

Continuăm seria de articole dedicate studiului modalităților puțin cunoscute de îmbunătățire a performanței interogărilor PostgreSQL „aparent simple”:
Să nu credeți că nu-mi place atât de mult JOIN... :)
Dar adesea fără ea, cererea se dovedește a fi semnificativ mai productivă decât cu ea. Așa că astăzi vom încerca scăpați de JOIN care necesită mult resurse - folosind un dicționar.

Începând cu PostgreSQL 12, unele dintre situațiile descrise mai jos pot fi reproduse ușor diferit din cauza . Acest comportament poate fi inversat prin specificarea cheii
MATERIALIZED.
O mulțime de „fapte” într-un vocabular limitat
Să luăm o sarcină de aplicație foarte reală - trebuie să afișăm o listă sau sarcini active cu expeditori:
25.01 | Иванов И.И. | Подготовить описание нового алгоритма.
22.01 | Иванов И.И. | Написать статью на Хабр: жизнь без JOIN.
20.01 | Петров П.П. | Помочь оптимизировать запрос.
18.01 | Иванов И.И. | Написать статью на Хабр: JOIN с учетом распределения данных.
16.01 | Петров П.П. | Помочь оптимизировать запрос.
În lumea abstractă, autorii sarcinilor ar trebui să fie distribuiți uniform între toți angajații organizației noastre, dar în realitate sarcinile provin, de regulă, de la un număr destul de limitat de persoane - „de la management” în sus în ierarhie sau „de la subcontractanți” din departamentele învecinate (analiști, designeri, marketing, ...).
Să acceptăm că în organizația noastră de 1000 de oameni, doar 20 de autori (de obicei chiar mai puțin) stabilesc sarcini pentru fiecare interpret specific și pentru a accelera interogarea „tradițională”.
Generator de scripturi
-- сотрудники
CREATE TABLE person AS
SELECT
id
, repeat(chr(ascii('a') + (id % 26)), (id % 32) + 1) "name"
, '2000-01-01'::date - (random() * 1e4)::integer birth_date
FROM
generate_series(1, 1000) id;
ALTER TABLE person ADD PRIMARY KEY(id);
-- задачи с указанным распределением
CREATE TABLE task AS
WITH aid AS (
SELECT
id
, array_agg((random() * 999)::integer + 1) aids
FROM
generate_series(1, 1000) id
, generate_series(1, 20)
GROUP BY
1
)
SELECT
*
FROM
(
SELECT
id
, '2020-01-01'::date - (random() * 1e3)::integer task_date
, (random() * 999)::integer + 1 owner_id
FROM
generate_series(1, 100000) id
) T
, LATERAL(
SELECT
aids[(random() * (array_length(aids, 1) - 1))::integer + 1] author_id
FROM
aid
WHERE
id = T.owner_id
LIMIT 1
) a;
ALTER TABLE task ADD PRIMARY KEY(id);
CREATE INDEX ON task(owner_id, task_date);
CREATE INDEX ON task(author_id);
Să arătăm ultimele 100 de sarcini pentru un anumit executant:
SELECT
task.*
, person.name
FROM
task
LEFT JOIN
person
ON person.id = task.author_id
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100; 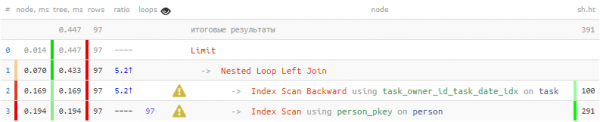
Se pare că 1/3 din timpul total și 3/4 citiri pagini de date au fost făcute doar pentru a căuta autorul de 100 de ori - pentru fiecare sarcină de ieșire. Dar știm că printre aceste sute doar 20 diferite - Este posibil să folosim aceste cunoștințe?
hstore-dicționar
Să profităm pentru a genera o valoare-cheie „dicționar”:
CREATE EXTENSION hstoreTrebuie doar să punem ID-ul autorului și numele acestuia în dicționar, astfel încât să putem extrage folosind această cheie:
-- формируем целевую выборку
WITH T AS (
SELECT
*
FROM
task
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100
)
-- формируем словарь для уникальных значений
, dict AS (
SELECT
hstore( -- hstore(keys::text[], values::text[])
array_agg(id)::text[]
, array_agg(name)::text[]
)
FROM
person
WHERE
id = ANY(ARRAY(
SELECT DISTINCT
author_id
FROM
T
))
)
-- получаем связанные значения словаря
SELECT
*
, (TABLE dict) -> author_id::text -- hstore -> key
FROM
T; 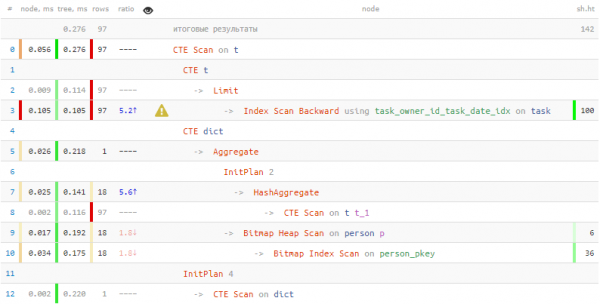
Cheltuit pentru obținerea de informații despre persoane De 2 ori mai puțin timp și de 7 ori mai puține date citite! Pe lângă „vocabular”, ceea ce ne-a ajutat să obținem aceste rezultate a fost regăsire în masă a înregistrărilor de la masă într-o singură trecere folosind = ANY(ARRAY(...)).
