


نیٹ فلکس انٹرنیٹ ٹیلی ویژن مارکیٹ میں سرفہرست ہے - وہ کمپنی جس نے اس سیگمنٹ کو تخلیق کیا اور فعال طور پر ترقی کر رہی ہے۔ Netflix نہ صرف سیارے کے تقریباً ہر کونے سے دستیاب فلموں اور ٹی وی سیریز کے وسیع کیٹلاگ اور ڈسپلے کے ساتھ کسی بھی ڈیوائس کے لیے جانا جاتا ہے، بلکہ اس کے قابل اعتماد انفراسٹرکچر اور منفرد انجینئرنگ کلچر کے لیے بھی جانا جاتا ہے۔
ڈیو اوپس 2019 میں پیچیدہ نظاموں کی ترقی اور معاونت کے لیے نیٹ فلکس کے نقطہ نظر کی ایک واضح مثال پیش کی گئی تھی۔ - Netflix میں ترقی کے ڈائریکٹر۔ نزنی نووگوروڈ اسٹیٹ یونیورسٹی کی فیکلٹی آف کمپیوٹیشنل میتھمیٹکس اینڈ میتھمیٹکس کا گریجویٹ۔ Lobachevsky, Sergey Netflix میں Open Connect - CDN ٹیم کے پہلے انجینئروں میں سے ایک۔ اس نے ویڈیو ڈیٹا کی نگرانی اور تجزیہ کرنے کے لیے نظام بنائے، انٹرنیٹ کنکشن کی رفتار کا اندازہ لگانے کے لیے ایک مقبول سروس FAST.com کا آغاز کیا، اور پچھلے کچھ سالوں سے انٹرنیٹ کی درخواستوں کو بہتر بنانے پر کام کر رہا ہے تاکہ Netflix ایپلی کیشن صارفین کے لیے جلد سے جلد کام کرے۔
رپورٹ کو کانفرنس کے شرکاء سے بہترین جائزے ملے، اور ہم نے آپ کے لیے متنی ورژن تیار کیا ہے۔

سرگئی نے اپنی رپورٹ میں تفصیل سے بات کی۔
- اس بارے میں کہ کلائنٹ اور سرور کے درمیان انٹرنیٹ کی درخواستوں کی تاخیر پر کیا اثر پڑتا ہے۔
- اس تاخیر کو کیسے کم کیا جائے؛
- غلطی برداشت کرنے والے نظاموں کو ڈیزائن، برقرار رکھنے اور مانیٹر کرنے کا طریقہ؛
- کم وقت میں اور کاروبار کے لیے کم سے کم خطرے کے ساتھ نتائج کیسے حاصل کیے جائیں؛
- نتائج کا تجزیہ کیسے کریں اور غلطیوں سے سیکھیں۔
ان سوالوں کے جواب صرف ان لوگوں کو ہی نہیں جو بڑے اداروں میں کام کرتے ہیں۔
پیش کردہ اصولوں اور تکنیکوں کو ہر ایک کو معلوم ہونا چاہیے اور ان پر عمل کرنا چاہیے جو انٹرنیٹ پروڈکٹس تیار کرتا ہے اور اس کی حمایت کرتا ہے۔
اگلا بیان ہے اسپیکر کے نقطہ نظر سے۔
انٹرنیٹ کی رفتار کی اہمیت
انٹرنیٹ کی درخواستوں کی رفتار کا تعلق براہ راست کاروبار سے ہے۔ شاپنگ انڈسٹری پر غور کریں: ایمیزون 2009 میں کہ 100ms کی تاخیر کے نتیجے میں فروخت کا 1% نقصان ہوتا ہے۔
زیادہ سے زیادہ موبائل ڈیوائسز ہیں، اس کے بعد موبائل سائٹس اور ایپلیکیشنز ہیں۔ اگر آپ کے صفحہ کو لوڈ ہونے میں 3 سیکنڈ سے زیادہ وقت لگتا ہے، تو آپ اپنے تقریباً نصف صارفین کو کھو رہے ہیں۔ کے ساتھ گوگل تلاش کے نتائج میں آپ کے صفحہ کی لوڈنگ کی رفتار کو مدنظر رکھتا ہے: صفحہ جتنا تیز ہوگا، گوگل میں اس کی پوزیشن اتنی ہی اونچی ہوگی۔
کنکشن کی رفتار مالیاتی اداروں میں بھی اہم ہے جہاں تاخیر اہم ہے۔ 2015 میں، ہائبرنیا نیٹ ورکس نیویارک اور لندن کے درمیان $400 ملین کیبل، شہروں کے درمیان لیٹنسی کو 6ms تک کم کرنے کے لیے۔ 66 ms تاخیر میں کمی کے لیے $1 ملین کا تصور کریں!
کے مطابق ، کنکشن کی رفتار 5 Mbit/s سے زیادہ کسی عام ویب سائٹ کی لوڈنگ کی رفتار کو براہ راست متاثر نہیں کرتی ہے۔ تاہم، کنکشن کی تاخیر اور صفحہ لوڈ کرنے کی رفتار کے درمیان ایک خطی تعلق ہے:
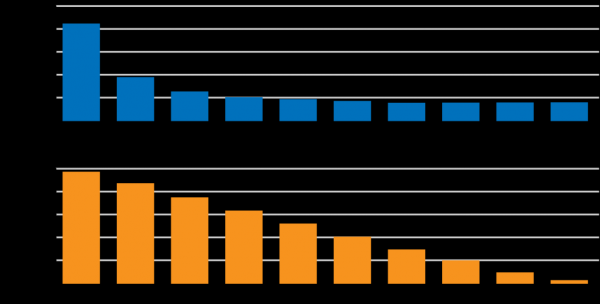
تاہم، Netflix ایک عام مصنوعات نہیں ہے. صارف پر تاخیر اور رفتار کا اثر تجزیہ اور ترقی کا ایک فعال علاقہ ہے۔ ایپلیکیشن لوڈنگ اور مواد کا انتخاب ہے جو تاخیر پر منحصر ہے، لیکن جامد عناصر کو لوڈ کرنا اور سلسلہ بندی بھی کنکشن کی رفتار پر منحصر ہے۔ صارف کے تجربے کو متاثر کرنے والے کلیدی عوامل کا تجزیہ اور اصلاح کرنا Netflix پر متعدد ٹیموں کے لیے ترقی کا ایک فعال شعبہ ہے۔ اہداف میں سے ایک Netflix ڈیوائسز اور کلاؤڈ انفراسٹرکچر کے درمیان درخواستوں کی تاخیر کو کم کرنا ہے۔
رپورٹ میں ہم خاص طور پر Netflix انفراسٹرکچر کی مثال کا استعمال کرتے ہوئے تاخیر کو کم کرنے پر توجہ مرکوز کریں گے۔ آئیے ایک عملی نقطہ نظر سے غور کریں کہ پیچیدہ تقسیم شدہ نظاموں کے ڈیزائن، ترقی اور آپریشن کے عمل تک کیسے پہنچنا ہے اور آپریشنل مسائل اور خرابیوں کی تشخیص کے بجائے اختراعات اور نتائج پر وقت صرف کرنا ہے۔
Netflix کے اندر
ہزاروں مختلف آلات Netflix ایپس کو سپورٹ کرتے ہیں۔ وہ چار مختلف ٹیموں کے ذریعہ تیار کیے گئے ہیں، ہر ایک کے لیے الگ الگ کلائنٹ ورژن تیار کرتے ہیں۔ Android، iOS، TV، اور ویب براؤزرز۔ ہم متوازی طور پر سینکڑوں A/B ٹیسٹ چلاتے ہوئے، صارف کے تجربے کو بہتر اور ذاتی بنانے کے لیے بھی سخت محنت کر رہے ہیں۔
پرسنلائزیشن کو AWS کلاؤڈ میں سینکڑوں مائیکرو سروسز کے ذریعے سپورٹ کیا جاتا ہے، جو صارف کا ذاتی ڈیٹا، استفسار ڈسپیچ، ٹیلی میٹری، بگ ڈیٹا اور انکوڈنگ فراہم کرتا ہے۔ ٹریفک کا تصور اس طرح لگتا ہے:
بائیں طرف انٹری پوائنٹ ہے، اور پھر ٹریفک کو کئی سو مائیکرو سروسز میں تقسیم کیا جاتا ہے جن کو مختلف بیک اینڈ ٹیمیں سپورٹ کرتی ہیں۔
ہمارے بنیادی ڈھانچے کا ایک اور اہم جزو Open Connect CDN ہے، جو آخری صارف تک جامد مواد فراہم کرتا ہے - ویڈیوز، تصاویر، کلائنٹ کوڈ وغیرہ۔ CDN کسٹم سرورز (OCA - Open Connect Appliance) پر واقع ہے۔ اندر ایس ایس ڈی اور ایچ ڈی ڈی ڈرائیوز کی صفیں ہیں جو این جی آئی این ایکس اور خدمات کے ایک سیٹ کے ساتھ آپٹیمائزڈ فری بی ایس ڈی چلا رہی ہیں۔ ہم ہارڈ ویئر اور سافٹ ویئر کے اجزاء کو ڈیزائن اور بہتر بناتے ہیں تاکہ ایسا CDN سرور صارفین کو زیادہ سے زیادہ ڈیٹا بھیج سکے۔
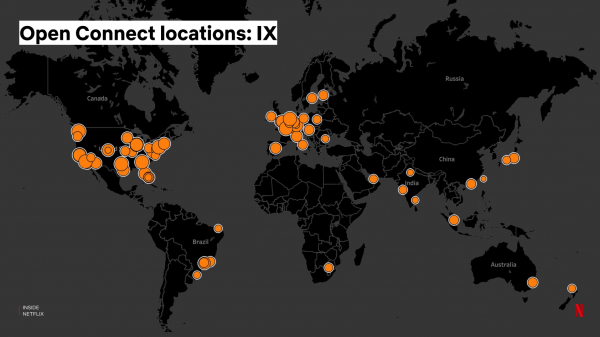
انٹرنیٹ ٹریفک ایکسچینج پوائنٹ (انٹرنیٹ ایکسچینج - IX) پر ان سرورز کی "دیوار" اس طرح دکھائی دیتی ہے:

انٹرنیٹ ایکسچینج انٹرنیٹ سروس فراہم کرنے والوں اور مواد فراہم کرنے والوں کو انٹرنیٹ پر ڈیٹا کا براہ راست تبادلہ کرنے کے لیے ایک دوسرے کے ساتھ "جوڑنے" کی صلاحیت فراہم کرتا ہے۔ دنیا بھر میں تقریباً 70-80 انٹرنیٹ ایکسچینج پوائنٹس ہیں جہاں ہمارے سرورز انسٹال ہیں، اور ہم انہیں آزادانہ طور پر انسٹال اور برقرار رکھتے ہیں:
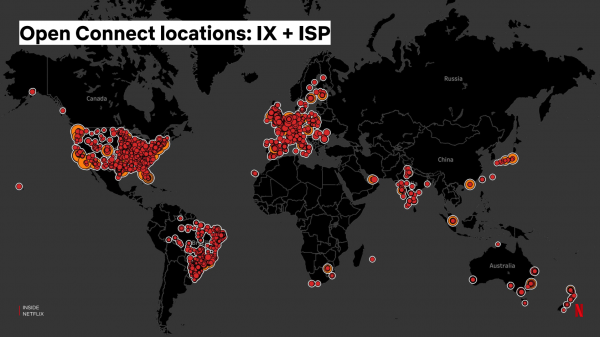
اس کے علاوہ، ہم انٹرنیٹ فراہم کرنے والوں کو براہ راست سرور بھی فراہم کرتے ہیں، جسے وہ اپنے نیٹ ورک میں انسٹال کرتے ہیں، نیٹ فلکس ٹریفک کی لوکلائزیشن اور صارفین کے لیے اسٹریمنگ کے معیار کو بہتر بناتے ہیں:
AWS سروسز کا ایک سیٹ کلائنٹس سے CDN سرورز پر ویڈیو درخواستیں بھیجنے کے ساتھ ساتھ سرورز کو خود ترتیب دینے کے لیے ذمہ دار ہے - مواد، پروگرام کوڈ، سیٹنگز وغیرہ کو اپ ڈیٹ کرنا۔ بعد کے لیے، ہم نے بیک بون نیٹ ورک بھی بنایا ہے جو انٹرنیٹ ایکسچینج پوائنٹس میں سرورز کو AWS کے ساتھ جوڑتا ہے۔ بیک بون نیٹ ورک فائبر آپٹک کیبلز اور راؤٹرز کا ایک عالمی نیٹ ورک ہے جسے ہم اپنی ضروریات کے مطابق ڈیزائن اور ترتیب دے سکتے ہیں۔
پر ، ہمارا CDN انفراسٹرکچر دنیا کے انٹرنیٹ ٹریفک کا تقریباً ⅛ چوٹی کے اوقات میں اور ⅓ شمالی امریکہ میں ٹریفک فراہم کرتا ہے، جہاں Netflix سب سے طویل عرصے سے رہا ہے۔ متاثر کن تعداد، لیکن میرے لیے سب سے حیرت انگیز کامیابیوں میں سے ایک یہ ہے کہ CDN کا پورا نظام 150 سے کم لوگوں کی ٹیم کے ذریعے تیار اور برقرار رکھا جاتا ہے۔
ابتدائی طور پر، CDN انفراسٹرکچر کو ویڈیو ڈیٹا کی فراہمی کے لیے ڈیزائن کیا گیا تھا۔ تاہم، وقت کے ساتھ ہم نے محسوس کیا کہ ہم اسے AWS کلاؤڈ میں کلائنٹس کی جانب سے متحرک درخواستوں کو بہتر بنانے کے لیے بھی استعمال کر سکتے ہیں۔
انٹرنیٹ ایکسلریشن کے بارے میں
آج، Netflix کے پاس 3 AWS علاقے ہیں، اور کلاؤڈ کو درخواستوں کی تاخیر کا انحصار اس بات پر ہوگا کہ گاہک قریبی علاقے سے کتنی دور ہے۔ ایک ہی وقت میں، ہمارے پاس بہت سے CDN سرور ہیں جو جامد مواد کی فراہمی کے لیے استعمال ہوتے ہیں۔ کیا متحرک سوالات کو تیز کرنے کے لیے اس فریم ورک کو استعمال کرنے کا کوئی طریقہ ہے؟ تاہم، بدقسمتی سے، ان درخواستوں کو کیش کرنا ناممکن ہے - APIs ذاتی نوعیت کے ہیں اور ہر نتیجہ منفرد ہے۔
آئیے CDN سرور پر ایک پراکسی بنائیں اور اس کے ذریعے ٹریفک بھیجنا شروع کریں۔ کیا یہ تیز تر ہوگا؟
میٹریل
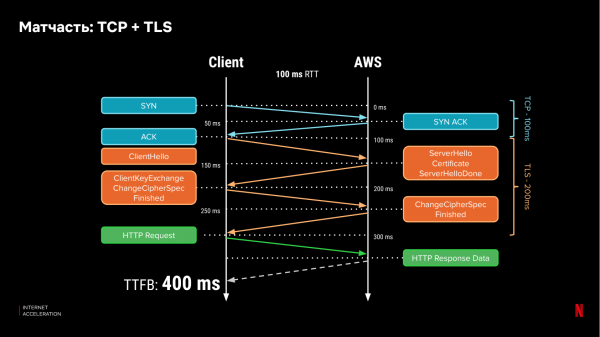
آئیے یاد رکھیں کہ نیٹ ورک پروٹوکول کیسے کام کرتے ہیں۔ آج، انٹرنیٹ پر زیادہ تر ٹریفک HTTPs کا استعمال کرتی ہے، جو کہ نچلی پرت کے پروٹوکول TCP اور TLS پر منحصر ہے۔ کسی کلائنٹ کے سرور سے جڑنے کے لیے، یہ مصافحہ کرتا ہے، اور ایک محفوظ کنکشن قائم کرنے کے لیے، کلائنٹ کو سرور کے ساتھ تین بار پیغامات کا تبادلہ کرنا ہوگا اور ڈیٹا کی منتقلی کے لیے کم از کم ایک بار مزید کرنا ہوگا۔ لیٹنسی فی راؤنڈ ٹرپ (RTT) 100 ms کے ساتھ، ہمیں ڈیٹا کا پہلا بٹ حاصل کرنے میں 400 ms لگیں گے:
اگر ہم سرٹیفکیٹس کو CDN سرور پر رکھتے ہیں، تو کلائنٹ اور سرور کے درمیان مصافحہ کا وقت نمایاں طور پر کم ہو سکتا ہے اگر CDN قریب ہو۔ آئیے فرض کریں کہ CDN سرور کی تاخیر 30ms ہے۔ پھر پہلا بٹ وصول کرنے میں 220 ایم ایس لگے گا:
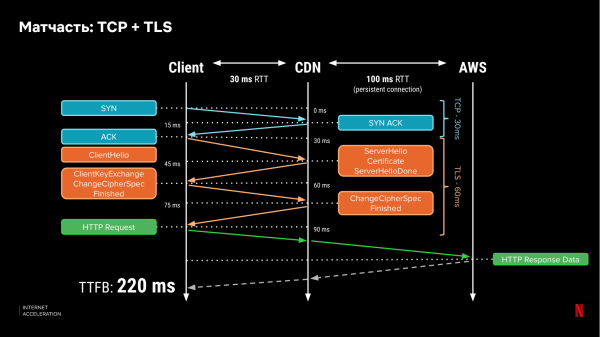
لیکن فوائد وہاں ختم نہیں ہوتے ہیں۔ ایک بار کنکشن قائم ہونے کے بعد، TCP کنجشن ونڈو کو بڑھاتا ہے (معلومات کی مقدار جو وہ اس کنکشن پر متوازی طور پر منتقل کر سکتی ہے)۔ اگر ڈیٹا پیکٹ کھو جاتا ہے، تو TCP پروٹوکول کے کلاسک نفاذ (جیسے TCP نیو رینو) کھلی "ونڈو" کو نصف تک کم کر دیتے ہیں۔ کنجشن ونڈو کی بڑھوتری، اور نقصان سے دوبارہ اس کی بازیابی کی رفتار سرور میں تاخیر (RTT) پر منحصر ہے۔ اگر یہ کنکشن صرف CDN سرور تک جاتا ہے، تو یہ بازیابی تیز تر ہوگی۔ ایک ہی وقت میں، پیکٹ کا نقصان ایک معیاری رجحان ہے، خاص طور پر وائرلیس نیٹ ورکس کے لیے۔
