


ہیلو، حبر قارئین! پچھلے مضمون میں، ہم نے AERODISK ENGINE سٹوریج سسٹمز میں ڈیزاسٹر ریکوری کی ایک سادہ خصوصیت پر تبادلہ خیال کیا: نقل۔ اس مضمون میں، ہم ایک زیادہ پیچیدہ اور دلچسپ موضوع پر غور کریں گے: میٹرو کلسٹر، دو ڈیٹا سینٹرز کے لیے ڈیزاسٹر پروٹیکشن کا ایک خودکار حل جو ایکٹیو ایکٹیو آپریشن کو قابل بناتا ہے۔ ہم اس کی وضاحت کریں گے، مظاہرہ کریں گے، توڑیں گے اور اسے ٹھیک کریں گے۔
ہمیشہ کی طرح، نظریہ پہلے
میٹرو کلسٹر ایک کلسٹر ہے جو شہر یا ضلع کے اندر کئی سائٹس پر تقسیم ہوتا ہے۔ لفظ "کلسٹر" واضح طور پر بتاتا ہے کہ کمپلیکس خودکار ہے، مطلب یہ ہے کہ ناکامی کی صورت میں کلسٹر نوڈس خود بخود بدل جاتے ہیں۔
یہ وہ جگہ ہے جہاں میٹرو کلسٹر اور معیاری نقل کے درمیان بنیادی فرق ہے: آپریشنز کا آٹومیشن۔ اس کا مطلب ہے کہ کسی بھی واقعے کی صورت میں (ڈیٹا سینٹر کی ناکامی، نیٹ ورک میں خلل وغیرہ)، سٹوریج سسٹم خود بخود ڈیٹا کی دستیابی کو برقرار رکھنے کے لیے ضروری اقدامات انجام دے گا۔ معیاری نقلوں کے ساتھ، یہ اعمال مکمل طور پر یا جزوی طور پر دستی طور پر منتظم کے ذریعے کیے جاتے ہیں۔
یہ کیا کرتا ہے؟
میٹرو کلسٹر کے مختلف نفاذ کا استعمال کرتے وقت صارفین کا بنیادی ہدف RTO (ریکوری ٹائم مقصد) کو کم سے کم کرنا ہے۔ یعنی ناکامی کے بعد آئی ٹی سروسز کو بحال کرنے میں لگنے والے وقت کو کم کرنا۔ روایتی نقل کے ساتھ، بحالی کا وقت میٹرو کلسٹر کے مقابلے میں ہمیشہ طویل ہوگا۔ کیوں؟ یہ آسان ہے۔ ایڈمنسٹریٹر کو سائٹ پر ہونا چاہیے اور دستی طور پر نقل کو تبدیل کرنا چاہیے، جبکہ میٹرو کلسٹر یہ خود بخود کرتا ہے۔
اگر آپ کے پاس ڈیوٹی پر کوئی وقف ایڈمنسٹریٹر نہیں ہے جو سوتا نہیں، کھاتا ہے، سگریٹ نہیں پیتا یا بیمار نہیں ہوتا، لیکن آپ کے سٹوریج سسٹم کی 24/7 حالت پر نظر رکھتا ہے، تو اس بات کی ضمانت دینے کا کوئی طریقہ نہیں ہے کہ ایڈمنسٹریٹر ناکامی کے دوران مینوئل سوئچ اوور انجام دینے کے لیے دستیاب ہوگا۔
اس کے مطابق، میٹرو کلسٹر کی غیر موجودگی میں RTO یا ڈیوٹی پر ایک لافانی لیول 99 ایڈمنسٹریٹر تمام سسٹمز کے سوئچنگ ٹائم اور زیادہ سے زیادہ مدت کے مجموعے کے برابر ہوگا جس کے بعد ایڈمنسٹریٹر کو اسٹوریج سسٹم اور ملحقہ سسٹمز کے ساتھ کام شروع کرنے کی ضمانت دی جاتی ہے۔
اس طرح، ہم واضح نتیجے پر پہنچے ہیں کہ میٹرو کلسٹر کا استعمال اس وقت کیا جانا چاہیے جب RTO کی ضرورت منٹوں کی ہو، گھنٹوں یا دنوں کی نہیں۔ یعنی، جب، ڈیٹا سینٹر کی شدید بندش کی صورت میں، IT ڈیپارٹمنٹ کو یقینی بنانا چاہیے کہ کاروبار منٹوں، یا سیکنڈوں میں IT سروسز تک رسائی بحال کر سکتا ہے۔
یہ کس طرح کام کرتا ہے؟
نچلی سطح پر، میٹرو کلسٹر مطابقت پذیر ڈیٹا ریپلیکیشن میکانزم کا استعمال کرتا ہے جسے ہم نے پچھلے مضمون میں بیان کیا ہے (دیکھیں )۔ چونکہ نقل ہم آہنگ ہے، اس لیے اس کے تقاضے اسی طرح ہیں، زیادہ واضح طور پر:
- فائبر آپٹکس بطور فزکس، 10 گیگابٹ ایتھرنیٹ (یا اس سے زیادہ)؛
- ڈیٹا سینٹرز کے درمیان فاصلہ 40 کلومیٹر سے زیادہ نہیں ہے۔
- ڈیٹا سینٹرز (اسٹوریج سسٹم کے درمیان) کے درمیان آپٹیکل چینل کی تاخیر 5 ملی سیکنڈ تک (بہترین طور پر 2)۔
یہ تمام ضروریات فطرت میں مشاورتی ہیں، یعنی میٹرو کلسٹر کام جاری رکھے گا چاہے ان ضروریات کو پورا نہ کیا جائے۔ تاہم، یہ سمجھنا چاہیے کہ ان تقاضوں کی عدم تعمیل کے نتائج میٹرو کلسٹر میں دونوں اسٹوریج سسٹمز کے کام میں سست روی کے مترادف ہیں۔
لہذا، اسٹوریج سسٹم کے درمیان ڈیٹا کی منتقلی کے لیے ایک ہم وقت ساز نقل استعمال کی جاتی ہے۔ لیکن نقلیں خود بخود کیسے بدل جاتی ہیں، اور سب سے اہم بات یہ ہے کہ تقسیم دماغی حالات سے کیسے بچا جاتا ہے؟ اس کے لیے اعلیٰ سطح پر ایک اضافی ادارہ — ایک ثالث — استعمال کیا جاتا ہے۔
ریفری کیسے کام کرتا ہے اور اس کا کام کیا ہے؟
ثالث ایک چھوٹی ورچوئل مشین یا ہارڈویئر کلسٹر ہے جسے کسی تیسری سائٹ پر لانچ کیا جانا چاہیے (جیسے، دفتر میں) اور اسے ICMP اور SSH کے ذریعے اسٹوریج سسٹم تک رسائی فراہم کی جائے۔ ایک بار لانچ ہونے کے بعد، ثالث کے پاس ایک IP ایڈریس ہونا چاہیے، اور پھر، سٹوریج سسٹم کی طرف، میٹرو کلسٹر میں حصہ لینے والے ریموٹ کنٹرولرز کے پتے کے ساتھ اس کا پتہ بھی بتانا چاہیے۔ اس کے بعد، ثالث استعمال کے لیے تیار ہے۔
ثالث میٹرو کلسٹر میں تمام سٹوریج سسٹم کی مسلسل نگرانی کرتا ہے، اور اگر کوئی سٹوریج سسٹم دستیاب نہیں ہے تو، دوسرے کلسٹر ممبر ("لائیو" سٹوریج سسٹمز میں سے ایک) کی جانب سے عدم دستیابی کی تصدیق کے بعد، یہ ریپلیکشن رول سوئچنگ کے طریقہ کار اور میپنگ کو شروع کرنے کا فیصلہ کرتا ہے۔
ایک بہت اہم نکتہ: ثالث کو ہمیشہ ان جگہوں سے مختلف سائٹ پر موجود ہونا چاہیے جہاں سٹوریج سسٹم موجود ہیں، یعنی نہ تو ڈیٹا سینٹر 1 میں، جہاں سٹوریج سسٹم 1 واقع ہے، اور نہ ہی ڈیٹا سینٹر 2 میں، جہاں سٹوریج سسٹم 2 انسٹال ہے۔
کیوں؟ کیونکہ صرف اسی طریقے سے ثالث، بچ جانے والے سٹوریج سسٹمز میں سے کسی ایک کو استعمال کرتے ہوئے، دو سٹوریج سسٹم سائٹس میں سے کسی ایک کی ناکامی کا غیر واضح اور درست طریقے سے تعین کر سکتا ہے۔ کسی بھی دوسرے ثالث کی جگہ کا تعین دماغی تقسیم کی صورت حال کا باعث بن سکتا ہے۔
اب آئیے ریفری کے کام کی تفصیلات میں غوطہ لگاتے ہیں۔
متعدد خدمات ثالث پر چلتی ہیں جو تمام اسٹوریج کنٹرولرز کو مسلسل پول کرتی ہیں۔ اگر رائے شماری کا نتیجہ پچھلے سے مختلف ہے (دستیاب/غیر دستیاب)، تو اسے ایک چھوٹے ڈیٹا بیس پر لکھا جاتا ہے، جو ثالث پر بھی چلتا ہے۔
آئیے مزید تفصیل سے ریفری کے کام کی منطق پر غور کریں۔
