

Chúng ta sẽ xem cách Zabbix hoạt động với cơ sở dữ liệu TimescaleDB làm phần phụ trợ. Chúng tôi sẽ chỉ cho bạn cách bắt đầu lại từ đầu và cách di chuyển từ PostgreSQL. Chúng tôi cũng sẽ cung cấp các bài kiểm tra hiệu suất so sánh của hai cấu hình.

HighLoad++ Siberia 2019. Hội trường Tomsk. Ngày 24 tháng 16, 00:XNUMX. Luận văn và . Hội nghị HighLoad++ tiếp theo sẽ được tổ chức vào ngày 6 và 7 tháng 2020 năm XNUMX tại St. Petersburg. Thông tin chi tiết và vé .
Andrey Gushchin (sau đây gọi là – AG): – Tôi là kỹ sư hỗ trợ kỹ thuật ZABBIX (sau đây gọi tắt là “Zabbix”), một huấn luyện viên. Tôi đã làm việc ở bộ phận hỗ trợ kỹ thuật hơn 6 năm và có kinh nghiệm trực tiếp về hiệu suất. Hôm nay tôi sẽ nói về hiệu suất mà TimescaleDB có thể cung cấp khi so sánh với PostgreSQL 10 thông thường. Ngoài ra, một số phần giới thiệu về cách hoạt động của nó nói chung.
Những thách thức hàng đầu về năng suất: từ thu thập dữ liệu đến làm sạch dữ liệu
Đầu tiên, có một số thách thức về hiệu suất nhất định mà mọi hệ thống giám sát đều phải đối mặt. Thử thách năng suất đầu tiên là thu thập và xử lý dữ liệu nhanh chóng.

Một hệ thống giám sát tốt phải nhanh chóng, kịp thời nhận tất cả dữ liệu, xử lý dữ liệu theo biểu thức kích hoạt, nghĩa là xử lý dữ liệu theo một số tiêu chí (điều này khác nhau ở các hệ thống khác nhau) và lưu vào cơ sở dữ liệu để sử dụng dữ liệu này trong tương lai.

Thử thách hiệu suất thứ hai là lưu trữ lịch sử. Lưu trữ trong cơ sở dữ liệu thường xuyên và có quyền truy cập nhanh chóng và thuận tiện vào các số liệu được thu thập trong một khoảng thời gian này. Điều quan trọng nhất là dữ liệu này thuận tiện để lấy, sử dụng nó trong các báo cáo, đồ thị, trình kích hoạt, trong một số giá trị ngưỡng, cho cảnh báo, v.v.

Thử thách hiệu suất thứ ba là xóa lịch sử, tức là khi bạn không cần lưu trữ bất kỳ số liệu chi tiết nào đã được thu thập trong 5 năm (thậm chí vài tháng hoặc hai tháng). Một số nút mạng đã bị xóa hoặc một số máy chủ, các số liệu không còn cần thiết nữa vì chúng đã lỗi thời và không còn được thu thập nữa. Tất cả điều này cần phải được dọn sạch để cơ sở dữ liệu của bạn không phát triển quá lớn. Nhìn chung, việc xóa lịch sử thường là một bài kiểm tra nghiêm túc đối với bộ nhớ - nó thường có tác động rất mạnh đến hiệu suất.
Làm thế nào để giải quyết vấn đề bộ nhớ đệm?
Bây giờ tôi sẽ nói cụ thể về Zabbix. Trong Zabbix, cuộc gọi đầu tiên và thứ hai được giải quyết bằng bộ nhớ đệm.

Thu thập và xử lý dữ liệu - Chúng tôi sử dụng RAM để lưu trữ tất cả dữ liệu này. Những dữ liệu này bây giờ sẽ được thảo luận chi tiết hơn.
Ngoài ra, về phía cơ sở dữ liệu còn có một số bộ đệm cho các lựa chọn chính - cho đồ thị và những thứ khác.
Bộ nhớ đệm bên cạnh máy chủ Zabbix: chúng tôi có ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Nó là gì?

