

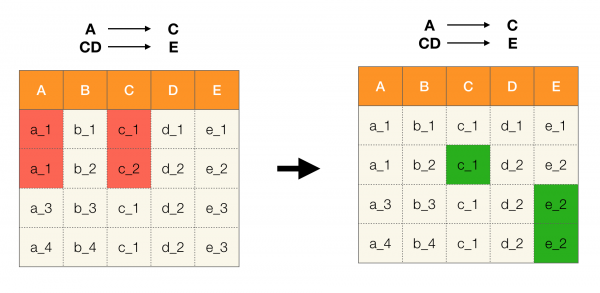
Trong bài viết này, chúng ta sẽ nói về các phần phụ thuộc chức năng trong cơ sở dữ liệu - chúng là gì, chúng được sử dụng ở đâu và có những thuật toán nào để tìm thấy chúng.
Chúng tôi sẽ xem xét các phụ thuộc chức năng trong bối cảnh cơ sở dữ liệu quan hệ. Nói một cách đại khái, trong những cơ sở dữ liệu như vậy, thông tin được lưu trữ dưới dạng bảng. Tiếp theo, chúng tôi sử dụng các khái niệm gần đúng không thể thay thế cho nhau trong lý thuyết quan hệ chặt chẽ: chúng tôi sẽ gọi bản thân bảng là mối quan hệ, các cột - thuộc tính (tập hợp của chúng - lược đồ quan hệ) và tập hợp các giá trị hàng trên một tập hợp con các thuộc tính - một bộ dữ liệu.
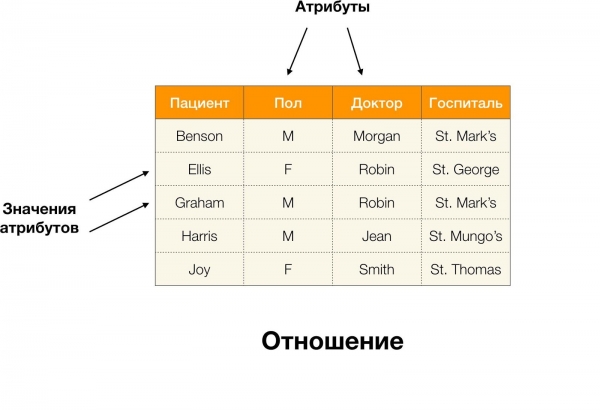
Ví dụ, trong bảng trên, (Benson, M, M cơ quan) là một bộ thuộc tính (Bệnh nhân, Paul, Bác sĩ).
Chính thức hơn, điều này được viết như sau:  [Bệnh Nhân, Giới Tính, Bác Sĩ🇧🇷 (Benson, M, M cơ quan).
[Bệnh Nhân, Giới Tính, Bác Sĩ🇧🇷 (Benson, M, M cơ quan).
Bây giờ chúng ta có thể giới thiệu khái niệm về sự phụ thuộc hàm (FD):
Định nghĩa 1. Mối quan hệ R thỏa mãn luật liên bang X → Y (trong đó X, Y ⊆ R) khi và chỉ nếu với bất kỳ bộ dữ liệu nào  ,
,  ∈ R giữ: nếu
∈ R giữ: nếu  [X] =
[X] =  [X] thì
[X] thì  [Y] =
[Y] =  [Y]. Trong trường hợp này, chúng ta nói rằng X (định thức hoặc tập hợp các thuộc tính xác định) xác định một cách chức năng Y (tập phụ thuộc).
[Y]. Trong trường hợp này, chúng ta nói rằng X (định thức hoặc tập hợp các thuộc tính xác định) xác định một cách chức năng Y (tập phụ thuộc).
Nói cách khác, sự hiện diện của luật liên bang X → Y có nghĩa là nếu chúng ta có hai bộ dữ liệu trong R và chúng khớp với nhau về thuộc tính X, khi đó chúng sẽ trùng nhau về thuộc tính Y.
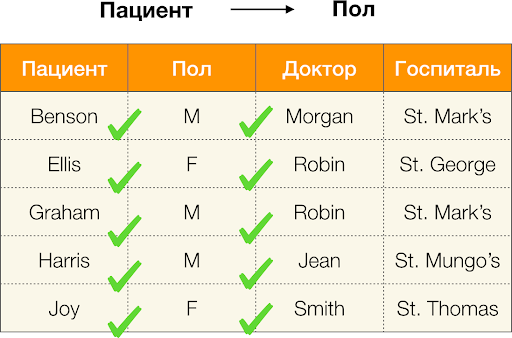
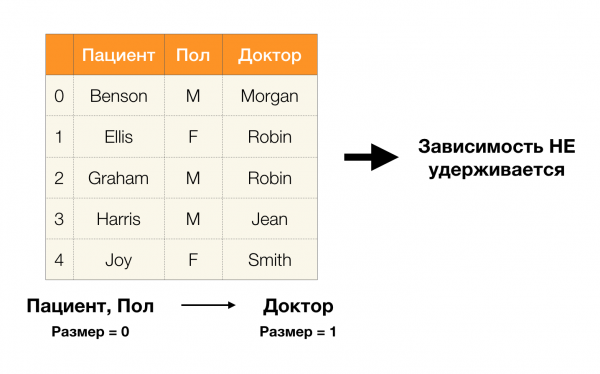
Và bây giờ, theo thứ tự. Chúng ta hãy nhìn vào các thuộc tính Bệnh nhân и Giới mà chúng ta muốn tìm hiểu xem có sự phụ thuộc giữa chúng hay không. Đối với tập hợp các thuộc tính như vậy, có thể tồn tại các phụ thuộc sau:
- Bệnh nhân → Giới tính
- Giới tính → Bệnh nhân
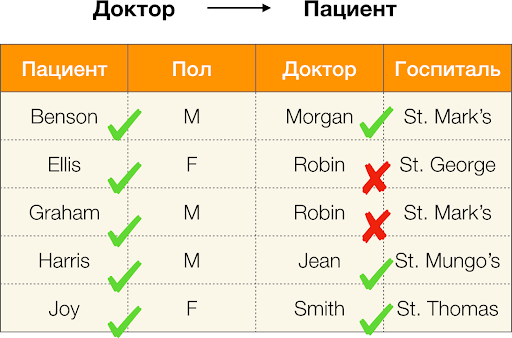
Như đã định nghĩa ở trên, để duy trì phần phụ thuộc đầu tiên, mỗi giá trị cột duy nhất Bệnh nhân chỉ có một giá trị cột phải khớp Giới. Và đối với bảng ví dụ thì điều này thực sự đúng. Tuy nhiên, điều này không hoạt động theo hướng ngược lại, tức là sự phụ thuộc thứ hai không được thỏa mãn và thuộc tính Giới không phải là yếu tố quyết định Kiên nhẫn. Tương tự, nếu chúng ta lấy sự phụ thuộc Bác sĩ → Bệnh nhân, bạn có thể thấy rằng nó bị vi phạm, vì giá trị Robin thuộc tính này có nhiều ý nghĩa khác nhau - Ellis và Graham.