مرحلہ 1۔ دستیابی کا تعین کرنا۔ سٹوریج سسٹم کی ناکامی کا اشارہ دینے والا واقعہ ایک سٹوریج سسٹم کے دونوں کنٹرولرز سے 5 سیکنڈ تک پنگ کی عدم موجودگی ہے۔
مرحلہ 2۔ سوئچنگ کا طریقہ کار شروع کریں۔ ثالث کے اس بات کے تعین کے بعد کہ اسٹوریج سسٹمز میں سے ایک دستیاب نہیں ہے، وہ "لائیو" اسٹوریج سسٹم کو ایک درخواست بھیجتا ہے تاکہ اس بات کی تصدیق کی جا سکے کہ "ڈیڈ" اسٹوریج سسٹم واقعی مردہ ہے۔
ثالث سے اس طرح کا حکم موصول ہونے کے بعد، دوسرا (زندہ) اسٹوریج سسٹم اضافی طور پر ناکام فرسٹ اسٹوریج سسٹم کی دستیابی کو چیک کرتا ہے اور، اگر یہ دستیاب نہیں ہے، تو ثالث کے اندازے کی تصدیق بھیجتا ہے۔ ذخیرہ کرنے کا نظام واقعی دستیاب نہیں ہے۔
یہ تصدیق موصول ہونے پر، ثالث ان نقلوں پر ریموٹ ریپلیکیشن فیل اوور اور میپنگ کی بحالی کا طریقہ کار شروع کرتا ہے جو ناکام اسٹوریج سسٹم پر فعال (پرائمری) تھے، اور ان نقلوں کو سیکنڈری سے پرائمری میں اپ گریڈ کرنے اور میپنگ کو بحال کرنے کے لیے دوسرے اسٹوریج سسٹم کو کمانڈ بھیجتا ہے۔ دوسرا سٹوریج سسٹم پھر ان طریقہ کار کو انجام دیتا ہے اور پھر اپنے ہی اسٹوریج سسٹم سے کھوئے ہوئے LUNs تک رسائی فراہم کرتا ہے۔
یہ اضافی تصدیق کیوں ضروری ہے؟ کورم کے لیے۔ یعنی کلسٹر ممبران کی کل طاق (3) تعداد کی اکثریت کو کلسٹر نوڈس میں سے کسی ایک کی ناکامی کی تصدیق کرنی ہوگی۔ تب ہی یہ فیصلہ معتبر طور پر درست ہو گا۔ یہ غلط فیل اوور سے بچنے کے لیے ضروری ہے اور اس کے نتیجے میں دماغ کی تقسیم۔
مرحلہ 2 میں تقریباً 5-10 سیکنڈ لگتے ہیں، لہذا، غیر دستیابی کا تعین کرنے کے لیے درکار وقت (5 سیکنڈ) کو مدنظر رکھتے ہوئے، حادثے کے 10-15 سیکنڈ کے اندر، ڈاؤن شدہ اسٹوریج سسٹم سے LUNs لائیو اسٹوریج سسٹم کے ساتھ کام کے لیے خود بخود دستیاب ہو جائیں گے۔
ظاہر ہے، میزبانوں کے ساتھ کنکشن کی رکاوٹوں سے بچنے کے لیے، آپ کو یہ بھی یقینی بنانا ہوگا کہ میزبانوں پر ٹائم آؤٹ درست طریقے سے ترتیب دیا گیا ہے۔ تجویز کردہ ٹائم آؤٹ کم از کم 30 سیکنڈ ہے۔ یہ میزبان کو کسی آفت کی صورت میں لوڈ سوئچنگ کے دوران اسٹوریج سسٹم سے منقطع ہونے سے روکے گا اور اس بات کو یقینی بنائے گا کہ I/O میں خلل نہ پڑے۔
ایک سیکنڈ انتظار کریں، لہذا اگر میٹرو کلسٹر کے ساتھ سب کچھ اتنا اچھا ہے، تو ہمیں باقاعدہ نقل کی ضرورت کیوں ہے؟
اصل میں، سب کچھ اتنا آسان نہیں ہے.
آئیے میٹرو کلسٹر کے فوائد اور نقصانات پر غور کریں۔
لہذا، ہم نے محسوس کیا کہ روایتی نقل کے مقابلے میں میٹرو کلسٹر کے واضح فوائد یہ ہیں:
- مکمل آٹومیشن آفت کی صورت میں بحالی کے کم سے کم وقت کو یقینی بناتا ہے۔
- اور یہ سب ہے :-)۔
اب، توجہ، منفی پہلو:
- حل کی قیمت۔ اگرچہ ایروڈسک سسٹمز میں میٹرو کلسٹر کو اضافی لائسنسنگ کی ضرورت نہیں ہوتی ہے (وہی لائسنس نقل کے لیے استعمال کیا جاتا ہے)، لیکن حل کی لاگت اب بھی ہم وقت ساز نقل کے استعمال سے زیادہ ہوگی۔ ہم وقت ساز نقل کے لیے تمام تقاضوں کو لاگو کیا جانا چاہیے، نیز اضافی سوئچنگ اور اضافی جگہ سے منسلک میٹرو کلسٹر کی ضروریات (دیکھیں میٹرو کلسٹر پلاننگ)۔
- حل کی پیچیدگی۔ میٹرو کلسٹر معیاری نقل کے مقابلے میں نمایاں طور پر زیادہ پیچیدہ ہوتا ہے اور منصوبہ بندی، ترتیب اور دستاویزات کے لیے نمایاں طور پر زیادہ توجہ اور کوشش کی ضرورت ہوتی ہے۔
آخرکار۔ جب آپ کو واقعی سیکنڈوں یا منٹوں میں RTO کو یقینی بنانے کی ضرورت ہو تو میٹرو کلسٹر یقیناً ایک بہت ہی تکنیکی طور پر جدید اور اچھا حل ہے۔ لیکن اگر ایسی کوئی ضرورت موجود نہیں ہے، اور کاروبار کے لیے گھنٹوں کا RTO قابل قبول ہے، تو چڑیوں کو توپ سے مارنے کا کوئی فائدہ نہیں۔ معیاری، ہینڈ آن ریپلیکیشن کافی ہے، کیونکہ میٹرو کلسٹر آئی ٹی کے بنیادی ڈھانچے کے لیے اضافی اخراجات اور پیچیدگی کا باعث بنے گا۔
میٹرو کلسٹر پلاننگ
اس سیکشن کا مقصد میٹرو کلسٹر ڈیزائن کے لیے ایک جامع گائیڈ بنانا نہیں ہے، بلکہ ان کلیدی شعبوں کو اجاگر کرنا ہے جن پر غور کرنے کے لیے آپ ایسا نظام بنانے کا فیصلہ کرتے ہیں۔ لہذا، میٹرو کلسٹر کو لاگو کرتے وقت، اسٹوریج سسٹم بنانے والے (ہم) اور دیگر متعلقہ سسٹمز سے مشورہ ضرور کریں۔
سائٹس
جیسا کہ اوپر بیان کیا گیا ہے، میٹرو کلسٹر کے لیے کم از کم تین سائٹس کی ضرورت ہوتی ہے: دو ڈیٹا سینٹرز جہاں اسٹوریج سسٹم اور متعلقہ سسٹم کام کریں گے، اور تیسری سائٹ جہاں ثالث کام کرے گا۔
ڈیٹا سینٹرز کے درمیان تجویز کردہ فاصلہ 40 کلومیٹر سے زیادہ نہیں ہے۔ زیادہ فاصلہ ممکنہ طور پر اضافی تاخیر کو متعارف کرائے گا، جو میٹرو کلسٹر میں انتہائی ناپسندیدہ ہے۔ یاد دہانی کے طور پر، تاخیر 5 ملی سیکنڈ سے کم ہونی چاہیے، حالانکہ 2 مثالی ہے۔
منصوبہ بندی کے عمل کے دوران تاخیر کو بھی چیک کرنے کی سفارش کی جاتی ہے۔ ڈیٹا سینٹرز کے درمیان فائبر آپٹکس فراہم کرنے والا کوئی بھی معروف فراہم کنندہ کافی تیزی سے اعلیٰ معیار کے ٹیسٹ کا اہتمام کر سکتا ہے۔
جہاں تک ثالث کو تاخیر کا تعلق ہے (یعنی تیسری سائٹ اور پہلی دو کے درمیان)، تجویز کردہ تاخیر کی حد 200 ملی سیکنڈ تک ہے، یعنی انٹرنیٹ پر ایک معیاری کارپوریٹ VPN کنکشن موزوں ہوگا۔
سوئچنگ اور نیٹ ورکنگ
نقل کی اسکیم کے برعکس، جو مختلف سائٹس سے سٹوریج سسٹمز کو آسانی سے جوڑتی ہے، میٹرو کلسٹر اسکیم کے لیے میزبانوں کو مختلف سائٹس پر دونوں اسٹوریج سسٹمز سے جڑنے کی ضرورت ہوتی ہے۔ فرق کو واضح کرنے کے لیے، دونوں اسکیمیں ذیل میں دکھائی گئی ہیں۔
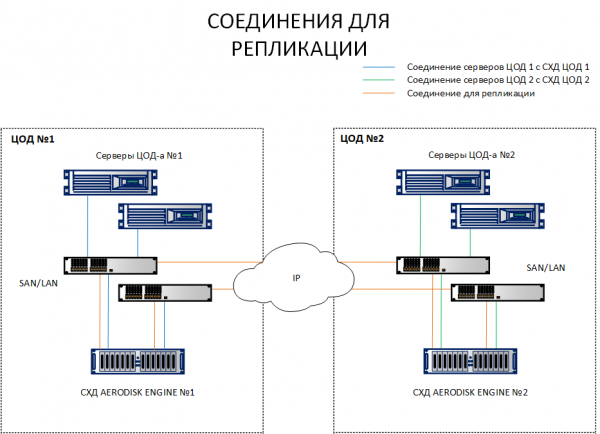
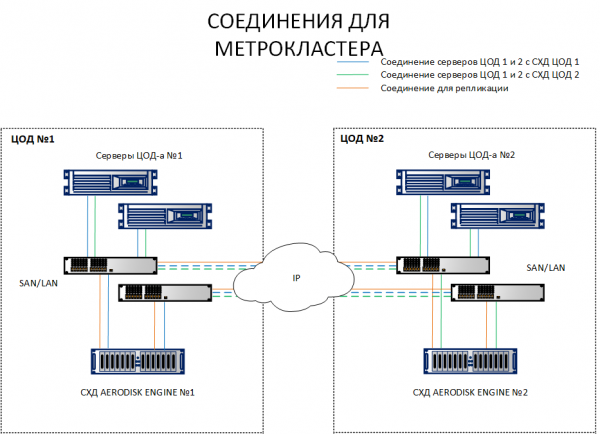
