

第一部分:
什么? 视频编解码器是一种用于压缩和/或解压缩数字视频的软件/硬件。
为了什么? 尽管在带宽和方面存在一定的限制,
就存储空间而言,市场对更高质量的视频需求日益增长。还记得我们在上一篇文章中计算过每秒 30 帧、每像素 24 位、分辨率为 480x240 的视频所需的最小存储空间吗?未压缩的情况下,我们得到了 82,944 Mbps。目前,压缩是向电视屏幕和互联网传输高清/全高清/4K 视频的唯一途径。那么,压缩是如何实现的呢?现在让我们简要回顾一下主要方法。
翻译是在 EDISON Software 的支持下完成的。我们从事 和 .
编解码器与容器
初学者常犯的一个错误是将数字视频编解码器与数字视频容器混淆。容器是一种特定的格式,它是一个封装了视频元数据(可能还包括音频)的层层包装。压缩后的视频可以看作是容器的有效载荷。
通常,视频文件的扩展名指示其容器类型。例如,video.mp4 文件很可能是一个 mp4 容器。 MPEG-4 Part 14而名为 video.mkv 的文件很可能 为了完全确定编解码器和容器格式,您可以使用 или .
有一点历史
在我们继续之前 怎么样?让我们深入了解一下历史,以便更好地了解一些较早的编解码器。
视频编解码器 H.261 它于1990年问世(严格来说是1988年),设计数据传输速率为64 kbps。它已经采用了色度二次采样、宏块等技术。1995年,视频编解码器标准正式发布。 H.263一直发展到 2001 年。
第一版于 2003 年完成。 H.264 / AVC同年,TrueMotion 发布了名为“免费有损视频编解码器”的软件。 VP32008年,谷歌收购了该公司,并发布了 VP8 同年,2012年12月,谷歌发布了 VP9并且它得到了大约四分之三的浏览器市场(包括移动设备)的支持。
AV1 是由开发的一款全新的免费开源视频编解码器。 开放媒体联盟 (媒体其中包括谷歌、Mozilla、微软、亚马逊、Netflix、AMD、ARM、英伟达、英特尔和思科等知名公司。该编解码器的第一个版本,即0.1.0版,于2016年4月7日发布。
AV1的诞生
2015年初,谷歌正在研究 VP10Xiph(隶属于 Mozilla)当时正在开发 达拉思科也开发了自己的免费视频编解码器,名为 托尔.
然后 MPEG 洛杉矶 首次公布的年度限额 HEVC (H.265)费用是 H.264 的 8 倍,但很快他们又改变了规则:
无年度限额
内容费(收入的0,5%)和
单位成本大约是 H.264 的 10 倍。
开放媒体联盟 它由来自各个领域的公司创建:设备制造商(英特尔、AMD、ARM、英伟达、思科)、内容提供商(谷歌、Netflix、亚马逊)、浏览器创建者(谷歌、Mozilla)等。
这些公司有着共同的目标:开发一种免版税的视频编解码器。然后,它出现了。 AV1 采用更为简便的专利许可模式。蒂莫西·B·特里贝里发表了一场精彩的演讲,这场演讲成为了当前AV1概念及其许可模式的起源。
您或许会惊讶地发现,您可以通过浏览器分析 AV1 编解码器(感兴趣的朋友可以访问以下地址)。).

通用编解码器
让我们来探讨一下通用视频编解码器的基本机制。这些概念中的大多数在现代编解码器中都非常有用并得到应用,例如: VP9, AV1 и HEVC请注意,许多解释会进行简化。有时会使用实际案例(例如 H.264)来演示相关技术。
步骤 1 - 分割图像
第一步是将框架分成几个部分、子部分等等。

为什么?原因有很多。当我们分割图像时,对于较小的运动部分,我们可以利用较小的区域更准确地预测其运动矢量。而对于静态背景,较大的区域就足够了。
编解码器通常将这些片段组织成段(或片段)、宏块(或编码树块)和多个子段。这些段的最大尺寸各不相同:HEVC 规定为 64x64,而 AVC 使用 16x16,子段最小可至 4x4。
还记得上一篇文章中的帧类型吗?!同样的道理也适用于块,所以我们可以有 I 片段、B 块、P 宏块等等。
对于想要练习的人来说,请注意观察图像是如何划分成各个部分和子部分的。为此,您可以使用上一篇文章中提到的技巧。 (付费版本,但提供免费试用版,但仅限前 10 帧)。以下是分析的部分。 VP9:

步骤二 - 预测
一旦我们有了各个板块,我们就可以对它们进行占星预测。 INTER-预测 必须传达 运动矢量 其余部分,以及用于内部预测的部分,都会被传输。 预测方向 其余部分。
步骤三——转变
一旦获得残差块(预测分区→实际分区),我们就可以对其进行变换,以确定在保持整体质量的前提下可以丢弃哪些像素。有些变换可以确保精确的结果。
虽然还有其他方法,但让我们更详细地了解一下。 离散余弦变换 (DCT -来自 离散余弦变换DCT的主要功能:
- 将像素块转换为大小相等的频率系数块。
- 节省电力,有助于消除空间冗余。
- 提供可逆性。
2017 年 2 月 2 日,Cintra, RJ 和 Bayer, FM 发表了一篇关于 DCT 类变换的图像压缩的论文,该变换只需要 14 个填充。
如果您不理解每一点的好处,请不要担心。现在让我们通过一些具体的例子来了解它们的真正价值。
我们来看这样一个 8x8 的像素块:
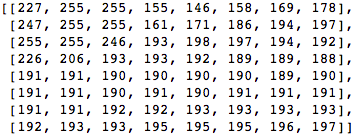
该代码块渲染成以下 8x8 像素的图像:
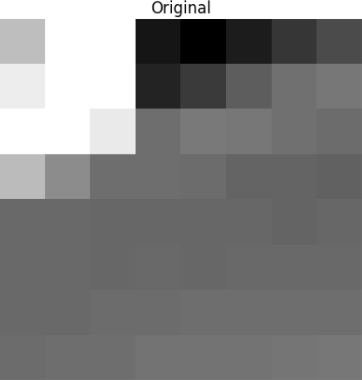
我们将 DCT 应用于该像素块,得到一个大小为 8×8 的系数块:

如果我们渲染这块系数,就会得到以下图像:
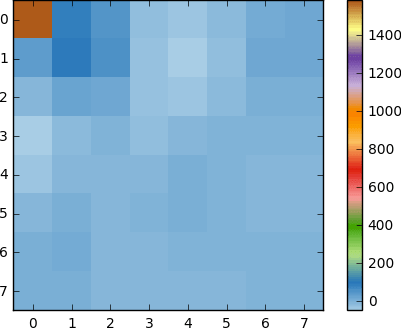
正如我们所见,这与原始图像并不相似。您可以看到第一个系数与其他系数显著不同。这个第一个系数被称为直流系数,它代表输入数组中所有样本的平均值。
这组系数具有一个有趣的特性:它可以将高频分量与低频分量分开。
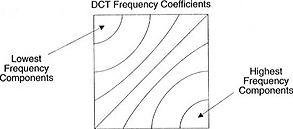
在图像中,大部分能量集中在较低频率上,因此通过将图像转换为其频率分量并丢弃较高频率系数,可以在不牺牲太多图像质量的情况下减少描述图像所需的数据量。
频率指的是信号变化的快慢。
让我们尝试应用在测试示例中获得的知识,使用 DCT 将原始图像转换为其频率(系数块),然后丢弃一些最不重要的系数。
首先,我们将其转换为频域。

接下来,我们舍弃一部分(67%)系数,主要是右下角部分。

最后,我们从这块被丢弃的系数中重建图像(记住,它必须是可逆的),并将其与原始图像进行比较。
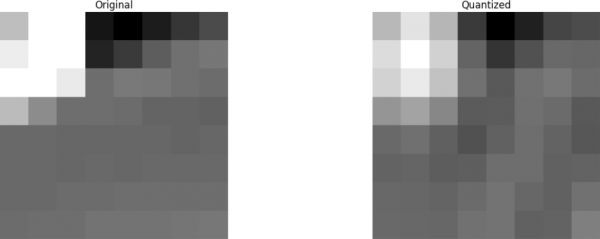
我们看到它与原图相似,但与原图仍存在许多差异。我们舍弃了 67,1875% 的数据,仍然得到了与原图相似的图像。我们本可以更仔细地舍弃系数以获得更高质量的图像,但这又是另一个话题了。
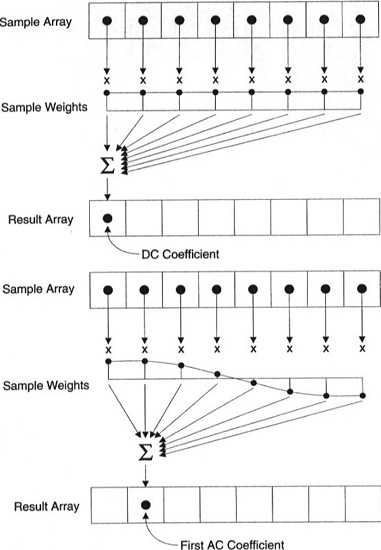
每个系数均由所有像素构成
重要提示:每个系数并非直接映射到单个像素,而是所有像素的加权和。这张精美的图表展示了如何使用每个索引特有的权重计算第一和第二个系数。
您还可以尝试通过观察基于 DCT 的简单图像来可视化它。例如,下图是使用每个系数权重形成的符号 A:

步骤 4 - 量化
在前一步舍弃部分系数后,最后一步(变换)中,我们执行一种特殊的量化形式。在这个阶段,信息丢失是可以接受的。或者更简单地说,我们将对系数进行量化以实现压缩。
如何量化一组系数?最简单的方法之一是均匀量化,即将这组系数除以一个值(例如 10),然后对结果进行四舍五入。
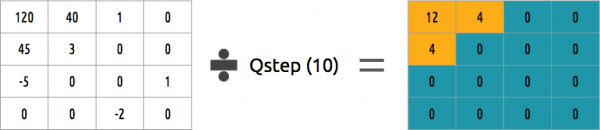
我们能否将这组系数取倒数?可以,只需乘以我们之前除以的那个值即可。

这种方法并不理想,因为它没有考虑到每个系数的重要性。可以使用量化矩阵代替单个值,该矩阵可以利用DCT特性,对右下角的大部分区域进行量化,而对左上角的一小部分区域进行量化。
步骤 5 - 熵编码
一旦我们对数据(图像块、片段、帧)进行了量化,我们仍然可以对其进行无损压缩。数据压缩有很多算法方法。我们将简要介绍其中的一些;要深入了解,您可以阅读《理解压缩:面向现代开发人员的数据压缩》一书(“)。
使用 VLC 播放器对视频进行编码
假设我们有一个字符流: a, e, r и t此表显示了流中每个符号出现频率的概率(介于 0 和 1 之间)。
| a | e | r | t | |
|---|---|---|---|---|
| 可能性 | 0,3 | 0,3 | 0,2 | 0,2 |
我们可以给最有可能发生的事件分配唯一的二进制代码(最好是较小的代码),给不太可能发生的事件分配较大的代码。
| a | e | r | t | |
|---|---|---|---|---|
| 可能性 | 0,3 | 0,3 | 0,2 | 0,2 |
| 二进制代码 | 0 | 10 | 110 | 1110 |
我们对数据流进行压缩,假设每个符号最终占用 8 位。如果不压缩,每个符号则需要 24 位。用代码替换每个符号可以节省一些空间!
第一步是对符号进行编码。 e,即 10,第二个符号是 a,然后(并非数学运算地)添加:[10] [0],最后是第三个字符 t这使得我们最终的压缩比特流等于 [10] [0] [1110] 或 1001110这只需要 7 位(比原版少 3,4 倍的空间)。
请注意,每个代码都必须是唯一的,并带有前缀。 这将帮助您找到这些数字。虽然这种方法并非完美无缺,但仍有一些视频编解码器提供这种算法压缩方法。
编码器和解码器都需要访问包含其二进制代码的符号表。因此,该符号表也必须包含在输入数据中。
算术编码
假设我们有一个字符流: a, e, r, s и t它们的概率如下表所示。
| a | e | r | s | t | |
|---|---|---|---|---|---|
| 可能性 | 0,3 | 0,3 | 0,15 | 0,05 | 0,2 |
利用这张表格,我们将构建包含所有可能符号的范围,并按数字大小排序。

现在让我们对三个符号组成的数据流进行编码: 吃.
首先,选择第一个字符 e该值位于 0,3 到 0,6(不含 0.3 和 0.6)的子区间内。我们取这个子区间,并按照之前的比例再次进行划分,但这次针对的是新的区间。

