

CAP定理是分散式系統理論的基石。當然,圍繞它的爭議並沒有平息:其中的定義並不規範,也沒有嚴格的證明……儘管如此,堅定地站在日常識™的立場上,我們直觀地理解該定理是正確的。

唯一不太明顯的是字母“P”的意思。當集群分裂時,它會決定是否在達到法定人數之前不做回應,或給出它擁有的數據。根據此選擇的結果,系統被分類為 CP 或 AP。例如,Cassandra 可以以任何一種方式運行,甚至不取決於叢集設置,而是取決於每個特定請求的參數。但是如果系統不是“P”並且分裂,那麼會怎麼樣?
這個問題的答案有些出乎意料:CA集群不能分裂。
這個無法分裂的集群是什麼?
此類叢集的一個關鍵屬性是共用資料儲存系統。在絕大多數情況下,這意味著透過 SAN 連接,這使得 CA 解決方案的使用僅限於能夠維護 SAN 基礎架構的大型企業。為了實現多個目標, 服務器 要處理相同的數據,需要使用叢集檔案系統。 HPE (CFS)、Veritas (VxCFS) 和 IBM (GPFS) 的產品組合中均提供此類檔案系統。
Oracle RAC
真正的應用叢集 (RAC) 選項最早於 2001 年隨 Oracle 9i 版本發布而推出。在這種叢集中,可以部署多個 Oracle 實例。 服務器 使用同一個資料庫。
Oracle 既可以使用叢集檔案系統,也可以使用自己的解決方案-ASM(自動儲存管理)。
每份副本都保留自己的日誌。交易在一份副本中執行並提交。如果一個實例發生故障,則倖存的叢集節點(實例)之一將讀取其日誌並恢復遺失的數據,從而確保可用性。
所有實例都維護自己的緩存,相同的頁面(區塊)可以同時駐留在多個實例的快取中。此外,如果一個實例需要一個頁面,而該頁面位於另一個實例的快取中,則它可以使用快取融合機制從其「鄰居」取得該頁面,而不是從磁碟讀取。
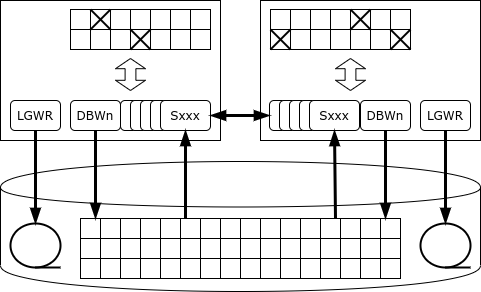
但是如果其中一個實例需要更改資料會發生什麼?
Oracle 的特殊性在於它沒有專門的鎖定服務:如果伺服器想要鎖定某一行,那麼鎖定記錄就會直接放在被鎖定的行所在的記憶體頁上。這種方法使 Oracle 成為單晶片資料庫中的效能冠軍:鎖服務永遠不會成為瓶頸。但在叢集配置中,這樣的架構可能會導致網路流量過大和死鎖。
一旦記錄被鎖定,實例就會通知所有其他實例,儲存該記錄的頁面已被獨佔鎖定。如果另一個實例需要更改同一頁面上的記錄,則必須等到頁面的變更被提交,即將變更資訊寫入磁碟日誌(同時事務可以繼續)。也可能發生這樣的情況:一個頁面被多個副本連續更改,然後當將該頁面寫入磁碟時,您必須找出誰擁有該頁面的當前版本。
跨不同的 RAC 節點隨機更新相同的頁面會導致資料庫效能急劇下降,甚至叢集效能可能低於單一實例的效能。
Oracle RAC 的正確使用方法是物理上劃分資料(例如,使用分區表機制)並透過專用節點存取每組分區。 RAC 的主要目的不是水平擴展,而是提供容錯能力。
如果節點停止回應心跳,則最先偵測到此情況的節點將啟動磁碟投票程序。如果遺失的節點也沒有在這裡簽到,那麼其中一個節點將承擔恢復資料的責任:
- 「凍結」遺失節點快取中的所有頁面;
- 讀取遺失節點的重做日誌並重新套用這些日誌中記錄的更改,同時檢查其他節點是否具有正在修改的頁面的更新版本;
- 回滾未完成的交易。
為了簡化節點之間的切換,Oracle 有一個服務的概念-虛擬實例。一個實例可以為多個服務提供服務,並且一個服務可以在節點之間移動。為資料庫的特定部分(例如一組客戶端)提供服務的應用程式實例與一個服務協同工作,當該節點發生故障時,負責該部分資料庫的服務將移動到另一個節點。
IBM Pure 交易資料系統
