

Sa artikulong ito, pag-uusapan ko kung paano nabago ang proyektong pinagtatrabahuhan ko mula sa isang malaking monolith tungo sa isang set ng mga microservice.
Ang proyekto ay nagsimula sa kasaysayan nito medyo matagal na ang nakalipas, sa simula ng 2000. Ang mga unang bersyon ay isinulat sa Visual Basic 6. Sa paglipas ng panahon, naging malinaw na ang pag-unlad sa wikang ito ay magiging mahirap na suportahan sa hinaharap, dahil ang IDE at ang wika mismo ay hindi gaanong binuo. Sa pagtatapos ng 2000s, napagpasyahan na lumipat sa mas promising C#. Ang bagong bersyon ay isinulat kasabay ng rebisyon ng luma, unti-unting dumami ang code na naisulat sa .NET. Ang backend sa C# ay unang nakatuon sa isang arkitektura ng serbisyo, ngunit sa panahon ng pag-unlad, ginamit ang mga karaniwang aklatan na may lohika, at inilunsad ang mga serbisyo sa isang proseso. Ang resulta ay isang application na tinawag naming "service monolith."
Ang isa sa ilang mga pakinabang ng kumbinasyong ito ay ang kakayahan ng mga serbisyo na tumawag sa isa't isa sa pamamagitan ng isang panlabas na API. Mayroong malinaw na mga kinakailangan para sa paglipat sa isang mas tamang serbisyo, at sa hinaharap, arkitektura ng microservice.
Sinimulan namin ang aming trabaho sa decomposition noong 2015. Hindi pa kami nakakarating sa isang perpektong estado - mayroon pa ring mga bahagi ng isang malaking proyekto na halos hindi matatawag na mga monolith, ngunit hindi rin sila mukhang mga microservice. Gayunpaman, makabuluhan ang pag-unlad.
Pag-uusapan ko ito sa artikulo.
nilalaman
Arkitektura at mga problema ng umiiral na solusyon
Sa una, ang arkitektura ay ganito ang hitsura: ang UI ay isang hiwalay na aplikasyon, ang monolitikong bahagi ay nakasulat sa Visual Basic 6, ang .NET na aplikasyon ay isang hanay ng mga kaugnay na serbisyo na nagtatrabaho sa isang medyo malaking database.
Mga disadvantages ng nakaraang solusyon
Isang punto ng kabiguan
Nagkaroon kami ng isang punto ng pagkabigo: ang .NET application ay tumakbo sa isang proseso. Kung nabigo ang anumang module, nabigo ang buong application at kailangang i-restart. Dahil nag-automate kami ng malaking bilang ng mga proseso para sa iba't ibang mga user, dahil sa isang pagkabigo sa isa sa mga ito, lahat ay hindi maaaring gumana nang ilang oras. At sa kaso ng isang error sa software, kahit na ang backup ay hindi nakatulong.
Pila ng mga pagpapabuti
Ang disbentaha na ito ay medyo pang-organisasyon. Ang aming application ay may maraming mga customer, at lahat sila ay nais na mapabuti ito sa lalong madaling panahon. Noong nakaraan, imposibleng gawin ito nang magkatulad, at ang lahat ng mga customer ay nakatayo sa linya. Negatibo ang prosesong ito para sa mga negosyo dahil kailangan nilang patunayan na mahalaga ang kanilang gawain. At gumugol ng oras ang development team sa pag-aayos ng pila na ito. Ito ay tumagal ng maraming oras at pagsisikap, at ang produkto sa huli ay hindi maaaring magbago nang mabilis hangga't gusto nila.
Suboptimal na paggamit ng mga mapagkukunan
Kapag nagho-host ng mga serbisyo sa isang proseso, lagi naming ganap na kinokopya ang configuration mula sa server patungo sa server. Nais naming ilagay nang hiwalay ang mga serbisyong may pinakamaraming load upang hindi masayang ang mga mapagkukunan at makakuha ng mas nababaluktot na kontrol sa aming deployment scheme.
Mahirap ipatupad ang mga makabagong teknolohiya
Isang problema na pamilyar sa lahat ng mga developer: may pagnanais na ipakilala ang mga modernong teknolohiya sa proyekto, ngunit walang pagkakataon. Sa isang malaking monolitikong solusyon, ang anumang pag-update ng kasalukuyang aklatan, hindi sa banggitin ang paglipat sa isang bago, ay nagiging isang medyo di-maliit na gawain. Ito ay tumatagal ng mahabang panahon upang patunayan sa pinuno ng koponan na ito ay magdadala ng higit pang mga bonus kaysa sa mga nasayang na nerbiyos.
Kahirapan sa pagbibigay ng mga pagbabago
Ito ang pinakamabigat na problema - naglalabas kami ng mga release tuwing dalawang buwan.
Ang bawat paglabas ay naging isang tunay na sakuna para sa bangko, sa kabila ng pagsubok at pagsisikap ng mga developer. Naunawaan ng negosyo na sa simula ng linggo ang ilan sa mga functionality nito ay hindi gagana. At naunawaan ng mga developer na isang linggo ng mga seryosong insidente ang naghihintay sa kanila.
Lahat ay nagkaroon ng pagnanais na baguhin ang sitwasyon.
Mga inaasahan mula sa mga microservice
Isyu ng mga sangkap kapag handa na. Paghahatid ng mga bahagi kapag handa na sa pamamagitan ng pagbubulok ng solusyon at paghihiwalay ng iba't ibang proseso.
Mga maliliit na pangkat ng produkto. Mahalaga ito dahil mahirap pangasiwaan ang isang malaking pangkat na nagtatrabaho sa lumang monolith. Ang nasabing pangkat ay pinilit na magtrabaho ayon sa isang mahigpit na proseso, ngunit gusto nila ng higit na pagkamalikhain at kalayaan. Ang mga maliliit na koponan lamang ang kayang bayaran ito.
Paghihiwalay ng mga serbisyo sa magkakahiwalay na proseso. Sa isip, gusto kong ihiwalay ito sa mga lalagyan, ngunit ang isang malaking bilang ng mga serbisyong nakasulat sa .NET Framework ay tumatakbo lamang sa ilalim ng WindowsLumilitaw na ngayon ang mga serbisyong nakabatay sa .NET Core, ngunit kakaunti pa rin ang mga ito.