جیسا کہ آپ خاکہ سے دیکھ سکتے ہیں، سائٹ 1 پر میزبان سٹوریج سسٹم 1 اور سٹوریج سسٹم 2 دونوں کو دیکھتے ہیں۔ اس کے برعکس، سائٹ 2 پر میزبان سٹوریج سسٹم 2 اور سٹوریج سسٹم 1 دونوں کو دیکھتے ہیں۔ دوسرے الفاظ میں، ہر میزبان دونوں سٹوریج سسٹم کو دیکھتا ہے۔ میٹرو کلسٹر کے کام کرنے کے لیے یہ ایک شرط ہے۔
یقیناً، فائبر آپٹک کیبل کے ذریعے ہر میزبان کو دوسرے ڈیٹا سینٹر تک بڑھانے کی ضرورت نہیں ہے۔ بندرگاہوں یا کیبلز کی کوئی مقدار کافی نہیں ہوگی۔ ان تمام کنکشنز کو ایتھرنیٹ 10G+ یا FibreChannel 8G+ سوئچز کے ذریعے بنایا جانا چاہیے (FC صرف IO کے لیے میزبانوں اور سٹوریج سسٹم کو جوڑنے کے لیے؛ ریپلیکشن چینل فی الحال صرف IP (ایتھرنیٹ 10G+) کے ذریعے دستیاب ہے۔
اب نیٹ ورک ٹوپولوجی کے بارے میں چند الفاظ۔ مناسب سب نیٹ کنفیگریشن بہت ضروری ہے۔ درج ذیل ٹریفک کی اقسام کے لیے کئی ذیلی نیٹس کی وضاحت کرنا ضروری ہے:
- ایک نقل سب نیٹ، جو سٹوریج سسٹمز کے درمیان ڈیٹا کو ہم آہنگ کرے گا۔ کئی ہو سکتے ہیں، لیکن اس معاملے میں، اس سے کوئی فرق نہیں پڑتا۔ سب کچھ موجودہ (پہلے سے نافذ) نیٹ ورک ٹوپولوجی پر منحصر ہے۔ اگر دو ہیں، تو ظاہر ہے کہ ان کے درمیان روٹنگ کو ترتیب دینے کی ضرورت ہے۔
- سٹوریج سب نیٹس جن کے ذریعے میزبان سٹوریج کے وسائل تک رسائی حاصل کریں گے (اگر iSCSI)۔ ہر ڈیٹا سینٹر میں ایک ایسا سب نیٹ ہونا چاہیے۔
- مینجمنٹ سب نیٹس، یعنی تین روٹڈ سب نیٹس تین جگہوں پر جہاں سے اسٹوریج سسٹم کا انتظام کیا جاتا ہے، اور ثالث بھی وہیں واقع ہے۔
ہم یہاں میزبان وسائل تک رسائی کے لیے ذیلی نیٹس پر غور نہیں کرتے، کیونکہ وہ انتہائی کام پر منحصر ہیں۔
مختلف ٹریفک کو مختلف سب نیٹس میں الگ کرنا بہت ضروری ہے (خاص طور پر نقل کو I/O سے الگ کرنا)، کیونکہ تمام ٹریفک کو ایک ہی "موٹی" سب نیٹ میں ملانا اس کا انتظام کرنا ناممکن بنا دیتا ہے، اور دو ڈیٹا سینٹر ماحول میں، یہ مختلف قسم کے نیٹ ورک تصادم کا باعث بھی بن سکتا ہے۔ ہم اس مضمون میں اس مسئلے کی گہرائی میں نہیں جائیں گے، کیونکہ ڈیٹا سینٹرز میں پھیلے ہوئے نیٹ ورک کی منصوبہ بندی کرنا نیٹ ورک آلات بنانے والوں کے وسائل پر تفصیل سے پایا جا سکتا ہے۔
ثالث کی ترتیب
ثالث کو ICMP اور SSH کے ذریعے تمام اسٹوریج سسٹم مینجمنٹ انٹرفیس تک رسائی فراہم کی جانی چاہیے۔ ثالث کی غلطی برداشت کرنے پر بھی غور کیا جائے۔ یہاں ایک انتباہ ہے۔
ریفری فیل سیفٹی انتہائی مطلوب ہے، لیکن ضروری نہیں ہے۔ اگر ریفری غلط وقت پر کریش ہو جائے تو کیا ہوتا ہے؟
- میٹرو کلسٹر کا نارمل آپریشن تبدیل نہیں ہوگا، کیونکہ ثالث کا میٹرو کلسٹر کے نارمل آپریشن پر کوئی اثر نہیں پڑتا ہے (اس کا کام ڈیٹا سینٹرز کے درمیان بوجھ کو بروقت تبدیل کرنا ہے)۔
