

У цій статті я розповім про те, як проект, в якому я працюю, перетворювався з великого моноліту на набір мікросервісів.
Проект почав свою історію досить давно, на початку 2000 року. Перші версії були написані на Visual Basic 6. З часом стало зрозуміло, що розробку цією мовою в майбутньому буде складно підтримувати, оскільки IDE і сама мова розвиваються слабо. Наприкінці 2000-х було вирішено переходити більш перспективний C#. Нова версія писалася паралельно з доопрацюванням старої, поступово все більше коду було на .NET. Backend на C# спочатку орієнтувався на сервісну архітектуру, проте при розробці використовувалися спільні бібліотеки з логікою та й запускалися сервіси в єдиному процесі. Вийшла програма, яку ми називали «сервісний моноліт».
Однією з небагатьох переваг такої зв'язки була можливість сервісів викликати один одного через зовнішній API. Були явні передумови переходу більш правильну сервісну, а перспективі і микросервисную архітектуру.
Свою роботу з декомпозиції ми розпочали приблизно у 2015 році. Поки що ми не досягли ідеального стану — залишилися частини великого проекту, які вже важко назвати монолітами, але й на мікросервіси вони не схожі. Проте прогрес суттєвий.
Про нього я розповім у статті.
Зміст
Архітектура та проблеми існуючого рішення
Спочатку архітектура виглядала наступним чином: UI - окремий додаток, монолітна частина написана на Visual Basic 6, додаток на .NET був набір пов'язаних сервісів, що працює з досить великою базою даних.
Недоліки колишнього вирішення
Єдина точка відмови
Ми мали єдину точку відмови: додаток на .NET запускався в одному процесі. Якщо в якомусь із модулів відбувався збій, відмовляв усі програми, і його доводилося перезапускати. Так як у нас автоматизується велика кількість процесів для різних користувачів, через збій в одному з них деякий час не могли працювати. А за програмної помилки не допомагало і резервування.
Черга доробок
Цей недолік скоріше організаційний. У нашому додатку безліч замовників, і всі вони хочуть доопрацювати його якнайшвидше. Раніше зробити це паралельно було неможливо і всі замовники вставали в чергу. Цей процес викликав негатив у бізнесу, адже їм потрібно було довести, що їхнє завдання несе цінність. А команда розробки витрачала час на те, щоби цю чергу організувати. Це забирало багато часу і сил, а продукт у результаті не міг змінюватися так швидко, як цього від нього хотіли б.
Неоптимальне використання ресурсів
При розміщенні сервісів у процесі ми завжди повністю копіювали конфігурацію від сервера до серверу. Нам хотілося розмістити найбільш навантажені сервіси окремо, щоб не витрачати ресурси даремно, і отримати гнучкіше управління нашою схемою розгортання.
Важко впроваджувати сучасні технології
Знайома всім розробникам проблема: є бажання впровадити у проект сучасні технології, але немає можливості. За великого монолітного рішення будь-яке оновлення поточної бібліотеки, не кажучи про перехід на нову, перетворюється на досить нетривіальне завдання. Потрібно довго доводити тимлід, що це принесе більше бонусів, ніж витрачених нервів.
Складність видачі змін
Це була найсерйозніша проблема – ми видавалися релізами кожні два місяці.
Кожен реліз перетворювався на справжню катастрофу для банку, незважаючи на тестування та зусилля розробників. Бізнес розумів, що в нього на початку тижня не працюватиме частина функціональності. А розробники розуміли, що на них чекає тиждень серйозних інцидентів.
Бажання змінити ситуацію було в усіх.
Очікування від мікросервісів
Видача компонентів за готовністю. Видача компонентів у міру готовності завдяки декомпозиції рішення та відокремлення різних процесів.
Невеликі продуктові команди. Це важливо, тому що великою командою, яка працює над старим монолітом, важко було керувати. Така команда змушена була працювати за суворим процесом, а хотілося більше творчості та незалежності. Це могли дозволити собі лише невеликі команди.
Ізоляція послуг в окремих процесах. В ідеалі хотілося ізолювати в контейнерах, але велика кількість сервісів, написаних на .NET Framework, запускається лише під Windows. Зараз з'являються сервіси на .NET Core, але їх поки що мало.
Гнучкість розгортання. Хотілося б комбінувати послуги так, як це потрібно нам, а не так, як змушує код.
Використання нових технологій. Це цікаво будь-якому програмісту.
Проблеми переходу
Звичайно, якби розбити моноліт на мікросервіси було просто, про це не треба було б говорити на конференціях та писати статті. У цьому процесі багато підводного каміння, опишу основні, які заважали нам.
перша проблема типова більшість монолітів: зв'язність бізнес-логіки. Коли ми пишемо моноліт, то хочемо перевикористовувати наші класи, щоби не писати зайвий код. А при переході на мікросервіс це стає проблемою: весь код досить жорстко пов'язаний, і складно розділити сервіси.
