

Herkese selam! Java + Spring'de mikro hizmetler yazan bir arka uç geliştiricisiyim. Tinkoff'un dahili ürün geliştirme ekiplerinden birinde çalışıyorum.

Ekibimizde sıklıkla bir DBMS'deki sorguları optimize etme sorunu ortaya çıkar. Her zaman biraz daha hızlı olmak istersiniz, ancak her zaman düşünceli bir şekilde oluşturulmuş dizinlerle idare edemezsiniz; bazı geçici çözümler aramanız gerekir. Veritabanlarıyla çalışırken makul optimizasyonlar bulmak için web'de dolaştığım bu gezilerden birinde şunu buldum: , SQL Performans Açıklaması kitabının yazarı. Bu, tüm makaleleri arka arkaya okuyabileceğiniz nadir bir blog türüdür.
Marcus'un kısa bir makalesini sizin için tercüme etmek istiyorum. Bir dereceye kadar, SQL standardına göre ofset işleminin gerçekleştirilmesiyle ilgili eski ama yine de geçerli soruna dikkat çekmeyi amaçlayan bir manifesto olarak adlandırılabilir.
Bazı yerlerde yazara açıklamalar ve yorumlarla destek olacağım. Bu tür yerlerin tümüne "yaklaşık" adını vereceğim. daha fazla netlik için
Küçük giriş
Sanırım birçok kişi ofset yoluyla sayfa seçimiyle çalışmanın ne kadar sorunlu ve yavaş olduğunu biliyor. Daha verimli bir tasarımla kolayca değiştirilebileceğini biliyor muydunuz?
Böylece offset anahtar sözcüğü veritabanına istekteki ilk n kaydı atlamasını söyler. Bununla birlikte, veritabanının yine de bu ilk n kaydı diskten verilen sırayla okuması gerekir (not: belirtilmişse sıralamayı uygulayın) ve ancak o zaman n+1'den itibaren kayıtları döndürmek mümkün olacaktır. En ilginç olanı, sorunun DBMS'deki spesifik uygulamada değil, standarda göre orijinal tanımda olmasıdır:
…satırlar ilk olarak şuna göre sıralanır: ve daha sonra belirtilen satır sayısını azaltarak sınırlandırın. başlangıçtan beri...
-SQL:2016, Bölüm 2, 4.15.3 Türetilmiş tablolar (not: şu anda en çok kullanılan standart)
Buradaki kilit nokta, ofsetin tek bir parametre almasıdır - atlanacak kayıt sayısı ve hepsi bu. Bu tanıma göre, DBMS yalnızca tüm kayıtları alabilir ve gereksiz olanları atabilir. Açıkçası ofsetin bu tanımı bizi ekstra iş yapmaya zorluyor. Ve SQL ya da NoSQL olması bile önemli değil.
Biraz daha acı
Ofsetle ilgili sorunlar burada bitmiyor ve işte nedeni. Diskten iki sayfalık verinin okunması arasında başka bir işlemle yeni bir kayıt eklenirse bu durumda ne olur?
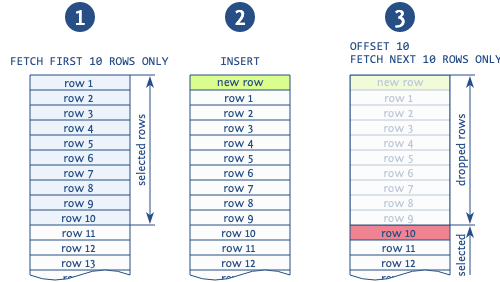
Önceki sayfalardaki kayıtları atlamak için ofset kullanıldığında, farklı sayfaların okumaları arasına yeni bir kayıt eklenmesi durumunda, büyük olasılıkla kopyalar elde edersiniz (not: bu, yapıya göre sıralamayı kullanarak sayfa sayfa okuduğumuzda mümkündür, ardından çıktımızın ortasında yeni bir giriş alabilir).
Şekil bu durumu açıkça göstermektedir. Baz ilk 10 kaydı okur, ardından yeni bir kayıt eklenir, bu da tüm okunan kayıtları 1 ile kaydırır. Daha sonra baz sonraki 10 kayıttan yeni bir sayfa alır ve olması gerektiği gibi 11. kayıttan değil, baştan başlar. 10'uncusu, bu kaydın kopyalanması. Bu ifadenin kullanımıyla ilişkili başka anormallikler de vardır, ancak bu en yaygın olanıdır.
Daha önce de öğrendiğimiz gibi bunlar belirli bir DBMS'nin veya uygulamalarının sorunları değildir. Sorun, sayfalandırmanın SQL standardına göre tanımlanmasındadır. DBMS'ye hangi sayfayı getireceğini veya kaç kayıt atlayacağını söyleriz. Bunun için çok az bilgi olduğundan veritabanı böyle bir isteği optimize edemiyor.
Ayrıca bunun belirli bir anahtar kelimeyle ilgili bir sorun olmadığını, sorgunun anlambilimiyle ilgili bir sorun olduğunu da açıklığa kavuşturmakta fayda var. Sorunlu doğaları bakımından aynı olan birkaç sözdizimi daha vardır:
- Ofset anahtar sözcüğü daha önce belirtildiği gibidir.
- İki anahtar kelimenin yapısı limit [offset] (limitin kendisi o kadar da kötü olmasa da).
- Satır numaralandırmasına (örneğin, satır_numarası(), satırsayısı vb.) dayalı olarak alt sınırlara göre filtreleme.
Bu ifadelerin tümü size yalnızca kaç satır atlayacağınızı söyler, ek bilgi veya bağlam yoktur.
