

Всім привіт. У цій статті я розповім, чому ми в Авіто дев'ять місяців тому вибрали Kafka, і що вона являє собою. Поділюсь одним із кейсів використання - брокер повідомлень. І насамкінець поговоримо про те, які плюси ми отримали від застосування підходу Kafka as a Service.
проблема

Спочатку трохи контексту. Якийсь час тому ми почали уникати монолітної архітектури, і зараз в Авіто вже кілька сотень різних сервісів. Вони мають свої сховища, свій стек технологій та відповідають за свою частину бізнес-логіки.
Одна з проблем із великою кількістю сервісів – комунікації. Сервіс А часто хоче дізнатися інформацію, яку має сервіс Б. У цьому випадку сервіс А звертається до сервісу Б через синхронний API. Сервіс В хоче знати, що відбувається у сервісів Г і Д, а ті, у свою чергу, цікавляться сервісами А і Б. Коли таких цікавих сервісів стає багато, зв'язки між ними перетворюються на заплутаний клубок.
При цьому будь-якої миті сервіс А може стати недоступним. І що робити в цьому випадку сервісу Б і решті всіх зав'язаних на нього сервісів? А якщо для виконання бізнес-операції необхідно здійснити ланцюжок послідовних синхронних викликів, ймовірність відмови всієї операції стає ще вищою (і вона тим вища, чим довша ця ланцюжок).
вибір технології

Окей, проблеми зрозумілі. Усунути їх можна, зробивши централізовану систему обміну повідомленнями між сервісами. Тепер кожному із сервісів достатньо знати лише про цю систему обміну повідомленнями. На додачу сама система повинна бути стійкою до відмов і горизонтально масштабованою, а також у разі аварій накопичувати в собі буфер звернення для подальшої їх обробки.
Давайте тепер оберемо технологію, на якій буде реалізовано доставку повідомлень. Для цього спершу зрозуміємо, чого ми від неї очікуємо:
- повідомлення між сервісами не повинні губитися;
- повідомлення можуть дублюватися;
- повідомлення можна зберігати та читати на глибину в кілька днів (персистентний буфер);
- послуги можуть передплатити дані, що їх цікавлять;
- кілька сервісів можуть читати одні й самі дані;
- повідомлення можуть містити деталізований, об'ємний payload (event-carried state transfer);
- іноді потрібна гарантія порядку повідомлень.
Також нам важливо було вибрати максимально масштабовану і надійну систему з високою пропускною здатністю (не менше 100k повідомлень по кілька кілобайт на секунду).
На цьому етапі ми розпрощалися з RabbitMQ (складно зберігати стабільним на високих rps), PGQ від SkyTools (недостатньо швидкий та погано масштабований) та NSQ (не персистентний). Всі ці технології у нас у компанії використовуються, але під вирішуване завдання вони не підійшли.
Далі ми почали дивитися на нові для нас технології – Apache Kafka, Apache Pulsar та NATS Streaming.
Першим відкинули Pulsar. Ми вирішили, що Kafka і Pulsar досить схожі між собою рішення. І незважаючи на те, що Pulsar перевірений великими компаніями, нові і пропонує більш низьку latency (теоретично), ми вирішили з цих двох залишити Kafka, як de facto стандарт для таких завдань. Ймовірно, ми повернемося до Apache Pulsar у майбутньому.
І ось залишилися два кандидати: NATS Streaming та Apache Kafka. Ми досить докладно вивчили обидва рішення, і вони підійшли під завдання. Але в результаті ми побоялися відносної молодості NATS Streaming (і того, що один з основних розробників, Tyler Treat, вирішив піти з проекту і розпочати свій власний Liftbridge). При цьому Clustering режим NATS Streaming не давав можливості сильного горизонтального масштабування (ймовірно, це вже не проблема після додавання режиму partitioning в 2017 році).
Тим не менш, NATS Streaming - крута технологія, написана на Go і має підтримку Cloud Native Computing Foundation. На відміну від Apache Kafka, їй не потрібний Zookeeper для роботи (можливо, ), оскільки всередині вона реалізує RAFT. При цьому NATS Streaming простіше в адмініструванні. Ми не виключаємо, що надалі ще повернемося до цієї технології.
