

În acest articol, voi vorbi despre modul în care proiectul la care lucrez s-a transformat dintr-un monolit mare într-un set de microservicii.
Proiectul și-a început istoria cu destul de mult timp în urmă, la începutul anului 2000. Primele versiuni au fost scrise în Visual Basic 6. De-a lungul timpului, a devenit clar că dezvoltarea în acest limbaj va fi greu de susținut în viitor, deoarece IDE-ul iar limba în sine este slab dezvoltată. La sfârșitul anilor 2000, s-a decis trecerea la C# mai promițător. Noua versiune a fost scrisă în paralel cu revizuirea celei vechi, treptat s-a scris tot mai mult cod în .NET. Backend-ul în C# s-a concentrat inițial pe o arhitectură de servicii, dar în timpul dezvoltării, au fost utilizate biblioteci comune cu logică, iar serviciile au fost lansate într-un singur proces. Rezultatul a fost o aplicație pe care am numit-o „monolit de serviciu”.
Unul dintre puținele avantaje ale acestei combinații a fost capacitatea serviciilor de a se apela între ele printr-un API extern. Existau premise clare pentru tranziția la un serviciu mai corect și, în viitor, o arhitectură de microservicii.
Ne-am început munca de descompunere în jurul anului 2015. Încă nu am ajuns la o stare ideală - mai există părți dintr-un proiect mare care cu greu pot fi numite monoliți, dar nici nu arată ca niște microservicii. Cu toate acestea, progresul este semnificativ.
Voi vorbi despre asta în articol.
Conținut
Arhitectura și problemele soluției existente
Inițial, arhitectura arăta astfel: UI este o aplicație separată, partea monolitică este scrisă în Visual Basic 6, aplicația .NET este un set de servicii conexe care lucrează cu o bază de date destul de mare.
Dezavantajele soluției anterioare
Un singur punct de eșec
Am avut un singur punct de eșec: aplicația .NET a rulat într-un singur proces. Dacă vreun modul a eșuat, întreaga aplicație a eșuat și a trebuit să fie repornită. Deoarece automatizăm un număr mare de procese pentru diferiți utilizatori, din cauza unei defecțiuni la unul dintre aceștia, toată lumea nu a putut lucra de ceva timp. Și în cazul unei erori de software, nici măcar backup-ul nu a ajutat.
Coada de îmbunătățiri
Acest dezavantaj este mai degrabă organizatoric. Aplicația noastră are mulți clienți și toți doresc să o îmbunătățească cât mai curând posibil. Anterior, era imposibil să se facă acest lucru în paralel și toți clienții stăteau la coadă. Acest proces a fost negativ pentru companii, deoarece trebuiau să demonstreze că sarcina lor era valoroasă. Și echipa de dezvoltare a petrecut timp organizând această coadă. Acest lucru a durat mult timp și efort, iar produsul nu s-a putut schimba atât de repede pe cât și-ar fi dorit.
Utilizarea suboptimă a resurselor
Când găzduim servicii într-un singur proces, am copiat întotdeauna complet configurația de la server la server. Ne-am dorit să plasăm separat serviciile cele mai încărcate, pentru a nu risipi resurse și pentru a obține un control mai flexibil asupra schemei noastre de implementare.
Greu de implementat tehnologii moderne
O problemă familiară tuturor dezvoltatorilor: există dorința de a introduce tehnologii moderne în proiect, dar nu există nicio oportunitate. Cu o soluție monolitică mare, orice actualizare a bibliotecii actuale, ca să nu mai vorbim de trecerea la una nouă, se transformă într-o sarcină destul de nebanală. Este nevoie de mult timp pentru a-i demonstra liderului echipei că acest lucru va aduce mai multe bonusuri decât nervi irositi.
Dificultate la emiterea modificărilor
Aceasta a fost cea mai serioasă problemă - lansam lansări la fiecare două luni.
Fiecare lansare s-a transformat într-un adevărat dezastru pentru bancă, în ciuda testării și eforturilor dezvoltatorilor. Afacerea a înțeles că la începutul săptămânii unele dintre funcționalitățile sale nu vor funcționa. Iar dezvoltatorii au înțeles că îi așteaptă o săptămână de incidente grave.
Toată lumea avea dorința de a schimba situația.
Așteptări de la microservicii
Eliberarea componentelor când sunt gata. Livrarea componentelor când sunt gata prin descompunerea soluției și separarea diferitelor procese.
Echipe mici de produs. Acest lucru este important deoarece o echipă mare care lucra la vechiul monolit a fost dificil de gestionat. O astfel de echipă a fost nevoită să lucreze după un proces strict, dar își dorea mai multă creativitate și independență. Doar echipele mici își puteau permite asta.
Izolarea serviciilor în procese separate. În mod ideal, aș dori să îl izolez în containere, dar un număr mare de servicii scrise în .NET Framework rulează doar sub WindowsServiciile bazate pe .NET Core apar acum, dar există încă puține.
Flexibilitatea implementării. Am dori să combinăm serviciile așa cum avem nevoie, și nu așa cum le forțează codul.
Utilizarea noilor tehnologii. Acest lucru este interesant pentru orice programator.
