


کچھ سال پہلے Kubernetes سرکاری GitHub بلاگ پر۔ تب سے، یہ خدمات کی تعیناتی کے لیے معیاری ٹیکنالوجی بن گئی ہے۔ Kubernetes اب اندرونی اور عوامی خدمات کے ایک اہم حصے کا انتظام کرتا ہے۔ جیسے جیسے ہمارے کلسٹرز بڑھتے گئے اور کارکردگی کے تقاضے مزید سخت ہوتے گئے، ہم نے یہ محسوس کرنا شروع کیا کہ Kubernetes پر کچھ سروسز وقفے وقفے سے تاخیر کا سامنا کر رہی ہیں جس کی وضاحت خود ایپلیکیشن کے بوجھ سے نہیں ہو سکتی۔
بنیادی طور پر، ایپلی کیشنز 100ms یا اس سے زیادہ کے بے ترتیب نیٹ ورک لیٹنسی کا تجربہ کرتی ہیں، جس کے نتیجے میں ٹائم آؤٹ یا دوبارہ کوششیں ہوتی ہیں۔ خدمات سے توقع کی جاتی تھی کہ وہ 100ms سے زیادہ تیزی سے درخواستوں کا جواب دے سکیں گے۔ لیکن یہ ناممکن ہے اگر کنکشن خود ہی اتنا وقت لے۔ علیحدہ طور پر، ہم نے بہت تیز MySQL سوالات کا مشاہدہ کیا جن میں ملی سیکنڈ لگنا چاہیے، اور MySQL نے ملی سیکنڈ میں مکمل کیا، لیکن درخواست کرنے والے درخواست کے نقطہ نظر سے، جواب میں 100 ms یا اس سے زیادہ کا وقت لگا۔
یہ فوری طور پر واضح ہو گیا کہ مسئلہ صرف کبرنیٹس نوڈ سے منسلک ہونے پر پیش آیا، چاہے کال کبرنیٹس کے باہر سے آئی ہو۔ مسئلہ کو دوبارہ پیدا کرنے کا سب سے آسان طریقہ ٹیسٹ میں ہے۔ ، جو کسی بھی اندرونی میزبان سے چلتا ہے، ایک مخصوص پورٹ پر Kubernetes سروس کی جانچ کرتا ہے، اور وقفے وقفے سے زیادہ تاخیر کا اندراج کرتا ہے۔ اس مضمون میں، ہم دیکھیں گے کہ ہم اس مسئلے کی وجہ کو کیسے تلاش کرنے میں کامیاب ہوئے۔
زنجیر میں غیر ضروری پیچیدگی کو ختم کرنا جو ناکامی کا باعث بنتا ہے۔
اسی مثال کو دوبارہ پیش کرتے ہوئے، ہم مسئلہ کی توجہ کو کم کرنا اور پیچیدگی کی غیر ضروری تہوں کو ہٹانا چاہتے تھے۔ ابتدائی طور پر، سبزیوں اور کبرنیٹس کی پھلیوں کے درمیان بہاؤ میں بہت زیادہ عناصر تھے۔ نیٹ ورک کے گہرے مسئلے کی نشاندہی کرنے کے لیے، آپ کو ان میں سے کچھ کو مسترد کرنے کی ضرورت ہے۔
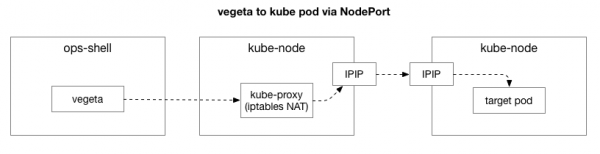
کلائنٹ (Vegeta) کلسٹر میں کسی بھی نوڈ کے ساتھ TCP کنکشن بناتا ہے۔ Kubernetes ایک اوورلے نیٹ ورک کے طور پر کام کرتا ہے (موجودہ ڈیٹا سینٹر نیٹ ورک کے اوپر) جو استعمال کرتا ہے۔ ، یعنی، یہ ڈیٹا سینٹر کے آئی پی پیکٹ کے اندر اوورلے نیٹ ورک کے آئی پی پیکٹوں کو سمیٹتا ہے۔ پہلے نوڈ سے منسلک ہونے پر، نیٹ ورک ایڈریس کا ترجمہ کیا جاتا ہے۔ (NAT) اسٹیٹفول کوبرنیٹس نوڈ کے آئی پی ایڈریس اور پورٹ کو اوورلے نیٹ ورک میں آئی پی ایڈریس اور پورٹ میں ترجمہ کرنے کے لیے (خاص طور پر، ایپلی کیشن کے ساتھ پوڈ)۔ آنے والے پیکٹوں کے لیے، اعمال کا الٹا تسلسل انجام دیا جاتا ہے۔ یہ ایک پیچیدہ نظام ہے جس میں بہت ساری ریاست اور بہت سے عناصر ہیں جو خدمات کے تعینات اور منتقل ہونے پر مسلسل اپ ڈیٹ اور تبدیل ہوتے رہتے ہیں۔
