


29 січня технічний комітет організації CNCF (Cloud Native Computing Foundation), що стоїть за Kubernetes, Prometheus та іншими Open Source-продуктами зі світу контейнерів та cloud native, про ухвалення проекту тура у свої лави. Відмінна нагода познайомитися ближче з цим «оркеструвальником систем розподіленого зберігання даних у Kubernetes».
Що за Rook?
- це написане на Go програмне забезпечення ( з вільної ліцензії Apache License 2.0), призначене для наділення сховищ даних автоматизованими функціями, які роблять їх самокерованими, самомасштабованими та самовідновлюваними. Для цього Rook автоматизує (для сховищ даних, що застосовуються в оточенні Kubernetes): розгортання, bootstrapping, конфігурацію, provisioning, масштабування, оновлення, міграції, відновлення після збоїв, моніторинг та управління ресурсами.
Проект знаходиться в альфа-стадії та спеціалізується на оркеструванні розподіленої системи зберігання даних Ceph у кластерах Kubernetes. Автори заявляють також про плани підтримки інших систем зберігання, але це станеться не в найближчих релізах.
Компоненти та технічні пристрої
В основі роботи Rook всередині Kubernetes - спеціальний оператор (Докладніше про Kubernetes Operators ми писали в ), що автоматизує конфігурацію сховища та реалізує його моніторинг.
Отже, оператор Rook є контейнером, який містить все необхідне для розгортання та подальшого обслуговування сховища. Серед обов'язків оператора:
- створення DaemonSet для демонів зберігання Ceph () із простим кластером RADOS;
- створення подів для моніторингу Ceph (з , які перевіряють стан кластера; для кворуму в більшості випадків розгортаються три екземпляри, і при падінні будь-якого з них піднімається новий);
- управління CRDs () для самого , , (наборів ресурсів та сервісів для обслуговування HTTP-запитів, що виконують PUT/GET для об'єктів, - вони сумісні з S3 та Swift API), а також ;
- ініціалізація подів для запуску всіх необхідних сервісів;
- створення агентів Rook.
Агенти Rook представлені окремими подами, що розвертаються на кожному вузлі Kubernetes. Призначення агента - конфігурація плагіна забезпечує підтримку томів зберігання в Kubernetes. Агент реалізує експлуатацію сховища: підключає мережеві пристрої для зберігання, монтує томи, форматує файлову систему тощо.
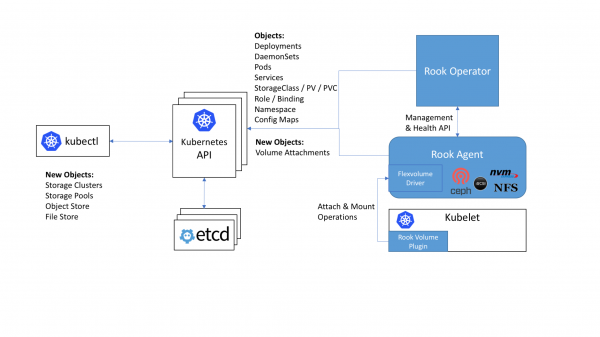
Місце та роль компонентів Rook у загальній схемі кластера Kubernetes
Rook пропонує три види сховищ:
- (Блокувати,
StorageClass) - монтує сховище до єдиного поду; - (Об'єкт,
ObjectStore) - доступно всередині та поза кластером Kubernetes (по S3 API); - (Shared File System,
Filesystem) - файлова система, яку можна монтувати на читання та запис з безлічі подов.
Внутрішній пристрій Rook включає:
- Монс - Поди для моніторингу Ceph (з вже згаданими ceph-mon);
- OSDs - поди з демонами ceph-osd (Object Storage Daemons);
- М.Г.Р. - піди з демоном (Ceph Manager), що надає додаткові можливості моніторингу та інтерфейси для зовнішніх систем (моніторингу/управління);
- RGW (Опціонально) - Поди з об'єктним сховищем;
- MDS (Опціонально) - поди з ФС, що розділяється.
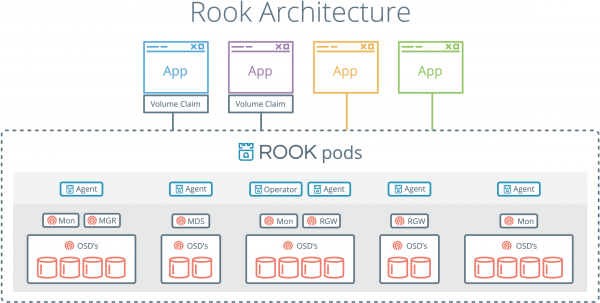
Усі демони Rook (Mons, OSDs, MGR, RGW, MDS) скомпільовані в єдиний бінарник (rook), що запускається в контейнері.
Для короткого представлення проекту Rook може стати в нагоді також ця невелика (12 слайдів) від Bassam Tabbara (CTO в Quantum Corp.).