让我们继续编写我们的流媒体代码 吃现在我们来看第二个符号。 a,它位于 0,3 到 0,39 的新子范围内,然后我们取最后一个符号 t 重复相同的过程,我们得到最后一个子范围从 0,354 到 0,372。
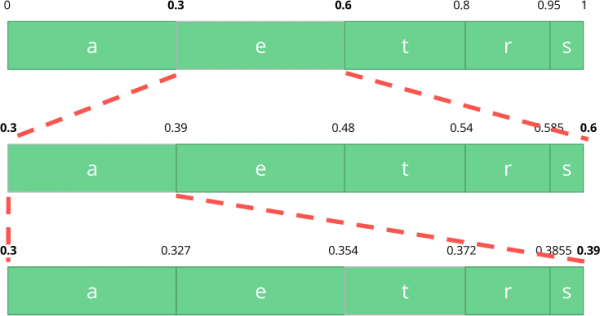
我们只需要在 0,354 到 0,372 之间的最后一个子范围内选择一个数字。我们选择 0,36(当然,这个子范围内的任何其他数字也是可以的)。只有使用这个数字,我们才能重构原始数据流。这就像我们在范围内画一条线来编码数据流一样。
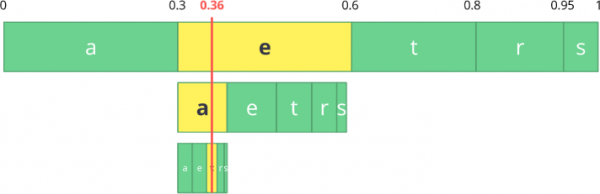
逆操作(即, 解码同样简单:利用我们的数字 0,36 和初始范围,我们可以运行相同的过程。但现在,使用这个数字,我们可以识别由该数字编码的数据流。
对于第一个范围,我们注意到我们的数字对应于切片,因此,这是我们的第一个符号。现在我们再次划分这个子范围,遵循与之前相同的过程。这里可以看到 0,36 对应于符号 a重复上述过程后,我们得到了最后一个符号。 t (形成我们最初的编码流) 吃).
编码器和解码器都需要一个符号概率表,因此必须将其作为输入数据发送。
是不是很巧妙?想出这个方案的人真是太聪明了。一些视频编解码器就采用了这种技术(或者至少提供了这种选项)。
其理念是无损压缩量化比特流。本文可能遗漏了大量细节、原因、权衡取舍等等。但如果您是开发人员,就应该了解更多。新的编解码器正在尝试使用不同的熵编码算法,例如: ANS.
步骤 6 - 比特流格式
完成上述所有步骤后,剩下的就是根据已执行的步骤对压缩帧进行解压缩。解码器必须明确地被告知编码器所做的决策。解码器必须获得所有必要的信息:位深度、色彩空间、分辨率、预测信息(运动矢量、方向性帧间预测)、配置文件、级别、帧速率、帧类型、帧号等等。
我们将对比特流进行粗略的了解。 H.264我们的第一步是创建一个最小的 H.264 比特流(FFmpeg 默认会添加所有编码选项,例如: 塞纳尔 ——我们稍后会弄清楚那是什么。我们可以使用我们自己的代码库和 FFmpeg 来实现这一点。
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264
此命令将生成原始比特流。 H.264 单帧,64×64分辨率,色彩空间 YUV420在这种情况下,使用下图作为边框。

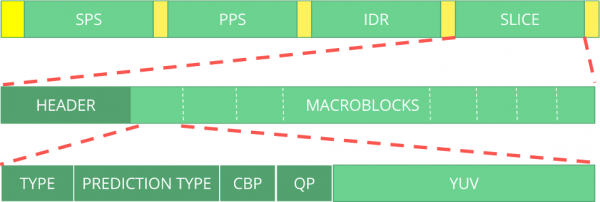
H.264 比特流
标准 AVC的 (H.264决定信息将以宏帧(在网络意义上)的形式发送,称为 NAL (这是一个网络抽象层)。NAL 的主要目标是提供一种“网络友好型”视频表示。该标准应同时适用于电视(基于流)和互联网(基于数据包)。
![]()
存在一个同步标记来定义 NAL 元素的边界。每个同步标记都包含一个值。 0x00 0x00 0x01, 除了第一个之外,它等于 0x00 0x00 0x00 0x01. 如果我们发射 十六进制转储 对于生成的 H.264 比特流,我们在文件开头至少识别出三个 NAL 模式。
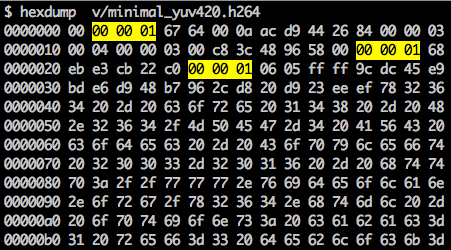
如前所述,解码器不仅需要知道图像数据,还需要知道视频、帧、颜色、使用的参数等等信息。每个NAL的第一个字节定义了它的类别和类型。
| NAL 类型标识符 | 使用说明 |
|---|---|
| 0 | 未知类型 |
| 1 | 不含IDR的编码图像片段 |
| 2 | 编码切片数据部分 A |
| 3 | 编码切片数据部分 B |
| 4 | 编码切片数据部分 C |
| 5 | IDR图像的编码IDR片段 |
| 6 | 有关SEI扩展的更多信息 |
| 7 | SPS序列参数集 |
| 8 | PPS图像参数集 |
| 9 | 访问分隔符 |
| 10 | 序列结束 |
| 11 | 直播结束 |
| ... | ... |
通常,比特流的第一个NAL是 SPS这种 NAL 类型负责传递常见的编码变量,例如配置文件、级别、分辨率等。
如果我们跳过第一个同步标记,我们可以解码第一个字节来找出第一个 NAL 类型。
例如,同步标记后的第一个字节是 01100111其中第一部分是(0) 在 f 场中orbidden_zero_bit接下来的 2 位(11)告诉我们该字段 nal_ref_idc, 这指示此 NAL 是否为引用字段。其余 5 位(00111)告诉我们该字段 nal_unit_type, 在这种情况下,它是SPS块(7)NAL。
第二个字节(二进制=01100100, 十六进制=0x64, 十二月=100) 在 SPS NAL 中是一个字段 profile_idc, 这显示了编码器使用的配置文件。在本例中,使用的是有限高配置文件(即不支持双向 B 段的高配置文件)。