Probleme de tranziție
Desigur, dacă ar fi ușor să spargi un monolit în microservicii, nu ar fi nevoie să vorbim despre asta la conferințe și să scriem articole. Există multe capcane în acest proces; voi descrie principalele care ne-au împiedicat.
Prima problemă tipic pentru majoritatea monoliților: coerența logicii de afaceri. Când scriem un monolit, vrem să ne refolosim clasele pentru a nu scrie cod inutil. Și atunci când treceți la microservicii, aceasta devine o problemă: tot codul este destul de strâns cuplat și este dificil să separați serviciile.
La momentul începerii lucrărilor, depozitul avea peste 500 de proiecte și peste 700 de mii de linii de cod. Aceasta este o decizie destul de mare și a doua problema. Nu a fost posibil să o luați pur și simplu și să o împărțiți în microservicii.
A treia problemă — lipsa infrastructurii necesare. De fapt, copiam manual codul sursă pe servere.
Cum să treceți de la monolit la microservicii
Furnizarea de microservicii
În primul rând, am stabilit imediat pentru noi înșine că separarea microserviciilor este un proces iterativ. Ni s-a cerut întotdeauna să dezvoltăm probleme de afaceri în paralel. Modul în care vom implementa acest lucru din punct de vedere tehnic este deja problema noastră. Prin urmare, ne-am pregătit pentru un proces iterativ. Nu va funcționa altfel dacă aveți o aplicație mare și nu este inițial gata să fie rescrisă.
Ce metode folosim pentru a izola microservicii?
Prima cale — mutați modulele existente ca servicii. În acest sens, am avut noroc: existau deja servicii înregistrate care funcționau folosind protocolul WCF. Au fost despărțiți în ansambluri separate. Le-am portat separat, adăugând un mic lansator la fiecare build. A fost scris folosind minunata bibliotecă Topshelf, care vă permite să rulați aplicația atât ca serviciu, cât și ca consolă. Acest lucru este convenabil pentru depanare, deoarece nu sunt necesare proiecte suplimentare în soluție.
Serviciile au fost conectate conform logicii de business, deoarece foloseau ansambluri comune și lucrau cu o bază de date comună. Cu greu ar putea fi numite microservicii în forma lor pură. Cu toate acestea, am putea furniza aceste servicii separat, în procese diferite. Numai acest lucru a făcut posibilă reducerea influenței lor unul asupra celuilalt, reducând problema cu dezvoltarea paralelă și un singur punct de eșec.
Asamblarea cu gazda este doar o linie de cod din clasa Program. Am ascuns munca cu Topshelf într-o clasă auxiliară.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
A doua modalitate de a aloca microservicii este: creează-le pentru a rezolva probleme noi. Dacă în același timp monolitul nu crește, acest lucru este deja excelent, ceea ce înseamnă că ne mișcăm în direcția corectă. Pentru a rezolva noi probleme, am încercat să creăm servicii separate. Dacă a existat o astfel de oportunitate, atunci am creat mai multe servicii „canonice” care își gestionează complet propriul model de date, o bază de date separată.
Noi, ca mulți, am început cu servicii de autentificare și autorizare. Sunt perfecte pentru asta. Sunt independenți, de regulă, au un model de date separat. Ei înșiși nu interacționează cu monolitul, doar că apelează la ei pentru a rezolva unele probleme. Folosind aceste servicii, puteți începe tranziția către o nouă arhitectură, puteți depana infrastructura pe acestea, puteți încerca câteva abordări legate de bibliotecile de rețea etc. Nu avem echipe în organizația noastră care să nu poată crea un serviciu de autentificare.
A treia modalitate de a aloca microserviciiCel pe care îl folosim ne este puțin specific. Aceasta este eliminarea logicii de afaceri din stratul UI. Principala noastră aplicație UI este desktop; ea, ca și backend-ul, este scrisă în C#. Dezvoltatorii au făcut periodic greșeli și au transferat părți de logică în interfața de utilizare care ar fi trebuit să existe în backend și să fie reutilizate.
Dacă te uiți la un exemplu real din codul părții UI, poți vedea că cea mai mare parte a acestei soluții conține o logică de afaceri reală, care este utilă în alte procese, nu doar pentru construirea formularului UI.
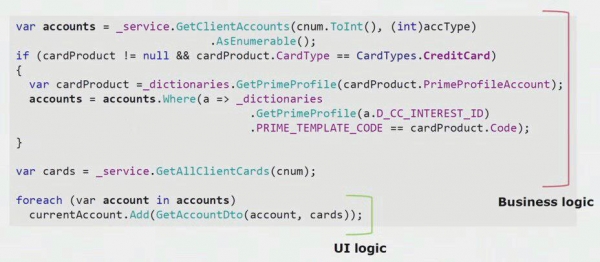
Logica reală a interfeței de utilizare este acolo doar în ultimele două rânduri. L-am transferat pe server pentru a putea fi reutilizat, reducând astfel interfața de utilizare și realizând arhitectura corectă.