На момент початку робіт у репозиторії було понад 500 проектів та понад 700 тис. рядків коду. Це досить велике рішення та друга проблема. Просто взяти і розділити його на мікросервіси неможливо.
Третя проблема - Відсутність необхідної інфраструктури. Фактично ми займалися ручним копіюванням вихідного коду на сервери.
Як перейти від моноліту до мікросервісів
Виділення мікросервісів
По-перше, ми собі відразу визначили, що поділ мікросервісів — процес ітераційний. Від нас завжди вимагали паралельно вести розробку бізнес-завдань. Як ми здійснюватимемо це технічно — вже наша проблема. Тому ми готувалися до ітераційного процесу. Інакше не вийде, якщо у вас велика програма, і вона спочатку не готова до того, щоб її переписували.
Які ми використовуємо способи виділення мікросервісів?
Перший спосіб - Виносити існуючі модулі як сервіси. У цьому плані нам пощастило: вже були оформлені служби, які працювали за протоколом WCF. Вони були рознесені за окремими зборами. Ми переносили їх окремо, додаючи до кожної збірки невеликий модуль запуску. Він був написаний за допомогою чудової бібліотеки Topshelf, яка дозволяє запускати програму і як сервіс, і як консоль. Це зручно для налагодження, тому що не потрібні додаткові проекти у вирішенні.
Служби були пов'язані з бізнес-логікою, оскільки використовували загальні зборки та працювали із загальною БД. Їх важко було назвати мікросервісами у чистому вигляді. Тим не менш, ми могли ці послуги видавати окремо, в різних процесах. Вже це дозволяло зменшити вплив їх один на одного, зменшивши проблему з паралельною розробкою та єдиною точкою відмови.
Складання з хостом - це лише один рядок коду в класі Program. Роботу з Topshelf ми сховали у допоміжний клас.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Другий спосіб виділення мікросервісів: створювати їх на вирішення нових завдань. Якщо при цьому моноліт не росте, це вже добре, отже, ми рухаємося у правильному напрямку. Для вирішення нових завдань ми намагалися робити окремі послуги. Якщо була така можливість, то ми створювали сервіси «канонічніші», які повністю керують своєю моделлю даних, окремою базою даних.
Ми, як і багато хто, починали з сервісів автентифікації та авторизації. Вони ідеально для цього підходять. Вони незалежні, зазвичай, вони мають відокремлена модель даних. Вони самі не взаємодіють із монолітом, тільки він звертається до них для вирішення якихось завдань. На цих сервісах можна розпочати перехід на нову архітектуру, налагодити на них інфраструктуру, спробувати якісь підходи, пов'язані з мережевими бібліотеками, тощо. У нас в організації немає команд, які не змогли б зробити сервіс аутентифікації.
Третій спосіб виділення мікросервісів, Які ми користуємося, трохи специфічний для нас. Це винесення бізнес-логіки із UI-шару. У нас основна UI-додаток десктопна, вона, як і backend, написана на C#. Розробники періодично помилялися і виносили на UI частини логіки, які мали існувати в backend і перевикористовуватися.
Якщо подивитися реальний приклад з коду UI-частини, то видно, що більшість цього рішення містить у собі справжню бізнес-логіку, яка корисна в інших процесах, не тільки для побудови UI-форми.
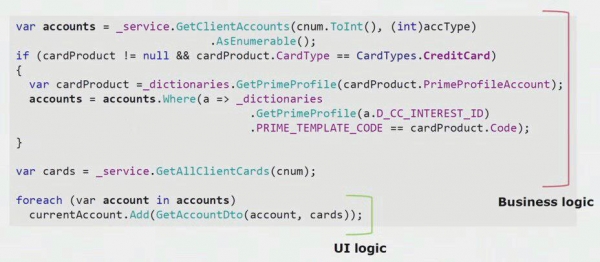
Реальна логіка UI там тільки остання пара рядків. Ми її переносили на сервер для того, щоб можна було перевикористовувати, тим самим зменшуючи UI та домагаючись правильної архітектури.
Четвертий, найважливіший спосіб виділення мікросервісів, що дозволяє зменшувати моноліт, — це винесення існуючих сервісів з переробкою. Коли ми виносимо існуючі модулі, результат не завжди подобається розробникам, і бізнес-процес з часу створення функціоналу міг застаріти. Завдяки рефакторингу ми можемо підтримати новий бізнес-процес, тому що вимоги бізнесу постійно змінюються. Ми можемо покращити вихідний код, прибрати відомі дефекти, створити якіснішу модель даних. Набирається багато переваг.
