


Dobrý deň, nedávno som narazil na zaujímavý problém: nastavenie úložiska na zálohovanie veľkého počtu blokových zariadení.
Každý týždeň zálohujeme všetky virtuálne stroje v našom cloude, takže musíme byť schopní obsluhovať tisíce záloh a robiť to čo najrýchlejšie a najefektívnejšie.
Bohužiaľ, štandardné konfigurácie RAID5, RAID6 v tomto prípade nám to nebude umožnené, keďže proces obnovy na takých veľkých diskoch, ako je ten náš, bude bolestivo dlhý a s najväčšou pravdepodobnosťou sa nikdy neskončí.
Pozrime sa, aké alternatívy existujú:
— Podobné ako RAID5, RAID6, ale s konfigurovateľnou úrovňou parity. V tomto prípade sa rezervácia vykonáva nie blok po bloku, ale pre každý objekt samostatne. Najjednoduchší spôsob, ako vyskúšať kódovanie vymazania, je rozšíriť .
je momentálne nevydaná funkcia ZFS. Na rozdiel od RAIDZ má DRAID distribuovaný blok parity a počas obnovy využíva všetky disky poľa naraz, vďaka čomu dokáže lepšie prežiť zlyhania disku a rýchlejšie sa po zlyhaní obnoviť.


K dispozícii je server Fujitsu Primergy RX300 S7 s procesorom Procesor Intel Xeon E5-2650L 0 @ 1.80 GHz, deväť kusov pamäte RAM Samsung DDR3-1333 8Gb PC3L-10600R registrovaný ECC (M393B1K70DH0-YH9), polica na disky Supermicro SuperChassis 847E26-RJBOD1, pripojený cez Duálny expandér LSI SAS2X36 a 45 diskov Seagage ST6000NM0115-1YZ110 na 6TB každej z nich.
Predtým, ako sa pre čokoľvek rozhodneme, musíme všetko poriadne otestovať.
K tomu som pripravil a otestoval rôzne konfigurácie. Na to som použil minio, ktoré fungovalo ako backend S3 a spúšťalo ho v rôznych režimoch s rôznym počtom cieľov.
V podstate bolo puzdro minio testované v kódovaní vymazania vs softvérový raid s rovnakým počtom diskov a paritou diskov, a to sú: RAID6, RAIDZ2 a DRAID2.
Pre informáciu: keď minio spustíte len s jedným cieľom, minio bude pracovať v režime brány S3 a poskytne váš lokálny súborový systém vo forme úložiska S3. Ak spustíte minio so špecifikovaním niekoľkých cieľov, automaticky sa zapne režim Erasure Coding, ktorý rozloží údaje medzi vašimi cieľmi a zároveň zabezpečí odolnosť voči chybám.
Štandardne minio rozdeľuje ciele do skupín po 16 diskoch s 2 paritami na skupinu. Tie. Dva disky môžu zlyhať súčasne bez straty dát.
Na testovanie výkonu som použil 16 diskov po 6 TB a napísal som na ne malé objekty s veľkosťou 1 MB, čo najpresnejšie vystihovalo našu budúcu záťaž, keďže všetky moderné zálohovacie nástroje rozdeľujú dáta do blokov s veľkosťou niekoľkých megabajtov a zapisujú ich týmto spôsobom.
Na vykonanie benchmarku sme použili utilitu s3bench, spustenú na vzdialenom serveri a posielajúcu do minia desiatky tisíc takýchto objektov v stovkách vlákien. Potom som sa ich pokúsil požiadať späť rovnakým spôsobom.
Výsledky benchmarku sú uvedené v nasledujúcej tabuľke:
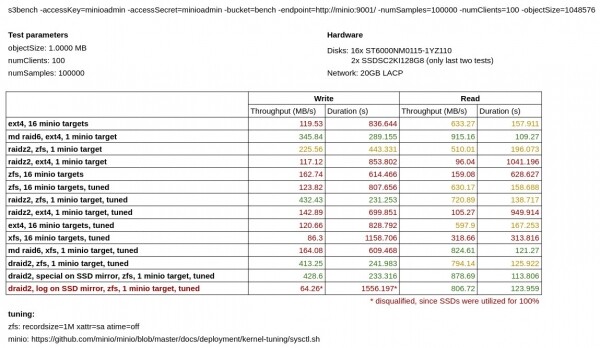
Ako vidíme, minio vo vlastnom režime kódovania vymazania má výrazne horšie výsledky pri zápise ako minio bežiace nad softvérovými RAID6, RAIDZ2 a DRAID2 v rovnakej konfigurácii.