Al patrulea și cel mai important mod de a izola microservicii, care face posibilă reducerea monolitului, este eliminarea serviciilor existente cu procesare. Când scoatem modulele existente așa cum sunt, rezultatul nu este întotdeauna pe placul dezvoltatorilor și este posibil ca procesul de afaceri să fi devenit depășit de când a fost creată funcționalitatea. Cu refactorizarea, putem sprijini un nou proces de afaceri, deoarece cerințele de afaceri sunt în continuă schimbare. Putem îmbunătăți codul sursă, putem elimina defectele cunoscute și putem crea un model de date mai bun. Sunt multe beneficii acumulate.
Separarea serviciilor de procesare este indisolubil legată de conceptul de context delimitat. Acesta este un concept de la Domain Driven Design. Înseamnă o secțiune a modelului de domeniu în care toți termenii unei singure limbi sunt definiți în mod unic. Să ne uităm la contextul asigurărilor și facturilor ca exemplu. Avem o aplicație monolitică și trebuie să lucrăm cu contul în asigurări. Ne așteptăm ca dezvoltatorul să găsească o clasă de cont existentă într-un alt ansamblu, să o facă referire din clasa Asigurare și vom avea cod de lucru. Se va respecta principiul DRY, sarcina se va face mai rapid prin utilizarea codului existent.
Ca urmare, se dovedește că contextele conturilor și asigurărilor sunt conectate. Pe măsură ce apar noi cerințe, această cuplare va interfera cu dezvoltarea, crescând complexitatea logicii de afaceri deja complexe. Pentru a rezolva această problemă, trebuie să găsiți granițele dintre contexte în cod și să eliminați încălcările acestora. De exemplu, în contextul asigurărilor, este foarte posibil ca un număr de cont din 20 de cifre de la Banca Centrală și data deschiderii contului să fie suficiente.
Pentru a separa aceste contexte delimitate unul de celălalt și pentru a începe procesul de separare a microserviciilor dintr-o soluție monolitică, am folosit o abordare precum crearea de API-uri externe în cadrul aplicației. Dacă știam că un modul ar trebui să devină un microserviciu, cumva modificat în cadrul procesului, atunci am făcut imediat apeluri la logica care aparține unui alt context limitat prin apeluri externe. De exemplu, prin REST sau WCF.
Am hotărât ferm că nu vom evita codul care ar necesita tranzacții distribuite. În cazul nostru, s-a dovedit a fi destul de ușor să urmați această regulă. Nu am întâlnit încă situații în care să fie cu adevărat necesare tranzacții strict distribuite - consistența finală între module este destul de suficientă.
Să ne uităm la un exemplu concret. Avem conceptul de orchestrator - o conductă care procesează entitatea „aplicației”. Își creează pe rând un client, un cont și un card bancar. Dacă clientul și contul sunt create cu succes, dar crearea cardului eșuează, aplicația nu trece la starea „de succes” și rămâne în starea „card necreat”. În viitor, activitatea de fundal o va prelua și o va termina. Sistemul se află într-o stare de inconsecvență de ceva timp, dar în general suntem mulțumiți de acest lucru.
Dacă apare o situație în care este necesară salvarea constantă a unei părți a datelor, cel mai probabil vom opta pentru consolidarea serviciului pentru a-l procesa într-un singur proces.
Să ne uităm la un exemplu de alocare a unui microserviciu. Cum îl poți aduce în producție relativ sigur? În acest exemplu, avem o parte separată a sistemului - un modul de serviciu de salarizare, una dintre secțiunile de cod ale căreia am dori să facem microserviciu.
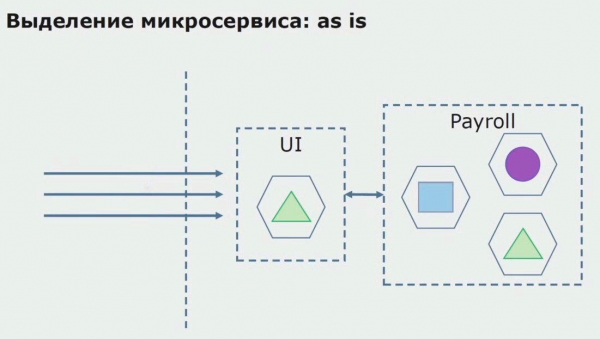
În primul rând, creăm un microserviciu prin rescrierea codului. Îmbunătățim unele aspecte de care nu am fost mulțumiți. Implementăm noi cerințe de afaceri de la client. Adăugăm un API Gateway la conexiunea dintre UI și backend, care va oferi redirecționarea apelurilor.
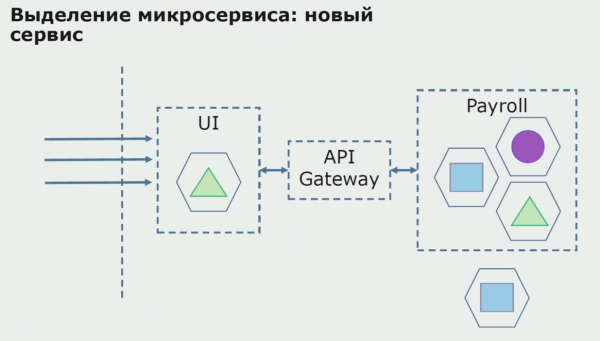
În continuare, lansăm această configurație în funcțiune, dar în stare pilot. Majoritatea utilizatorilor noștri încă lucrează cu procese de afaceri vechi. Pentru utilizatorii noi, dezvoltăm o nouă versiune a aplicației monolitice care nu mai conține acest proces. În esență, avem o combinație între un monolit și un microserviciu care funcționează ca pilot.