Kakayahang umangkop sa pag-deploy. Gusto naming pagsamahin ang mga serbisyo sa paraang kailangan namin, at hindi sa paraan na pinipilit ito ng code.
Paggamit ng mga bagong teknolohiya. Ito ay kawili-wili sa sinumang programmer.
Mga problema sa paglipat
Siyempre, kung madaling masira ang isang monolith sa mga microservice, hindi na kailangang pag-usapan ito sa mga kumperensya at magsulat ng mga artikulo. Maraming mga pitfalls sa prosesong ito; ilalarawan ko ang mga pangunahing hadlang sa amin.
Unang problema tipikal para sa karamihan ng mga monolith: pagkakaugnay ng lohika ng negosyo. Kapag nagsusulat kami ng monolith, gusto naming muling gamitin ang aming mga klase upang hindi magsulat ng hindi kinakailangang code. At kapag lumipat sa mga microservice, nagiging problema ito: ang lahat ng code ay mahigpit na pinagsama, at mahirap paghiwalayin ang mga serbisyo.
Sa oras ng pagsisimula ng trabaho, ang imbakan ay may higit sa 500 mga proyekto at higit sa 700 libong mga linya ng code. Ito ay isang malaking desisyon at pangalawang problema. Hindi posible na kunin lang ito at hatiin sa mga microservice.
Pangatlong problema - kakulangan ng kinakailangang imprastraktura. Sa katunayan, manu-mano naming kinokopya ang source code sa mga server.
Paano lumipat mula sa monolith patungo sa mga microservice
Paglalaan ng mga microservice
Una, agad naming natukoy para sa aming sarili na ang paghihiwalay ng mga microservice ay isang umuulit na proseso. Palagi kaming kinakailangan na bumuo ng mga problema sa negosyo nang magkatulad. Kung paano natin ito ipapatupad sa teknikal ay problema na natin. Samakatuwid, naghanda kami para sa isang umuulit na proseso. Hindi ito gagana sa ibang paraan kung mayroon kang malaking application at hindi pa ito handang isulat muli.
Anong mga pamamaraan ang ginagamit namin upang ihiwalay ang mga microservice?
Ang unang paraan — ilipat ang mga kasalukuyang module bilang mga serbisyo. Kaugnay nito, masuwerte kami: mayroon nang mga rehistradong serbisyo na gumana gamit ang WCF protocol. Sila ay pinaghiwalay sa magkakahiwalay na mga asamblea. Inilipat namin ang mga ito nang hiwalay, nagdaragdag ng isang maliit na launcher sa bawat build. Ito ay isinulat gamit ang kahanga-hangang Topshelf library, na nagbibigay-daan sa iyong patakbuhin ang application bilang isang serbisyo at bilang isang console. Ito ay maginhawa para sa pag-debug dahil walang karagdagang mga proyekto ang kinakailangan sa solusyon.
Ang mga serbisyo ay konektado ayon sa lohika ng negosyo, dahil gumamit sila ng mga karaniwang pagtitipon at nagtrabaho sa isang karaniwang database. Halos hindi sila matatawag na mga microservice sa kanilang purong anyo. Gayunpaman, maaari naming ibigay ang mga serbisyong ito nang hiwalay, sa iba't ibang proseso. Ito lamang ang naging posible upang mabawasan ang kanilang impluwensya sa isa't isa, na binabawasan ang problema sa parallel na pag-unlad at isang solong punto ng kabiguan.
Ang pagpupulong kasama ang host ay isang linya lamang ng code sa klase ng Programa. Itinago namin ang trabaho sa Topshelf sa isang auxiliary class.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Ang pangalawang paraan upang maglaan ng mga microservice ay: lumikha ng mga ito upang malutas ang mga bagong problema. Kung sa parehong oras ang monolith ay hindi lumalaki, ito ay mahusay na, na nangangahulugan na tayo ay gumagalaw sa tamang direksyon. Upang malutas ang mga bagong problema, sinubukan naming lumikha ng hiwalay na mga serbisyo. Kung nagkaroon ng ganoong pagkakataon, lumikha kami ng higit pang "canonical" na mga serbisyo na ganap na namamahala ng kanilang sariling modelo ng data, isang hiwalay na database.
Kami, tulad ng marami, ay nagsimula sa mga serbisyo ng pagpapatunay at awtorisasyon. Ang mga ito ay perpekto para dito. Ang mga ito ay independyente, bilang isang patakaran, mayroon silang isang hiwalay na modelo ng data. Sila mismo ay hindi nakikipag-ugnayan sa monolith, tanging ito ay lumiliko sa kanila upang malutas ang ilang mga problema. Gamit ang mga serbisyong ito, maaari mong simulan ang paglipat sa isang bagong arkitektura, i-debug ang imprastraktura sa mga ito, subukan ang ilang mga diskarte na nauugnay sa mga library ng network, atbp. Wala kaming anumang mga team sa aming organisasyon na hindi makagawa ng serbisyo sa pagpapatotoo.
Ang ikatlong paraan upang maglaan ng mga microserviceAng ginagamit namin ay medyo partikular sa amin. Ito ang pag-alis ng lohika ng negosyo mula sa layer ng UI. Ang aming pangunahing UI application ay desktop; ito, tulad ng backend, ay nakasulat sa C#. Pana-panahong nagkakamali ang mga developer at inilipat ang mga bahagi ng logic sa UI na dapat ay umiral sa backend at ginamit muli.
Kung titingnan mo ang isang tunay na halimbawa mula sa code ng bahagi ng UI, makikita mo na ang karamihan sa solusyon na ito ay naglalaman ng tunay na lohika ng negosyo na kapaki-pakinabang sa iba pang mga proseso, hindi lamang para sa pagbuo ng UI form.
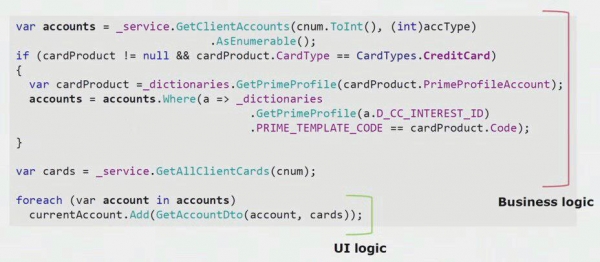
Ang tunay na lohika ng UI ay naroroon lamang sa huling dalawang linya. Inilipat namin ito sa server upang magamit itong muli, sa gayon ay binabawasan ang UI at naabot ang tamang arkitektura.