DBMS 的叢集解決方案於 2009 年出現在 Blue Giant 產品組合中。從意識形態上講,它是建立在「常規」硬體上的 Parallel Sysplex 集群的後繼者。 2009 年,軟體套件 DB2 pureScale 發布;2012 年,IBM 推出了名為 Pure Data Systems for Transactions 的硬體和軟體套件(裝置)。這不應與 Pure Data Systems for Analytics 混淆,後者只不過是 Netezza 的改名版。
pureScale 架構乍看之下與 Oracle RAC 類似:同樣,多個節點連接到一個公共資料儲存系統,每個節點運行自己的 DBMS 實例,具有自己的記憶體區域和事務日誌。但是,與 Oracle 不同的是,DB2 具有專用的鎖定服務,由一組 db2LLM* 程序表示。在叢集配置中,此服務位於單獨的節點上,在 Parallel Sysplex 中稱為耦合設施 (CF),在 Pure Data 中稱為 PowerHA。
PowerHA 提供以下服務:
- 區塊管理器;
- 全域緩衝區快取;
- 進程間通訊領域。
遠端記憶體存取用於將資料從 PowerHA 傳輸到 DB 節點並返回,因此叢集互連必須支援 RDMA 協定。 PureScale 可以透過乙太網路使用 Infiniband 和 RDMA。
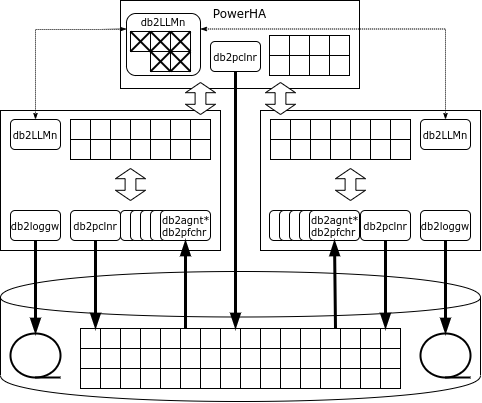
如果某個節點需要一個頁面,而該頁面不在快取中,則該節點會從全域快取中請求該頁面,並且只有當該頁面也不在快取中時,它才會從磁碟讀取該頁面。與 Oracle 不同,請求僅傳送到 PowerHA,而不會傳送到鄰近節點。
如果實例要修改某一行,它會以獨佔模式鎖定該行,並以共用模式鎖定該行所在的頁面。所有的鎖都在全域鎖定管理器中註冊。當事務完成時,節點會向鎖定管理器發送訊息,鎖定管理器將修改後的頁面複製到全域快取中,釋放鎖定,並使其他節點快取中的修改後的頁面無效。
如果包含被修改行的頁面已經被鎖定,鎖管理器將從進行修改的節點的記憶體中讀取修改後的頁面,釋放鎖,使其他節點的快取中的修改後的頁面無效,並將頁面鎖返回給請求它的節點。
「髒」頁面(即已修改的頁面)可以從常規節點和 PowerHA(castout)寫入磁碟。
如果 pureScale 節點發生故障,則復原僅限於故障發生時尚未完成的交易:該節點在已完成的交易中修改的頁面位於 PowerHA 上的全域快取中。此節點在叢集伺服器之一上的精簡配置中重新啟動,回滾任何待處理的事務,並釋放鎖定。
PowerHA 在兩台伺服器上運行,主節點同步複製其狀態。如果主節點發生故障,PowerHA 叢集將使用備援節點繼續運作。
當然,如果透過單一節點存取資料集,叢集的整體效能會更高。 PureScale 甚至可以注意到某個資料區域正在由單一節點處理,然後與該區域相關的所有鎖都將由該節點在本地處理,而無需與 PowerHA 通訊。但是一旦應用程式嘗試透過另一個節點存取該數據,集中式鎖定處理就會恢復。
IBM 對 90% 讀取、10% 寫入工作負載進行的內部測試與實際生產工作負載非常相似,結果顯示可幾乎線性擴展到 128 個節點。不幸的是,測試條件尚未披露。
HPE NonStop SQL
惠普企業的產品組合中也有自己的高可用性平台。這是 NonStop 平台,由 Tandem Computers 於 1976 年向市場推出。 1997 年,該公司被康柏公司收購,康柏公司又在 2002 年與惠普公司合併。