Відділення послуг з переробкою нерозривно пов'язане з поняттям обмеженого контексту. Це поняття із предметно-орієнтованого проектування. Воно означає ділянку доменної моделі, де всі терміни єдиної мови однозначно визначені. Розглянемо з прикладу контексту страховок і рахунків. У нас монолітний додаток, і необхідно у страховках попрацювати з рахунком. Ми очікуємо, що розробник знайде в іншому складання існуючий клас «Рахунок», зробить посилання на нього з класу «Страхівка», і ми отримаємо робочий код. Принцип DRY буде дотримано, завдання за рахунок використання існуючого коду буде зроблено швидше.
У результаті виявляється, що контексти рахунків та страховок пов'язані. Коли з'являться нові вимоги, цей зв'язок заважатиме розробці, збільшуючи складність і так складної бізнес-логіки. Для вирішення цієї проблеми потрібно в коді знаходити межі між контекстами та прибирати їх порушення. Наприклад, контексту страховок цілком можливо буде достатньо 20-значного номера рахунку ЦП і дати відкриття рахунку.
Щоб ці обмежені контексти відокремлювати один від одного і почати процес виділення мікросервісів з монолітного рішення, ми використовували такий підхід, як створення всередині програми зовнішніх API. Якщо ми знали, що якийсь модуль має стати мікросервісом, якось видозмінитися в рамках процесу, ми відразу ж робили виклики логіки, яка належить іншому обмеженому контексту, через зовнішні виклики. Наприклад, через REST чи WCF.
Ми для себе твердо вирішили, що не уникатимемо коду, який вимагатиме робити розподілені транзакції. У нашому випадку виявилося досить легко дотримуватися цього правила. У нас досі не виникло таких ситуацій, коли реально потрібні жорсткі розподілені транзакції — цілком достатньо узгодженості між модулями.
Розглянемо конкретний приклад. Ми маємо поняття оркестратора — конвеєра, який обробляє сутність «заявки». Він по черзі створює клієнта, рахунок та банківську картку. Якщо клієнт та рахунок створено успішно, а створення картки провалилося, заявка не переходить у статус «успішно» і залишається у статусі «карта не створена». У майбутньому фонова активність підхопить її та закінчить. Система деякий час перебуває у стані неузгодженості, але нас це загалом влаштовує.
Якщо все ж таки з'явиться ситуація, коли потрібно буде узгоджено зберегти частину даних, ми, швидше за все, підемо на укрупнення сервісу, щоб обробити це в одному процесі.
Розглянемо приклад виділення мікросервісу. Яким чином можна відносно безпечно довести його до продакшну? У цьому прикладі ми маємо окрему частину системи — модуль зарплатного обслуговування, одну з ділянок коду якого ми хотіли б зробити мікросервісним.
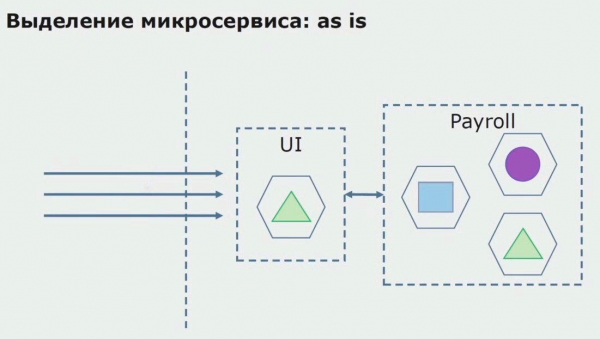
Насамперед створюємо мікросервіс, переписуючи код. Покращуємо деякі моменти, які нас не влаштовували. Реалізуємо нові бізнес-вимоги від замовника. Додаємо у зв'язку між UI та бекендом API Gateway, який забезпечуватиме прокидання викликів.
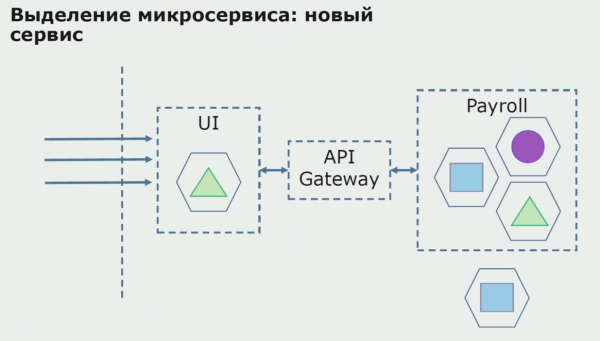
Далі ми випускаємо цю конфігурацію в експлуатацію, але може пілота. Більшість користувачів у нас, як і раніше, працює зі старими бізнес-процесами. Для нових користувачів ми розробляємо нову версію монолітної програми, яка цей процес вже не містить. По суті у нас у вигляді пілота працює зв'язка моноліту та мікросервісу.
