


Nakakita ako ng ilang kawili-wiling materyal tungkol sa artificial intelligence sa mga laro. Sa pagpapaliwanag ng mga pangunahing bagay tungkol sa AI gamit ang mga simpleng halimbawa, at sa loob ay maraming kapaki-pakinabang na tool at pamamaraan para sa maginhawang pag-unlad at disenyo nito. Kung paano, saan at kailan gagamitin ang mga ito ay naroon din.
Karamihan sa mga halimbawa ay nakasulat sa pseudocode, kaya walang advanced na kaalaman sa programming ang kinakailangan. Sa ilalim ng hiwa mayroong 35 na mga sheet ng teksto na may mga larawan at gif, kaya maghanda.
UPD. Humihingi ako ng paumanhin, ngunit nagawa ko na ang sarili kong pagsasalin ng artikulong ito sa Habré . Maaari mong basahin ang kanyang bersyon , ngunit sa ilang kadahilanan ang artikulo ay dumaan sa akin (ginamit ko ang paghahanap, ngunit may nangyaring mali). At dahil nagsusulat ako sa isang blog na nakatuon sa pagbuo ng laro, nagpasya akong iwanan ang aking bersyon ng pagsasalin para sa mga subscriber (ang ilang mga punto ay naiiba ang format, ang ilan ay sadyang tinanggal sa payo ng mga developer).
Ano ang AI?
Nakatuon ang Game AI sa kung anong mga aksyon ang dapat gawin ng isang bagay batay sa mga kondisyon kung saan ito matatagpuan. Ito ay karaniwang tinutukoy bilang "matalinong ahente" na pamamahala, kung saan ang isang ahente ay isang karakter ng manlalaro, isang sasakyan, isang bot, o kung minsan ay isang bagay na mas abstract: isang buong grupo ng mga entity o kahit isang sibilisasyon. Sa bawat kaso, ito ay isang bagay na dapat makita ang kapaligiran nito, gumawa ng mga desisyon batay dito, at kumilos alinsunod sa kanila. Ito ay tinatawag na Sense/Think/Act cycle:
- Sense: Ang ahente ay nakakahanap o nakakatanggap ng impormasyon tungkol sa mga bagay sa kapaligiran nito na maaaring makaimpluwensya sa pag-uugali nito (mga pagbabanta sa malapit, mga item na kokolektahin, mga kawili-wiling lugar upang tuklasin).
- Isipin: Ang ahente ang magpapasya kung paano magreaksyon (isinasaalang-alang kung ito ay sapat na ligtas upang mangolekta ng mga item o kung dapat siyang lumaban/magtago muna).
- Kumilos: ang ahente ay nagsasagawa ng mga aksyon upang ipatupad ang nakaraang desisyon (nagsisimulang lumipat patungo sa kaaway o bagay).
- ...ngayon ay nagbago ang sitwasyon dahil sa mga aksyon ng mga character, kaya umuulit ang cycle sa bagong data.
May posibilidad na tumuon ang AI sa bahagi ng Sense ng loop. Halimbawa, ang mga autonomous na kotse ay kumukuha ng mga larawan ng kalsada, pinagsama ang mga ito sa radar at lidar data, at binibigyang-kahulugan ang mga ito. Karaniwan itong ginagawa sa pamamagitan ng machine learning, na nagpoproseso ng papasok na data at nagbibigay dito ng kahulugan, na kumukuha ng semantic na impormasyon tulad ng "may isa pang kotse na 20 yarda sa unahan mo." Ito ang tinatawag na mga problema sa pag-uuri.
Ang mga laro ay hindi nangangailangan ng isang kumplikadong sistema upang kumuha ng impormasyon dahil ang karamihan sa data ay isa nang mahalagang bahagi nito. Hindi na kailangang magpatakbo ng mga algorithm sa pagkilala ng imahe upang matukoy kung may kaaway sa unahan—alam na ng laro at direktang pinapakain ang impormasyon sa proseso ng paggawa ng desisyon. Samakatuwid, ang Sense na bahagi ng cycle ay kadalasang mas simple kaysa sa Think and Act na bahagi.
Mga Limitasyon ng Game AI
May ilang limitasyon ang AI na dapat sundin:
- Hindi kailangang sanayin nang maaga ang AI, na para bang ito ay isang algorithm sa pag-aaral ng makina. Walang saysay na magsulat ng isang neural network sa panahon ng pagbuo upang masubaybayan ang libu-libong mga manlalaro at matutunan ang pinakamahusay na paraan upang maglaro laban sa kanila. Bakit? Dahil hindi pa nilalabas ang laro at walang mga manlalaro.
- Ang laro ay dapat na masaya at mapaghamong, kaya hindi dapat mahanap ng mga ahente ang pinakamahusay na diskarte laban sa mga tao.
- Kailangang magmukhang makatotohanan ang mga ahente upang maramdaman ng mga manlalaro na sila ay nakikipaglaro laban sa mga totoong tao. Ang programang AlphaGo ay higit na mahusay sa mga tao, ngunit ang mga hakbang na pinili ay napakalayo sa tradisyonal na pag-unawa sa laro. Kung ang laro ay ginagaya ang isang tao na kalaban, ang pakiramdam na ito ay hindi dapat umiral. Kailangang baguhin ang algorithm upang makagawa ito ng mga makatwirang desisyon sa halip na mga mainam.
- Dapat gumana ang AI sa real time. Nangangahulugan ito na hindi maaaring monopolyo ng algorithm ang paggamit ng CPU sa mahabang panahon upang makagawa ng mga desisyon. Kahit na ang 10 millisecond ay masyadong mahaba, dahil ang karamihan sa mga laro ay nangangailangan lamang ng 16 hanggang 33 millisecond upang gawin ang lahat ng pagproseso at magpatuloy sa susunod na graphics frame.
- Sa isip, kahit man lang bahagi ng system ay dapat na batay sa data, upang ang mga hindi taga-coder ay makakagawa ng mga pagbabago at ang mga pagsasaayos ay maaaring mangyari nang mas mabilis.
Tingnan natin ang mga diskarte sa AI na sumasaklaw sa buong cycle ng Sense/Think/Act.
Paggawa ng mga Pangunahing Desisyon
Magsimula tayo sa pinakasimpleng laro - Pong. Layunin: ilipat ang paddle upang ang bola ay tumalbog dito sa halip na lumipad lampas dito. Parang tennis, kung saan talo ka kapag hindi mo natamaan ang bola. Dito ang AI ay may medyo madaling gawain - ang pagpapasya kung saang direksyon ililipat ang platform.

Mga pahayag na may kondisyon
Para sa AI sa Pong, ang pinaka-halatang solusyon ay palaging subukang ilagay ang platform sa ilalim ng bola.
Isang simpleng algorithm para dito, nakasulat sa pseudocode:
bawat frame/update habang tumatakbo ang laro:
kung ang bola ay nasa kaliwa ng sagwan:
ilipat sagwan pakaliwa
iba pa kung ang bola ay nasa kanan ng sagwan:
ilipat sagwan pakanan
Kung ang platform ay gumagalaw sa bilis ng bola, kung gayon ito ang perpektong algorithm para sa AI sa Pong. Hindi na kailangang gawing kumplikado ang anumang bagay kung walang napakaraming data at posibleng mga aksyon para sa ahente.
Ang diskarte na ito ay napakasimple na ang buong siklo ng Sense/Think/Act ay halos hindi napapansin. Ngunit nariyan ito:
- Ang bahagi ng Sense ay nasa dalawa kung pahayag. Alam ng laro kung nasaan ang bola at kung nasaan ang platform, kaya tinitingnan ito ng AI para sa impormasyong iyon.
- Kasama rin ang bahaging Think sa dalawang if statements. Naglalaman sila ng dalawang solusyon, na sa kasong ito ay kapwa eksklusibo. Bilang resulta, isa sa tatlong mga aksyon ang napili - ilipat ang platform sa kaliwa, ilipat ito sa kanan, o walang gawin kung ito ay nakaposisyon nang tama.
- Ang bahaging Act ay makikita sa Move Paddle Pakaliwa at Move Paddle Right na mga pahayag. Depende sa disenyo ng laro, maaari nilang ilipat ang platform kaagad o sa isang tiyak na bilis.
Ang ganitong mga diskarte ay tinatawag na reaktibo - mayroong isang simpleng hanay ng mga patakaran (sa kasong ito kung ang mga pahayag sa code) na tumutugon sa kasalukuyang estado ng mundo at kumikilos.
Puno ng desisyon
Ang halimbawa ng Pong ay aktwal na katumbas ng isang pormal na konsepto ng AI na tinatawag na puno ng desisyon. Ang algorithm ay dumaan dito upang maabot ang isang "dahon"—isang desisyon tungkol sa kung anong aksyon ang gagawin.
Gumawa tayo ng block diagram ng decision tree para sa algorithm ng ating platform:
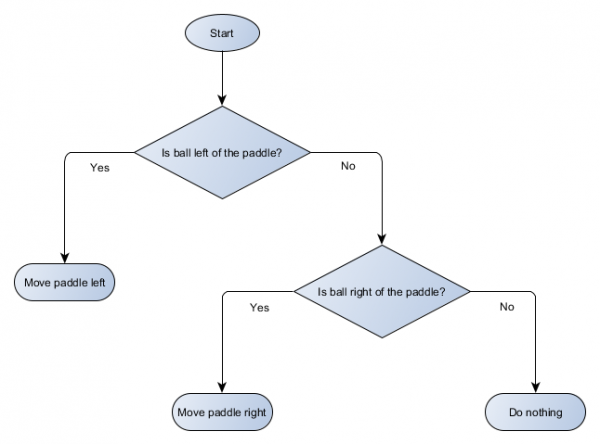
Ang bawat bahagi ng puno ay tinatawag na node - Gumagamit ang AI ng teorya ng graph upang ilarawan ang mga naturang istruktura. Mayroong dalawang uri ng mga node:
- Decision node: pagpili sa pagitan ng dalawang alternatibo batay sa pagsubok ng ilang kundisyon, kung saan ang bawat alternatibo ay kinakatawan bilang isang hiwalay na node.
- Mga end node: Ang aksyon na gagawin na kumakatawan sa panghuling desisyon.
Ang algorithm ay nagsisimula mula sa unang node (ang "ugat" ng puno). Ito ay maaaring gumawa ng isang desisyon tungkol sa kung aling child node ang pupuntahan, o ipapatupad nito ang aksyon na nakaimbak sa node at lalabas.
Ano ang pakinabang ng pagkakaroon ng decision tree na gawin ang parehong trabaho gaya ng mga if statement sa nakaraang seksyon? Mayroong pangkalahatang sistema dito kung saan ang bawat desisyon ay may isang kondisyon lamang at dalawang posibleng resulta. Nagbibigay-daan ito sa developer na lumikha ng AI mula sa data na kumakatawan sa mga desisyon sa isang puno nang hindi kinakailangang i-hard-code ito. Ipakita natin ito sa anyo ng talahanayan:
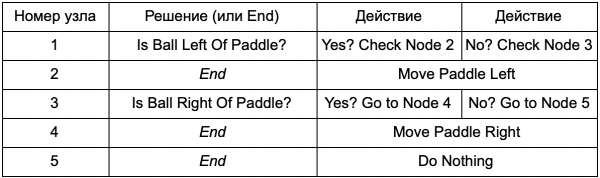
Sa gilid ng code makakakuha ka ng isang sistema para sa pagbabasa ng mga string. Gumawa ng node para sa bawat isa sa kanila, ikonekta ang logic ng desisyon batay sa pangalawang column, at mga child node batay sa ikatlo at ikaapat na column. Kailangan mo pa ring i-program ang mga kondisyon at aksyon, ngunit ngayon ang istraktura ng laro ay magiging mas kumplikado. Dito ka magdagdag ng mga karagdagang desisyon at pagkilos, at pagkatapos ay i-customize ang buong AI sa pamamagitan lamang ng pag-edit sa text file ng kahulugan ng puno. Susunod, ililipat mo ang file sa taga-disenyo ng laro, na maaaring magbago ng gawi nang hindi muling kino-compile ang laro o binabago ang code.
