

Bună ziua Numele meu este Danil Lipovoy, echipa noastră de la Sbertech a început să folosească HBase ca stocare pentru date operaționale. În cursul studierii lui s-a acumulat experiență pe care am vrut să o sistematizez și să o descriu (sperăm că va fi de folos multora). Toate experimentele de mai jos au fost efectuate cu HBase versiunile 1.2.0-cdh5.14.2 și 2.0.0-cdh6.0.0-beta1.
- Arhitectura generala
- Scrierea datelor la HBASE
- Citirea datelor de la HBASE
- Memorarea în cache a datelor
- Procesarea datelor în loturi MultiGet/MultiPut
- Strategie de împărțire a tabelelor în regiuni (divizarea)
- Toleranță la erori, compactare și localitatea datelor
- Setări și performanță
- Testare stresanta
- Constatări
1. Arhitectura generala
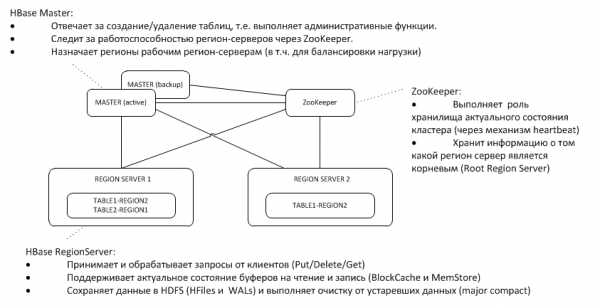
Masterul de rezervă ascultă bătăile inimii celui activ pe nodul ZooKeeper și, în caz de dispariție, preia funcțiile masterului.
2. Scrieți datele în HBASE
Mai întâi, să ne uităm la cel mai simplu caz - scrierea unui obiect cheie-valoare într-un tabel folosind put(rowkey). Clientul trebuie să afle mai întâi unde se află Root Region Server (RRS), care stochează tabelul hbase:meta. El primește aceste informații de la ZooKeeper. După care accesează RRS și citește tabelul hbase:meta, din care extrage informații despre ce RegionServer (RS) este responsabil pentru stocarea datelor pentru o anumită cheie de rând în tabelul de interes. Pentru utilizare ulterioară, meta-tabelul este stocat în cache de către client și, prin urmare, apelurile ulterioare merg mai repede, direct către RS.
Apoi, RS, după ce a primit o solicitare, în primul rând o scrie în WriteAheadLog (WAL), care este necesară pentru recuperare în caz de blocare. Apoi salvează datele în MemStore. Acesta este un buffer în memorie care conține un set sortat de chei pentru o anumită regiune. Un tabel poate fi împărțit în regiuni (partiții), fiecare dintre ele conține un set disjuns de chei. Acest lucru vă permite să plasați regiuni pe diferite servere pentru a obține performanțe mai mari. Cu toate acestea, în ciuda evidenței acestei afirmații, vom vedea mai târziu că acest lucru nu funcționează în toate cazurile.
După plasarea unei intrări în MemStore, clientului îi este returnat un răspuns că intrarea a fost salvată cu succes. Cu toate acestea, în realitate este stocat doar într-un buffer și ajunge pe disc numai după ce a trecut o anumită perioadă de timp sau când este umplut cu date noi.
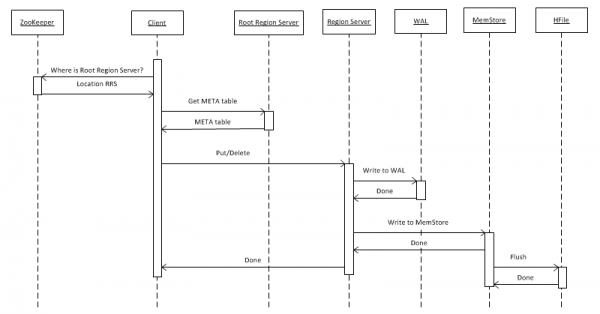
Când efectuați operația „Ștergere”, datele nu sunt șterse fizic. Ele sunt pur și simplu marcate ca șterse, iar distrugerea în sine are loc în momentul apelării funcției compacte majore, care este descrisă mai detaliat în paragraful 7.