Ang ikaapat at pinakamahalagang paraan upang ihiwalay ang mga microservice, na ginagawang posible na bawasan ang monolith, ay ang pag-alis ng mga umiiral na serbisyo na may pagpoproseso. Kapag kinuha namin ang mga umiiral nang module, hindi palaging gusto ng mga developer ang resulta, at maaaring luma na ang proseso ng negosyo mula nang magawa ang functionality. Sa refactoring, maaari naming suportahan ang isang bagong proseso ng negosyo dahil ang mga kinakailangan sa negosyo ay patuloy na nagbabago. Maaari naming pagbutihin ang source code, alisin ang mga kilalang depekto, at gumawa ng mas magandang modelo ng data. Maraming benepisyo ang naipon.
Ang paghihiwalay ng mga serbisyo mula sa pagpoproseso ay hindi mapaghihiwalay na nauugnay sa konsepto ng bounded na konteksto. Ito ay isang konsepto mula sa Domain Driven Design. Nangangahulugan ito ng isang seksyon ng modelo ng domain kung saan ang lahat ng mga termino ng isang wika ay natatanging tinukoy. Tingnan natin ang konteksto ng insurance at mga bayarin bilang isang halimbawa. Mayroon kaming monolitikong aplikasyon, at kailangan naming magtrabaho kasama ang account sa insurance. Inaasahan namin na ang developer ay makakahanap ng kasalukuyang klase ng Account sa isa pang pagpupulong, i-refer ito mula sa klase ng Insurance, at magkakaroon kami ng working code. Ang DRY na prinsipyo ay igagalang, ang gawain ay gagawin nang mas mabilis sa pamamagitan ng paggamit ng umiiral na code.
Bilang resulta, lumalabas na ang mga konteksto ng mga account at insurance ay konektado. Habang lumalabas ang mga bagong kinakailangan, ang pagkabit na ito ay makakasagabal sa pag-unlad, na nagpapataas ng pagiging kumplikado ng dati nang kumplikadong lohika ng negosyo. Upang malutas ang problemang ito, kailangan mong hanapin ang mga hangganan sa pagitan ng mga konteksto sa code at alisin ang kanilang mga paglabag. Halimbawa, sa konteksto ng seguro, medyo posible na ang isang 20-digit na Central Bank account number at ang petsa ng pagbukas ng account ay magiging sapat.
Upang paghiwalayin ang mga hangganang konteksto sa isa't isa at simulan ang proseso ng paghihiwalay ng mga microservice mula sa isang monolitikong solusyon, gumamit kami ng diskarte gaya ng paggawa ng mga panlabas na API sa loob ng application. Kung alam namin na ang ilang module ay dapat maging isang microservice, kahit papaano ay binago sa loob ng proseso, pagkatapos ay agad kaming tumawag sa logic na kabilang sa isa pang limitadong konteksto sa pamamagitan ng mga panlabas na tawag. Halimbawa, sa pamamagitan ng REST o WCF.
Mahigpit kaming nagpasya na hindi namin iiwasan ang code na mangangailangan ng mga ipinamamahaging transaksyon. Sa aming kaso, naging napakadaling sundin ang panuntunang ito. Hindi pa kami nakakaranas ng mga sitwasyon kung saan ang mahigpit na ipinamahagi na mga transaksyon ay talagang kailangan - ang huling pagkakapare-pareho sa pagitan ng mga module ay sapat na.
Tingnan natin ang isang partikular na halimbawa. Mayroon kaming konsepto ng isang orkestra - isang pipeline na nagpoproseso ng entity ng "application". Lumilikha siya ng isang kliyente, isang account at isang bank card sa turn. Kung matagumpay na nalikha ang kliyente at account, ngunit nabigo ang paggawa ng card, hindi lilipat ang aplikasyon sa katayuang "matagumpay" at mananatili sa katayuang "hindi nilikha ang card". Sa hinaharap, kukunin ito at tatapusin ng background na aktibidad. Ang sistema ay nasa isang estado ng hindi pagkakapare-pareho sa loob ng ilang panahon, ngunit sa pangkalahatan ay nasisiyahan kami dito.
Kung lumitaw ang isang sitwasyon kung kailan kinakailangan na patuloy na i-save ang bahagi ng data, malamang na pupunta kami para sa pagsasama-sama ng serbisyo upang maproseso ito sa isang proseso.
Tingnan natin ang isang halimbawa ng paglalaan ng microservice. Paano mo ito madadala sa produksyon na medyo ligtas? Sa halimbawang ito, mayroon kaming hiwalay na bahagi ng system - isang module ng serbisyo ng payroll, isa sa mga seksyon ng code kung saan gusto naming gumawa ng microservice.
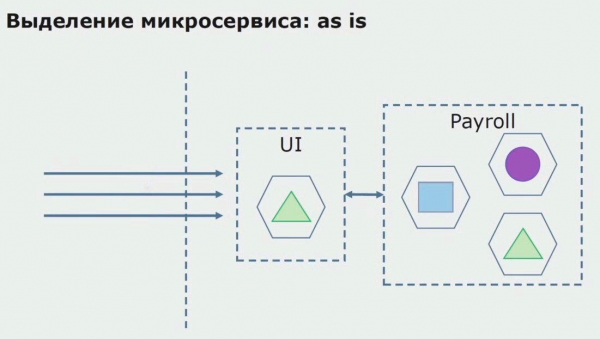
Una sa lahat, lumikha kami ng isang microservice sa pamamagitan ng muling pagsulat ng code. Pinagbubuti namin ang ilang aspeto na hindi namin ikinatuwa. Nagpapatupad kami ng mga bagong kinakailangan sa negosyo mula sa customer. Nagdaragdag kami ng API Gateway sa koneksyon sa pagitan ng UI at ng backend, na magbibigay ng pagpapasa ng tawag.