انٹرنیٹ بینڈوڈتھ کم ہو سکتی ہے، خاص طور پر چوٹی کے اوقات میں، صارفین کے ٹریفک کی وجہ سے، جو ٹریفک جام کا باعث بن سکتی ہے۔ تاہم، انٹرنیٹ پر کچھ درخواستوں کو دوسروں پر ترجیح دینے کا کوئی طریقہ نہیں ہے۔ مثال کے طور پر، نیٹ ورک کو لوڈ کرنے والے "بھاری" ڈیٹا اسٹریمز پر چھوٹی اور تاخیر سے متعلق حساس درخواستوں کو ترجیح دیں۔ تاہم، ہمارے معاملے میں، ہمارے اپنے بیک بون نیٹ ورک کا ہونا ہمیں درخواست کے راستے کے ایک حصے پر - CDN اور کلاؤڈ کے درمیان ایسا کرنے کی اجازت دیتا ہے، اور ہم اسے مکمل طور پر ترتیب دے سکتے ہیں۔ آپ اس بات کو یقینی بنا سکتے ہیں کہ چھوٹے اور تاخیر سے متعلق حساس پیکٹوں کو ترجیح دی جاتی ہے، اور بڑے ڈیٹا کا بہاؤ تھوڑی دیر بعد ہوتا ہے۔ CDN کلائنٹ کے جتنا قریب ہوگا، کارکردگی اتنی ہی زیادہ ہوگی۔
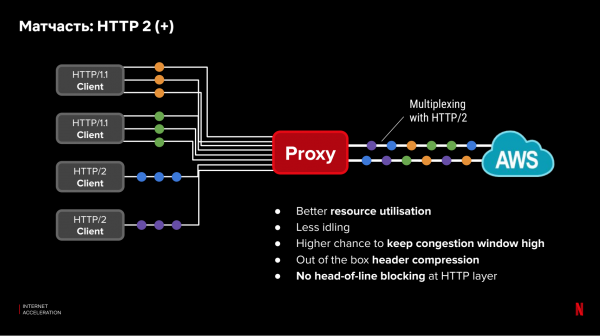
ایپلیکیشن لیول پروٹوکول (OSI لیول 7) کا بھی تاخیر پر اثر پڑتا ہے۔ نئے پروٹوکول جیسے HTTP/2 متوازی درخواستوں کی کارکردگی کو بہتر بناتے ہیں۔ تاہم، ہمارے پاس پرانے آلات کے ساتھ Netflix کلائنٹس ہیں جو نئے پروٹوکول کو سپورٹ نہیں کرتے ہیں۔ تمام کلائنٹس کو اپ ڈیٹ یا بہتر طریقے سے ترتیب نہیں دیا جا سکتا۔ ایک ہی وقت میں، CDN پراکسی اور کلاؤڈ کے درمیان مکمل کنٹرول اور نئے، بہترین پروٹوکول اور ترتیبات کو استعمال کرنے کی صلاحیت موجود ہے۔ پرانے پروٹوکول کے ساتھ غیر موثر حصہ صرف کلائنٹ اور CDN سرور کے درمیان کام کرے گا۔ مزید یہ کہ، ہم CDN اور کلاؤڈ کے درمیان پہلے سے قائم کنکشن پر ملٹی پلیکس کی درخواستیں کر سکتے ہیں، TCP کی سطح پر کنکشن کے استعمال کو بہتر بناتے ہوئے:
ہم پیمائش کرتے ہیں۔
اس حقیقت کے باوجود کہ نظریہ بہتری کا وعدہ کرتا ہے، ہم فوری طور پر نظام کو پیداوار میں شروع کرنے کے لیے جلدی نہیں کرتے۔ اس کے بجائے، ہمیں پہلے یہ ثابت کرنا ہوگا کہ یہ خیال عملی طور پر کام کرے گا۔ ایسا کرنے کے لیے آپ کو کئی سوالات کے جوابات دینے کی ضرورت ہے:
- رفتار: کیا ایک پراکسی تیز ہوگی؟
- وشوسنییتا: کیا یہ زیادہ کثرت سے ٹوٹ جائے گا؟
- پیچیدگی: ایپلی کیشنز کے ساتھ کیسے ضم کیا جائے؟
- قیمت: اضافی انفراسٹرکچر کی تعیناتی پر کتنا خرچ آتا ہے؟
آئیے پہلے نکتے کا اندازہ لگانے کے لیے اپنے نقطہ نظر پر تفصیل سے غور کریں۔ باقی کے ساتھ بھی اسی طرح نمٹا جاتا ہے۔
درخواستوں کی رفتار کا تجزیہ کرنے کے لیے، ہم ترقی پر زیادہ وقت خرچ کیے بغیر اور پیداوار کو توڑے بغیر، تمام صارفین کا ڈیٹا حاصل کرنا چاہتے ہیں۔ اس کے لیے کئی طریقے ہیں:
- RUM، یا غیر فعال درخواست کی پیمائش۔ ہم صارفین کی جانب سے موجودہ درخواستوں پر عمل درآمد کے وقت کی پیمائش کرتے ہیں اور صارف کی مکمل کوریج کو یقینی بناتے ہیں۔ نقصان یہ ہے کہ سگنل بہت سے عوامل کی وجہ سے زیادہ مستحکم نہیں ہے، مثال کے طور پر، مختلف درخواست کے سائز، سرور اور کلائنٹ پر کارروائی کا وقت۔ اس کے علاوہ، آپ پیداوار میں اثر کے بغیر نئی ترتیب کی جانچ نہیں کر سکتے ہیں۔
- لیبارٹری ٹیسٹ۔ خصوصی سرورز اور انفراسٹرکچر جو کلائنٹس کی تقلید کرتے ہیں۔ ان کی مدد سے ہم ضروری ٹیسٹ کرواتے ہیں۔ اس طرح ہم پیمائش کے نتائج اور واضح سگنل پر مکمل کنٹرول حاصل کرتے ہیں۔ لیکن آلات اور صارف کے مقامات کی کوئی مکمل کوریج نہیں ہے (خاص طور پر دنیا بھر میں سروس اور ہزاروں ڈیوائس ماڈلز کے لیے سپورٹ کے ساتھ)۔
آپ دونوں طریقوں کے فوائد کو کیسے یکجا کر سکتے ہیں؟
ہماری ٹیم نے ایک حل ڈھونڈ لیا ہے۔ ہم نے کوڈ کا ایک چھوٹا سا ٹکڑا - ایک نمونہ - جسے ہم نے اپنی درخواست میں بنایا ہے۔ تحقیقات ہمیں اپنے آلات سے مکمل طور پر کنٹرول شدہ نیٹ ورک ٹیسٹ کرنے کی اجازت دیتی ہیں۔ یہ اس طرح کام کرتا ہے:
- ایپلیکیشن لوڈ کرنے اور ابتدائی سرگرمی مکمل کرنے کے فوراً بعد، ہم اپنی تحقیقات چلاتے ہیں۔
- کلائنٹ سرور سے درخواست کرتا ہے اور ٹیسٹ کے لیے ایک "نسخہ" وصول کرتا ہے۔ ترکیب یو آر ایل کی ایک فہرست ہے جس پر HTTP(s) کی درخواست کرنے کی ضرورت ہے۔ اس کے علاوہ، نسخہ درخواست کے پیرامیٹرز کو ترتیب دیتا ہے: درخواستوں کے درمیان تاخیر، درخواست کردہ ڈیٹا کی مقدار، HTTP(s) ہیڈر وغیرہ۔ ایک ہی وقت میں، ہم متوازی طور پر متعدد مختلف ترکیبوں کی جانچ کر سکتے ہیں - جب کسی ترتیب کی درخواست کرتے ہیں، تو ہم تصادفی طور پر طے کرتے ہیں کہ کون سی ترکیب جاری کرنی ہے۔