Intrări în tabel: serializare și deserializare
Dar dacă trebuie să salvăm nu doar un câmp de text, ci o intrare întreagă în dicționar? În acest caz, capacitatea PostgreSQL ne va ajuta tratați o intrare de tabel ca o singură valoare:
...
, dict AS (
SELECT
hstore(
array_agg(id)::text[]
, array_agg(p)::text[] -- магия #1
)
FROM
person p
WHERE
...
)
SELECT
*
, (((TABLE dict) -> author_id::text)::person).* -- магия #2
FROM
T;Să ne uităm la ce s-a întâmplat aici:
- Am luat p ca alias pentru intrarea completă în tabelul de persoane și a asamblat o serie de ele.
- aceasta gama de înregistrări a fost reformată la o matrice de șiruri de text (person[]::text[]) pentru a-l plasa în dicționarul hstore ca o matrice de valori.
- Când primim o înregistrare aferentă, noi scos din dicționar cu cheie ca șir de text.
- Avem nevoie de text se transformă într-o valoare de tip tabel persoană (pentru fiecare tabel este creat automat un tip cu același nume).
- „Extindeți” înregistrarea tastata în coloane folosind
(...).*.
dicționar json
Dar un astfel de truc pe care l-am aplicat mai sus nu va funcționa dacă nu există un tip de masă corespunzător pentru a face „turnarea”. Exact aceeași situație va apărea și dacă încercăm să folosim un rând CTE, nu un tabel „adevărat”..
În acest caz ne vor ajuta :
...
, p AS ( -- это уже CTE
SELECT
*
FROM
person
WHERE
...
)
, dict AS (
SELECT
json_object( -- теперь это уже json
array_agg(id)::text[]
, array_agg(row_to_json(p))::text[] -- и внутри json для каждой строки
)
FROM
p
)
SELECT
*
FROM
T
, LATERAL(
SELECT
*
FROM
json_to_record(
((TABLE dict) ->> author_id::text)::json -- извлекли из словаря как json
) AS j(name text, birth_date date) -- заполнили нужную нам структуру
) j; Trebuie remarcat faptul că atunci când descriem structura țintă, nu putem enumera toate câmpurile șirului sursă, ci doar cele de care avem cu adevărat nevoie. Dacă avem un tabel „nativ”, atunci este mai bine să folosim funcția json_populate_record.
Accesăm dicționarul încă o dată, dar Costurile json-[de]serializării sunt destul de mariPrin urmare, este rezonabil să utilizați această metodă numai în unele cazuri când scanarea CTE „cinstă” se arată mai proastă.
Testarea performanței
Deci, avem două moduri de a serializa datele într-un dicționar - hstore/json_object. În plus, matricele de chei și valori în sine pot fi generate în două moduri, cu conversie internă sau externă în text: array_agg(i::text) / array_agg(i)::text[].
Să verificăm eficacitatea diferitelor tipuri de serializare folosind un exemplu pur sintetic - serializați diferite numere de chei:
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, ...) i
)
TABLE dict;Script de evaluare: serializare
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
TABLE dict
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 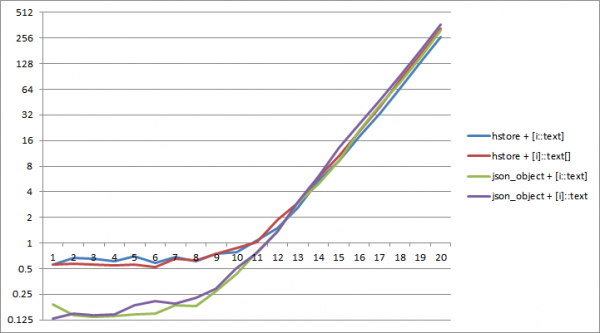
Pe PostgreSQL 11, până la o dimensiune de dicționar de aproximativ 2^12 chei Serializarea la json durează mai puțin. În acest caz, cea mai eficientă este combinația dintre json_object și conversia de tip „internă”. array_agg(i::text).
Acum să încercăm să citim valoarea fiecărei chei de 8 ori - la urma urmei, dacă nu accesați dicționarul, atunci de ce este nevoie de el?
Script de evaluare: citirea dintr-un dicționar
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
json_object(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
SELECT
(TABLE dict) -> (i % ($$ || (1 << v) || $$) + 1)::text
FROM
generate_series(1, $$ || (1 << (v + 3)) || $$) i
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 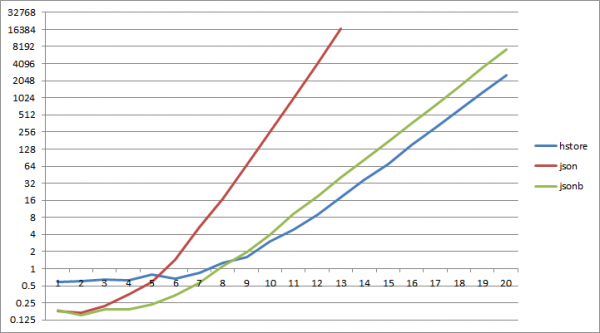
Și... deja aproximativ cu 2^6 taste, citirea dintr-un dicționar json începe să piardă de mai multe ori citind din hstore, pentru jsonb același lucru se întâmplă la 2^9.
Concluzii finale:
- dacă trebuie să o faci JOIN cu mai multe înregistrări repetate — este mai bine să folosiți „dicționarul” tabelului
- dacă dicționarul tău este de așteptat mic și nu vei citi prea multe din el - puteți folosi json[b]
- în toate celelalte cazuri hstore + array_agg(i::text) va fi mai eficient
Sursa: www.habr.com