Do đó, sự phụ thuộc chức năng giúp xác định mối quan hệ hiện có giữa các tập hợp thuộc tính bảng. Từ đây trở đi chúng ta sẽ xem xét những kết nối thú vị nhất, hay đúng hơn là những kết nối như vậy X → Ychúng là gì:
- không tầm thường, nghĩa là vế phải của sự phụ thuộc không phải là tập con của vế trái (Y ̸⊆ X);
- tối thiểu, nghĩa là không có sự phụ thuộc như vậy Z → YĐó Z ⊂ X.
Các phụ thuộc được xem xét cho đến thời điểm này là nghiêm ngặt, nghĩa là chúng không quy định bất kỳ vi phạm nào trên bảng, nhưng ngoài chúng, còn có những phụ thuộc cho phép một số mâu thuẫn giữa các giá trị của các bộ dữ liệu. Các phần phụ thuộc như vậy được đặt trong một lớp riêng biệt, được gọi là gần đúng và được phép vi phạm đối với một số bộ dữ liệu nhất định. Lượng này được quy định bởi chỉ báo lỗi tối đa emax. Ví dụ, tỷ lệ lỗi  = 0.01 có thể có nghĩa là sự phụ thuộc có thể bị vi phạm bởi 1% số bộ dữ liệu có sẵn trên tập thuộc tính được xem xét. Nghĩa là, đối với 1000 bản ghi, tối đa 10 bộ dữ liệu có thể vi phạm Luật Liên bang. Chúng tôi sẽ xem xét một số liệu hơi khác một chút, dựa trên các giá trị khác nhau theo cặp của các bộ dữ liệu được so sánh. Vì nghiện X → Y về thái độ r nó được coi là như thế này:
= 0.01 có thể có nghĩa là sự phụ thuộc có thể bị vi phạm bởi 1% số bộ dữ liệu có sẵn trên tập thuộc tính được xem xét. Nghĩa là, đối với 1000 bản ghi, tối đa 10 bộ dữ liệu có thể vi phạm Luật Liên bang. Chúng tôi sẽ xem xét một số liệu hơi khác một chút, dựa trên các giá trị khác nhau theo cặp của các bộ dữ liệu được so sánh. Vì nghiện X → Y về thái độ r nó được coi là như thế này:

Hãy tính sai số cho Bác sĩ → Bệnh nhân từ ví dụ trên. Chúng tôi có hai bộ dữ liệu có giá trị khác nhau về thuộc tính Bệnh nhân, nhưng trùng nhau Bác sĩ:  [Bác sĩ, Bệnh nhân] = (Robin, Ellis) Và
[Bác sĩ, Bệnh nhân] = (Robin, Ellis) Và  [Bác sĩ, Bệnh nhân] = (Robin, Graham). Theo định nghĩa về lỗi, chúng ta phải tính đến tất cả các cặp xung đột, nghĩa là sẽ có hai trong số chúng: (
[Bác sĩ, Bệnh nhân] = (Robin, Graham). Theo định nghĩa về lỗi, chúng ta phải tính đến tất cả các cặp xung đột, nghĩa là sẽ có hai trong số chúng: ( ,
,  ) và nghịch đảo của nó (
) và nghịch đảo của nó ( ,
,  ). Hãy thay thế nó vào công thức và nhận được:
). Hãy thay thế nó vào công thức và nhận được:

Bây giờ chúng ta hãy thử trả lời câu hỏi: “Tại sao lại như vậy?” Trên thực tế, luật liên bang có khác. Loại đầu tiên là những phụ thuộc được quản trị viên xác định ở giai đoạn thiết kế cơ sở dữ liệu. Chúng thường có số lượng ít, nghiêm ngặt và ứng dụng chính là chuẩn hóa dữ liệu và thiết kế lược đồ quan hệ.
Loại thứ hai là phần phụ thuộc, đại diện cho dữ liệu “ẩn” và các mối quan hệ chưa được biết trước đây giữa các thuộc tính. Nghĩa là, những sự phụ thuộc như vậy chưa được nghĩ đến tại thời điểm thiết kế và chúng được tìm thấy cho tập dữ liệu hiện có, để sau này, dựa trên nhiều luật liên bang đã được xác định, mọi kết luận có thể được rút ra về thông tin được lưu trữ. Chính xác là chúng tôi đang làm việc với những phần phụ thuộc này. Chúng được xử lý bởi toàn bộ lĩnh vực khai thác dữ liệu với các kỹ thuật và thuật toán tìm kiếm khác nhau được xây dựng trên cơ sở chúng. Hãy cùng tìm hiểu xem các phụ thuộc hàm được tìm thấy (chính xác hoặc gần đúng) trong bất kỳ dữ liệu nào có thể hữu ích như thế nào.