如果你查看比特流规范的话。 H.264 对于 SPS NAL,我们会发现参数名称、类别和描述有很多值。例如,让我们看一下这些字段。 pic_width_in_mbs_minus_1 и pic_height_in_map_units_minus_1.
| 参数名称 | 类别 | 使用说明 |
|---|---|---|
| pic_width_in_mbs_minus_1 | 0 | ue(v) |
| pic_height_in_map_units_minus_1 | 0 | ue(v) |
如果我们对这些字段的值进行一些数学运算,就能得到分辨率。我们可以用以下方式表示 1920 x 1080: pic_width_in_mbs_minus_1 值为 119((119 + 1)* macroblock_size = 120 * 16 = 1920)。同样,为了节省空间,我们没有编码 1920,而是编码了 119。
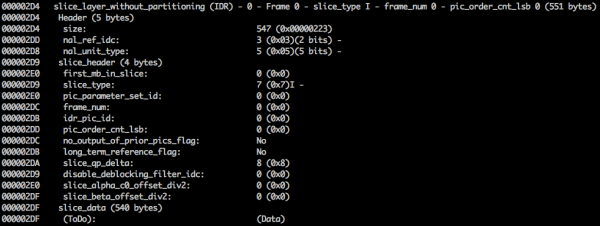
如果我们继续以二进制形式检查我们创建的视频(例如: xxd -b -c 11 v/minimal_yuv420.h264然后我们就可以继续讨论最后一个 NAL,也就是帧本身。