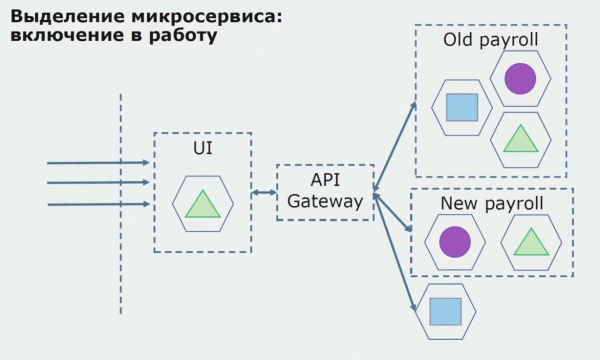
При успішному пілоті ми розуміємо, що нова конфігурація справді працездатна, можемо прибрати з рівняння старий моноліт і залишити нову конфігурацію дома старого рішення.
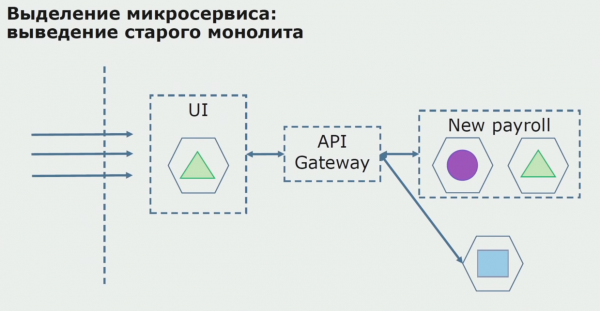
Отже, ми використовуємо практично всі існуючі методи поділу вихідного коду моноліту. Всі вони дозволяють нам зменшувати розмір частин програми і переводити їх на нові бібліотеки, роблячи якісніший вихідний код.
Робота з БД
БД піддається поділу гірше, ніж вихідний код, оскільки містить як поточну схему, а й накопичені історичні дані.
У нашої БД, як і в багатьох інших, був ще один важливий недолік - величезний розмір. Цю БД проектували відповідно до заплутаної бізнес-логіки моноліту, і між таблицями різних обмежених контекстів накопичилися зв'язки.
У нашому випадку на довершення всіх бід (велика база даних, безліч зв'язків, іноді незрозумілі межі між таблицями) виникла проблема, яка зустрічається у багатьох великих проектах: використання шаблону shared database. Дані бралися з таблиць через view, через реплікацію і відвантажувалися до інших систем, де потрібна ця реплікація. В результаті ми не могли виносити таблиці в окрему схему, тому що вони активно використовувалися.
У поділі нам допомагає те саме розбиття на обмежені контексти в коді. Воно, як правило, дає нам досить добре уявлення про те, як ми розбиваємо дані на рівні бази даних. Ми розуміємо, які таблиці належать до одного обмеженого контексту, а які до іншого.
Ми застосували два глобальні способи поділу бази даних: відділення існуючих таблиць та відділення з переробкою.
Відділення існуючих таблиць - це метод, який добре застосовувати тоді, якщо структура даних якісна, задовольняє бізнес-вимог і всіх влаштовує. І тут ми можемо виділяти в окрему схему існуючі таблиці.
Відділення з переробкою необхідно тоді, коли бізнес-модель дуже змінилася, і таблиці вже нас не задовольняють.
Відділення існуючих таблиць. Нам потрібно визначити, що ми відокремлюватимемо. Без цього знання нічого не вийде і тут нам допоможе поділ обмежених контекстів у коді. Як правило, якщо виходить зрозуміти межі контекстів у вихідному коді, стає зрозуміло, які таблиці мають потрапити до списку відділення.
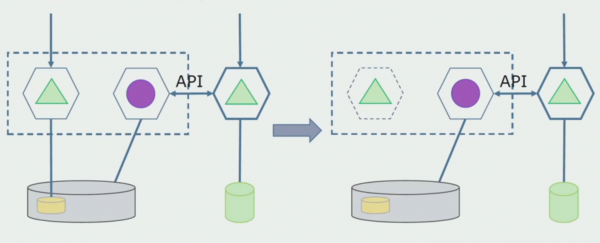
Припустимо, що у нас є рішення, в якому два модулі моноліту взаємодіють з однією базою даних. Нам потрібно зробити так, щоб з ділянкою відокремлюваних таблиць взаємодіяв тільки один модуль, а інший почав взаємодіяти з ним через API. Для початку достатньо, щоб через API вевся лише запис. Це необхідна умова, щоб ми могли говорити про незалежність мікросервісів. Зв'язки на читання можуть залишатися, поки в цьому немає великої проблеми.