Ngày nay, một trong những ứng dụng chính của phụ thuộc là làm sạch dữ liệu. Nó liên quan đến việc phát triển các quy trình để xác định “dữ liệu bẩn” và sau đó sửa nó. Các ví dụ nổi bật về “dữ liệu bẩn” là dữ liệu trùng lặp, lỗi dữ liệu hoặc lỗi chính tả, giá trị bị thiếu, dữ liệu lỗi thời, khoảng trắng thừa và những thứ tương tự.
Ví dụ về lỗi dữ liệu:
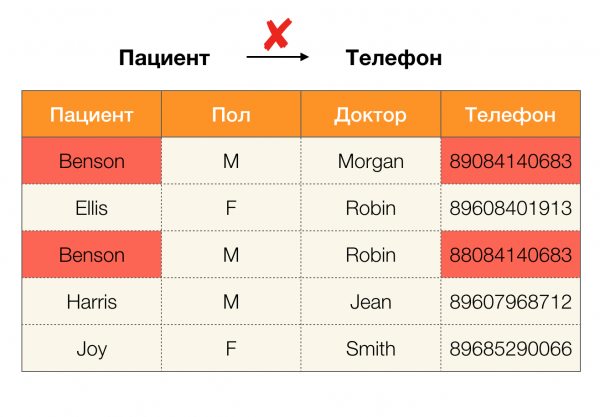
Ví dụ về trùng lặp dữ liệu:
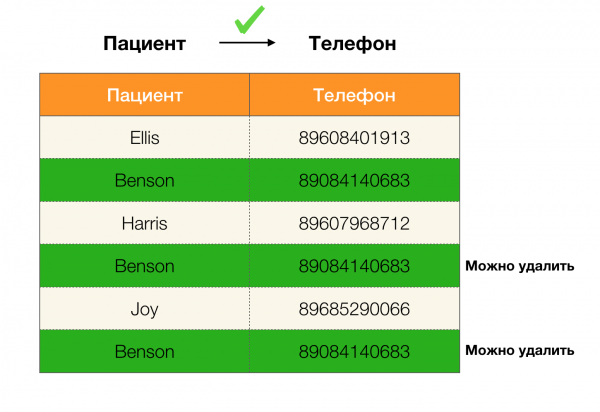
Ví dụ: chúng ta có một bảng và một bộ luật liên bang phải được thi hành. Làm sạch dữ liệu trong trường hợp này liên quan đến việc thay đổi dữ liệu để Luật Liên bang trở nên chính xác. Trong trường hợp này, số lượng sửa đổi phải ở mức tối thiểu (quy trình này có các thuật toán riêng mà chúng tôi sẽ không tập trung vào trong bài viết này). Dưới đây là một ví dụ về chuyển đổi dữ liệu như vậy. Bên trái là mối quan hệ ban đầu, trong đó rõ ràng là các FL cần thiết không được đáp ứng (ví dụ về vi phạm một trong các FL được đánh dấu màu đỏ). Bên phải là mối quan hệ được cập nhật, với các ô màu xanh lá cây hiển thị các giá trị đã thay đổi. Sau thủ tục này, các phụ thuộc cần thiết bắt đầu được duy trì.
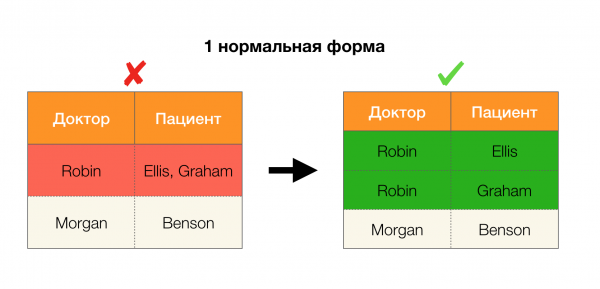
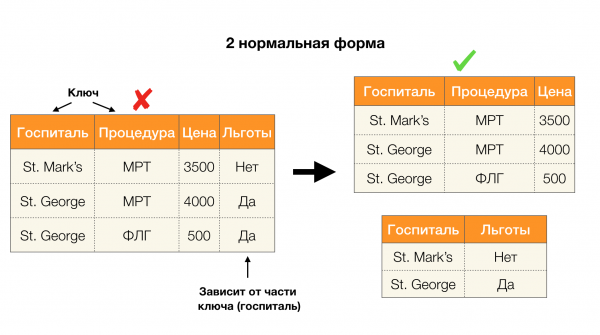
Một ứng dụng phổ biến khác là thiết kế cơ sở dữ liệu. Ở đây cần nhớ lại các dạng chuẩn và chuẩn hóa. Chuẩn hóa là quá trình làm cho một mối quan hệ phù hợp với một tập hợp các yêu cầu nhất định, mỗi yêu cầu được xác định bởi dạng chuẩn theo cách riêng của nó. Chúng tôi sẽ không mô tả các yêu cầu của các dạng chuẩn khác nhau (điều này được thực hiện trong bất kỳ cuốn sách nào về khóa học cơ sở dữ liệu dành cho người mới bắt đầu), nhưng chúng tôi sẽ chỉ lưu ý rằng mỗi dạng đó sử dụng khái niệm phụ thuộc hàm theo cách riêng của mình. Xét cho cùng, FL vốn là các ràng buộc toàn vẹn được tính đến khi thiết kế cơ sở dữ liệu (trong ngữ cảnh của nhiệm vụ này, FL đôi khi được gọi là siêu khóa).
Hãy xem xét ứng dụng của họ cho bốn dạng chuẩn trong hình bên dưới. Hãy nhớ lại rằng dạng chuẩn Boyce-Codd nghiêm ngặt hơn dạng thứ ba, nhưng ít nghiêm ngặt hơn dạng thứ tư. Hiện tại, chúng tôi chưa xem xét vấn đề sau vì công thức của nó đòi hỏi sự hiểu biết về sự phụ thuộc đa giá trị, điều này không thú vị đối với chúng tôi trong bài viết này.