افادیت۔ tcpdump ویجیٹا ٹیسٹ میں TCP ہینڈ شیک (SYN اور SYN-ACK کے درمیان) کے دوران تاخیر ہوتی ہے۔ اس غیر ضروری پیچیدگی کو دور کرنے کے لیے آپ استعمال کر سکتے ہیں۔ hping3 SYN پیکٹ کے ساتھ سادہ "pings" کے لیے۔ ہم چیک کرتے ہیں کہ کیا رسپانس پیکٹ میں تاخیر ہوئی ہے، اور پھر کنکشن کو دوبارہ ترتیب دیں۔ ہم صرف 100ms سے بڑے پیکٹ کو شامل کرنے کے لیے ڈیٹا کو فلٹر کر سکتے ہیں اور Vegeta کے مکمل نیٹ ورک لیئر 7 ٹیسٹ کے مقابلے میں مسئلہ کو دوبارہ پیدا کرنے کا آسان طریقہ حاصل کر سکتے ہیں۔ 30927ms کے وقفوں پر سروس "نوڈ پورٹ" (10) پر TCP SYN/SYN-ACK کا استعمال کرتے ہوئے Kubernetes نوڈ "pings" ہیں، جو سب سے سست ردعمل کے ذریعے فلٹر کیے گئے ہیں:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 ms
فوری طور پر پہلا مشاہدہ کر سکتے ہیں. ترتیب نمبروں اور اوقات کو دیکھتے ہوئے، یہ واضح ہے کہ یہ ایک بار کی بھیڑ نہیں ہیں۔ تاخیر اکثر جمع ہوتی ہے اور آخر کار اس پر کارروائی کی جاتی ہے۔
اگلا، ہم یہ جاننا چاہتے ہیں کہ بھیڑ کی موجودگی میں کون سے اجزاء شامل ہو سکتے ہیں۔ ہوسکتا ہے کہ یہ NAT میں سیکڑوں iptables قواعد میں سے کچھ ہیں؟ یا نیٹ ورک پر IPIP ٹنلنگ کے ساتھ کوئی مسئلہ ہے؟ اسے چیک کرنے کا ایک طریقہ یہ ہے کہ سسٹم کے ہر قدم کو ختم کر کے اسے جانچیں۔ اگر آپ NAT اور فائر وال منطق کو ہٹاتے ہیں تو کیا ہوتا ہے، صرف IPIP حصہ چھوڑ کر:
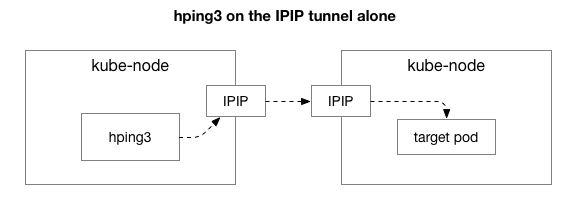
خوش قسمتی سے ، Linux اگر مشین ایک ہی نیٹ ورک پر ہے تو آپ کو براہ راست IP اوورلے پرت تک آسانی سے رسائی حاصل کرنے کی اجازت دیتا ہے:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 ms
نتائج کے مطابق، مسئلہ اب بھی باقی ہے! اس میں iptables اور NAT شامل نہیں ہیں۔ تو مسئلہ TCP ہے؟ آئیے دیکھتے ہیں کہ ایک باقاعدہ ICMP پنگ کیسے جاتا ہے:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms
نتائج ظاہر کرتے ہیں کہ مسئلہ دور نہیں ہوا ہے۔ شاید یہ ایک IPIP سرنگ ہے؟ آئیے ٹیسٹ کو مزید آسان بناتے ہیں:
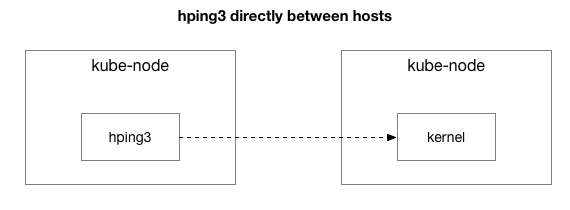
کیا تمام پیکٹ ان دو میزبانوں کے درمیان بھیجے گئے ہیں؟
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 ms
ہم نے صورتحال کو دو Kubernetes نوڈس تک آسان بنا دیا ہے جو ایک دوسرے کو کوئی بھی پیکٹ بھیجتے ہیں، یہاں تک کہ ایک ICMP پنگ۔ اگر ہدف کا میزبان "خراب" ہے (کچھ دوسروں سے بدتر) ہے تو وہ اب بھی تاخیر دیکھتے ہیں۔
اب آخری سوال: تاخیر صرف کیوب نوڈ سرورز پر ہی کیوں ہوتی ہے؟ اور کیا ایسا ہوتا ہے جب کیوب نوڈ بھیجنے والا یا وصول کنندہ ہوتا ہے؟ خوش قسمتی سے، Kubernetes کے باہر کسی میزبان کی طرف سے ایک پیکٹ بھیج کر اس کا پتہ لگانا بھی کافی آسان ہے، لیکن اسی "معروف برا" وصول کنندہ کے ساتھ۔ جیسا کہ آپ دیکھ سکتے ہیں، مسئلہ غائب نہیں ہوا ہے:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 ms