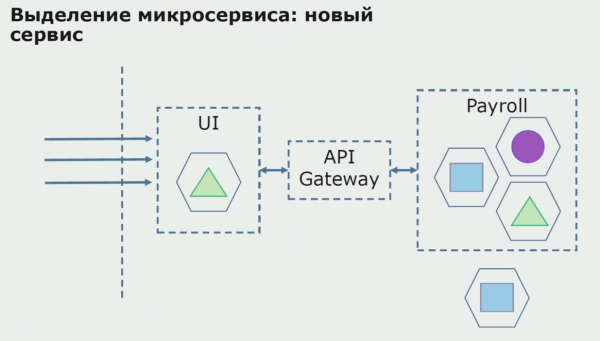
Susunod, ilalabas namin ang configuration na ito sa pagpapatakbo, ngunit nasa pilot state. Karamihan sa aming mga user ay gumagana pa rin sa mga lumang proseso ng negosyo. Para sa mga bagong user, gumagawa kami ng bagong bersyon ng monolitikong application na hindi na naglalaman ng prosesong ito. Sa totoo lang, mayroon kaming kumbinasyon ng monolith at microservice na nagtatrabaho bilang piloto.
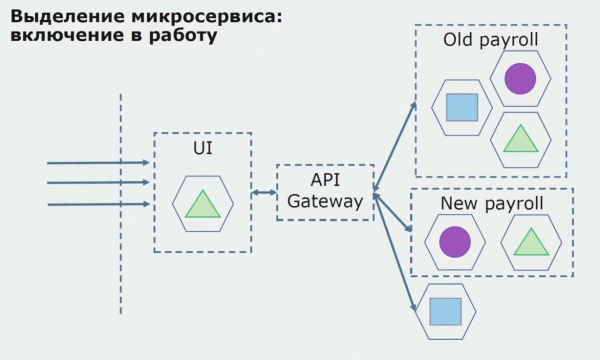
Sa isang matagumpay na pilot, naiintindihan namin na ang bagong configuration ay talagang magagawa, maaari naming alisin ang lumang monolith mula sa equation at iwanan ang bagong configuration sa halip ng lumang solusyon.
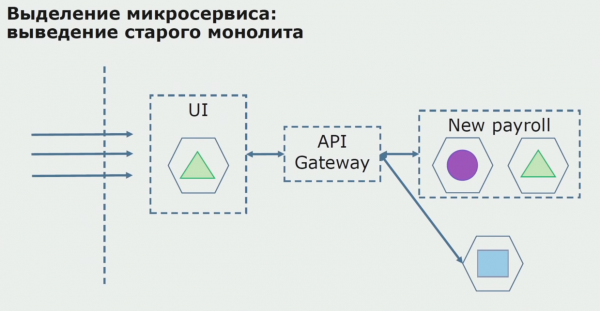
Sa kabuuan, ginagamit namin ang halos lahat ng umiiral na mga pamamaraan para sa paghahati ng source code ng isang monolith. Lahat ng mga ito ay nagpapahintulot sa amin na bawasan ang laki ng mga bahagi ng application at isalin ang mga ito sa mga bagong aklatan, na ginagawang mas mahusay ang source code.
Paggawa gamit ang database
Ang database ay maaaring hatiin nang mas masahol kaysa sa source code, dahil naglalaman ito hindi lamang ng kasalukuyang schema, kundi pati na rin ang naipon na makasaysayang data.
Ang aming database, tulad ng marami pang iba, ay may isa pang mahalagang disbentaha - ang malaking sukat nito. Ang database na ito ay idinisenyo ayon sa masalimuot na lohika ng negosyo ng isang monolith, at mga relasyon na naipon sa pagitan ng mga talahanayan ng iba't ibang mga hangganan na konteksto.
Sa aming kaso, sa itaas ng lahat ng mga problema (malaking database, maraming koneksyon, minsan hindi malinaw na mga hangganan sa pagitan ng mga talahanayan), isang problema ang lumitaw na nangyayari sa maraming malalaking proyekto: ang paggamit ng nakabahaging template ng database. Ang data ay kinuha mula sa mga talahanayan sa pamamagitan ng view, sa pamamagitan ng pagtitiklop, at ipinadala sa iba pang mga system kung saan kailangan ang pagtitiklop na ito. Bilang resulta, hindi namin mailipat ang mga talahanayan sa isang hiwalay na schema dahil aktibong ginagamit ang mga ito.
Ang parehong paghahati sa limitadong konteksto sa code ay tumutulong sa amin sa paghihiwalay. Karaniwan itong nagbibigay sa amin ng isang magandang ideya kung paano namin pinaghiwa-hiwalay ang data sa antas ng database. Nauunawaan namin kung aling mga talahanayan ang nabibilang sa isang may hangganang konteksto at alin sa isa pa.
Gumamit kami ng dalawang pandaigdigang paraan ng paghati sa database: paghahati ng mga umiiral na talahanayan at paghahati sa pagproseso.
Ang paghahati sa mga kasalukuyang talahanayan ay isang mahusay na paraan upang magamit kung ang istraktura ng data ay mabuti, nakakatugon sa mga kinakailangan ng negosyo, at lahat ay masaya dito. Sa kasong ito, maaari nating paghiwalayin ang mga umiiral na talahanayan sa isang hiwalay na schema.
Ang isang departamento na may pagpoproseso ay kailangan kapag ang modelo ng negosyo ay nagbago nang malaki, at ang mga talahanayan ay hindi na nasiyahan sa amin.
Paghahati ng mga umiiral na talahanayan. Kailangan nating matukoy kung ano ang paghiwalayin natin. Kung wala ang kaalamang ito, walang gagana, at dito makakatulong sa atin ang paghihiwalay ng mga hangganan na konteksto sa code. Bilang panuntunan, kung mauunawaan mo ang mga hangganan ng mga konteksto sa source code, magiging malinaw kung aling mga talahanayan ang dapat isama sa listahan para sa departamento.
Isipin natin na mayroon tayong solusyon kung saan nakikipag-ugnayan ang dalawang monolith module sa isang database. Kailangan nating tiyakin na isang module lang ang nakikipag-ugnayan sa seksyon ng mga pinaghiwalay na talahanayan, at ang isa ay nagsisimulang makipag-ugnayan dito sa pamamagitan ng API. Upang magsimula, sapat na ang pag-record lamang ang isinasagawa sa pamamagitan ng API. Ito ay isang kinakailangang kondisyon para pag-usapan natin ang kalayaan ng mga microservice. Ang mga koneksyon sa pagbabasa ay maaaring manatili hangga't walang malaking problema.