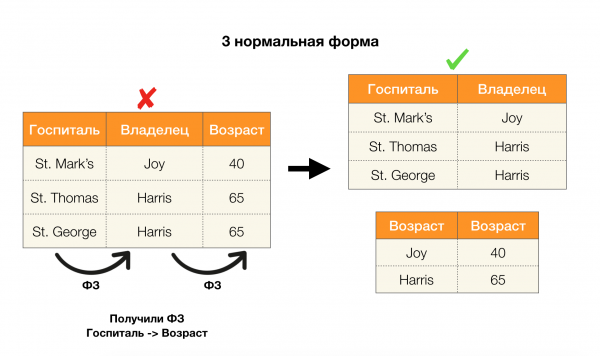
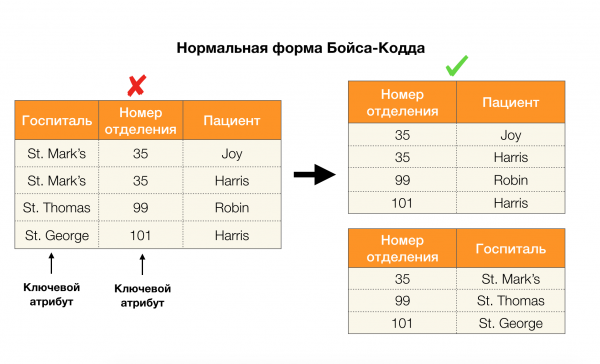
Một lĩnh vực khác mà các phần phụ thuộc đã tìm thấy ứng dụng của chúng là giảm tính chiều của không gian đối tượng trong các tác vụ như xây dựng bộ phân loại Bayes đơn giản, xác định các đối tượng quan trọng và tham số hóa lại mô hình hồi quy. Trong các bài viết gốc, nhiệm vụ này được gọi là xác định mức độ dư thừa và mức độ liên quan của tính năng [5, 6] và nó được giải quyết bằng việc sử dụng tích cực các khái niệm cơ sở dữ liệu. Với sự ra đời của những công trình như vậy, có thể nói rằng ngày nay có nhu cầu về các giải pháp cho phép chúng ta kết hợp cơ sở dữ liệu, phân tích và triển khai các vấn đề tối ưu hóa trên vào một công cụ [7, 8, 9].
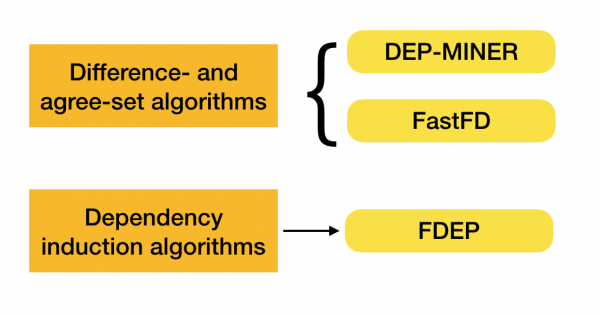
Có nhiều thuật toán (cả hiện đại và không hiện đại) để tìm kiếm luật liên bang trong một tập dữ liệu, các thuật toán này có thể được chia thành ba nhóm:
- Các thuật toán truyền tải mạng đại số (Lattice traversal Algorithms)
- Các thuật toán dựa trên việc tìm kiếm các giá trị đã thỏa thuận (Thuật toán khác biệt và thỏa thuận)
- Các thuật toán dựa trên so sánh từng cặp (Thuật toán cảm ứng phụ thuộc)
Mô tả ngắn gọn về từng loại thuật toán được trình bày trong bảng dưới đây:
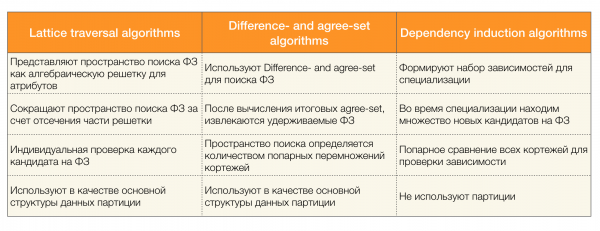
Bạn có thể đọc thêm về cách phân loại này [4]. Dưới đây là ví dụ về thuật toán cho từng loại:
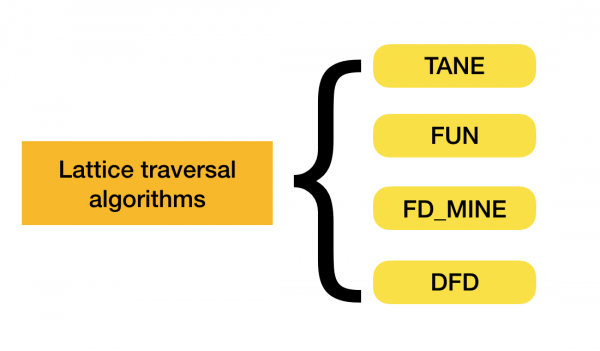
Hiện nay, các thuật toán mới đang xuất hiện kết hợp nhiều cách tiếp cận để tìm các phụ thuộc hàm. Ví dụ về các thuật toán như vậy là Pyro [2] và HyFD [3]. Một phân tích về công việc của họ được mong đợi trong các bài viết sau của loạt bài này. Trong bài viết này, chúng tôi sẽ chỉ xem xét các khái niệm cơ bản và bổ đề cần thiết để hiểu các kỹ thuật phát hiện sự phụ thuộc.
Hãy bắt đầu với một thuật toán đơn giản - sự khác biệt và sự đồng ý, được sử dụng trong loại thuật toán thứ hai. Tập sai phân là tập hợp các bộ không có cùng giá trị, trong khi tập hợp đồng ý, ngược lại, là tập các bộ có cùng giá trị. Điều đáng chú ý là trong trường hợp này chúng ta chỉ xét vế trái của sự phụ thuộc.