پھر ہم وہی درخواستیں پچھلے سورس کیوب نوڈ سے بیرونی میزبان کو چلائیں گے (جس میں سورس ہوسٹ شامل نہیں ہے کیونکہ پنگ میں RX اور TX دونوں شامل ہوتے ہیں):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
لیٹنسی پیکٹ کیپچرز کی جانچ کرکے، ہم نے کچھ اضافی معلومات حاصل کیں۔ خاص طور پر، کہ بھیجنے والا (نیچے) اس ٹائم آؤٹ کو دیکھتا ہے، لیکن وصول کنندہ (اوپر) نہیں دیکھتا ہے - ڈیلٹا کالم (سیکنڈ میں) دیکھیں:
اس کے علاوہ، اگر آپ وصول کنندہ کی جانب سے TCP اور ICMP پیکٹوں کی ترتیب میں فرق کو دیکھیں (تسلسل نمبر کے لحاظ سے)، ICMP پیکٹ ہمیشہ اسی ترتیب میں آتے ہیں جس میں وہ بھیجے گئے تھے، لیکن مختلف وقت کے ساتھ۔ ایک ہی وقت میں، TCP پیکٹ بعض اوقات آپس میں جڑ جاتے ہیں، اور ان میں سے کچھ پھنس جاتے ہیں۔ خاص طور پر، اگر آپ SYN پیکٹ کی بندرگاہوں کی جانچ کرتے ہیں، تو وہ بھیجنے والے کی طرف ترتیب میں ہیں، لیکن وصول کنندہ کی طرف نہیں۔
کیسے میں ایک ٹھیک ٹھیک فرق ہے جدید سرورز (جیسے ہمارے ڈیٹا سینٹر میں) TCP یا ICMP پر مشتمل پیکٹوں پر کارروائی کرتے ہیں۔ جب ایک پیکٹ آتا ہے، تو نیٹ ورک اڈاپٹر "اسے فی کنکشن ہیش کرتا ہے"، یعنی یہ کنکشن کو قطاروں میں توڑنے اور ہر قطار کو الگ پروسیسر کور پر بھیجنے کی کوشش کرتا ہے۔ TCP کے لیے، اس ہیش میں ماخذ اور منزل کا IP ایڈریس اور پورٹ دونوں شامل ہیں۔ دوسرے لفظوں میں، ہر کنکشن کو مختلف طریقے سے (ممکنہ طور پر) ہیش کیا جاتا ہے۔ ICMP کے لیے، صرف IP پتے ہیش کیے جاتے ہیں، کیونکہ وہاں کوئی بندرگاہیں نہیں ہیں۔
ایک اور نیا مشاہدہ: اس مدت کے دوران ہم دو میزبانوں کے درمیان تمام مواصلات پر ICMP میں تاخیر دیکھتے ہیں، لیکن TCP ایسا نہیں کرتا۔ یہ ہمیں بتاتا ہے کہ ممکنہ طور پر وجہ RX قطار ہیشنگ سے متعلق ہے: بھیڑ تقریبا یقینی طور پر RX پیکٹوں کی پروسیسنگ میں ہے، جوابات بھیجنے میں نہیں۔
یہ ممکنہ وجوہات کی فہرست سے پیکٹ بھیجنے کو ختم کرتا ہے۔ اب ہم جانتے ہیں کہ پیکٹ پروسیسنگ کا مسئلہ کچھ کیوب نوڈ سرورز پر وصول کرنے کی طرف ہے۔
دانا میں پیکٹ پروسیسنگ کو سمجھنا Linux
یہ سمجھنے کے لیے کہ یہ مسئلہ کچھ کیوب نوڈ سرورز پر ریسیور پر کیوں ہوتا ہے، آئیے دیکھتے ہیں کہ دانا کیسے Linux پروسیسنگ پیکٹ.
سب سے آسان روایتی عمل پر واپس آتے ہوئے، نیٹ ورک کارڈ پیکٹ وصول کرتا ہے اور بھیجتا ہے۔ بنیادی Linuxکہ ایک پیکٹ ہے جس پر کارروائی کی ضرورت ہے۔ دانا دوسرے کام کو روکتا ہے، سیاق و سباق کو انٹرپٹ ہینڈلر میں تبدیل کرتا ہے، پیکٹ پر کارروائی کرتا ہے، اور پھر موجودہ کاموں پر واپس آجاتا ہے۔
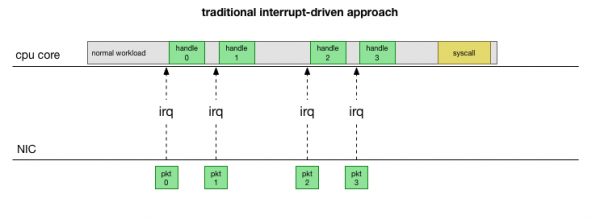
یہ سیاق و سباق سوئچنگ سست ہے: 10 کی دہائی میں 90Mbps نیٹ ورک کارڈز پر تاخیر شاید قابل توجہ نہ ہو، لیکن جدید 10G کارڈز پر زیادہ سے زیادہ 15 ملین پیکٹ فی سیکنڈ کے تھرو پٹ کے ساتھ، ایک چھوٹے سے آٹھ کور سرور کے ہر کور میں لاکھوں کی تعداد میں خلل پڑ سکتا ہے۔ فی سیکنڈ کے اوقات.