Ang mga puno ng desisyon ay lubhang kapaki-pakinabang kapag ang mga ito ay awtomatikong binuo mula sa isang malaking hanay ng mga halimbawa (halimbawa, gamit ang ID3 algorithm). Ginagawa silang isang epektibo at mataas na pagganap na tool para sa pag-uuri ng mga sitwasyon batay sa data na nakuha. Gayunpaman, lumalampas kami sa isang simpleng sistema para sa mga ahente upang pumili ng mga aksyon.
Mga senaryo
Sinuri namin ang isang sistema ng decision tree na gumamit ng mga paunang ginawang kundisyon at pagkilos. Ang taong nagdidisenyo ng AI ay maaaring ayusin ang puno gayunpaman ang gusto niya, ngunit kailangan pa rin niyang umasa sa coder na nag-program ng lahat ng ito. Paano kung maaari naming bigyan ang taga-disenyo ng mga tool upang lumikha ng kanilang sariling mga kundisyon o aksyon?
Upang ang programmer ay hindi na kailangang magsulat ng code para sa mga kundisyon Ay Ball Left Of Paddle at Ball Right Of Paddle, maaari siyang lumikha ng isang sistema kung saan ang taga-disenyo ay magsusulat ng mga kundisyon upang suriin ang mga halagang ito. Pagkatapos ang data ng decision tree ay magiging ganito:
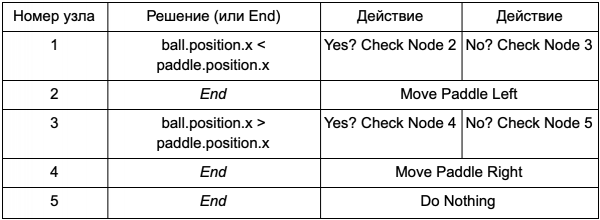
Ito ay mahalagang kapareho ng sa unang talahanayan, ngunit ang mga solusyon sa kanilang sarili ay may sariling code, medyo katulad ng kondisyonal na bahagi ng isang if statement. Sa gilid ng code, mababasa ito sa pangalawang column para sa mga node ng desisyon, ngunit sa halip na maghanap ng partikular na kundisyon na isasagawa (Is Ball Left Of Paddle), sinusuri nito ang conditional expression at nagbabalik ng tama o mali nang naaayon. Ginagawa ito gamit ang Lua o Angelscript scripting language. Gamit ang mga ito, ang isang developer ay maaaring kumuha ng mga bagay sa kanyang laro (bola at sagwan) at lumikha ng mga variable na magiging available sa script (ball.position). Gayundin, ang scripting language ay mas simple kaysa sa C++. Hindi ito nangangailangan ng buong yugto ng compilation, kaya mainam ito para sa mabilis na pagsasaayos ng lohika ng laro at pinapayagan ang mga "non-coder" na lumikha ng mga kinakailangang function mismo.
Sa halimbawa sa itaas, ang scripting language ay ginagamit lamang upang suriin ang conditional expression, ngunit maaari rin itong gamitin para sa mga aksyon. Halimbawa, ang data na Move Paddle Right ay maaaring maging isang script statement (ball.position.x += 10). Upang ang aksyon ay tinukoy din sa script, nang hindi kailangang i-program ang Move Paddle Right.
Maaari kang pumunta pa at isulat ang buong decision tree sa isang scripting language. Ito ay magiging code sa anyo ng mga hardcoded conditional statement, ngunit sila ay matatagpuan sa mga panlabas na script file, iyon ay, maaari silang baguhin nang hindi muling kino-compile ang buong programa. Madalas mong ma-edit ang script file habang naglalaro para mabilis na masubukan ang iba't ibang mga tugon ng AI.
Tugon sa Kaganapan
Ang mga halimbawa sa itaas ay perpekto para kay Pong. Patuloy nilang pinapatakbo ang siklo ng Sense/Think/Act at kumikilos batay sa pinakabagong estado ng mundo. Ngunit sa mas kumplikadong mga laro kailangan mong tumugon sa mga indibidwal na kaganapan, at hindi suriin ang lahat nang sabay-sabay. Si Pong sa kasong ito ay isa nang masamang halimbawa. Pumili tayo ng isa pa.
Isipin ang isang tagabaril kung saan ang mga kalaban ay hindi gumagalaw hanggang sa makita nila ang manlalaro, pagkatapos nito ay kumilos sila depende sa kanilang "espesyalisasyon": may tatakbo upang "magmadali", may aatake mula sa malayo. Isa pa rin itong pangunahing reaktibong sistema - "kung ang isang manlalaro ay may nakita, gumawa ng isang bagay" - ngunit maaari itong lohikal na hatiin sa isang Player Seen na kaganapan at isang Reaksyon (pumili ng tugon at isagawa ito).
Ibinabalik tayo nito sa siklo ng Sense/Think/Act. Maaari tayong mag-code ng bahagi ng Sense na susuriin ang bawat frame kung nakikita ng AI ang player. Kung hindi, walang mangyayari, ngunit kung nakikita nito, gagawin ang kaganapan ng Player Seen. Ang code ay magkakaroon ng hiwalay na seksyon na nagsasabing "kapag nangyari ang Player Seen event, gawin" kung saan ang tugon na kailangan mo upang tugunan ang mga bahagi ng Think and Act. Kaya, magse-set up ka ng mga reaksyon sa kaganapan ng Player Seen: para sa "nagmamadali" na karakter - ChargeAndAttack, at para sa sniper - HideAndSnipe. Ang mga ugnayang ito ay maaaring gawin sa data file para sa mabilis na pag-edit nang hindi kinakailangang muling mag-compile. Magagamit din dito ang Scripting language.
Paggawa ng mahihirap na desisyon
Bagama't napakalakas ng mga simpleng sistema ng reaksyon, maraming sitwasyon kung saan hindi sapat ang mga ito. Minsan kailangan mong gumawa ng iba't ibang mga desisyon batay sa kung ano ang kasalukuyang ginagawa ng ahente, ngunit mahirap isipin ito bilang isang kondisyon. Minsan napakaraming kundisyon para epektibong kumatawan sa mga ito sa isang decision tree o script. Minsan kailangan mong suriin nang maaga kung paano magbabago ang sitwasyon bago magpasya sa susunod na hakbang. Higit pang mga sopistikadong diskarte ang kailangan upang malutas ang mga problemang ito.
May hangganan na makina ng estado
Ang Finite state machine o FSM (finite state machine) ay isang paraan ng pagsasabi na ang aming ahente ay kasalukuyang nasa isa sa ilang posibleng estado, at maaari itong lumipat mula sa isang estado patungo sa isa pa. Mayroong isang tiyak na bilang ng mga naturang estado—kaya ang pangalan. Ang pinakamagandang halimbawa mula sa buhay ay isang ilaw ng trapiko. Mayroong iba't ibang mga pagkakasunud-sunod ng mga ilaw sa iba't ibang mga lugar, ngunit ang prinsipyo ay pareho - ang bawat estado ay kumakatawan sa isang bagay (huminto, lumakad, atbp.). Ang isang traffic light ay nasa isang estado lamang sa anumang oras, at gumagalaw mula sa isa't isa batay sa mga simpleng panuntunan.
Ito ay isang katulad na kuwento sa mga NPC sa mga laro. Halimbawa, kumuha tayo ng bantay na may mga sumusunod na estado:
- Nagpatrolya.
- umaatake.
- tumatakas.
At ang mga kundisyong ito para sa pagbabago ng estado nito:
- Kung nakikita ng bantay ang kaaway, siya ay umaatake.
- Kung umatake ang guwardiya ngunit hindi na nakikita ang kalaban, babalik siya sa pagpapatrolya.
- Kung ang isang guwardiya ay umatake ngunit malubhang nasugatan, siya ay tumakas.
Maaari ka ring sumulat ng mga if-statement na may variable na estado ng tagapag-alaga at iba't ibang mga pagsusuri: may kaaway ba sa malapit, ano ang antas ng kalusugan ng NPC, atbp. Magdagdag pa tayo ng ilang estado:
- Katamaran - sa pagitan ng mga patrol.
- Paghahanap - kapag nawala ang napansing kaaway.
- Paghahanap ng Tulong - kapag may nakitang kalaban, ngunit napakalakas para lumaban nang mag-isa.
Ang pagpipilian para sa bawat isa sa kanila ay limitado - halimbawa, ang bantay ay hindi hahanapin ang isang nakatagong kaaway kung siya ay may mababang kalusugan.
Pagkatapos ng lahat, mayroong isang malaking listahan ng mga "kung" , Iyon " ay maaaring maging masyadong masalimuot, kaya kailangan nating gawing pormal ang isang paraan na nagbibigay-daan sa amin na panatilihin sa isip ang mga estado at paglipat sa pagitan ng mga estado. Upang gawin ito, isinasaalang-alang namin ang lahat ng mga estado, at sa ilalim ng bawat estado ay isinulat namin sa isang listahan ang lahat ng mga paglipat sa ibang mga estado, kasama ang mga kondisyon na kinakailangan para sa kanila.
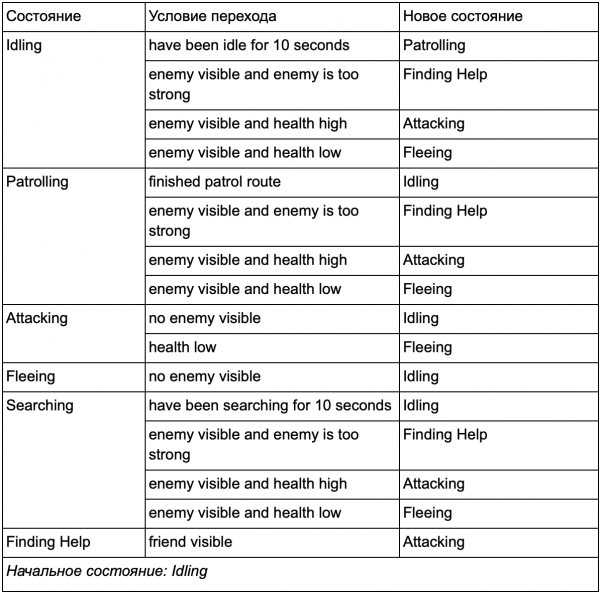
Ito ay isang state transition table - isang komprehensibong paraan upang kumatawan sa FSM. Gumuhit tayo ng diagram at makakuha ng kumpletong pangkalahatang-ideya kung paano nagbabago ang gawi ng NPC.
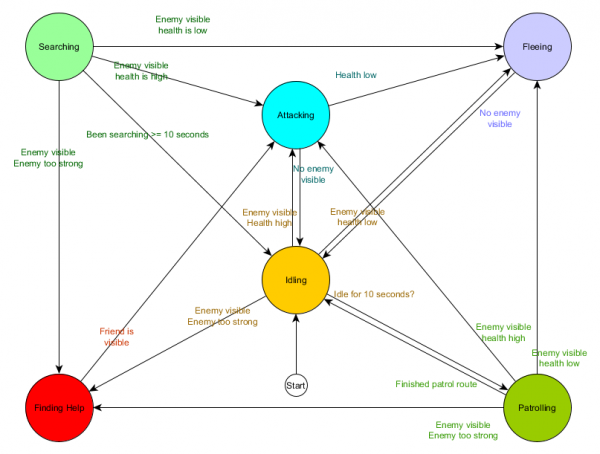
Ang diagram ay sumasalamin sa kakanyahan ng paggawa ng desisyon para sa ahente na ito batay sa kasalukuyang sitwasyon. Bukod dito, ang bawat arrow ay nagpapakita ng paglipat sa pagitan ng mga estado kung ang kundisyon sa tabi nito ay totoo.
