

تصور کریں: آپ ایک بڑے شاپنگ سینٹر کے آئی ٹی انفراسٹرکچر کی خدمت کر رہے ہیں۔ شہر میں بارش شروع ہو جاتی ہے۔ بارش کی نہریں چھت کو توڑ دیتی ہیں، ریٹیل احاطے میں پانی ٹخنوں تک بھر جاتا ہے۔ ہم امید کرتے ہیں کہ آپ کا سرور روم تہہ خانے میں نہیں ہے، ورنہ مسائل سے بچا نہیں جا سکتا۔
بیان کی گئی کہانی کوئی خیالی نہیں بلکہ 2020 کے چند واقعات کی اجتماعی تفصیل ہے۔ بڑی کمپنیوں میں، ڈیزاسٹر ریکوری پلان (DRP) اس کیس کے لیے ہمیشہ ہاتھ میں ہوتا ہے۔ کارپوریشنز میں، یہ کاروباری تسلسل کے ماہرین کی ذمہ داری ہے۔ لیکن درمیانی اور چھوٹی کمپنیوں میں، اس طرح کے مسائل کو حل کرنا آئی ٹی خدمات پر آتا ہے۔ آپ کو کاروباری منطق کو خود سمجھنا ہوگا، سمجھنا ہوگا کہ کیا ناکام ہوسکتا ہے اور کہاں، تحفظ کے ساتھ آئیں اور اسے نافذ کریں۔
یہ بہت اچھا ہے اگر کوئی IT ماہر کاروبار کے ساتھ گفت و شنید کر سکے اور تحفظ کی ضرورت پر بات کر سکے۔ لیکن میں نے ایک سے زیادہ بار دیکھا ہے کہ کس طرح ایک کمپنی نے ڈیزاسٹر ریکوری (DR) کے حل میں کوتاہی کی کیونکہ اس نے اسے بے کار سمجھا۔ جب ایک حادثہ پیش آیا، ایک طویل وصولی سے نقصان کا خطرہ تھا، اور کاروبار تیار نہیں تھا۔ آپ جتنا چاہیں دہرا سکتے ہیں: "میں نے آپ کو ایسا کہا تھا" لیکن IT سروس کو پھر بھی خدمات بحال کرنی ہوں گی۔

ایک معمار کی حیثیت سے، میں آپ کو بتاؤں گا کہ اس صورتحال سے کیسے بچا جائے۔ مضمون کے پہلے حصے میں، میں تیاری کا کام دکھاؤں گا: سیکیورٹی ٹولز کے انتخاب کے لیے گاہک کے ساتھ تین سوالات پر کیسے تبادلہ خیال کیا جائے:
- ہم کس چیز کی حفاظت کر رہے ہیں؟
- ہم کس چیز سے بچ رہے ہیں؟
- ہم کتنی حفاظت کرتے ہیں؟
دوسرے حصے میں، ہم اس سوال کا جواب دینے کے اختیارات کے بارے میں بات کریں گے: اپنا دفاع کیسے کریں۔ میں ان معاملات کی مثالیں دوں گا کہ کس طرح مختلف گاہک اپنا تحفظ تیار کرتے ہیں۔
ہم کس چیز کی حفاظت کرتے ہیں: اہم کاروباری افعال کی نشاندہی کرنا
بہتر ہے کہ کاروباری کسٹمر کے ساتھ ایمرجنسی کے بعد کے ایکشن پلان پر بات کر کے تیاری شروع کر دیں۔ یہاں سب سے بڑی مشکل ایک عام زبان تلاش کرنا ہے۔ گاہک کو عام طور پر اس بات کی پرواہ نہیں ہوتی کہ آئی ٹی حل کیسے کام کرتا ہے۔ وہ اس بات کی پرواہ کرتا ہے کہ آیا یہ سروس کاروباری کام انجام دے سکتی ہے اور پیسہ لا سکتی ہے۔ مثال کے طور پر: اگر سائٹ کام کر رہی ہے، لیکن ادائیگی کا نظام بند ہے، کلائنٹس سے کوئی آمدنی نہیں ہے، اور "انتہا پسند" اب بھی آئی ٹی کے ماہر ہیں۔