ConfigurationCache là bộ đệm chính trong đó chúng tôi lưu trữ số liệu, máy chủ, mục dữ liệu, trình kích hoạt; mọi thứ bạn cần để xử lý tiền xử lý, thu thập dữ liệu, thu thập từ máy chủ nào, với tần suất như thế nào. Tất cả điều này được lưu trữ trong ConfigurationCache để không đi tới cơ sở dữ liệu và tạo các truy vấn không cần thiết. Sau khi máy chủ khởi động, chúng tôi cập nhật bộ đệm này (tạo nó) và cập nhật định kỳ (tùy thuộc vào cài đặt cấu hình).
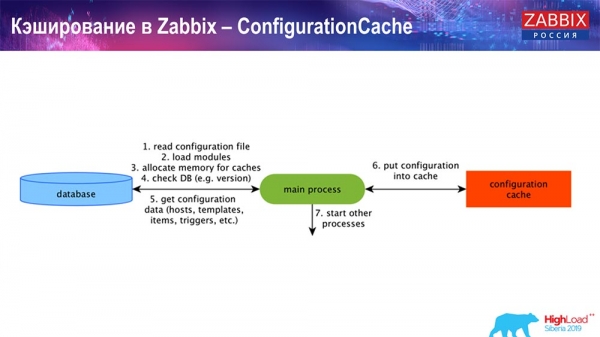
Bộ nhớ đệm trong Zabbix. Thu thập dữ liệu
Ở đây sơ đồ khá lớn:
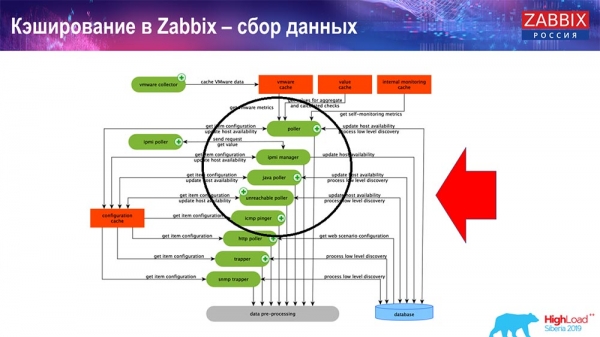
Những người chính trong chương trình này là những người thu thập:
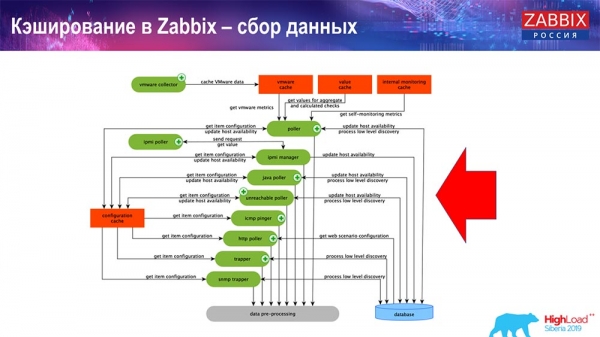
Bản thân đây là các quy trình lắp ráp, các "người thăm dò" khác nhau chịu trách nhiệm về các loại lắp ráp khác nhau. Họ thu thập dữ liệu qua icmp, ipmi và các giao thức khác nhau và chuyển tất cả sang tiền xử lý.
Lịch sử tiền xử lýCache
Ngoài ra, nếu chúng tôi có các phần tử dữ liệu được tính toán (những người quen thuộc với Zabbix đều biết), tức là các phần tử dữ liệu được tính toán, tổng hợp, chúng tôi sẽ lấy chúng trực tiếp từ ValueCache. Tôi sẽ cho bạn biết nó được lấp đầy như thế nào sau. Tất cả những người thu thập này sử dụng ConfigurationCache để nhận công việc của họ và sau đó chuyển chúng sang tiền xử lý.
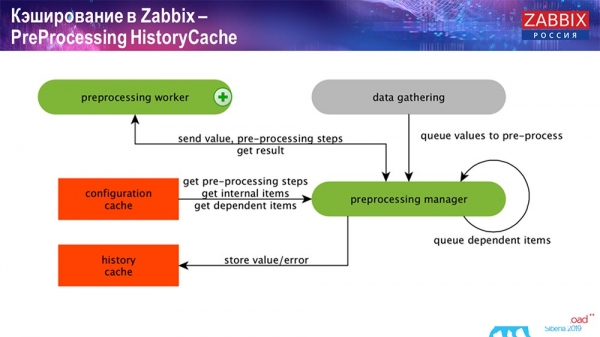
Quá trình tiền xử lý cũng sử dụng ConfigurationCache để lấy các bước tiền xử lý và xử lý dữ liệu này theo nhiều cách khác nhau. Bắt đầu từ phiên bản 4.2, chúng tôi đã chuyển nó sang proxy. Điều này rất thuận tiện vì bản thân quá trình tiền xử lý là một thao tác khá khó khăn. Và nếu bạn có Zabbix rất lớn, với số lượng lớn các phần tử dữ liệu và tần suất thu thập cao, thì điều này giúp đơn giản hóa công việc rất nhiều.
Theo đó, sau khi chúng tôi xử lý dữ liệu này theo cách nào đó bằng cách sử dụng tiền xử lý, chúng tôi sẽ lưu dữ liệu đó vào HistoryCache để xử lý thêm. Điều này kết thúc việc thu thập dữ liệu. Chúng tôi chuyển sang quá trình chính.
Công việc của trình đồng bộ hóa lịch sử
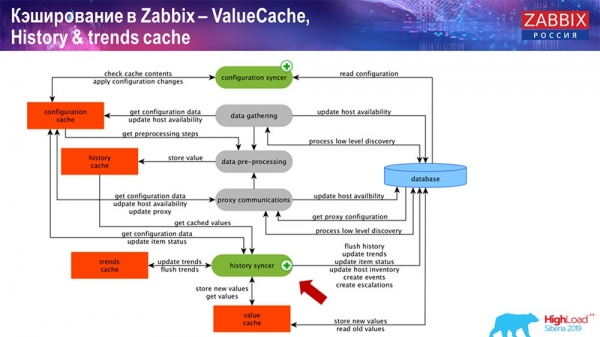
Quá trình chính trong Zabbix (vì nó là kiến trúc nguyên khối) là trình đồng bộ hóa Lịch sử. Đây là quy trình chính liên quan cụ thể đến việc xử lý nguyên tử của từng thành phần dữ liệu, nghĩa là từng giá trị:
- giá trị đến (lấy từ HistoryCache);
- kiểm tra trong Trình đồng bộ hóa cấu hình: liệu có bất kỳ trình kích hoạt nào để tính toán hay không - tính toán chúng;
nếu có - tạo sự kiện, tạo báo cáo để tạo cảnh báo, nếu cần theo cấu hình; - hồ sơ kích hoạt để xử lý, tổng hợp tiếp theo; nếu bạn tổng hợp trong giờ qua, v.v., giá trị này sẽ được ValueCache ghi nhớ để không đi vào bảng lịch sử; Do đó, ValueCache chứa đầy dữ liệu cần thiết để tính toán trình kích hoạt, phần tử được tính toán, v.v.;
- sau đó trình đồng bộ hóa Lịch sử ghi tất cả dữ liệu vào cơ sở dữ liệu;
- cơ sở dữ liệu ghi chúng vào đĩa - đây là lúc quá trình xử lý kết thúc.
Cơ sở dữ liệu. Bộ nhớ đệm
Về phía cơ sở dữ liệu, khi bạn muốn xem biểu đồ hoặc một số báo cáo về các sự kiện, có nhiều bộ nhớ đệm khác nhau. Nhưng trong báo cáo này tôi sẽ không nói về họ.
Đối với MySQL, có Innodb_buffer_pool và một loạt các bộ nhớ đệm khác nhau cũng có thể được cấu hình.
Nhưng đây là những cái chính:
- chia sẻ_buffers;
- hiệu quả_cache_size;
- Bể bơi chung.

Đối với tất cả các cơ sở dữ liệu, tôi đã nói rằng có một số bộ đệm nhất định cho phép bạn lưu trữ trong RAM dữ liệu thường cần cho các truy vấn. Họ có công nghệ riêng cho việc này.
Giới thiệu về hiệu suất cơ sở dữ liệu
Theo đó, có một môi trường cạnh tranh, tức là máy chủ Zabbix thu thập dữ liệu và ghi lại. Khi được khởi động lại, nó cũng đọc từ lịch sử để điền vào ValueCache, v.v. Tại đây, bạn có thể có các tập lệnh và báo cáo sử dụng API Zabbix, được xây dựng trên giao diện web. API Zabbix vào cơ sở dữ liệu và nhận dữ liệu cần thiết để lấy biểu đồ, báo cáo hoặc một số loại danh sách sự kiện, sự cố gần đây.
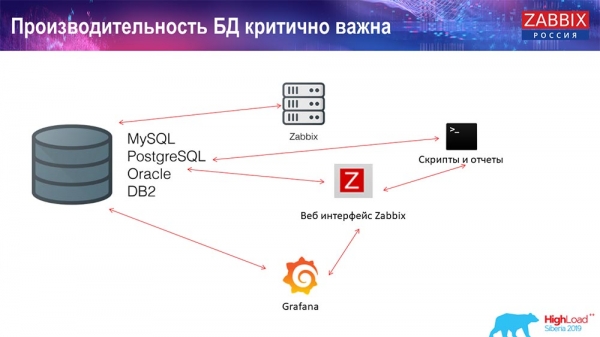
Ngoài ra, một giải pháp trực quan hóa rất phổ biến là Grafana mà người dùng của chúng tôi sử dụng. Có thể đăng nhập trực tiếp cả thông qua API Zabbix và thông qua cơ sở dữ liệu. Nó cũng tạo ra một sự cạnh tranh nhất định trong việc thu thập dữ liệu: cần phải điều chỉnh cơ sở dữ liệu tốt hơn, tốt hơn để tuân thủ việc cung cấp kết quả và thử nghiệm nhanh chóng.