Một khái niệm quan trọng khác đã gặp ở trên là mạng đại số. Vì nhiều thuật toán hiện đại hoạt động dựa trên khái niệm này nên chúng ta cần biết nó là gì.
Để giới thiệu khái niệm mạng, cần định nghĩa một tập hợp có thứ tự một phần (hay tập hợp có thứ tự một phần, viết tắt là poset).
Định nghĩa 2. Một tập S được gọi là sắp thứ tự một phần theo quan hệ nhị phân ⩽ nếu với mọi a, b, c ∈ S thì các tính chất sau được thỏa mãn:
- Tính phản xạ, tức là a ⩽ a
- Phản đối xứng, nghĩa là nếu a ⩽ b và b ⩽ a thì a = b
- Nghĩa là, với a ⩽ b và b ⩽ c thì a ⩽ c
Một quan hệ như vậy được gọi là quan hệ thứ tự từng phần (rời), và bản thân tập hợp đó được gọi là tập hợp có thứ tự từng phần. Ký hiệu chính thức: ⟨S, ⩽⟩.
Là ví dụ đơn giản nhất về tập hợp được sắp thứ tự một phần, chúng ta có thể lấy tập hợp tất cả các số tự nhiên N với quan hệ thứ tự thông thường ⩽. Thật dễ dàng để xác minh rằng tất cả các tiên đề cần thiết đều được thỏa mãn.
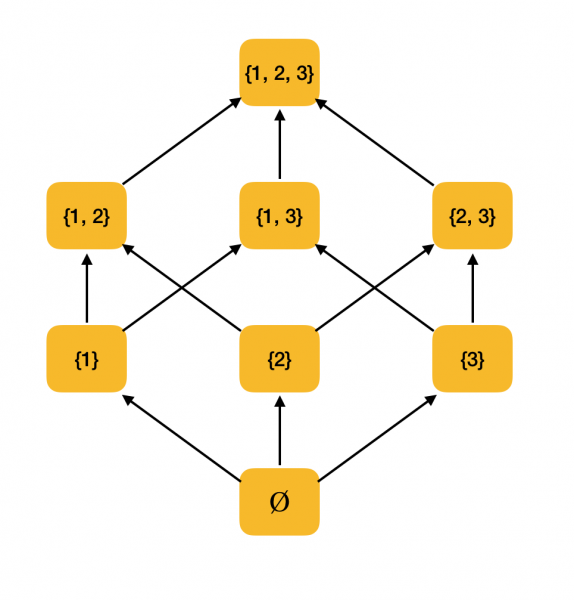
Một ví dụ có ý nghĩa hơn. Xét tập hợp tất cả các tập con {1, 2, 3}, được sắp xếp theo quan hệ bao hàm ⊆. Thật vậy, quan hệ này thỏa mãn mọi điều kiện cấp một phần, vì vậy ⟨P ({1, 2, 3}), ⊆⟩ là tập được sắp thứ tự từng phần. Hình dưới đây cho thấy cấu trúc của tập hợp này: nếu một phần tử có thể đến được bằng mũi tên đến phần tử khác thì chúng có mối quan hệ thứ tự.
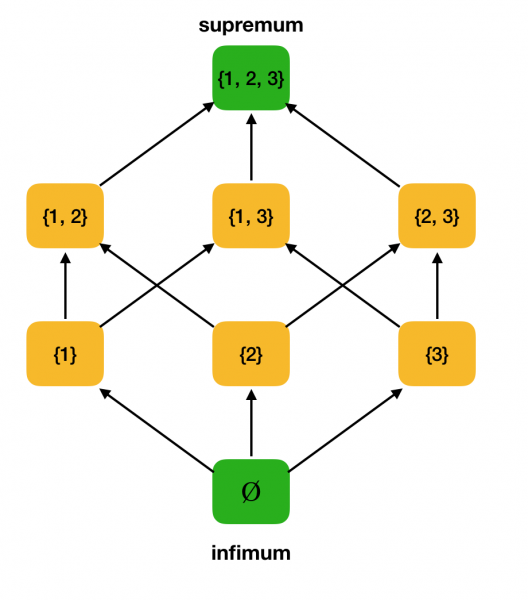
Chúng ta sẽ cần thêm hai định nghĩa đơn giản hơn từ lĩnh vực toán học - tối cao và tối thiểu.
Định nghĩa 3. Cho ⟨S, ⩽⟩ là tập sắp thứ tự từng phần, A ⊆ S. Giới hạn trên của A là phần tử u ∈ S sao cho ∀x ∈ S: x ⩽ u. Gọi U là tập hợp tất cả các giới hạn trên của S. Nếu có phần tử nhỏ nhất trong U thì nó được gọi là phần tử tối cao và được ký hiệu là sup A.
Khái niệm về giới hạn dưới chính xác cũng được giới thiệu tương tự.
Định nghĩa 4. Cho ⟨S, ⩽⟩ là tập sắp thứ tự từng phần, A ⊆ S. Phần tử nhỏ nhất của A là phần tử l ∈ S sao cho ∀x ∈ S: l ⩽ x. Gọi L là tập hợp tất cả các giới hạn dưới của S. Nếu có phần tử lớn nhất trong L thì nó được gọi là vô số và được ký hiệu là inf A.
Hãy xem xét ví dụ về tập hợp được sắp thứ tự một phần ở trên ⟨P ({1, 2, 3}), ⊆⟩ và tìm tập lớn nhất và nhỏ nhất trong đó:
Bây giờ chúng ta có thể xây dựng định nghĩa của một mạng đại số.
Định nghĩa 5. Cho ⟨P,⩽⟩ là tập được sắp thứ tự từng phần sao cho mọi tập con gồm hai phần tử đều có giới hạn trên và giới hạn dưới. Khi đó P được gọi là mạng đại số. Trong trường hợp này, sup{x, y} được viết là x ∨ y và inf {x, y} là x ∧ y.