ایک آئی ٹی پروفیشنل کو کئی وجوہات کی بنا پر اس طرح کے مذاکرات میں دشواری ہو سکتی ہے:
- آئی ٹی سروس کاروبار میں انفارمیشن سسٹم کے کردار کو پوری طرح نہیں سمجھتی ہے۔ مثال کے طور پر، اگر کاروباری عمل یا شفاف کاروباری ماڈل کی کوئی تفصیل دستیاب نہیں ہے۔
- پورا عمل آئی ٹی سروس پر منحصر نہیں ہے۔ مثال کے طور پر، جب کام کا کچھ حصہ ٹھیکیدار انجام دیتے ہیں، اور آئی ٹی ماہرین کا ان پر براہ راست اثر نہیں ہوتا ہے۔
میں گفتگو کو اس طرح بناؤں گا:
- ہم کاروباروں کو بتاتے ہیں کہ حادثات ہر ایک کے ساتھ ہوتے ہیں، اور بحالی میں وقت لگتا ہے۔ سب سے اچھی بات یہ ہے کہ حالات کا مظاہرہ کیا جائے، یہ کیسے ہوتا ہے اور اس کے کیا نتائج ممکن ہیں۔
- ہم یہ ظاہر کرتے ہیں کہ ہر چیز کا انحصار IT سروس پر نہیں ہے، لیکن آپ اپنی ذمہ داری کے علاقے میں ایکشن پلان میں مدد کے لیے تیار ہیں۔
- ہم کاروباری گاہک سے جواب طلب کرتے ہیں: اگر apocalypse ہوتا ہے تو پہلے کون سا عمل بحال کیا جانا چاہیے؟ اس میں کون اور کیسے شریک ہے؟
کاروبار سے ایک آسان جواب درکار ہے، مثال کے طور پر: کال سینٹر کو 24/7 درخواستیں رجسٹر کرنا جاری رکھنے کی ضرورت ہے۔
- ہم سسٹم کے ایک یا دو صارفین سے اس عمل کو تفصیل سے بیان کرنے کو کہتے ہیں۔
اگر آپ کی کمپنی کے پاس ہے تو مدد کرنے کے لیے کسی تجزیہ کار کو شامل کرنا بہتر ہے۔شروع کرنے کے لیے، تفصیل اس طرح نظر آ سکتی ہے: کال سینٹر کو فون، میل اور ویب سائٹ سے پیغامات کے ذریعے درخواستیں موصول ہوتی ہیں۔ پھر وہ انہیں ویب انٹرفیس کے ذریعے 1C میں داخل کرتا ہے، اور پیداوار انہیں وہاں سے اس طرح لے جاتی ہے۔
- پھر ہم دیکھتے ہیں کہ کون سے ہارڈ ویئر اور سافٹ ویئر کے حل اس عمل کی حمایت کرتے ہیں۔ جامع تحفظ کے لیے، ہم تین سطحوں کو مدنظر رکھتے ہیں:
- سائٹ کے اندر ایپلی کیشنز اور سسٹمز (سافٹ ویئر لیول)،
- وہ سائٹ جہاں سسٹم چلتے ہیں (انفراسٹرکچر لیول)
- نیٹ ورک (وہ اکثر اس کے بارے میں بھول جاتے ہیں)۔
- ہم ناکامی کے ممکنہ نکات کی نشاندہی کرتے ہیں: سسٹم نوڈس جن پر سروس کا عمل انحصار کرتا ہے۔ ہم دیگر کمپنیوں کے تعاون یافتہ نوڈس کی بھی نشاندہی کرتے ہیں، جیسے ٹیلی کام آپریٹرز، ہوسٹنگ فراہم کرنے والے، ڈیٹا سینٹرز، وغیرہ۔ اس کو ذہن میں رکھتے ہوئے، آپ اگلے مرحلے کے لیے کاروباری صارف کے پاس واپس جا سکتے ہیں۔