Ang bawat pag-update ay tinitingnan namin ang kasalukuyang estado ng ahente, tinitingnan ang listahan ng mga transition, at kung natutugunan ang mga kundisyon para sa paglipat, tinatanggap nito ang bagong estado. Halimbawa, sinusuri ng bawat frame kung ang 10 segundong timer ay nag-expire na, at kung gayon, ang bantay ay pupunta mula sa Idling state patungo sa Patrolling. Sa parehong paraan, sinusuri ng Attacking state ang kalusugan ng ahente - kung ito ay mababa, pagkatapos ay mapupunta ito sa Fleeing state.
Ito ay pinangangasiwaan ang mga transition sa pagitan ng mga estado, ngunit paano naman ang pag-uugaling nauugnay sa mga estado mismo? Sa mga tuntunin ng pagpapatupad ng aktwal na pag-uugali para sa isang partikular na estado, karaniwang may dalawang uri ng "hook" kung saan nagtatalaga kami ng mga aksyon sa FSM:
- Mga pagkilos na pana-panahon naming ginagawa para sa kasalukuyang estado.
- Ang mga aksyon na ginagawa namin kapag lumilipat mula sa isang estado patungo sa isa pa.
Mga halimbawa para sa unang uri. Ililipat ng estado ng Patrolling ang ahente sa ruta ng patrol sa bawat frame. Susubukan ng Attacking state na magsimula ng pag-atake sa bawat frame o paglipat sa isang estado kung saan ito posible.
Para sa pangalawang uri, isaalang-alang ang paglipat "kung ang kalaban ay nakikita at ang kalaban ay masyadong malakas, pagkatapos ay pumunta sa Paghahanap ng Tulong na estado. Dapat piliin ng ahente kung saan pupunta para sa tulong at iimbak ang impormasyong ito upang malaman ng estado ng Paghahanap ng Tulong kung saan pupunta. Kapag natagpuan ang tulong, babalik ang ahente sa estado ng Pag-atake. Sa puntong ito, gugustuhin niyang sabihin sa kaalyado ang tungkol sa banta, kaya maaaring mangyari ang NotifyFriendOfThreat na aksyon.
Muli, maaari nating tingnan ang sistemang ito sa pamamagitan ng lens ng Sense/Think/Act cycle. Ang kahulugan ay nakapaloob sa data na ginamit ng lohika ng paglipat. Mag-isip - magagamit ang mga transition sa bawat estado. At ang Act ay isinasagawa sa pamamagitan ng mga aksyon na pana-panahong ginagawa sa loob ng isang estado o sa mga paglipat sa pagitan ng mga estado.
Minsan ang patuloy na pagboto sa mga kondisyon ng paglipat ay maaaring magastos. Halimbawa, kung ang bawat ahente ay nagsasagawa ng mga kumplikadong kalkulasyon sa bawat frame upang matukoy kung makakakita ito ng mga kaaway at maunawaan kung maaari itong lumipat mula sa estado ng Patrolling patungo sa Pag-atake, aabutin ito ng maraming oras ng CPU.
Ang mga mahahalagang pagbabago sa estado ng mundo ay maaaring isipin bilang mga kaganapan na ipoproseso habang nangyayari ang mga ito. Sa halip na suriin ng FSM ang kundisyon ng paglipat na "makikita ba ng aking ahente ang manlalaro?" bawat frame, maaaring i-configure ang isang hiwalay na sistema upang masuri nang hindi gaanong madalas (hal. 5 beses bawat segundo). At ang resulta ay mag-isyu ng Player Seen kapag pumasa ang tseke.
Ipapasa ito sa FSM, na dapat na ngayong pumunta sa natanggap na kondisyon ng Player Seen event at tumugon nang naaayon. Ang resultang pag-uugali ay pareho maliban sa isang halos hindi mahahalata na pagkaantala bago tumugon. Ngunit bumuti ang pagganap bilang resulta ng paghihiwalay ng bahagi ng Sense sa isang hiwalay na bahagi ng programa.
Hierarchical na may hangganan na makina ng estado
Gayunpaman, ang pagtatrabaho sa malalaking FSM ay hindi palaging maginhawa. Kung gusto naming palawakin ang estado ng pag-atake upang paghiwalayin ang MeleeAttacking at RangedAttacking, kakailanganin naming baguhin ang mga transition mula sa lahat ng iba pang mga estado na humahantong sa estado ng Pag-atake (kasalukuyan at hinaharap).
Marahil ay napansin mo na sa aming halimbawa mayroong maraming mga duplicate na paglipat. Karamihan sa mga transition sa Idling state ay kapareho ng mga transition sa Patrolling state. Mabuti kung hindi ulitin ang ating sarili, lalo na kung magdaragdag tayo ng higit pang mga katulad na estado. Makatuwirang igrupo ang Idling at Patrolling sa ilalim ng pangkalahatang label na "non-combat", kung saan mayroon lamang isang karaniwang hanay ng mga transition upang labanan ang mga estado. Kung iisipin natin ang label na ito bilang isang estado, ang Idling at Patrolling ay magiging mga substate. Isang halimbawa ng paggamit ng hiwalay na transition table para sa isang bagong non-combat substate:
Pangunahing estado:
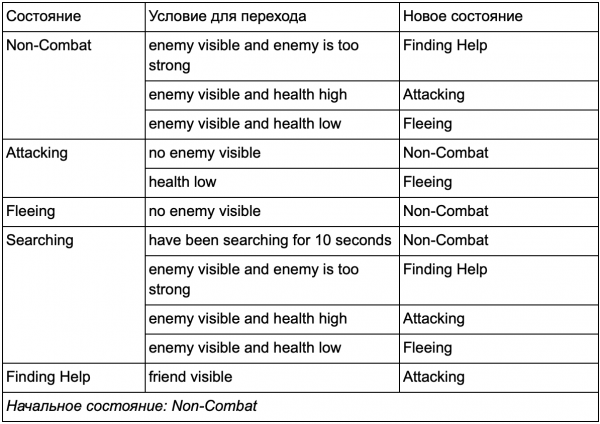
Out of battle status:

At sa anyo ng diagram:
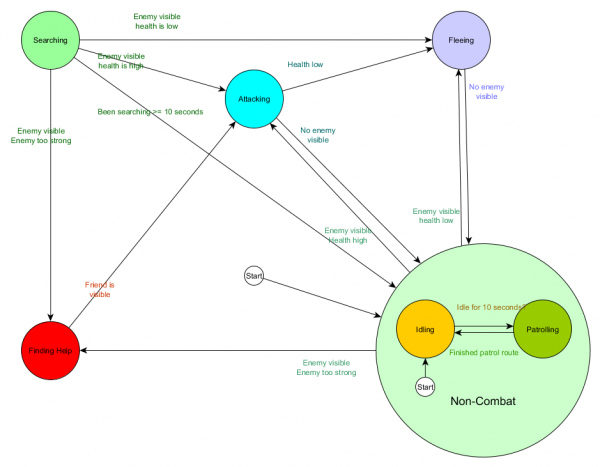
Ito ay ang parehong sistema, ngunit may isang bagong non-combat state na kinabibilangan ng Idling at Patrolling. Sa bawat estado na naglalaman ng FSM na may mga substate (at ang mga substate na ito, sa turn, ay naglalaman ng sarili nilang mga FSM - at iba pa hangga't kailangan mo), nakakakuha kami ng Hierarchical Finite State Machine o HFSM (hierarchical finite state machine). Sa pamamagitan ng pagpapangkat ng estado na hindi nakikipaglaban, pinutol namin ang isang grupo ng mga kalabisan na paglipat. Magagawa natin ang parehong para sa anumang mga bagong estado na may mga karaniwang transition. Halimbawa, kung sa hinaharap ay palawakin natin ang Attacking state sa MeleeAttacking at MissileAttacking states, sila ay magiging mga substate na lumilipat sa pagitan ng isa't isa batay sa distansya sa kaaway at pagkakaroon ng ammo. Bilang resulta, ang mga kumplikadong gawi at sub-gawi ay maaaring katawanin na may pinakamababang mga duplicate na transition.
Puno ng pag-uugali
Sa HFSM, ang mga kumplikadong kumbinasyon ng mga pag-uugali ay nilikha sa isang simpleng paraan. Gayunpaman, may kaunting kahirapan na ang paggawa ng desisyon sa anyo ng mga panuntunan sa paglipat ay malapit na nauugnay sa kasalukuyang estado. At sa maraming laro ito mismo ang kailangan. At ang maingat na paggamit ng hierarchy ng estado ay maaaring mabawasan ang bilang ng mga pag-uulit ng paglipat. Ngunit minsan kailangan mo ng mga panuntunang gumagana kahit saang estado ka naroroon, o nalalapat sa halos anumang estado. Halimbawa, kung ang kalusugan ng isang ahente ay bumaba sa 25%, gugustuhin mong tumakas siya kahit na siya ay nasa labanan, walang ginagawa, o nagsasalita - kailangan mong idagdag ang kundisyong ito sa bawat estado. At kung gusto ng iyong taga-disenyo na baguhin ang mababang threshold sa kalusugan mula 25% hanggang 10%, kakailanganin itong gawin muli.
Sa isip, ang sitwasyong ito ay nangangailangan ng isang sistema kung saan ang mga pagpapasya tungkol sa "kung anong estado ang dapat naroroon" ay nasa labas ng mga estado mismo, upang makagawa lamang ng mga pagbabago sa isang lugar at hindi mahawakan ang mga kundisyon ng paglipat. Lumilitaw ang mga puno ng pag-uugali dito.
Mayroong ilang mga paraan upang ipatupad ang mga ito, ngunit ang esensya ay halos pareho para sa lahat at katulad ng isang puno ng desisyon: ang algorithm ay nagsisimula sa isang "ugat" na node, at ang puno ay naglalaman ng mga node na kumakatawan sa alinman sa mga desisyon o aksyon. Mayroong ilang mga pangunahing pagkakaiba bagaman:
- Ibinabalik na ngayon ng mga node ang isa sa tatlong value: Nagtagumpay (kung nakumpleto ang trabaho), Nabigo (kung hindi ito masisimulan), o Running (kung tumatakbo pa rin ito at walang huling resulta).
- Wala nang mga decision node na mapipili sa pagitan ng dalawang alternatibo. Sa halip, sila ay mga node ng Dekorador, na mayroong isang node ng bata. Kung Magtagumpay sila, ipapatupad nila ang kanilang nag-iisang child node.
- Ang mga node na nagsasagawa ng mga aksyon ay nagbabalik ng isang Running value upang kumatawan sa mga aksyon na ginagawa.
Ang maliit na hanay ng mga node na ito ay maaaring pagsamahin upang lumikha ng isang malaking bilang ng mga kumplikadong pag-uugali. Isipin natin ang bantay ng HFSM mula sa nakaraang halimbawa bilang isang puno ng pag-uugali:
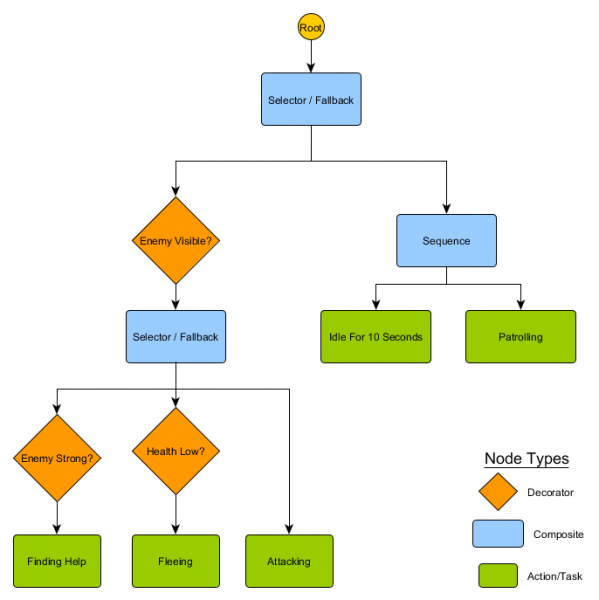
Sa istrukturang ito ay dapat walang malinaw na paglipat mula sa Idling/Patrolling states patungo sa Attacking o anumang iba pang estado. Kung makikita ang isang kalaban at mababa ang kalusugan ng karakter, titigil ang pagpapatupad sa Fleeing node, anuman ang node na dati nitong ini-execute - Patrolling, Idling, Attacking, o anumang iba pa.