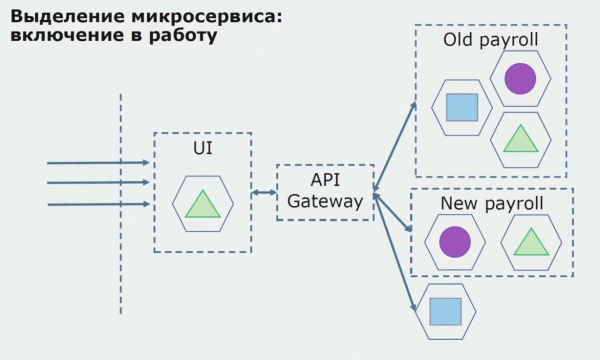
Cu un pilot de succes, înțelegem că noua configurație este într-adevăr funcțională, putem elimina vechiul monolit din ecuație și lăsăm noua configurație în locul soluției vechi.
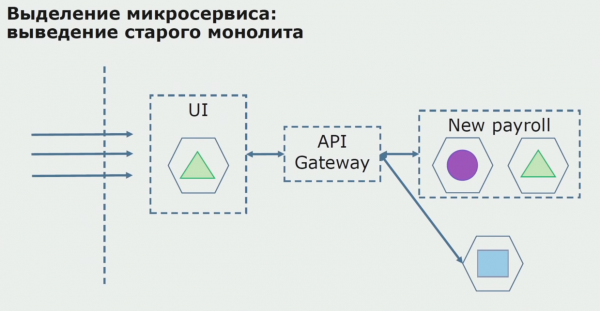
În total, folosim aproape toate metodele existente pentru împărțirea codului sursă al unui monolit. Toate ne permit să reducem dimensiunea părților aplicației și să le traducem în biblioteci noi, făcând cod sursă mai bun.
Lucrul cu baza de date
Baza de date poate fi împărțită mai rău decât codul sursă, deoarece conține nu numai schema curentă, ci și date istorice acumulate.
Baza noastră de date, ca multe altele, a avut un alt dezavantaj important - dimensiunea sa uriașă. Această bază de date a fost concepută în conformitate cu logica de afaceri complicată a unui monolit și relațiile acumulate între tabelele din diferite contexte delimitate.
În cazul nostru, pentru a pune capăt tuturor necazurilor (bază de date mare, multe conexiuni, uneori granițe neclare între tabele), a apărut o problemă care apare în multe proiecte mari: utilizarea șablonului de bază de date partajată. Datele au fost preluate din tabele prin vizualizare, prin replicare și expediate către alte sisteme unde a fost necesară această replicare. Ca urmare, nu am putut muta tabelele într-o schemă separată, deoarece au fost utilizate în mod activ.
Aceeași împărțire în contexte limitate în cod ne ajută la separare. De obicei, ne oferă o idee destul de bună despre cum descompunăm datele la nivel de bază de date. Înțelegem care tabele aparțin unui context mărginit și care altuia.
Am folosit două metode globale de partiţionare a bazei de date: partiţionarea tabelelor existente şi partiţionarea cu procesare.
Împărțirea tabelelor existente este o metodă bună de utilizat dacă structura datelor este bună, îndeplinește cerințele de afaceri și toată lumea este mulțumită de ea. În acest caz, putem separa tabelele existente într-o schemă separată.
Este nevoie de un departament cu procesare atunci când modelul de business s-a schimbat mult, iar tabelele nu ne mai mulțumesc deloc.
Împărțirea tabelelor existente. Trebuie să stabilim ce vom separa. Fără aceste cunoștințe, nimic nu va funcționa, iar aici separarea contextelor mărginite în cod ne va ajuta. De regulă, dacă puteți înțelege limitele contextelor din codul sursă, devine clar ce tabele ar trebui incluse în lista pentru departament.
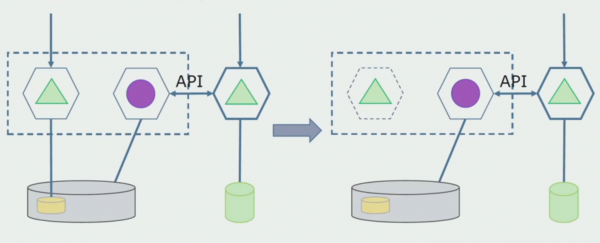
Să ne imaginăm că avem o soluție în care două module monolitice interacționează cu o bază de date. Trebuie să ne asigurăm că doar un modul interacționează cu secțiunea de tabele separate, iar celălalt începe să interacționeze cu acesta prin intermediul API-ului. Pentru început, este suficient ca doar înregistrarea să fie efectuată prin API. Aceasta este o condiție necesară pentru ca noi să vorbim despre independența microserviciilor. Conexiunile de citire pot rămâne atâta timp cât nu există nicio problemă mare.