ہم کس چیز سے بچاتے ہیں: خطرات
اس کے بعد، ہم کاروباری گاہک سے معلوم کرتے ہیں کہ ہم پہلے کن خطرات سے خود کو بچاتے ہیں۔ تمام خطرات کو دو گروہوں میں تقسیم کیا جا سکتا ہے:
- سروس بند ہونے کی وجہ سے وقت کا نقصان؛
- جسمانی اثرات، انسانی عوامل وغیرہ کی وجہ سے ڈیٹا کا نقصان۔
کاروبار ڈیٹا اور وقت دونوں کو کھونے سے ڈرتے ہیں - یہ سب پیسے کے نقصان کی طرف جاتا ہے۔ لہذا ہم ایک بار پھر ہر خطرے والے گروپ سے سوالات پوچھتے ہیں:
- اس عمل کے لیے، کیا ہم اندازہ لگا سکتے ہیں کہ پیسے میں ڈیٹا کا کتنا نقصان اور وقت ضائع ہوتا ہے؟
- ہم کون سا ڈیٹا کھو نہیں سکتے؟
- ہم کہاں بند ہونے کی اجازت نہیں دے سکتے ہیں؟
- کون سے واقعات ہمارے لیے سب سے زیادہ امکان اور سب سے زیادہ خطرہ ہیں؟
بحث کے بعد، ہم سمجھیں گے کہ ناکامی کے نکات کو کس طرح ترجیح دی جائے۔
ہم کتنی حفاظت کرتے ہیں: RPO اور RTO
جب ناکامی کے اہم نکات واضح ہوتے ہیں، تو ہم RTO اور RPO اشارے کا حساب لگاتے ہیں۔
میں آپ کو اس کی یاد دلانے دیتا ہوں آر ٹی او (ریکوری ٹائم مقصد) - یہ حادثے کے لمحے سے سروس کے مکمل طور پر بحال ہونے تک قابل اجازت وقت ہے۔ کاروباری زبان میں، یہ قابل قبول ڈاون ٹائم ہے۔ اگر ہم جانتے ہیں کہ اس عمل میں کتنی رقم آئی ہے، تو ہم ڈاؤن ٹائم کے ہر منٹ سے نقصانات کا حساب لگا سکتے ہیں اور قابل قبول نقصان کا حساب لگا سکتے ہیں۔
آر پی او (ریکوری پوائنٹ مقصد) - درست ڈیٹا ریکوری پوائنٹ۔ یہ اس وقت کا تعین کرتا ہے جس کے دوران ہم ڈیٹا کھو سکتے ہیں۔ کاروباری نقطہ نظر سے، ڈیٹا کے نقصان کے نتیجے میں جرمانہ ہو سکتا ہے، مثال کے طور پر۔ ایسے نقصانات کو رقم میں بھی تبدیل کیا جا سکتا ہے۔
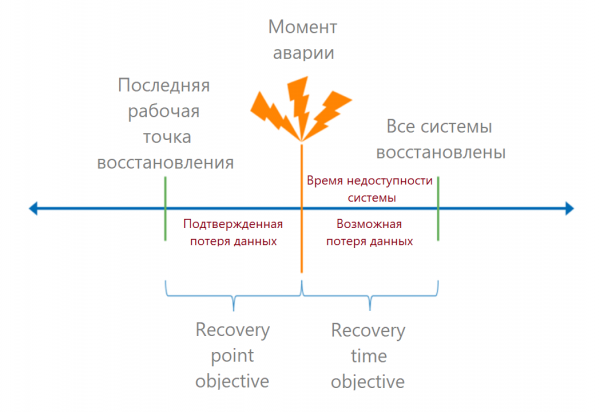
آخری صارف کے لیے وصولی کے وقت کا حساب لگانے کی ضرورت ہے: وہ کتنی دیر تک سسٹم میں لاگ ان ہو سکے گا۔ تو پہلے ہم سلسلہ میں موجود تمام لنکس کے ریکوری ٹائم کو شامل کرتے ہیں۔ یہاں اکثر غلطی ہوتی ہے: وہ فراہم کنندہ کا RTO SLA سے لیتے ہیں، اور باقی شرائط کو بھول جاتے ہیں۔