Bu makalenin ilerleyen kısımlarında ofset anahtar sözcüğü tüm bu seçeneklerin özeti olarak kullanılacaktır.
OFFSET'siz Hayat
Şimdi tüm bu sorunlar olmasaydı dünyamızın nasıl olacağını hayal edelim. Dengesiz hayatın o kadar da zor olmadığı ortaya çıktı: bir seçimle, yalnızca henüz görmediğimiz satırları (not: yani önceki sayfada olmayanları) bir koşul kullanarak seçebilirsiniz.
Bu durumda, seçimlerin sıralı bir kümede (eski güzel sıralamaya göre) yürütülmesi gerçeğinden yola çıkıyoruz. Sıralı bir kümemiz olduğundan, yalnızca önceki sayfanın son kaydının arkasında bulunan verileri elde etmek için oldukça basit bir filtre kullanabiliriz:
SELECT ...
FROM ...
WHERE ...
AND id < ?last_seen_id
ORDER BY id DESC
FETCH FIRST 10 ROWS ONLYBu yaklaşımın tüm prensibi budur. Elbette birden fazla sütuna göre sıralama yapıldığında işler daha eğlenceli hale geliyor ama fikir hala aynı. Bu tasarımın birçok kişiye uygulanabileceğini unutmamak önemlidir. -kararlar.
Bu yaklaşıma arama yöntemi veya anahtar kümesi sayfalandırması denir. Kayan sonuç problemini çözer (not: daha önce açıklanan sayfa okumaları arasında yazma durumu) ve elbette hepimizin sevdiği şey, klasik ofsetten daha hızlı ve daha kararlı çalışır. Kararlılık, istek işleme süresinin istenen tablonun sayısıyla orantılı olarak artmaması gerçeğinde yatmaktadır (not: sayfalandırmaya yönelik farklı yaklaşımların çalışmaları hakkında daha fazla bilgi edinmek istiyorsanız, . Ayrıca farklı yöntemler için karşılaştırmalı kıyaslamaları da burada bulabilirsiniz).
Slaytlardan biri Anahtarlara göre sayfalandırma elbette her şeye kadir değildir; kendi sınırlamaları vardır. En önemlisi rastgele sayfaları okuma yeteneğinin olmamasıdır (not: tutarsız bir şekilde). Ancak sonsuz kaydırma çağında (not: ön uçta), bu o kadar da sorun değil. Tıklama için sayfa numarası belirtmek zaten kullanıcı arayüzü tasarımında kötü bir karardır (not: makalenin yazarının görüşü).
Araçlar ne olacak?
Bu yöntem için araçsal desteğin bulunmaması nedeniyle anahtarlarda sayfalandırma genellikle uygun değildir. Çeşitli çerçeveler de dahil olmak üzere çoğu geliştirme aracı, sayfalandırmanın tam olarak nasıl gerçekleştirileceğini seçmenize izin vermez.
Durum, açıklanan yöntemin, DBMS'den tarayıcıda sonsuz kaydırma ile bir AJAX isteğinin yürütülmesine kadar kullanılan teknolojilerde uçtan uca destek gerektirmesi gerçeğiyle daha da kötüleşiyor. Yalnızca sayfa numarasını belirtmek yerine artık tüm sayfalar için aynı anda bir dizi anahtar belirtmeniz gerekiyor.
Ancak anahtarlarda sayfalandırmayı destekleyen çerçevelerin sayısı giderek artıyor. İşte şu anda sahip olduğumuz şey:
- Java için;
- Ruby için;
- и Django için;
- Python için;
- — JPA uygulamaları için kriter API'si;
- Perl için;
- , Node.js için eşleyici .
(Not: Çeviri sırasında bazı kütüphanelerin 2017-2018'den bu yana güncellenmemesi nedeniyle bazı bağlantılar kaldırıldı. İlgilenirseniz orijinal kaynağa bakabilirsiniz.)
Şu anda yardımınıza ihtiyaç var. Sayfalandırmayı herhangi bir şekilde kullanan bir çerçeve geliştirir veya desteklerseniz, sizden anahtarlarda sayfalandırma için yerel destek sağlamanızı rica ediyorum, rica ediyorum, rica ediyorum. Herhangi bir sorunuz varsa veya yardıma ihtiyacınız varsa, yardımcı olmaktan memnuniyet duyarım (, , ) (not: Marcus'la olan deneyimime dayanarak kendisinin bu konuyu yayma konusunda gerçekten istekli olduğunu söyleyebilirim).
Anahtarlara göre sayfalama desteğine layık olduğunu düşündüğünüz hazır çözümler kullanıyorsanız, bir istek oluşturun, hatta mümkünse hazır bir çözüm sunun. Ayrıca bu makaleye bağlantı verebilirsiniz.
Sonuç
Anahtarlarla sayfalama gibi basit ve kullanışlı bir yaklaşımın yaygınlaşmamasının nedeni, teknik olarak uygulanmasının zor olması ya da büyük çaba gerektirmesi değildir. Bunun ana nedeni, çoğu kişinin ofsetle görmeye ve çalışmaya alışkın olmasıdır - bu yaklaşım standardın kendisi tarafından belirlenir.
Sonuç olarak, çok az kişi sayfalandırma yaklaşımını değiştirmeyi düşünüyor ve bu nedenle çerçevelerden ve kütüphanelerden gelen araçsal destek zayıf bir şekilde gelişiyor. Bu nedenle, ofsetsiz sayfalama fikri ve hedefi size yakınsa, yayılmasına yardımcı olun!
Kaynak:
Yazarı: Markus Winand
Kaynak: habr.com