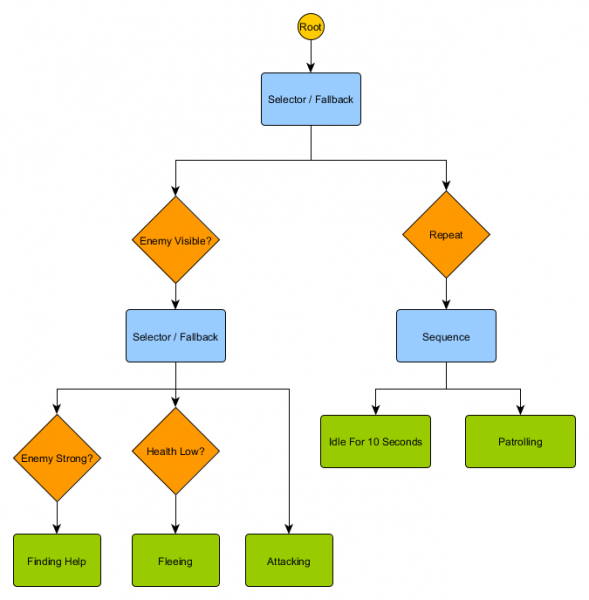
Ang mga puno ng pag-uugali ay kumplikado—maraming paraan upang mabuo ang mga ito, at ang paghahanap ng tamang kumbinasyon ng mga dekorador at compound node ay maaaring maging mahirap. Mayroon ding mga tanong tungkol sa kung gaano kadalas suriin ang puno - gusto ba nating dumaan sa bawat bahagi nito o kapag nagbago ang isa sa mga kundisyon? Paano namin iniimbak ang estado na nauukol sa mga node - paano namin malalaman kung 10 segundo na kaming Idling, o paano namin malalaman kung aling mga node ang huling nag-execute para maproseso namin nang tama ang sequence?
Ito ang dahilan kung bakit maraming mga pagpapatupad. Halimbawa, pinalitan ng ilang system ang mga node ng dekorador ng mga inline na dekorador. Muli nilang sinusuri ang puno kapag nagbago ang mga kundisyon ng dekorador, tumulong sa pagsali sa mga node, at nagbibigay ng mga pana-panahong pag-update.
Sistemang nakabatay sa utility
Ang ilang mga laro ay may maraming iba't ibang mga mekanika. Ito ay kanais-nais na matanggap nila ang lahat ng mga benepisyo ng simple at pangkalahatang mga panuntunan sa paglipat, ngunit hindi kinakailangan sa anyo ng isang kumpletong puno ng pag-uugali. Sa halip na magkaroon ng malinaw na hanay ng mga pagpipilian o puno ng mga posibleng aksyon, mas madaling suriin ang lahat ng mga aksyon at piliin ang pinakaangkop sa ngayon.
Ang Utility-based system ay makakatulong dito. Ito ay isang sistema kung saan ang ahente ay may iba't ibang mga aksyon at pinipili kung alin ang isasagawa batay sa relatibong utility ng bawat isa. Kung ang utility ay isang di-makatwirang sukatan kung gaano kahalaga o kanais-nais para sa ahente na gawin ang pagkilos na ito.
Ang kinakalkula na utility ng isang aksyon batay sa kasalukuyang estado at kapaligiran, maaaring suriin at piliin ng ahente ang pinakaangkop na ibang estado anumang oras. Ito ay katulad ng FSM, maliban kung ang mga transition ay tinutukoy ng isang pagtatantya para sa bawat potensyal na estado, kabilang ang kasalukuyang estado. Pakitandaan na pipiliin namin ang pinakakapaki-pakinabang na pagkilos upang magpatuloy (o manatili kung nakumpleto na namin ito). Para sa higit pang pagkakaiba-iba, ito ay maaaring isang balanse ngunit random na pagpili mula sa isang maliit na listahan.
Nagtatalaga ang system ng arbitrary na hanay ng mga halaga ng utility—halimbawa, mula 0 (ganap na hindi kanais-nais) hanggang 100 (ganap na kanais-nais). Ang bawat aksyon ay may bilang ng mga parameter na nakakaapekto sa pagkalkula ng halagang ito. Pagbabalik sa aming halimbawa ng tagapag-alaga:

Ang mga paglipat sa pagitan ng mga aksyon ay malabo—anumang estado ay maaaring sumunod sa anumang iba pa. Ang mga priyoridad ng aksyon ay matatagpuan sa mga ibinalik na halaga ng utility. Kung ang isang kalaban ay nakikita, at ang kalaban na iyon ay malakas, at ang kalusugan ng karakter ay mababa, kung gayon ang Fleeing at FindingHelp ay magbabalik ng mataas na hindi-zero na mga halaga. Sa kasong ito, ang FindingHelp ay palaging magiging mas mataas. Gayundin, ang mga non-combat na aktibidad ay hindi kailanman bumabalik ng higit sa 50, kaya sila ay palaging mas mababa kaysa sa mga labanan. Kailangan mong isaalang-alang ito kapag lumilikha ng mga aksyon at kinakalkula ang kanilang utility.
Sa aming halimbawa, ang mga aksyon ay nagbabalik ng alinman sa isang nakapirming pare-parehong halaga o isa sa dalawang nakapirming halaga. Ang isang mas makatotohanang sistema ay magbabalik ng isang pagtatantya mula sa patuloy na hanay ng mga halaga. Halimbawa, ang pagkilos na Tumakas ay nagbabalik ng mas mataas na halaga ng utility kung mababa ang kalusugan ng ahente, at ang pagkilos na Pag-atake ay nagbabalik ng mas mababang halaga ng utility kung masyadong malakas ang kaaway. Dahil dito, inuuna ang pagkilos ng Pagtakas kaysa Pag-atake sa anumang sitwasyon kung saan nararamdaman ng ahente na wala siyang sapat na kalusugan upang talunin ang kaaway. Nagbibigay-daan ito sa mga aksyon na ma-prioritize batay sa anumang bilang ng mga pamantayan, na ginagawang mas flexible at variable ang diskarteng ito kaysa sa isang puno ng pag-uugali o FSM.
Ang bawat aksyon ay may maraming kundisyon para sa pagkalkula ng programa. Maaari silang isulat sa scripting language o bilang isang serye ng mga mathematical formula. Ang Sims, na ginagaya ang pang-araw-araw na gawain ng isang character, ay nagdaragdag ng karagdagang layer ng pagkalkula - ang ahente ay tumatanggap ng isang serye ng mga "motivations" na nakakaimpluwensya sa mga rating ng utility. Kung nagugutom ang isang karakter, lalo silang magugutom sa paglipas ng panahon, at tataas ang halaga ng utility ng pagkilos ng EatFood hanggang sa gawin ito ng karakter, binabawasan ang antas ng gutom at ibabalik sa zero ang halaga ng EatFood.
Ang ideya ng pagpili ng mga aksyon batay sa isang sistema ng rating ay medyo simple, kaya ang isang Utility-based na sistema ay maaaring gamitin bilang bahagi ng mga proseso ng paggawa ng desisyon ng AI, sa halip na bilang isang kumpletong kapalit para sa mga ito. Maaaring humingi ang decision tree ng utility rating ng dalawang child node at piliin ang mas mataas. Katulad nito, ang isang puno ng pag-uugali ay maaaring magkaroon ng isang pinagsama-samang Utility node upang suriin ang utility ng mga aksyon upang magpasya kung aling bata ang isasagawa.
Paggalaw at pag-navigate
Sa mga nakaraang halimbawa, mayroon kaming isang plataporma na inilipat namin sa kaliwa o kanan, at isang guwardiya na nagpapatrolya o umaatake. Ngunit paano natin eksaktong pinangangasiwaan ang paggalaw ng ahente sa loob ng isang yugto ng panahon? Paano tayo magtatakda ng bilis, paano natin maiiwasan ang mga hadlang, at paano tayo nagpaplano ng ruta kapag ang pagpunta sa isang destinasyon ay mas mahirap kaysa sa paglipat lamang sa isang tuwid na linya? Tingnan natin ito.
Pamamahala
Sa paunang yugto, ipagpalagay namin na ang bawat ahente ay may halaga ng bilis, na kinabibilangan ng kung gaano ito kabilis gumagalaw at sa anong direksyon. Maaari itong masukat sa metro bawat segundo, kilometro bawat oras, pixel bawat segundo, atbp. Kapag naaalala ang Sense/Think/Act loop, maiisip natin na ang Think part ay pumipili ng bilis, at ang Act na bahagi ay inilalapat ang bilis na iyon sa ahente. Kadalasan, ang mga laro ay may sistema ng pisika na gumagawa ng gawaing ito para sa iyo, pag-aaral ng halaga ng bilis ng bawat bagay at pagsasaayos nito. Samakatuwid, maaari mong iwanan ang AI na may isang gawain - upang magpasya kung anong bilis ang dapat magkaroon ng ahente. Kung alam mo kung saan dapat ang ahente, kailangan mong ilipat ito sa tamang direksyon sa isang itinakdang bilis. Isang napakaliit na equation:
ninanais_paglalakbay = destinasyon_posisyon – ahente_posisyon
Isipin ang isang 2D na mundo. Ang ahente ay nasa punto (-2,-2), ang destinasyon ay nasa isang lugar sa hilagang-silangan sa punto (30, 20), at ang kinakailangang landas para makarating doon ang ahente ay (32, 22). Sabihin nating ang mga posisyong ito ay sinusukat sa metro - kung kukunin natin ang bilis ng ahente na 5 metro bawat segundo, susukatin natin ang ating displacement vector at makakuha ng bilis na humigit-kumulang (4.12, 2.83). Gamit ang mga parameter na ito, darating ang ahente sa patutunguhan nito sa loob ng halos 8 segundo.
Maaari mong muling kalkulahin ang mga halaga anumang oras. Kung ang ahente ay nasa kalahati sa target, ang paggalaw ay magiging kalahati ng haba, ngunit dahil ang maximum na bilis ng ahente ay 5 m/s (napagpasyahan namin ito sa itaas), ang bilis ay magiging pareho. Gumagana rin ito para sa paglipat ng mga target, na nagpapahintulot sa ahente na gumawa ng maliliit na pagbabago habang sila ay gumagalaw.
Ngunit gusto namin ng higit pang pagkakaiba-iba - halimbawa, dahan-dahang pagtaas ng bilis upang gayahin ang isang karakter na lumilipat mula sa nakatayo hanggang sa pagtakbo. Ang parehong ay maaaring gawin sa dulo bago huminto. Ang mga feature na ito ay kilala bilang steering behaviors, na ang bawat isa ay may mga partikular na pangalan: Seek, Flee, Arrival, atbp. Ang ideya ay ang mga acceleration forces ay maaaring ilapat sa bilis ng ahente, batay sa paghahambing ng posisyon ng ahente at kasalukuyang bilis sa destinasyon sa upang gumamit ng iba't ibang paraan ng paglipat sa layunin.
