

Kamakailan, ang mga kasamahan sa "shop" ay nagsimulang magtanong sa akin nang nakapag-iisa sa isa't isa: paano makukuha ang lahat ng mga channel ng Bluetooth nang sabay-sabay mula sa isang SDR receiver? Pinapayagan ito ng bandwidth, mayroong mga SDR na may output bandwidth na 80 MHz o higit pa. Maaari mong, siyempre, gawin ito sa isang FPGA, ngunit ang naturang oras ng pag-unlad ay magiging mahaba. Matagal ko nang alam na ang paggawa nito sa isang GPU ay medyo simple, ngunit gawin ito nang ganoon!
Tinutukoy ng pamantayan ng Bluetooth ang isang pisikal na layer sa dalawang bersyon: Classic at Mababang Enerhiya. Available ang pagtutukoy . Ang dokumento ay napakalaki, ang pagbabasa nito sa kabuuan nito ay mapanganib para sa utak. Sa kabutihang palad, ang malalaking kumpanya ng teknolohiya sa pagsukat ay may paraan upang lumikha ng mga visual na dokumento sa isang paksa. и , Halimbawa. Wala akong ganap na pagkakataon na makipagkumpitensya sa kanila sa mga tuntunin ng kalidad ng pagtatanghal ng materyal. Kung interesado ka, mangyaring sundin ang mga link.
Ang kailangan ko lang malaman tungkol sa pisikal na layer upang lumikha ng isang multi-channel na filter ay ang frequency grid spacing at modulation rate. Ang mga ito ay naka-tabulate sa isa sa mga sumusunod na dokumento:
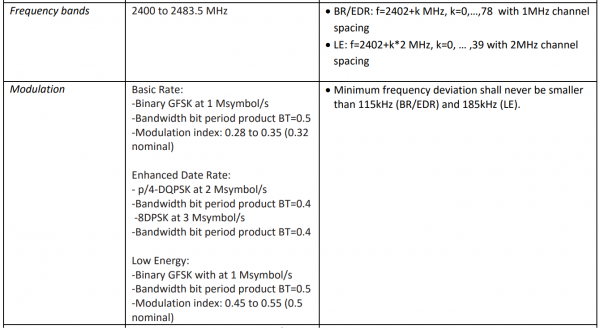
Kaya, kailangan nating i-cut ang 80 MHz band sa 79 na mga filter na may tuning step na 1 MHz at, sa parehong oras, sa 40 na mga filter na may tuning step na 2 MHz. Ang mga sampling frequency mula sa mga output ng filter ay dapat na 1 MHz at 2 MHz, ayon sa pagkakabanggit.
Kaya, kailangan namin ng dalawang filter na bangko.
Una, piliin natin ang mga parameter ng mga filter na ito batay sa Bluetooth Classic at Bluetooth Low Energy signal bands. Kailangan namin ang kanilang mga impulse response para kalkulahin ang load sa computing device ng filter. Narito ito ay nagkakahalaga ng pagbanggit kaagad na pinili namin ang mga haba ng impulse response batay sa mga kinakailangan ng isang "mabilis" na algorithm sa pag-filter. Ang kakanyahan ay hindi nagbabago mula dito. At ang bilang ng mga impulse response coefficient ay hindi dapat masyadong malaki para maipatupad ang filter sa matino na computing equipment.