مسلسل رکاوٹوں کو سنبھالنے سے بچنے کے لیے، کئی سال پہلے میں Linux شامل کیا : نیٹ ورک API جسے تمام جدید ڈرائیور تیز رفتاری سے کارکردگی کو بہتر بنانے کے لیے استعمال کرتے ہیں۔ کم رفتار پر دانا اب بھی پرانے طریقے سے نیٹ ورک کارڈ سے رکاوٹیں وصول کرتا ہے۔ ایک بار جب کافی پیکٹ پہنچ جاتے ہیں جو حد سے تجاوز کر جاتے ہیں، دانا مداخلت کو غیر فعال کر دیتا ہے اور اس کے بجائے نیٹ ورک اڈاپٹر کو پولنگ کرنا اور ٹکڑوں میں پیکٹ اٹھانا شروع کر دیتا ہے۔ پروسیسنگ softirq میں کی جاتی ہے، یعنی in سسٹم کالز اور ہارڈویئر میں رکاوٹ کے بعد، جب دانا (صارف کی جگہ کے برعکس) پہلے سے چل رہا ہے۔
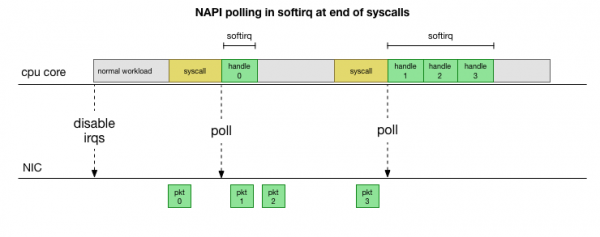
یہ بہت تیز ہے، لیکن ایک مختلف مسئلہ کا سبب بنتا ہے۔ اگر بہت سارے پیکٹ ہیں، تو پھر سارا وقت نیٹ ورک کارڈ سے پیکٹوں کی پروسیسنگ میں صرف ہوتا ہے، اور صارف کی جگہ کے عمل کے پاس ان قطاروں کو خالی کرنے کا وقت نہیں ہوتا ہے (TCP کنکشنز سے پڑھنا وغیرہ)۔ آخر کار قطاریں بھر جاتی ہیں اور ہم پیکٹ گرانے لگتے ہیں۔ بیلنس تلاش کرنے کی کوشش میں، کرنل softirq سیاق و سباق میں پروسیس شدہ پیکٹوں کی زیادہ سے زیادہ تعداد کے لیے ایک بجٹ سیٹ کرتا ہے۔ ایک بار جب یہ بجٹ حد سے زیادہ ہو جائے تو ایک الگ تھریڈ جاگ جاتا ہے۔ ksoftirqd (آپ ان میں سے ایک کو دیکھیں گے۔ ps فی کور) جو ان نرمی کو عام syscall/interrupt پاتھ سے باہر ہینڈل کرتا ہے۔ اس تھریڈ کو معیاری پراسیس شیڈیولر کا استعمال کرتے ہوئے شیڈول کیا گیا ہے، جو وسائل کو منصفانہ طور پر مختص کرنے کی کوشش کرتا ہے۔
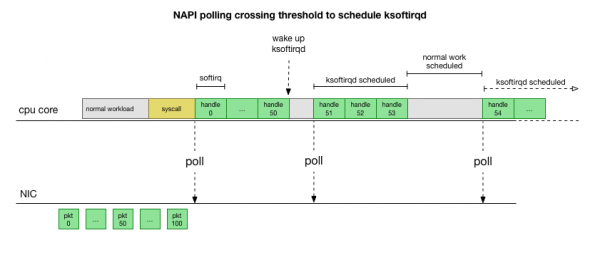
مطالعہ کرنے کے بعد کہ دانا کس طرح پیکٹوں پر کارروائی کرتا ہے، آپ دیکھ سکتے ہیں کہ بھیڑ کا ایک خاص امکان ہے۔ اگر softirq کالز کم موصول ہوتی ہیں، تو پیکٹوں کو نیٹ ورک کارڈ پر RX قطار میں کارروائی کے لیے کچھ وقت انتظار کرنا پڑے گا۔ یہ پروسیسر کور کو روکنے والے کسی کام کی وجہ سے ہو سکتا ہے، یا کوئی اور چیز کور کو softirq چلانے سے روک رہی ہے۔
پروسیسنگ کو بنیادی یا طریقہ تک محدود کرنا
Softirq میں تاخیر فی الحال صرف ایک اندازہ ہے۔ لیکن یہ سمجھ میں آتا ہے، اور ہم جانتے ہیں کہ ہم کچھ بہت ملتی جلتی چیز دیکھ رہے ہیں۔ تو اگلا مرحلہ اس نظریہ کی تصدیق کرنا ہے۔ اور اگر تصدیق ہو جائے تو تاخیر کی وجہ تلاش کریں۔
آئیے اپنے سست پیکٹوں پر واپس آتے ہیں:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms
جیسا کہ پہلے بات کی گئی ہے، یہ ICMP پیکٹ ایک واحد NIC RX قطار میں ہیش کیے جاتے ہیں اور ایک واحد CPU کور کے ذریعے کارروائی کی جاتی ہے۔ اگر ہم آپریشن کو سمجھنا چاہتے ہیں۔ Linux، یہ جاننا مفید ہے کہ کہاں (کس سی پی یو کور پر) اور کس طرح (softirq، ksoftirqd) ان پیکٹوں پر کارروائی کی جاتی ہے تاکہ عمل کو ٹریس کیا جا سکے۔