آئیے ایک مخصوص مثال کو دیکھتے ہیں۔ صارف 1C میں لاگ ان ہوتا ہے، سسٹم ڈیٹا بیس کی خرابی کے ساتھ کھلتا ہے۔ وہ سسٹم ایڈمنسٹریٹر سے رابطہ کرتا ہے۔ ڈیٹا بیس کلاؤڈ میں واقع ہے، سسٹم ایڈمنسٹریٹر سروس فراہم کرنے والے کو مسئلہ کی اطلاع دیتا ہے۔ ہم کہتے ہیں کہ تمام مواصلات میں 15 منٹ لگتے ہیں۔ کلاؤڈ میں، اس سائز کا ڈیٹا بیس ایک گھنٹے میں بیک اپ سے بحال ہو جائے گا، لہذا، سروس فراہم کرنے والے کی طرف RTO ایک گھنٹہ ہے۔ لیکن صارف کے لیے یہ آخری تاریخ نہیں ہے، مسئلہ کا پتہ لگانے کے لیے اس میں 15 منٹ کا اضافہ کیا گیا ہے۔
اس کے بعد، سسٹم ایڈمنسٹریٹر کو چیک کرنے کی ضرورت ہے کہ ڈیٹا بیس درست ہے، اسے 1C سے جوڑیں اور خدمات شروع کریں۔ اس کے لیے مزید ایک گھنٹہ درکار ہے، جس کا مطلب ہے کہ منتظم کی طرف سے RTO پہلے ہی 2 گھنٹے 15 منٹ کا ہے۔ صارف کو مزید 15 منٹ درکار ہیں: لاگ ان کریں، چیک کریں کہ ضروری لین دین ظاہر ہوا ہے۔ اس مثال میں 2 گھنٹے 30 منٹ سروس کی بحالی کا کل وقت ہے۔
یہ حسابات کاروبار کو ظاہر کریں گے کہ بحالی کی مدت کن بیرونی عوامل پر منحصر ہے۔ مثال کے طور پر، اگر دفتر میں سیلاب آ گیا ہے، تو آپ کو سب سے پہلے لیک کو تلاش کرنے اور اسے ٹھیک کرنے کی ضرورت ہے۔ اس میں وقت لگے گا، جس کا انحصار آئی ٹی پر نہیں ہے۔
ہم کس طرح حفاظت کرتے ہیں: مختلف خطرات کے لیے آلات کا انتخاب
تمام نکات پر بحث کرنے کے بعد، گاہک پہلے ہی کاروبار کے لیے کسی حادثے کی قیمت کو سمجھتا ہے۔ اب آپ ٹولز کا انتخاب کر سکتے ہیں اور بجٹ پر بحث کر سکتے ہیں۔ کلائنٹ کیسز کی مثالیں استعمال کرتے ہوئے، میں آپ کو دکھاؤں گا کہ ہم مختلف کاموں کے لیے کون سے ٹولز پیش کرتے ہیں۔
آئیے خطرات کے پہلے گروپ سے شروع کرتے ہیں: سروس بند ہونے کی وجہ سے ہونے والے نقصانات۔ اس مسئلے کے حل کے لیے اچھا RTO فراہم کرنا چاہیے۔
- کلاؤڈ میں ایپلیکیشن کی میزبانی کریں۔
شروع کرنے کے لئے، آپ آسانی سے کلاؤڈ پر جا سکتے ہیں - فراہم کنندہ نے پہلے ہی اعلی دستیابی کے مسائل کے بارے میں سوچا ہے. ورچوئلائزیشن ہوسٹس کو ایک کلسٹر میں جمع کیا جاتا ہے، پاور اور نیٹ ورک کو محفوظ کیا جاتا ہے، ڈیٹا کو غلطی سے برداشت کرنے والے سٹوریج سسٹم پر محفوظ کیا جاتا ہے، اور سروس فراہم کرنے والا مالی طور پر ڈاؤن ٹائم کے لیے ذمہ دار ہوتا ہے۔
مثال کے طور پر، آپ کلاؤڈ میں ڈیٹا بیس کے ساتھ ایک ورچوئل مشین کی میزبانی کر سکتے ہیں۔ ایپلیکیشن ایک قائم چینل کے ذریعے یا اسی کلاؤڈ سے بیرونی طور پر ڈیٹا بیس سے جڑے گی۔ اگر کلسٹر میں سرورز میں سے کسی ایک کے ساتھ مسائل پیدا ہوتے ہیں، تو VM پڑوسی سرور پر 2 منٹ سے بھی کم وقت میں دوبارہ شروع ہو جائے گا۔ اس کے بعد، اس میں DBMS شروع ہو جائے گا، اور چند منٹوں میں ڈیٹا بیس دستیاب ہو جائے گا۔