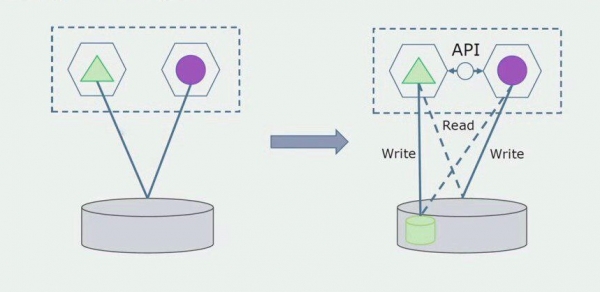
Următorul pas este că putem separa secțiunea de cod care funcționează cu tabele separate, cu sau fără procesare, într-un microserviciu separat și să o rulăm într-un proces separat, un container. Acesta va fi un serviciu separat, cu o conexiune la baza de date monolit și la acele tabele care nu au legătură directă cu aceasta. Monolitul interacționează în continuare pentru lectură cu partea detașabilă.
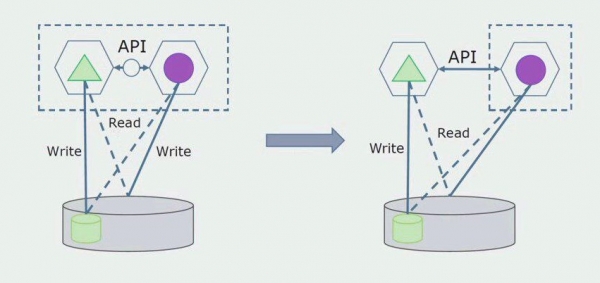
Mai târziu vom elimina această conexiune, adică citirea datelor dintr-o aplicație monolitică din tabele separate vor fi, de asemenea, transferate în API.
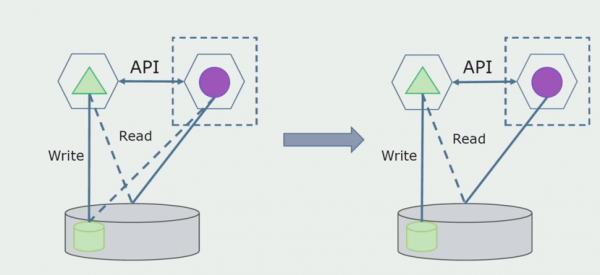
În continuare, vom selecta din baza de date generală tabelele cu care funcționează doar noul microserviciu. Putem muta tabelele într-o schemă separată sau chiar într-o bază de date fizică separată. Există încă o conexiune de citire între microserviciu și baza de date monolit, dar nu este nimic de care să vă faceți griji, în această configurație poate trăi destul de mult timp.
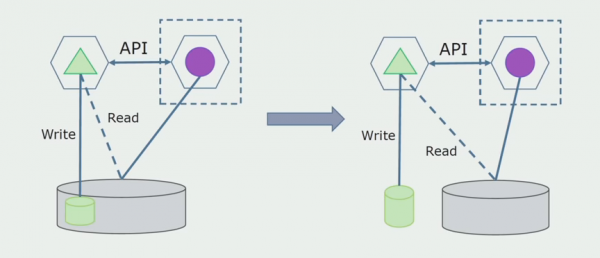
Ultimul pas este să eliminați complet toate conexiunile. În acest caz, este posibil să fie nevoie să migrăm datele din baza de date principală. Uneori dorim să reutilizam unele date sau directoare replicate din sisteme externe în mai multe baze de date. Acest lucru ni se întâmplă periodic.
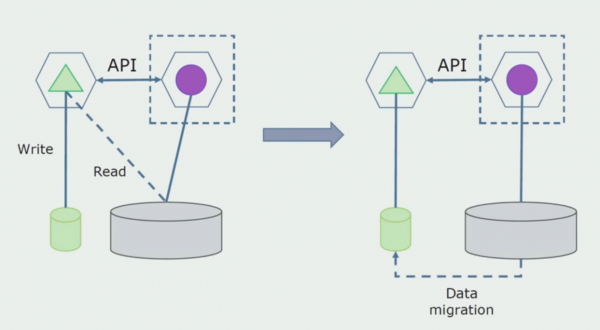
Departamentul de procesare. Această metodă este foarte asemănătoare cu prima, doar în ordine inversă. Alocăm imediat o nouă bază de date și un nou microserviciu care interacționează cu monolitul printr-un API. Dar, în același timp, rămâne un set de tabele de baze de date pe care dorim să le ștergem în viitor. Nu mai avem nevoie de el, l-am înlocuit în noul model.
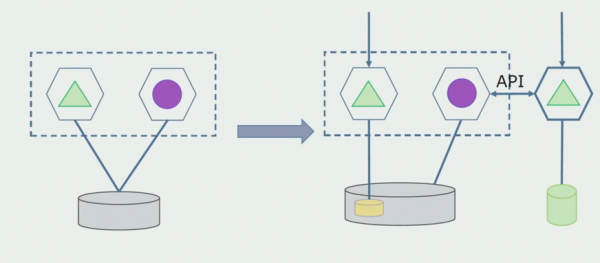
Pentru ca această schemă să funcționeze, probabil că vom avea nevoie de o perioadă de tranziție.