اب وقت آگیا ہے کہ ٹولز استعمال کریں جو آپ کو ریئل ٹائم میں دانا کی کارکردگی کی نگرانی کرنے کی اجازت دیتے ہیں۔ Linuxیہاں ہم نے استعمال کیا۔ . ٹولز کا یہ سیٹ آپ کو چھوٹے سی پروگرام لکھنے کی اجازت دیتا ہے جو دانا میں صوابدیدی افعال کو جوڑ دیتے ہیں اور واقعات کو صارف کی جگہ Python پروگرام میں بفر کرتے ہیں جو ان پر کارروائی کر کے نتیجہ آپ کو واپس کر سکتا ہے۔ دانا میں صوابدیدی افعال کو ہُک کرنا ایک پیچیدہ معاملہ ہے، لیکن افادیت کو زیادہ سے زیادہ تحفظ کے لیے ڈیزائن کیا گیا ہے اور اسے بالکل اسی قسم کے پروڈکشن مسائل کا پتہ لگانے کے لیے ڈیزائن کیا گیا ہے جو ٹیسٹ یا ترقی کے ماحول میں آسانی سے دوبارہ پیش نہیں کیے جاتے ہیں۔
یہاں منصوبہ آسان ہے: ہم جانتے ہیں کہ دانا ان ICMP پنگوں پر کارروائی کرتا ہے، لہذا ہم کرنل فنکشن پر ایک ہک لگائیں گے۔ ، جو آنے والے ICMP ایکو درخواست پیکٹ کو قبول کرتا ہے اور ICMP ایکو جواب بھیجنا شروع کرتا ہے۔ ہم icmp_seq نمبر کو بڑھا کر ایک پیکٹ کی شناخت کر سکتے ہیں، جو ظاہر کرتا ہے۔ hping3 اوپر
کوڈ پیچیدہ لگتا ہے، لیکن یہ اتنا خوفناک نہیں جتنا لگتا ہے۔ فنکشن icmp_echo پہنچاتا ہے struct sk_buff *skb: یہ ایک پیکٹ ہے جس میں "ایکو درخواست" ہے۔ ہم اسے ٹریک کر سکتے ہیں، ترتیب کو نکال سکتے ہیں۔ echo.sequence (جو اس کے ساتھ موازنہ کرتا ہے۔ icmp_seq hping3 کے ذریعہ выше)، اور اسے صارف کی جگہ پر بھیجیں۔ موجودہ عمل کے نام/آئی ڈی پر قبضہ کرنا بھی آسان ہے۔ ذیل میں وہ نتائج ہیں جو ہم براہ راست دیکھتے ہیں جب کرنل پیکٹوں پر کارروائی کرتا ہے:
TGID PID PROCESS NAME ICMP_seq 0 0 سویپر/11 770 0 0 سویپر/11 771 0 0 سویپر/11 772 0 0 سویپر/11 773 0 0 سویپر/11 774 20041 20086 775 0 PRO ME0W 11 سویپر/ 776 0 0 11 swapper/777 0 0 11 ترجمان-رپورٹ-s 778
یہاں یہ بات ذہن نشین رہے کہ سیاق و سباق میں softirq سسٹم کال کرنے والے عمل "عمل" کے طور پر ظاہر ہوں گے جب حقیقت میں یہ دانا ہے جو دانا کے تناظر میں پیکٹوں کو محفوظ طریقے سے پروسیس کرتا ہے۔
اس ٹول کے ذریعے ہم مخصوص عمل کو مخصوص پیکجوں کے ساتھ منسلک کر سکتے ہیں جو کہ کی تاخیر کو ظاہر کرتے ہیں۔ hping3. آئیے اسے آسان بناتے ہیں۔ grep کچھ اقدار کے لیے اس کیپچر پر icmp_seq. مندرجہ بالا icmp_seq اقدار سے مماثل پیکٹوں کو ان کے RTT کے ساتھ نوٹ کیا گیا جس کا ہم نے اوپر مشاہدہ کیا ہے (قوسین میں ان پیکٹوں کے لیے متوقع RTT ویلیوز ہیں جنہیں ہم نے RTT ویلیوز 50 ms سے کم ہونے کی وجہ سے فلٹر کیا ہے):
TGID PID PROCESS NAME ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99ms 76 76 k d11 softq / 1954 soft** q d/89 76 ** 76ms 11 1955 ksoftirqd/ 79 76 ** 76ms 11 1956 ksoftirqd/69 76 ** 76ms 11 1957 ksoftirqd/59 76 ** (76ms) 11 1958 ksoftirqd/49 76 ** (76ms) 11 ksoftirqd/1959 39ms** ksoftir qd/ 76 76 ** (11ms) 1960 29 ksoftirqd/76 76 ** (11ms) -- 1961 19 cadvisor 76 76 11 cadvisor 1962 9 10137 ksoftirqd/10436 soft2068ms /10137 10436 ** 2069ms 76 76 Ksoftirqd/11 2070 ** 75ms 76 76 KSoftirQD/11 2071 ** (65ms) 76 76 KSoftirQd/11 2072 ** (55ms) 76 76 KSoftirQd/11 2073 ** (45ms) 76 76 KSoftirQd/11 2074 ** ) 35 76 ksoftirqd/76 11 ** (2075ms)