Fișierele în format HFile sunt acumulate în HDFS și din când în când se lansează procesul de compactare minoră, care pur și simplu îmbină fișierele mici în altele mai mari fără a șterge nimic. În timp, aceasta se transformă într-o problemă care apare doar la citirea datelor (vom reveni la asta puțin mai târziu).
Pe lângă procesul de încărcare descris mai sus, există o procedură mult mai eficientă, care este poate cea mai puternică latură a acestei baze de date - BulkLoad. Constă în faptul că formăm independent HFile și le punem pe disc, ceea ce ne permite să scalam perfect și să atingem viteze foarte decente. De fapt, limitarea aici nu este HBase, ci capacitățile hardware-ului. Mai jos sunt rezultatele de pornire pe un cluster format din 16 RegionServere și 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 fire), HBase versiunea 1.2.0-cdh5.14.2.
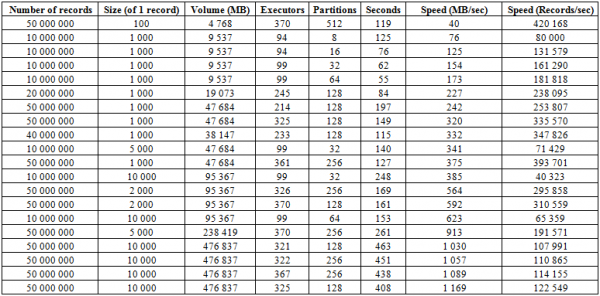
Aici puteți vedea că prin creșterea numărului de partiții (regiuni) din tabel, precum și a executorilor Spark, obținem o creștere a vitezei de descărcare. De asemenea, viteza depinde de volumul de înregistrare. Blocurile mari dau o creștere a MB/sec, blocurile mici a numărului de înregistrări introduse pe unitatea de timp, toate celelalte lucruri fiind egale.
De asemenea, puteți începe să încărcați în două mese în același timp și să obțineți o viteză dublă. Mai jos puteți vedea că scrierea blocurilor de 10 KB pe două tabele deodată are loc la o viteză de aproximativ 600 MB/sec în fiecare (total 1275 MB/sec), ceea ce coincide cu viteza de scriere într-un singur tabel de 623 MB/sec (vezi nr. 11 de mai sus)

Dar a doua rulare cu înregistrări de 50 KB arată că viteza de descărcare crește ușor, ceea ce indică faptul că se apropie de valorile limită. În același timp, trebuie să rețineți că practic nu există nicio încărcare creată pe HBASE în sine, tot ceea ce este necesar este să oferiți mai întâi date din hbase:meta și, după ce aliniați HFiles, să resetați datele BlockCache și să salvați Bufferul MemStore pe disc, dacă nu este gol.
3. Citirea datelor din HBASE
Dacă presupunem că clientul are deja toate informațiile din hbase:meta (vezi punctul 2), atunci cererea merge direct la RS unde este stocată cheia necesară. În primul rând, căutarea este efectuată în MemCache. Indiferent dacă există sau nu date acolo, căutarea se face și în buffer-ul BlockCache și, dacă este necesar, în HFiles. Dacă au fost găsite date în fișier, acestea sunt plasate în BlockCache și vor fi returnate mai repede la următoarea solicitare. Căutarea în HFile este relativ rapidă datorită utilizării filtrului Bloom, de ex. după ce a citit o cantitate mică de date, determină imediat dacă acest fișier conține cheia necesară și, dacă nu, trece la următoarea.
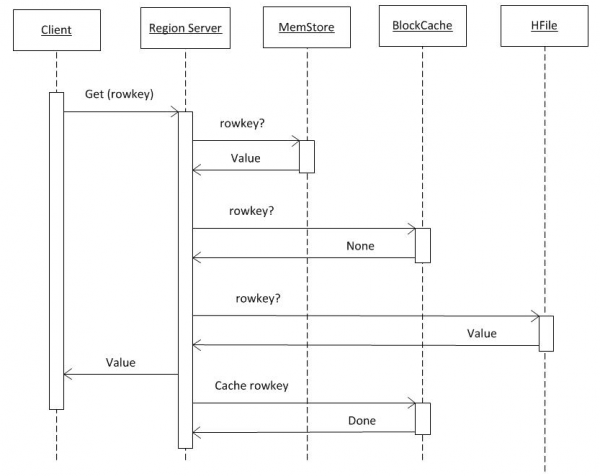
După ce a primit date din aceste trei surse, RS generează un răspuns. În special, poate transfera mai multe versiuni găsite ale unui obiect simultan dacă clientul a solicitat versiunea.
