

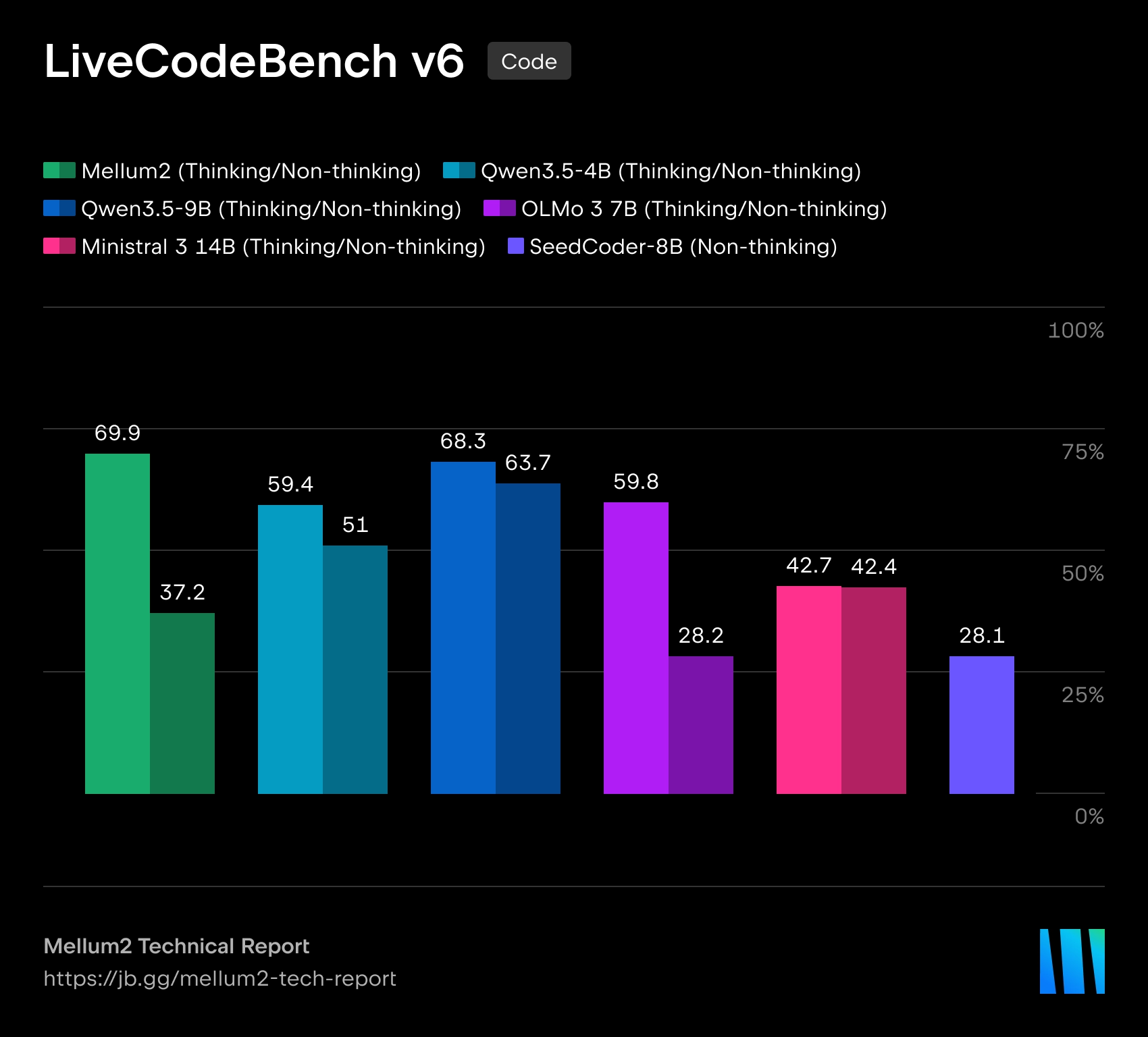
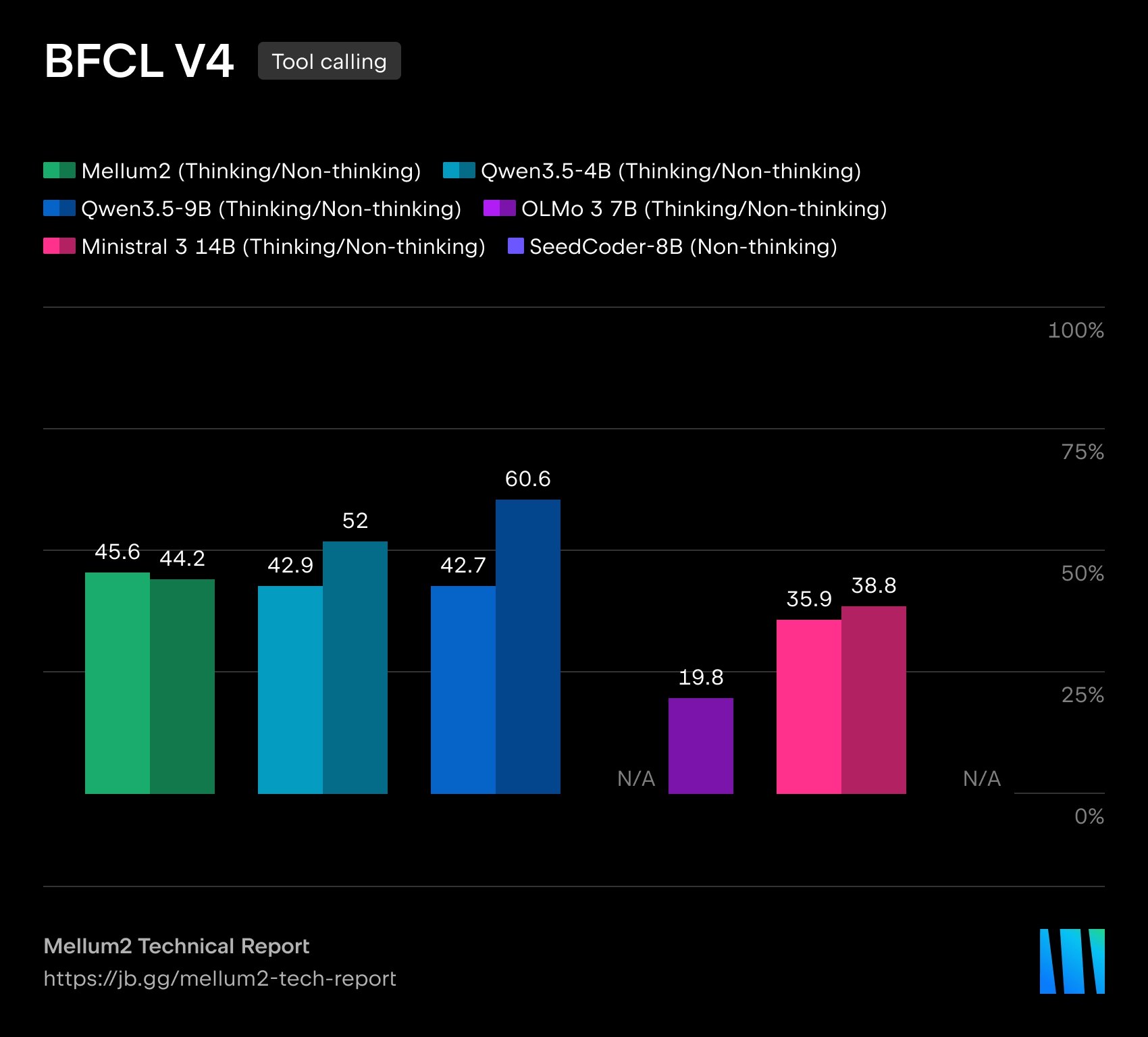
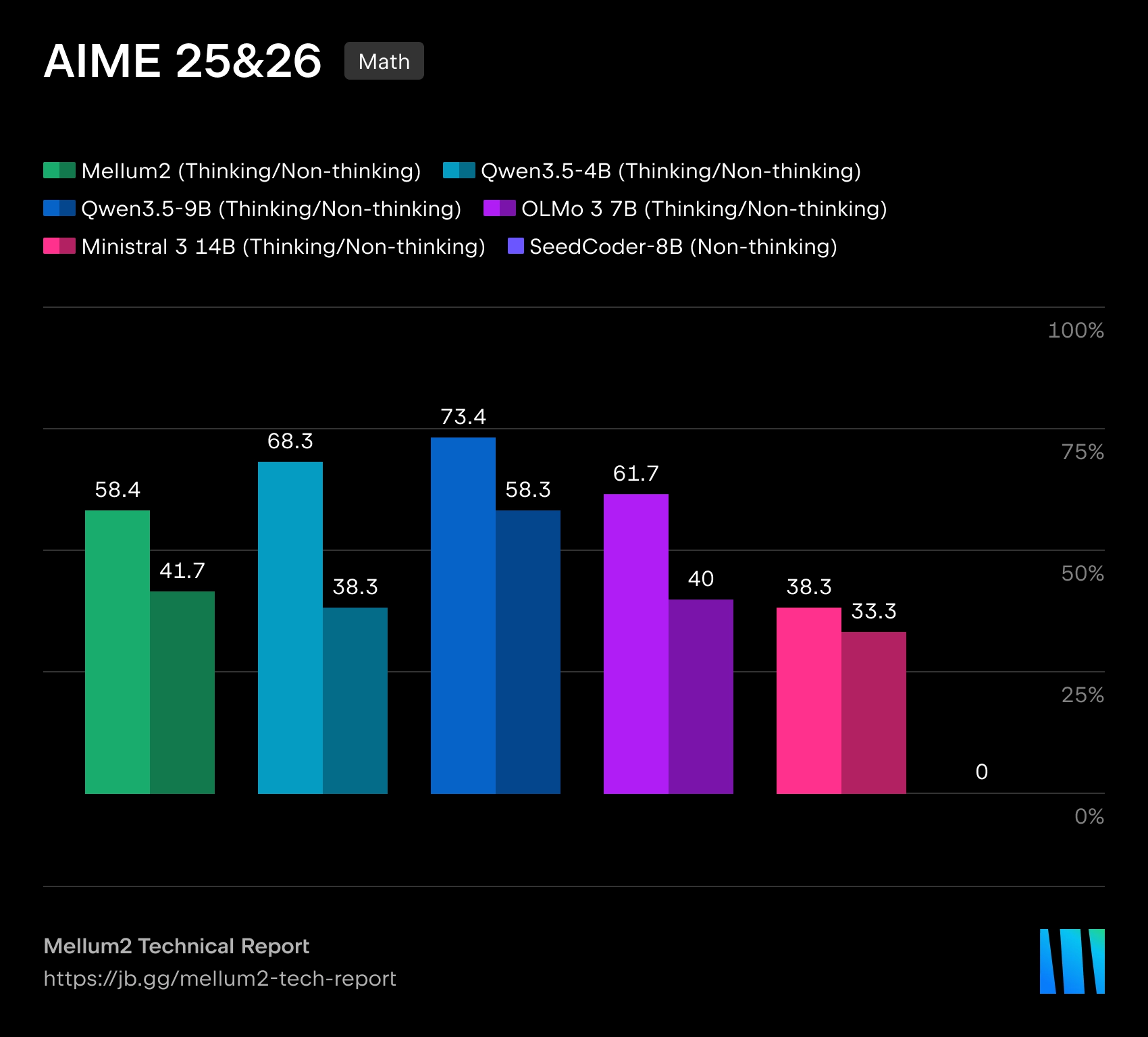
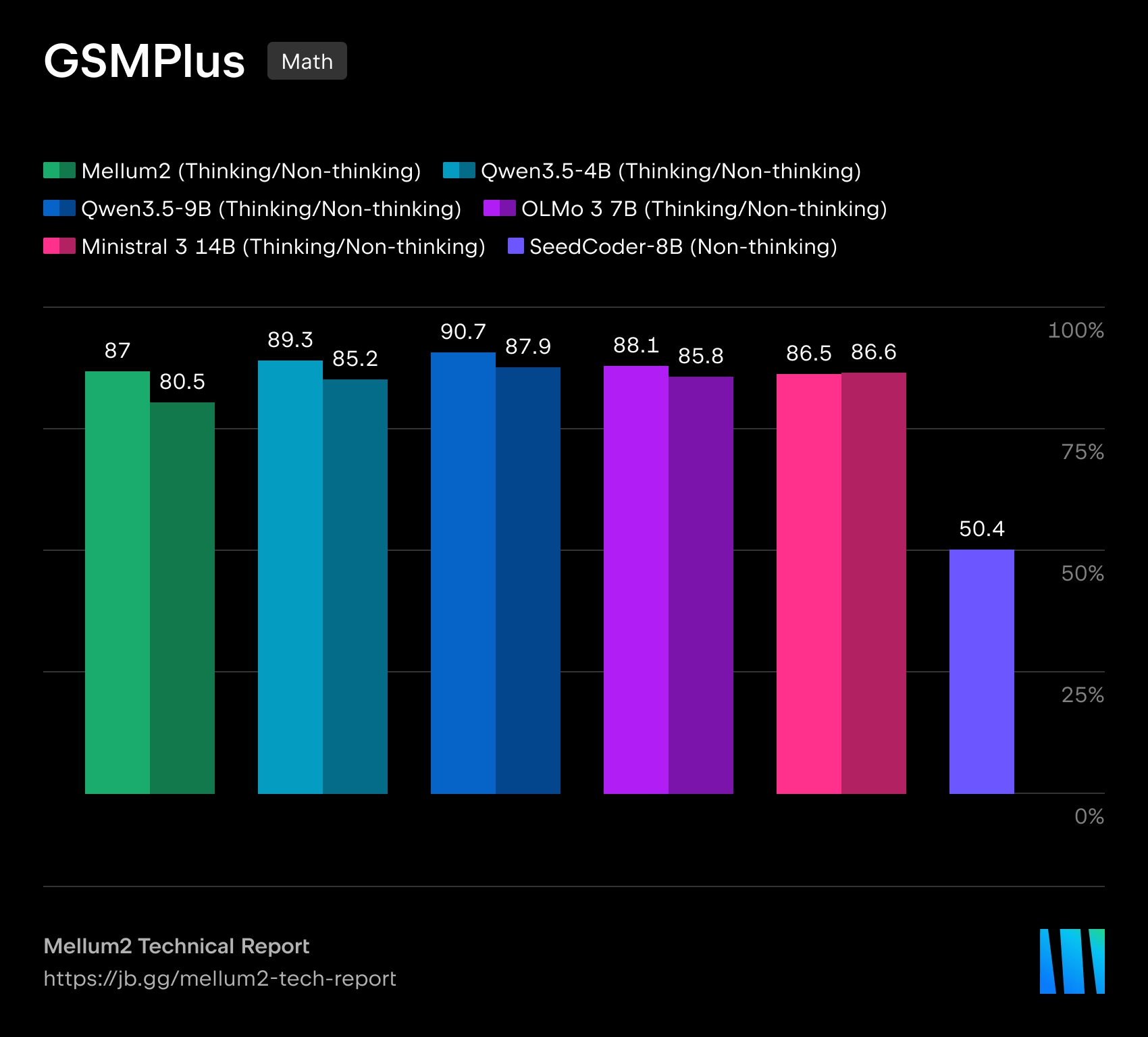
JetBrains đã mở một mô hình Mellum2Được thiết kế để sử dụng trong các công cụ AI cho phát triển phần mềm. Mô hình này được công bố theo giấy phép. Apache 2.0Thông tin về trọng số có sẵn trên Hugging Face. JetBrains nhấn mạnh rằng Mellum2 được huấn luyện từ đầu và được thiết kế không phải cho các tác vụ đa phương thức, mà để làm việc với văn bản và mã: định tuyến yêu cầu, đường dẫn RAG, tóm tắt, tác nhân phụ trợ và triển khai riêng trong cơ sở hạ tầng của công ty.