- تحقیقات کے آغاز کا وقت منتخب کیا جاتا ہے تاکہ کلائنٹ پر نیٹ ورک وسائل کے فعال استعمال سے متصادم نہ ہو۔ بنیادی طور پر، وہ وقت منتخب کیا جاتا ہے جب کلائنٹ فعال نہ ہو۔
- نسخہ حاصل کرنے کے بعد، کلائنٹ متوازی طور پر ہر یو آر ایل سے درخواستیں کرتا ہے۔ ہر ایک پتے کی درخواست دہرائی جا سکتی ہے - نام نہاد۔ "دالیں"۔ پہلی نبض پر، ہم پیمائش کرتے ہیں کہ کنکشن قائم کرنے اور ڈیٹا ڈاؤن لوڈ کرنے میں کتنا وقت لگا۔ دوسری نبض پر، ہم پہلے سے قائم کنکشن پر ڈیٹا لوڈ کرنے میں لگنے والے وقت کی پیمائش کرتے ہیں۔ تیسرے سے پہلے، ہم تاخیر کا تعین کر سکتے ہیں اور دوبارہ رابطہ قائم کرنے کی رفتار کی پیمائش کر سکتے ہیں، وغیرہ۔
ٹیسٹ کے دوران، ہم ان تمام پیرامیٹرز کی پیمائش کرتے ہیں جو آلہ حاصل کر سکتا ہے:
- DNS درخواست کا وقت؛
- TCP کنکشن سیٹ اپ کا وقت؛
- TLS کنکشن سیٹ اپ کا وقت؛
- ڈیٹا کا پہلا بائٹ حاصل کرنے کا وقت؛
- کل لوڈنگ وقت؛
- حیثیت کا نتیجہ کوڈ
- تمام دالیں مکمل ہونے کے بعد، نمونہ تجزیہ کے لیے تمام پیمائشوں کو لوڈ کرتا ہے۔
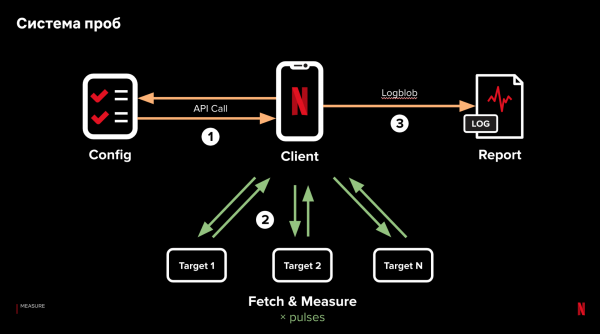
کلیدی نکات کلائنٹ پر منطق پر کم سے کم انحصار، سرور پر ڈیٹا پروسیسنگ اور متوازی درخواستوں کی پیمائش ہیں۔ اس طرح، ہم استفسار کی کارکردگی کو متاثر کرنے والے مختلف عوامل کے اثر و رسوخ کو الگ تھلگ کرنے اور جانچنے کے قابل ہیں، انہیں ایک ہی نسخے میں مختلف کرتے ہیں، اور حقیقی کلائنٹس سے نتائج حاصل کرتے ہیں۔
یہ بنیادی ڈھانچہ صرف استفسار کی کارکردگی کے تجزیہ سے زیادہ کے لیے مفید ثابت ہوا ہے۔ فی الحال ہمارے پاس 14 فعال ترکیبیں ہیں، 6000 سے زیادہ نمونے فی سیکنڈ، زمین کے تمام گوشوں سے ڈیٹا اور مکمل ڈیوائس کوریج حاصل کرتے ہیں۔ اگر Netflix نے کسی تیسرے فریق سے اسی طرح کی سروس خریدی ہے، تو اس پر سالانہ لاکھوں ڈالر لاگت آئے گی، جس میں زیادہ خراب کوریج ہوگی۔
عملی طور پر ٹیسٹنگ تھیوری: پروٹو ٹائپ
اس طرح کے نظام کے ساتھ، ہم درخواست میں تاخیر پر CDN پراکسی کی تاثیر کا جائزہ لینے کے قابل تھے۔ اب آپ کو ضرورت ہے:
- ایک پراکسی پروٹو ٹائپ بنائیں؛
- پروٹوٹائپ کو CDN پر رکھیں؛
- اس بات کا تعین کریں کہ کلائنٹس کو کسی مخصوص CDN سرور پر پراکسی کی طرف کیسے بھیجنا ہے۔
- پراکسی کے بغیر AWS میں درخواستوں سے کارکردگی کا موازنہ کریں۔
کام یہ ہے کہ مجوزہ حل کی تاثیر کا جلد از جلد جائزہ لیا جائے۔ اچھی نیٹ ورکنگ لائبریریوں کی دستیابی کی وجہ سے ہم نے پروٹو ٹائپ کو لاگو کرنے کے لیے گو کا انتخاب کیا۔ ہر CDN سرور پر، ہم نے پروٹوٹائپ پراکسی کو ایک جامد بائنری کے طور پر انسٹال کیا ہے تاکہ انحصار کو کم کیا جا سکے اور انضمام کو آسان بنایا جا سکے۔ ابتدائی نفاذ میں، ہم نے HTTP/2 کنکشن پولنگ اور ملٹی پلیکسنگ کی درخواست کے لیے زیادہ سے زیادہ معیاری اجزاء اور معمولی ترمیمات کا استعمال کیا۔
AWS علاقوں کے درمیان توازن قائم کرنے کے لیے، ہم نے جغرافیائی DNS ڈیٹا بیس کا استعمال کیا، وہی جو کلائنٹس کو متوازن کرنے کے لیے استعمال کیا جاتا ہے۔ کلائنٹ کے لیے CDN سرور منتخب کرنے کے لیے، ہم انٹرنیٹ ایکسچینج (IX) میں سرورز کے لیے TCP Anycast استعمال کرتے ہیں۔ اس آپشن میں، ہم تمام CDN سرورز کے لیے ایک IP ایڈریس استعمال کرتے ہیں، اور کلائنٹ کو کم سے کم IP ہاپس کے ساتھ CDN سرور پر بھیج دیا جائے گا۔ انٹرنیٹ فراہم کنندگان (ISPs) کے ذریعہ نصب کردہ CDN سرورز میں، TCP Anycast کو ترتیب دینے کے لیے ہمارے پاس روٹر پر کنٹرول نہیں ہے، اس لیے ہم استعمال کرتے ہیں۔ جو صارفین کو ویڈیو سٹریمنگ کے لیے انٹرنیٹ فراہم کنندگان کو ہدایت کرتا ہے۔
لہذا، ہمارے پاس درخواست کے تین قسم کے راستے ہیں: کھلے انٹرنیٹ کے ذریعے کلاؤڈ تک، IX میں CDN سرور کے ذریعے، یا انٹرنیٹ فراہم کنندہ پر واقع CDN سرور کے ذریعے۔ ہمارا مقصد یہ سمجھنا ہے کہ کون سا طریقہ بہتر ہے، اور پراکسی کا کیا فائدہ ہے، اس کے مقابلے میں کہ درخواستیں پروڈکشن کو کیسے بھیجی جاتی ہیں۔ ایسا کرنے کے لیے، ہم مندرجہ ذیل نمونے لینے کا نظام استعمال کرتے ہیں:
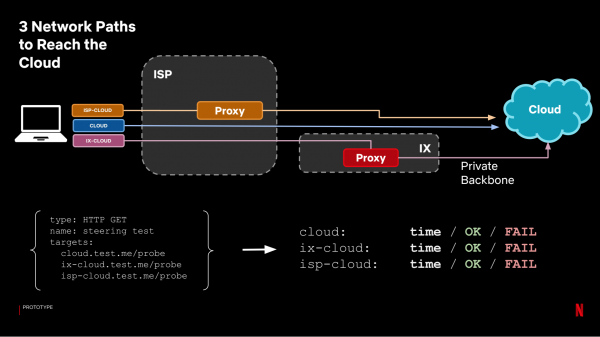
راستے میں سے ہر ایک الگ ہدف بن جاتا ہے، اور ہم اس وقت کو دیکھتے ہیں جو ہمیں ملا ہے۔ تجزیہ کے لیے، ہم پراکسی کے نتائج کو ایک گروپ میں یکجا کرتے ہیں (IX اور ISP پراکسی کے درمیان بہترین وقت کا انتخاب کریں)، اور ان کا موازنہ کلاؤڈ کو درخواست کے وقت کے ساتھ بغیر پراکسی کے کریں:
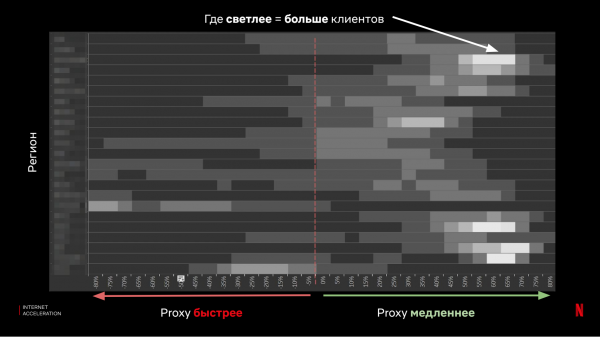
جیسا کہ آپ دیکھ سکتے ہیں، نتائج ملے جلے تھے - زیادہ تر معاملات میں پراکسی اچھی رفتار فراہم کرتی ہے، لیکن ایسے کلائنٹس کی بھی کافی تعداد موجود ہے جن کے لیے صورتحال نمایاں طور پر بگڑ جائے گی۔