4. Memorarea în cache a datelor
Bufferele MemStore și BlockCache ocupă până la 80% din memoria RS alocată pe heap (restul este rezervat sarcinilor de service RS). Dacă modul de utilizare tipic este astfel încât procesele să scrie și să citească imediat aceleași date, atunci este logic să reduceți BlockCache și să creșteți MemStore, deoarece Când scrierea datelor nu intră în cache pentru citire, BlockCache va fi folosit mai rar. Buffer-ul BlockCache este format din două părți: LruBlockCache (întotdeauna în heap) și BucketCache (de obicei off-heap sau pe un SSD). BucketCache ar trebui să fie utilizat atunci când există o mulțime de solicitări de citire și nu se potrivesc în LruBlockCache, ceea ce duce la lucrul activ al Garbage Collector. În același timp, nu trebuie să vă așteptați la o creștere radicală a performanței din utilizarea cache-ului de citire, dar vom reveni la aceasta în paragraful 8.
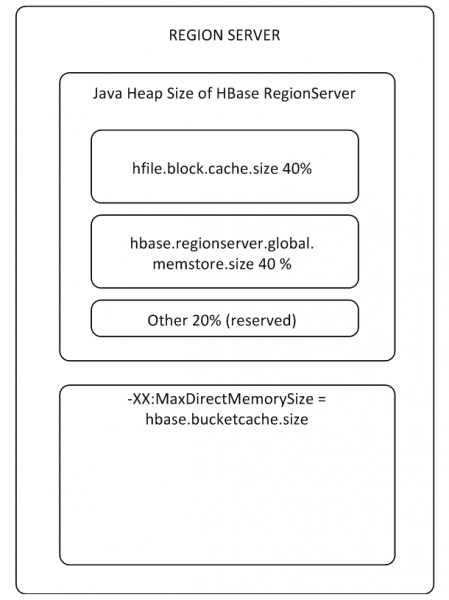
Există un BlockCache pentru întregul RS și există un MemStore pentru fiecare tabel (unul pentru fiecare familie de coloane).
Ca în teorie, la scriere, datele nu intră în cache și într-adevăr, astfel de parametri CACHE_DATA_ON_WRITE pentru tabel și „DATE cache la scriere” pentru RS sunt setați la false. Cu toate acestea, în practică, dacă scriem date în MemStore, apoi le ștergem pe disc (astfel îl ștergem), apoi ștergem fișierul rezultat, atunci executând o solicitare de obținere vom primi cu succes datele. Mai mult, chiar dacă dezactivați complet BlockCache și umpleți tabelul cu date noi, apoi resetați MemStore pe disc, le ștergeți și le solicitați dintr-o altă sesiune, acestea vor fi totuși preluate de undeva. Deci HBase stochează nu numai date, ci și mistere misterioase.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Parametrul „DATE cache la citire” este setat la fals. Dacă aveți idei, bine ați venit să o discutați în comentarii.
5. Procesarea loturilor de date MultiGet/MultiPut
Procesarea cererilor individuale (Get/Put/Delete) este o operațiune destul de costisitoare, așa că, dacă este posibil, ar trebui să le combinați într-o Listă sau Listă, ceea ce vă permite să obțineți o creștere semnificativă a performanței. Acest lucru este valabil mai ales pentru operația de scriere, dar atunci când citiți există următoarea capcană. Graficul de mai jos arată timpul necesar pentru citirea a 50 de înregistrări din MemStore. Citirea a fost efectuată într-un singur fir, iar axa orizontală arată numărul de chei din cerere. Aici puteți vedea că atunci când creșteți la o mie de chei într-o singură solicitare, timpul de execuție scade, adică. viteza creste. Cu toate acestea, cu modul MSLAB activat în mod implicit, după acest prag începe o scădere radicală a performanței și cu cât cantitatea de date din înregistrare este mai mare, cu atât timpul de operare este mai lung.