Hãy kiểm tra xem ví dụ hoạt động của chúng ta ⟨P ({1, 2, 3}), ⊆⟩ có phải là một mạng không. Thật vậy, với mọi a, b ∈ P ({1, 2, 3}), a∨b = a∪b và a∧b = a∩b. Ví dụ, hãy xem xét các tập hợp {1, 2} và {1, 3} và tìm cực tiểu và cực đại của chúng. Nếu chúng ta cắt chúng, chúng ta sẽ nhận được tập {1}, đây sẽ là tập nhỏ nhất. Chúng tôi đạt được mức tối đa bằng cách kết hợp chúng - {1, 2, 3}.
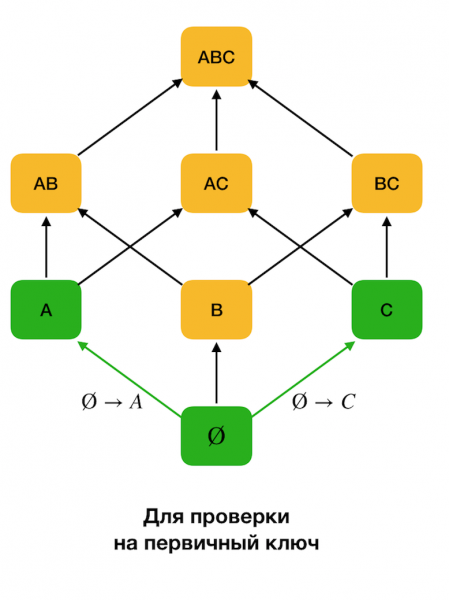
Trong các thuật toán xác định các vấn đề vật lý, không gian tìm kiếm thường được biểu diễn dưới dạng mạng, trong đó các tập hợp một phần tử (đọc cấp độ đầu tiên của mạng tìm kiếm, trong đó phía bên trái của các phụ thuộc bao gồm một thuộc tính) đại diện cho mỗi thuộc tính của mối quan hệ ban đầu.
Đầu tiên, chúng ta xét các phụ thuộc có dạng ∅ → Thuộc tính duy nhất. Bước này cho phép bạn xác định thuộc tính nào là khóa chính (đối với những thuộc tính như vậy không có định thức và do đó phía bên trái trống). Hơn nữa, các thuật toán như vậy sẽ di chuyển lên dọc theo mạng. Điều đáng chú ý là không thể duyệt toàn bộ mạng, nghĩa là nếu kích thước tối đa mong muốn của phía bên trái được chuyển đến đầu vào, thì thuật toán sẽ không đi xa hơn mức có kích thước đó.
Hình dưới đây cho thấy cách sử dụng mạng đại số trong bài toán tìm FZ. Ở đây mỗi cạnh (X, XY) đại diện cho sự phụ thuộc X → Y. Ví dụ: chúng tôi đã vượt qua cấp độ đầu tiên và biết rằng cơn nghiện vẫn được duy trì Một → B (chúng tôi sẽ hiển thị điều này dưới dạng kết nối màu xanh lá cây giữa các đỉnh A и B). Điều này có nghĩa là hơn nữa, khi chúng ta di chuyển lên dọc theo mạng, chúng ta có thể không kiểm tra được sự phụ thuộc A, C → B, bởi vì nó sẽ không còn là tối thiểu nữa. Tương tự, chúng tôi sẽ không kiểm tra nó nếu phần phụ thuộc được giữ C → B.
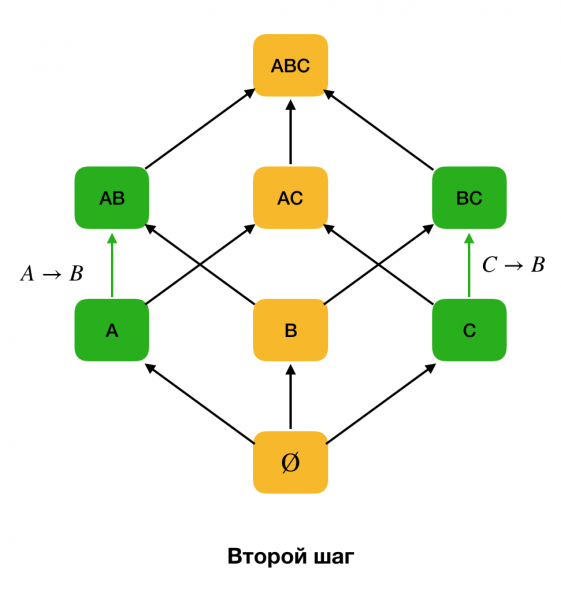
Ngoài ra, theo quy định, tất cả các thuật toán hiện đại để tìm kiếm luật liên bang đều sử dụng cấu trúc dữ liệu như phân vùng (trong nguồn ban đầu - phân vùng bị tước [1]). Định nghĩa chính thức của một phân vùng như sau:
Định nghĩa 6. Cho X ⊆ R là tập thuộc tính của quan hệ r. Một cụm là một tập hợp các chỉ số của các bộ trong r có cùng giá trị cho X, nghĩa là c(t) = {i|ti[X] = t[X]}. Một phân vùng là một tập hợp các cụm, không bao gồm các cụm có độ dài đơn vị:

Nói một cách đơn giản, một phân vùng cho một thuộc tính X là một tập hợp các danh sách, trong đó mỗi danh sách chứa các số dòng có cùng giá trị cho X. Trong văn học hiện đại, cấu trúc biểu diễn các phân vùng được gọi là chỉ mục danh sách vị trí (PLI). Các cụm có độ dài đơn vị được loại trừ cho mục đích nén PLI vì chúng là các cụm chỉ chứa số bản ghi có giá trị duy nhất luôn dễ xác định.