- مزید برآں، اگر ثالث کسی بھی وجہ سے ناکام ہوجاتا ہے اور ڈیٹا سینٹر کی ناکامی سے محروم ہوجاتا ہے، تو کوئی سوئچ اوور نہیں ہوگا کیونکہ کوئی بھی ضروری سوئچ اوور کمانڈز جاری کرنے یا کورم قائم کرنے کے قابل نہیں ہوگا۔ اس صورت میں، میٹرو کلسٹر ایک معیاری نقل کے نظام میں تبدیل ہو جائے گا، جسے کسی آفت کے دوران دستی طور پر تبدیل کرنا پڑے گا، جس کا اثر RTO پر پڑے گا۔
اس سے کیا ہوتا ہے؟ اگر واقعی کم از کم آر ٹی او کی ضرورت ہے، تو ثالث کو غلطی سے روادار ہونا چاہیے۔ اس کے لیے دو اختیارات ہیں:
- ایک ثالث کے ساتھ ایک غلطی برداشت کرنے والے ہائپر وائزر پر ایک ورچوئل مشین چلائیں، کیونکہ تمام بالغ ہائپر وائزر غلطی برداشت کرنے کی حمایت کرتے ہیں۔
- اگر آپ تیسری سائٹ (روایتی دفتر میں) پر مناسب کلسٹر انسٹال کرنے میں بہت سست ہیں اور آپ کے پاس موجودہ ہائپر وائزر کلسٹر نہیں ہے، تو ہم نے ایک ہارڈویئر ثالث کا آپشن فراہم کیا ہے، جو ایک 2U باکس میں رکھا گیا ہے جس میں دو باقاعدہ x86 سرور ہیں اور مقامی ناکامی سے بچ سکتے ہیں۔
ہم پرزور مشورہ دیتے ہیں کہ ثالث کی غلطی برداشت کو یقینی بنایا جائے، حالانکہ میٹرو کلسٹر کو عام آپریشن میں اس کی ضرورت نہیں ہے۔ تاہم، جیسا کہ تھیوری اور پریکٹس دونوں ہی ظاہر کرتے ہیں، جب واقعی قابلِ بھروسہ، تباہی برداشت کرنے والا انفراسٹرکچر بنا رہے ہیں، تو افسوس سے محفوظ رہنا بہتر ہے۔ اپنے آپ کو اور اپنے کاروبار کو "Murphy's Law" سے بچانا بہتر ہے، یعنی ثالث اور اسٹوریج سسٹم کی میزبانی کرنے والی سائٹس دونوں کی بیک وقت ناکامی سے۔
حل فن تعمیر
مندرجہ بالا ضروریات کو مدنظر رکھتے ہوئے، ہم مندرجہ ذیل عمومی حل فن تعمیر کو حاصل کرتے ہیں۔
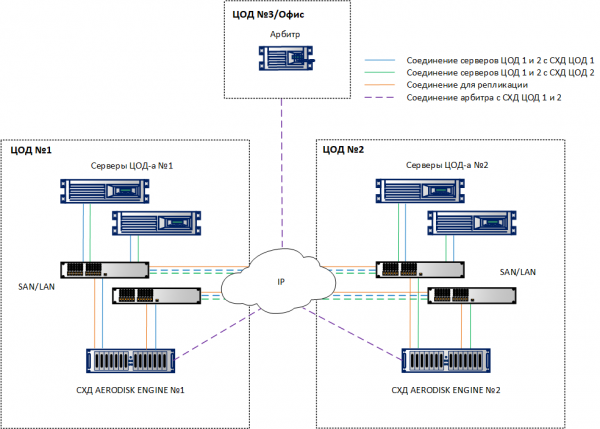
اہم اوورلوڈ سے بچنے کے لیے LUNs کو دونوں سائٹوں پر یکساں طور پر تقسیم کیا جانا چاہیے۔ ایک ہی وقت میں، دونوں ڈیٹا سینٹرز کا سائز بناتے وقت، نہ صرف صلاحیت کو دوگنا کرنے پر غور کریں (جو بیک وقت دو سٹوریج سسٹمز پر ڈیٹا کو ذخیرہ کرنے کے لیے درکار ہے)، بلکہ IOPS اور MB/s میں کارکردگی کو بھی دوگنا کریں تاکہ ایک ڈیٹا سینٹر میں ناکامی کی صورت میں ایپلیکیشن کے انحطاط کو روکا جا سکے۔
یہ بات قابل غور ہے کہ سائز کو درست کرنے کے ساتھ (یعنی بشرطیکہ ہم نے IOPS اور MB/s کے لیے مناسب اوپری حدیں فراہم کی ہوں، ساتھ ہی ساتھ ضروری CPU اور RAM وسائل بھی فراہم کیے ہوں)، اگر میٹرو کلسٹر میں موجود سٹوریج سسٹمز میں سے کوئی ایک ناکام ہو جاتا ہے، تو عارضی طور پر ایک سٹوریج سسٹم پر چلنے پر کارکردگی میں نمایاں کمی نہیں ہوگی۔