نتیجے کے طور پر، ہم نے کئی اہم کام کیے:
- ہم نے CDN پراکسی کے ذریعے کلائنٹس کی طرف سے کلاؤڈ کو درخواستوں کی متوقع کارکردگی کا اندازہ کیا۔
- ہم نے ہر قسم کے آلات سے حقیقی کلائنٹس سے ڈیٹا حاصل کیا۔
- ہم نے محسوس کیا کہ تھیوری کی 100% تصدیق نہیں ہوئی تھی اور CDN پراکسی کے ساتھ ابتدائی پیشکش ہمارے لیے کام نہیں کرے گی۔
- ہم نے رسک نہیں لیا - ہم نے کلائنٹس کے لیے پروڈکشن کنفیگریشنز کو تبدیل نہیں کیا۔
- کچھ نہیں ٹوٹا تھا۔
پروٹو ٹائپ 2.0
لہذا، ڈرائنگ بورڈ پر واپس جائیں اور اس عمل کو دوبارہ دہرائیں۔
خیال یہ ہے کہ 100% پراکسی استعمال کرنے کے بجائے، ہم ہر کلائنٹ کے لیے تیز ترین راستے کا تعین کریں گے، اور ہم وہاں درخواستیں بھیجیں گے - یعنی، ہم وہی کریں گے جسے کلائنٹ اسٹیئرنگ کہتے ہیں۔
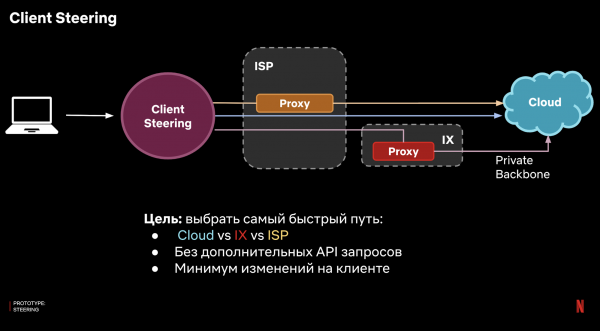
اس کو کیسے نافذ کیا جائے؟ ہم سرور کی طرف منطق کا استعمال نہیں کر سکتے، کیونکہ... مقصد اس سرور سے جڑنا ہے۔ کلائنٹ پر ایسا کرنے کا کوئی طریقہ ہونا ضروری ہے۔ اور مثالی طور پر، یہ پیچیدہ منطق کی کم از کم مقدار کے ساتھ کریں، تاکہ کلائنٹ پلیٹ فارمز کی ایک بڑی تعداد کے ساتھ انضمام کا مسئلہ حل نہ ہو۔
جواب DNS استعمال کرنا ہے۔ ہمارے معاملے میں، ہمارا اپنا DNS انفراسٹرکچر ہے، اور ہم ایک ڈومین زون قائم کر سکتے ہیں جس کے لیے ہمارے سرورز آمرانہ ہوں گے۔ یہ اس طرح کام کرتا ہے:
- کلائنٹ میزبان کا استعمال کرتے ہوئے DNS سرور سے درخواست کرتا ہے، مثال کے طور پر api.netflix.xom۔
- درخواست ہمارے DNS سرور پر پہنچ جاتی ہے۔
- DNS سرور جانتا ہے کہ اس کلائنٹ کے لیے کون سا راستہ سب سے تیز ہے اور متعلقہ IP ایڈریس جاری کرتا ہے۔
حل میں ایک اضافی پیچیدگی ہے: آمرانہ DNS فراہم کنندگان کلائنٹ کا IP ایڈریس نہیں دیکھتے ہیں اور صرف کلائنٹ کے استعمال کردہ ریکسریو ریزولور کا IP ایڈریس پڑھ سکتے ہیں۔
نتیجے کے طور پر، ہمارے آمرانہ حل کرنے والے کو ایک انفرادی کلائنٹ کے لیے نہیں، بلکہ کلائنٹس کے ایک گروپ کے لیے ریکسریو ریزولور کی بنیاد پر فیصلہ کرنا چاہیے۔
حل کرنے کے لیے، ہم وہی نمونے استعمال کرتے ہیں، کلائنٹس سے ہر ایک بار بار آنے والے حل کرنے والے کے لیے پیمائش کے نتائج کو جمع کرتے ہیں اور فیصلہ کرتے ہیں کہ ان کے اس گروپ کو کہاں بھیجنا ہے - IX کے ذریعے ایک پراکسی TCP Anycast کے ذریعے، ISP پراکسی کے ذریعے، یا براہ راست کلاؤڈ پر۔
ہمیں مندرجہ ذیل نظام ملتا ہے:
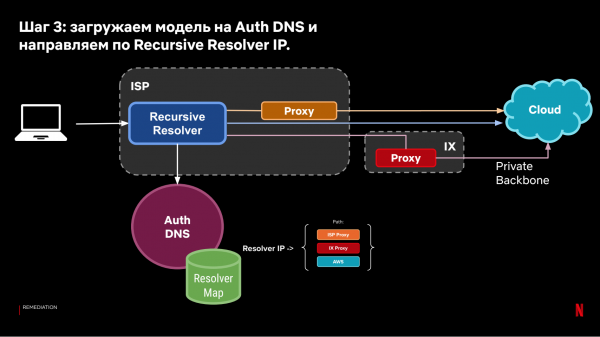
نتیجے میں آنے والا DNS اسٹیئرنگ ماڈل آپ کو کلائنٹس سے کلاؤڈ تک رابطوں کی رفتار کے تاریخی مشاہدات کی بنیاد پر کلائنٹس کو ہدایت کرنے کی اجازت دیتا ہے۔
ایک بار پھر، سوال یہ ہے کہ یہ نقطہ نظر کس حد تک مؤثر طریقے سے کام کرے گا؟ جواب دینے کے لیے، ہم دوبارہ اپنا پروب سسٹم استعمال کرتے ہیں۔ لہذا، ہم پیش کنندہ کنفیگریشن کو ترتیب دیتے ہیں، جہاں ایک ہدف DNS اسٹیئرنگ کی سمت کی پیروی کرتا ہے، دوسرا براہ راست کلاؤڈ (موجودہ پیداوار) پر جاتا ہے۔
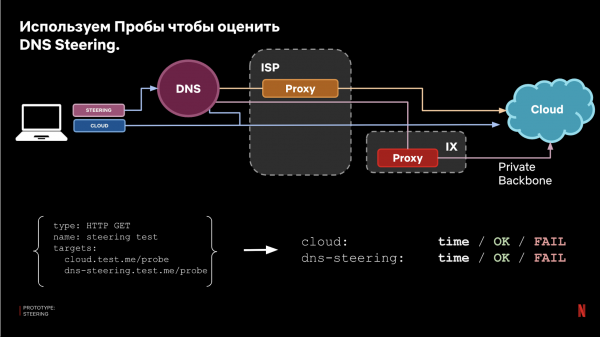
نتیجے کے طور پر، ہم نتائج کا موازنہ کرتے ہیں اور تاثیر کا اندازہ لگاتے ہیں:
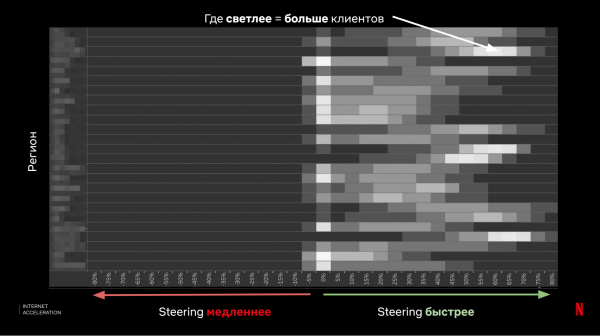
نتیجے کے طور پر، ہم نے کئی اہم چیزیں سیکھیں:
- ہم نے DNS اسٹیئرنگ کا استعمال کرتے ہوئے کلائنٹس کی طرف سے کلاؤڈ کو درخواستوں کی متوقع کارکردگی کا اندازہ کیا۔
- ہم نے ہر قسم کے آلات سے حقیقی کلائنٹس سے ڈیٹا حاصل کیا۔
- مجوزہ خیال کی تاثیر ثابت ہو چکی ہے۔
- ہم نے رسک نہیں لیا - ہم نے کلائنٹس کے لیے پروڈکشن کنفیگریشنز کو تبدیل نہیں کیا۔
- کچھ نہیں ٹوٹا تھا۔
اب مشکل حصے کے بارے میں - ہم اسے پیداوار میں شروع کرتے ہیں۔
آسان حصہ اب ختم ہو گیا ہے - ایک کام کرنے والا پروٹو ٹائپ ہے۔ اب مشکل حصہ Netflix کی تمام ٹریفک کے لیے ایک حل شروع کر رہا ہے، جس میں 150 ملین صارفین، ہزاروں آلات، سینکڑوں مائیکرو سروسز، اور ہمیشہ بدلتے ہوئے پروڈکٹ اور انفراسٹرکچر کو تعینات کیا جا رہا ہے۔ Netflix سرورز کو فی سیکنڈ لاکھوں درخواستیں موصول ہوتی ہیں، اور لاپرواہی سے سروس کو توڑنا آسان ہے۔ ایک ہی وقت میں، ہم انٹرنیٹ پر ہزاروں CDN سرورز کے ذریعے ٹریفک کو متحرک طور پر روٹ کرنا چاہتے ہیں، جہاں کچھ تبدیل ہوتا رہتا ہے اور مسلسل اور انتہائی نامناسب وقت میں ٹوٹ جاتا ہے۔
اور اس سب کے ساتھ، ٹیم کے پاس 3 انجینئرز ہیں جو سسٹم کی ترقی، تعیناتی اور مکمل تعاون کے ذمہ دار ہیں۔
لہذا، ہم آرام دہ اور صحت مند نیند کے بارے میں بات کرتے رہیں گے.