نتائج ہمیں کئی چیزیں بتاتے ہیں۔ سب سے پہلے، ان تمام پیکجوں کو سیاق و سباق کے مطابق پروسیس کیا جاتا ہے۔ ksoftirqd/11. اس کا مطلب یہ ہے کہ مشینوں کے اس مخصوص جوڑے کے لیے، ICMP پیکٹ کو وصول کرنے والے سرے پر کور 11 پر ہیش کیا گیا تھا۔ ہم یہ بھی دیکھتے ہیں کہ جب بھی جام ہوتا ہے، وہاں ایسے پیکٹ ہوتے ہیں جو سسٹم کال کے تناظر میں پروسیس ہوتے ہیں۔ cadvisor. پھر ksoftirqd کام سنبھالتا ہے اور جمع کی گئی قطار پر کارروائی کرتا ہے: بالکل اس کے بعد جمع ہونے والے پیکٹوں کی تعداد cadvisor.
حقیقت یہ ہے کہ اس سے پہلے کہ یہ ہمیشہ کام کرتا ہے۔ cadvisor، مسئلہ میں اس کی شمولیت کا مطلب ہے۔ ستم ظریفی یہ ہے کہ مقصد - کارکردگی کا یہ مسئلہ پیدا کرنے کے بجائے "کنٹینرز چلانے کے وسائل کے استعمال اور کارکردگی کی خصوصیات کا تجزیہ کریں"۔
کنٹینرز کے دیگر پہلوؤں کی طرح، یہ تمام انتہائی جدید ٹولز ہیں اور ان سے توقع کی جا سکتی ہے کہ کچھ غیر متوقع حالات میں کارکردگی کے مسائل کا سامنا کرنا پڑے گا۔
کیڈوائزر کیا کرتا ہے جو پیکٹ کی قطار کو سست کرتا ہے؟
اب ہمیں اچھی طرح سمجھ آ گئی ہے کہ کریش کیسے ہوتا ہے، کون سا عمل اس کا سبب بن رہا ہے، اور کس سی پی یو پر۔ ہم دیکھتے ہیں کہ سخت تالے کی وجہ سے دانا Linux وقت پر منصوبہ بندی کرنے کا وقت نہیں ہے ksoftirqd. اور ہم دیکھتے ہیں کہ پیکٹ سیاق و سباق میں پروسیس ہوتے ہیں۔ cadvisor. یہ فرض کرنا منطقی ہے۔ cadvisor ایک سست سیسکال شروع کرتا ہے، جس کے بعد اس وقت جمع ہونے والے تمام پیکٹوں پر کارروائی ہوتی ہے:
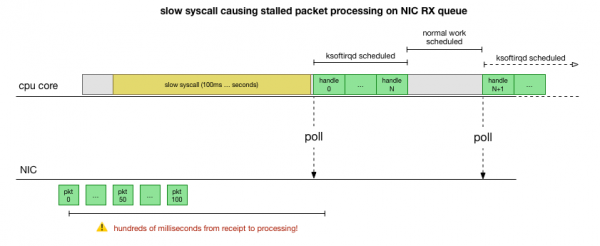
یہ ایک نظریہ ہے، لیکن اس کی جانچ کیسے کی جائے؟ اس سارے عمل میں ہم سی پی یو کور کو ٹریس کر سکتے ہیں، اس نقطہ کو تلاش کریں جہاں پیکٹس کی تعداد بجٹ سے زیادہ ہوتی ہے اور ksoftirqd کہا جاتا ہے، اور پھر تھوڑا سا پیچھے مڑ کر دیکھیں کہ اس پوائنٹ سے بالکل پہلے CPU کور پر کیا چل رہا تھا۔ . یہ ہر چند ملی سیکنڈ بعد CPU کا ایکسرے کرنے جیسا ہے۔ یہ کچھ اس طرح نظر آئے گا:
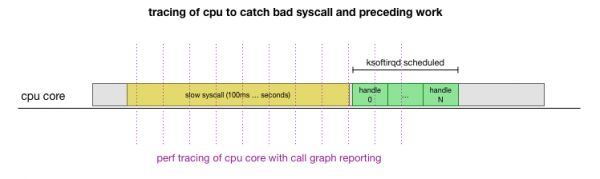
آسانی سے، یہ سب موجودہ اوزار کے ساتھ کیا جا سکتا ہے. مثال کے طور پر، ایک مخصوص فریکوئنسی پر دیئے گئے CPU کور کو چیک کرتا ہے اور چلانے والے نظام کا کال گراف بنا سکتا ہے، بشمول صارف کی جگہ اور کرنل دونوں Linuxآپ اس ریکارڈ کو لے سکتے ہیں اور پروگرام کے چھوٹے کانٹے کا استعمال کرتے ہوئے اس پر کارروائی کر سکتے ہیں۔ برینڈن گریگ سے، جو اسٹیک ٹریس کی ترتیب کو محفوظ رکھتا ہے۔ ہم ہر 1ms پر سنگل لائن اسٹیک ٹریس کو محفوظ کر سکتے ہیں، اور پھر ٹریس میں پکڑے جانے سے پہلے 100 ملی سیکنڈ کے نمونے کو نمایاں اور محفوظ کر سکتے ہیں۔ ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