Există apoi două abordări posibile.
în primul rând: duplicăm toate datele din bazele de date noi și vechi. În acest caz, avem redundanța datelor și pot apărea probleme de sincronizare. Dar putem lua doi clienți diferiți. Unul va funcționa cu noua versiune, celălalt cu cea veche.
în al doilea rând: împărțim datele după niște criterii de afaceri. De exemplu, aveam 5 produse în sistem care erau stocate în vechea bază de date. Pe al șaselea îl plasăm în cadrul noii sarcini de afaceri într-o nouă bază de date. Dar vom avea nevoie de un API Gateway care să sincronizeze aceste date și să arate clientului de unde și de ce să obțină.
Ambele abordări funcționează, alegeți în funcție de situație.
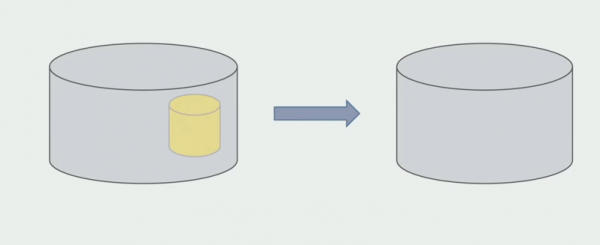
După ce suntem siguri că totul funcționează, partea din monolit care funcționează cu structuri vechi de baze de date poate fi dezactivată.
Ultimul pas este eliminarea vechilor structuri de date.
Pentru a rezuma, putem spune că avem probleme cu baza de date: este greu să lucrezi cu ea în comparație cu codul sursă, este mai dificil de partajat, dar se poate și trebuie făcut. Am găsit câteva modalități care ne permit să facem acest lucru în siguranță, dar este totuși mai ușor să facem greșeli cu datele decât cu codul sursă.
Lucrul cu codul sursă
Așa arăta diagrama codului sursă când am început să analizăm proiectul monolitic.
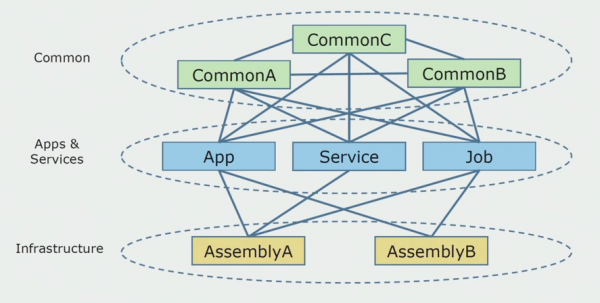
Poate fi împărțit aproximativ în trei straturi. Acesta este un strat de module lansate, pluginuri, servicii și activități individuale. De fapt, acestea erau puncte de intrare într-o soluție monolitică. Toate au fost sigilate etanș cu un strat comun. Avea o logică de afaceri pe care serviciile o împărtășeau și o mulțime de conexiuni. Fiecare serviciu și plugin a folosit până la 10 sau mai multe ansambluri comune, în funcție de dimensiunea lor și de conștiința dezvoltatorilor.
Am fost norocoși să avem biblioteci de infrastructură care puteau fi folosite separat.
Uneori a apărut o situație când unele obiecte comune nu aparțineau de fapt acestui strat, ci erau biblioteci de infrastructură. Acest lucru a fost rezolvat prin redenumire.
Cea mai mare preocupare au fost contextele delimitate. S-a întâmplat ca 3-4 contexte să fie amestecate într-un singur ansamblu comun și să se folosească reciproc în cadrul acelorași funcții de afaceri. A fost necesar să înțelegem unde ar putea fi împărțit acest lucru și de-a lungul ce granițe și ce să facem în continuare cu maparea acestei diviziuni în ansambluri de cod sursă.
Am formulat mai multe reguli pentru procesul de împărțire a codului.
Prima: Nu mai doream să împărtășim logica de afaceri între servicii, activități și pluginuri. Am vrut să facem logica de afaceri independentă în cadrul microserviciilor. Microserviciile, pe de altă parte, sunt gândite în mod ideal ca servicii care există complet independent. Cred că această abordare este oarecum risipitoare și este dificil de realizat, deoarece, de exemplu, serviciile în C# vor fi în orice caz conectate printr-o bibliotecă standard. Sistemul nostru este scris în C#; nu am folosit încă alte tehnologii. Prin urmare, am decis că ne putem permite să folosim ansambluri tehnice comune. Principalul lucru este că nu conțin fragmente de logica de afaceri. Dacă aveți un înveliș convenabil peste ORM-ul pe care îl utilizați, atunci copiarea acestuia de la service la service este foarte costisitoare.
Echipa noastră este un fan al design-ului bazat pe domenii, așa că arhitectura ceapă s-a potrivit perfect pentru noi. Baza serviciilor noastre nu este stratul de acces la date, ci un ansamblu cu logică de domeniu, care conține doar logica de business și nu are conexiuni cu infrastructura. În același timp, putem modifica în mod independent ansamblul domeniului pentru a rezolva probleme legate de cadre.