RTO: منٹوں میں ناپا جاتا ہے۔ یہ شرائط فراہم کنندہ کے ساتھ معاہدے میں بیان کی جا سکتی ہیں۔
قیمت: ہم آپ کی درخواست کے لیے کلاؤڈ وسائل کی لاگت کا حساب لگاتے ہیں۔
جس سے یہ آپ کی حفاظت نہیں کرے گا۔: فراہم کنندہ کی سائٹ پر بڑے پیمانے پر ناکامیوں سے، مثال کے طور پر، شہر کی سطح پر حادثات کی وجہ سے۔ - درخواست کو کلسٹر کریں۔
اگر آپ RTO کو بہتر بنانا چاہتے ہیں، تو آپ پچھلے آپشن کو مضبوط کر سکتے ہیں اور فوری طور پر کلسٹرڈ ایپلیکیشن کو کلاؤڈ میں رکھ سکتے ہیں۔
آپ فعال-غیر فعال یا فعال-فعال موڈ میں ایک کلسٹر کو لاگو کر سکتے ہیں. ہم وینڈر کی ضروریات کی بنیاد پر کئی VMs بناتے ہیں۔ زیادہ وشوسنییتا کے لیے، ہم انہیں مختلف سرورز اور اسٹوریج سسٹمز میں تقسیم کرتے ہیں۔ اگر سرور میں سے کسی ایک ڈیٹا بیس کے ساتھ ناکام ہو جاتا ہے، تو بیک اپ نوڈ چند سیکنڈوں میں بوجھ لے لیتا ہے۔
RTO: سیکنڈوں میں ماپا گیا۔
قیمت: ایک باقاعدہ کلاؤڈ سے تھوڑا زیادہ مہنگا، کلسٹرنگ کے لیے اضافی وسائل درکار ہوں گے۔
جس سے یہ آپ کی حفاظت نہیں کرے گا۔: پھر بھی سائٹ پر ہونے والی بڑی ناکامیوں سے حفاظت نہیں کرے گا۔ لیکن مقامی رکاوٹیں زیادہ دیر تک نہیں رہیں گی۔مشق سے: خوردہ کمپنی کے پاس کئی معلوماتی نظام اور ویب سائٹس تھیں۔ تمام ڈیٹا بیس مقامی طور پر کمپنی کے دفتر میں موجود تھے۔ کسی بھی DR کے بارے میں نہیں سوچا گیا جب تک کہ دفتر کو لگاتار کئی بار بجلی کے بغیر چھوڑ دیا گیا۔ صارفین ویب سائٹ کے کریش ہونے سے ناخوش تھے۔
سروس کی دستیابی کا مسئلہ کلاؤڈ پر جانے کے بعد حل ہو گیا۔ اس کے علاوہ، ہم نوڈس کے درمیان ٹریفک کو متوازن کرکے ڈیٹا بیس پر بوجھ کو بہتر بنانے میں کامیاب ہوگئے۔ - ڈیزاسٹر پروف کلاؤڈ پر جائیں۔
اگر آپ کو یہ یقینی بنانا ہے کہ مرکزی سائٹ پر قدرتی آفت بھی آپ کے کام میں مداخلت نہیں کرتی ہے، تو آپ تباہی سے بچنے والے کلاؤڈ کا انتخاب کر سکتے ہیں، اس آپشن میں فراہم کنندہ ورچوئلائزیشن کلسٹر کو 2 ڈیٹا سینٹرز میں پھیلا دیتا ہے۔ ڈیٹا سینٹرز کے درمیان مستقل مطابقت پذیر نقل ہوتی ہے، ایک سے ایک۔ ڈیٹا سینٹرز کے درمیان چینلز محفوظ ہیں اور مختلف راستوں کے ساتھ جاتے ہیں، لہذا اس طرح کے کلسٹر نیٹ ورک کے مسائل سے خوفزدہ نہیں ہیں.