Xóa lịch sử. Zabbix có quản gia
Lệnh gọi thứ ba được sử dụng trong Zabbix là xóa lịch sử bằng Housekeeper. Housekeeper tuân theo tất cả các cài đặt, nghĩa là các yếu tố dữ liệu của chúng tôi cho biết thời gian lưu trữ (tính theo ngày), xu hướng lưu trữ trong bao lâu và động lực của các thay đổi.
Tôi chưa nói về TrendCache, thứ mà chúng tôi tính toán nhanh chóng: dữ liệu đến, chúng tôi tổng hợp trong một giờ (chủ yếu đây là những con số cho giờ trước), số lượng là trung bình/tối thiểu và chúng tôi ghi lại mỗi giờ một lần trong bảng về động lực của những thay đổi (“Xu hướng”). “Quản gia” bắt đầu và xóa dữ liệu khỏi cơ sở dữ liệu bằng các lựa chọn thông thường, việc này không phải lúc nào cũng hiệu quả.
Làm thế nào để hiểu rằng nó không hiệu quả? Bạn có thể xem hình ảnh sau trên biểu đồ hiệu suất của các quy trình nội bộ:
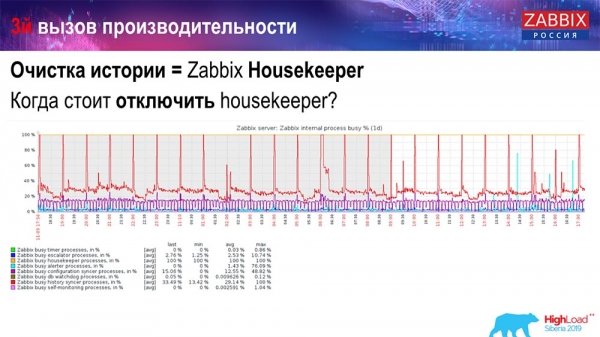
Trình đồng bộ hóa Lịch sử của bạn liên tục bận (biểu đồ màu đỏ). Và biểu đồ “màu đỏ” ở trên cùng. Đây là một “Quản gia” khởi động và chờ cơ sở dữ liệu xóa tất cả các hàng mà nó đã chỉ định.
Hãy lấy một số ID vật phẩm: bạn cần xóa 5 nghìn cuối cùng; tất nhiên là theo chỉ số. Nhưng thông thường tập dữ liệu khá lớn - cơ sở dữ liệu vẫn đọc nó từ đĩa và đặt nó vào bộ nhớ đệm, và đây là một thao tác rất tốn kém đối với cơ sở dữ liệu. Tùy thuộc vào kích thước của nó, điều này có thể dẫn đến một số vấn đề về hiệu suất.
Bạn có thể vô hiệu hóa Housekeeper một cách đơn giản - chúng ta có giao diện web quen thuộc. Cài đặt trong phần Quản trị chung (cài đặt cho “Quản gia”), chúng tôi vô hiệu hóa công việc quản lý nội bộ đối với lịch sử và xu hướng nội bộ. Theo đó, Housekeeper không còn kiểm soát việc này:

Bạn có thể làm gì tiếp theo? Bạn đã tắt nó đi, đồ thị của bạn đã cân bằng... Những vấn đề gì nữa có thể phát sinh trong trường hợp này? Điều gì có thể giúp đỡ?
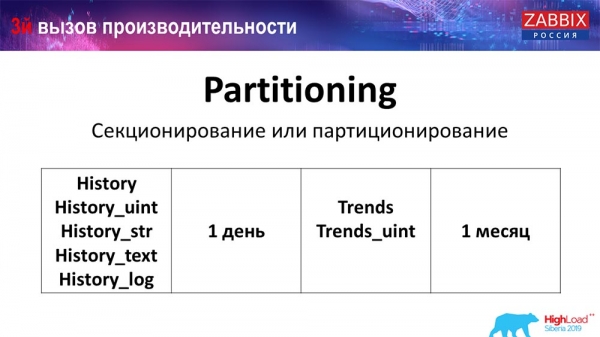
Phân vùng (phân vùng)
Thông thường, điều này được cấu hình theo một cách khác trên mỗi cơ sở dữ liệu quan hệ mà tôi đã liệt kê. MySQL có công nghệ riêng của mình. Nhưng nhìn chung chúng rất giống nhau khi nói đến PostgreSQL 10 và MySQL. Tất nhiên, có rất nhiều khác biệt nội bộ về cách triển khai và cách tất cả ảnh hưởng đến hiệu suất. Nhưng nhìn chung việc tạo phân vùng mới cũng thường dẫn đến những vấn đề nhất định.

Tùy thuộc vào thiết lập của bạn (lượng dữ liệu bạn tạo trong một ngày), họ thường đặt mức tối thiểu - đây là 1 ngày / đợt và đối với “xu hướng”, động lực thay đổi - 1 tháng / đợt mới. Điều này có thể thay đổi nếu bạn có một thiết lập rất lớn.
Hãy nói ngay về kích thước của thiết lập: lên tới 5 nghìn giá trị mới mỗi giây (được gọi là nvps) - đây sẽ được coi là một “thiết lập” nhỏ. Trung bình – từ 5 đến 25 nghìn giá trị mỗi giây. Tất cả những gì ở trên đã là các bản cài đặt lớn và rất lớn, yêu cầu cấu hình cơ sở dữ liệu rất cẩn thận.
Đối với các cài đặt rất lớn, 1 ngày có thể không tối ưu. Cá nhân tôi đã thấy các phân vùng trên MySQL có dung lượng 40 gigabyte mỗi ngày (và có thể nhiều hơn nữa). Đây là một lượng dữ liệu rất lớn, có thể dẫn đến một số vấn đề. Nó cần phải được giảm bớt.
Tại sao bạn cần phân vùng?
Tôi nghĩ mọi người đều biết những gì Phân vùng cung cấp là phân vùng bảng. Thông thường đây là các tệp riêng biệt trên các yêu cầu đĩa và nhịp. Nó chọn một phân vùng tối ưu hơn nếu nó là một phần của phân vùng thông thường.
Đặc biệt, đối với Zabbix, nó được sử dụng theo phạm vi, theo phạm vi, nghĩa là chúng tôi sử dụng dấu thời gian (một số thông thường, thời gian kể từ đầu kỷ nguyên). Bạn chỉ định ngày bắt đầu/cuối ngày và đây là phân vùng. Theo đó, nếu bạn yêu cầu dữ liệu đã cũ hai ngày, mọi thứ sẽ được truy xuất từ cơ sở dữ liệu nhanh hơn vì bạn chỉ cần tải một tệp vào bộ đệm và trả lại nó (chứ không phải một bảng lớn).