ترقی کو کیسے جاری رکھا جائے اور اپنا سارا وقت سپورٹ پر نہ صرف کیا جائے؟ ہمارا نقطہ نظر 3 اصولوں پر مبنی ہے:
- ہم خرابی کے ممکنہ پیمانے (دھماکے کے رداس) کو کم کرتے ہیں۔
- ہم حیرت کی تیاری کر رہے ہیں - ہم توقع کرتے ہیں کہ جانچ اور ذاتی تجربے کے باوجود کچھ ٹوٹ جائے گا۔
- مکرم انحطاط - اگر کوئی چیز ٹھیک کام نہیں کرتی ہے، تو اسے خود بخود ٹھیک ہونا چاہیے، خواہ سب سے زیادہ موثر طریقے سے نہ ہو۔
یہ پتہ چلا کہ ہمارے معاملے میں، مسئلہ کے اس نقطہ نظر کے ساتھ، ہم ایک آسان اور مؤثر حل تلاش کر سکتے ہیں اور نمایاں طور پر نظام کی مدد کو آسان بنا سکتے ہیں۔ ہم نے محسوس کیا کہ ہم کلائنٹ میں کوڈ کا ایک چھوٹا ٹکڑا شامل کر سکتے ہیں اور کنکشن کے مسائل کی وجہ سے نیٹ ورک کی درخواست کی غلطیوں کی نگرانی کر سکتے ہیں۔ نیٹ ورک کی خرابیوں کی صورت میں، ہم براہ راست کلاؤڈ پر فال بیک کرتے ہیں۔ یہ حل کلائنٹ ٹیموں کے لیے اہم کوششوں کی ضرورت نہیں ہے، لیکن ہمارے لیے غیر متوقع خرابیوں اور حیرتوں کے خطرے کو بہت حد تک کم کرتا ہے۔
بلاشبہ، فال بیک کے باوجود، ہم ترقی کے دوران ایک واضح نظم و ضبط کی پیروی کرتے ہیں:
- نمونہ ٹیسٹ۔
- A/B ٹیسٹنگ یا کینریز۔
- پروگریسو رول آؤٹ۔
نمونوں کے ساتھ، نقطہ نظر کو بیان کیا گیا ہے - تبدیلیوں کو سب سے پہلے اپنی مرضی کے مطابق ہدایت کا استعمال کرتے ہوئے تجربہ کیا جاتا ہے.
کینری ٹیسٹنگ کے لیے، ہمیں سرورز کے تقابلی جوڑے حاصل کرنے کی ضرورت ہے جس پر ہم موازنہ کر سکتے ہیں کہ نظام تبدیلیوں سے پہلے اور بعد میں کیسے کام کرتا ہے۔ ایسا کرنے کے لیے، ہماری بہت سی CDN سائٹس سے، ہم سرورز کے جوڑے منتخب کرتے ہیں جو موازنہ ٹریفک حاصل کرتے ہیں:
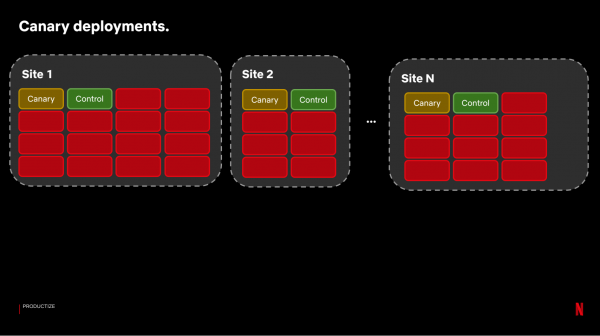
پھر ہم کینری سرور پر تبدیلیوں کے ساتھ تعمیر کو انسٹال کرتے ہیں۔ نتائج کا جائزہ لینے کے لیے، ہم ایک ایسا نظام چلاتے ہیں جو کنٹرول سرورز کے نمونے کے ساتھ تقریباً 100-150 میٹرکس کا موازنہ کرتا ہے:
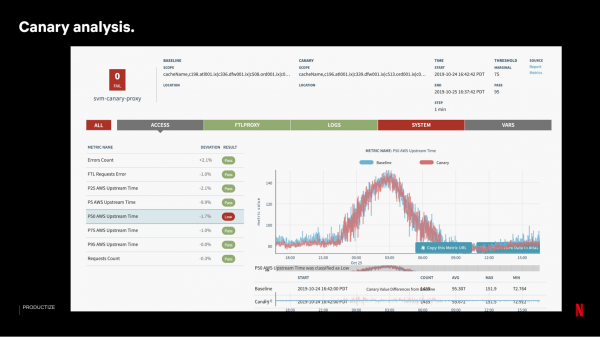
اگر کینری ٹیسٹنگ کامیاب ہو جاتی ہے، تو ہم اسے آہستہ آہستہ لہروں میں چھوڑ دیتے ہیں۔ ہم ہر سائٹ پر ایک ہی وقت میں سرورز کو اپ ڈیٹ نہیں کرتے ہیں - مسائل کی وجہ سے پوری سائٹ کو کھونے سے صارفین کی سروس پر مختلف مقامات پر ایک ہی تعداد میں سرور کھونے سے زیادہ اہم اثر پڑتا ہے۔
عام طور پر، اس نقطہ نظر کی تاثیر اور حفاظت جمع شدہ میٹرکس کی مقدار اور معیار پر منحصر ہے۔ ہمارے استفسار کے سرعت کے نظام کے لیے، ہم تمام ممکنہ اجزاء سے میٹرکس جمع کرتے ہیں:
- کلائنٹس سے - سیشنز اور درخواستوں کی تعداد، فال بیک ریٹ؛
- پراکسی - درخواستوں کی تعداد اور وقت کے اعدادوشمار؛
- DNS - درخواستوں کی تعداد اور نتائج؛
- کلاؤڈ ایج - کلاؤڈ میں درخواستوں پر کارروائی کے لیے نمبر اور وقت۔
یہ سب ایک ہی پائپ لائن میں جمع کیا جاتا ہے، اور ضروریات کے مطابق، ہم فیصلہ کرتے ہیں کہ کون سے میٹرکس کو ریئل ٹائم اینالیٹکس کو بھیجنا ہے، اور کون سے Elasticsearch یا Big Data کو مزید تفصیلی تشخیص کے لیے۔
ہم نگرانی کرتے ہیں۔

ہمارے معاملے میں، ہم کلائنٹ اور سرور کے درمیان درخواستوں کے اہم راستے پر تبدیلیاں کر رہے ہیں۔ ایک ہی وقت میں، کلائنٹ پر، سرور پر، اور انٹرنیٹ کے ذریعے راستے میں مختلف اجزاء کی تعداد بہت زیادہ ہے۔ کلائنٹ اور سرور میں تبدیلیاں مسلسل ہوتی رہتی ہیں - درجنوں ٹیموں کے کام کے دوران اور ماحولیاتی نظام میں قدرتی تبدیلیاں۔ ہم درمیان میں ہیں - مسائل کی تشخیص کرتے وقت، ایک اچھا موقع ہے کہ ہم اس میں شامل ہوں گے۔ لہذا، ہمیں واضح طور پر سمجھنے کی ضرورت ہے کہ مسائل کو تیزی سے الگ کرنے کے لیے میٹرکس کی وضاحت، جمع اور تجزیہ کیسے کیا جائے۔
مثالی طور پر، حقیقی وقت میں تمام قسم کے میٹرکس اور فلٹرز تک مکمل رسائی۔ لیکن بہت سارے میٹرکس ہیں، لہذا لاگت کا سوال پیدا ہوتا ہے۔ ہمارے معاملے میں، ہم مندرجہ ذیل میٹرکس اور ڈویلپمنٹ ٹولز کو الگ کرتے ہیں:

مسائل کا پتہ لگانے اور ٹرائی کرنے کے لیے ہم اپنا اوپن سورس ریئل ٹائم سسٹم استعمال کرتے ہیں۔ и - تصور کے لئے. یہ مجموعی میٹرکس کو میموری میں محفوظ کرتا ہے، قابل اعتماد ہے اور الرٹنگ سسٹم کے ساتھ مربوط ہے۔ لوکلائزیشن اور تشخیص کے لیے، ہمارے پاس Elasticsearch اور Kibana کے لاگز تک رسائی ہے۔ شماریاتی تجزیہ اور ماڈلنگ کے لیے، ہم ٹیبلاؤ میں بڑے ڈیٹا اور تصور کا استعمال کرتے ہیں۔
ایسا لگتا ہے کہ اس نقطہ نظر کے ساتھ کام کرنا بہت مشکل ہے۔ تاہم، میٹرکس اور ٹولز کو درجہ بندی کے مطابق ترتیب دے کر، ہم فوری طور پر کسی مسئلے کا تجزیہ کر سکتے ہیں، مسئلے کی قسم کا تعین کر سکتے ہیں، اور پھر تفصیلی میٹرکس میں ڈرل ڈاؤن کر سکتے ہیں۔ عام طور پر، ہم خرابی کے ماخذ کی شناخت کے لیے تقریباً 1-2 منٹ صرف کرتے ہیں۔ اس کے بعد، ہم تشخیص پر ایک مخصوص ٹیم کے ساتھ کام کرتے ہیں - دسیوں منٹ سے لے کر کئی گھنٹوں تک۔
یہاں تک کہ اگر تشخیص جلدی ہو جائے، ہم نہیں چاہتے کہ ایسا اکثر ہو۔ مثالی طور پر، ہمیں صرف ایک اہم انتباہ موصول ہوگا جب سروس پر اہم اثر پڑے گا۔ ہمارے استفسار کے سرعت کے نظام کے لیے، ہمارے پاس صرف 2 الرٹس ہیں جو مطلع کریں گے:
- کلائنٹ فال بیک فیصد - کسٹمر کے رویے کا اندازہ؛
- فیصد تحقیقات کی خرابیاں - نیٹ ورک کے اجزاء کا استحکام ڈیٹا۔
یہ اہم انتباہات اس بات کی نگرانی کرتے ہیں کہ آیا سسٹم صارفین کی اکثریت کے لیے کام کر رہا ہے۔ ہم دیکھتے ہیں کہ کتنے کلائنٹس نے فال بیک استعمال کیا اگر وہ درخواست کی رفتار حاصل کرنے سے قاصر تھے۔ ہم فی ہفتہ اوسطاً 1 نازک الرٹ دیتے ہیں، حالانکہ سسٹم میں بہت ساری تبدیلیاں ہو رہی ہیں۔ یہ ہمارے لیے کیوں کافی ہے؟
- اگر ہماری پراکسی کام نہیں کرتی ہے تو کلائنٹ کا فال بیک ہے۔
- ایک خودکار اسٹیئرنگ سسٹم ہے جو مسائل کا جواب دیتا ہے۔
مؤخر الذکر کے بارے میں مزید تفصیلات۔ ہمارا آزمائشی نظام، اور کلائنٹ سے کلاؤڈ تک کی درخواستوں کے لیے خودکار طریقے سے بہترین راستے کا تعین کرنے کا نظام، ہمیں خود بخود کچھ مسائل سے نمٹنے کی اجازت دیتا ہے۔
آئیے اپنی نمونہ کنفیگریشن اور 3 پاتھ کیٹیگریز پر واپس آتے ہیں۔ لوڈنگ کے وقت کے علاوہ، ہم خود کی ترسیل کی حقیقت کو دیکھ سکتے ہیں. اگر ڈیٹا کو لوڈ کرنا ممکن نہیں تھا، تو مختلف راستوں پر نتائج کو دیکھ کر ہم یہ تعین کر سکتے ہیں کہ کہاں اور کیا ٹوٹا، اور کیا ہم درخواست کے راستے کو تبدیل کر کے اسے خود بخود ٹھیک کر سکتے ہیں۔
مثالیں:
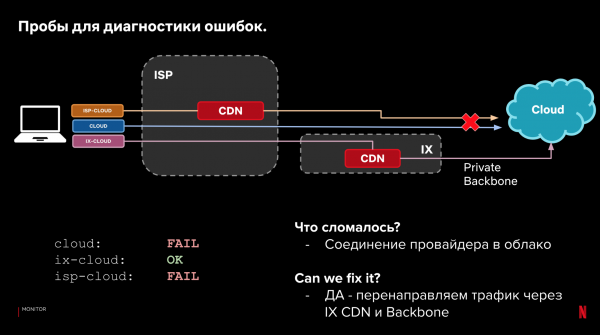
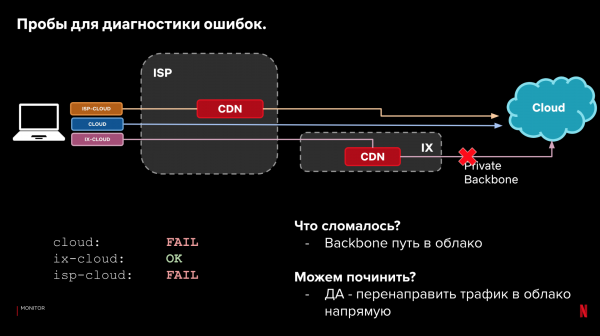
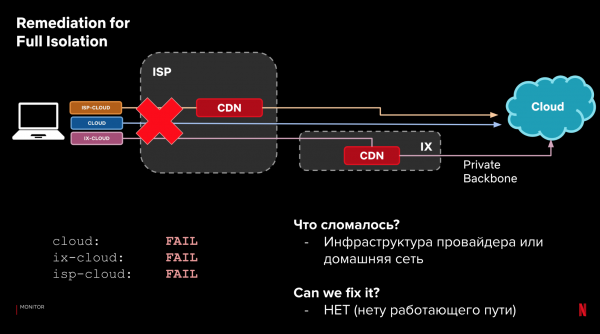
یہ عمل خودکار ہو سکتا ہے۔ اسے اسٹیئرنگ سسٹم میں شامل کریں۔ اور کارکردگی اور وشوسنییتا کے مسائل کا جواب دینا سکھائیں۔ اگر کوئی چیز ٹوٹنے لگتی ہے، اگر کوئی بہتر آپشن ہو تو رد عمل ظاہر کریں۔ ایک ہی وقت میں، کلائنٹس پر فال بیک کی بدولت فوری ردعمل اہم نہیں ہے۔
اس طرح، نظام کی حمایت کے اصول مندرجہ ذیل طور پر وضع کیے جا سکتے ہیں:
- خرابی کے پیمانے کو کم کرنا؛
- میٹرکس جمع کرنا؛
- اگر ہم کر سکتے ہیں تو ہم خود بخود خرابی کی مرمت کر لیتے ہیں۔
- اگر ایسا نہیں ہو سکتا تو ہم آپ کو مطلع کرتے ہیں۔
- ہم فوری جواب کے لیے ڈیش بورڈز اور ٹریج ٹول سیٹ پر کام کر رہے ہیں۔
سبق سیکھا
پروٹو ٹائپ لکھنے میں زیادہ وقت نہیں لگتا۔ ہمارے معاملے میں، یہ 4 ماہ کے بعد تیار تھا. اس کے ساتھ ہمیں نئے میٹرکس موصول ہوئے، اور ترقی کے آغاز کے 10 ماہ بعد ہمیں پہلا پروڈکشن ٹریفک موصول ہوا۔ پھر تھکا دینے والا اور بہت مشکل کام شروع ہوا: آہستہ آہستہ سسٹم کو تیار کریں اور اسکیل کریں، مرکزی ٹریفک کو منتقل کریں اور غلطیوں سے سیکھیں۔ تاہم، یہ موثر عمل لکیری نہیں ہوگا - تمام کوششوں کے باوجود، ہر چیز کا اندازہ نہیں لگایا جا سکتا۔ نئے ڈیٹا کو تیزی سے دہرانا اور اس کا جواب دینا بہت زیادہ موثر ہے۔
اپنے تجربے کی بنیاد پر، ہم درج ذیل کی سفارش کر سکتے ہیں:
- اپنی وجدان پر بھروسہ نہ کریں۔
ہماری ٹیم کے ممبران کے وسیع تجربے کے باوجود ہماری وجدان ہمیں مسلسل ناکام رہی۔ مثال کے طور پر، ہم نے CDN پراکسی، یا TCP Anycast کے رویے کے استعمال سے متوقع رفتار کی غلط پیش گوئی کی۔
- پیداوار سے ڈیٹا حاصل کریں۔