Ang bawat pag-uugali ay may bahagyang naiibang layunin. Ang Seek and Arrival ay mga paraan upang ilipat ang isang ahente sa isang destinasyon. Ang Pag-iwas sa Balakid at Paghihiwalay ay ayusin ang paggalaw ng ahente upang maiwasan ang mga hadlang sa daan patungo sa layunin. Ang Alignment at Cohesion ay nagpapanatili sa mga ahente na magkasamang gumagalaw. Ang anumang bilang ng iba't ibang gawi sa pagpipiloto ay maaaring isama upang makabuo ng iisang path vector na isinasaalang-alang ang lahat ng mga salik. Isang ahente na gumagamit ng mga gawi sa Pagdating, Paghihiwalay, at Pag-iwas sa Balakid upang lumayo sa mga pader at iba pang ahente. Ang diskarte na ito ay mahusay na gumagana sa mga bukas na lokasyon nang walang mga hindi kinakailangang detalye.
Sa mas mahirap na mga kondisyon, ang pagdaragdag ng iba't ibang mga pag-uugali ay mas masahol pa - halimbawa, ang isang ahente ay maaaring makaalis sa isang pader dahil sa isang salungatan sa pagitan ng Pagdating at Pag-iwas sa Obstacle. Samakatuwid, kailangan mong isaalang-alang ang mga opsyon na mas kumplikado kaysa sa simpleng pagdaragdag ng lahat ng mga halaga. Ang paraan ay ito: sa halip na magdagdag ng mga resulta ng bawat pag-uugali, maaari mong isaalang-alang ang paggalaw sa iba't ibang direksyon at piliin ang pinakamahusay na opsyon.
Gayunpaman, sa isang kumplikadong kapaligiran na may mga dead ends at mga pagpipilian tungkol sa kung aling paraan upang pumunta, kakailanganin namin ng isang bagay na mas advanced.
Paghanap ng paraan
Ang mga pag-uugali sa pagpipiloto ay mahusay para sa simpleng paggalaw sa isang bukas na lugar (football field o arena) kung saan ang pagpunta mula A hanggang B ay isang tuwid na landas na may maliliit na detour lamang sa paligid ng mga hadlang. Para sa mga kumplikadong ruta, kailangan namin ang paghahanap ng landas, na isang paraan ng paggalugad sa mundo at pagpapasya sa isang ruta na dadaan dito.
Ang pinakasimpleng ay maglapat ng grid sa bawat parisukat sa tabi ng ahente at suriin kung alin sa kanila ang pinapayagang lumipat. Kung ang isa sa kanila ay isang destinasyon, pagkatapos ay sundin ang ruta mula sa bawat parisukat hanggang sa nauna hanggang sa maabot mo ang simula. Ito ang ruta. Kung hindi, ulitin ang proseso sa kalapit na iba pang mga parisukat hanggang sa mahanap mo ang iyong patutunguhan o maubusan ka ng mga parisukat (ibig sabihin ay walang posibleng ruta). Ito ang pormal na kilala bilang Breadth-First Search o BFS (breadth-first search algorithm). Sa bawat hakbang ay tumitingin siya sa lahat ng direksyon (kaya lapad, "lapad"). Ang espasyo sa paghahanap ay parang wavefront na gumagalaw hanggang sa maabot nito ang ninanais na lokasyon - ang espasyo sa paghahanap ay lumalawak sa bawat hakbang hanggang sa maisama ang dulong punto, pagkatapos ay maaari itong masubaybayan pabalik sa simula.
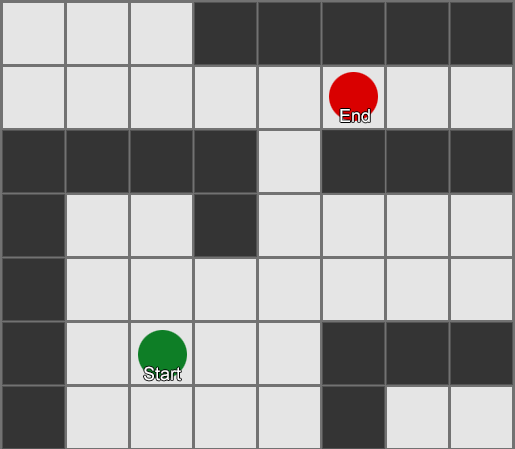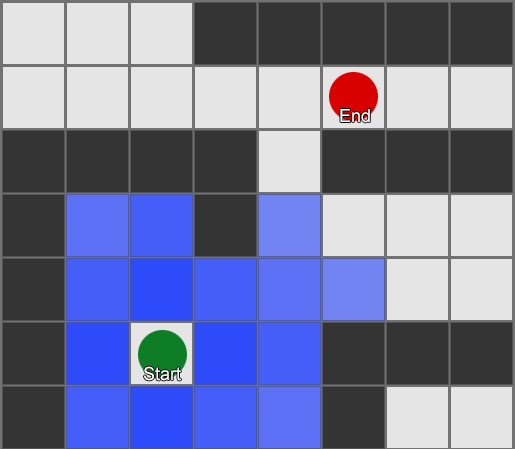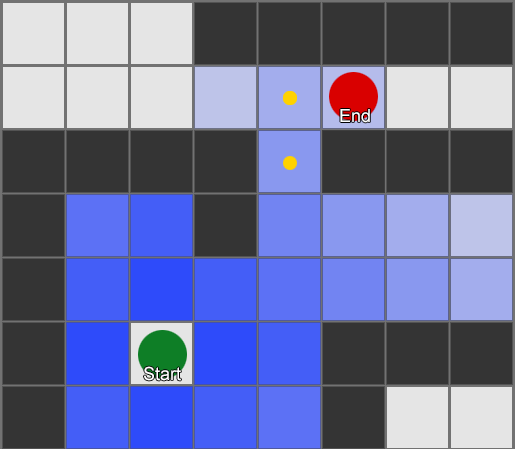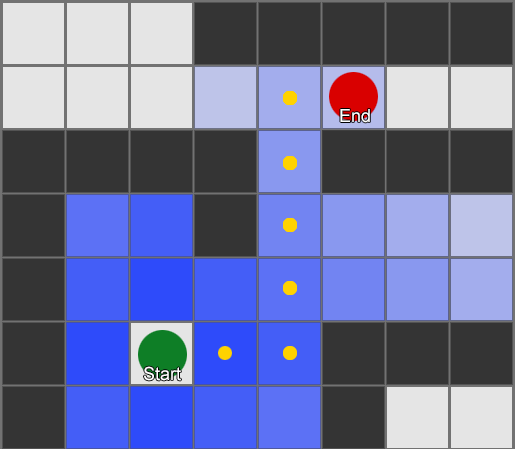
Bilang isang resulta, makakatanggap ka ng isang listahan ng mga parisukat kung saan ang nais na ruta ay pinagsama-sama. Ito ang landas (kaya, paghahanap ng landas) - isang listahan ng mga lugar na bibisitahin ng ahente habang sinusundan ang destinasyon.
Dahil alam natin ang posisyon ng bawat parisukat sa mundo, maaari tayong gumamit ng mga pag-uugali ng pagpipiloto upang lumipat sa landas - mula sa node 1 hanggang sa node 2, pagkatapos ay mula sa node 2 hanggang sa node 3, at iba pa. Ang pinakasimpleng opsyon ay ang magtungo sa gitna ng susunod na parisukat, ngunit ang mas magandang opsyon ay huminto sa gitna ng gilid sa pagitan ng kasalukuyang parisukat at ng susunod. Dahil dito, ang ahente ay magagawang maghiwa-hiwalay sa matalim na pagliko.
Ang algorithm ng BFS ay mayroon ding mga disadvantages - nag-explore ito ng maraming mga parisukat sa "maling" direksyon tulad ng sa "tamang" direksyon. Dito pumapasok ang isang mas kumplikadong algorithm na tinatawag na A* (A star). Gumagana ito sa parehong paraan, ngunit sa halip na bulag na suriin ang mga parisukat ng kapitbahay (pagkatapos ay mga kapitbahay ng mga kapitbahay, pagkatapos ay mga kapitbahay ng mga kapitbahay ng mga kapitbahay, at iba pa), kinokolekta nito ang mga node sa isang listahan at pag-uri-uriin ang mga ito upang ang susunod na node na susuriin ay palaging ang isa na humahantong sa pinakamaikling ruta. Ang mga node ay pinagbukod-bukod batay sa isang heuristic na isinasaalang-alang ang dalawang bagay-ang "gastos" ng isang hypothetical na ruta patungo sa nais na parisukat (kabilang ang anumang mga gastos sa paglalakbay) at isang pagtatantya kung gaano kalayo ang parisukat na iyon mula sa patutunguhan (biasin ang paghahanap sa tamang daan).
Ang halimbawang ito ay nagpapakita na ang ahente ay nag-e-explore ng isang parisukat sa isang pagkakataon, sa bawat oras na pumipili ng katabing isa na pinaka-promising. Ang resultang path ay kapareho ng BFS, ngunit mas kaunting mga parisukat ang isinaalang-alang sa proseso - na may malaking epekto sa pagganap ng laro.
Paggalaw na walang grid
Ngunit karamihan sa mga laro ay hindi inilatag sa isang grid, at madalas na imposibleng gawin ito nang hindi sinasakripisyo ang pagiging totoo. Kailangan ang mga kompromiso. Ano ang sukat ng mga parisukat? Masyadong malaki at hindi nila mairepresenta nang tama ang maliliit na corridors o mga liko, masyadong maliit at magkakaroon ng masyadong maraming mga parisukat na hahanapin, na sa huli ay magtatagal ng maraming oras.
Ang unang bagay na dapat maunawaan ay ang isang mesh ay nagbibigay sa amin ng isang graph ng mga konektadong node. Ang mga algorithm ng A* at BFS ay talagang gumagana sa mga graph at walang pakialam sa aming mesh. Maaari kaming maglagay ng mga node saanman sa mundo ng laro: hangga't may koneksyon sa pagitan ng alinmang dalawang konektadong node, gayundin sa pagitan ng mga punto ng simula at pagtatapos at kahit isa sa mga node, gagana ang algorithm tulad ng dati. Madalas itong tinatawag na waypoint system, dahil ang bawat node ay kumakatawan sa isang makabuluhang posisyon sa mundo na maaaring maging bahagi ng anumang bilang ng hypothetical na mga landas.
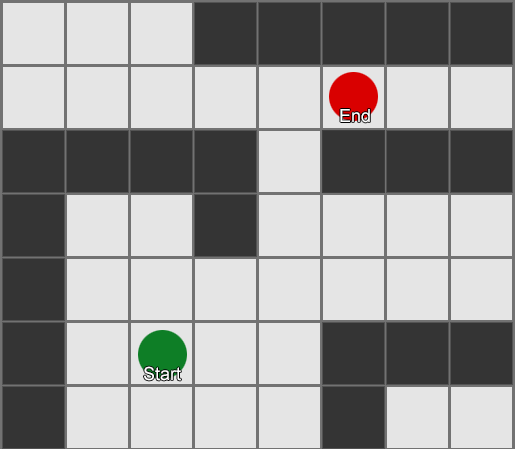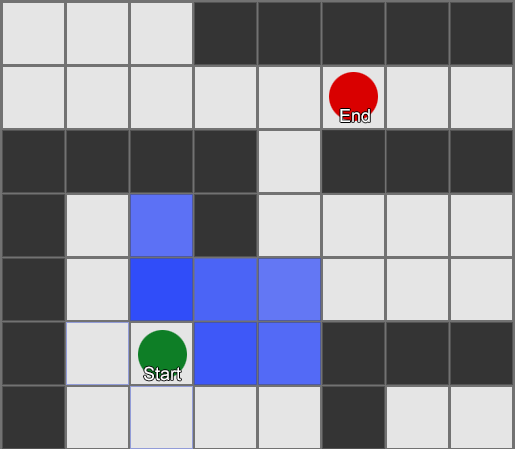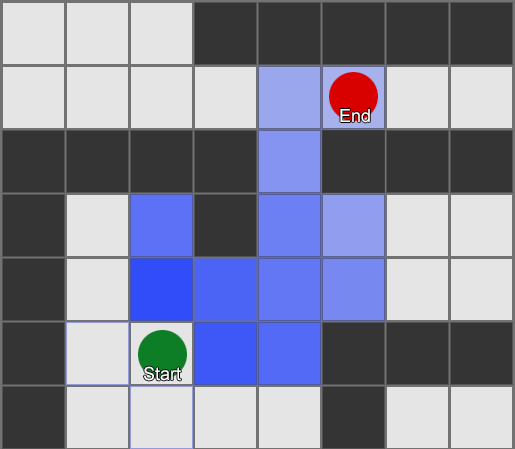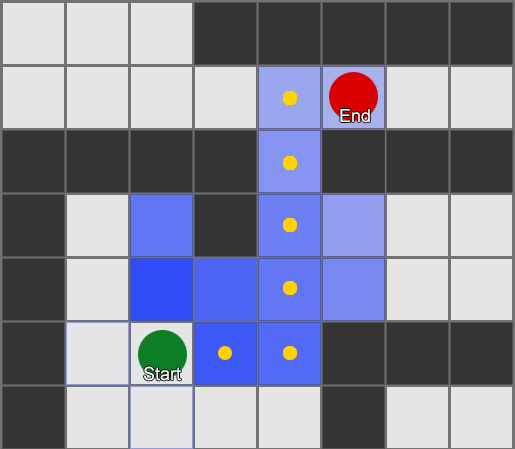
Halimbawa 1: isang buhol sa bawat parisukat. Ang paghahanap ay nagsisimula sa node kung saan matatagpuan ang ahente at nagtatapos sa node ng gustong parisukat.