RTO: 0 پر ہوتا ہے۔
قیمت: سب سے مہنگا کلاؤڈ آپشن۔
جس سے یہ آپ کی حفاظت نہیں کرے گا۔: یہ ڈیٹا بدعنوانی کے ساتھ ساتھ انسانی عنصر سے بھی مدد نہیں کرے گا، اس لیے بیک اپ بنانے کی سفارش کی جاتی ہے۔مشق سے: ہمارے کلائنٹس میں سے ایک نے تباہی کی بحالی کا ایک جامع منصوبہ تیار کیا۔ یہ وہ حکمت عملی ہے جس کا اس نے انتخاب کیا:
- تباہی برداشت کرنے والا کلاؤڈ ایپلیکیشن کو انفراسٹرکچر کی سطح پر ناکامیوں سے بچاتا ہے۔
- دو سطحی بیک اپ انسانی غلطی کی صورت میں تحفظ فراہم کرتا ہے۔ بیک اپ کی دو قسمیں ہیں: "سرد" اور "گرم"۔ ایک "کولڈ" بیک اپ غیر فعال حالت میں ہے اور اسے تعینات کرنے میں وقت لگتا ہے۔ ایک "ہاٹ" بیک اپ پہلے ہی استعمال کے لیے تیار ہے اور تیزی سے بحال ہو جاتا ہے۔ یہ خاص طور پر وقف شدہ اسٹوریج سسٹم میں محفوظ ہے۔ تیسری کاپی ٹیپ پر ریکارڈ کی جاتی ہے اور دوسرے کمرے میں محفوظ کی جاتی ہے۔
ہفتے میں ایک بار، کلائنٹ تحفظ کی جانچ کرتا ہے اور تمام بیک اپ کی فعالیت کو چیک کرتا ہے، بشمول ٹیپ سے۔ ہر سال کمپنی تباہی سے بچنے والے کلاؤڈ کی جانچ کرتی ہے۔
- دوسری سائٹ پر نقل ترتیب دیں۔
مرکزی سائٹ پر عالمی مسائل سے بچنے کے بارے میں ایک اور آپشن: جیو ریزرویشن فراہم کریں۔ دوسرے لفظوں میں، دوسرے شہر میں کسی سائٹ پر بیک اپ ورچوئل مشینیں بنائیں۔ DR کے لیے خصوصی حل اس کے لیے موزوں ہیں: ہماری کمپنی میں ہم VMware vCloud Availability (vCAV) استعمال کرتے ہیں۔ اس کی مدد سے، آپ کلاؤڈ فراہم کرنے والی متعدد سائٹوں کے درمیان تحفظ کو ترتیب دے سکتے ہیں یا آن پریمائز سائٹ سے کلاؤڈ پر بحال کر سکتے ہیں۔ میں پہلے ہی vCAV کے ساتھ کام کرنے کی اسکیم کے بارے میں مزید تفصیل سے بات کر چکا ہوں۔ .
آر پی او اور آر ٹی او: 5 منٹ سے۔
قیمت: پہلے آپشن سے زیادہ مہنگا، لیکن ڈیزاسٹر پروف کلاؤڈ میں ہارڈ ویئر کی نقل سے سستا ہے۔ قیمت vCAV لائسنس کی قیمت، انتظامیہ کی فیس، کلاؤڈ وسائل کی لاگت اور PAYG ماڈل کے مطابق ریزرو وسائل پر مشتمل ہے (سوئچڈ آف VMs کے لیے کام کرنے والے وسائل کی لاگت کا 10%)۔
مشق سے: کلائنٹ نے ماسکو میں ہمارے کلاؤڈ میں مختلف ڈیٹا بیس کے ساتھ 6 ورچوئل مشینیں رکھی تھیں۔ سب سے پہلے، بیک اپ کے ذریعے تحفظ فراہم کیا گیا تھا: کچھ بیک اپ کاپیاں ماسکو میں کلاؤڈ میں محفوظ کی گئی تھیں، اور کچھ ہماری سینٹ پیٹرزبرگ سائٹ پر محفوظ کی گئی تھیں۔ وقت کے ساتھ، ڈیٹا بیس کا سائز بڑھتا گیا، اور بیک اپ سے بحال ہونے میں زیادہ وقت لگنے لگا۔