اس کی وضاحت اس حقیقت سے ہوتی ہے کہ جب دو سائٹس بیک وقت چل رہی ہوں تو ہم وقت ساز نقل لکھنے کی نصف کارکردگی کو استعمال کرتی ہے، کیونکہ ہر لین دین کو دو اسٹوریج سسٹمز (RAID-1/10 کی طرح) پر لکھا جانا چاہیے۔ لہذا، اگر سٹوریج سسٹمز میں سے کوئی ایک ناکام ہو جاتا ہے، تو نقل کا اثر عارضی طور پر ختم ہو جاتا ہے (جب تک کہ سٹوریج کا ناکام نظام بحال نہیں ہو جاتا)، اور ہمیں تحریری کارکردگی میں دو گنا اضافہ ملتا ہے۔ ناکام سٹوریج سسٹم کے LUNs کو ورکنگ سٹوریج سسٹم پر دوبارہ شروع کرنے کے بعد، یہ دوگنا اضافہ دوسرے سٹوریج سسٹم کے LUNs سے لوڈ ہونے کی وجہ سے غائب ہو جاتا ہے، اور ہم کارکردگی کی اسی سطح پر واپس آ جاتے ہیں جو "ناکامی" سے پہلے تھی لیکن اب ایک ہی سائٹ کے اندر۔
مناسب سائز کے ساتھ، آپ اس بات کو یقینی بنا سکتے ہیں کہ صارفین کو ذخیرہ کرنے کے پورے نظام کی ناکامی بالکل بھی محسوس نہیں ہوگی۔ لیکن پھر، اس کے لیے بہت محتاط سائز کی ضرورت ہوتی ہے، جس کے لیے، آپ ہم سے مفت میں رابطہ کر سکتے ہیں :-)۔
میٹرو کلسٹر کا قیام
میٹرو کلسٹر کا قیام باقاعدہ نقل ترتیب دینے کے مترادف ہے، جسے ہم نے بیان کیا ہے۔ لہذا، ہم صرف اختلافات پر توجہ مرکوز کریں گے. ہم نے اوپر دیے گئے فن تعمیر کی بنیاد پر ایک لیب سیٹ اپ ترتیب دیا، لیکن کم سے کم ترتیب میں: 10G ایتھرنیٹ کے ذریعے جڑے ہوئے دو اسٹوریج سسٹم، دو 10G سوئچز، اور ایک میزبان جو سوئچز کے ذریعے 10G پورٹس کے ذریعے دونوں اسٹوریج سسٹم تک رسائی حاصل کرتا ہے۔ ثالث ایک ورچوئل مشین پر چلتا ہے۔
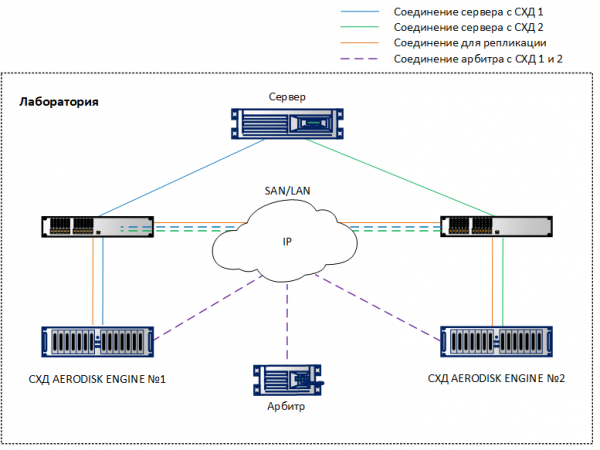
ایک نقل کے لیے ورچوئل IPs (VIPs) کو ترتیب دیتے وقت، آپ کو VIP قسم کا انتخاب کرنا چاہیے – میٹرو کلسٹر کے لیے۔
ہم نے دو LUNs کے لیے دو نقل کے لنکس بنائے اور انہیں دو اسٹوریج سسٹمز میں تقسیم کیا: LUN TEST پرائمری آن سٹوریج سسٹم 1 (METRO لنک)، LUN TEST2 پرائمری برائے اسٹوریج سسٹم 2 (METRO2 لنک)۔
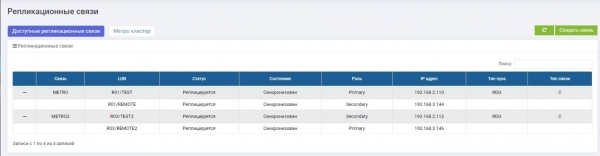
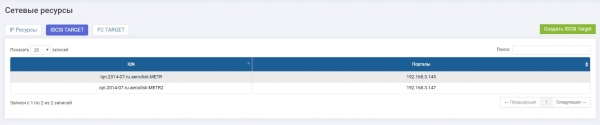
ہم نے ان کے لیے دو ایک جیسے اہداف ترتیب دیے ہیں (ہمارے معاملے میں، iSCSI، لیکن FC بھی تعاون یافتہ ہے، ترتیب کی منطق ایک جیسی ہے)۔
SHD1:

SHD2:
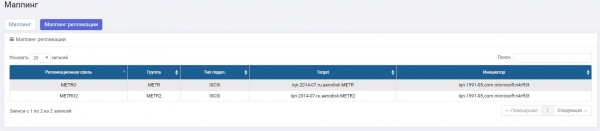
نقل کنکشن کے لیے، ہر سٹوریج سسٹم پر میپنگز بنائے گئے تھے۔
SHD1:
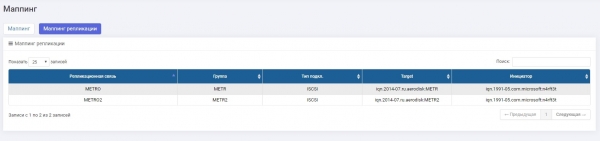
SHD2:
ہم نے ملٹی پاتھ کو ترتیب دیا اور اسے میزبان کے سامنے پیش کیا۔
ثالث مقرر کرنا
خود ثالث کے ساتھ کوئی خاص بات نہیں ہے۔ بس اسے تیسری سائٹ پر فعال کریں، اسے ایک IP پتہ تفویض کریں، اور ICMP اور SSH رسائی کو ترتیب دیں۔ کنفیگریشن خود سٹوریج سسٹم سے کی جاتی ہے۔ ثالث کو میٹرو کلسٹر میں کسی بھی سٹوریج سسٹم کنٹرولرز پر صرف ایک بار کنفیگر کرنے کی ضرورت ہے۔ یہ ترتیبات خود بخود تمام کنٹرولرز پر پھیل جائیں گی۔
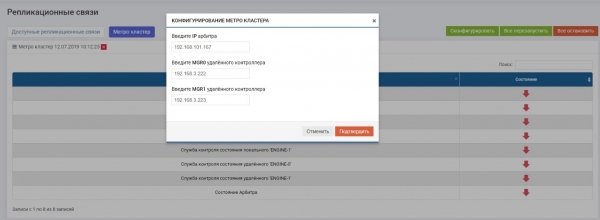
ریموٹ ریپلیکیشن سیکشن میں >> میٹرو کلسٹر (کسی بھی کنٹرولر پر) >> "کنفیگر" بٹن۔