Hãy xem một ví dụ. Hãy quay lại cùng bảng với bệnh nhân và xây dựng phân vùng cho các cột Bệnh nhân и Giới (một cột mới đã xuất hiện ở bên trái, trong đó đánh dấu số hàng của bảng):
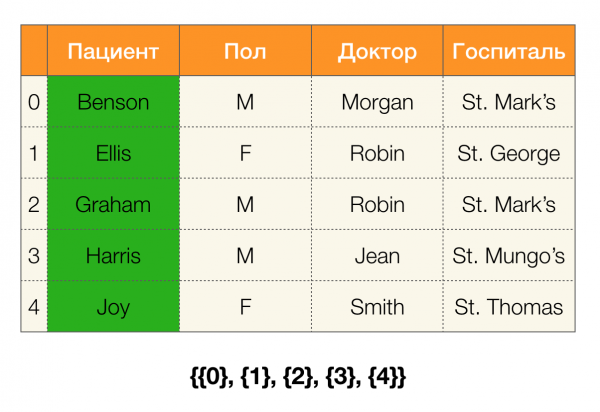
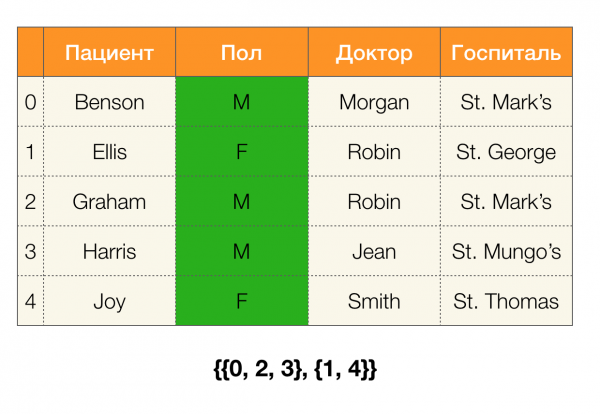
Hơn nữa, theo định nghĩa, việc phân vùng cho cột Bệnh nhân thực sự sẽ trống vì các cụm đơn lẻ bị loại khỏi phân vùng.
Các phân vùng có thể có được bằng một số thuộc tính. Và có hai cách để thực hiện việc này: bằng cách duyệt qua bảng, xây dựng một phân vùng bằng cách sử dụng tất cả các thuộc tính cần thiết cùng một lúc hoặc xây dựng nó bằng cách sử dụng thao tác giao nhau của các phân vùng bằng cách sử dụng một tập hợp con các thuộc tính. Các thuật toán tìm kiếm luật liên bang sử dụng tùy chọn thứ hai.
Nói một cách đơn giản, ví dụ: lấy phân vùng theo cột ABC, bạn có thể lấy phân vùng cho AC и B (hoặc bất kỳ tập hợp con rời rạc nào khác) và giao chúng với nhau. Hoạt động giao nhau của hai phân vùng sẽ chọn ra các cụm có độ dài lớn nhất chung cho cả hai phân vùng.
Hãy xem xét một ví dụ:
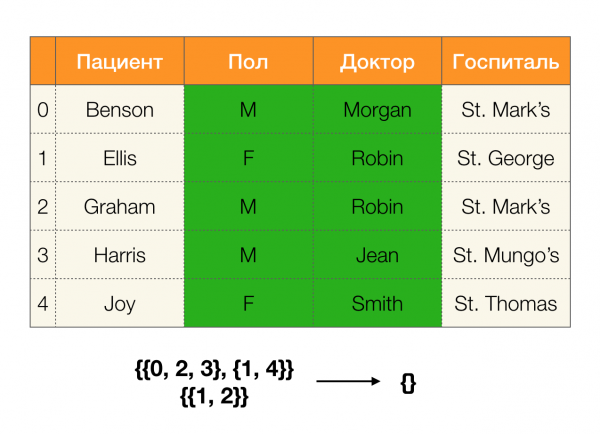

Trong trường hợp đầu tiên, chúng tôi nhận được một phân vùng trống. Nếu bạn nhìn kỹ vào bảng thì quả thực không có giá trị nào giống hệt nhau cho hai thuộc tính. Nếu chúng ta sửa đổi bảng một chút (trường hợp bên phải), chúng ta sẽ có được một giao lộ không trống. Hơn nữa, dòng 1 và 2 thực chất chứa cùng một giá trị cho các thuộc tính Giới и Bác sĩ.