VMware vCloud دستیابی پر مبنی نقل کو بیک اپ میں شامل کیا گیا تھا۔ ورچوئل مشینوں کی نقلیں سینٹ پیٹرزبرگ میں بیک اپ سائٹ پر محفوظ کی جاتی ہیں اور ہر 5 منٹ بعد اپ ڈیٹ ہوتی ہیں۔ اگر مرکزی سائٹ پر کوئی ناکامی واقع ہوتی ہے تو، ملازمین آزادانہ طور پر سینٹ پیٹرزبرگ میں ورچوئل مشین کی نقل پر سوئچ کرتے ہیں اور اس کے ساتھ کام جاری رکھتے ہیں۔
زیر غور تمام حل اعلیٰ دستیابی فراہم کرتے ہیں، لیکن رینسم ویئر وائرس یا ملازم کی حادثاتی غلطی کی وجہ سے ڈیٹا کے نقصان سے تحفظ نہیں دیتے۔ اس صورت میں، ہمیں بیک اپ کی ضرورت ہوگی جو مطلوبہ آر پی او فراہم کرے گی۔
5. بیک اپ کے بارے میں مت بھولنا
ہر کوئی جانتا ہے کہ آپ کو بیک اپ بنانے کی ضرورت ہے، یہاں تک کہ اگر آپ کے پاس ڈیزاسٹر پروف حل موجود ہے۔ اس لیے میں آپ کو مختصراً چند نکات یاد دلاؤں گا۔
سختی سے بولیں، بیک اپ DR نہیں ہے۔ اور اسی لیے:
- یہ ایک طویل وقت ہے. اگر ڈیٹا کو ٹیرا بائٹس میں ماپا جاتا ہے، تو بازیافت میں ایک گھنٹے سے زیادہ وقت لگے گا۔ آپ کو بحال کرنے، نیٹ ورک تفویض کرنے، چیک کرنے کی ضرورت ہے کہ یہ آن ہوتا ہے، دیکھیں کہ ڈیٹا ترتیب میں ہے۔ اس لیے اچھا آر ٹی او فراہم کرنا تب ہی ممکن ہے جب بہت کم ڈیٹا ہو۔
- ڈیٹا پہلی بار بحال نہیں ہوسکتا ہے، اور آپ کو کارروائی کو دہرانے کے لیے وقت دینا ہوگا۔ مثال کے طور پر، ایسے اوقات ہوتے ہیں جب ہم بالکل نہیں جانتے کہ ڈیٹا کب ضائع ہوا تھا۔ ہم کہتے ہیں کہ نقصان 15.00 بجے محسوس کیا گیا تھا، اور ہر گھنٹے کی کاپیاں بنائی جاتی ہیں۔ 15.00 سے ہم تمام ریکوری پوائنٹس کو دیکھتے ہیں: 14:00، 13:00 اور اسی طرح۔ اگر نظام اہم ہے، تو ہم ریکوری پوائنٹ کی عمر کو کم سے کم کرنے کی کوشش کرتے ہیں۔ لیکن اگر تازہ بیک اپ میں ضروری ڈیٹا شامل نہیں تھا، تو ہم اگلا نقطہ لیتے ہیں - یہ اضافی وقت ہے۔
اس صورت میں، بیک اپ شیڈول مطلوبہ فراہم کر سکتا ہے آر پی او. بیک اپ کے لیے، اہم سائٹ کے ساتھ مسائل کی صورت میں جیو ریزرویشن فراہم کرنا ضروری ہے۔ کچھ بیک اپ کاپیاں الگ سے ذخیرہ کرنے کی سفارش کی جاتی ہے۔
ڈیزاسٹر ریکوری پلان میں کم از کم 2 ٹولز ہونے چاہئیں:
- 1-4 اختیارات میں سے ایک، جو سسٹم کو ناکامی اور گرنے سے بچائے گا۔
- ڈیٹا کو نقصان سے بچانے کے لیے بیک اپ۔
مرکزی انٹرنیٹ فراہم کنندہ کے نیچے جانے کی صورت میں بیک اپ کمیونیکیشن چینل کا خیال رکھنا بھی ضروری ہے۔ اور - آواز! - کم از کم اجرت پر DR پہلے ہی تیار ہے۔
ماخذ: www.habr.com