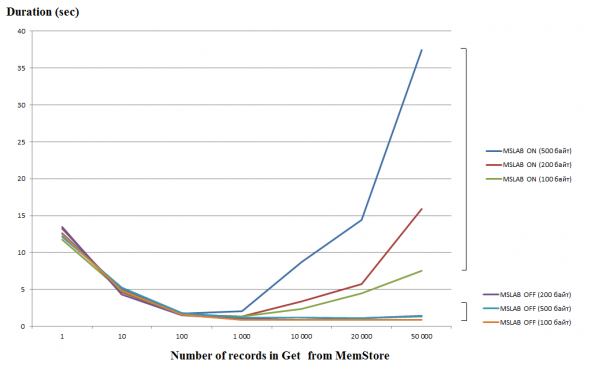
Testele au fost efectuate pe o mașină virtuală, 8 nuclee, versiunea HBase 2.0.0-cdh6.0.0-beta1.
Modul MSLAB este conceput pentru a reduce fragmentarea heap-ului, care apare din cauza amestecării datelor de generație nouă și veche. Ca o soluție, atunci când MSLAB este activat, datele sunt plasate în celule relativ mici (bucăți) și procesate în bucăți. Ca rezultat, atunci când volumul din pachetul de date solicitat depășește dimensiunea alocată, performanța scade brusc. Pe de altă parte, dezactivarea acestui mod nu este, de asemenea, recomandabilă, deoarece va duce la opriri din cauza GC în momentele de procesare intensivă a datelor. O soluție bună este creșterea volumului celulei în cazul scrierii active prin put în același timp cu citirea. Este de remarcat faptul că problema nu apare dacă, după înregistrare, rulați comanda de golire, care resetează MemStore pe disc, sau dacă încărcați folosind BulkLoad. Tabelul de mai jos arată că interogările din MemStore pentru date mai mari (și aceeași cantitate) duc la încetiniri. Cu toate acestea, prin creșterea dimensiunii bucăților, readucem timpul de procesare la normal.
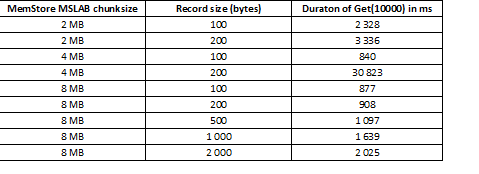
Pe lângă creșterea dimensiunii bucăților, împărțirea datelor în funcție de regiune ajută, de exemplu. împărțirea mesei. Acest lucru are ca rezultat mai puține solicitări care vin în fiecare regiune și dacă se potrivesc într-o celulă, răspunsul rămâne bun.
6. Strategie pentru împărțirea tabelelor în regiuni (diviziunea)
Deoarece HBase este o stocare cheie-valoare și partiționarea se realizează prin cheie, este extrem de important să împărțiți datele în mod egal în toate regiunile. De exemplu, împărțirea unui astfel de tabel în trei părți va duce la împărțirea datelor în trei regiuni:
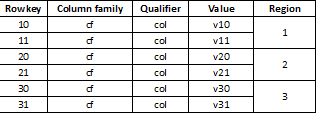
Se întâmplă că acest lucru duce la o încetinire bruscă dacă datele încărcate ulterior arată ca, de exemplu, valori lungi, majoritatea începând cu aceeași cifră, de exemplu:
1000001
1000002
...
1100003
Deoarece cheile sunt stocate ca o matrice de octeți, toate vor începe la fel și vor aparține aceleiași regiuni #1 care stochează acest interval de chei. Există mai multe strategii de partiționare:
HexStringSplit – Transformă cheia într-un șir codificat hexazecimal în intervalul „00000000” => „FFFFFFFF” și umplutură în stânga cu zerouri.
UniformSplit – Transformă cheia într-o matrice de octeți cu codificare hexazecimală în intervalul „00” => „FF” și umplutură în dreapta cu zerouri.
În plus, puteți specifica orice interval sau set de taste pentru împărțire și configurați împărțirea automată. Cu toate acestea, una dintre cele mai simple și mai eficiente abordări este UniformSplit și utilizarea concatenării hash, de exemplu cea mai semnificativă pereche de octeți de la rularea cheii prin funcția CRC32(rowkey) și rowkey în sine:
hash + rowkey
Apoi, toate datele vor fi distribuite uniform între regiuni. La citire, primii doi octeți sunt pur și simplu aruncați și cheia originală rămâne. RS controlează, de asemenea, cantitatea de date și chei din regiune și, dacă limitele sunt depășite, o împarte automat în părți.
