificată/livrată.
- Calitatea procesului: numărul de defecte, defecte de la QA.
Chiar ajută să înțelegeți ce merge bine și ce nu merge bine.
Ziua a cincea
Toate acestea sunt, desigur, bune și interesante, dar spre sfârșitul celei de-a doua luni s-a întâmplat ceva care, în principiu, era previzibil, deși nu mă așteptam la o asemenea amploare. Oamenii au început să plece pentru că top managementul se schimbase. Oameni noi au intrat în conducere și au început să schimbe totul, iar cei vechi au renunțat. Și, de obicei, într-o companie care are câțiva ani, toată lumea este prieteni și toată lumea se cunoaște.
Acest lucru era de așteptat, dar amploarea disponibilizărilor a fost neașteptată. De exemplu, într-o săptămână doi lideri de echipă și-au depus simultan demisia din proprie voință. Prin urmare, a trebuit nu numai să uit de alte probleme, dar să mă concentrez asupra crearea unei echipe. Aceasta este o problemă lungă și greu de rezolvat, dar a trebuit să fie rezolvată pentru că am vrut să salvez oamenii care au rămas (sau pe cei mai mulți dintre ei). A fost necesar să reacționăm cumva la faptul că oamenii au plecat pentru a menține moralul în echipă.
În teorie, acest lucru este bine: vine o persoană nouă care are carte albă completă, care poate evalua abilitățile echipei și poate înlocui personalul. De fapt, nu poți să aduci oameni noi din atâtea motive. Întotdeauna ai nevoie de echilibru.
- Vechi și nou. Trebuie să păstrăm bătrânii care pot schimba și sprijini misiunea. Dar, în același timp, trebuie să aducem sânge nou, despre asta vom vorbi puțin mai târziu.
- Experienţă. Am vorbit mult cu juniori buni care erau dornici și doreau să lucreze cu noi. Dar nu i-am putut prelua pentru că nu erau destui seniori care să-i susțină pe juniori și să acționeze ca mentori pentru ei. A fost necesar să recrutăm mai întâi vârful și abia apoi tineretul.
- Morcov si bat.
Nu am un răspuns bun la întrebarea care este echilibrul corect, cum să-l mențin, câți oameni să păstrez și cât de mult să împinge. Acesta este un proces pur individual.
Ziua cincizeci și unu
Am început să mă uit atent la echipă pentru a înțelege cine am și mi-am amintit încă o dată:
„Majoritatea problemelor sunt probleme ale oamenilor.”
Am descoperit că echipa ca atare - atât Dev cât și Ops - are trei mari probleme:
- Satisfacția față de starea actuală a lucrurilor.
- Lipsa de responsabilitate - pentru că nimeni nu a adus niciodată rezultatele muncii interpreților pentru a influența afacerea.
- Frica de schimbare.

Schimbarea te scoate întotdeauna din zona ta de confort și, cu cât oamenii sunt mai tineri, cu atât le displace mai mult schimbarea pentru că nu înțeleg de ce și nu înțeleg cum. Cel mai frecvent răspuns pe care l-am auzit este: „Nu am făcut niciodată asta”. Mai mult, s-a ajuns la o absurditate totală – cele mai mici schimbări nu puteau avea loc fără ca cineva să fie indignat. Și oricât de mult le-au afectat schimbările munca, oamenii au spus: „Nu, de ce? Acest lucru nu va funcționa.”
Dar nu te poți îmbunătăți fără să schimbi nimic.
Am avut o conversație absolut absurdă cu un angajat, i-am spus ideile mele de optimizare, la care mi-a spus:
- Oh, n-ai văzut ce am avut anul trecut!
- Și ce dacă?
„Acum este mult mai bine decât era.”
- Deci, nu se poate mai bine?
- Pentru ce?
Bună întrebare - de ce? Este ca și cum acum este mai bine decât a fost, atunci totul este suficient de bun. Acest lucru duce la o lipsă de responsabilitate, ceea ce este absolut normal în principiu. După cum spuneam, grupul tehnic a fost puțin pe margine. Compania credea că ar trebui să existe, dar nimeni nu a stabilit niciodată standardele. Asistența tehnică nu a văzut niciodată SLA, așa că a fost destul de „acceptabil” pentru grup (și acest lucru m-a frapat cel mai mult):
- 12 secunde de încărcare;
- 5-10 minute de oprire pentru fiecare lansare;
- Depanarea problemelor critice durează zile și săptămâni;
- lipsa personalului de serviciu 24x7 / de gardă.