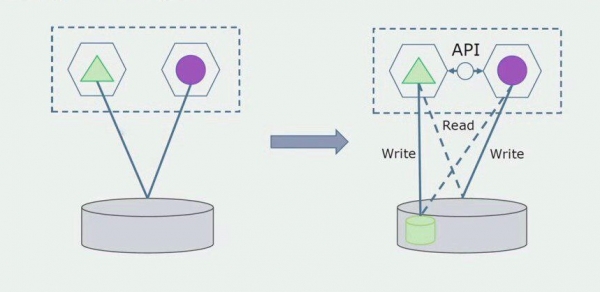
Ang susunod na hakbang ay maaari nating paghiwalayin ang seksyon ng code na gumagana sa mga hiwalay na talahanayan, mayroon man o walang pagproseso, sa isang hiwalay na microservice at patakbuhin ito sa isang hiwalay na proseso, isang lalagyan. Ito ay magiging isang hiwalay na serbisyo na may koneksyon sa monolith database at ang mga talahanayan na hindi direktang nauugnay dito. Ang monolith ay nakikipag-ugnayan pa rin para sa pagbabasa sa nababakas na bahagi.
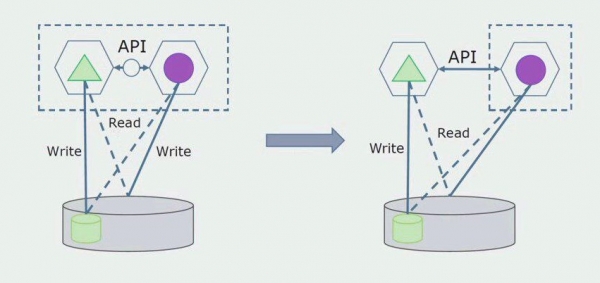
Sa ibang pagkakataon, aalisin namin ang koneksyon na ito, iyon ay, ang pagbabasa ng data mula sa isang monolitikong aplikasyon mula sa mga hiwalay na talahanayan ay ililipat din sa API.
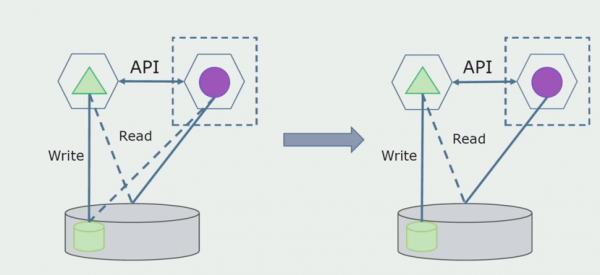
Susunod, pipiliin namin mula sa pangkalahatang database ang mga talahanayan kung saan gumagana lamang ang bagong microservice. Maaari naming ilipat ang mga talahanayan sa isang hiwalay na schema o kahit sa isang hiwalay na pisikal na database. Mayroon pa ring koneksyon sa pagbabasa sa pagitan ng microservice at ng monolith database, ngunit walang dapat ipag-alala, sa pagsasaayos na ito maaari itong mabuhay nang mahabang panahon.
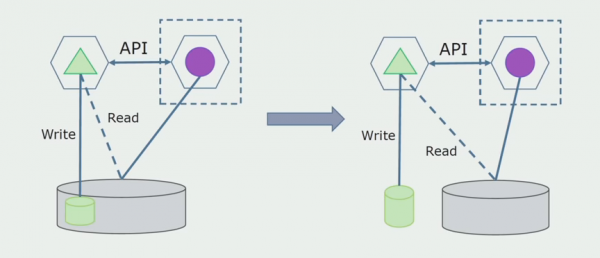
Ang huling hakbang ay ganap na alisin ang lahat ng koneksyon. Sa kasong ito, maaaring kailanganin naming mag-migrate ng data mula sa pangunahing database. Minsan gusto naming muling gamitin ang ilang data o mga direktoryo na kinopya mula sa mga panlabas na system sa ilang mga database. Ito ay nangyayari sa atin pana-panahon.
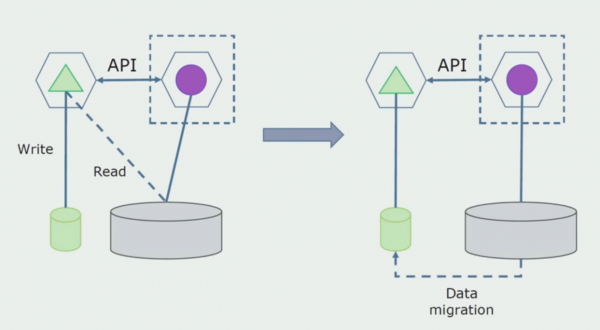
Kagawaran ng pagproseso. Ang pamamaraang ito ay halos kapareho sa una, sa reverse order lamang. Agad kaming naglalaan ng bagong database at bagong microservice na nakikipag-ugnayan sa monolith sa pamamagitan ng API. Ngunit sa parehong oras, may nananatiling isang set ng mga talahanayan ng database na gusto naming tanggalin sa hinaharap. Hindi na namin ito kailangan; pinalitan namin ito sa bagong modelo.
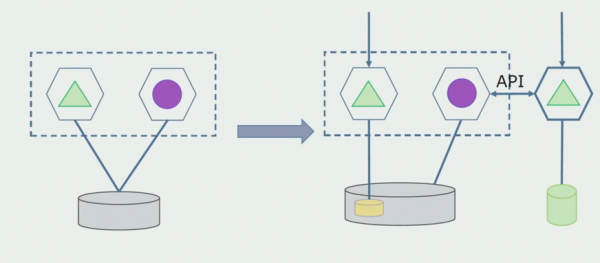
Para gumana ang scheme na ito, malamang na kailangan namin ng panahon ng paglipat.
Mayroong dalawang posibleng mga diskarte.
Muna: duplicate namin ang lahat ng data sa bago at lumang database. Sa kasong ito, mayroon kaming data redundancy at maaaring lumitaw ang mga problema sa pag-synchronize. Ngunit maaari tayong kumuha ng dalawang magkaibang kliyente. Ang isa ay gagana sa bagong bersyon, ang isa sa luma.