7. Toleranță la erori și localitatea datelor
Deoarece o singură regiune este responsabilă pentru fiecare set de chei, soluția pentru problemele asociate cu blocările sau dezafectarea RS este de a stoca toate datele necesare în HDFS. Când RS cade, comandantul detectează acest lucru prin absența unei bătăi a inimii pe nodul ZooKeeper. Apoi atribuie regiunea deservită unui alt RS și, deoarece fișierele HF sunt stocate într-un sistem de fișiere distribuit, noul proprietar le citește și continuă să servească datele. Cu toate acestea, deoarece unele dintre date pot fi în MemStore și nu au avut timp să intre în HFiles, WAL, care este stocat și în HDFS, este folosit pentru a restabili istoricul operațiunilor. După aplicarea modificărilor, RS este capabil să răspundă solicitărilor, dar mutarea duce la faptul că unele dintre date și procesele care le deservesc ajung pe noduri diferite, de exemplu. localitatea este în scădere.
Soluția problemei este compactarea majoră - această procedură mută fișierele în acele noduri care sunt responsabile pentru ele (unde se află regiunile lor), drept urmare, în timpul acestei proceduri, încărcarea rețelei și a discurilor crește brusc. Cu toate acestea, în viitor, accesul la date este vizibil accelerat. În plus, major_compaction realizează îmbinarea tuturor fișierelor HF într-un singur fișier dintr-o regiune și, de asemenea, curăță datele în funcție de setările tabelului. De exemplu, puteți specifica numărul de versiuni ale unui obiect care trebuie reținute sau durata de viață după care obiectul este șters fizic.
Această procedură poate avea un efect foarte pozitiv asupra funcționării HBasei. Imaginea de mai jos arată cum s-a degradat performanța ca urmare a înregistrării active a datelor. Aici puteți vedea cum 40 de fire au scris într-un tabel și 40 de fire au citit simultan date. Firele de scriere generează tot mai multe fișiere HF, care sunt citite de alte fire. Drept urmare, din ce în ce mai multe date trebuie să fie eliminate din memorie și în cele din urmă GC începe să funcționeze, ceea ce practic paralizează toată munca. Lansarea compactării majore a dus la curățarea resturilor rezultate și la restabilirea productivității.
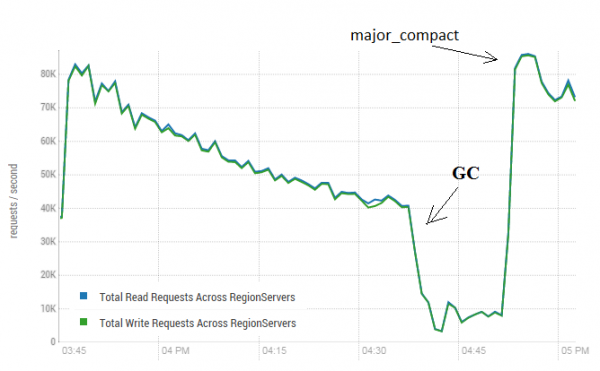
Testul a fost efectuat pe 3 DataNodes și 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 fire). HBase versiunea 1.2.0-cdh5.14.2
Este de remarcat faptul că compactarea majoră a fost lansată pe un tabel „în direct”, în care datele au fost scrise și citite în mod activ. A existat o declarație online că acest lucru ar putea duce la un răspuns incorect la citirea datelor. Pentru a verifica, a fost lansat un proces care a generat date noi și le-a scris într-un tabel. După care am citit imediat și am verificat dacă valoarea rezultată coincide cu ceea ce era notat. În timp ce acest proces a fost în derulare, compactarea majoră a fost efectuată de aproximativ 200 de ori și nu a fost înregistrată o singură defecțiune. Poate că problema apare rar și numai în timpul încărcării mari, așa că este mai sigur să opriți procesele de scriere și citire așa cum a fost planificat și să efectuați curățarea pentru a preveni astfel de reduceri ale GC.