Nhiều cơ sở dữ liệu còn tăng tốc độ chèn (chèn vào 1 bảng con). Bây giờ tôi đang nói một cách trừu tượng, nhưng điều này cũng có thể xảy ra. Việc phân chia thường giúp ích.
Elaticsearch cho NoSQL
Gần đây, trong phiên bản 3.4, chúng tôi đã triển khai giải pháp NoSQL. Đã thêm khả năng viết trong Elaticsearch. Bạn có thể viết một số loại nhất định: bạn chọn - viết số hoặc một số dấu hiệu; chúng ta có string text, các bạn có thể ghi log vào Elaticsearch... Theo đó, giao diện web cũng sẽ truy cập vào Elaticsearch. Điều này hoạt động tốt trong một số trường hợp, nhưng hiện tại nó có thể được sử dụng.

Thang thời gianDB. Siêu bảng
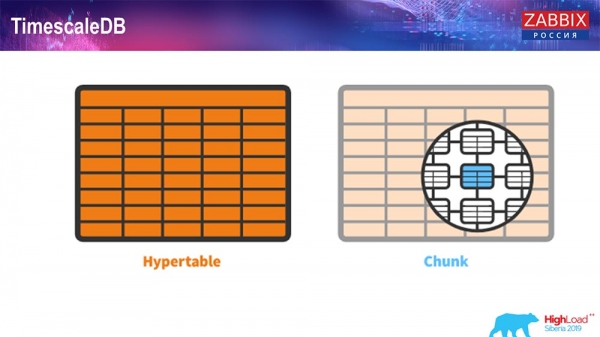
Đối với 4.4.2, chúng tôi đã chú ý đến một thứ như TimescaleDB. Nó là gì? Đây là một phần mở rộng cho PostgreSQL, nghĩa là nó có giao diện PostgreSQL gốc. Ngoài ra, tiện ích mở rộng này cho phép bạn làm việc hiệu quả hơn nhiều với dữ liệu chuỗi thời gian và có tính năng phân vùng tự động. Nó trông như thế nào:

Điều này thật khó tin - có một khái niệm như vậy trong Timescale. Đây là một siêu bảng mà bạn tạo và nó chứa các đoạn. Chunks là các phân vùng, đây là các bảng con, nếu tôi không nhầm. Nó thực sự hiệu quả.
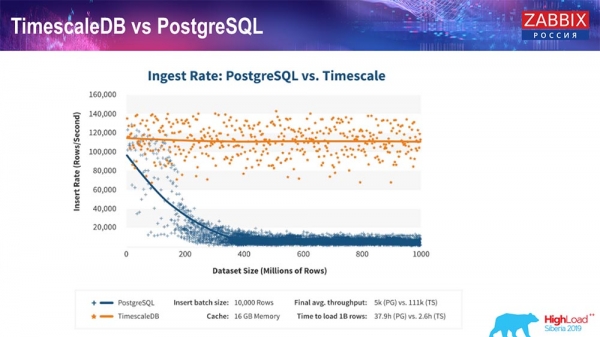
TimescaleDB và PostgreSQL
Như các nhà sản xuất TimescaleDB đảm bảo, họ sử dụng thuật toán chính xác hơn để xử lý các truy vấn, đặc biệt là các phần chèn cụ thể, cho phép chúng có hiệu suất gần như không đổi khi kích thước của phần chèn tập dữ liệu ngày càng tăng. Nghĩa là, sau 200 triệu hàng Postgres, hàng thông thường bắt đầu bị chùng xuống rất nhiều và mất hiệu suất theo đúng nghĩa đen về XNUMX, trong khi Timescale cho phép bạn chèn các phần chèn một cách hiệu quả nhất có thể với bất kỳ lượng dữ liệu nào.
Làm cách nào để cài đặt TimescaleDB? Thật đơn giản!
Nó có trong tài liệu, nó được mô tả - bạn có thể cài đặt nó từ các gói cho bất kỳ... Nó phụ thuộc vào các gói Postgres chính thức. Có thể được biên dịch bằng tay. Điều đó xảy ra đến mức tôi phải biên dịch cơ sở dữ liệu.
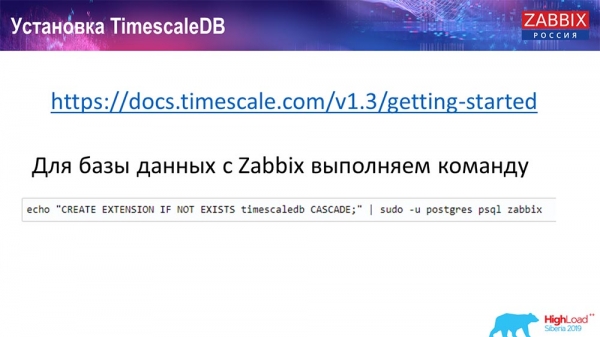
Trên Zabbix, chúng tôi chỉ cần kích hoạt Extention. Tôi nghĩ rằng những người đã sử dụng Extention trong Postgres... Bạn chỉ cần kích hoạt Extention, tạo nó cho cơ sở dữ liệu Zabbix mà bạn đang sử dụng.
Và bước cuối cùng...
Thang thời gianDB. Di chuyển các bảng lịch sử
Bạn cần tạo một siêu bảng. Có một chức năng đặc biệt cho việc này – Tạo siêu bảng. Trong đó, tham số đầu tiên là bảng cần thiết trong cơ sở dữ liệu này (mà bạn cần tạo một siêu bảng).