Halimbawa 2: Isang mas maliit na hanay ng mga node (mga waypoint). Magsisimula ang paghahanap sa parisukat ng ahente, dumaan sa kinakailangang bilang ng mga node, at pagkatapos ay magpapatuloy sa destinasyon.
Ito ay isang ganap na nababaluktot at makapangyarihang sistema. Ngunit kailangan ng ilang pag-iingat sa pagpapasya kung saan at kung paano maglalagay ng waypoint, kung hindi, maaaring hindi makita ng mga ahente ang pinakamalapit na punto at hindi nila masisimulan ang landas. Mas magiging madali kung awtomatiko tayong maglalagay ng mga waypoint batay sa geometry ng mundo.
Dito lalabas ang navigation mesh o navmesh (navigation mesh). Ito ay karaniwang isang 2D mesh ng mga tatsulok na naka-overlay sa geometry ng mundo - saanman pinapayagang maglakad ang ahente. Ang bawat isa sa mga tatsulok sa mesh ay nagiging isang node sa graph, at may hanggang tatlong katabing tatsulok na nagiging magkatabing mga node sa graph.
Ang larawang ito ay isang halimbawa mula sa Unity engine - sinuri nito ang geometry sa mundo at lumikha ng isang navmesh (sa screenshot sa light blue). Ang bawat polygon sa isang navmesh ay isang lugar kung saan ang isang ahente ay maaaring tumayo o lumipat mula sa isang polygon patungo sa isa pang polygon. Sa halimbawang ito, ang mga polygon ay mas maliit kaysa sa mga sahig kung saan sila matatagpuan - ginagawa ito upang isaalang-alang ang laki ng ahente, na lalampas sa nominal na posisyon nito.

Maaari tayong maghanap ng ruta sa pamamagitan ng mesh na ito, muli gamit ang A* algorithm. Bibigyan tayo nito ng halos perpektong ruta sa mundo, na isinasaalang-alang ang lahat ng geometry at hindi nangangailangan ng mga hindi kinakailangang node at paglikha ng mga waypoint.
Ang Pathfinding ay masyadong malawak na paksa kung saan ang isang seksyon ng isang artikulo ay hindi sapat. Kung nais mong pag-aralan ito nang mas detalyado, makakatulong ito .
Планирование
Natutunan namin sa paghahanap ng landas na kung minsan ay hindi sapat na pumili lamang ng direksyon at lumipat - kailangan naming pumili ng ruta at gumawa ng ilang mga pagliko upang makarating sa aming gustong destinasyon. Maaari nating gawing pangkalahatan ang ideyang ito: ang pagkamit ng layunin ay hindi lamang ang susunod na hakbang, ngunit isang buong pagkakasunud-sunod kung saan minsan kailangan mong tumingin sa unahan ng ilang hakbang upang malaman kung ano ang dapat na una. Ito ay tinatawag na pagpaplano. Ang Pathfinding ay maaaring isipin bilang isa sa ilang mga extension sa pagpaplano. Sa mga tuntunin ng ating Sense/Think/Act cycle, dito nagpaplano ang bahaging Think ng maraming bahagi ng Act para sa hinaharap.
Tingnan natin ang halimbawa ng board game na Magic: The Gathering. Nauna kami sa mga sumusunod na hanay ng mga card sa aming mga kamay:
- Swamp - Nagbibigay ng 1 itim na mana (land card).
- Forest - nagbibigay ng 1 berdeng mana (land card).
- Fugitive Wizard - Nangangailangan ng 1 asul na mana para ipatawag.
- Elvish Mystic - Nangangailangan ng 1 berdeng mana para ipatawag.
Hindi namin binabalewala ang natitirang tatlong card upang gawing mas madali. Ayon sa mga panuntunan, pinapayagan ang isang manlalaro na maglaro ng 1 land card bawat pagliko, maaari niyang "i-tap" ang card na ito upang kunin ang mana mula rito, at pagkatapos ay mag-spell (kabilang ang pagpapatawag ng isang nilalang) ayon sa dami ng mana. Sa sitwasyong ito, alam ng taong manlalaro na maglaro ng Forest, mag-tap ng 1 berdeng mana, at pagkatapos ay ipatawag ang Elvish Mystic. Ngunit paano malalaman ito ng larong AI?
Madaling pagpaplano
Ang walang kuwentang diskarte ay subukan ang bawat aksyon hanggang sa wala nang natitira na angkop. Sa pamamagitan ng pagtingin sa mga card, nakikita ng AI kung ano ang maaaring laruin ng Swamp. At tinutugtog niya ito. Mayroon bang iba pang mga pagkilos na natitira sa pagliko na ito? Hindi nito maaaring ipatawag ang alinman sa Elvish Mystic o Fugitive Wizard, dahil nangangailangan sila ng berde at asul na mana ayon sa pagkakabanggit upang ipatawag sila, habang ang Swamp ay nagbibigay lamang ng itim na mana. At hindi na siya makakapaglaro ng Forest, dahil naglaro na siya ng Swamp. Kaya, sinunod ng larong AI ang mga patakaran, ngunit ginawa ito nang hindi maganda. Maaaring pagbutihin.
Ang pagpaplano ay makakahanap ng isang listahan ng mga aksyon na magdadala sa laro sa nais na estado. Kung paanong ang bawat parisukat sa isang landas ay may mga kapitbahay (sa paghahanap ng daan), ang bawat aksyon sa isang plano ay mayroon ding mga kapitbahay o kahalili. Maaari nating hanapin ang mga pagkilos na ito at ang mga kasunod na pagkilos hanggang sa maabot natin ang gustong estado.
Sa aming halimbawa, ang nais na resulta ay "magtawag ng isang nilalang kung maaari." Sa simula ng pagliko, nakikita lang namin ang dalawang posibleng pagkilos na pinapayagan ng mga panuntunan ng laro:
1. Maglaro ng Swamp (resulta: Swamp sa laro)
2. Maglaro ng Forest (resulta: Forest sa laro)
Ang bawat aksyon na gagawin ay maaaring humantong sa mga karagdagang aksyon at isara ang iba, muli depende sa mga panuntunan ng laro. Isipin na naglaro kami ng Swamp - aalisin nito ang Swamp bilang susunod na hakbang (naglaro na kami nito), at aalisin din nito ang Forest (dahil ayon sa mga patakaran maaari kang maglaro ng isang land card bawat pagliko). Pagkatapos nito, idinagdag ng AI ang pagkuha ng 1 itim na mana bilang susunod na hakbang dahil walang ibang mga opsyon. Kung magpapatuloy siya at pipiliin ang Tap the Swamp, makakatanggap siya ng 1 unit ng black mana at wala siyang magagawa dito.
1. Maglaro ng Swamp (resulta: Swamp sa laro)
1.1 “Tap” Swamp (resulta: Swamp “tapped”, +1 unit ng black mana)
Walang magagamit na mga aksyon - END
2. Maglaro ng Forest (resulta: Forest sa laro)
Ang listahan ng mga aksyon ay maikli, naabot namin ang isang patay na dulo. Ulitin namin ang proseso para sa susunod na hakbang. Naglalaro kami ng Forest, buksan ang aksyon na "makakuha ng 1 berdeng mana", na magbubukas naman ng ikatlong aksyon - ipatawag ang Elvish Mystic.
1. Maglaro ng Swamp (resulta: Swamp sa laro)
1.1 “Tap” Swamp (resulta: Swamp “tapped”, +1 unit ng black mana)
Walang magagamit na mga aksyon - END
2. Maglaro ng Forest (resulta: Forest sa laro)
2.1 "Tap" Forest (resulta: Forest ay "na-tap", +1 unit ng berdeng mana)
2.1.1 Ipatawag ang Elvish Mystic (resulta: Elvish Mystic sa laro, -1 berdeng mana)
Walang magagamit na mga aksyon - END
Sa wakas, ginalugad namin ang lahat ng posibleng aksyon at nakahanap kami ng planong nagpapatawag ng isang nilalang.
Ito ay isang napakasimpleng halimbawa. Maipapayo na piliin ang pinakamahusay na posibleng plano, sa halip na anumang plano na nakakatugon sa ilang pamantayan. Sa pangkalahatan ay posible na suriin ang mga potensyal na plano batay sa kinalabasan o pangkalahatang benepisyo ng kanilang pagpapatupad. Maaari kang makakuha ng iyong sarili ng 1 puntos para sa paglalaro ng land card at 3 puntos para sa pagpapatawag ng isang nilalang. Ang paglalaro ng Swamp ay isang 1 point plan. At ang paglalaro ng Forest → Tap the Forest → summon Elvish Mystic ay magbibigay agad ng 4 na puntos.
Ganito gumagana ang pagpaplano sa Magic: The Gathering, ngunit ang parehong logic ay nalalapat sa ibang mga sitwasyon. Halimbawa, ang paglipat ng isang pawn upang bigyan ng puwang ang obispo na lumipat sa chess. O kaya'y magtago sa likod ng isang pader upang ligtas na mag-shoot sa XCOM tulad nito. Sa pangkalahatan, nakukuha mo ang ideya.
Pinahusay na pagpaplano
Minsan napakaraming potensyal na pagkilos upang isaalang-alang ang bawat posibleng opsyon. Pagbabalik sa halimbawa gamit ang Magic: The Gathering: sabihin natin na sa laro at sa iyong kamay mayroong ilang card ng lupa at nilalang - ang bilang ng mga posibleng kumbinasyon ng mga galaw ay maaaring nasa dose-dosenang. Mayroong ilang mga solusyon sa problema.
Ang unang paraan ay backwards chaining. Sa halip na subukan ang lahat ng mga kumbinasyon, mas mahusay na magsimula sa huling resulta at subukang maghanap ng direktang ruta. Sa halip na pumunta mula sa ugat ng puno patungo sa isang tiyak na dahon, lumipat tayo sa kabaligtaran ng direksyon - mula sa dahon hanggang sa ugat. Ang pamamaraang ito ay mas madali at mas mabilis.