De asemenea, compactarea majoră nu afectează starea MemStore; pentru a-l spăla pe disc și pentru a-l compacta, trebuie să utilizați flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Setări și performanță
După cum am menționat deja, HBase își arată cel mai mare succes acolo unde nu trebuie să facă nimic, atunci când execută BulkLoad. Cu toate acestea, acest lucru se aplică majorității sistemelor și oamenilor. Cu toate acestea, acest instrument este mai potrivit pentru stocarea datelor în vrac în blocuri mari, în timp ce, dacă procesul necesită mai multe solicitări concurente de citire și scriere, se folosesc comenzile Get și Put descrise mai sus. Pentru a determina parametrii optimi, lansările au fost efectuate cu diferite combinații de parametri și setări de tabel:
- Au fost lansate 10 fire simultan de 3 ori la rând (să numim asta un bloc de fire).
- Timpul de funcționare al tuturor firelor dintr-un bloc a fost mediat și a fost rezultatul final al funcționării blocului.
- Toate firele au lucrat cu aceeași masă.
- Înainte de fiecare pornire a blocului de filet, a fost efectuată o compactare majoră.
- Fiecare bloc a efectuat doar una dintre următoarele operații:
-A pune
- Obține
— Ia+Pune
- Fiecare bloc a efectuat 50 de iterații ale funcționării sale.
- Dimensiunea blocului unei înregistrări este de 100 de octeți, 1000 de octeți sau 10000 de octeți (aleatoriu).
- Blocurile au fost lansate cu numere diferite de chei solicitate (fie o cheie, fie 10).
- Blocurile au fost rulate în diferite setări ale tabelului. Parametri modificați:
— BlockCache = activat sau dezactivat
— BlockSize = 65 KB sau 16 KB
— Partiții = 1, 5 sau 30
— MSLAB = activat sau dezactivat
Deci blocul arată astfel:
A. Modul MSLAB a fost pornit/dezactivat.
b. A fost creat un tabel pentru care au fost setati urmatorii parametri: BlockCache = true/none, BlockSize = 65/16 Kb, Partition = 1/5/30.
c. Compresia a fost setată la GZ.
d. Au fost lansate 10 fire de execuție simultan, făcând operații de 1/10 put/get/get+put în acest tabel cu înregistrări de 100/1000/10000 octeți, efectuând 50 de interogări la rând (chei aleatorii).
e. Punctul d a fost repetat de trei ori.
f. Durata de funcționare a tuturor firelor a fost mediată.
Au fost testate toate combinațiile posibile. Este previzibil că viteza va scădea pe măsură ce dimensiunea înregistrării crește sau că dezactivarea memoriei cache va duce la încetinirea vitezei. Cu toate acestea, scopul a fost de a înțelege gradul și semnificația influenței fiecărui parametru, astfel încât datele colectate au fost introduse în intrarea unei funcții de regresie liniară, ceea ce face posibilă evaluarea semnificației folosind t-statistici. Mai jos sunt rezultatele blocurilor care efectuează operațiuni Put. Set complet de combinații 2*2*3*2*3 = 144 opțiuni + 72 tk. unele au fost făcute de două ori. Prin urmare, sunt 216 rulări în total:
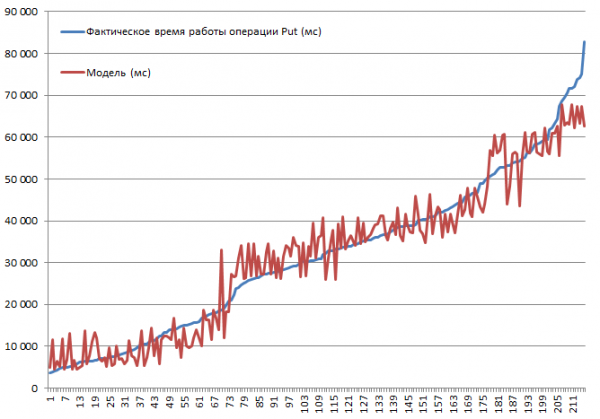
Testarea a fost efectuată pe un mini-cluster format din 3 DataNodes și 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 fire). HBase versiunea 1.2.0-cdh5.14.2.
Cea mai mare viteză de inserare de 3.7 secunde a fost obținută cu modul MSLAB dezactivat, pe o masă cu o partiție, cu BlockCache activat, BlockSize = 16, înregistrări de 100 de octeți, 10 bucăți per pachet.