نتائج یہ ہیں:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
یہاں بہت ساری چیزیں موجود ہیں، لیکن اہم بات یہ ہے کہ ہمیں "کیڈوائزر پہلے ksoftirqd" پیٹرن ملتا ہے جو ہم نے پہلے ICMP ٹریسر میں دیکھا تھا۔ اس کا کیا مطلب ہے؟
ہر لائن وقت کے ایک خاص نقطہ پر ایک CPU ٹریس ہے۔ لائن پر ہر کال ڈاون اسٹیک کو سیمی کالون سے الگ کیا جاتا ہے۔ لائنوں کے بیچ میں ہم دیکھتے ہیں کہ syscall کہا جاتا ہے: read(): .... ;do_syscall_64;sys_read; .... لہذا کیڈوائزر سسٹم کال پر بہت زیادہ وقت صرف کرتا ہے۔ read()افعال سے متعلق mem_cgroup_* (کال اسٹیک کے اوپر / لائن کے آخر میں)۔
کال ٹریس میں یہ دیکھنا تکلیف دہ ہے کہ بالکل کیا پڑھا جا رہا ہے، تو آئیے چلتے ہیں۔ strace اور آئیے دیکھتے ہیں کہ کیڈوائزر کیا کرتا ہے اور 100 ایم ایس سے زیادہ طویل سسٹم کالز تلاش کریں:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
جیسا کہ آپ توقع کر سکتے ہیں، ہم یہاں سست کالیں دیکھتے ہیں۔ read(). پڑھنے کی کارروائیوں اور سیاق و سباق کے مواد سے mem_cgroup یہ واضح ہے کہ ان چیلنجوں read() فائل کا حوالہ دیں memory.stat، جو میموری کے استعمال اور cgroup کی حدود (Docker's resource solation technology) کو ظاہر کرتا ہے۔ کیڈوائزر ٹول کنٹینرز کے لیے وسائل کے استعمال کی معلومات حاصل کرنے کے لیے اس فائل سے استفسار کرتا ہے۔ آئیے چیک کریں کہ آیا یہ دانا ہے یا کیڈوائزر کچھ غیر متوقع طور پر کر رہا ہے:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
اصلی 0m0.153s
صارف 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~$
اب ہم بگ کو دوبارہ تیار کر سکتے ہیں اور سمجھ سکتے ہیں کہ دانا Linux پیتھالوجی کا سامنا کرنا پڑتا ہے۔
پڑھنے کا عمل اتنا سست کیوں ہے؟
اس مرحلے پر، اسی طرح کے مسائل کے بارے میں دوسرے صارفین کے پیغامات تلاش کرنا بہت آسان ہے۔ جیسا کہ یہ نکلا، کیڈوائزر ٹریکر میں اس بگ کی اطلاع دی گئی تھی۔ ، یہ صرف اتنا ہے کہ کسی نے محسوس نہیں کیا کہ نیٹ ورک اسٹیک میں تاخیر بھی تصادفی طور پر ظاہر ہوتی ہے۔ یہ واقعی دیکھا گیا تھا کہ کیڈوائزر توقع سے زیادہ CPU وقت استعمال کر رہا تھا، لیکن اس کو زیادہ اہمیت نہیں دی گئی، کیونکہ ہمارے سرورز میں CPU کے بہت زیادہ وسائل ہیں، اس لیے اس مسئلے کا بغور مطالعہ نہیں کیا گیا۔
مسئلہ یہ ہے کہ cgroups نام کی جگہ (کنٹینر) کے اندر میموری کے استعمال کو مدنظر رکھتے ہیں۔ جب اس cgroup کے تمام عمل باہر نکلتے ہیں، Docker میموری cgroup کو جاری کرتا ہے۔ تاہم، "میموری" صرف پروسیس میموری نہیں ہے۔ اگرچہ پروسیس میموری خود اب استعمال نہیں ہوتی ہے، لیکن ایسا لگتا ہے کہ دانا اب بھی کیش شدہ مواد کو تفویض کرتا ہے، جیسے ڈینٹریز اور انوڈس (ڈائریکٹری اور فائل میٹا ڈیٹا)، جو میموری cgroup میں کیش ہوتے ہیں۔ مسئلہ کی تفصیل سے:
zombie cgroups: cgroups جن کا کوئی عمل نہیں ہے اور انہیں حذف کر دیا گیا ہے، لیکن پھر بھی میموری مختص ہے (میرے معاملے میں، ڈینٹری کیشے سے، لیکن اسے صفحہ کیشے یا tmpfs سے بھی مختص کیا جا سکتا ہے)۔
سی گروپ کو آزاد کرتے وقت کیش میں موجود تمام صفحات کی کرنل کی جانچ بہت سست ہوسکتی ہے، اس لیے سست عمل کا انتخاب کیا جاتا ہے: جب تک ان صفحات کی دوبارہ درخواست نہ کی جائے انتظار کریں، اور پھر آخر میں جب میموری کی ضرورت ہو تو cgroup کو صاف کریں۔ اس وقت تک، اعداد و شمار جمع کرتے وقت cgroup کو بھی مدنظر رکھا جاتا ہے۔
کارکردگی کے نقطہ نظر سے، انہوں نے کارکردگی کے لیے میموری کی قربانی دی: کچھ کیش میموری کو پیچھے چھوڑ کر ابتدائی صفائی کو تیز کرنا۔ یہ ٹھیک ہے. جب دانا آخری کیش شدہ میموری کا استعمال کرتا ہے، تو cgroup بالآخر صاف ہو جاتا ہے، اس لیے اسے "لیک" نہیں کہا جا سکتا۔ بدقسمتی سے، تلاش کے طریقہ کار کے مخصوص نفاذ memory.stat اس کرنل ورژن (4.9) میں، ہمارے سرورز پر میموری کی بڑی مقدار کے ساتھ مل کر، اس کا مطلب ہے کہ تازہ ترین کیشڈ ڈیٹا کو بحال کرنے اور سی گروپ زومبی کو صاف کرنے میں زیادہ وقت لگتا ہے۔
یہ پتہ چلتا ہے کہ ہمارے کچھ نوڈس میں اتنے سی گروپ زومبی تھے کہ پڑھنے اور تاخیر ایک سیکنڈ سے زیادہ ہوگئی۔
کیڈوائزر کے مسئلے کا حل یہ ہے کہ پورے سسٹم میں فوری طور پر ڈینٹریز/انوڈس کیشز کو آزاد کیا جائے، جو فوری طور پر پڑھنے میں تاخیر کے ساتھ ساتھ میزبان پر نیٹ ورک لیٹنسی کو بھی ختم کر دیتا ہے، کیونکہ کیش کو صاف کرنے سے کیش شدہ زومبی سی گروپ کے صفحات آن ہو جاتے ہیں اور انہیں بھی آزاد کر دیا جاتا ہے۔ یہ ایک حل نہیں ہے، لیکن یہ مسئلہ کی وجہ کی تصدیق کرتا ہے.
معلوم ہوا کہ کرنل کے نئے ورژن (4.19+) میں کال کی کارکردگی بہتر ہوئی تھی۔ memory.stat، تو اس دانا پر سوئچ کرنے سے مسئلہ حل ہوگیا۔ ایک ہی وقت میں، ہمارے پاس Kubernetes کلسٹرز میں دشواری والے نوڈس کا پتہ لگانے، ان کو خوبصورتی سے نکالنے اور دوبارہ شروع کرنے کے لیے ٹولز تھے۔ ہم نے تمام کلسٹرز کو کنگھی کیا، کافی زیادہ تاخیر کے ساتھ نوڈس ملے اور انہیں دوبارہ شروع کیا۔ اس سے ہمیں باقی سرورز پر OS کو اپ ڈیٹ کرنے کا وقت ملا۔
اپ میزانی
کیونکہ اس بگ نے سینکڑوں ملی سیکنڈز کے لیے RX NIC قطار کی پروسیسنگ کو روک دیا، اس لیے اس نے بیک وقت مختصر کنکشنز اور درمیانی کنکشن لیٹنسی، جیسے MySQL کی درخواستوں اور رسپانس پیکٹوں کے درمیان زیادہ تاخیر کا باعث بنا۔
سب سے بنیادی نظاموں کی کارکردگی کو سمجھنا اور برقرار رکھنا، جیسا کہ Kubernetes، ان پر مبنی تمام خدمات کی وشوسنییتا اور رفتار کے لیے اہم ہے۔ ہر وہ سسٹم جسے آپ چلاتے ہیں Kubernetes کی کارکردگی میں بہتری سے فائدہ اٹھاتے ہیں۔
ماخذ: www.habr.com