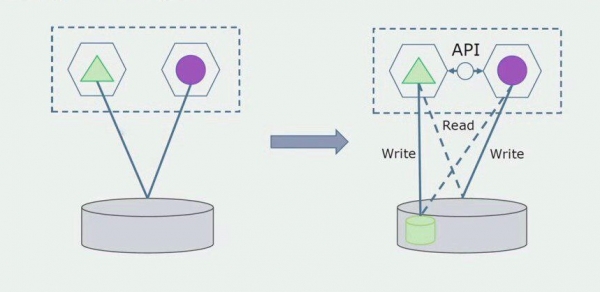
Наступним кроком ми вже можемо ділянку коду, що працює з таблицями, що відокремлюються, з переробкою або без переробки виділити в окремий мікросервіс і запускати в окремому процесі, контейнері. Це буде окремий сервіс із зв'язком з базою даних моноліту та тими таблицями, які не належать безпосередньо до нього. Моноліт ще взаємодіє на читання з частиною, що відокремлюється.
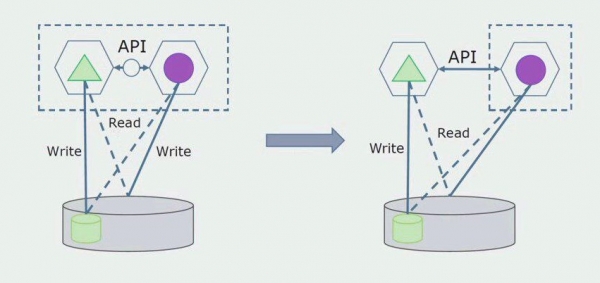
Пізніше ми приберемо цей зв'язок, тобто читання даних монолітного додатка з таблиць, що відокремлюються, теж переведемо на API.
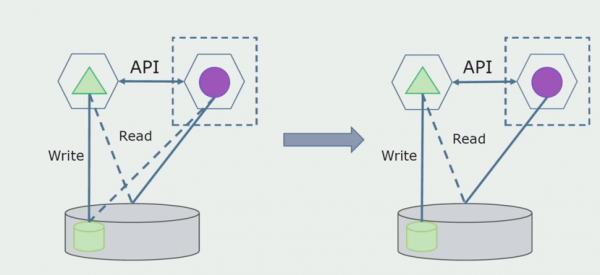
Далі виділимо із загальної БД таблиці, з якими працює лише новий мікросервіс. Ми можемо винести таблиці в окрему схему або навіть окрему фізичну БД. Залишився зв'язок на читання між мікросервісом та БД моноліту, але в цьому немає нічого страшного, у такій конфігурації він може жити досить довго.
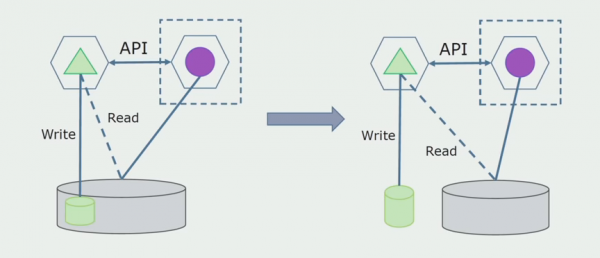
Останній крок – повністю прибрати усі зв'язки. У цьому випадку нам, можливо, знадобиться міграція даних від основної бази. Іноді ми захочемо перевикористовувати в кількох базах якісь дані або довідники, що реплікуються із зовнішніх систем. У нас це періодично трапляється.
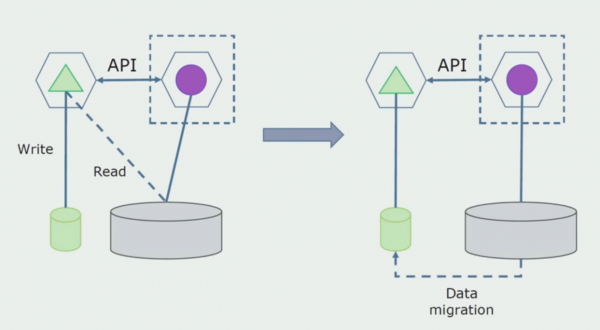
Відділення із переробкою. Цей метод дуже схожий на перший, лише йде у зворотному порядку. У нас відразу ж виділяється нова база даних та новий мікросервіс, що взаємодіє з монолітом через API. Але при цьому залишається набір таблиць БД, які ми хочемо у майбутньому видалити. Він нам більше не буде потрібний, у новій моделі ми його замінили.
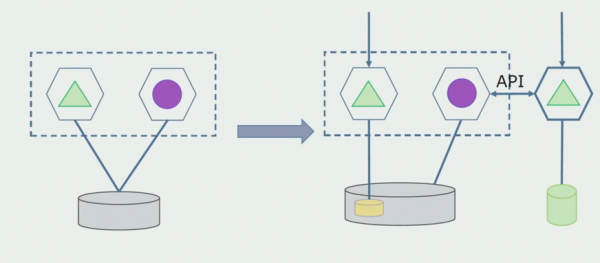
Щоб ця схема запрацювала, нам, швидше за все, буде потрібно перехідний період.
Далі є два можливі підходи.