Cea mai mică viteză de inserare de 82.8 sec a fost obținută cu modul MSLAB activat, pe un tabel cu o partiție, cu BlockCache activat, BlockSize = 16, înregistrări de 10000 de octeți, câte 1 fiecare.
Acum să ne uităm la model. Vedem calitatea bună a modelului bazat pe R2, dar este absolut clar că extrapolarea este contraindicată aici. Comportamentul actual al sistemului atunci când parametrii se modifică nu va fi liniar; acest model este necesar nu pentru predicții, ci pentru înțelegerea a ceea ce s-a întâmplat în parametrii dați. De exemplu, aici vedem din criteriul Studentului că parametrii BlockSize și BlockCache nu contează pentru operația Put (care este în general destul de previzibilă):

Dar faptul că creșterea numărului de partiții duce la o scădere a performanței este oarecum neașteptat (am văzut deja impactul pozitiv al creșterii numărului de partiții cu BulkLoad), deși de înțeles. În primul rând, pentru procesare, trebuie să generați cereri către 30 de regiuni în loc de una, iar volumul de date nu este de așa natură încât acest lucru să producă un câștig. În al doilea rând, timpul total de funcționare este determinat de cel mai lent RS și, deoarece numărul de DataNodes este mai mic decât numărul de RS, unele regiuni au localitate zero. Ei bine, să ne uităm la primele cinci:

Acum să evaluăm rezultatele executării blocurilor Get:

Numărul de partiții și-a pierdut semnificația, ceea ce se explică probabil prin faptul că datele sunt bine stocate în cache și cache-ul de citit este cel mai semnificativ parametru (statistic). Desigur, creșterea numărului de mesaje dintr-o solicitare este, de asemenea, foarte utilă pentru performanță. Scoruri de top:

Ei bine, în sfârșit, să ne uităm la modelul blocului care a efectuat prima dată obține și apoi a pus:

Toți parametrii sunt importanți aici. Și rezultatele liderilor:

9. Testarea sarcinii
Ei bine, în sfârșit vom lansa o încărcătură mai mult sau mai puțin decentă, dar este întotdeauna mai interesant când ai ceva cu care să compari. Pe site-ul DataStax, dezvoltatorul cheie al Cassandra, există NT a unui număr de stocări NoSQL, inclusiv versiunea HBase 0.98.6-1. Încărcarea a fost efectuată de 40 de fire, dimensiunea datelor 100 de octeți, discuri SSD. Rezultatul testării operațiunilor de citire-modificare-scriere a arătat următoarele rezultate.
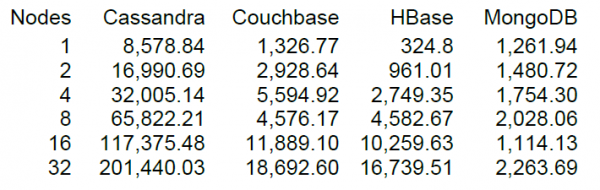
Din câte am înțeles, citirea a fost efectuată în blocuri de 100 de înregistrări și pentru 16 noduri HBase, testul DataStax a arătat o performanță de 10 mii de operații pe secundă.
Este norocos că clusterul nostru are și 16 noduri, dar nu este foarte „norocos” că fiecare are 64 de nuclee (thread-uri), în timp ce la testul DataStax sunt doar 4. Pe de altă parte, au unități SSD, în timp ce noi avem HDD-uri sau mai mult, noua versiune a HBase și utilizarea procesorului în timpul încărcării practic nu a crescut semnificativ (vizual cu 5-10 la sută). Cu toate acestea, să încercăm să începem să folosim această configurație. Setările implicite ale tabelului, citirea este efectuată în intervalul de cheie de la 0 la 50 de milioane aleatoriu (adică, în esență nouă de fiecare dată). Tabelul conține 50 de milioane de înregistrări, împărțite în 64 de partiții. Cheile sunt indexate folosind crc32. Setările tabelului sunt implicite, MSLAB este activat. Lansând 40 de fire, fiecare fir citește un set de 100 de chei aleatorii și scrie imediat cei 100 de octeți generați înapoi la aceste chei.
Stand: 16 DataNode și 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 fire). HBase versiunea 1.2.0-cdh5.14.2.