Kung ang kaaway ay may 1 kalusugan, maaari mong mahanap ang "deal 1 o higit pang pinsala" na plano. Upang makamit ito, dapat matugunan ang ilang mga kundisyon:
1. Ang pinsala ay maaaring sanhi ng isang spell - dapat itong nasa kamay.
2. Para mag-spell, kailangan mo ng mana.
3. Para makakuha ng mana, kailangan mong maglaro ng land card.
4. Upang maglaro ng land card, kailangan mong magkaroon nito sa iyong kamay.
Ang isa pang paraan ay ang pinakamahusay na unang paghahanap. Sa halip na subukan ang lahat ng mga landas, pipiliin natin ang pinakaangkop. Kadalasan, ang pamamaraang ito ay nagbibigay ng pinakamainam na plano nang walang mga hindi kinakailangang gastos sa paghahanap. Ang A* ay isang anyo ng pinakamahusay na unang paghahanap - sa pamamagitan ng pagsusuri sa mga pinaka-maaasahan na ruta mula sa simula, mahahanap na nito ang pinakamahusay na landas nang hindi kinakailangang suriin ang iba pang mga opsyon.
Ang isang kawili-wili at lalong popular na pinakamahusay na unang pagpipilian sa paghahanap ay ang Monte Carlo Tree Search. Sa halip na hulaan kung aling mga plano ang mas mahusay kaysa sa iba kapag pinipili ang bawat kasunod na aksyon, pinipili ng algorithm ang mga random na kahalili sa bawat hakbang hanggang sa maabot nito ang dulo (kapag ang plano ay nagresulta sa tagumpay o pagkatalo). Ang huling resulta ay gagamitin upang madagdagan o bawasan ang bigat ng mga nakaraang opsyon. Sa pamamagitan ng pag-uulit ng prosesong ito nang maraming beses nang sunud-sunod, ang algorithm ay nagbibigay ng isang mahusay na pagtatantya kung ano ang pinakamahusay na susunod na hakbang, kahit na magbago ang sitwasyon (kung ang kaaway ay kumilos upang makagambala sa player).
Walang kuwento tungkol sa pagpaplano sa mga laro ang kumpleto nang walang Goal-Oriented Action Planning o GOAP (goal-oriented action planning). Ito ay isang malawakang ginagamit at tinalakay na paraan, ngunit maliban sa ilang natatanging detalye, ito ay mahalagang paraan ng backwards chaining na napag-usapan natin kanina. Kung ang layunin ay "sirain ang manlalaro" at ang manlalaro ay nasa likod ng takip, ang plano ay maaaring: sirain gamit ang isang granada → kunin ito → itapon ito.
Kadalasan mayroong ilang mga layunin, bawat isa ay may sariling priyoridad. Kung hindi makumpleto ang pinakamataas na priyoridad na layunin (walang kumbinasyon ng mga aksyon ang lumilikha ng planong "patayin ang manlalaro" dahil hindi nakikita ang manlalaro), babalik ang AI sa mga mas mababang priority na layunin.
Pagsasanay at pagbagay
Nasabi na namin na ang larong AI ay karaniwang hindi gumagamit ng machine learning dahil hindi ito angkop para sa pamamahala ng mga ahente nang real time. Ngunit hindi ito nangangahulugan na hindi ka maaaring humiram ng isang bagay mula sa lugar na ito. Gusto namin ng kalaban sa shooter na may matutunan kami. Halimbawa, alamin ang tungkol sa pinakamahusay na mga posisyon sa mapa. O isang kalaban sa isang fighting game na haharangin ang madalas na ginagamit na combo moves ng player, na nag-uudyok sa kanya na gumamit ng iba. Kaya maaaring maging kapaki-pakinabang ang machine learning sa mga ganitong sitwasyon.
Mga Istatistika at Probability
Bago tayo pumasok sa mga kumplikadong halimbawa, tingnan natin kung hanggang saan ang magagawa natin sa pamamagitan ng pagkuha ng ilang simpleng mga sukat at paggamit sa mga ito upang gumawa ng mga desisyon. Halimbawa, real-time na diskarte - paano natin matutukoy kung ang isang manlalaro ay makakapaglunsad ng pag-atake sa unang ilang minuto ng laro at anong depensa ang ihahanda laban dito? Maaari naming pag-aralan ang mga nakaraang karanasan ng isang manlalaro upang maunawaan kung ano ang maaaring maging reaksyon sa hinaharap. Upang magsimula, wala kaming ganoong hilaw na data, ngunit maaari naming kolektahin ito - sa tuwing ang AI ay naglalaro laban sa isang tao, maaari nitong itala ang oras ng unang pag-atake. Pagkatapos ng ilang session, makakakuha tayo ng average ng oras na aabutin para sa pag-atake ng manlalaro sa hinaharap.
Mayroon ding problema sa mga average na halaga: kung ang isang manlalaro ay nagmamadali ng 20 beses at mabagal na naglaro ng 20 beses, kung gayon ang mga kinakailangang halaga ay nasa isang lugar sa gitna, at hindi ito magbibigay sa amin ng anumang kapaki-pakinabang. Ang isang solusyon ay upang limitahan ang input data - ang huling 20 piraso ay maaaring isaalang-alang.
Ang isang katulad na diskarte ay ginagamit kapag tinatantya ang posibilidad ng ilang mga aksyon sa pamamagitan ng pag-aakalang ang mga nakaraang kagustuhan ng manlalaro ay magiging pareho sa hinaharap. Kung ang isang manlalaro ay umatake sa amin ng limang beses gamit ang bolang apoy, dalawang beses na may kidlat, at isang beses na may suntukan, halatang mas gusto niya ang bolang apoy. I-extrapolate natin at tingnan ang posibilidad ng paggamit ng iba't ibang armas: fireball=62,5%, lightning=25% at suntukan=12,5%. Ang aming larong AI ay kailangang maghanda upang protektahan ang sarili mula sa apoy.
Ang isa pang kawili-wiling paraan ay ang paggamit ng Naive Bayes Classifier upang pag-aralan ang malaking halaga ng data ng pag-input at pag-uri-uriin ang sitwasyon upang ang AI ay tumugon sa nais na paraan. Kilala ang mga Bayesian classifier sa kanilang paggamit sa mga filter ng spam ng email. Doon nila sinusuri ang mga salita, ikinukumpara ang mga ito sa kung saan lumitaw ang mga salitang iyon dati (sa spam o hindi), at gumawa ng mga konklusyon tungkol sa mga papasok na email. Magagawa natin ang parehong bagay kahit na may mas kaunting input. Batay sa lahat ng kapaki-pakinabang na impormasyon na nakikita ng AI (tulad ng kung anong mga yunit ng kaaway ang nilikha, o kung anong mga spelling ang kanilang ginagamit, o kung anong mga teknolohiya ang kanilang sinaliksik), at ang huling resulta (digmaan o kapayapaan, pagmamadali o pagtatanggol, atbp.) - pipiliin namin ang nais na pag-uugali ng AI.
Ang lahat ng mga pamamaraan ng pagsasanay na ito ay sapat, ngunit ipinapayong gamitin ang mga ito batay sa data ng pagsubok. Matututo ang AI na umangkop sa iba't ibang diskarte na ginamit ng iyong mga manlalaro. Ang AI na umaangkop sa player pagkatapos ilabas ay maaaring maging masyadong predictable o masyadong mahirap talunin.
Pagbagay batay sa halaga
Dahil sa nilalaman ng aming mundo ng laro at mga panuntunan, maaari naming baguhin ang hanay ng mga halaga na nakakaimpluwensya sa paggawa ng desisyon, sa halip na gamitin lamang ang data ng input. Ginagawa namin ito:
- Hayaang mangolekta ang AI ng data sa estado ng mundo at mga pangunahing kaganapan sa panahon ng laro (tulad ng nasa itaas).
- Baguhin natin ang ilang mahahalagang halaga batay sa data na ito.
- Ipinapatupad namin ang aming mga desisyon batay sa pagproseso o pagsusuri sa mga halagang ito.
Halimbawa, ang isang ahente ay may ilang kuwartong mapagpipilian sa isang first-person shooter map. Ang bawat silid ay may sariling halaga, na tumutukoy kung gaano kanais-nais na bisitahin. Random na pinipili ng AI kung aling silid ang pupuntahan batay sa halaga. Naaalala ng ahente kung saang silid siya pinatay at binabawasan ang halaga nito (ang posibilidad na bumalik siya doon). Katulad din para sa baligtad na sitwasyon - kung ang ahente ay sumisira sa maraming mga kalaban, kung gayon ang halaga ng silid ay tumataas.
modelo ni Markov
Paano kung ginamit namin ang nakolektang data upang gumawa ng mga hula? Kung naaalala namin ang bawat silid na nakikita namin ang isang manlalaro sa isang tiyak na tagal ng panahon, huhulaan namin kung aling silid ang maaaring mapuntahan ng manlalaro. Sa pamamagitan ng pagsubaybay at pagre-record ng mga galaw ng player sa mga kwarto (mga halaga), mahuhulaan namin ang mga ito.
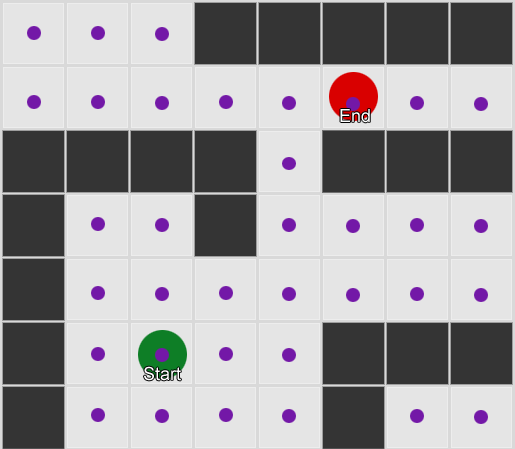
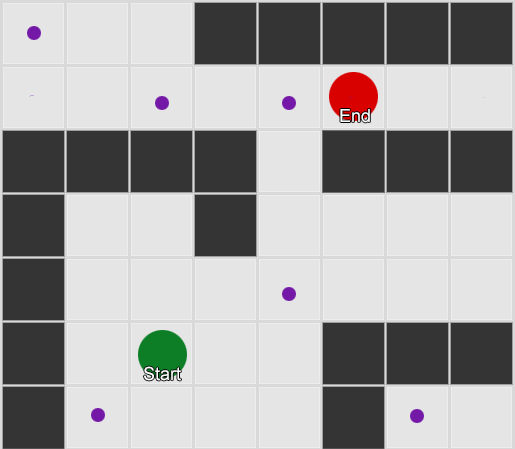
Kumuha tayo ng tatlong silid: pula, berde at asul. At pati na rin ang mga obserbasyon na aming naitala habang nanonood ng session ng laro:
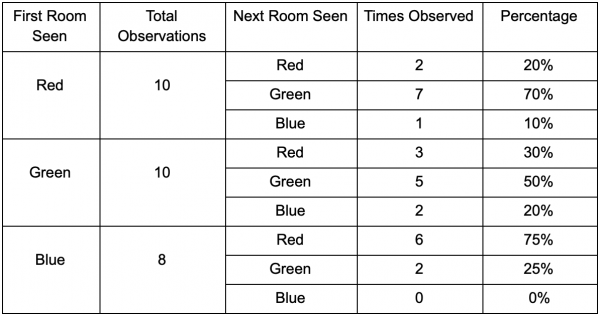
Ang bilang ng mga obserbasyon sa bawat silid ay halos pantay - hindi pa rin namin alam kung saan gagawa ng magandang lugar para sa isang ambush. Ang pagkolekta ng mga istatistika ay kumplikado din sa pamamagitan ng respawning ng mga manlalaro, na lumilitaw nang pantay-pantay sa buong mapa. Ngunit ang data tungkol sa susunod na silid na kanilang papasukin pagkatapos lumitaw sa mapa ay kapaki-pakinabang na.
Makikita na ang berdeng silid ay nababagay sa mga manlalaro - karamihan sa mga tao ay lumipat mula sa pulang silid patungo dito, 50% sa kanila ay nananatili pa doon. Ang asul na silid, sa kabaligtaran, ay hindi sikat; halos walang pumupunta dito, at kung gagawin nila, hindi sila mananatili nang matagal.