Oddelene ja otestujte minio na ext4 vs XFS. Prekvapivo sa ukázalo, že pre môj typ pracovného zaťaženia je XFS výrazne pomalšie ako ext4.
V prvej sérii testov Mdadm preukázal nadradenosť nad ZFS, ale neskôr že môžete zlepšiť výkon ZFS nastavením nasledujúcich možností:
xattr=sa atime=off recordsize=1Ma potom sa testy so ZFS stali oveľa lepšími.
Môžete si tiež všimnúť, že DRAID neposkytuje veľké zvýšenie výkonu oproti RAIDZ, ale teoreticky by mal byť oveľa bezpečnejší.
V posledných dvoch testoch som skúsil preniesť aj metadáta (špeciálne) a ZIL (log) do zrkadla z SSD. Odstránením metadát sa však rýchlosť nahrávania príliš nezvýšila a pri odstraňovaní ZIL to bolo moje narazil na strop pri 100% využití, takže tento test považujem za neúspešný. Nevylučujem, že keby som mal rýchlejšie SSD disky, možno by to mohlo výrazne zlepšiť moje výsledky, ale bohužiaľ som ich nemal.
Nakoniec som sa rozhodol použiť DRAID a napriek jeho beta stavu je to v našom prípade najrýchlejšie a najefektívnejšie riešenie úložiska.
Vytvoril som jednoduchý DRAID2 v konfigurácii s tromi skupinami a dvoma distribuovanými náhradnými dielmi:
# zpool status data
pool: data
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
draid2:3g:2s-0 ONLINE 0 0 0
sdy ONLINE 0 0 0
sdam ONLINE 0 0 0
sdf ONLINE 0 0 0
sdau ONLINE 0 0 0
sdab ONLINE 0 0 0
sdo ONLINE 0 0 0
sdw ONLINE 0 0 0
sdak ONLINE 0 0 0
sdd ONLINE 0 0 0
sdas ONLINE 0 0 0
sdm ONLINE 0 0 0
sdu ONLINE 0 0 0
sdai ONLINE 0 0 0
sdaq ONLINE 0 0 0
sdk ONLINE 0 0 0
sds ONLINE 0 0 0
sdag ONLINE 0 0 0
sdi ONLINE 0 0 0
sdq ONLINE 0 0 0
sdae ONLINE 0 0 0
sdz ONLINE 0 0 0
sdan ONLINE 0 0 0
sdg ONLINE 0 0 0
sdac ONLINE 0 0 0
sdx ONLINE 0 0 0
sdal ONLINE 0 0 0
sde ONLINE 0 0 0
sdat ONLINE 0 0 0
sdaa ONLINE 0 0 0
sdn ONLINE 0 0 0
sdv ONLINE 0 0 0
sdaj ONLINE 0 0 0
sdc ONLINE 0 0 0
sdar ONLINE 0 0 0
sdl ONLINE 0 0 0
sdt ONLINE 0 0 0
sdah ONLINE 0 0 0
sdap ONLINE 0 0 0
sdj ONLINE 0 0 0
sdr ONLINE 0 0 0
sdaf ONLINE 0 0 0
sdao ONLINE 0 0 0
sdh ONLINE 0 0 0
sdp ONLINE 0 0 0
sdad ONLINE 0 0 0
spares
s0-draid2:3g:2s-0 AVAIL
s1-draid2:3g:2s-0 AVAIL
errors: No known data errorsDobre, vyriešili sme úložisko, teraz sa porozprávajme o tom, čo budeme zálohovať. Tu by som chcel okamžite hovoriť o troch riešeniach, ktoré sa mi podarilo vyskúšať, a to sú:
- vidlička , špecializované riešenie pre zálohovanie blokových zariadení, má úzku integráciu s Ceph. Dokáže vytvárať rozdiely medzi snímkami a vytvárať z nich prírastkovú zálohu. Podporuje veľké množstvo backendov úložiska, vrátane lokálnych a S3. Vyžaduje samostatnú databázu na uloženie deduplikačnej hašovacej tabuľky. Z mínusov: napísané v pythone, má mierne nereagujúce cli.