这里我们看到它的前 6 个字节值: 01100101 10001000 10000100 00000000 00100001 11111111由于已知第一个字节指示 NAL 类型,因此在这种情况下(00101这是IDR片段(5),然后就可以对其进行进一步研究:
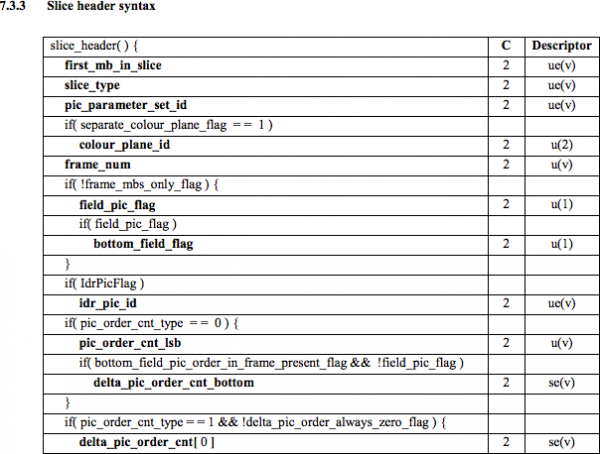
利用规范信息,可以解码片段类型(切片类型)和帧号(帧数以及其他重要领域。
要获取某些字段的值(ue(v), me(v), se(v)或 te(v)),我们需要使用基于以下原理的特殊解码器来解码片段: 这种方法对于编码变量值非常有效,尤其是在有很多默认值的情况下。
意 切片类型 и 帧数 该视频包含 7 个片段(I-片段)和 0 个帧(第一帧)。
可以将比特流视为一种协议。如果您想了解更多关于比特流的信息,应该参考其规范。 ITU H.264下图为图像数据所在位置的宏观示意图(YUV (以压缩形式)
还可以探索其他比特流,例如: VP9, H.265 (HEVC)或者甚至是我们最新最好的比特流 AV1它们都相似吗?不,但是一旦你理解了至少一个,理解其余的就容易多了。
想练习吗?探索 H.264 比特流。
您可以生成单帧视频,并使用 MediaInfo 检查比特流。 H.264事实上,没有任何规定阻止你查看分析比特流的源代码。 H.264 (AVC的).
练习时,您可以使用 Intel Video Pro Analyzer(我已经提到过该程序是付费的,但是是否有限制为 10 帧的免费试用版?)。
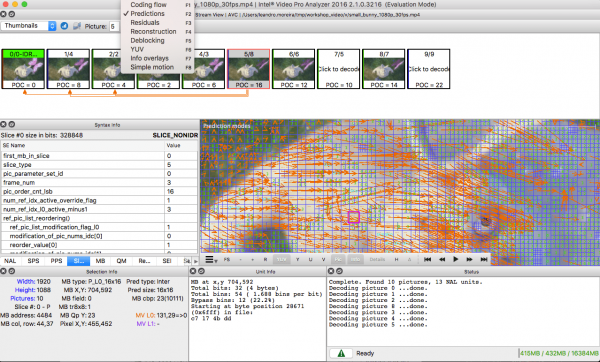
查看
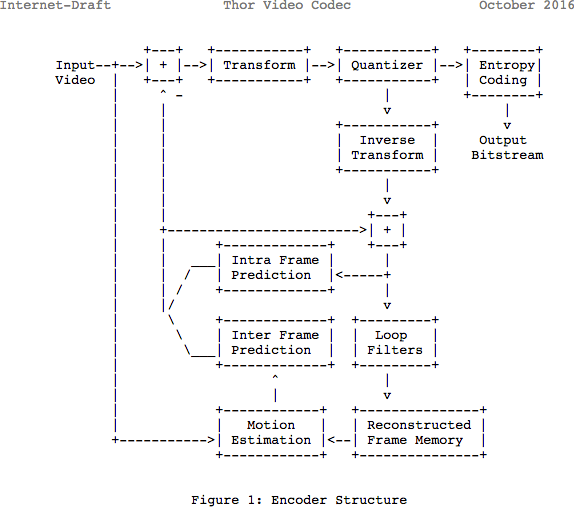
请注意,许多现代编解码器都使用我们刚才学习的相同模型。让我们来看一个视频编解码器框图。 托尔它包含了我们采取的所有步骤。这篇文章的目的在于让您更好地了解该领域的创新和相关文档。
我们之前计算过,存储一个720p分辨率、30帧/秒的1小时视频文件需要139GB的磁盘空间。使用本文讨论的方法(帧间和帧内预测、变换、量化、熵编码等),我们可以获得一个质量相当令人满意的视频(假设像素密度为0,031比特),而占用空间仅为367,82MB,而不是139GB。
H.265 如何实现比 H.264 更高的压缩率?
现在我们对编解码器的工作原理有了更多了解,就更容易理解新的编解码器如何用更少的比特提供更高的分辨率。
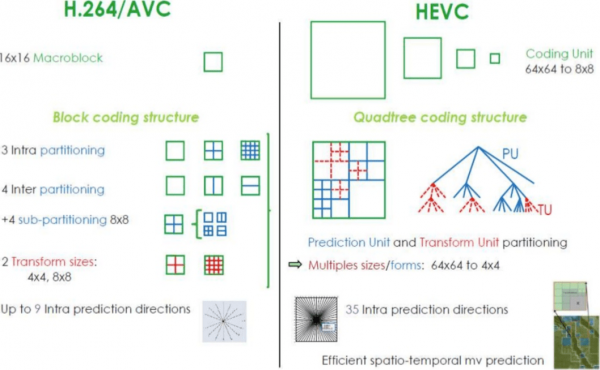
如果我们比较 AVC的 и HEVC值得注意的是,这几乎总是需要在更高的 CPU 负载和压缩比之间做出选择。
HEVC 相比之下,它拥有更多章节(和子章节)选项。 AVC的此外,还增加了更多内部预测方向、改进了熵编码等等。所有这些改进都使得…… H.265 压缩能力比上述数值高出 50%。 H.264.
第一部分:
来源: habr.com