І все-таки на сьогоднішній день нашим переможцем стала Apache Kafka. На наших тестах вона показала себе досить швидкою (більше мільйона повідомлень за секунду на читання та на запис при об'ємі повідомлень 1 кілобайт), досить надійною, добре масштабованою та перевіреною досвідом у продажі великими компаніями. Крім цього, Kafka підтримує щонайменше кілька великих комерційних компаній (ми, наприклад, користуємося Confluent версією), а також Kafka має розвинену екосистему.
Огляд Kafka
Перш ніж почати, відразу порекомендую чудову книгу. "Kafka: The Definitive Guide" (Є й у російському перекладі, але терміни трохи ламають мозок). У ній можна знайти інформацію, необхідну для базового розуміння Kafka і навіть трохи більше. Сама документація від Apache та блог від Confluent також добре написані та легко читаються.
Отже, погляньмо на те, як влаштована Kafka з висоти пташиного польоту. Базова топологія Kafka складається з producer, consumer, broker та zookeeper.
брокер
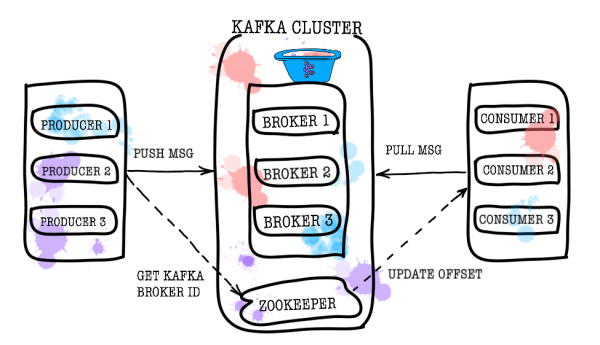
За зберігання даних відповідає брокер (broker). Всі дані зберігаються в бінарному вигляді, і брокер мало знає про те, що вони являють собою, і яка їх структура.
Кожен логічний тип подій зазвичай перебуває у окремому топіці (topic). Наприклад, подія створення оголошення може потрапляти в топік item.created, а подія його зміни — item.changed. Топики можна як класифікатори подій. На рівні топіка можна задати такі конфігураційні параметри, як:
- обсяг збережених даних та/або їх вік (retention.bytes, retention.ms);
- фактор надмірності даних (replication factor);
- максимальний розмір одного повідомлення (max.message.bytes);
- мінімальна кількість узгоджених реплік, при якому в топ можна буде записати дані (min.insync.replicas);
- можливість провести failover на не синхронну репліку, що відстає, з потенційною втратою даних (unclean.leader.election.enable);
- і ще багато інших ().
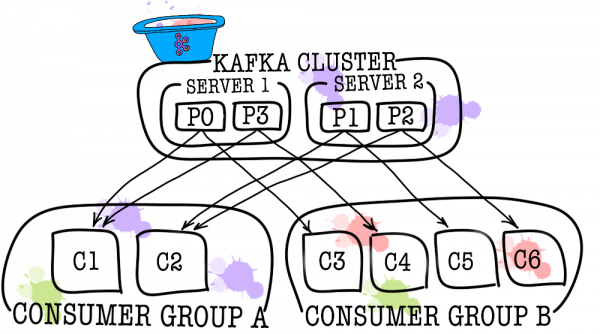
У свою чергу, кожен топік розбивається на одну і більше партицію (partition). Саме у партиції у результаті потрапляють події. Якщо в кластері більше одного брокера, то партиції будуть розподілені по всіх брокерах рівномірно (наскільки це можливо), що дозволить масштабувати навантаження на запис та читання в один топік відразу на кілька брокерів.
На диску дані кожної партиції зберігаються як файлів сегментів, за умовчанням рівних одному гігабайту (контролюється через log.segment.bytes). Важлива особливість — видалення даних із партицій (при спрацьовуванні retention) відбувається саме сегментами (не можна видалити одну подію з партиції, можна видалити лише цілий сегмент, причому неактивний).