جتنی جلدی ممکن ہو کم از کم پیداواری ڈیٹا تک رسائی حاصل کرنا ضروری ہے۔ لیبارٹری کے حالات میں منفرد کیسز، کنفیگریشنز اور سیٹنگز کی تعداد حاصل کرنا تقریباً ناممکن ہے۔ نتائج تک فوری رسائی آپ کو ممکنہ مسائل کے بارے میں فوری طور پر جاننے اور سسٹم کے فن تعمیر میں ان کو مدنظر رکھنے کی اجازت دے گی۔
- دوسرے لوگوں کے مشوروں اور نتائج پر عمل نہ کریں - اپنا ڈیٹا اکٹھا کریں۔
ڈیٹا اکٹھا کرنے اور ان کا تجزیہ کرنے کے اصولوں پر عمل کریں، لیکن دوسرے لوگوں کے نتائج اور بیانات کو آنکھ بند کر کے قبول نہ کریں۔ صرف آپ ہی جان سکتے ہیں کہ آپ کے صارفین کے لیے کیا کام کرتا ہے۔ آپ کے سسٹمز اور آپ کے گاہک دوسری کمپنیوں سے نمایاں طور پر مختلف ہو سکتے ہیں۔ خوش قسمتی سے، تجزیہ کے اوزار اب دستیاب اور استعمال میں آسان ہیں۔ آپ جو نتائج حاصل کرتے ہیں وہ ہو سکتا ہے وہ نہ ہوں جو Netflix، Facebook، Akamai اور دیگر کمپنیاں دعوی کرتی ہیں۔ ہمارے معاملے میں، DNS درخواستوں پر TLS، HTTP2 یا اعدادوشمار کی کارکردگی Facebook، Uber، Akamai کے نتائج سے مختلف ہے - کیونکہ ہمارے پاس مختلف آلات، کلائنٹس اور ڈیٹا کا بہاؤ ہے۔
- غیر ضروری طور پر فیشن کے رجحانات کی پیروی نہ کریں اور تاثیر کا اندازہ کریں۔
سادہ شروع کریں۔ کم وقت میں کام کرنے کا ایک سادہ نظام بنانا بہتر ہے اس سے بہتر ہے کہ آپ بہت زیادہ وقت ایسے اجزاء تیار کرنے میں صرف کریں جن کی آپ کو ضرورت نہیں ہے۔ آپ کی پیمائش اور نتائج کی بنیاد پر اہم کاموں اور مسائل کو حل کریں۔
- نئی ایپلی کیشنز کے لیے تیار ہو جائیں۔
جس طرح تمام مسائل کا اندازہ لگانا مشکل ہے اسی طرح فوائد اور ایپلی کیشنز کا پیشگی اندازہ لگانا بھی مشکل ہے۔ سٹارٹ اپس سے ایک اشارہ لیں - گاہک کے حالات کے مطابق ڈھالنے کی ان کی صلاحیت۔ آپ کے معاملے میں، آپ نئے مسائل اور ان کے حل تلاش کر سکتے ہیں۔ اپنے پروجیکٹ میں، ہم نے درخواست میں تاخیر کو کم کرنے کا ایک ہدف مقرر کیا ہے۔ تاہم، تجزیہ اور بات چیت کے دوران، ہم نے محسوس کیا کہ ہم پراکسی سرورز بھی استعمال کر سکتے ہیں:
- AWS علاقوں میں ٹریفک کو متوازن کرنے اور اخراجات کو کم کرنے کے لیے؛
- CDN استحکام کو ماڈل بنانے کے لیے؛
- DNS ترتیب دینے کے لیے؛
- TLS/TCP کو ترتیب دینے کے لیے۔
حاصل يہ ہوا
رپورٹ میں، میں نے بتایا کہ نیٹ فلکس کس طرح کلائنٹس اور کلاؤڈ کے درمیان انٹرنیٹ کی درخواستوں کو تیز کرنے کا مسئلہ حل کرتا ہے۔ کس طرح ہم کلائنٹس پر نمونے لینے کے نظام کا استعمال کرتے ہوئے ڈیٹا اکٹھا کرتے ہیں، اور جمع کردہ تاریخی ڈیٹا کو کلائنٹس کی جانب سے پروڈکشن کی درخواستوں کو انٹرنیٹ پر تیز ترین راستے سے روٹ کرنے کے لیے استعمال کرتے ہیں۔ اس کام کو حاصل کرنے کے لیے ہم نیٹ ورک پروٹوکول، اپنے CDN انفراسٹرکچر، بیک بون نیٹ ورک، اور DNS سرورز کے اصولوں کو کس طرح استعمال کرتے ہیں۔
تاہم، ہمارا حل صرف ایک مثال ہے کہ ہم نے Netflix پر اس طرح کے نظام کو کیسے نافذ کیا۔ ہمارے لئے کیا کام کیا. آپ کے لیے میری رپورٹ کا اطلاق شدہ حصہ ترقی اور تعاون کے اصول ہیں جن پر ہم عمل کرتے ہیں اور اچھے نتائج حاصل کرتے ہیں۔
ہمارے مسئلے کا حل شاید آپ کے مطابق نہ ہو۔ تاہم، تھیوری اور ڈیزائن کے اصول باقی ہیں، چاہے آپ کا اپنا CDN انفراسٹرکچر نہ ہو، یا اگر یہ ہمارے سے نمایاں طور پر مختلف ہو۔
کاروباری درخواستوں کی رفتار کی اہمیت بھی اہم رہتی ہے۔ اور یہاں تک کہ ایک سادہ سروس کے لیے بھی آپ کو انتخاب کرنے کی ضرورت ہے: کلاؤڈ فراہم کنندگان، سرور کی جگہ، CDN اور DNS فراہم کنندگان کے درمیان۔ آپ کا انتخاب آپ کے صارفین کے لیے انٹرنیٹ کے سوالات کی تاثیر کو متاثر کرے گا۔ اور آپ کے لیے اس اثر و رسوخ کی پیمائش اور سمجھنا ضروری ہے۔
آسان حل کے ساتھ شروع کریں، اس بات کا خیال رکھیں کہ آپ پروڈکٹ کو کیسے تبدیل کرتے ہیں۔ جاتے جاتے سیکھیں اور اپنے صارفین، اپنے انفراسٹرکچر اور اپنے کاروبار کے ڈیٹا کی بنیاد پر سسٹم کو بہتر بنائیں۔ ڈیزائن کے عمل کے دوران غیر متوقع خرابی کے امکان کے بارے میں سوچیں۔ اور پھر آپ اپنے ترقیاتی عمل کو تیز کر سکتے ہیں، حل کی کارکردگی کو بہتر بنا سکتے ہیں، غیر ضروری امدادی بوجھ سے بچ سکتے ہیں اور سکون سے سو سکتے ہیں۔
اس سال آن لائن فارمیٹ میں۔ آپ DevOps کے باپوں میں سے ایک سے سوالات پوچھ سکتے ہیں، جان ولس خود!
ماخذ: www.habr.com