Nimeni nu a încercat vreodată să ne întrebe de ce nu o facem mai bine și nimeni nu și-a dat seama vreodată că nu trebuie să fie așa.
Ca bonus, a mai fost o problemă: lipsa de experienta. Seniorii au plecat, iar echipa tânără rămasă a crescut sub regimul anterior și a fost otrăvită de acesta.
Pe lângă toate acestea, oamenilor le era și frică să nu eșueze și să pară incompetenți. Acest lucru se exprimă prin faptul că, în primul rând, ei sub nicio formă nu a cerut ajutor. De câte ori am vorbit în grup și individual, iar eu am spus: „Pune o întrebare dacă nu știi cum să faci ceva”. Am încredere în mine și știu că pot rezolva orice problemă, dar va dura timp. Prin urmare, dacă pot întreba pe cineva care știe să rezolve în 10 minute, o să întreb. Cu cât ai mai puțină experiență, cu atât îți este mai frică să întrebi pentru că crezi că vei fi considerat incompetent.
Această teamă de a pune întrebări se manifestă în moduri interesante. De exemplu, întrebați: „Ce mai faceți cu această sarcină?” - „Au mai rămas câteva ore, deja am terminat.” A doua zi întrebi din nou, primești răspunsul că totul este în regulă, dar a fost o problemă, cu siguranță va fi gata până la sfârșitul zilei. Mai trece o zi și până când ești prins de perete și forțat să vorbești cu cineva, asta continuă. O persoană vrea să rezolve singură o problemă, crede că dacă nu o rezolvă singur, va fi un mare eșec.
De asta dezvoltatorii au umflat estimările. Era aceeași anecdotă, când discutau despre o anumită sarcină, mi-au dat o asemenea cifră încât am fost foarte surprins. La care mi s-a spus că în devizele dezvoltatorului, dezvoltatorul include timpul în care biletul va fi returnat de la QA, pentru că acolo vor găsi erori, și timpul pe care îl va lua PR și timpul în care oamenii care ar trebui să revizuiască va fi ocupat - adică totul, orice este posibil.
În al doilea rând, oamenii cărora le este frică să nu pară incompetenți supraanaliza. Când spui ce trebuie făcut exact, începe: „Nu, ce se întâmplă dacă ne gândim la asta aici?” În acest sens, compania noastră nu este unică, aceasta este o problemă standard pentru tineri.
Ca răspuns, am introdus următoarele practici:
- Regula 30 de minute. Dacă nu puteți rezolva problema în jumătate de oră, cereți ajutor pe cineva. Acest lucru funcționează cu diferite grade de succes, deoarece oamenii încă nu întreabă, dar cel puțin procesul a început.
- Eliminați totul, în afară de esența, în estimarea termenului limită pentru finalizarea unei sarcini, adică luați în considerare doar cât timp va dura scrierea codului.
- Învățare continuă pentru cei care supraanalizează. Este doar o muncă constantă cu oamenii.
Ziua a șasecea
În timp ce făceam toate acestea, era timpul să-mi dau seama de buget. Desigur, am găsit o mulțime de lucruri interesante în locul în care ne-am cheltuit banii. De exemplu, am avut un întreg rack într-un centru de date separat cu un server FTP, care a fost folosit de un client. S-a dovedit că „... ne-am mutat, dar el a rămas așa, nu l-am schimbat”. A fost acum 2 ani.
Un interes deosebit a fost factura pentru serviciile cloud. Cred că principalul motiv pentru factura de cloud mare este dezvoltatorii care au acces nelimitat la servere pentru prima dată în viața lor. Nu trebuie să întrebe: „Vă rog să-mi dați un server de testare”, ei îl pot lua singuri. În plus, dezvoltatorii vor întotdeauna să construiască un sistem atât de cool, încât Facebook și Netflix vor fi gelosi.
Dar dezvoltatorii nu au experiență în achiziționarea de servere și priceperea de a determina dimensiunea necesară a serverelor, deoarece nu aveau nevoie de ea înainte. Și de obicei nu prea înțeleg diferența dintre scalabilitate și performanță.
Rezultatele inventarului:
- Am părăsit același centru de date.
- Am reziliat contractul cu 3 servicii de jurnal. Pentru că am avut 5 dintre ele - fiecare dezvoltator care a început să se joace cu ceva a luat unul nou.