Боєць
Zookeeper виконує роль сховища метаданих та координатора. Саме він здатний сказати, чи живі брокери (дивитись на це очима zookeeper можна через zookeeper-shell командою ls /brokers/ids), який з брокерів є контролером (get /controller), чи перебувають партиції в синхронному стані зі своїми репліками (get /brokers/topics/topic_name/partitions/partition_number/state). Також саме до zookeeper спочатку підуть producer і consumer, щоб дізнатися, на якому брокері які топіки та партиції зберігаються. У випадках, коли для топіка задано repplication factor більше 1, zookeeper вкаже, які партиції є лідерами (у них буде робитися запис і з них буде читати). У разі падіння брокера саме в zookeeper буде записана інформація про нових лідер-партій (з версії 1.1.0 асинхронно, ).
У старіших версіях Kafka zookeeper відповідав і за зберігання офсетів, але зараз вони зберігаються у спеціальному топіці __consumer_offsets на брокері (хоча ви можете ще використовувати zookeeper для цих цілей).
Найпростішим способом перетворити ваші дані на гарбуз є саме втрата інформації з zookeeper. У такому сценарії зрозуміти, що й звідки треба читати, буде дуже складно.
Виробник
Producer - це найчастіше сервіс, що здійснює безпосередній запис даних в Apache Kafka. Producer вибирає topic, у якому зберігатимуться його тематичні повідомлення, і починає записувати у нього інформацію. Наприклад, producer'ом може бути обслуговування оголошень. У такому разі він відправлятиме в тематичні топіки такі події, як «оголошення створене», «оголошення оновлено», «оголошення видалено» тощо. Кожна подія при цьому є парою ключ-значення.
За замовчуванням всі події розподіляються за партиціями топіка round-robin`ом, якщо ключ не заданий (втрачаючи впорядкованість), і через MurmurHash (ключ), якщо ключ присутній (упорядкованість у рамках однієї партиції).
Тут одразу варто зазначити, що Kafka гарантує порядок подій лише у рамках однієї партиції. Але насправді це часто не є проблемою. Наприклад, можна гарантовано додавати всі зміни одного і того ж оголошення до однієї партиції (тим самим зберігаючи порядок цих змін у межах оголошення). Також можна передавати порядковий номер у одному з полів події.
Споживач
Consumer відповідає за отримання даних із Apache Kafka. Якщо повернутись наприклад вище, consumer'ом може бути сервіс модерації. Цей сервіс буде підписаний на топік сервісу оголошень, і при появі нового оголошення отримуватиме його та аналізуватиме на відповідність деяким заданим політикам.
Apache Kafka запам'ятовує, які останні події отримав consumer (для цього використовується службовий топік __consumer__offsets), тим самим гарантуючи, що при успішному читанні consumer не отримає те саме повідомлення двічі. Тим не менш, якщо використовувати опцію enable.auto.commit = true і повністю віддати роботу з відстеження положення consumer'а в топіці на відкуп Кафці, можна . У продакшен коді найчастіше положення консьюмера контролюється вручну (розробник керує моментом, коли обов'язково має статися commit прочитаної події).
У тих випадках, коли одного consumer недостатньо (наприклад, потік нових подій дуже великий), можна додати ще кілька consumer, зв'язавши їх разом у consumer group. Consumer group логічно являє собою такий самий consumer, але з розподілом даних між учасниками групи. Це дозволяє кожному з учасників взяти частку повідомлень, тим самим масштабуючи швидкість читання.
Результати тестування

Тут не писатиму багато пояснювального тексту, просто поділюся отриманими результатами. Тестування проводилося на 3 фізичних машинах (12 CPU, 384GB RAM, 15k SAS DISK, 10GBit/s Net), брокери та zookeeper були розгорнуті в lxc.
Тестування роботи
У ході тестування було отримано такі результати.
- Швидкість запису повідомлень розміром 1KB одночасно 9 producer'ами - 1300000 подій на секунду.