Trường cần tạo và chunk_time_interval (đây là khoảng thời gian của các đoạn (phân vùng cần được sử dụng). 86 là một ngày.
Tham số Migrate_data: Nếu bạn chèn thành true thì thao tác này sẽ di chuyển tất cả dữ liệu hiện tại sang các phần được tạo trước.
Bản thân tôi đã sử dụng Migrate_data - việc này mất khá nhiều thời gian, tùy thuộc vào mức độ lớn của cơ sở dữ liệu của bạn. Tôi có hơn một terabyte - mất hơn một giờ để tạo. Trong một số trường hợp, trong quá trình thử nghiệm, tôi đã xóa dữ liệu lịch sử cho văn bản (history_text) và chuỗi (history_str) để không chuyển chúng - chúng không thực sự thú vị đối với tôi.
Và chúng tôi thực hiện cập nhật cuối cùng trong db_extention của mình: chúng tôi cài đặt timescaledb để cơ sở dữ liệu và đặc biệt là Zabbix của chúng tôi hiểu rằng có db_extention. Anh ta kích hoạt nó và sử dụng cú pháp cũng như truy vấn chính xác tới cơ sở dữ liệu, sử dụng những “tính năng” cần thiết cho TimescaleDB.
Cấu hình máy chủ
Tôi đã sử dụng hai máy chủ. Máy chủ đầu tiên là một máy ảo khá nhỏ, 20 bộ xử lý, 16 gigabyte RAM. Tôi đã định cấu hình Postgres 10.8 trên đó:

Hệ điều hành là DebianHệ thống tệp – xfs. Tôi đã thực hiện các thiết lập tối thiểu để sử dụng cơ sở dữ liệu này, ngoại trừ những thiết lập mà Zabbix sẽ sử dụng. Máy chủ Zabbix, PostgreSQL và các tác nhân tải cũng được cài đặt trên máy này.

Tôi đã sử dụng 50 tác nhân đang hoạt động sử dụng LoadableModule để nhanh chóng tạo ra các kết quả khác nhau. Họ là những người tạo ra các chuỗi, số, v.v. Tôi đã lấp đầy cơ sở dữ liệu với rất nhiều dữ liệu. Ban đầu, cấu hình chứa 5 nghìn phần tử dữ liệu trên mỗi máy chủ và khoảng mỗi phần tử dữ liệu chứa một trình kích hoạt - để đây trở thành một thiết lập thực sự. Đôi khi bạn thậm chí cần nhiều hơn một trình kích hoạt để sử dụng.