- 7 sisteme AWS au fost oprite. Din nou, nimeni nu a oprit proiectele moarte, toți au continuat să lucreze.
- Costurile software reduse de 6 ori.
Ziua șaptezeci și cinci
Timpul a trecut, iar în două luni și jumătate a trebuit să mă întâlnesc cu consiliul de administrație. Consiliul nostru de administrație nu este mai bun sau mai rău decât alții, ca toate consiliile de administrație, vrea să știe totul; Oamenii investesc bani și vor să înțeleagă cât de mult se potrivește ceea ce facem în KPI-urile setate.
Consiliul de administrație primește o mulțime de informații în fiecare lună: numărul de utilizatori, creșterea acestora, ce servicii folosesc și cum, performanță și productivitate și, în final, viteza medie de încărcare a paginii.
Singura problemă este că eu cred că media este răul pur. Dar este foarte greu să explici acest lucru consiliului de administrație. Ei sunt obișnuiți să opereze cu numere agregate și nu, de exemplu, cu răspândirea timpilor de încărcare pe secundă.
Au fost câteva puncte interesante în acest sens. De exemplu, am spus că trebuie să împărțim traficul între servere web separate, în funcție de tipul de conținut.

Adică, ColdFusion trece prin Jetty și nginx și lansează paginile. Iar imaginile, JS și CSS trec printr-un nginx separat cu propriile lor configurații. Aceasta este o practică destul de standard despre care vorbesc acum cativa ani. Drept urmare, imaginile se încarcă mult mai repede și... viteza medie de încărcare a crescut cu 200 ms.
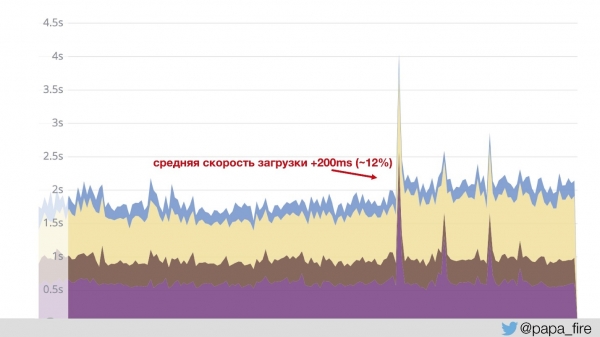
Acest lucru s-a întâmplat deoarece graficul este construit pe baza datelor care vin cu Jetty. Adică, conținutul rapid nu este inclus în calcul - valoarea medie a crescut. Acest lucru ne-a fost clar, am râs, dar cum să explicăm consiliului de administrație de ce am făcut ceva și a devenit cu 12% mai rău?
Ziua optzeci și cinci
La sfârșitul celei de-a treia luni, mi-am dat seama că era un lucru pe care nu mă bazasem deloc: timpul. Tot ce am vorbit necesită timp.

Acesta este adevăratul meu calendar săptămânal - doar o săptămână de lucru, nu foarte ocupată. Nu este timp suficient pentru toate. Prin urmare, din nou, trebuie să recrutați oameni care vă vor ajuta să faceți față problemelor.
Concluzie
Asta nu e tot. În această poveste, nici nu am ajuns la modul în care am lucrat cu produsul și am încercat să ne acordăm la valul general, sau cum am integrat suportul tehnic sau cum am rezolvat alte probleme tehnice. De exemplu, am aflat destul de întâmplător că pe cele mai mari tabele din baza de date nu folosim SEQUENCE. Avem o funcție auto-scrisă nextID, și nu este utilizat într-o tranzacție.
Au mai fost un milion de lucruri similare despre care am putea vorbi mult timp. Dar cel mai important lucru care mai trebuie spus este cultura.

Cultura sau lipsa acesteia este cea care duce la toate celelalte probleme. Încercăm să construim o cultură în care oamenii:
- nu vă fie frică de eșecuri;
- invata din greseli;
- colaborează cu alte echipe;
- ia initiativa;
- asume responsabilitatea;
- salută rezultatul ca obiectiv;
- sărbătorind succesul.
Cu asta va veni totul.
Leon Fire , și .
Există două strategii în ceea ce privește moștenirea: evitați să lucrați cu ea cu orice preț sau depășiți cu curaj dificultățile asociate. Noi c Luăm a doua cale, schimbând procesele și abordările. Alatura-te noua , и și împreună vom implementa o cultură DevOps.
Sursa: www.habr.com