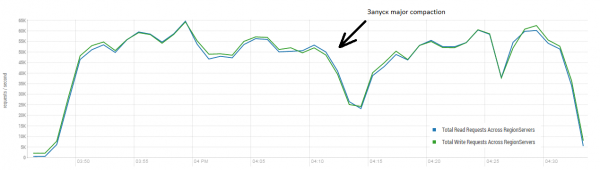
Rezultatul mediu este mai aproape de 40 de mii de operații pe secundă, ceea ce este semnificativ mai bun decât în testul DataStax. Cu toate acestea, în scopuri experimentale, puteți modifica ușor condițiile. Este destul de puțin probabil ca toate lucrările să fie efectuate exclusiv pe o singură masă și, de asemenea, numai pe chei unice. Să presupunem că există un anumit set „fierbinte” de chei care generează sarcina principală. Prin urmare, să încercăm să creăm o încărcare cu înregistrări mai mari (10 KB), tot în loturi de 100, în 4 tabele diferite și limitând gama de chei solicitate la 50 de mii. Graficul de mai jos arată lansarea a 40 de fire, fiecare thread citește un set de 100 de chei și imediat scrie aleatoriu 10 KB pe spatele acestor chei.
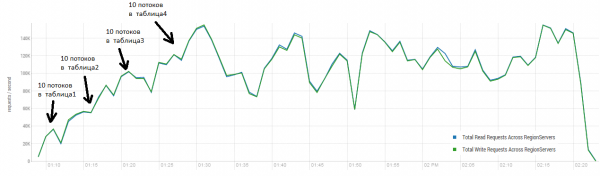
Stand: 16 DataNode și 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 fire). HBase versiunea 1.2.0-cdh5.14.2.
În timpul încărcării, compactarea majoră a fost lansată de mai multe ori, așa cum se arată mai sus, fără această procedură, performanța se va degrada treptat, cu toate acestea, apare și sarcina suplimentară în timpul execuției. Retragerile sunt cauzate de diverse motive. Uneori firele de execuție s-au terminat de funcționare și a existat o pauză în timp ce au fost repornite, uneori aplicațiile terță parte au creat o încărcare pe cluster.
Citirea și scrisul imediat este unul dintre cele mai dificile scenarii de lucru pentru HBase. Dacă faceți doar cereri mici de introducere, de exemplu 100 de octeți, combinându-le în pachete de 10-50 de mii de bucăți, puteți obține sute de mii de operații pe secundă, iar situația este similară cu cererile doar în citire. Este de remarcat faptul că rezultatele sunt radical mai bune decât cele obținute de DataStax, mai ales datorită solicitărilor în blocuri de 50 de mii.
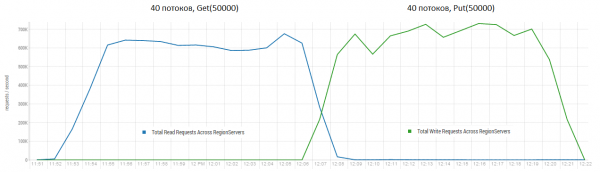
Stand: 16 DataNode și 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 fire). HBase versiunea 1.2.0-cdh5.14.2.
10. Concluzii
Acest sistem este configurat destul de flexibil, dar influența unui număr mare de parametri rămâne încă necunoscută. Unele dintre ele au fost testate, dar nu au fost incluse în setul de teste rezultat. De exemplu, experimentele preliminare au arătat o semnificație nesemnificativă a unui astfel de parametru precum DATA_BLOCK_ENCODING, care codifică informații folosind valori din celulele învecinate, ceea ce este de înțeles pentru datele generate aleatoriu. Dacă utilizați un număr mare de obiecte duplicate, câștigul poate fi semnificativ. În general, putem spune că HBase dă impresia unei baze de date destul de serioase și bine gândite, care poate fi destul de productivă atunci când se efectuează operațiuni cu blocuri mari de date. Mai ales dacă este posibilă separarea în timp a proceselor de citire și scriere.
Dacă în opinia dumneavoastră există ceva care nu este suficient dezvăluit, sunt gata să vă spun mai detaliat. Vă invităm să vă împărtășiți experiența sau să discutați dacă nu sunteți de acord cu ceva.
Sursa: www.habr.com