Tôi đã điều chỉnh khoảng thời gian cập nhật và tải bằng cách không chỉ sử dụng 50 tác nhân (thêm nhiều hơn) mà còn sử dụng các phần tử dữ liệu động và giảm khoảng thời gian cập nhật xuống còn 4 giây.
Kiểm tra hiệu suất. PostgreSQL: 36 nghìn NVP
Lần ra mắt đầu tiên, thiết lập đầu tiên tôi có là trên PostreSQL 10 thuần túy trên phần cứng này (35 nghìn giá trị mỗi giây). Nói chung, như bạn có thể thấy trên màn hình, việc chèn dữ liệu mất chưa đầy một giây - mọi thứ đều tốt và nhanh chóng, ổ SSD (200 gigabyte). Điều duy nhất là 20 GB đầy khá nhanh.
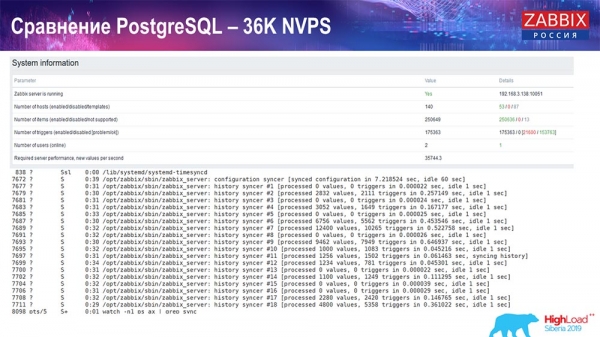
Sẽ có khá nhiều đồ thị như vậy trong tương lai. Đây là bảng điều khiển hiệu suất máy chủ Zabbix tiêu chuẩn.
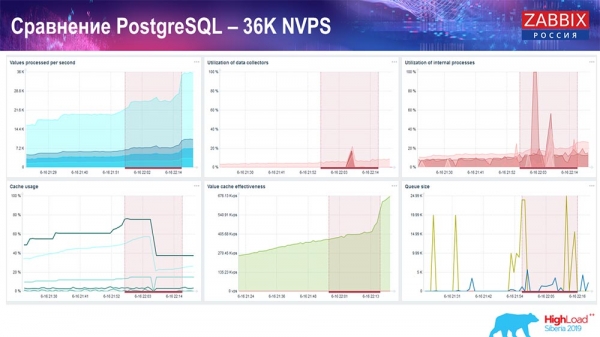
Biểu đồ đầu tiên là số lượng giá trị mỗi giây (màu xanh lam, trên cùng bên trái), 35 nghìn giá trị trong trường hợp này. Đây (trên cùng ở giữa) là quá trình tải các quy trình xây dựng và đây (trên cùng bên phải) là quá trình tải các quy trình nội bộ: bộ đồng bộ hóa lịch sử và quản gia, ở đây (ở giữa dưới cùng) đã chạy được một thời gian.
Biểu đồ này (ở giữa phía dưới) hiển thị mức sử dụng ValueCache - số lần truy cập ValueCache cho trình kích hoạt (vài nghìn giá trị mỗi giây). Một biểu đồ quan trọng khác là biểu đồ thứ tư (phía dưới bên trái), hiển thị cách sử dụng HistoryCache, mà tôi đã nói đến, là bộ đệm trước khi chèn vào cơ sở dữ liệu.
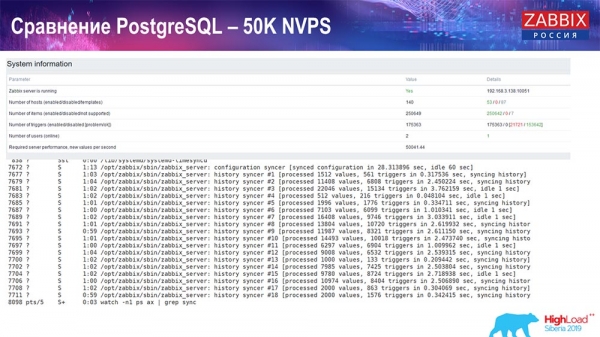
Kiểm tra hiệu suất. PostgreSQL: 50 nghìn NVP
Tiếp theo, tôi tăng tải lên 50 nghìn giá trị mỗi giây trên cùng một phần cứng. Khi được Housekeeper tải, 10 nghìn giá trị được ghi lại trong 2-3 giây kèm theo tính toán. Trên thực tế, những gì được hiển thị trong ảnh chụp màn hình sau:
“Quản gia” đã bắt đầu cản trở công việc, nhưng nhìn chung, tải trọng đối với những người đánh bẫy lịch sử vẫn ở mức 60% (biểu đồ thứ ba, trên cùng bên phải). HistoryCache đã bắt đầu được tích cực điền trong khi Housekeeper đang chạy (phía dưới bên trái). Nó nặng khoảng nửa gigabyte, đầy 20%.
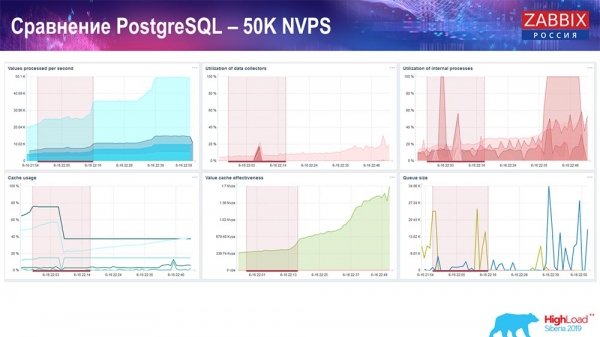
Kiểm tra hiệu suất. PostgreSQL: 80 nghìn NVP
Sau đó tôi tăng nó lên 80 nghìn giá trị mỗi giây:
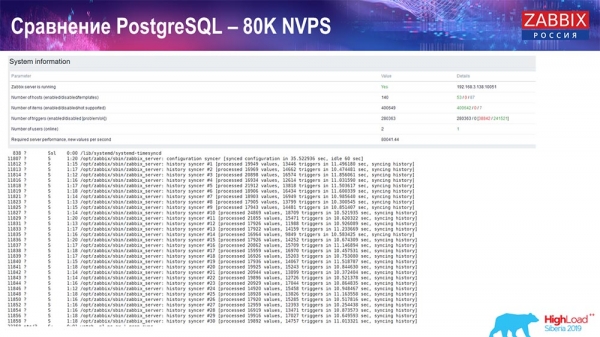
Đó là khoảng 400 nghìn phần tử dữ liệu, 280 nghìn trình kích hoạt. Như bạn có thể thấy, phần chèn này xét về mặt tải trọng của các tàu chìm trong lịch sử (có 30 chiếc trong số đó) đã khá cao. Sau đó, tôi tăng các tham số khác nhau: bộ ghi lịch sử, bộ đệm... Trên phần cứng này, tải trên bộ ghi lịch sử bắt đầu tăng đến mức tối đa, gần như “trên kệ” - theo đó, HistoryCache đã đạt mức tải rất cao:
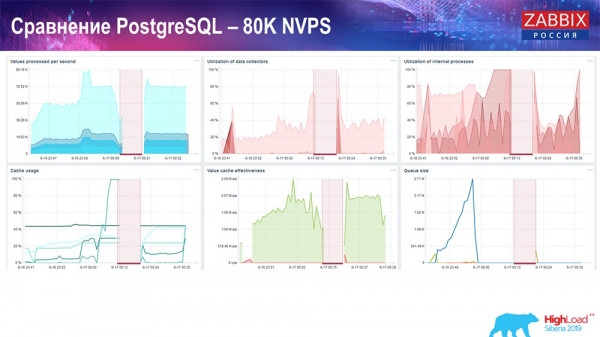
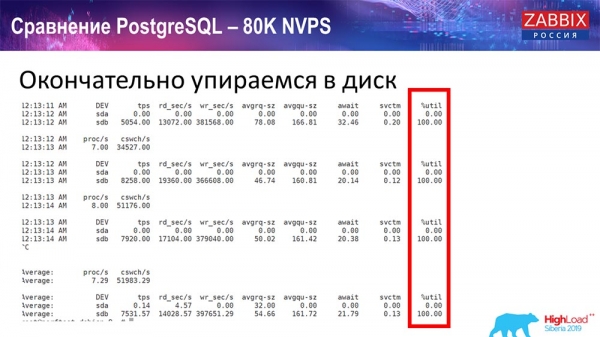
Trong suốt thời gian qua, tôi đã theo dõi tất cả các thông số hệ thống (cách sử dụng bộ xử lý, RAM) và phát hiện ra rằng mức sử dụng đĩa là tối đa - tôi đã đạt được dung lượng tối đa của đĩa này trên phần cứng này, trên máy ảo này. "Postgres" bắt đầu đổ dữ liệu khá tích cực với cường độ như vậy và đĩa không còn thời gian để ghi, đọc...
Tôi lấy một máy chủ khác đã có 48 bộ xử lý và 128 gigabyte RAM:
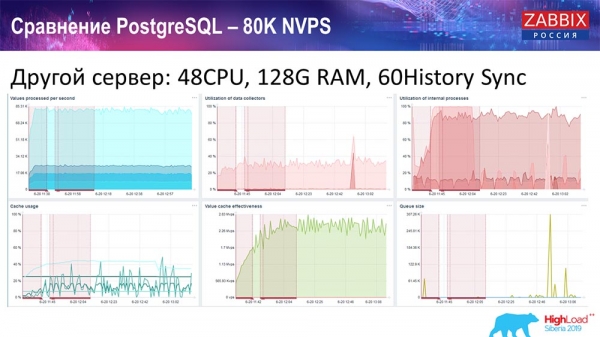