- Швидкість читання повідомлень розміром 1KB одночасно 9 consumer'ами - 1500000 подій на секунду.
Тестування відмовостійкості
В ході тестування були отримані наступні результати (3 брокери, 3 zookeeper).
- Нештатне завершення одного з брокерів не призводить до припинення або недоступності кластера. Робота триває в штатному режимі, але на брокери, що залишилися, припадає велике навантаження.
- Нештатне завершення двох брокерів у разі кластера з трьох брокерів та min.isr = 2 призводить до недоступності кластера на запис, але доступності на читання. Якщо min.isr = 1, кластер продовжує бути доступний і на читання, і на запис. Тим не менш, цей режим суперечить вимогам до високої безпеки даних.
- Нештатне завершення одного із серверів Zookeeper не призводить до зупинення або недоступності кластера. Робота продовжується у штатному режимі.
- Нештатне завершення двох серверів Zookeeper призводить до недоступності кластера до моменту відновлення роботи хоча б одного із серверів Zookeeper. Це твердження правильне для кластера Zookeeper з трьох серверів. В результаті після досліджень було вирішено збільшити кластер Zookeeper до 3 серверів для збільшення стійкості до відмов.
Kafka as a service

Ми переконалися, що Kafka - чудова технологія, яка дозволяє вирішити поставлене перед нами завдання (реалізацію брокера повідомлень). Проте, ми вирішили заборонити сервісам безпосередньо звертатися до Kafka та закрили її зверху сервісом data-bus. Для чого ми це зробили? Насправді є кілька причин.
Data-bus забрав на себе всі завдання, пов'язані з інтеграцією з Kafka (реалізація та налаштування consumer'ів та producer'ів, моніторинг, алертинг, логування, масштабування тощо). Таким чином, інтеграція з брокером повідомлень відбувається дуже просто.
Data-bus дозволив абстрагуватись від конкретної мови або бібліотеки для роботи з Kafka.
Data-bus дозволив іншим сервісам абстрагуватись від шару зберігання. Можливо, рано чи пізно ми поміняємо Kafka на Pulsar, і при цьому ніхто нічого не помітить (всі послуги знають тільки про API data-bus).
Data-bus взяв він валідацію схем подій.
За допомогою data-bus реалізовано автентифікацію.
Під прикриттям data-bus ми можемо без даунтайму, непомітно оновлювати версії Kafka, централізовано вести конфігурації producer'ів, consumer'ів, брокерів тощо.
Data-bus дозволив додавати необхідні нам фічі, яких немає в Kafka (такі як аудит топіків, контроль за аномаліями у кластері, створення DLQ тощо).
Data-bus дозволяє реалізувати failover централізовано для всіх сервісів.
На даний момент для початку відправки подій до брокерів повідомлень достатньо підключити невелику бібліотеку в код свого сервісу. Це все. У вас з'являється можливість писати, читати і масштабуватися одним рядком коду. Вся реалізація прихована від вас, назовні стирчить лише кілька ручок типу розміру батча. Під капотом сервіс data-bus піднімає в Kubernetes необхідну кількість інстансів producer'ів та consumer'ів і підкладає їм необхідну конфігурацію, але це для вашого сервісу прозоро.
Звичайно, срібної кулі не буває, і такий підхід має свої обмеження.
- Data-bus потрібно підтримувати самотужки, на відміну від сторонніх бібліотек.
- Data-bus збільшує кількість взаємодій між сервісами та брокером повідомлень, що призводить до зниження продуктивності порівняно з голою Kafka.
- Не все можна так просто приховати від сервісів, дублювати функціонал KSQL або Kafka Streams у data-bus нам не хочеться, тому іноді доводиться дозволяти ходити сервіси безпосередньо.
У нашому випадку плюси переважили мінуси, і рішення прикрити брокер повідомлень окремим сервісом справдилося. За рік експлуатації у нас не було жодних серйозних аварій та проблем.
PS Дякуємо моїй дівчині, Катерині Обаляєвій, за круті картинки до цієї статті. Якщо вони вам сподобалися, Знайдеться ще більше ілюстрацій.
Джерело: habr.com