ہم ثالث کا IP ایڈریس درج کرتے ہیں، ساتھ ہی ساتھ دو ریموٹ اسٹوریج سسٹم کنٹرولرز کے کنٹرول انٹرفیس بھی۔
اس کے بعد، آپ کو تمام خدمات کو فعال کرنے کی ضرورت ہے ("سب کو دوبارہ شروع کریں" بٹن پر کلک کریں)۔ اگر آپ کو مستقبل میں سسٹم کو دوبارہ ترتیب دینے کی ضرورت ہے، تو آپ کو ترتیبات کے اثر انداز ہونے کے لیے خدمات کو دوبارہ شروع کرنا ہوگا۔
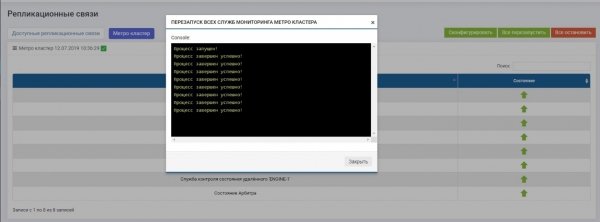
ہم چیک کرتے ہیں کہ تمام خدمات چل رہی ہیں۔
یہ میٹرو کلسٹر سیٹ اپ کو مکمل کرتا ہے۔
کریش ٹیسٹ
ہمارے معاملے میں کریش ٹیسٹ کافی آسان اور تیز ہوگا، کیونکہ نقل کی فعالیت (سوئچنگ، مستقل مزاجی، وغیرہ) پر بحث کی گئی تھی۔ لہذا، میٹرو کلسٹر کی وشوسنییتا کو جانچنے کے لیے، ہمیں صرف حادثے کا پتہ لگانے، سوئچنگ، اور تحریری نقصانات (ان پٹ/آؤٹ پٹ اسٹاپ) کی عدم موجودگی کی تصدیق کرنے کی ضرورت ہے۔
ایسا کرنے کے لیے، ہم ایک بڑی فائل کی LUN میں کاپی شروع کرنے کے بعد، اس کے دونوں کنٹرولرز کو جسمانی طور پر بند کر کے اسٹوریج سسٹم میں سے ایک کی مکمل ناکامی کی نقل کرتے ہیں، جسے دوسرے سٹوریج سسٹم پر چالو کیا جانا چاہیے۔
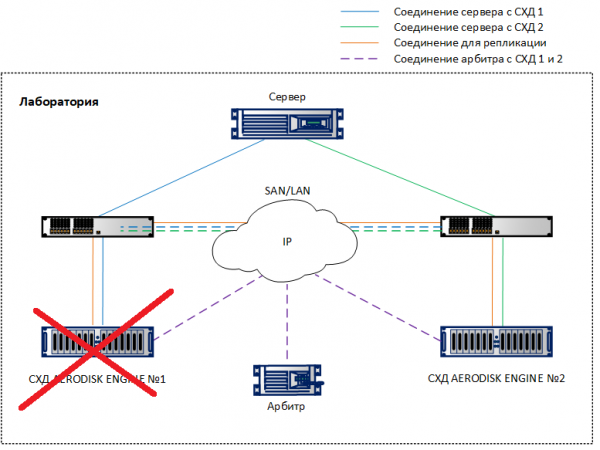
ہم نے ایک سٹوریج سسٹم بند کر دیا۔ دوسرے سٹوریج سسٹم پر، ہم انتباہات اور لاگ پیغامات دیکھتے ہیں جو اس بات کی نشاندہی کرتے ہیں کہ پڑوسی نظام سے رابطہ منقطع ہو گیا ہے۔ اگر SMTP یا SNMP نگرانی کی اطلاعات کو ترتیب دیا گیا ہے، تو منتظم کو متعلقہ اطلاعات موصول ہوں گی۔
ٹھیک 10 سیکنڈ بعد (دونوں اسکرین شاٹس میں نظر آتا ہے)، میٹرو ریپلیکشن لنک (جو ناکام اسٹوریج سسٹم پر پرائمری تھا) خود بخود ورکنگ اسٹوریج سسٹم پر پرائمری بن گیا۔ موجودہ میپنگ کا استعمال کرتے ہوئے، LUN TEST میزبان کے لیے قابل رسائی رہا۔ تحریروں میں قدرے کمی آئی (وعدہ کردہ 10 فیصد کے اندر)، لیکن اس میں کوئی خلل نہیں پڑا۔

ٹیسٹ کامیابی سے مکمل ہوا۔
مختصر کرنے کے لئے
AERODISK Engine N-series سٹوریج سسٹمز میں میٹرو کلسٹر کا موجودہ نفاذ مکمل طور پر ان چیلنجوں سے نمٹتا ہے جن کے لیے IT سروس کے ڈاؤن ٹائم کو ختم کرنے یا کم سے کم کرنے اور کم سے کم مزدوری کے اخراجات کے ساتھ 24/7/365 آپریشن کو یقینی بنانے کی ضرورت ہوتی ہے۔
بلاشبہ، آپ کہہ سکتے ہیں کہ یہ سب صرف نظریہ ہے، مثالی لیب کے حالات، اور اسی طرح... لیکن ہمارے پاس متعدد مکمل منصوبے ہیں جن میں ہم نے ڈیزاسٹر ریکوری کی فعالیت کو لاگو کیا ہے، اور سسٹم بالکل کام کر رہے ہیں۔ ہمارے معروف کلائنٹس میں سے ایک، جو تباہی کو برداشت کرنے والی ترتیب میں دو اسٹوریج سسٹم استعمال کرتا ہے، پہلے ہی اس منصوبے کے بارے میں معلومات شائع کرنے پر رضامند ہو چکا ہے، اس لیے اگلے حصے میں، ہم لائیو عمل درآمد کے بارے میں بات کریں گے۔
آپ کا شکریہ، ہم نتیجہ خیز بحث کے منتظر ہیں۔
ماخذ: www.habr.com