Tôi cũng đã “điều chỉnh” nó - đã cài đặt bộ đồng bộ hóa Lịch sử (60 phần) và đạt được hiệu suất chấp nhận được. Trên thực tế, chúng tôi không “ở trên kệ”, nhưng đây có lẽ là giới hạn của năng suất, nơi mà cần phải làm gì đó để giải quyết nó.
Kiểm tra hiệu suất. TimescaleDB: 80 nghìn NVP
Nhiệm vụ chính của tôi là sử dụng TimescaleDB. Mỗi biểu đồ hiển thị mức giảm:
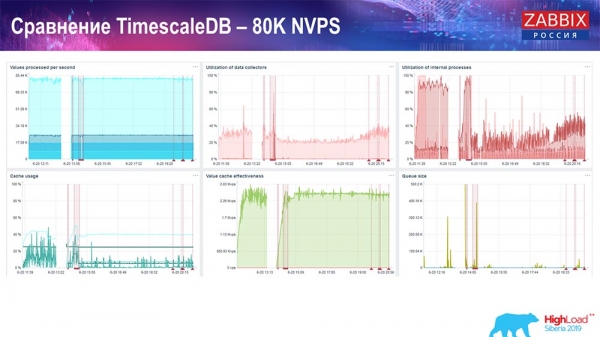
Những lỗi này chính xác là do di chuyển dữ liệu. Sau đó, trong máy chủ Zabbix, cấu hình tải của các phần tử lịch sử, như bạn có thể thấy, đã thay đổi rất nhiều. Nó cho phép bạn chèn dữ liệu nhanh hơn gần 3 lần và sử dụng ít HistoryCache hơn - theo đó, dữ liệu sẽ được gửi đúng hạn. Một lần nữa, 80 nghìn giá trị mỗi giây là một tỷ lệ khá cao (tất nhiên, không phải đối với Yandex). Nhìn chung đây là một thiết lập khá lớn, với một máy chủ.
Kiểm tra hiệu năng PostgreSQL: 120 nghìn NVP
Tiếp theo, tôi tăng giá trị số phần tử dữ liệu lên nửa triệu và nhận được giá trị tính toán là 125 nghìn mỗi giây:
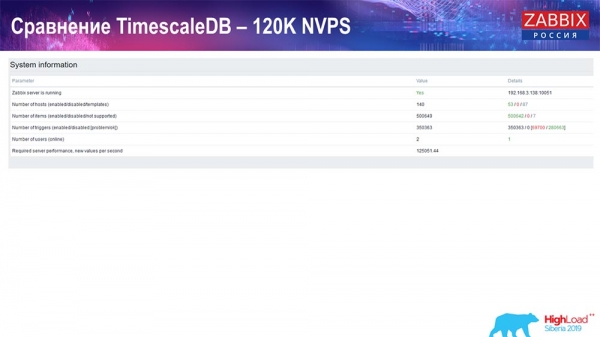
Và tôi đã nhận được những biểu đồ này:
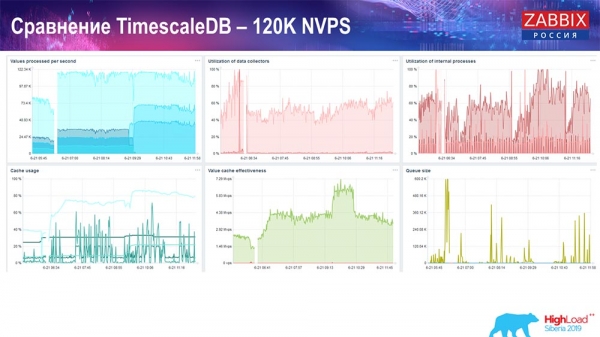
Về nguyên tắc, đây là một thiết lập hoạt động, nó có thể hoạt động trong một thời gian khá dài. Nhưng vì tôi chỉ có một chiếc đĩa 1,5 terabyte nên tôi đã dùng hết nó trong vài ngày. Điều quan trọng nhất là đồng thời các phân vùng mới đã được tạo trên TimescaleDB và điều này hoàn toàn không được chú ý về hiệu suất, điều này không thể nói về MySQL.
Thông thường, các phân vùng được tạo vào ban đêm vì điều này thường chặn việc chèn và hoạt động với các bảng và có thể dẫn đến suy giảm chất lượng dịch vụ. Trong trường hợp này thì không phải vậy! Nhiệm vụ chính là kiểm tra khả năng của TimescaleDB. Kết quả là con số sau: 120 nghìn giá trị mỗi giây.
Ngoài ra còn có các ví dụ trong cộng đồng:
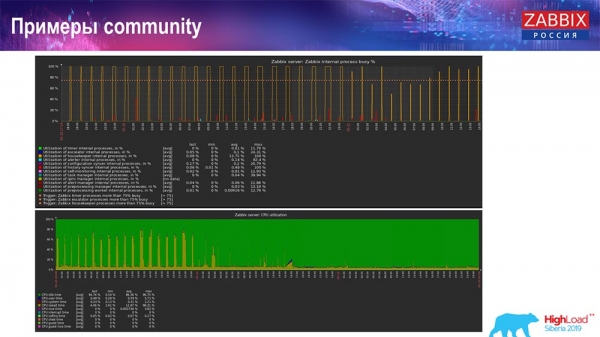
Người này cũng bật TimescaleDB và tải việc sử dụng io.weight giảm xuống bộ xử lý; và việc sử dụng các phần tử quy trình nội bộ cũng đã giảm do có thêm TimescaleDB. Hơn nữa, đây là những đĩa pancake thông thường, tức là một máy ảo thông thường trên các đĩa thông thường (không phải SSD)!
Đối với một số thiết lập nhỏ bị giới hạn bởi hiệu suất ổ đĩa, theo tôi, TimescaleDB là một giải pháp rất tốt. Nó sẽ cho phép bạn tiếp tục làm việc trước khi chuyển sang phần cứng nhanh hơn cho cơ sở dữ liệu.
Tôi mời tất cả các bạn tham dự các sự kiện của chúng tôi: Hội nghị ở Moscow, Hội nghị thượng đỉnh ở Riga. Sử dụng các kênh của chúng tôi - Telegram, diễn đàn, IRC. Nếu bạn có bất kỳ câu hỏi nào, hãy đến bàn của chúng tôi, chúng ta có thể nói về mọi thứ.
Câu hỏi của khán giả
Câu hỏi từ khán giả (sau đây gọi là - A): - Nếu TimescaleDB quá dễ cấu hình và nó mang lại hiệu suất tăng cao như vậy, thì có lẽ đây nên được sử dụng như một phương pháp hay nhất để định cấu hình Zabbix với Postgres? Và liệu giải pháp này có cạm bẫy và nhược điểm nào không, hay xét cho cùng, nếu tôi quyết định tự làm Zabbix cho riêng mình, tôi có thể dễ dàng lấy Postgres, cài đặt Timescale vào đó ngay, sử dụng và không phải nghĩ đến vấn đề gì ?