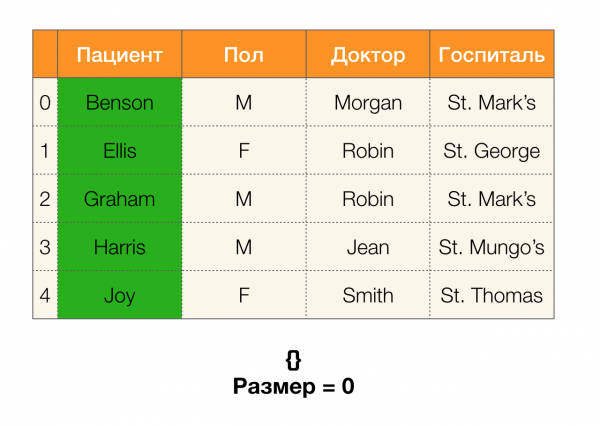
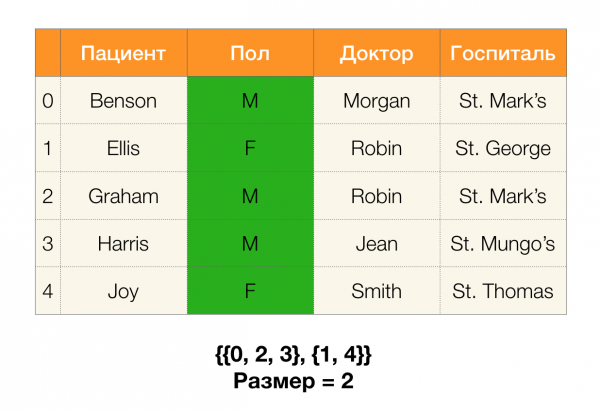
Tiếp theo, chúng ta sẽ cần một khái niệm như kích thước phân vùng. Chính thức:

Nói một cách đơn giản, kích thước phân vùng là số cụm có trong phân vùng (hãy nhớ rằng các cụm đơn lẻ không được bao gồm trong phân vùng!):
Bây giờ chúng ta có thể định nghĩa một trong những bổ đề chính, đối với các phân vùng đã cho, cho phép chúng ta xác định xem liệu một phụ thuộc có được giữ hay không:
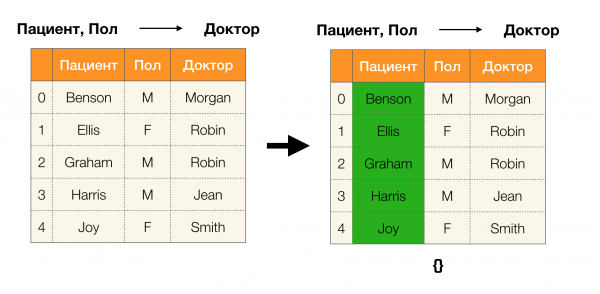
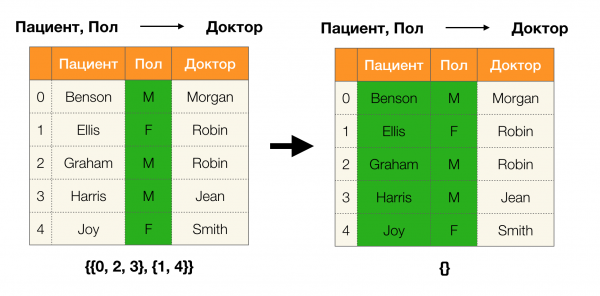
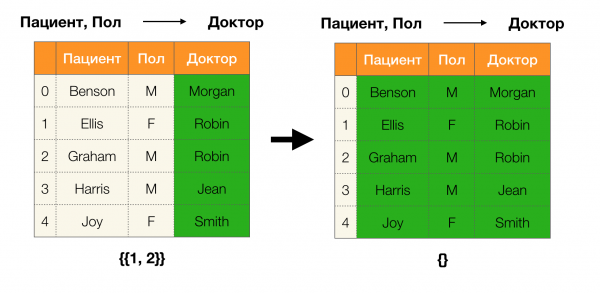
Bổ đề 1. Sự phụ thuộc A, B → C đúng khi và chỉ khi

Theo bổ đề, để xác định liệu một phụ thuộc có đúng hay không, phải thực hiện bốn bước:
- Tính toán phân vùng cho phía bên trái của phần phụ thuộc
- Tính toán phân vùng cho phía bên phải của phần phụ thuộc
- Tính tích của bước thứ nhất và bước thứ hai
- So sánh kích thước của các phân vùng thu được ở bước đầu tiên và bước thứ ba
Dưới đây là một ví dụ về việc kiểm tra xem sự phụ thuộc có đúng theo bổ đề này hay không:
Trong bài viết này, chúng tôi đã xem xét các khái niệm như sự phụ thuộc hàm, sự phụ thuộc hàm gần đúng, xem chúng được sử dụng ở đâu, cũng như những thuật toán tìm kiếm hàm vật lý nào tồn tại. Chúng tôi cũng đã xem xét chi tiết các khái niệm cơ bản nhưng quan trọng được sử dụng tích cực trong các thuật toán hiện đại để tìm kiếm luật liên bang.
Người giới thiệu:
- Huhtala Y. và cộng sự. TANE: Một thuật toán hiệu quả để khám phá các phụ thuộc hàm và gần đúng // Tạp chí máy tính. – 1999. – T. 42. – Không. 2. – trang 100-111.
- Kruse S., Naumann F. Khám phá hiệu quả các phụ thuộc gần đúng // Kỷ yếu của Quỹ VLDB. – 2018. – T. 11. – Không. 7. – trang 759-772.
- Papenbrock T., Naumann F. Một cách tiếp cận kết hợp để khám phá sự phụ thuộc chức năng // Kỷ yếu của Hội nghị quốc tế về quản lý dữ liệu năm 2016. – ACM, 2016. – trang 821-833.
- Papenbrock T. và cộng sự. Khám phá sự phụ thuộc chức năng: Đánh giá thử nghiệm bảy thuật toán // Kỷ yếu của Tài trợ VLDB. – 2015. – T. 8. – Không. 10. – trang 1082-1093.
- Kumar A. và cộng sự. Tham gia hay không tham gia?: Hãy suy nghĩ kỹ về việc tham gia trước khi lựa chọn tính năng // Kỷ yếu của Hội nghị quốc tế về quản lý dữ liệu năm 2016. – ACM, 2016. – trang 19-34.
- Abo Khamis M. và cộng sự. Học trong cơ sở dữ liệu với các tensor thưa thớt // Kỷ yếu của Hội nghị chuyên đề ACM SIGMOD-SIGACT-SIGAI lần thứ 37 về Nguyên tắc của Hệ thống Cơ sở dữ liệu. – ACM, 2018. – trang 325-340.
- Hellerstein JM và cộng sự. Thư viện phân tích MADlib: hoặc các kỹ năng MAD, SQL //Proceedings of the VLDB Endowment. – 2012. – T. 5. – Không. 12. – trang 1700-1711.
- Qin C., Rusu F. Các phép tính gần đúng mang tính suy đoán để tối ưu hóa độ dốc phân tán theo quy mô terascale // Kỷ yếu của Hội thảo lần thứ tư về Phân tích dữ liệu trong Đám mây. – ACM, 2015. – Trang 1.
- Mạnh X. và cộng sự. Mllib: Học máy trong Apache Spark // Tạp chí Nghiên cứu Học máy. – 2016. – T. 17. – Không. 1. – trang 1235-1241.
Tác giả bài viết: , nhà nghiên cứu tại , и , nhà nghiên cứu tại
Nguồn: www.habr.com
