


preistorie
S-a întâmplat că serverul a fost atacat de un virus ransomware, care, printr-un „accident norocos”, a lăsat parțial neatins fișierele .ibd (fișierele de date brute ale tabelelor innodb), dar în același timp a criptat complet fișierele .fpm ( fișiere de structură). În acest caz, .idb poate fi împărțit în:
- supuse restaurării prin instrumente și ghidaje standard. Pentru astfel de cazuri, există o excelentă ;
- tabele parțial criptate. De cele mai multe ori acestea sunt tabele mari, pentru care (după cum am înțeles) atacatorii nu au avut suficientă memorie RAM pentru criptarea completă;
- Ei bine, tabele complet criptate care nu pot fi restaurate.
A fost posibil să se determine cărei opțiuni aparțin tabelele prin simpla deschidere în orice editor de text sub codificarea dorită (în cazul meu este UTF8) și pur și simplu vizualizarea fișierului pentru prezența câmpurilor de text, de exemplu:
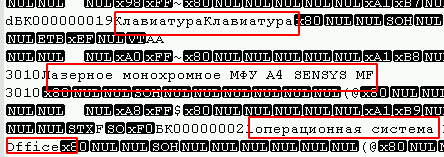
De asemenea, la începutul fișierului puteți observa un număr mare de 0 octeți, iar virușii care folosesc algoritmul de criptare bloc (cel mai comun) îi afectează de obicei și pe aceștia.
![]()
În cazul meu, atacatorii au lăsat un șir de 4 octeți (1, 0, 0, 0) la sfârșitul fiecărui fișier criptat, ceea ce a simplificat sarcina. Pentru a căuta fișiere neinfectate, scriptul a fost suficient:
def opened(path):
files = os.listdir(path)
for f in files:
if os.path.isfile(path + f):
yield path + f
for full_path in opened("C:somepath"):
file = open(full_path, "rb")
last_string = ""
for line in file:
last_string = line
file.close()
if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0):
print(full_path)Astfel, s-a dovedit a găsi fișiere aparținând primului tip. Al doilea implică multă muncă manuală, dar ceea ce s-a găsit a fost deja suficient. Totul ar fi bine, dar trebuie să știi structură absolut precisă și (desigur) a apărut un caz în care a trebuit să lucrez cu o masă care se schimbă frecvent. Nimeni nu și-a amintit dacă tipul câmpului a fost modificat sau a fost adăugată o nouă coloană.
Wilds City, din păcate, nu a putut ajuta cu un astfel de caz, motiv pentru care se scrie acest articol.
Treci la subiect
Există o structură a unui tabel de acum 3 luni care nu coincide cu cel actual (eventual un câmp, și eventual mai multe). Structura tabelului:
CREATE TABLE `table_1` (
`id` INT (11),
`date` DATETIME ,
`description` TEXT ,
`id_point` INT (11),
`id_user` INT (11),
`date_start` DATETIME ,
`date_finish` DATETIME ,
`photo` INT (1),
`id_client` INT (11),
`status` INT (1),
`lead__time` TIME ,
`sendstatus` TINYINT (4)
); în acest caz, trebuie să extrageți:
id_pointint(11);id_userint(11);date_startDATETIME;date_finishDATETIME.
Pentru recuperare, se folosește o analiză octet cu octet a fișierului .ibd, urmată de conversia acestora într-o formă mai lizibilă. Deoarece pentru a găsi ceea ce avem nevoie, trebuie doar să analizăm tipuri de date precum int și datatime, articolul le va descrie doar pe acestea, dar uneori ne vom referi și la alte tipuri de date, care pot ajuta în alte incidente similare.
Problema 1: câmpurile cu tipurile DATETIME și TEXT au avut valori NULL și pur și simplu sunt omise în fișier, din această cauză, nu a fost posibil să se determine structura de restaurat în cazul meu. În noile coloane, valoarea implicită a fost nulă și o parte din tranzacție ar putea fi pierdută din cauza setării innodb_flush_log_at_trx_commit = 0, deci ar trebui să se aloce timp suplimentar pentru a determina structura.
Problema 2: trebuie luat în considerare faptul că rândurile șterse prin DELETE vor fi toate în fișierul ibd, dar cu ALTER TABLE structura lor nu va fi actualizată. Ca rezultat, structura datelor poate varia de la începutul fișierului până la sfârșitul acestuia. Dacă folosiți adesea OPTIMIZE TABLE, atunci este puțin probabil să întâlniți o astfel de problemă.
Nota, versiunea SGBD afectează modul în care sunt stocate datele și este posibil ca acest exemplu să nu funcționeze pentru alte versiuni majore. În cazul meu, a fost folosită versiunea pentru Windows a mariadb 10.1.24. De asemenea, deși în mariadb lucrezi cu tabele InnoDB, de fapt sunt , care exclude aplicabilitatea metodei cu InnoDB mysql.
Analiza dosarului
În python, tipul de date afișează date Unicode în locul unui set obișnuit de numere. Deși puteți vizualiza fișierul în această formă, pentru comoditate, puteți converti octeții în formă numerică prin conversia matricei de octeți într-o matrice obișnuită (list(example_byte_array)). În orice caz, ambele metode sunt potrivite pentru analiză.
După ce ați căutat prin mai multe fișiere ibd, puteți găsi următoarele:
![]()
În plus, dacă împărțiți fișierul la aceste cuvinte cheie, veți obține în mare parte chiar și blocuri de date. Vom folosi infimum ca divizor.
table = table.split("infimum".encode())O observație interesantă: pentru tabelele cu o cantitate mică de date, între infimum și supremum există un indicator către numărul de rânduri din bloc.
![]() — tabel de testare cu primul rând
— tabel de testare cu primul rând
![]() - tabel de testare cu 2 rânduri
- tabel de testare cu 2 rânduri
Tabelul de matrice de rânduri[0] poate fi omis. După ce am căutat prin el, încă nu am putut găsi datele brute din tabel. Cel mai probabil, acest bloc este folosit pentru a stoca indecși și chei.
Începând cu tabelul[1] și transpunându-l într-o matrice numerică, puteți observa deja câteva modele, și anume:

Acestea sunt valori int stocate într-un șir. Primul octet indică dacă numărul este pozitiv sau negativ. În cazul meu, toate cifrele sunt pozitive. Din cei 3 octeți rămași, puteți determina numărul folosind următoarea funcție. Scenariul:
def find_int(val: str): # example '128, 1, 2, 3'
val = [int(v) for v in val.split(", ")]
result_int = val[1]*256**2 + val[2]*256*1 + val[3]
return result_intDe exemplu, 128, 0, 0, 1 = 1Sau 128, 0, 75, 108 = 19308.
Tabelul avea o cheie primară cu incrementare automată și poate fi găsită și aici

După ce au comparat datele din tabelele de testare, s-a dezvăluit că obiectul DATETIME este format din 5 octeți și a început cu 153 (cel mai probabil indicând intervale anuale). Deoarece intervalul DATTIME este de la „1000-01-01” la „9999-12-31”, cred că numărul de octeți poate varia, dar în cazul meu, datele se încadrează în perioada 2016-2019, așa că vom presupune acei 5 octeți sunt suficienti.
Pentru a determina timpul fără secunde, au fost scrise următoarele funcții. Scenariul:
day_ = lambda x: x % 64 // 2 # {x,x,X,x,x }
def hour_(x1, x2): # {x,x,X1,X2,x}
if x1 % 2 == 0:
return x2 // 16
elif x1 % 2 == 1:
return x2 // 16 + 16
else:
raise ValueError
min_ = lambda x1, x2: (x1 % 16) * 4 + (x2 // 64) # {x,x,x,X1,X2}Nu a fost posibil să scriu o funcție funcțională pentru an și lună, așa că a trebuit să o piratez. Scenariul:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128',
'2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0',
'2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128',
'2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0',
'2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128',
'2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0',
'2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192',
'2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64',
'2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192',
'2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64',
'2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192',
'2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64',
'2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0',
'2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128',
'2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0',
'2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128',
'2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0',
'2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128',
'2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64',
'2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192',
'2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64',
'2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192',
'2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64',
'2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192',
'2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128',
'2020, 3': '153, 165, 192','2020, 4': '153, 166, 0',
'2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128',
'2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0',
'2020, 9': '153, 167, 64','2020, 10': '153, 167, 128',
'2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'}
def year_month(x1, x2): # {x,X,X,x,x }
for key, value in ym_list.items():
key = [int(k) for k in key.replace("'", "").split(", ")]
value = [int(v) for v in value.split(", ")]
if x1 == value[1] and x2 // 64 == value[2] // 64:
return key
return 0, 0Sunt sigur că dacă petreceți n timp, această neînțelegere poate fi corectată.
Apoi, o funcție care returnează un obiect datetime dintr-un șir. Scenariul:
def find_data_time(val:str):
val = [int(v) for v in val.split(", ")]
day = day_(val[2])
hour = hour_(val[2], val[3])
minutes = min_(val[3], val[4])
year, month = year_month(val[1], val[2])
return datetime(year, month, day, hour, minutes)A reușit să detecteze valori repetate frecvent de la int, int, datetime, datetime ![]() , se pare că acesta este ceea ce aveți nevoie. Mai mult, o astfel de secvență nu se repetă de două ori pe linie.
, se pare că acesta este ceea ce aveți nevoie. Mai mult, o astfel de secvență nu se repetă de două ori pe linie.
Folosind o expresie regulată, găsim datele necesare:
fined = re.findall(r'128, d*, d*, d*, 128, d*, d*, d*, 153, 1[6,5,4,3]d, d*, d*, d*, 153, 1[6,5,4,3]d, d*, d*, d*', int_array)Vă rugăm să rețineți că atunci când căutați folosind această expresie, nu va fi posibil să determinați valori NULL în câmpurile obligatorii, dar în cazul meu acest lucru nu este critic. Apoi trecem prin ceea ce am găsit într-o buclă. Scenariul:
result = []
for val in fined:
pre_result = []
bd_int = re.findall(r"128, d*, d*, d*", val)
bd_date= re.findall(r"(153, 1[6,5,4,3]d, d*, d*, d*)", val)
for it in bd_int:
pre_result.append(find_int(bd_int[it]))
for bd in bd_date:
pre_result.append(find_data_time(bd))
result.append(pre_result)De fapt, asta este tot, datele din matricea de rezultate sunt datele de care avem nevoie. ###PS.###
Înțeleg că această metodă nu este potrivită pentru toată lumea, dar scopul principal al articolului este să acționeze mai degrabă decât să-ți rezolvi toate problemele. Cred că cea mai corectă soluție ar fi să începi să studiezi singur codul sursă , dar din cauza timpului limitat, metoda actuală părea a fi cea mai rapidă.
În unele cazuri, după analizarea fișierului, veți putea determina structura aproximativă și o veți restaura folosind una dintre metodele standard din linkurile de mai sus. Acest lucru va fi mult mai corect și va cauza mai puține probleme.
Sursa: www.habr.com