- vidlička , dlho známy a osvedčený zálohovací nástroj, dokáže zálohovať dáta a dobre ich deduplikovať. Schopný ukladať zálohy lokálne aj na vzdialený server cez scp. Môže zálohovať blokovať zariadenia, ak sú spustené s príznakom --special, jedno z mínusov: pri vytváraní zálohy je úložisko úplne zablokované, preto sa odporúča vytvoriť samostatné úložisko pre každý virtuálny stroj, v princípe to nie je problém, našťastie sa vytvárajú veľmi jednoducho.
je aktívne sa rozvíjajúci projekt, napísaný in go, pomerne rýchly a podporuje veľké množstvo úložných backendov, vrátane lokálneho úložiska, scp, S3 a mnohých ďalších. Samostatne by som chcel poznamenať, že existuje špeciálne vytvorený pre restic, ktorý vám umožňuje rýchlo exportovať úložisko na použitie na diaľku. Zo všetkých vyššie uvedených sa mi to páčilo najviac. Je možné zálohovať z stdin. Nemá takmer žiadne viditeľné nevýhody, ale existuje niekoľko funkcií:
-
Najprv som to skúsil použiť v režime všeobecného úložiska pre všetky virtuálne stroje (ako Benji) a dokonca to fungovalo celkom dobre, ale operácie obnovy trvali veľmi dlho, pretože... Vždy pred obnovením sa Restic pokúsi prečítať metadáta všetkých záloh. Tento problém bol jednoducho vyriešený, rovnako ako v prípade borg, vytvorením samostatného úložiska pre každý virtuálny stroj. Tento prístup sa ukázal ako veľmi efektívny aj pri správe záloh. Samostatné úložiská môžu mať samostatné heslo na prístup k údajom a tiež sa nemusíme báť, že by sa globálne repo nejako zlomilo. Môžete vytvoriť nové úložiská rovnako ľahko ako v zálohe Borg.
V každom prípade sa deduplikácia vykonáva iba vzhľadom na predchádzajúcu verziu zálohy, predchádzajúca záloha je určená cestou pre zadanú zálohu, takže ak zálohujete rôzne objekty zo štandardného adresára do spoločného úložiska, nezabudnite zadať hodnotu; možnosť
--stdin-filenamealebo zakaždým explicitne špecifikujte možnosť--parent.
-
Po druhé, obnovenie na stdout trvá oveľa dlhšie ako obnovenie do súborového systému kvôli jeho paralelnej povahe. V budúcnosti plánujeme pridať užšiu podporu zálohovania pre blokové zariadenia.
-
Po tretie, v súčasnosti sa odporúča používať , pretože verzia 0.9.6 má chybu s dlhými časmi obnovy veľkých súborov.
Aby som otestoval efektivitu zálohovania a rýchlosť zápisu/obnovy zo zálohy, vytvoril som samostatné úložisko a skúsil som zálohovať malý obraz virtuálneho stroja (21 GB). Vykonali sa dve zálohy bez zmeny originálu, pričom sa pomocou každého z uvedených riešení skontrolovalo, ako rýchlejšie/pomalšie boli skopírované deduplikované údaje.
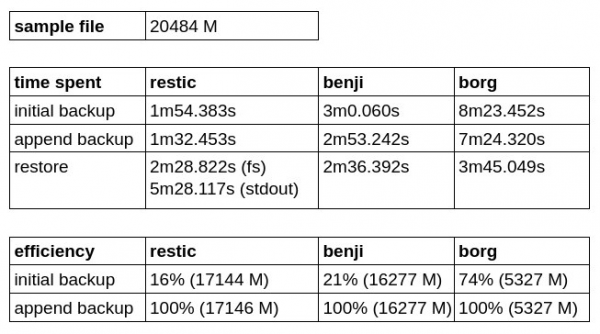
Ako vidíme, Borg Backup má najlepší pomer počiatočnej účinnosti zálohovania, ale je horší z hľadiska rýchlosti zápisu aj obnovy.
Ukázalo sa, že Restic je rýchlejší ako Benji Backup, ale obnovenie na stdout trvá dlhšie a, žiaľ, ešte nevie zapisovať priamo do blokového zariadenia.
Po zvážení všetkých pre a proti som sa rozhodol usadiť zvyšok с oddychový server ako najpohodlnejšie a najsľubnejšie riešenie zálohovania.
Na tomto screencaste môžete vidieť, ako sa 10-gigabitový kanál úplne využíva počas niekoľkých operácií zálohovania súčasne. Stojí za zmienku, že recyklácia diskov nepresahuje 30%.
Bol som viac než spokojný s riešením, ktoré som dostal!
Zdroj: hab.com