Перший: ми дублюємо всі дані в новій та старій базах В цьому випадку у нас виникає надмірність даних, можуть виникати проблеми із синхронізацією. Зате ми можемо взяти двох різних клієнтів. Один працюватиме з новою версією, інший зі старою.
Другий: розділяємо дані за якимось бізнес-ознакою Наприклад, у нас в системі було 5 продуктів, які зберігаються у старій базі даних. Шостий у рамках нового бізнес-завдання ми поміщаємо у нову БД. Але нам знадобиться API Gateway, який синхронізує ці дані та покаже клієнту, звідки та що брати.
Обидва підходи робітники вибирайте залежно від ситуації.
Після того, як ми переконаємося, що все працює, частину моноліту, яка працює зі старими структурами БД, можна відключити.
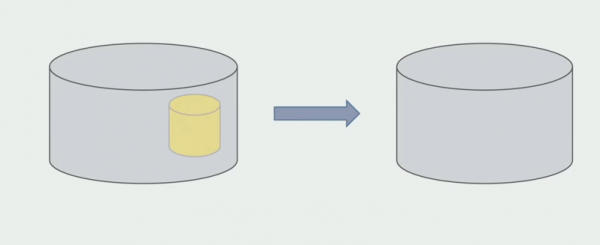
Останнім кроком буде видалення старих структур даних.
Підсумовуючи, можна сказати, що у нас існують проблеми з БД: складно з нею працювати в порівнянні з вихідним кодом, розділяти складніше, але робити це можна і потрібно. Ми знайшли деякі способи, які дозволяють це робити досить безпечно, все ж таки з даними припуститися помилки простіше, ніж з вихідним кодом.
Робота з вихідним кодом
Так виглядала схема вихідного коду, коли ми почали аналізувати монолітний проект.
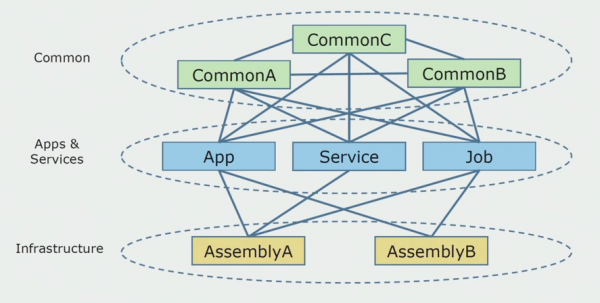
Її умовно можна розділити на три шари. Це шар модулів, плагінів, сервісів і окремих активностей. Фактично це були вхідні точки всередині монолітного рішення. Усі вони були намертво скріплені шаром Common. У ньому була бізнес-логіка, яка використовувалася сервісами спільно, та багато зв'язків. Кожен сервіс та плагін використовував до 10 і більше common-збірок, залежно від їх розміру та совісті розробників.
Нам пощастило, ми мали інфраструктурні бібліотеки, які можна було використовувати окремо.
Іноді виникала ситуація, коли деякі Соммон-об'єкти насправді не належали до цього шару, а були інфраструктурними бібліотеками. Це вирішувалося перейменуванням.
Найбільше занепокоєння викликали обмежені контексти. Бувало, що 3-4 контексти змішувалися в одній збірці Common і використовували один одного в рамках бізнес-функцій. Необхідно було зрозуміти, де це можна розділити і по яких межах, і що далі робити з мапінг цього поділу на збірки вихідного коду.
Ми сформулювали кілька правил процесу поділу коду.
Перше: ми більше не хотіли спільного використання бізнес-логіки між сервісами, активностями та плагінами. Хотіли зробити бізнес-логіку незалежною у рамках мікросервісів. З іншого боку, мікросервіси, в ідеальному випадку, сприймаються як послуги, які існують абсолютно незалежно. Я вважаю, що цей підхід трохи марнотратний, та й досягти його складно, адже, наприклад, сервіси на C# будуть у будь-якому випадку з'єднані стандартною бібліотекою. Наша система написана на С#, інші технології поки що використовувати не доводилося. Тому ми вирішили, що можемо собі дозволити використати загальні технічні зборки. Головне, щоби у них не було жодних фрагментів бізнес-логіки. Якщо у вас є зручна обгортка над ORM, який ви використовуєте, скопіювати її з сервісу в сервіс дуже дорого.
Наша команда є шанувальниками предметно-орієнтованого проектування, тому «цибульна архітектура» нам чудово підійшла. Основою в наших сервісах стало не data access layer, а збирання з доменною логікою, яка містить лише бізнес-логіку та позбавлена зв'язків з інфраструктурою. При цьому ми можемо незалежно доопрацьовувати доменну збірку для вирішення проблем, пов'язаних із фреймворками.