Pangalawa: hinahati namin ang data ayon sa ilang pamantayan sa negosyo. Halimbawa, mayroon kaming 5 produkto sa system na nakaimbak sa lumang database. Inilalagay namin ang pang-anim sa loob ng bagong gawain sa negosyo sa isang bagong database. Ngunit kakailanganin namin ng API Gateway na magsi-synchronize ng data na ito at magpapakita sa kliyente kung saan at kung saan kukuha.
Ang parehong mga diskarte ay gumagana, pumili depende sa sitwasyon.
Matapos naming matiyak na gumagana ang lahat, maaaring hindi paganahin ang bahagi ng monolith na gumagana sa mga lumang istruktura ng database.
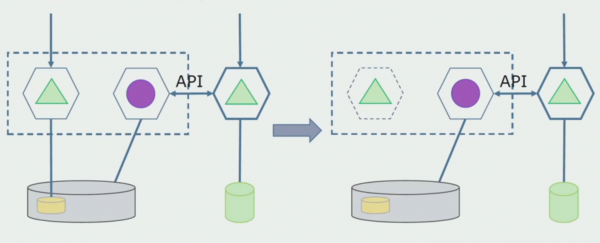
Ang huling hakbang ay alisin ang mga lumang istruktura ng data.
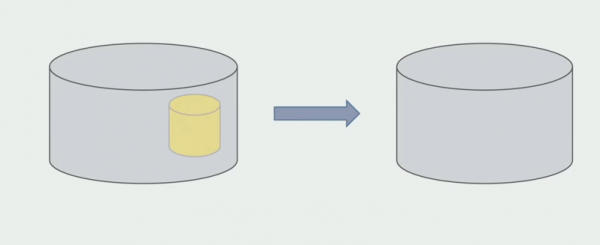
Upang ibuod, masasabi nating mayroon tayong mga problema sa database: mahirap gamitin ito kumpara sa source code, mas mahirap itong ibahagi, ngunit maaari at dapat itong gawin. Nakakita kami ng ilang paraan na nagbibigay-daan sa aming gawin ito nang ligtas, ngunit mas madaling magkamali sa data kaysa sa source code.
Paggawa gamit ang source code
Ito ang hitsura ng diagram ng source code noong sinimulan naming pag-aralan ang monolitikong proyekto.
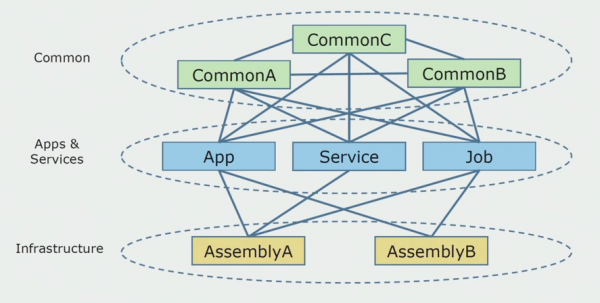
Maaari itong halos nahahati sa tatlong layer. Ito ay isang layer ng mga inilunsad na module, plugin, serbisyo at indibidwal na aktibidad. Sa katunayan, ito ay mga entry point sa loob ng isang monolitikong solusyon. Lahat ng mga ito ay mahigpit na selyado ng isang Karaniwang layer. Mayroon itong lohika ng negosyo na ibinahagi ng mga serbisyo at maraming koneksyon. Gumagamit ang bawat serbisyo at plugin ng hanggang 10 o higit pang karaniwang assemblies, depende sa laki ng mga ito at sa konsensya ng mga developer.
Kami ay mapalad na magkaroon ng mga aklatan sa imprastraktura na maaaring gamitin nang hiwalay.
Minsan lumitaw ang isang sitwasyon kapag ang ilang karaniwang bagay ay hindi kabilang sa layer na ito, ngunit mga library ng imprastraktura. Nalutas ito sa pamamagitan ng pagpapalit ng pangalan.
Ang pinakamalaking alalahanin ay mga hangganan na konteksto. Nangyari na ang 3-4 na konteksto ay pinaghalo sa isang Karaniwang pagpupulong at ginamit ang isa't isa sa loob ng parehong mga function ng negosyo. Kinakailangang maunawaan kung saan ito maaaring hatiin at kasama kung anong mga hangganan, at kung ano ang susunod na gagawin sa pagmamapa sa dibisyong ito sa mga source code assemblies.
Gumawa kami ng ilang panuntunan para sa proseso ng paghahati ng code.
Ang unang: Hindi na namin gustong ibahagi ang lohika ng negosyo sa pagitan ng mga serbisyo, aktibidad at plugin. Nais naming gawing independyente ang lohika ng negosyo sa loob ng mga microservice. Ang mga microservice, sa kabilang banda, ay perpektong naisip bilang mga serbisyo na ganap na umiiral nang nakapag-iisa. Naniniwala ako na ang pamamaraang ito ay medyo maaksaya, at mahirap na makamit, dahil, halimbawa, ang mga serbisyo sa C# ay sa anumang kaso ay konektado ng isang karaniwang aklatan. Ang aming system ay nakasulat sa C#; hindi pa kami gumagamit ng iba pang mga teknolohiya. Samakatuwid, napagpasyahan namin na kayang-kaya naming gumamit ng mga karaniwang teknikal na pagtitipon. Ang pangunahing bagay ay hindi sila naglalaman ng anumang mga fragment ng lohika ng negosyo. Kung mayroon kang convenience wrapper sa ORM na iyong ginagamit, ang pagkopya nito mula sa serbisyo patungo sa serbisyo ay napakamahal.
Ang aming koponan ay isang tagahanga ng disenyo na hinimok ng domain, kaya ang arkitektura ng sibuyas ay angkop para sa amin. Ang batayan ng aming mga serbisyo ay hindi ang data access layer, ngunit isang assembly na may domain logic, na naglalaman lamang ng business logic at walang koneksyon sa imprastraktura. Kasabay nito, maaari nating independiyenteng baguhin ang pagpupulong ng domain upang malutas ang mga problemang nauugnay sa mga balangkas.