Ngunit ang data ay nagsasabi sa amin ng isang bagay na mas mahalaga - kapag ang isang manlalaro ay nasa isang asul na silid, ang susunod na silid na makikita namin sa kanya ay magiging pula, hindi berde. Kahit na ang berdeng silid ay mas sikat kaysa sa pulang silid, ang sitwasyon ay nagbabago kung ang manlalaro ay nasa asul na silid. Ang susunod na estado (ibig sabihin, ang silid na pupuntahan ng manlalaro) ay nakasalalay sa nakaraang estado (ibig sabihin, ang silid na kasalukuyang kinaroroonan ng manlalaro). Dahil nag-e-explore kami ng mga dependency, gagawa kami ng mas tumpak na mga hula kaysa kung magbibilang lang kami ng mga obserbasyon nang hiwalay.
Ang paghula sa isang hinaharap na estado batay sa data mula sa isang nakaraang estado ay tinatawag na modelo ng Markov, at ang mga naturang halimbawa (na may mga silid) ay tinatawag na mga Markov chain. Dahil ang mga pattern ay kumakatawan sa posibilidad ng mga pagbabago sa pagitan ng magkakasunod na mga estado, ang mga ito ay biswal na ipinapakita bilang mga FSM na may posibilidad sa bawat paglipat. Noong nakaraan, ginamit namin ang FSM upang kumatawan sa estado ng pag-uugali kung saan naroroon ang isang ahente, ngunit ang konseptong ito ay umaabot sa anumang estado, nauugnay man ito sa ahente o hindi. Sa kasong ito, kinakatawan ng mga estado ang silid na inookupahan ng ahente:
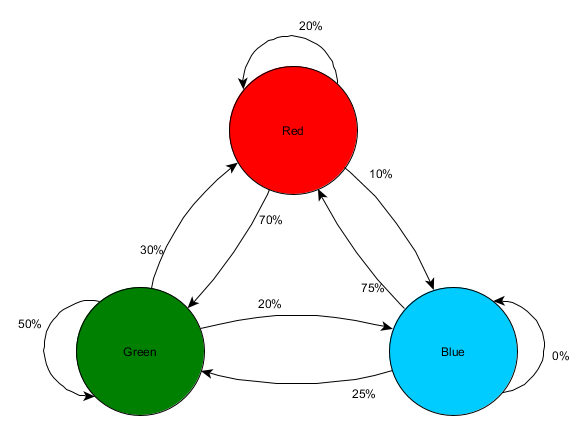
Ito ay isang simpleng paraan ng kumakatawan sa kamag-anak na posibilidad ng mga pagbabago sa estado, na nagbibigay sa AI ng ilang kakayahang mahulaan ang susunod na estado. Maaari mong asahan ang ilang mga hakbang sa unahan.
Kung ang isang manlalaro ay nasa berdeng silid, mayroong 50% na pagkakataon na mananatili siya roon sa susunod na pagmasdan siya. Ngunit ano ang mga pagkakataon na naroroon pa rin siya kahit na pagkatapos? Hindi lamang may pagkakataon na ang manlalaro ay nanatili sa berdeng silid pagkatapos ng dalawang obserbasyon, ngunit mayroon ding pagkakataon na siya ay umalis at bumalik. Narito ang bagong talahanayan na isinasaalang-alang ang bagong data:
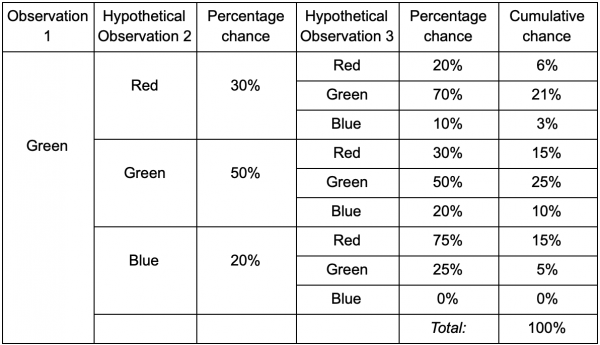
Ipinapakita nito na ang pagkakataong makita ang manlalaro sa berdeng silid pagkatapos ng dalawang obserbasyon ay magiging katumbas ng 51% - 21% na siya ay mula sa pulang silid, 5% sa kanila na bibisita ang manlalaro sa asul na silid sa pagitan nila, at 25% na ang manlalaro ay hindi aalis sa berdeng silid.
Ang talahanayan ay isang visual na tool lamang - ang pamamaraan ay nangangailangan lamang ng pagpaparami ng mga probabilidad sa bawat hakbang. Nangangahulugan ito na maaari kang tumingin sa hinaharap gamit ang isang caveat: ipinapalagay namin na ang pagkakataong makapasok sa isang silid ay ganap na nakasalalay sa kasalukuyang silid. Ito ay tinatawag na Markov Property - ang hinaharap na estado ay nakasalalay lamang sa kasalukuyan. Ngunit hindi ito XNUMX% tumpak. Ang mga manlalaro ay maaaring magbago ng mga desisyon depende sa iba pang mga kadahilanan: antas ng kalusugan o dami ng mga bala. Dahil hindi namin itinatala ang mga halagang ito, ang aming mga hula ay magiging hindi gaanong tumpak.
N-Grams
Paano naman ang halimbawa ng fighting game at paghula sa combo moves ng player? Pareho! Ngunit sa halip na isang estado o kaganapan, susuriin namin ang buong sequence na bumubuo sa isang combo strike.
Ang isang paraan upang gawin ito ay ang pag-imbak ng bawat input (tulad ng Kick, Punch o Block) sa isang buffer at isulat ang buong buffer bilang isang kaganapan. Kaya paulit-ulit na pinindot ng player ang Kick, Kick, Punch para gamitin ang SuperDeathFist attack, iniimbak ng AI system ang lahat ng inputs sa isang buffer at naaalala ang huling tatlong ginamit sa bawat hakbang.
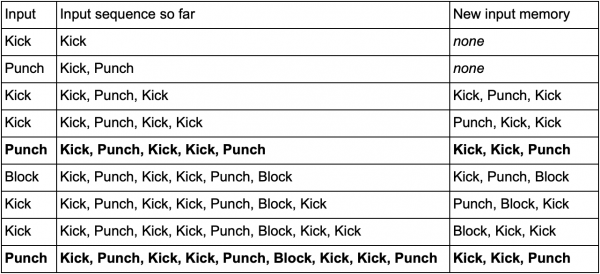
(Ang mga linyang naka-bold ay kapag inilunsad ng manlalaro ang pag-atake ng SuperDeathFist.)
Makikita ng AI ang lahat ng opsyon kapag pinili ng player ang Kick, na sinusundan ng isa pang Kick, at pagkatapos ay mapansin na ang susunod na input ay palaging Punch. Papayagan nito ang ahente na mahulaan ang combo move ng SuperDeathFist at harangan ito kung maaari.
Ang mga sequence ng mga kaganapan ay tinatawag na N-grams, kung saan ang N ay ang bilang ng mga elemento na nakaimbak. Sa nakaraang halimbawa ito ay isang 3-gramo (trigram), na nangangahulugang: ang unang dalawang entry ay ginagamit upang mahulaan ang pangatlo. Alinsunod dito, sa isang 5-gramo, hinuhulaan ng unang apat na entry ang ikalima at iba pa.
Kailangang maingat na piliin ng taga-disenyo ang laki ng N-gramo. Ang isang mas maliit na N ay nangangailangan ng mas kaunting memorya ngunit nag-iimbak din ng mas kaunting kasaysayan. Halimbawa, ang isang 2-gramo (bigram) ay magre-record ng Kick, Kick o Kick, Punch, ngunit hindi makakapag-imbak ng Kick, Kick, Punch, kaya hindi tutugon ang AI sa SuperDeathFist combo.
Sa kabilang banda, ang mas malalaking numero ay nangangailangan ng mas maraming memorya at ang AI ay magiging mas mahirap sanayin dahil magkakaroon ng mas maraming posibleng pagpipilian. Kung mayroon kang tatlong posibleng input ng Kick, Punch o Block, at gumamit kami ng 10-gramo, iyon ay mga 60 libong iba't ibang mga opsyon.
Ang modelo ng bigram ay isang simpleng Markov chain - bawat nakaraang estado/kasalukuyang pares ng estado ay isang bigram, at maaari mong hulaan ang pangalawang estado batay sa una. Ang 3-gramo at mas malalaking N-grams ay maaari ding ituring bilang mga Markov chain, kung saan ang lahat ng elemento (maliban sa huli sa N-gram) ay magkakasamang bumubuo sa unang estado at ang huling elemento ang pangalawa. Ang halimbawa ng fighting game ay nagpapakita ng pagkakataong lumipat mula sa Kick and Kick state patungo sa Kick and Punch state. Sa pamamagitan ng pagtrato sa maramihang mga entry sa kasaysayan ng pag-input bilang isang yunit, mahalagang binabago namin ang pagkakasunud-sunod ng pag-input sa bahagi ng buong estado. Nagbibigay ito sa amin ng Markov property, na nagbibigay-daan sa amin na gumamit ng mga Markov chain upang mahulaan ang susunod na input at hulaan kung anong combo move ang susunod.
Konklusyon
Napag-usapan namin ang tungkol sa mga pinakakaraniwang tool at diskarte sa pagbuo ng artificial intelligence. Tiningnan din namin ang mga sitwasyon kung saan kailangang gamitin ang mga ito at kung saan ang mga ito ay lalong kapaki-pakinabang.
Ito ay dapat na sapat upang maunawaan ang mga pangunahing kaalaman ng laro AI. Ngunit, siyempre, ang mga ito ay hindi lahat ng mga pamamaraan. Hindi gaanong sikat, ngunit hindi gaanong epektibo ang:
- mga algorithm sa pag-optimize kabilang ang pag-akyat sa burol, gradient descent at genetic algorithm
- adversarial search/scheduling algorithm (minimax at alpha-beta pruning)
- mga paraan ng pag-uuri (perceptron, neural network at support vector machine)
- mga sistema para sa pagpoproseso ng pang-unawa at memorya ng mga ahente
- mga diskarte sa arkitektura sa AI (hybrid system, subset architecture at iba pang paraan ng pag-overlay ng mga AI system)
- mga tool sa animation (pagpaplano at koordinasyon ng paggalaw)
- mga kadahilanan sa pagganap (antas ng detalye, anumang oras, at mga algorithm ng timeslicing)
Mga online na mapagkukunan sa paksa:
1. Ang GameDev.net ay may At .
2. naglalaman ng maraming presentasyon at artikulo sa malawak na hanay ng mga paksang nauugnay sa pagbuo ng AI ng laro.
3. kasama ang mga paksa mula sa GDC AI Summit, marami sa mga ito ay magagamit nang libre.
4. Ang mga kapaki-pakinabang na materyales ay matatagpuan din sa website .
5. Si Tommy Thompson, AI researcher at developer ng laro, ay gumagawa ng mga video sa YouTube na may paliwanag at pag-aaral ng AI sa mga komersyal na laro.
Mga aklat sa paksa:
1. Ang serye ng aklat ng Game AI Pro ay isang koleksyon ng mga maikling artikulo na nagpapaliwanag kung paano ipatupad ang mga partikular na feature o kung paano lutasin ang mga partikular na problema.
2. Ang serye ng AI Game Programming Wisdom ay ang hinalinhan ng serye ng Game AI Pro. Naglalaman ito ng mas lumang mga pamamaraan, ngunit halos lahat ay may kaugnayan kahit ngayon.
3. ay isa sa mga pangunahing teksto para sa lahat na gustong maunawaan ang pangkalahatang larangan ng artificial intelligence. Hindi ito isang libro tungkol sa pagbuo ng laro - itinuturo nito ang mga pangunahing kaalaman sa AI.
Pinagmulan: www.habr.com