На цьому етапі ми зустріли першу серйозну проблему. Сервіс повинен був посилатися на одну доменну збірку, логіку ми хотіли зробити незалежною, і нам сильно заважав принцип DRY. Розробники хотіли для уникнення дублювання перевикористовувати класи із сусідніх збірок, і в результаті домени знову почали зв'язуватися між собою. Ми проаналізували результати і вирішили, що, можливо, проблема лежить ще й області пристрою сховища вихідного коду. У нас був великий репозиторій, у якому лежали всі вихідні коди. Solution для проекту дуже важко було зібрати на локальній машині. Тому для частин проекту створювалися окремі маленькі solution, і ніхто не забороняв додати в них якусь Сommon-або доменну збірку та перевикористовувати. Єдиний інструмент, який не дозволяв нам це робити, це код ревью. Але часом і він давав збої.
Тоді ми почали переходити на модель із окремими репозиторіями. Бізнес-логіка перестала витікати з сервісу до сервісу, домени справді стали незалежними. Обмежені контексти підтримуються чіткіше. Як при цьому ми перевикористовуємо інфраструктурні бібліотеки? Ми виділили їх в окремий репозиторій, потім помістили до Nuget-пакетів, які поклали в Artifactory. При будь-якій зміні складання та публікація відбувається автоматично.
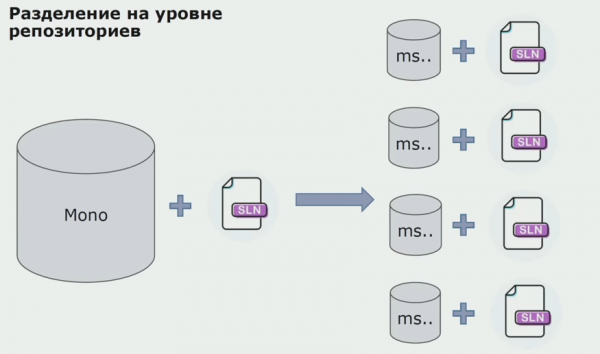
Наші послуги стали посилатися на внутрішні інфраструктурні пакети так само, як і на зовнішні. Зовнішні бібліотеки ми завантажуємо з Nuget. Для роботи з Artifactory, куди ми поміщали ці пакети, ми застосували два пакетні менеджери. У маленьких репозиторіях ми використовували Nuget. У репозиторіях із кількома сервісами ми використовували Paket, який забезпечує більшу узгодженість версій між модулями.
Таким чином, працюючи над вихідним кодом, трохи змінивши архітектуру та розділяючи репозиторії, ми робимо наші сервіси більш незалежними.
Проблеми інфраструктури
Більшість недоліків під час переходу на мікросервіси пов'язані з інфраструктурою. Вам знадобиться автоматизоване розгортання, потрібні нові бібліотеки для роботи інфраструктури.
Ручне встановлення в середу
Спочатку рішення на довкілля ми встановлювали вручну. Щоб автоматизувати цей процес, ми створили CI/CD-конвеєр. Вибрали процес continuous delivery, тому що continuous deployment для нас поки що неприйнятний з точки зору бізнес-процесів. Тому відправлення в експлуатацію здійснюються за кнопкою, а на тестування автоматично.
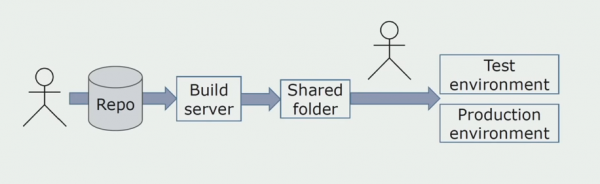
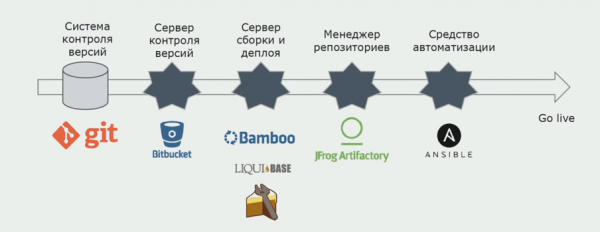
Ми використовуємо Atlassian, Bitbucket для зберігання вихідних кодів та Bamboo для збирання. Нам подобається писати складальні скрипти на Cake, тому що це той самий C#. У Artifactory приходять готові пакети, і Ansible автоматично потрапляє на тестові сервери, після чого їх можна відразу тестувати.
Роздільне логування
Свого часу однією з ідей моноліту було забезпечення спільного логування. Нам також потрібно було зрозуміти, що робити з окремими логами, що лежать на дисках. Логи у нас пишуться до текстових файлів. Ми вирішили використати стандартний ELK-стек. Не стали писати в ELK безпосередньо через провайдери, а вирішили, що доопрацюємо текстові логи і записуватимемо в них ID трасування у вигляді ідентифікатора, додаючи ім'я сервісу, щоб ці логи потім можна було розбирати.