Para sa mga filter na may hakbang na 1 MHz, pipili kami ng low-pass filter bandwidth (kalahati ng bandwidth ng band-pass filter) na 500 kHz, at inaayos ang haba ng impulse response sa 480 taps. Para sa mga filter na may hakbang na 2 MHz, pipiliin namin ang mga parameter na ito bilang 1 MHz at 240 taps, ayon sa pagkakabanggit. Pinipili namin ang uri ng window ng Kaiser. Kalkulahin natin ang mga impulse response sa filterDesigner at i-upload ang mga ito sa C-header na format:
Mga screenshot mula sa filterDesigner
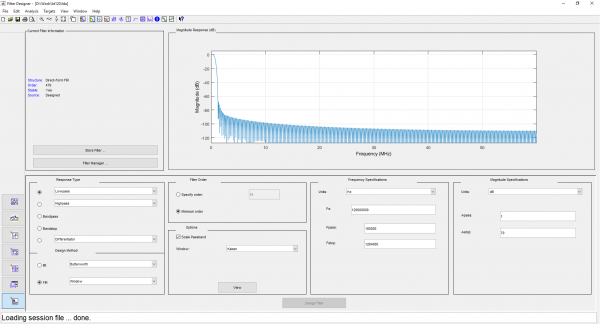
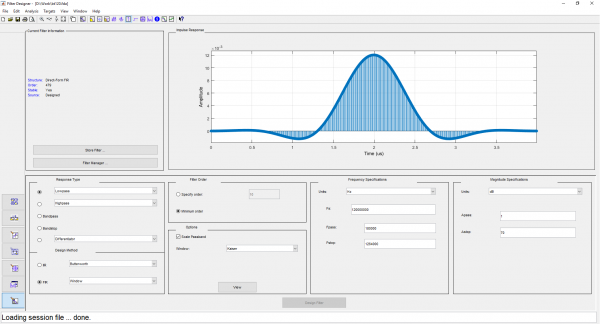
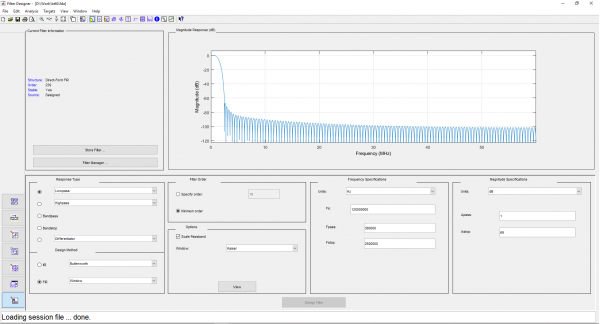
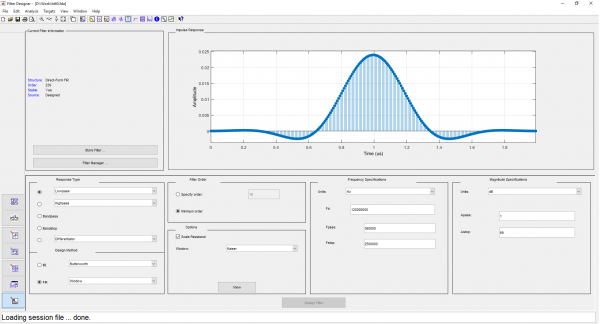
Maaari mong lutasin ang problema sa isang brute force na paraan: bumuo ng isang DDC array na naaayon sa bilang ng mga filter (). Ang diskarte na ito ay mabuti para sa mga FPGA, kung saan ang pagtitipid ay posible sa pamamagitan ng pagbabawas ng bit na kapasidad ng mga unang yugto ng mga computer. Gayundin, ang FPGA ay ang pinaka-enerhiya na paraan ng pagpapatupad. Ngunit ang mga gastos sa paggawa sa pamamaraang ito ay ang pinakamataas.
Kapag nagpapatakbo ng isang filter na bangko sa mga sikat na GPU ngayon, nagiging posible na magpatupad ng mas sopistikadong algorithm: isang polyphase filter bank batay sa FFT, na sa CUDA ay available mula sa library. Sa banyagang panitikan, ang algorithm ay tinatawag na Polyphase o WOLA (Weight, Overlap and Add) FFT Filterbank. Ang katamaran sa pagguhit ay hindi nagbibigay sa akin ng pagkakataong kumpletuhin ang isang visual na paliwanag sa aking sarili. Mayroong maraming materyal sa paksa sa Internet, isang partikular na malinaw na graph ang ginawa sa pahina 11 (maraming salamat sa mga respetadong may-akda), narito:
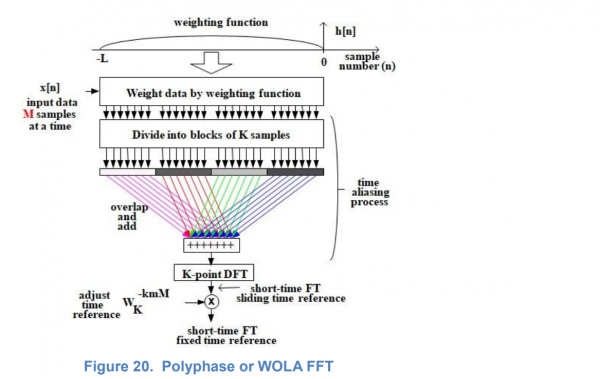
Susubukan kong ipaliwanag ang pamamaraan ng pagproseso sa sarili kong mga salita. Mangyaring huwag basahin para sa mahina ng puso.