AG: – Vâng, tôi có thể nói rằng đây là một đề xuất hay: hãy sử dụng Postgres ngay lập tức với tiện ích mở rộng TimescaleDB. Như tôi đã nói, rất nhiều đánh giá tốt, mặc dù thực tế là “tính năng” này chỉ là thử nghiệm. Nhưng thực tế các thử nghiệm cho thấy đây là một giải pháp tuyệt vời (với TimescaleDB) và tôi nghĩ nó sẽ phát triển! Chúng tôi đang theo dõi cách tiện ích mở rộng này phát triển và sẽ thực hiện các thay đổi nếu cần thiết.
Ngay cả trong quá trình phát triển, chúng tôi đã dựa vào một trong những “tính năng” nổi tiếng của họ: có thể làm việc với các khối hơi khác một chút. Nhưng sau đó họ đã loại bỏ nó trong bản phát hành tiếp theo và chúng tôi phải ngừng dựa vào mã này. Tôi khuyên bạn nên sử dụng giải pháp này trên nhiều thiết lập. Nếu bạn sử dụng MySQL... Đối với các thiết lập trung bình, mọi giải pháp đều hoạt động tốt.
A: – Trên các biểu đồ cuối cùng từ cộng đồng, có một biểu đồ có “Quản gia”:
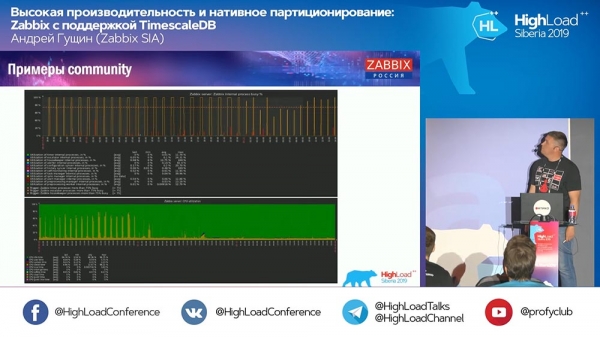
Anh tiếp tục làm việc. Quản gia làm gì với TimescaleDB?
AG: – Bây giờ tôi không thể nói chắc chắn – Tôi sẽ xem mã và cho bạn biết chi tiết hơn. Nó sử dụng các truy vấn TimescaleDB không phải để xóa các đoạn mà để tổng hợp chúng bằng cách nào đó. Tôi chưa sẵn sàng trả lời câu hỏi kỹ thuật này. Chúng ta sẽ tìm hiểu thêm tại khán đài hôm nay hoặc ngày mai.
A: – Tôi có một câu hỏi tương tự – về hiệu suất của thao tác xóa trong Timescale.
Trả lời (câu trả lời từ khán giả): – Khi xóa dữ liệu trong một bảng, nếu thực hiện bằng cách xóa thì bạn cần phải duyệt qua bảng - xóa, xóa, đánh dấu mọi thứ để hút bụi sau này. Trong Timescale, vì bạn có nhiều khối nên bạn có thể thả. Nói một cách đại khái, bạn chỉ cần nói với tệp có dữ liệu lớn: “Xóa!”
Timescale hiểu đơn giản là đoạn như vậy không còn tồn tại nữa. Và vì nó được tích hợp vào trình lập kế hoạch truy vấn nên nó sử dụng các móc nối để nắm bắt các điều kiện của bạn trong các thao tác chọn hoặc các thao tác khác và ngay lập tức hiểu rằng đoạn này không còn tồn tại - “Tôi sẽ không đến đó nữa!” (Dữ liệu không tồn tại). Đó là tất cả! Nghĩa là, việc quét bảng được thay thế bằng việc xóa tệp nhị phân nên rất nhanh.
A: – Chúng ta đã đề cập đến chủ đề không phải SQL. Theo như tôi hiểu, Zabbix không thực sự cần sửa đổi dữ liệu và tất cả những thứ này giống như nhật ký. Có thể sử dụng cơ sở dữ liệu chuyên dụng không thể thay đổi dữ liệu của họ, nhưng đồng thời lưu, tích lũy và phân phối nhanh hơn nhiều - Clickhouse chẳng hạn, một cái gì đó giống Kafka?.. Kafka cũng là một nhật ký! Có thể bằng cách nào đó tích hợp chúng?
AG: - Việc dỡ hàng có thể được thực hiện. Chúng tôi có một “tính năng” nhất định kể từ phiên bản 3.4: bạn có thể ghi tất cả các tệp lịch sử, sự kiện, mọi thứ khác vào tệp; và sau đó gửi nó đến bất kỳ cơ sở dữ liệu nào khác bằng cách sử dụng một số trình xử lý. Trên thực tế, nhiều người làm lại và ghi trực tiếp vào cơ sở dữ liệu. Một cách nhanh chóng, những người đánh chìm lịch sử ghi tất cả những thứ này vào các tệp, xoay các tệp này, v.v. và bạn có thể chuyển chúng sang Clickhouse. Tôi không thể nói về kế hoạch, nhưng có lẽ việc hỗ trợ thêm cho các giải pháp NoSQL (chẳng hạn như Clickhouse) sẽ tiếp tục.
A: – Nói chung hóa ra là bạn hoàn toàn có thể thoát khỏi postgres?
AG: – Tất nhiên, phần khó nhất trong Zabbix là các bảng lịch sử, nơi tạo ra nhiều vấn đề và sự kiện nhất. Trong trường hợp này, nếu bạn không lưu trữ các sự kiện trong một thời gian dài và lưu trữ lịch sử theo xu hướng trong một số bộ lưu trữ nhanh khác, thì nói chung, tôi nghĩ sẽ không có vấn đề gì.
A: – Bạn có thể ước tính mọi thứ sẽ hoạt động nhanh hơn bao nhiêu nếu bạn chuyển sang Clickhouse chẳng hạn?
AG: – Tôi chưa thử nó. Tôi nghĩ rằng ít nhất những con số tương tự có thể đạt được khá đơn giản, vì Clickhouse có giao diện riêng, nhưng tôi không thể nói chắc chắn. Tốt hơn là nên kiểm tra. Tất cả phụ thuộc vào cấu hình: bạn có bao nhiêu máy chủ, v.v. Chèn là một chuyện, nhưng bạn cũng cần truy xuất dữ liệu này - Grafana hoặc thứ gì khác.
A: – Vậy chúng ta đang nói về một cuộc chiến bình đẳng chứ không phải về lợi thế to lớn của những cơ sở dữ liệu nhanh này?
AG: – Tôi nghĩ khi chúng ta hội nhập sẽ có những bài kiểm tra chính xác hơn.
A: – RRD cũ tốt đẹp đã đi đâu? Điều gì khiến bạn chuyển sang cơ sở dữ liệu SQL? Ban đầu, tất cả số liệu được thu thập trên RRD.
AG: – Zabbix có RRD, có lẽ là ở một phiên bản rất cổ xưa. Luôn có cơ sở dữ liệu SQL - một cách tiếp cận cổ điển. Cách tiếp cận cổ điển là MySQL, PostgreSQL (chúng đã tồn tại từ rất lâu). Chúng tôi gần như chưa bao giờ sử dụng giao diện chung cho cơ sở dữ liệu SQL và RRD.


Một số quảng cáo 🙂
Cảm ơn bạn đã ở với chúng tôi. Bạn có thích bài viết của chúng tôi? Bạn muốn xem nội dung thú vị hơn? Hỗ trợ chúng tôi bằng cách đặt hàng hoặc giới thiệu cho bạn bè, , một dạng tương tự duy nhất của các máy chủ cấp đầu vào do chúng tôi phát minh ra dành cho bạn: (có sẵn với RAID1 và RAID10, tối đa 24 lõi và tối đa 40GB DDR4).
Dell R730xd rẻ hơn gấp 2 lần tại trung tâm dữ liệu Equinix Tier IV ở Amsterdam? Chỉ ở đây ở Hà Lan! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - từ $99! Đọc về
Nguồn: www.habr.com