Експлуатація Rook
Оператор Rook повноцінно підтримує Kubernetes версії 1.6 та вище (і, частково, старіший реліз K8s - 1.5.2). Його інсталяція в виглядає так:
cd cluster/examples/kubernetes
kubectl create -f rook-operator.yaml
kubectl create -f rook-cluster.yamlКрім того, для оператора Rook підготовлено завдяки чому інсталяція може проводитися і так:
helm repo add rook-alpha https://charts.rook.io/alpha
helm install rook-alpha/rook Є невелика кількість (наприклад, можна вимкнути підтримку , якщо ця можливість не використовується у вашому кластері), які передаються в helm install через параметр --set key=value[,key=value] (або зберігати в окремому YAML-файлі, а передавати через -f values.yaml).
Після встановлення оператора Rook та запуску подів з його агентами залишається створити сам кластер Rook, найпростіша конфігурація якого виглядає так (rook-cluster.yaml):
apiVersion: v1
kind: Namespace
metadata:
name: rook
---
apiVersion: rook.io/v1alpha1
kind: Cluster
metadata:
name: rook
namespace: rook
spec:
dataDirHostPath: /var/lib/rook
storage:
useAllNodes: true
useAllDevices: false
storeConfig:
storeType: bluestore
databaseSizeMB: 1024
journalSizeMB: 1024Примітка: особливу увагу варто звернути на атрибут dataDirHostPath, коректне значення якого необхідне збереження кластера після перезавантажень. Для випадків його використання як постійного місця зберігання даних Rook на хості Kubernetes автори рекомендують мати в цьому каталозі хоча б 5 Гб вільного дискового простору.
Залишається власне створити кластер з конфігурації та переконатися, що піди створилися у кластері (у просторі імен rook):
kubectl create -f rook-cluster.yaml
kubectl -n rook get pod
NAME READY STATUS RESTARTS AGE
rook-api-1511082791-7qs0m 1/1 Running 0 5m
rook-ceph-mgr0-1279756402-wc4vt 1/1 Running 0 5m
rook-ceph-mon0-jflt5 1/1 Running 0 6m
rook-ceph-mon1-wkc8p 1/1 Running 0 6m
rook-ceph-mon2-p31dj 1/1 Running 0 6m
rook-ceph-osd-0h6nb 1/1 Running 0 5mАпгрейд кластера Rook (до нової версії) - це процедура, яка на даному етапі вимагає почергового оновлення всіх його компонентів у певній послідовності, а починати її можна тільки після того, як ви переконалися в повністю здоровому стані поточної інсталяції Rook. Детальну покрокову інструкцію на прикладі оновлення Rook версії 0.5.0 до 0.5.1 можна знайти в .
У листопаді минулого року у блозі Rook порівняння продуктивності із EBS. Його результати варті уваги, а якщо зовсім коротко, то вони такі:
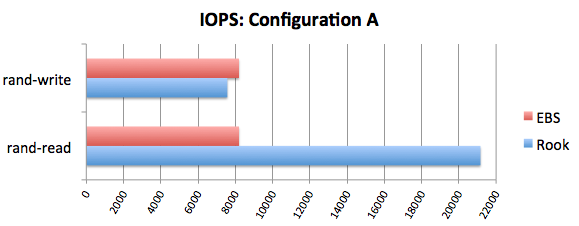
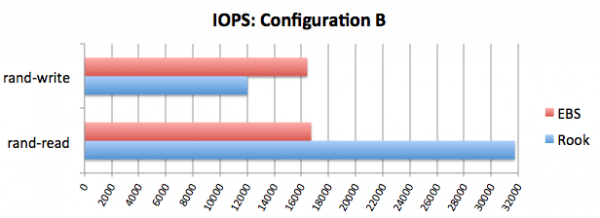
Перспективи
Поточний статус Rook - alpha, а останнім великим релізом на сьогоднішній день є , випущена у листопаді 2017 року (актуальне виправлення - Вийшло 14 грудня). Вже у першій половині 2018 року очікуються релізи більш зрілих версій: бети та стабільної (офіційно готової для використання у production).
Згідно з проекту, розробники мають докладне бачення з розвитку Rook як мінімум у двох найближчих релізах: 0.7 (його готовність у трекері GitHub як 60%) та 0.8. Серед очікуваних змін – переведення підтримки Ceph Block та Ceph Object у статус бета-версії, динамічний provisioning томів для CephFS, розвинена система логування, автоматизовані оновлення кластера, підтримка снапшотів для томів.
Прийняття Rook до числа (поки що на ранньому етапі — «inception-level», — нарівні з и ) є своєрідною гарантією зростаючого інтересу до продукту. Наскільки він закріпиться у світі хмарних програм, стане краще ясно після появи стабільних версій, які, безумовно, принесуть Rook нових «випробувачів» та користувачів.
P.S.
Читайте також у нашому блозі:
- «»;
- «»;
- «»;
- «»;
- «».
Джерело: habr.com