Susubukan kong ipaliwanag ang pamamaraan ng pagproseso sa sarili kong mga salita sa loob ng balangkas ng aking mga kakayahan sa pamamaraan. Ang FFT ay ang convolution ng input signal na may buong spectrum ng kumplikadong orthogonal harmonics na akma sa loob ng impulse response interval. Ang impulse response ng filter, kung saan ang signal ay pinarami bago ang FFT input, ay modulated ng harmonic spectra na ito. Sa madaling salita, naka-bracket ang impulse response envelope ng mga resultang comb filter. Dagdag pa, ang harmonic spectrum ay pinanipis ng ilang beses, dahil sa pagpapalawak ng bandwidth ng filter na nauugnay sa filter sa hugis-parihaba na window. Sa larawan nakikita natin ang pagnipis ng apat. Sa madaling salita, pagkatapos palawakin ang banda na may Kaiser window (na may sabay-sabay na pagtaas ng attenuation sa stopband), hindi na namin kailangan ang lahat ng mga filter, ngunit isang-kapat lamang ng mga ito. Ang natitira ay kalabisan, ang kanilang mga katangian ng dalas ay nagsasapawan. Sa apat na magkakasunod na FFT point, pipiliin lang namin ang zero one, ang kalkulasyon kung saan ay ang kabuuan ng apat.
input point na kinuha pagkatapos ng isang oras na katumbas ng isang quarter ng tagal ng orihinal na FFT.
Pipiliin natin ang bakal na nasa kamay. Ito ang input board mula sa Instrumentation Systems FMC126P. Naisulat ko na ang tungkol dito sa isang nakaraan . Ang isang submodule mula sa parehong kumpanya na may AD9371 transceiver na may 100 MHz band ay ipinasok sa FMC connector ng board. Ang buong stream mula sa transceiver ay maaaring patuloy na mailipat sa isang computer para sa pagproseso.
Pumili tayo ng video card na may GPU GTX 1050. (Nagsinungaling ako, ito ang pumili sa atin: ito lang ang nasa kamay, napunit ito sa computer upang kalkulahin ang mga antenna, ngunit ito ay mas nakakagulat na makita isang gumaganang suklay). Lumipat tayo sa bahagi ng software.
Sa kasamaang palad, dahil sa mga lisensya, hindi namin mai-publish ang buong code. Mga GPU core lang ang maipapakita namin. Gayunpaman, ang natitirang bahagi ng code ay hindi partikular na kawili-wili.
Narito ang kernel na gumagawa ng signal-window multiplication at karagdagan, at isang wrapper na tatawagin ito:
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
Ang signal processing code na tumatawag sa kernel na ito ay eksaktong inuulit ang algorithm diagram na ipinapakita sa figure sa itaas, kaya wala akong nakikitang dahilan upang ipakita ito dito.
Ang mga suklay ay sinubukan sa output spectrum ng mga channel sa real time. Isang 9371 MHz signal generator signal ang ibinigay sa AD2450 input, at ang selectivity ng mga filter ay tumutugma sa kinakalkula.
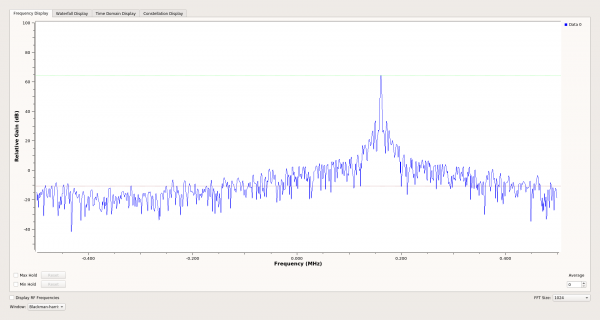
Kasama sa mga plano ang: pag-aangkop ng software sa XRTX board at pagpapatupad ng paghahanap ng package, kung may nangangailangan nito o may libreng oras.
Nakumpleto ang lahat ng gawain ng software , luwalhati sa kanya!
Pinagmulan: www.habr.com