În această etapă ne-am confruntat cu prima noastră problemă serioasă. Serviciul trebuia să se refere la un ansamblu de domeniu, am vrut să facem logica independentă, iar principiul DRY ne-a împiedicat foarte mult aici. Dezvoltatorii doreau să refolosească clasele din ansamblurile vecine pentru a evita duplicarea și, ca urmare, domeniile au început să fie conectate din nou. Am analizat rezultatele și am decis că, probabil, problema se află și în zona dispozitivului de stocare a codului sursă. Aveam un depozit mare care conținea tot codul sursă. Soluția pentru întregul proiect a fost foarte dificil de asamblat pe o mașină locală. Prin urmare, au fost create soluții mici separate pentru părți ale proiectului și nimeni nu a interzis adăugarea unor ansambluri comune sau de domeniu și reutilizarea lor. Singurul instrument care nu ne-a permis să facem acest lucru a fost revizuirea codului. Dar uneori și ea a eșuat.
Apoi am început să trecem la un model cu depozite separate. Logica de afaceri nu mai curge de la serviciu la serviciu, domeniile au devenit cu adevărat independente. Contextele delimitate sunt susținute mai clar. Cum reutilizam bibliotecile de infrastructură? Le-am separat într-un depozit separat, apoi le-am pus în pachetele Nuget, pe care le-am pus în Artifactory. Cu orice modificare, asamblarea și publicarea au loc automat.
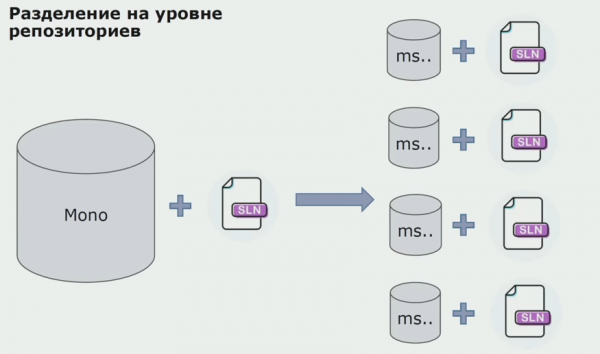
Serviciile noastre au început să facă referire la pachetele de infrastructură internă în același mod ca și cele externe. Descărcăm biblioteci externe din Nuget. Pentru a lucra cu Artifactory, unde am plasat aceste pachete, am folosit doi manageri de pachete. În depozitele mici am folosit și Nuget. În depozitele cu mai multe servicii, am folosit Paket, care oferă mai multă consistență a versiunilor între module.
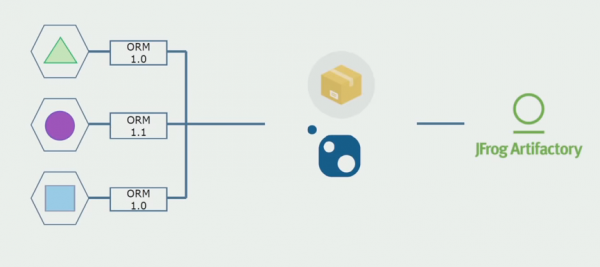
Astfel, lucrând la codul sursă, schimbând puțin arhitectura și separând depozitele, ne facem serviciile mai independente.
Probleme de infrastructură
Cele mai multe dintre dezavantajele trecerii la microservicii sunt legate de infrastructură. Veți avea nevoie de implementare automată, veți avea nevoie de noi biblioteci pentru a rula infrastructura.
Instalare manuală în medii
Inițial, am instalat manual soluția pentru medii. Pentru a automatiza acest proces, am creat o conductă CI/CD. Am ales procesul de livrare continuă deoarece implementarea continuă nu este încă acceptabilă pentru noi din punct de vedere al proceselor de afaceri. Prin urmare, trimiterea pentru funcționare se efectuează folosind un buton, iar pentru testare - automat.
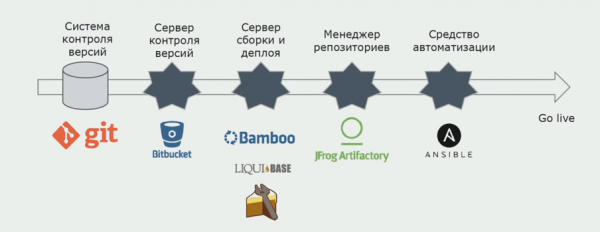
Folosim Atlassian, Bitbucket pentru stocarea codului sursă și Bamboo pentru construcție. Ne place să scriem scripturi de construcție în Cake, deoarece este același cu C#. Pachetele gata făcute vin la Artifactory, iar Ansible ajunge automat la serverele de testare, după care pot fi testate imediat.
Înregistrare separată
La un moment dat, una dintre ideile monolitului a fost de a oferi jurnalism partajat. De asemenea, trebuia să înțelegem ce să facem cu jurnalele individuale care se află pe discuri. Jurnalele noastre sunt scrise în fișiere text. Am decis să folosim o stivă ELK standard. Nu i-am scris ELK direct prin intermediul furnizorilor, dar am decis că vom modifica jurnalele de text și vom scrie ID-ul de urmărire în ele ca identificator, adăugând numele serviciului, astfel încât aceste jurnale să poată fi analizate mai târziu.