Mellum2 được xây dựng trên kiến trúc Sự kết hợp của các chuyên giaVới tổng kích thước là 12 tỷ thông số Chỉ khoảng 1000 token được kích hoạt. 2.5 tỷ thông sốĐiều này sẽ giúp giảm chi phí tính toán và độ trễ trong quá trình suy luận. Theo JetBrains, hiệu năng chuẩn của mô hình tương đương với các mô hình mã nguồn mở có kích thước tương tự, nhưng mang lại tốc độ suy luận nhanh hơn gấp đôi.
JetBrains mô tả Mellum2 là sự phát triển của mô hình Mellum ban đầu, được tạo ra để hoàn thành mã lệnh. Phiên bản mới mở rộng sang nhiều nhiệm vụ hơn, đòi hỏi làm việc với cả mã chương trình và ngôn ngữ tự nhiên. Công ty định vị Mellum2 là một mô hình "chuyên biệt" - không phải là sự thay thế cho các mô hình ngôn ngữ tự nhiên đa năng, mà là một thành phần chuyên dụng, nhanh chóng cho các thao tác trung gian thường xuyên trong các hệ thống AI phức tạp.
Trong số các trường hợp sử dụng được đề xuất có: được gọi là Phân loại và định tuyến yêu cầu giữa các mô hình và công cụ, nén và xử lý ngữ cảnh trong hệ thống RAG, chuẩn bị dữ liệu cho các tác nhân, lập lịch, xác thực kết quả trung gian và thực thi cục bộ trong môi trường không thể gửi mã nguồn hoặc dữ liệu nội bộ đến API bên ngoài.
Trên khuôn mặt ôm xuất bản một bộ sưu tập Mellum 2Bao gồm một số biến thể mô hình: Thinking, Instruct, Thinking-SFT, Instruct-SFT, Base và Base-Pretrain. Các mô hình được phân phối ở định dạng Safetensors theo giấy phép Apache 2.0.
Các ví dụ về cách sử dụng thông qua Transformers, vLLM, SGLang và Docker Model Runner được cung cấp để khởi chạy.
Điều thú vị hơn về mặt kỹ thuật không phải là sự xuất hiện của một mô hình mã nguồn mở khác, mà là phân khúc thị trường ngách mà JetBrains đã chọn. Công ty không tập trung vào cạnh tranh với các mô hình đa năng lớn nhất, mà tập trung vào các thành phần chi phí thấp và tốc độ nhanh có thể tích hợp trực tiếp vào IDE, trợ lý nội bộ, hệ thống RAG của doanh nghiệp và các quy trình xử lý tác nhân. Đối với các nhà phát triển và công ty, điều này có nghĩa là khả năng chạy một số logic AI cục bộ hoặc trên máy chủ riêng của họ, đồng thời vẫn duy trì quyền kiểm soát mã, dữ liệu và chi phí suy luận.
Nguồn: linux.org.ru