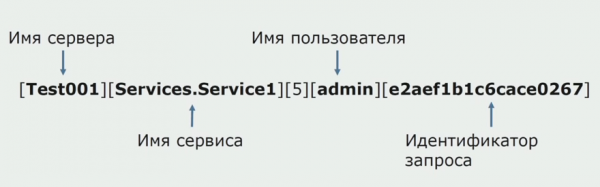
За допомогою Filebeat ми отримуємо можливість збирати наші логи з серверівпотім їх перетворювати, за допомогою Kibana будувати запити в UI і дивитися, як йшов виклик між сервісами. У цьому дуже допомагає ID трасування.
Тестування та налагодження пов'язаних сервісів
Спочатку ми не до кінця розуміли, як нам налагоджувати сервіси, що розробляються. З монолітом все було просто, ми запускали його на локальній машині. Спочатку намагалися робити і з мікросервісами, але іноді для повноцінного запуску одного мікросервісу потрібно запускати і кілька інших, а це незручно. Ми зрозуміли, що потрібно переходити до моделі, коли ми залишаємо на локальній машині лише послуги або послуги, який хочемо налагодити. Інші послуги застосовуються з серверів, що збігаються по конфігурації з prod. Після налагодження при тестуванні для кожного завдання на тестовий сервер видаються лише змінені сервіси. Таким чином, тестується рішення у такому вигляді, в якому воно в майбутньому опиниться на продажі.
Є сервери, на яких стоять лише production-версії сервісів. Ці сервери потрібні на випадок інцидентів для перевірки поставки перед деплом і для внутрішніх навчань.
Ми додали процес автоматичного тестування за допомогою популярної бібліотеки Specflow. Тести запускаються автоматично за допомогою NUnit одразу після розгортання з Ansible. Якщо покриття завдання повністю автоматичне, то немає потреби у ручному тестуванні. Хоча іноді все ж таки потрібне додаткове ручне тестування. Для визначення, які тести запускати для конкретного завдання, ми використовуємо теги Jira.
Додатково зросла потреба у навантажувальному тестуванні, раніше воно проводилося лише в окремих випадках. Для запуску тестів ми використовуємо JMeter, для їх зберігання InfluxDB, а для побудови графіків процесу Grafana.
Чого ми досягли?
По-перше, ми позбулися поняття «реліз». Зникли двомісячні монструозні релізи, коли ця махіна розгорталася в production-середовищі, ламаючи на якийсь час бізнес-процеси. Зараз ми розвертаємо послуги в середньому кожні 1,5 дні, групуючи їх, тому що в експлуатацію вони виходять після погодження.
У нашій системі немає фатальних збоїв. Якщо ми випустили мікросервіс з помилкою, то пов'язана з нею функціональність буде зламана, а решта функціональності не постраждає. Це значно покращує користувальницький досвід.
Ми можемо керувати схемою розгортання. Можна виділяти групи сервісів окремо від решти рішення, якщо це потреба.
Крім того, ми суттєво зменшили проблему з великою чергою доробок. У нас з'явилися окремі продуктові команди, які працюють із частиною сервісів незалежно. Тут вже непогано підходить Scrum-процес. У конкретної команди може бути окремий власник продукту, який ставить їй завдання.
Резюме
- Мікросервіс добре підходять для декомпозиції складних систем. У процесі ми починаємо розуміти, що є в нашій системі, які є обмежені контексти, де проходять їхні межі. Це дозволяє правильно розподіляти доробки за модулями та не допустити заплутування коду.
- Мікросервіси надають організаційні переваги. Про них часто говорять тільки як про архітектуру, але будь-яка архітектура потрібна на вирішення потреб бізнесу, а чи не сама собою. Тому ми можемо сказати, що мікросервіси добре підходять для вирішення завдань невеликими командами з огляду на те, що зараз дуже популярний Scrum.
- Поділ – це ітеративний процес. Не можна взяти програму і просто розділити на мікросервіси. Продукт, що вийшов, навряд чи буде працездатним. При виділенні мікросервісів вигідно переписувати існуюче legacy, тобто перетворювати його на код, який нам подобається і краще задовольняє потребам бізнесу за функціональністю та швидкістю.
Невелика застереження: витрати на перехід до мікросервісів досить суттєві. Тільки на вирішення проблеми інфраструктури пішло багато часу. Тому, якщо у вас невелика програма, яка не вимагає специфічного масштабування, якщо немає великої кількості замовників, які борються за увагу та час вашої команди, то, можливо, мікросервіси – це не те, що вам потрібне сьогодні. Це досить дорого. Якщо починати процес з мікросервісів, то витрати спочатку будуть більшими, ніж якщо той же проект починати з розробки моноліту.
PS Більш емоційна розповідь (і як особисто вам) - по .
Тут є повна версія доповіді.
Джерело: habr.com