Sa yugtong ito naranasan namin ang aming unang seryosong problema. Ang serbisyo ay kailangang sumangguni sa isang pagpupulong ng domain, gusto naming gawing independyente ang lohika, at ang DRY na prinsipyo ay lubos na humadlang sa amin dito. Nais ng mga developer na muling gamitin ang mga klase mula sa mga kalapit na asembliya upang maiwasan ang pagdoble, at bilang resulta, nagsimulang muling maiugnay ang mga domain. Sinuri namin ang mga resulta at nagpasya na marahil ang problema ay namamalagi din sa lugar ng source code storage device. Mayroon kaming malaking repositoryo na naglalaman ng lahat ng source code. Ang solusyon para sa buong proyekto ay napakahirap na i-assemble sa isang lokal na makina. Samakatuwid, ang mga hiwalay na maliliit na solusyon ay ginawa para sa mga bahagi ng proyekto, at walang sinuman ang nagbabawal sa pagdaragdag ng ilang karaniwang o domain assembly sa kanila at muling gamitin ang mga ito. Ang tanging tool na hindi nagpapahintulot sa amin na gawin ito ay ang pagsusuri ng code. Pero minsan nabigo din.
Pagkatapos ay nagsimula kaming lumipat sa isang modelo na may hiwalay na mga repositoryo. Ang lohika ng negosyo ay hindi na dumadaloy mula sa serbisyo patungo sa serbisyo, ang mga domain ay tunay na naging independyente. Ang mga hangganan na konteksto ay suportado nang mas malinaw. Paano natin magagamit muli ang mga library ng imprastraktura? Pinaghiwalay namin ang mga ito sa isang hiwalay na imbakan, pagkatapos ay inilagay ang mga ito sa mga pakete ng Nuget, na inilagay namin sa Artifactory. Sa anumang pagbabago, awtomatikong nagaganap ang pagpupulong at paglalathala.
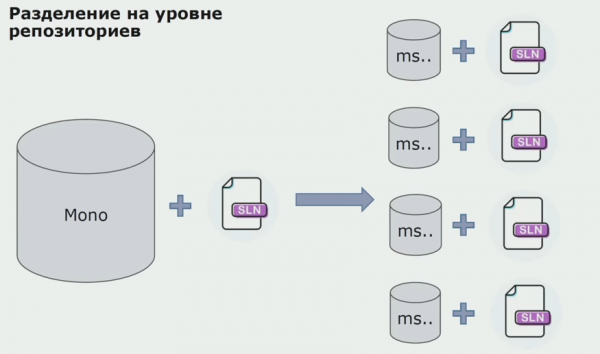
Ang aming mga serbisyo ay nagsimulang sumangguni sa mga panloob na pakete ng imprastraktura sa parehong paraan tulad ng mga panlabas. Nagda-download kami ng mga panlabas na aklatan mula sa Nuget. Upang magtrabaho kasama ang Artifactory, kung saan namin inilagay ang mga package na ito, gumamit kami ng dalawang manager ng package. Sa maliliit na repositoryo ay ginamit din namin ang Nuget. Sa mga repository na may maraming serbisyo, ginamit namin ang Paket, na nagbibigay ng higit pang pagkakapare-pareho ng bersyon sa pagitan ng mga module.
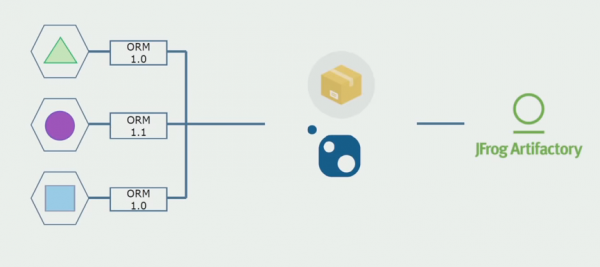
Kaya, sa pamamagitan ng pagtatrabaho sa source code, bahagyang pagbabago ng arkitektura at paghihiwalay ng mga repositoryo, ginagawa naming mas independyente ang aming mga serbisyo.
Mga problema sa imprastraktura
Karamihan sa mga kawalan ng paglipat sa mga microservice ay nauugnay sa imprastraktura. Kakailanganin mo ang awtomatikong pag-deploy, kakailanganin mo ng mga bagong aklatan upang patakbuhin ang imprastraktura.
Manu-manong pag-install sa mga kapaligiran
Sa una, na-install namin nang manu-mano ang solusyon para sa mga kapaligiran. Upang i-automate ang prosesong ito, gumawa kami ng pipeline ng CI/CD. Pinili namin ang tuluy-tuloy na proseso ng paghahatid dahil ang tuluy-tuloy na pag-deploy ay hindi pa katanggap-tanggap para sa amin mula sa punto ng view ng mga proseso ng negosyo. Samakatuwid, ang pagpapadala para sa operasyon ay isinasagawa gamit ang isang pindutan, at para sa pagsubok - awtomatiko.
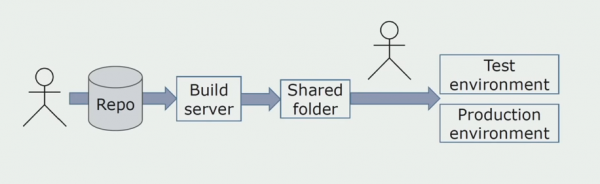
Ginagamit namin ang Atlassian, Bitbucket para sa imbakan ng source code at Bamboo para sa pagbuo. Gusto naming magsulat ng mga build script sa Cake dahil pareho ito sa C#. Ang mga handa na pakete ay dumarating sa Artifactory, at ang Ansible ay awtomatikong napupunta sa mga server ng pagsubok, pagkatapos nito ay masusuri agad ang mga ito.
Hiwalay na pag-log
Sa isang pagkakataon, ang isa sa mga ideya ng monolith ay ang pagbibigay ng shared logging. Kailangan din naming maunawaan kung ano ang gagawin sa mga indibidwal na log na nasa mga disk. Ang aming mga log ay isinulat sa mga text file. Nagpasya kaming gumamit ng karaniwang ELK stack. Hindi kami direktang sumulat sa ELK sa pamamagitan ng mga provider, ngunit nagpasya kaming baguhin ang mga text log at isulat ang trace ID sa mga ito bilang isang identifier, idinadagdag ang pangalan ng serbisyo, para ma-parse ang mga log na ito sa ibang pagkakataon.
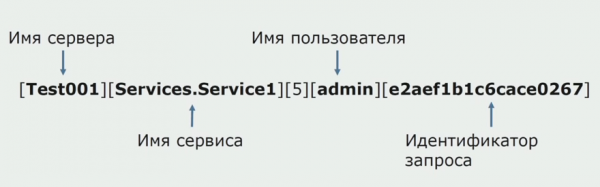
Gamit ang Filebeat, nagagawa naming kolektahin ang aming mga log mula sa mga server, pagkatapos ay i-transform ang mga ito, gamitin ang Kibana upang bumuo ng mga query sa UI, at tingnan kung paano nairuta ang tawag sa pagitan ng mga serbisyo. Malaking tulong ang mga Trace ID para dito.