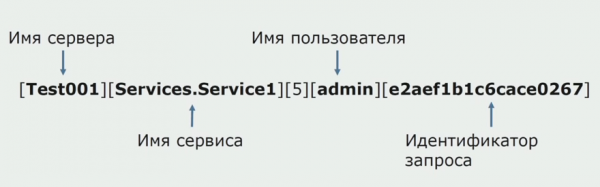
Cu Filebeat putem colecta jurnalele noastre de la servere, apoi transformați-le, folosiți Kibana pentru a construi interogări în interfața cu utilizatorul și vedeți cum a fost rutat apelul între servicii. ID-urile de urmărire sunt foarte utile în acest sens.
Servicii legate de testare și depanare
Inițial, nu am înțeles pe deplin cum să depanăm serviciile în curs de dezvoltare. Totul a fost simplu cu monolitul; l-am rulat pe o mașină locală. La început au încercat să facă același lucru cu microservicii, dar uneori pentru a lansa complet un microserviciu trebuie să lansați mai multe alte, iar acest lucru este incomod. Ne-am dat seama că trebuie să trecem la un model în care să lăsăm pe mașina locală doar serviciul sau serviciile pe care vrem să le depanăm. Serviciile rămase sunt utilizate de la servere care se potrivesc cu configurația cu prod. După depanare, în timpul testării, pentru fiecare sarcină, doar serviciile modificate sunt emise serverului de testare. Astfel, soluția este testată în forma în care va apărea în producție în viitor.
Există servere care rulează doar versiuni de producție ale serviciilor. Aceste servere sunt necesare în caz de incidente, pentru a verifica livrarea înainte de implementare și pentru instruirea internă.
Am adăugat un proces automat de testare folosind populara bibliotecă Specflow. Testele rulează automat folosind NUnit imediat după implementarea din Ansible. Dacă acoperirea sarcinii este complet automată, atunci nu este nevoie de testare manuală. Deși uneori este încă necesară testarea manuală suplimentară. Folosim etichete în Jira pentru a determina ce teste să rulăm pentru o anumită problemă.
În plus, nevoia de testare a sarcinii a crescut; anterior a fost efectuată doar în cazuri rare. Folosim JMeter pentru a rula teste, InfluxDB pentru a le stoca și Grafana pentru a construi grafice de proces.
Ce am realizat?
În primul rând, am scăpat de conceptul de „eliberare”. Au dispărut lansările monstruoase de două luni când acest colos a fost implementat într-un mediu de producție, perturbând temporar procesele de afaceri. Acum implementăm serviciile în medie la fiecare 1,5 zile, grupându-le pentru că intră în funcțiune după aprobare.
Nu există eșecuri fatale în sistemul nostru. Dacă lansăm un microserviciu cu o eroare, atunci funcționalitatea asociată acestuia va fi întreruptă și toate celelalte funcționalități nu vor fi afectate. Acest lucru îmbunătățește considerabil experiența utilizatorului.
Putem controla modelul de implementare. Puteți selecta grupuri de servicii separat de restul soluției, dacă este necesar.
În plus, am redus semnificativ problema cu o coadă mare de îmbunătățiri. Acum avem echipe de produse separate care lucrează cu unele dintre servicii în mod independent. Procesul Scrum este deja potrivit aici. O anumită echipă poate avea un proprietar de produs separat care îi atribuie sarcini.
Rezumat
- Microserviciile sunt potrivite pentru descompunerea sistemelor complexe. În acest proces, începem să înțelegem ce este în sistemul nostru, ce contexte limitate există, unde se află granițele lor. Acest lucru vă permite să distribuiți corect îmbunătățirile între module și să preveniți confuzia de cod.
- Microserviciile oferă beneficii organizaționale. Deseori se vorbește despre ele doar ca arhitectură, dar orice arhitectură este necesară pentru a rezolva nevoile afacerii, și nu singură. Prin urmare, putem spune că microserviciile sunt foarte potrivite pentru rezolvarea problemelor în echipe mici, având în vedere că Scrum este foarte popular acum.
- Separarea este un proces iterativ. Nu puteți lua o aplicație și pur și simplu o puteți împărți în microservicii. Este puțin probabil ca produsul rezultat să fie funcțional. Atunci când dedicăm microservicii, este benefic să rescriem moștenirea existentă, adică să o transformăm în cod care ne place și care răspunde mai bine nevoilor afacerii în ceea ce privește funcționalitatea și viteza.
Un mic avertisment: Costurile trecerii la microservicii sunt destul de semnificative. A fost nevoie de mult timp pentru a rezolva singur problema infrastructurii. Deci, dacă aveți o aplicație mică care nu necesită o scalare specifică, cu excepția cazului în care aveți un număr mare de clienți care concurează pentru atenția și timpul echipei dvs., atunci este posibil ca microservicii să nu fie ceea ce aveți nevoie astăzi. Este destul de scump. Dacă începeți procesul cu microservicii, atunci costurile vor fi inițial mai mari decât dacă începeți același proiect cu dezvoltarea unui monolit.
PS O poveste mai emoționantă (și parcă pentru tine personal) - conform .
Iată versiunea completă a raportului.
Sursa: www.habr.com