NonStop 用於建立關鍵任務應用程序,例如 HLR 或銀行卡處理。該平台以硬體和軟體綜合體(設備)的形式提供,其中包括運算節點、資料儲存系統和通訊設備。 ServerNet 網路(在現代系統中為 Infiniband)既用於節點之間的交換,也用於存取資料儲存系統。
該系統的早期版本使用彼此同步的專有處理器:所有操作由多個處理器同步執行,一旦其中一個處理器出現錯誤,它就會關閉,而第二個處理器繼續工作。後來,系統切換到傳統處理器(首先是 MIPS,然後是 Itanium,最後是 x86),並開始使用其他機制進行同步:
- 訊息:每個系統進程都有一個「影子」孿生,活動進程會定期向其發送有關其狀態的訊息;如果主進程失敗,影子進程從最後一條訊息確定的時刻開始工作;
- 投票:資料儲存系統有一個特殊的硬體元件,它接受多個相同的請求,並且只有當請求匹配時才執行它們;處理器不採用物理同步,而是非同步運行,並且僅在輸入/輸出時刻比較其工作結果。
自 1987 年以來,NonStop 平台一直在運行關係 DBMS - 首先是 SQL/MP,後來是 SQL/MX。
整個資料庫被分成幾個部分,每個部分負責自己的資料存取管理器(DAM)流程。它提供資料記錄、快取和鎖定機制。資料處理由執行程序(Executor Server Process)執行,與對應的資料管理器運行在相同的節點上。 SQL/MX 排程器在工作人員之間分割任務並合併結果。當需要做出一致的變更時,使用 TMF(事務管理工具)庫提供的兩階段提交協定。
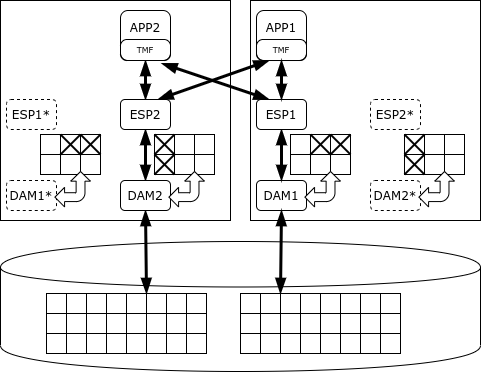
NonStop SQL 可以對程序進行優先排序,以便長時間的分析查詢不會幹擾事務的執行。然而,它的目的正是處理短期交易,而不是分析。開發商保證NonStop集群可用性達到五個「九」的級別,即每年停機時間僅5分鐘。
SAP-HANA
HANA DBMS(1.0)的第一個穩定版本於 2010 年 2013 月發布,SAP ERP 套件於 XNUMX 年 XNUMX 月轉換至 HANA。該平台基於購買的技術:TREX 搜尋引擎(列式儲存搜尋)、P*TIME 和 MAX DB DBMS。
「HANA」這個字本身就是「高性能分析設備」的縮寫。此 DBMS 以程式碼形式提供,可在任何 x86 伺服器上運行,但是,工業安裝僅允許在經過認證的設備上運行。有來自惠普、聯想、思科、戴爾、富士通、日立、NEC 的解決方案。一些聯想配置甚至允許在沒有 SAN 的情況下運行——通用儲存系統的角色由本機磁碟上的 GPFS 叢集扮演。
與上面列出的平台不同,HANA 是一種記憶體 DBMS,即主資料映像儲存在 RAM 中,並且只有日誌和定期快照寫入磁碟以便在發生災難時進行復原。
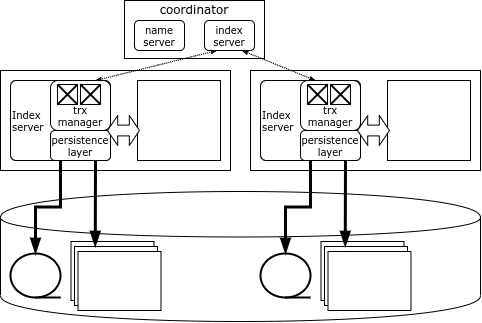
每個HANA叢集節點負責自己所屬的部分數據,資料映射儲存在一個特殊的元件-Name Server中,位於協調器節點上。節點之間資料不會重複。有關死鎖的資訊也儲存在每個節點上,但係統有一個全域死鎖偵測器。
連接到叢集時,HANA 用戶端會下載其拓撲,然後可以根據所需的資料直接存取任何節點。如果事務影響單一節點上的數據,則可以由該節點在本地執行,但如果多個節點上的資料發生更改,則發起者節點將聯繫協調者節點,後者將開啟並協調分散式事務,並使用最佳化的兩階段提交協定提交它。
協調器節點是重複的,因此如果協調器發生故障,備份節點將立即接管。但是如果有資料的節點發生故障,存取其資料的唯一方法就是重新啟動該節點。通常,HANA 叢集會維護一個備用伺服器,以便盡快重新啟動其上遺失的節點。
來源: www.habr.com