Pagsubok at pag-debug ng mga kaugnay na serbisyo
Sa una, hindi namin lubos na nauunawaan kung paano i-debug ang mga serbisyong binuo. Ang lahat ay simple sa monolith; pinatakbo namin ito sa isang lokal na makina. Sa una sinubukan nilang gawin ang parehong sa mga microservice, ngunit kung minsan upang ganap na mailunsad ang isang microservice kailangan mong maglunsad ng maraming iba pa, at ito ay hindi maginhawa. Napagtanto namin na kailangan naming lumipat sa isang modelo kung saan iiwan lang namin sa lokal na makina ang serbisyo o mga serbisyo na gusto naming i-debug. Ang natitirang mga serbisyo ay ginagamit mula sa mga server na tumutugma sa configuration sa prod. Pagkatapos ng pag-debug, sa panahon ng pagsubok, para sa bawat gawain, ang mga binagong serbisyo lamang ang ibinibigay sa test server. Kaya, ang solusyon ay nasubok sa anyo kung saan ito lilitaw sa produksyon sa hinaharap.
May mga server na nagpapatakbo lamang ng mga bersyon ng produksyon ng mga serbisyo. Ang mga server na ito ay kailangan sa kaso ng mga insidente, upang suriin ang paghahatid bago i-deploy at para sa panloob na pagsasanay.
Nagdagdag kami ng isang awtomatikong proseso ng pagsubok gamit ang sikat na library ng Specflow. Awtomatikong tumatakbo ang mga pagsubok gamit ang NUnit pagkatapos ng pag-deploy mula sa Ansible. Kung ang saklaw ng gawain ay ganap na awtomatiko, kung gayon hindi na kailangan para sa manu-manong pagsubok. Bagama't kung minsan ay kailangan pa rin ng karagdagang manu-manong pagsusuri. Gumagamit kami ng mga tag sa Jira para matukoy kung aling mga pagsubok ang tatakbo para sa isang partikular na isyu.
Bilang karagdagan, ang pangangailangan para sa pagsubok ng pagkarga ay tumaas; dati ito ay isinasagawa lamang sa mga bihirang kaso. Ginagamit namin ang JMeter upang magpatakbo ng mga pagsubok, InfluxDB upang iimbak ang mga ito, at Grafana upang bumuo ng mga graph ng proseso.
Ano ang narating natin?
Una, inalis namin ang konsepto ng "release". Wala na ang dalawang buwang napakalaking release noong ang napakalaking ito ay na-deploy sa isang production environment, na pansamantalang nakakagambala sa mga proseso ng negosyo. Ngayon, naglalagay kami ng mga serbisyo sa average bawat 1,5 araw, pinapangkat ang mga ito dahil gumagana ang mga ito pagkatapos ng pag-apruba.
Walang mga nakamamatay na pagkabigo sa aming system. Kung maglalabas kami ng microservice na may bug, masisira ang functionality na nauugnay dito, at hindi maaapektuhan ang lahat ng iba pang functionality. Ito ay lubos na nagpapabuti sa karanasan ng gumagamit.
Makokontrol natin ang pattern ng deployment. Maaari kang pumili ng mga pangkat ng mga serbisyo nang hiwalay mula sa iba pang solusyon, kung kinakailangan.
Bilang karagdagan, makabuluhang nabawasan namin ang problema sa isang malaking pila ng mga pagpapabuti. Mayroon na kaming magkakahiwalay na pangkat ng produkto na nagtatrabaho sa ilan sa mga serbisyo nang hiwalay. Ang proseso ng Scrum ay angkop na dito. Maaaring may hiwalay na May-ari ng Produkto ang isang partikular na team na nagtatalaga ng mga gawain dito.
Buod
- Ang mga microservice ay angkop na angkop para sa nabubulok na mga kumplikadong sistema. Sa proseso, sinisimulan nating maunawaan kung ano ang nasa ating sistema, kung ano ang mga limitadong konteksto, kung saan ang kanilang mga hangganan. Nagbibigay-daan ito sa iyo na maipamahagi nang tama ang mga pagpapabuti sa mga module at maiwasan ang pagkalito ng code.
- Nagbibigay ang mga microservice ng mga benepisyo ng organisasyon. Ang mga ito ay madalas na pinag-uusapan lamang bilang arkitektura, ngunit ang anumang arkitektura ay kinakailangan upang malutas ang mga pangangailangan sa negosyo, at hindi sa sarili nitong. Samakatuwid, maaari nating sabihin na ang mga microservice ay angkop na angkop para sa paglutas ng mga problema sa maliliit na koponan, dahil sikat na sikat na ang Scrum ngayon.
- Ang paghihiwalay ay isang umuulit na proseso. Hindi ka maaaring kumuha ng application at hatiin lang ito sa mga microservice. Ang resultang produkto ay malamang na hindi gumagana. Kapag nag-aalay ng mga microservice, kapaki-pakinabang na muling isulat ang umiiral nang legacy, iyon ay, gawin itong code na gusto namin at mas nakakatugon sa mga pangangailangan ng negosyo sa mga tuntunin ng functionality at bilis.
Isang maliit na caveat: Ang mga gastos sa paglipat sa mga microservice ay medyo makabuluhan. Matagal bago malutas ang problema sa imprastraktura nang mag-isa. Kaya kung mayroon kang maliit na application na hindi nangangailangan ng partikular na pag-scale, maliban na lang kung marami kang customer na nakikipagkumpitensya para sa atensyon at oras ng iyong team, maaaring hindi ang mga microservice ang kailangan mo ngayon. Ito ay medyo mahal. Kung sisimulan mo ang proseso gamit ang mga microservice, ang mga gastos sa simula ay mas mataas kaysa kung sisimulan mo ang parehong proyekto sa pagbuo ng isang monolith.
P.S. Isang mas emosyonal na kwento (at parang para sa iyo personal) - ayon sa .
Narito ang buong bersyon ng ulat.
Pinagmulan: www.habr.com
